Uma Cadeia de Markov é por vezes um modelo probabilístico adequado para determinada série temporal em que a observação em
um determinado momento é uma categoria à qual um indivíduo corresponde. A mais simples Cadeia de Markov é aquela na qual existe um
número finito de estados ou categorias, um número finito de pontos no tempo equidistantes em que são feitas as observações, a
cadeia é de primeira ordem e as probabilidades de transição são as mesmas para cada intervalo de tempo. Estas foram as cadeias que
estudamos até agora.
Vamos considerar aqui vários métodos para obter estimadores da matriz de probabilidades transição em três situações:
quando o comprimento do intervalo entre os pontos de tempo do modelo coincide com o intervalo de observação, quando a duração deste
comprimento do intervalo entre os pontos de tempo não coincide com o intervalo de observação e quando os intervalos de observação
são desiguais em comprimento. Além disso, discutimos o uso da técnica de bootstraps como um método para avaliar a incerteza nas estimaçães
e para a construção de intervalos de confiança da matriz de transição. Também estudaremos como verificar a ordem de uma Cadeia de Markov.
Depois apresentamos testes para verificar a ordem da cadeia. Diferentes livros e artigos foram consultados para escrever este texto, alguns importantes são
Jacobsen (1982), Billingsley (1961a), Billingsley (1961b) e Basawa & Prakasa Rao (1980). Outras referências serão também mencionadas no texto.
Seja \(\{X_1,X_2,\cdots\}\) um processo estocástico ou uma sequência de variáveis aleatórias assumindo valores em algum conjunto
finito chamado aqui de espaço de estados \(\mathcal{S}\). A variável \(X_n\) deve ser considerada como estado no tempo \(n\) de um sistema cuja
evolução é regida por um conjunto de leis de probabilidade.
A típica Cadeia de Markov a tempo discreto limita a descrição do histórico de cada sujeito a pontos de tempo com igualmente espaçados.
Em outras palavras, em vez de modelar a possibilidade de progressão a cada instante no tempo, ou seja, dia, mês ou ano. O intervalo entre esses pontos
de tempo é conhecido como o comprimento do ciclo.
Nesta seção, presume-se que a matriz de probabilidades de transição vai ser estimada a partir de dados de coorte longitudinais, com
intervalos de observação comuns a todos os sujeitos. A atenção é restrita a obtenção da estimativa de máxima
verossimilhança da matriz de transição em três situações específicas crescentes de complexidade. O primeiro caso
é quando os intervalos de observação são constantes e coincidem com a duração do ciclo. O segundo caso acontece quando os
intervalos de observação são constantes, mas não coincidem com a duração do ciclo. Os métodos discutidos na presente
seção somente podem ser utilizados em certas situações. Quando não puder, o método discutido para o terceiro caso é
possível. O terceiro caso, representa a situação mais comum, quando os intervalos de observação não são iguais em
comprimento. A duração do ciclo pode ou não coincidir com um destes intervalos.
Vamos considerar \(\{x_0,x_2,\cdots,x_{n} \}\) uma amostra de uma Cadeia de Markov com probabilidades de transição \(p_{x,y}\) e distribuição
inicial \(\pi_0\). Observe que \(\{x_0,x_1,\cdots,x_n \}\) deve ser uma sequência de \(n+1\) estados. Então, a probabilidade de que \(x_0,x_1,\cdots,x_n\)
seja essa sequência é justamente
\begin{equation*}
\pi(x_0)p_{x_0,x_1}\cdots p_{x_{n-1},x_n}\cdot
\end{equation*}
Para \(x,y=1,2,\cdots,d\), seja \(n_{x,y}\) o número de transições, assim a matriz \((n_{x,y})\) vai ser chamada de matriz de contagens de
transições da sequência. Dado que
\begin{equation*}
\pi(x_0)p_{x_0,x_1}\cdots p_{x_{n-1},x_n} \, = \, \pi(x_0) \prod_{x,y} p_{x,y}^{n_{x,y}},
\end{equation*}
a contagem das transições junto com o estado inicial formam uma estatística suficiente. A distribuição dessa estatística vai
ser nosso objetivo.
Sabemos que a probabilidade de obtiver uma sequência em particular, que começe com com \(x_0\) e tenha matriz de contagens de transição
\((n_{x,y})\) foi dada acima e, com o objetivo de encontrarmos a distribuição da estatística suficiente é necessário somente contar
o número de tais sequ≖ncias. Se \(n_{x,\cdot}=\sum_y n_{x,y}\) e \(n_{\cdot, y}=\sum_x n_{x,y}\) então \(\{n_{x,\cdot}\}\) e \(\{n_{\cdot, y}\}\)
são as frequências das contagens de \(\{x_0,x_1,\cdots,x_{n-1}\}\) e \(\{x_1,x_2,\cdots,x_n \}\) respectivamente. Disso seque que
\begin{equation*}
\begin{array}{rcl}
n_{x,\cdot} \, - \, n_{\cdot, y} & = & \pmb{1}_{x}(x_0)-\pmb{1}_{x}(x_n) \\[0.6em]
\displaystyle \sum_{x,y} n_{x,y} & = & \displaystyle \sum_x n_{x,\cdot} \, = \, \sum_y n_{\cdot, y} \, = \, n \cdot
\end{array}
\end{equation*}
É claro a partir da primeira dessas relações que \((n_{x,y})\) e o estado inicial determinam completamente o estado final. Da mesma forma, \((n_{x,y})\)
e o estado do final determinam o estado inicial. No entanto, \((n_{x,y})\) sozinho não determina os estados inicial e final: por exemplo, as sequências
\(\{1,2,1 \}\) e \(\{2,1,2 \}\) têm contagens de transição idênticas. A resposta a este problema combinatório é a seguinte.
