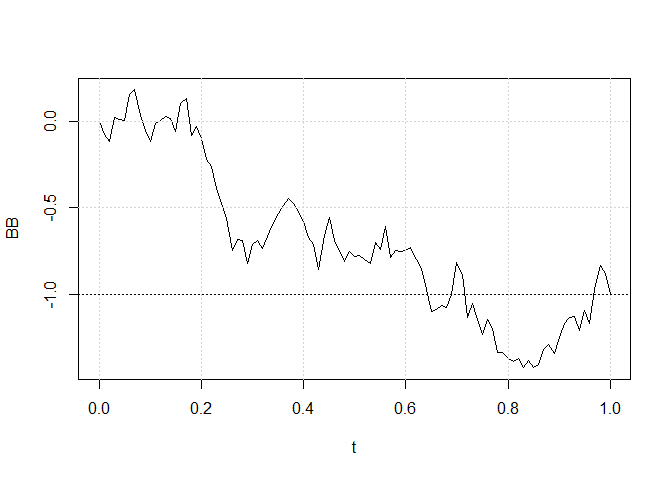I. Processos estocásticos e equações diferenciais estocásticas
Última atualização: 13 de setembro de 2021.
Este capítulo revisa o material básico sobre processos estocásticos e estatísticas, bem como cálculo estocástico, principalmente
emprestado de Øksendal, B. (1998), Karatzas, I. & Shrevre, S.E. (1988) e Revouz, D. & Yor, M. (1991). Ele também cobre noções básicas
sobre simulação de processos estocásticos comumente usados, como passeios aleatórios e movimento browniano e também lembra alguns conceitos
de Monte Carlo. Mesmo que se presuma que o leitor esteja familiarizado com essas noções básicas, iremos apresentá-las aqui a fim de introduzir a
notação que usaremos ao longo do texto. Limitaremos nossa atenção principalmente às variáveis aleatórias reais e unidimensionais
e aos processos estocásticos. Também restringimos nossa atenção a modelos paramétricos com parâmetros multidimensionais.
I.1 Elementos de probabilidade e variáveis aleatórias
Um espaço de probabilidade é um triplo \((\Omega,\mathcal{A},P)\) onde \(\Omega\) é o espaço amostral de resultados possíveis de um experimento aleatório;
\(\mathcal{A}\) é uma \(\sigma\)-álgebra: isto é, \(\mathcal{A}\) é uma coleção de conjuntos tais que:
o conjunto vazio \(\emptyset\) está em \(\mathcal{A}\);
se \(A\in\mathcal{A}\), então o conjunto complementar \(A^c\in\mathcal{A}\);
se \(A_1, A_2,\cdots\in\mathcal{A}\), então
\begin{equation*}
\bigcup_{i=1}^\infty A_i\in\mathcal{A}\cdot
\end{equation*}
\(P\) é uma medida de probabilidade em \((\Omega,\mathcal{A})\). Na prática, \(\mathcal{A}\) forma a coleção de eventos para os quais uma probabilidade pode
ser atribuída. Dado um espaço de probabilidade \((\Omega,\mathcal{A}, P)\), uma variável aleatória \(X\) é definida como uma função
mensurável de \(\Omega\) a \(\mathbb{R}\),
\begin{equation*}
X \, : \, \Omega\to\mathbb{R}\cdot
\end{equation*}
Acima, o termo mensurável intuitivamente significa que sempre é possível calcular probabilidades relacionadas à variável aleatória \(X\).
Mais precisamente, denotando por \(\mathcal{B}(\mathbb{R})\) a \(\sigma\)-álgebra de Borel em \(\mathbb{R}\), ou seja, a \(\sigma\)-álgebra gerada por conjuntos
abertos de \(\mathbb{R}\) e seja \(X^{−1}\) a função inversa de \(X\). Então, \(X\) é mensurável se
\begin{equation*}
\forall A\in\mathcal{B}(\mathbb{R}), \quad B\in \exists B\in\mathcal{A} \, : \, X^{-1}(A)=B;
\end{equation*}
ou seja, de modo que seja sempre possível medir o conjunto de valores assumidos por \(X\) usando a medida de probabilidade \(P\) no espaço original \(\Omega\),
\begin{equation*}
P(X\in A) \, = \, P(\{\omega\in\Omega:X(\omega)\in A\}) \, = \, P(\{\omega\in\Omega:\omega\in X^{-1}(A)\}) \, = \, P(B),
\end{equation*}
para \(A\in\mathcal{B}(\mathbb{R})\) e \(B\in\mathcal{A}\).
Função de distribuição e de densidade
A função \(F(x) = P(X\leq x) = P(X(\omega)\in (−\infty, x])\) é chamada de função de distribuição cumulativa:
é uma função não decrescente tal que \(\lim_{x\to-\infty} F(x) = 0\), \(\lim_{x\to\infty} F(x) = 1\) e \(F\) é contínua à
direita. Se \(F\) for absolutamente contínua, sua derivada \(f(x)\) é chamada de função de densidade, que é uma função não
negativa integrável de Lebesgue cuja integral sobre a reta real é igual a um.
Falando livremente, se \(F(x)\) é a probabilidade de que a variável aleatória \(X\) assume valores menores ou iguais a \(x\), a quantidade \(f(x)\mbox{d}x\) pode ser considerada
como a probabilidade de que a variável aleatória assume valores no intervalo infinitesimal \([x, x+\mbox{d}x)\).
Se a variável aleatória leva apenas um conjunto de valores enumeráveis, então ela é considerada discreta e sua densidade no ponto \(x\) é definida
como \(P(X = x)\). No caso contínuo, \(P(X = x) = 0\) sempre.
Independência
Duas variáveis aleatórias \(X\) e \(Y\) são independentes se
\begin{equation*}
P(X\in A, Y\in B) \, = \, P(X\in A) P(Y\in B)
\end{equation*}
para quaisquer dois conjuntos \(A\) e \(B\) em \(\mathbb{R}\).
I.1.1 Esperança, variância e momentos