Teorema 1. Fórmula de Whittle (1955))
Seja \((n_{x,y})\) uma matriz \(d\times d\) de inteiros não negativos satisfazendo que \(\sum_{xy} n_{xy}=n\) e tais que
\begin{equation*}
n_{x,\cdot} - n_{\cdot, y} \, = \, \pmb{1}_{x}(u) \, - \, \pmb{1}_{x}(v),
\end{equation*}
\(x,y=1,\cdots,d\) para algum par \(u,v\). Se \(N_{u,v}^{(n)}(n_{x,y})\) representa o número de sequências \(\{x_0,x_1,\cdots,x_n\}\) tendo contagens de
transição \((n_{x,y})\) e satisfazendo \(x_0=u\) e \(x_n=v\), então
\begin{equation*}
N_{u,v}^{(n)}(n_{x,y}) \, = \, \dfrac{\displaystyle \prod_x n_{x\cdot}!}{\displaystyle \prod_{x,y} n_{x,y}!}C_{v,u},
\end{equation*}
onde \(C_{v,u}\) é o cofator \((v,u)\) da matriz \((n_{x,y})^*\) de componentes
\begin{equation*}
n_{x,y}^* \, = \, \left\{ \begin{array}{lcl} \pmb{1}_{x}(y) - \dfrac{n_{x,y}}{n_{x,\cdot}} & \mbox{se} & n_{x,\cdot}>0 \\[0.8em]
\pmb{1}_{x}(y) & \mbox{se} & n_{x,\cdot}=0
\end{array}\right.\cdot
\end{equation*}
Demonstração. (Billingsley, 1961b)
A demonstração é por indução. O resultado é fácil de estabelecer se \(n=1\), caso em que ambos os lados de são 1.
Se \((n_{u,v})\) é \((n_{x,y})\) com a \((u,v)\) entrada diminuída em 1, temos que
\begin{equation*}
N_{u,v}^{(n)}(n_{x,y}) \, = \, \sum_w N_{w,v}^{(n-1)}(n_{u,w}),
\end{equation*}
onde a soma se estende sobre aqueles \(w\) para so quais \(n_{u,w}>0\). Por isso, basta mostrar que o lado direito de \(N_{u,v}^{(n)}(n_{x,y})\) satisfaz esta mesma
relação ou que
\begin{equation*}
(n_{x,y})^* \, = \, \sum_w n_{u,w}n_{u,\cdot}^{-1}(n_{v,w})^*(u,w)\cdot
\end{equation*}
Desde que \((n_{v,w})^*\) e \((n_{x,y})^*\) concordem fora da \(w\)-ésima coluna, \((n_{v,w})^*(u,w)=(n_{v,w})^*\). Com este fato, juntamente com
a definição, segue que \((n_{x,y})^*\) é equivalente a \(\sum_w n_{u,w}^*(n_{v,w})^*=0\) onde a soma se estende sobre todos os \(w\). Dado que
\(\sum_w n_{u,w}^*(n_{v,w})^*=\pmb{1}_{u}(v)|(n_{x,y})^*|\), a expressão recorrente acima vale para o caso no qual \(u\neq v\) e é
necessário somente mostrar que \(|(n_{x,y})^*|=0\) caso \(u=v\). Suponhamos convenientemente que \(n_{x,\cdot}=n_{\cdot,x}\) seja positivo para
\(x\leq r\) e zero para \(x>r\). Então \((n_{x,y})\) tem a forma
\begin{equation*}
(n_{x,y})=\begin{pmatrix}
A & 0 \\ 0 & 0
\end{pmatrix},
\end{equation*}
onde \(A\) é uma matriz \(r\times r\). Pela definição,
\begin{equation*}
(n_{x,y})^*=\begin{pmatrix}
A^* & 0 \\ 0 & \mbox{I}
\end{pmatrix},
\end{equation*}
onde as linhas de \(A^*\) somam zero. Por isso, \(|(n_{x,y})^*|=|A^*|=0\).
▉
Exemplo 1: Cadeia com dois estados.
Seja, por exemplo, a sequência de 12 valores observados \(\{0,1,1,0,1,0,1,1,1,0,0,1\}\). Esta sequência tem \(u=0\) e \(v=1\) e
matriz de contagens de transição
\begin{equation*}
(n_{x,y}) \, = \, \begin{pmatrix} 1 & 4 \\ 3 & 3 \end{pmatrix}\cdot
\end{equation*}
Podemos utilizar a seguinte função R para encontrarmos a matriz de contagens de transição:
Vemos, do Teorema 1 que
\begin{equation*}
n_{x,y}^* \, = \, \begin{pmatrix} \dfrac{4}{5} & -\dfrac{4}{5} \\[0.8em] -\dfrac{1}{2} & \dfrac{1}{2} \end{pmatrix}
\end{equation*}
e \(C_{0,1}=4/5\). Temos que
\begin{equation*}
N_{0,1}^{(12)}(n_{x,y}) \, = \, \dfrac{5!\cdot 6!}{1!\cdot 3!\cdot 3!\cdot 4!}\cdot \dfrac{4}{5} \, = \, 80\cdot
\end{equation*}
Logo, 80 é o número de sequências \(\{0,x_1,\cdots,x_{10},1\}\) tendo contagens de transição \((n_{x,y})\).
Desenvolvemos uma função R para encontrarmos o número de sequências \(\{x_0,x_1,\cdots,x_n\}\) tendo
contagens de transição \((n_{x,y})\) e satisfazendo \(x_0=u\) e \(x_n=v\):
> Whittle = function(M, u, v){
n = length(rowSums(M))
Prod1 = 1;
for(i in 1:n) Prod1 = Prod1*gamma(rowSums(M)[[i]]+1)
Prod2 = 1;
for(i in 1:dim(M)[1]){
for(k in 1:dim(M)[2]) Prod2 = Prod2*gamma(M[i,k]+1)
}
u = which(row.names(M) == u)
v = which(row.names(M) == v)
C = cofactor(eye(n)-M/rowSums(M), v, u)
return((Prod1/Prod2)*C)
}
> Whittle(Matriz, 0, 1)
[1] 80
Suponhamos que nos seja dada a realização de uma Cadeia de Markov e que se deseja estimar a matriz de probabilidades de transição.
Uma abordagem é encontrar as contagens de transição e estimar as probabilidades de transição de uma forma óbvia.
Exemplo 2: Cadeia com três estados
Esta é uma situação hipotética. Consideremos uma Cadeia de Markov com três estados da qual é observada a sequência:
Por simples contagem, segue-se que, a matriz do número de transições entre os estados é
\begin{equation*}
(n_{x,y})=\begin{pmatrix}
4 & 8 & 10 \\
13 & 17 & 22 \\
6 & 26 & 9
\end{pmatrix},
\end{equation*}
onde \(n_{x,y}\) denota o número de transições observadas desde o estado \(x\) ao estado \(y\).
Uma vez que o número de transições do estado 2 para o estado 3 é 22 e o número total de transições do estado 2
é \(13+17+22\), uma estimativa empírica de \(\widehat{p}_{2,3}\) é 22/52. Uma estimativa empírica para a matriz de transições
seria então
\begin{equation*}
\widehat{\Gamma}=\begin{pmatrix} \dfrac{4}{22} & \dfrac{8}{22} & \dfrac{10}{22} \\[0.8em]
\dfrac{13}{52} & \dfrac{17}{52} & \dfrac{22}{52} \\[0.8em] \dfrac{6}{41} & \dfrac{26}{41} & \dfrac{9}{41} \end{pmatrix} \cdot
\end{equation*}
Vamos agora mostrar que este é, de fato, a estimativa de máxima verossimilhança condicional de \(\Gamma\), condicionada à
primeira observação. Suponhamos, então, que nós queremos estimar os \(d^2-d\) parâmetros de uma Cadeia de Markov \(\{C_n\}\)
com \(d\) estados a partir uma realização \(x_0,x_1,\cdots,x_T\). A função de verossimilhança condicional à primeira
observação é
\begin{equation*}
L=\prod_{x=1}^d \prod_{y=1}^d \gamma_{x,y}^{n_{x,y}} \cdot
\end{equation*}
Desta expressão obtemos que o logaritmo da função de verossimilhança é
\begin{equation*}
\ell=\sum_{x=1}^d \left( \sum_{y=1}^d n_{x,y}\log \gamma_{x,y} \right)= \sum_{x=1}^d \ell_x,
\end{equation*}
a qual podemos maximizar maximizando cada somando separadamente.
Substituindo \(\displaystyle 1-\sum_{z\neq x} \gamma_{x,z}\) por \(\gamma_{x,x}\), diferenciando cada \(\ell_x\) com relação à todas as probabilidades
de transição não diagonais \(\gamma_{x,y}\) e igualando as derivadas a zero obtemos
\begin{equation*}
0=\dfrac{-n_{x,x}}{\displaystyle 1-\sum_{z\neq x} \gamma_{x,z}}+\dfrac{n_{x,y}}{\gamma_{x,y}}=-\dfrac{n_{x,x}}{\gamma_{x,x}}+\dfrac{n_{x,y}}{\gamma_{x,y}} \cdot
\end{equation*}
Assim, a menos que um denominador seja zero na equação acima
\begin{equation*}
n_{x,y}\gamma_{x,x}=n_{x,x}\gamma_{x,y},
\end{equation*}
e por isso \(\displaystyle \gamma_{x,x}\sum_{y=1}^d n_{x,y}=n_{xx}\).
Isto implica que o ponto de máximo local da função de verossimilhança das probabilidades de transição é
\begin{equation*}
\widehat{\gamma}_{x,x}=\dfrac{n_{x,x}}{\displaystyle \sum_{y=1}^d n_{x,y}} \quad \mbox{e} \quad \widehat{\gamma}_{x,y}=\dfrac{n_{x,y}}{\displaystyle \sum_{y=1}^d n_{x,y}} \cdot
\end{equation*}
Também poderíamos utilizar multiplicadores de Lagrange para expressar as restrições \(\sum_{y=1}^d \gamma_{x,y}=1\), sob as quais
buscamos maximizar os termos \(\ell_x\) e, portanto, a função de verossimilhança. Mas isso, não é necessário em geral.
Exemplo 3: Continuação do Exemplo 2
Fazendo uso do pacote de funções markovchain, construímos a matriz de contagens de transições utilizando
o comando createSequenceMatrix, como mostrado a seguir:
Às vezes o número de Whittle é impraticável, como nesta situação.
Utilizando a função anterior obtemos que:
> Whittle(Matriz, u = 2, v = 1)
[1] 8.462769e+44
A questão agora é transformar as frequências observadas em probabilidades, para isso utilizamos o
comando markovchainFit do qual temos por resposta uma lista com diversas informações. A
primeira resposta é a matriz de probabilidades de transição estimada, a qual pode ser obtida também
digitando mcFitMLE[[1]].
> mcFitMLE = markovchainFit(data=x)
> mcFitMLE$estimate
1 2 3
1 0.1818182 0.3636364 0.4545455
2 0.2500000 0.3269231 0.4230769
3 0.1463415 0.6341463 0.2195122
> mcFitMLE[[1]]
MLE Fit
A 3 - dimensional discrete Markov Chain defined by the following states:
1, 2, 3
The transition matrix (by rows) is defined as follows:
1 2 3
1 0.1818182 0.3636364 0.4545455
2 0.2500000 0.3269231 0.4230769
3 0.1463415 0.6341463 0.2195122
Teorema 2.
Seja \(\{C_n\}\) uma Cadeia de Markov ergódica. Então, independentemente da distribuição inicial
\begin{equation*}
\sqrt{n_{x,y}}(\widehat{p}_{x,y}-p_{x,y}) \overset{D}{\longrightarrow} Z,
\end{equation*}
onde \(Z\sim N(0,\Sigma)\), \(\Sigma=(\sigma_{x,y})\), \(x,y\in\mathcal{S}\) e
\begin{equation*}
\sigma_{x,y}=\left\{\begin{array}{lcl} p_{x,y}(1-p_{x,y}) & \quad \mbox{caso} \quad \{x,y\}\ne \{z,w\} \\
-p_{x,y}p_{x,z} & \quad \mbox{caso} \quad x=z, \; y\ne w \\
0 & \quad \mbox{caso contrário} \end{array} \right.
\end{equation*}
Demonstração.
Consequência do Teorema Central do Limite (Anderson & Goodman, 1957).
▉
O resultado deste teorema implica que a covariância assintótica tem uma estrutura multinomial dentro das linhas e independência entre as
linhas. Como resposta temos também o desvio padrão da estimação, calculado segundo a expressão acima, como
\(\widehat{p}_{x,y}/\sqrt{n_{x,y}}\), assim como um intervalo de confiança de 95%, os limites inferior e superior deste intervalo e o valor da
função de log-verossimilhança.
Exemplo 3: Continuação do Exemplo 2
Mostramos agora a forma de obtermos os resultados apresentados no Teorema 2. Todos os resultados estão guardados no objeto mcFitMLE e
para sabermos o valor do desvio padrão, por exemplo, digitamos:
Então, por final, obtemos os limites inferior e superior do intervalos confidenciais como mostrado abaixo. Ainda mostramos o valor
da função \(\ell\), o logaritmo da função de verosimilhança.
O nosso próximo exemplo é uma aplicação de Cadeias de Markov em engenharia; tem a ver com pontes e baseia-se no
trabalho de Skuriat-Olechnowska (2005). A maioria das pontes na Holanda é construída em concreto e mais de metade delas tem mais
de 30 anos. À medida que as pontes se deterioram a uma velocidade acelerada devido à corrosão, à degradação
do concreto e ao dano do veículo a Divisão de Engenharia Civil de Rijkswaterstaat, organização responsável pela
concepção, construção, gestão e manutenção das principais infra-estruturas da Holanda. Isso inclui
a rede rodoviária principal, a rede de hidrovia principal e os sistemas de águas. Faz parte do Ministério dos Transportes, das
Obras Públicas e da Gestão da Àgua deve repará-las e, sempre que possível, impedem uma maior deterioração.
O referido ministério é o principal encarregado por de cerca de 3500 pontes na Holanda por isso o ministério gosta de conhecer a
vida útil restante de suas estruturas já que é sabido que durante a vida útil, as estruturas precisarão ser reparadas.
Neste momento, uma estratégia de reparo baseada em inspeções é usada para determinar quando o reparo será feito. Esta
estratégia de reparo para pontes de concreto na Holanda resulta em reparação de pontes a cada 25 até 35 anos. O reparo
será normalmente de 0.5% até 155% da área da estrutura (van Beek et al., 2003).
Estes dados contém informações sobre o estado em que a estrutura de pontes encontraram-se durante as inspeções, ou seja,
contém um histórico de inspeções e o ano de construção.
Estado
Perfeito
Muito bom
Bom
Razoável
Mediocre
Ruim
Muito ruim
Classificação
0
1
2
3
4
5
6
Tabela 1. Esquema de classificação da condição das pontes.
Para o gerenciamento das informações utilizam-se diversos sistemas, dois deles: PONTIS e BRIDGIT são dois dos Sistemas de Gerenciamento
de Ponte mais comuns atualmente disponíveis (Golabi and Shepard, 1997; Thompson et al., 1998). Ambos têm suas origens no Arizona Pavement
Management System desenvolvido no final da década de 1970 e são quase exclusivamente utilizados nos Estados Unidos. Todos esses modelos usam
Cadeias de Markov para modelar a deterioração incerta das pontes ao longo do tempo. Nos Países Baixos, os resultados das inspeções
de ponte são registrados em um banco de dados, que é usado principalmente para manutenção de registros.
Esta base de dados é uma fonte muito rica de informações, contém dados coletados ao longo de quase 20 anos, e a finalidade da
pesquisa atual é usar esses dados para estimar a taxa de deterioração.
Definida a codificação dos estados que vamos utilizar, classificado o estado de conservação das pontes inspecionadas procedemos à
estimação da matriz de probabilidades de transição desta cadeia. A tabela a seguir mostra a contagem das transições de
cada estado para qualquer outro estado.
Para
0
1
2
3
4
5
6
De
0
520
134
327
111
36
7
0
1
270
128
222
97
36
7
0
2
284
101
368
193
61
9
5
3
94
33
119
131
42
3
1
4
16
14
42
50
17
7
0
5
7
3
4
4
3
0
1
6
1
1
0
3
1
0
0
Tabela 2. Contagem original de transições das classificações das condições das pontes.
Reconhecendo que as Cadeias de Markov são uma ferramenta adequada para modelagem da deterioração de pontes propomos
técnicas adequadas que levem em consideração o tipo especial de censura envolvendo inspeções de pontes.
Além disso, gostaríamos de ter testes estatísticos à nossa disposição para avaliar a validade
e o desempenho relativo de diferentes tipos de Cadeias de Markov.
Essencialmente, estamos interessados em obter a funcionalidade de um sistema de gerenciamento de ponte como PONTIS, ao mesmo tempo em que cuidamos
especialmente a validade de nossos pressupostos e os modelos resultantes em relação à situação nos Países Baixos.
Nós vemos que a informação, que vem de dados de deterioração, é bastante subjetiva. Vemos que a classificação
da condição que varia de um perfeito (estado 0) para um muito ruim (estado 6) através da definição de estados. Interessante observar
que pontes em estados mau e muito mal raramente acontecem, por causa disso procedeu-se à junção destes estados e codificou-se como 5. O
resultado apresenta-se na Tabela a seguir. Os dados provêm da Divisão de Engenharia Civil do Ministério dos Transportes, Obras Públicas e
Gestão da Àgua na Holanda.
Para
0
1
2
3
4
5
De
0
520
134
327
111
36
7
1
270
128
222
97
36
7
2
284
101
368
193
61
14
3
94
33
119
131
42
4
4
16
14
42
50
17
7
5
7
3
4
4
3
1
6
1
1
0
3
1
0
Tabela 3. Contagem de transições das classificações das condições das pontes.
Exemplo 4: Inspeção de pontes (Skuriat-Olechnowska, 2005).
O banco de dados inclui um total de 5986 eventos de inspeções registradas para 2473 superestruturas individuais. Ignorando o tempo entre a
construção da ponte e uma primeira inspeção, há 3513 transições registradas entre estados de condição.
Pela Tabela 3 podemos observar que os estados 5 e 6 raramente ocorrem no banco de dados. Para determinar uma matriz de probabilidade de transição,
esses estados foram combinados no estado 5 para representar uma condição "ruim" e "muito ruim", caso contrário, algumas probabilidades de
transição podem ser zero.
Foi realizada uma análise sobre modelagem de deterioração de pontes mas os dados foram coletados, no banco de dados denominado DISK e
fornecidos pelo Divisão de Engenharia do Rijkswaterstaat, continham um número limitado de estados de condição das pontes, decidimos usar uma
Cadeia de Markov para modelar a deterioração. O modelo de deterioração de Markov é baseado em condições. Por isso, é
flex&iacue;vel na adaptação aos dados de inspeção visual.
Infelizmente, não pudemos observar o tempo exato das transições. Assim, adaptamos uma Cadeia de Markov com censura de intervalo. Censura de intervalo
significa que não sabemos a hora exata de um evento. Em nosso contexto, isso significa que não sabemos a hora em que a ponte se move de um estado para outro.
Uma probabilidade de transição foi definida como a probabilidade de uma ponte passar de um estado para outro, igual ou pior. Assumimos que nenhuma manutenção
foi realizada entre as inspeções.
Com o auxilio dos seguintes comandos investigamos o comportamento futuro desta cadeia:
Temos por resposta que 32.4% das pontes inspecionadas corresponderão a pontes em perfeito estado, 10.9% corresponderá a pontes em estado
muito bom, 30.8% permanecerão em estado bom, 18.6% das pontes corresponderão à pontes em estado de conservação razoável,
6.1% estarão em estado medíocre na próxima avaliaço enquanto 1.2% delas estarão em estado ruim ou muito ruim.
Consideremos a situação na qual \(L_0\) seja o intervalo de observação, porém o desejado seria \(L_d\) a duração
do ciclo desejado. O estimador de máxima verossimilhança da matriz de transições de probabilidades é \(\widehat{\Gamma}_0\),
associada com o comprimento do ciclo de observação \(L_0\).
Pela propriedade de invariância, o estimador de máxima verossimilhança da matriz de transição associado com a duração
do ciclo \(L_d\) é obtida como
\begin{equation*}
\widehat{\Gamma}_d=\widehat{\Gamma}^t,
\end{equation*}
onde \(t=L_d/L_0\).
No exemplo anterior, se em vez de observarmos por um período de um ano tivesse sido o período de observação de dois anos: \(L_0=2\) e
\(L_d=1\). Então, pode-se encontrar a raiz quadrada da matriz de transição estimada, devido a que \(t=1/2\).
O cálculo da matriz \(\widehat{\Gamma}_d\) é simples a partir da decomposição de \(\widehat{\Gamma}_0\) em seus valores e vectores
próprios, chamada de decomposição espectral. Com base nesta decomposição, esta matriz pode ser escrita como
\begin{equation*}
\widehat{\Gamma}_0=V\Lambda V^{-1},
\end{equation*}
onde
\begin{equation*}
\Lambda=\begin{pmatrix} \lambda_1 & 0 & \cdots & 0 \\
0 & \lambda_2 & \cdots & 0 \\
\vdots & \vdots & \vdots & \vdots \\
0 & 0 & \cdots & \lambda_N
\end{pmatrix}
\end{equation*}
é a matriz de auto-valores e \(V\) a matriz de auto-vetores correspondentes.
Os autovalores são transformados segundo o valor da potência \(t\), mas os autovetores não mudam. Temos diversas opções disponíveis
de funções de decomposição de matrizes, de forma que estes cálculos podem ser feitos muito rapidamente, por exemplo, no R a função
básica eigen permite realizar estes cálculos.
Este método é muito semelhante a um método utilizado para se obter o estimador de máxima verossimilhança da matriz de transição a
tempo contínuo em Kalbfleisch & Lawless (1985). No entanto, enquanto este método funciona sempre no caso a tempo contínuo, nem sempre funciona no caso a tempo discreto.
Um modelo a tempo discreto não é necessariamente Markov em todos os ciclos. Isto é comparável a dizer que alguns dos valores próprios da matriz de
transição podem ser negativos. Desde que a matriz de transição estimada \(\widehat{\Gamma}\) seja semidefinida positiva, todos os valores próprios
serão não-negativos, este método permitirá calcular o estimador de máxima verossimilhança diretamente.
O procedimento apresentado não é único na literatura especializada, porém o consideramos de fácil implementação. Um outro procedimento
pode ser consultado em Miller and Homan, (1994).
Vejamos o exemplo a seguir o qual é um estudo de coorte sobre o HIV presentado em Sendi, P.P., Craig, B.A., Pfluger, D., Gafni, A. and Bucher, H.C.. Systematic validation of disease
models for pharmacoeconomic evaluations. Journal of Evaluation in Clinical Practice. 1999; Volume 5; pp. 283-295.
Os pesquisadores construíram uma Cadeia de Markov estacionária para descrever a progressão mensal de indivíduos infectados por HIV em maior risco de desenvolver
infecção por Complexo Mycobacterium avium. O Complexo Mycobacterium avium é um grupo de bactérias que pode ser encontrado normalmente na rede hidráulica das
cidades e em pessoas com imunossupressão, como portadores do HIV/AIDS. Esta progressão incluía a possibilidade de movimento entre três faixas de contagem de células
CD4 distintas, com e sem AIDS.
Em nosso modelo, definimos quatro categorias amplas de estados de saúde para descrever a história de indivíduos infectados pelo HIV com alta depleção de CD4
e maior risco de desenvolver doença de MAC. Essas categorias são:
(1) não AUXILIA. Indivíduos infectados pelo HIV assintomáticos sem história de doença do indicador de AIDS. Estratificamos a condição
"Sem AIDS" em três níveis de CD4: 0 - 49 células/mm\(^3\), 50 - 74 células/mm\(^3\), 75+ células/mm\(^3\). Condiciona-se o risco de AIDS e MAC sintomáticos
na contagem de células CD4 do paciente;
(2) AIDS (não-MAC). Os indivíduos infectados pelo HIV com AIDS de acordo com os Centros de Controle e Prevenção de Doenças dos Estados Unidos (1992)
expandiram a definição de vigilância (excluindo uma contagem de células CD4 <200 ceacute;lulas/mm\(^3\)). Estratificada a condição de AIDS em três níveis
de CD4: 0 - 49 células/mm\(^3\), 50 - 74 células/mm\(^3\), 75+ células/mm\(^3\). Condiciona-se o risco de morrer de AIDS sintomática ou de desenvolver MAC após
a contagem de células CD4 do paciente;
(3) MAC. Pacientes HIV-positivos com infecção pelo complexo Mycobacterium avium e;
(4) morte. Os pacientes que morrem por qualquer causa mudam para absorver a Cadeia de Markov.
Para
0-49
50-74
75+
De
0-49
682
33
25
50-74
154
64
47
75+
19
19
43
Tabela 4. Transições observadas em seis meses na contagem de células CD4 (1993-1995). Estudo realizado na Suiça com pacientes infectados pelo HIV..
Exemplo. Estudo de coorte HIV
Dados coletados num estudo multicêntrico onde os pacientes infectados pelo HIV têm visitas de acompanhamento bastante regulares, a cada seis meses. Os dados estão
disponíveis no arquivo de dados craigsendi, pacote markovchain e mostrados na Tabela acima.
> data(craigsendi)
> csMc = as(craigsendi, "markovchain")
> csMc
Unnamed Markov chain
A 3 - dimensional discrete Markov Chain defined by the following states:
0-49, 50-74, 75-UP
The transition matrix (by rows) is defined as follows:
0-49 50-74 75-UP
0-49 0.9216216 0.04459459 0.03378378
50-74 0.5811321 0.24150943 0.17735849
75-UP 0.2345679 0.23456790 0.53086420
Devemos mencionar que os dados apresentados na Tabela acima constituem a contagem das transições observadas mas, uma vez convertidos em Cadeia de Markov
temos as probabilidades estimadas de transição.
A apresentação do Exemplo acerca da estudo de coorte HIV permite-nos a leitura dos dados na referência mencionada antes e guardados no arquivo
craigsendi. Esclarecemos novamente que os dados originais foram observados num per&iaute;odo de seis meses, o qual não é o desejado no
estudo, queremos o comportamento mensal.
Mostramos a continuação nossa implementação no R do procedimento para encontrarmos a matriz de probabilidades de transição
no ciclo desejado. Observe que, em nossa implementação no seguinte exemplo, todos oa auto-valores foram positivos.
Exemplo (Continuação)
Para esta análise, a duração do ciclo desejado é de um mês. Para estimar a matriz de probabilidades de transição para
esse intervalo, vamos decompor \(\widehat{\Gamma}^6\). Utilizando a função R eigen obtemos:
Traduzindo estes resultados: a matriz de auto-valores é
\begin{equation*}
\Lambda=\begin{pmatrix} 1.000000 & 0 & 0 \\
0 & 0.5701572 & 0 \\
0 & 0 & 0.123838 \\
\end{pmatrix}
\end{equation*}
e a matriz de auto-vetores correspondente é
\begin{equation*}
V=\begin{pmatrix} -0.5773503 & -0.1276876 & 0.02817213 \\
-0.5773503 & 0.2867671 & -0.87297660 \\
-0.5773503 & 0.9494527 & 0.48694783 \\
\end{pmatrix}\cdot
\end{equation*}
Como mencionado o ciclo observado foi de 6 meses, mas o ciclo desejado é de um mês. Para isso tomamos a raiz sexta de \(\Lambda\) e fazendo os cálculos sugeridos
obtemos que a matriz de transição estimada de um mês é
\begin{equation*}
\widehat{\Gamma}=\begin{pmatrix} 0.9819 & 0.0122 & 0.0059 \\
0.1766 & 0.7517 & 0.0717 \\
0.0177 & 0.0933 & 0.8830 \\
\end{pmatrix}\cdot
\end{equation*}
Se esta matriz fosse multiplicada seis vezes o resultado será a matriz \(\widehat{\Gamma}^6\) como esperado. Observe que este processo é muito
rápido e simples. Neste exemplo, a matriz sugere que haverá demasiados pacientes no estado 0-49 após seis ciclos.
Podemos agora, inclusive, identificarmos a distribuição estacionária, para isso fazemos:
Significa que, a longo prazo, 83.4% dos indivíduos infectados por HIV mantem-se na faixa 0-49 de contagem de células CD4, 7.7% apresentam contagem na faixa
50-74 em 8.9% dos casos a contagem é 75 ou mais.
Muitas vezes acontece ser útil descrever um processo estocástico como um conjunto de estados discretos com transições probabilísticas e exemplos abundam
em vários campos, como o estudo de processos químicos, sequências de DNA, finanças dentre outros. Se a probabilidade de transição para o próximo
estado é condicionada apenas no estado atual, chamamos este modelo de uma Cadeia de Markov, e quando as probabilidades condicionais não são dadas de outra forma, elas
serão estimadas a partir de uma série temporal de observações.
Mas, e caso a probabilidade de transição para o próximo estado seja condicionada não somente no estado atual? em tais situações surgem novos
questionamentos.
Se a ordem da Cadeia de Markov estiver em questão o primeiro é respondermos: o que é ordem de uma Cadeia de Markov?
Definição 7 (Ordem de uma Cadeia de Markov).
Uma sequência de observações discretas a tempo discreto \(\{C_n\}_{n\geq 1}\) formam uma Cadeia de Markov de ordem
\(k\) se a probabilidade condicional satisfaz
\begin{equation*}
P(C_{n+1} \, | \, C_n,C_{n-1},\cdots) = P(C_{n+1} \, | \, C_n,\cdots,C_{n-k+1}), \qquad \forall k< n\cdot
\end{equation*}
As cadeias de Markov consideradas até o momento são cadeias de ordem um, ou seja, \(k=1\). Isso significa, como sabemos, que as probabilidades de transição
para um estado futuro dependem apenas do estado atual e não de estados anteriores. Um processo de ordem \(k\) pode sempre ser lançado como de primeira ordem agrupando
estados. Um processo que não tenha dependência do passado ou presente, como variáveis aleatórias independentes, é dito ser uma Cadeia de Markov de
ordem zero.
Por outro lado, como deve ser facilmente percebido cadeias de ordens superiores, ou seja, cadeias de segunda ordem ou superiores implicam numa representação mais complicada.
Considere primeiro uma Cadeia de Markov de segunda ordem. Dado que um indivíduo está no estado \(z\) no instante \(n-2\) e em \(y\) no instante \(n-1\), seja \(\gamma_{zyx}\)
a probabilidade de estar o indivíduo no estado \(x\) no instante \(n\). Uma cadeia estacionária de primeira ordem é uma cadeia especial de segunda ordem, na qual
\(\gamma_{zyz}\) não depende de \(z\).
Para vermos isso, considere o par de estados sucessivos \(z\) e \(y\) definidos como um estado composto \((z,y)\). A probabilidade do estado composto \((y,x)\) no instante \(n\) dado o
estado composto \((z,y)\) no instante \(n-1\) é \(\gamma_{zyx}\). Vejamos isso.
Sabemos que
\begin{equation*}
P(C_n=x|C_{n-1}=y,C_{n-2}=z) = \gamma_{zyx}
\end{equation*}
e queremos verificar se \(P\big(C_n=(y,x)|C_{n-1}=(z,y)\big)= \gamma_{zyx}\). Logo
\begin{equation*}
\begin{array}{rcl}
P\big(C_n=(y,x)|C_{n-1}=(z,y)\big) & = & \gamma_{zyx} \\[0.8em]
P\big(C_n=(y,x)|C_{n-1}=y,C_{n-2}=z\big) & = & P\big(C_n=x, C_{n-1}=y|C_{n-1}=y,C_{n-2}=z\big) \, = \, \gamma_{zyx}\cdot
\end{array}
\end{equation*}
Claro que, a probabilidade do estado \((w,x)\), \(w\neq y\), dado \((x,y)\), é zero. Os estados compostos podem ser encontrados para formar uma cadeia com \(d^2\) estados, onde \(d\)
é o número de estados e com certas probabilidades de transição 0. Esta repressentação nos ajudará na descrição dos testes de
verificação da ordem de uma cadeia a serem descritos aqui.
Verificarmos a ordem de uma Cadeia de Markov poderá ser realizado de diversas maneiras, mas aqui consideraremos duas delas. O primeiro teste, conhecido como teste aproximado,
descrito na Subseção V.3.1 é baseado na estatística \(\chi^2\); por outro lado, um segundo teste descrito na Subseção V.3.2 é conhecido
como teste exato. Devemos mencionar novamente que muitos dos resultados apresentados aqui foram resumidos no artigo de Anderson, T.W. & Goodman, L.A. (1957).
Exemplificaremos a teoria a ser apresentada neste seção com o seguinte exemplo, inspirado no trabalho de Doubleday & Esunge (2011). A ideia é usar Cadeias de Markov
para prever o comportamento dos preços das ações utilizando o índice Dow Jones Industrial Average (DJIA); este foi um índice criado em 1896 por Charles
Dow, editor do The Wall Street Journal e fundador do Dow Jones & Company.
O DJIA é ao lado do Nasdaq Composite e do Standard & Poor's 500 um dos principais indicadores dos movimentos do mercado americano. Dos três indicadores, o DJIA é
o mais largamente publicado e discutido. O cálculo deste índice é bastante simples e baseia-se na cotação das ações de 30 das maiores e
mais importantes empresas dos Estados Unidos. Como o índice não é calculado pela Bolsa de Valores de Nova Iorque, seus componentes são escolhidos pelos editores
do jornal financeiro norte-americano The Wall Street Journal. Não existindo nenhum critério pré-determinado a não ser que os componentes sejam companhias
norte-americanas líderes em seus segmentos de mercado.
Exemplo. Tendência de mercado financeiro
A modelagem do Índice Dow Jones Industrial Average ou DJIA é frequentemente utilizada para determinar estratégias de negociação com o máximo de
recompensa. As mudanças no comportamento do DJIA são importantes, pois os movimentos podem afetar profundamente as escolhas dos investidores, sejam estes indivíduos ou
corporações.
O objetivo neste exemplo é mostrar como analisar o DJIA usando um modelo estocástico de tempo discreto, ou seja, uma Cadeia de Markov. Dois modelos foram destacados, onde o
DJIA foi considerado como sendo em (1) ganho ou perda e (2) ganho ou perda pequeno, moderado ou grande. Esses modelos foram usados para obter probabilidades de transição e
a distribuição estacionária.
Os preços de fechamento do mercado são considerados para que a análise possa ser feita de forma discreta e as probabilidades de transição são
utilizadas como partes de Cadeias de Markov para modelar o mercado. Dada esta formulação de uma matriz de transição e seu estado estacionário, podemos
configurar um sistema de classificação do Dow Jones Industrial Average (DJIA).
A idéia de usar Cadeias de Markov para prever o comportamento dos preços das ações é popular, pois os investidores potenciais estão interessados
nas tendências do mercado, o que pode levar a uma estratégia de investimento ideal.
Para este estudo, serão analisadas duas estratégias, a saber:
Probabilidades do DJIA movendo-se para cima ou para baixo.
Probabilidades do DJIA movendo-se entre as partições dos possíveis ganhos e perdas.
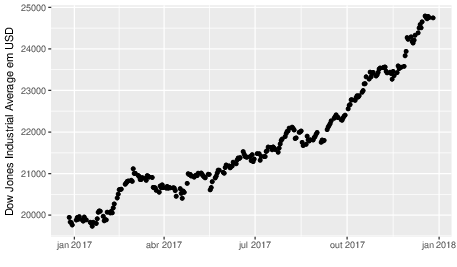
Os valores de fechamento do DJIA foram reunidos para os 252 dias de negociação entre 27 de dezembro de 2016 e 26 de dezembro de 2017. Os dados, apresentados na Figura abaixo,
foram obtidos de Yahoo! Finance em https://finance.yahoo.com/quote/\%5EDJI/history e podem ser obtidos aqui (arquivo CSV).
Questões em aberto: como vamos construir uma Cadeia de Markov a partir dos dados relatados? Qual a ordem desta cadeia?
Figura V.1: Índice Dow Jones Industrial Average, valor no fechamento diário.
Por conveniência, rotularemos os estados que cada medida pode tomar por inteiros positivos até \(d\). Uma seqüência de medidas discretas pode vir de um processo que seja
naturalmente discreto, como uma seqüência de DNA ou de um processo contínuo discretizado por um dispositivo de medição analógico-digital.
A abordagem clássica consiste em formular a questão como um teste de hipótese de que uma cadeia tem uma determinada ordem
e especificar uma estatística de teste discriminante. Muitas vezes, a estatística de teste escolhida tem uma distribuição limitante conhecida, como \(\chi^2\),
da qual o \(p\)-valor é calculado. O uso de uma distribuição limitante é inexato porque somente será alcançado para conjuntos de dados infinitos. Para
pequenos conjuntos de dados, pode ser uma aproximação muito fraca.
Existem abordagens alternativas que fornecem uma resposta positiva à seleção de modelos. O Critério de Informação de Akaike (AIC) e o Critério de
Informação Bayesiano (BIC) e outros produzem rankings em várias ordens com base em suas verossimilitudes relativas e têm penalidades internas por excesso de ajuste.
Infelizmente, essas abordagens dependem de aproximações que somente são válidas no limite de grandes amostras. Em pequenas situações de amostra,
não se pode ter certeza de sua eficácia.
Apesar das deficiências dos testes de hipóteses, existe uma vantagem em que é possível, em princípio, realizar um teste de significância de ordem Markov
exato que seja válido para qualquer tamanho de amostra. Em vez de depender de propriedades assintóticas, a distribuição da estatística de teste é descoberta
por amostragem a partir do conjunto de sequências, aqui referidas como substitutos, que coincidem exatamente com as propriedades da ordem \(n\) da séerie temporal observada. O desafio
é gerar eficientemente um grande número de amostras, especialmente para pedidos superiores. Para o nosso conhecimento, nenhuma solução para este problema foi relatada na
literatura conhecidas por nós.
Para realizar um teste e verificar, como hipótese nula, se a cadeia é de ordem \(k\) é necessário calcular a distribuição de uma
estatística de ordem superior adequada. Se a estatística de ordem superior observada for suficientemente improvável, a hipóteses nula será
rejeitada. A probabilidade, dada a hipóteses nula, da estatística de teste alcançando o valor observado ou um mais extremo é referida como \(p\)-valor.
Tipicamente, um \(p\)-valor menor ou igual a 0.05 é assumido como motivo para rejeitar a hipótese nula. Em diversos trabalhos como em Anderson & Goodman (1957),
os autores descrevem o teste aproximado amplamente utilizado com este objetivo.
Vamos começar com a suposição de que \(\{C_n\}\) seja uma sequência observada de uma Cadeia de Markov de primeira ordem \((k=1)\) e calculamos o
\(p\)-valor de uma estatística de segunda ordem usando a distribuição \(\chi^2\). A distribuição nula é
\begin{equation*}
P(C_{n+1}=x|C_{n}=y,C_{n-1}=z) = P(C_{n+1}=x|C_{n}=y)
\end{equation*}
ou pela fórmula de Bayes
\begin{equation*}
P(C_{n+1}=x,C_{n}=y,C_{n-1}=z) = \dfrac{P(C_{n+1}=x,C_{n}=y)P(C_{n}=y,C_{n-1}=z)}{P(C_n=y)}\cdot
\end{equation*}
A expressão a esquerda acima multiplicada por \(N-2\), sendo \(N\) a quantidade de observações na série temporal observada, é o número
esperado de vezes que a sequência \((C_{n+1} = x, C_n = y, C_{n-1} = z)\) aparece nos dados, dada a hipótese nula. As quantidades no lado direito não são
valores esperados. Eles são retirados da sequência observada.
Seja \(E_\omega\) a contagem esperada de sequências onde \(\sum_\omega E_\omega = N-2\) e \(\omega\) indexa o conjunto de todas as sequências para as quais a contagem
esperada é maior do que zero. Do mesmo modo, seja \(O_\omega\geq 0\) a contagem correspondente dos dados observados.
Agora podemos definir a estatística de teste \(\chi^2\) observada como
\begin{equation*}
\chi^2_{obs}=\sum_{\omega} \dfrac{\big(E_\omega-O_\omega\big)^2}{E_\omega},
\end{equation*}
a qual é uma medida do desvio da contagem observada do esperado. A vantagem da estatística \(\chi^2\) é que, atendendo aos graus de liberdade \(m\), a
distribuição da estatística é conhecida no limite \(N\to\infty\). O \(p\)-valor é então obtido como \(P(\chi^2(m)\geq \chi^2_{obs})\).
Um problema que exige alguma discussão é como calcular os graus de liberdade necessários para determinar a distribuição \(\chi^2(m)\). Para testar
a hipótese da \(k\)-ésima ordem, contamos as sequências de comprimento \(m=k+1\) observadas e calculamos as sequências de comprimento \(m+1\) esperadas.
Supondo que todas as \(d^m\) sequências de comprimento \(m\) estejam presentes nos dados, seja \(\mathcal{F}\) a matriz \(d^m\times d^m\) das contagens de transição.
O \((i,j)\)-ésimo elemento de \(\mathcal{F}\) é o número de vezes que as transições de \(i\) para \(j\) acontecem. Como as sequências consecutivas
se sobrepõem e diferem por apenas um símbolo, existem no m´ximo \(d\) entradas não-zero em cada linha e coluna de \(\mathcal{F}\).
É útil reorganizar \(\mathcal{F}\) na forma bloco diagonal com \(m\) blocos \(d\times d\). Em cada bloco tanto as linhas como as colunas devem somar o comprimento
correspondente às \(m\) contagens de sequências. Levando em consideração as dependências entre linhas e colunas nos deixa com \(d^{m-1}(d-1)^2\) graus
de liberdade para \(m>0\) e \((d-1)^2\) para \(m=0\). No caso de que nem todas as sequências de comprimento \(m\) estejam presentes nos dados observados, \(\mathcal{F}\) será
menor do que \(d^m\times d^m\) e os blocos ao longo da diagonal podem ser de tamanho diferente. Se o tamanho do \(i\)-ésimo bloco for \(r_i\times c_i\), então o número
total de graus de liberdade é \(\sum_i (r_i-1)(c_i-1)\).
No caso especial onde \(m=1\), a hipótese nula do teste é que as observações em pontos de tempo sucessivos são estatísticamente independentes
contra a hipótese alternativa de que as observações formam uma cadeia de primeira ordem.
Exemplo. Tendência de mercado financeiro (continuação)
Para a aplicação da estratégia (1), cada dia foi classificado como tendo fechado maior ou menor que o dia anterior, assim permitindo a classificação
de dois estados, a saber:
Estado 1: O valor de fechamento é inferior ao valor de fechamento do dia anterior.
Estado 2: O valor de fechamento é maior ou igual ao valor de fechamento do dia anterior.
Com as linhas de comando R seguintes fizemos a leitura dos dados, geramos o gráfico e construímos a cadeia:
> dados=read.csv('DJIA.csv',sep=',',h=T)
> attach(dados)
> library(ggplot2); library(psych); library(car)
> Datas = as.Date(dados$Date)
> par(mar=c(5,4,1,1),pch=19,cex.axis=0.4)
> qplot(Datas, Close, xlab=' ', ylab='Dow Jones Industrial Average em USD')
> Estados = seq(1, length(Close)-1)
> for(i in 1:length(Estados)){Estados[i] = ifelse(Close[i]>Close[i+1], 1, 2)}
Como resposta a matriz de probabilidades de transição estimada é
\begin{equation*}
\widehat{\Gamma}=\begin{pmatrix} 0.4722222 & 0.5277778 \\ 0.4014085 & 0.5985915\end{pmatrix},
\end{equation*}
isto obtido da seguinte lista de comandos R:
> library(markovchain)
> createSequenceMatrix(Estados, sanitize=FALSE)
> mcFitMLE = markovchainFit(data=Estados)
> mcFitMLE$estimate^100
MLE Fit^100
A 2 - dimensional discrete Markov Chain defined by the following states:
1, 2
The transition matrix (by rows) is defined as follows:
1 2
1 0.432 0.568
2 0.432 0.568
Ainda temos também que a distribuição estacionária é \(\pi=(0.432,0.568)\). Significa que temos 43%
de probabilidade de perda na nossa carteira de ações com o índice DJAI e 57% de probabilidade de ganho. Aplicamos
agora os conhecimentos desenvolvidos nesta seção para verificar a ordem da Cadeia de Markov.
Para isso devemos verificar se a cadeia em questão é de ordem um ou não e, como vimos, podemos utilizar a estatística
de teste \(\chi^2\). Para isto, ou seja, para aplicarmos o teste aproximado descrito nesta subseção fazemos:
> assessOrder(Estados)
The assessOrder test statistic is: 3.964894
the Chi-Square d.f. are: 2
The p-value is: 0.1377318
com o qual concluímos que aceitamos a hipóteses nula da cadeia com dois estados ser de ordem um.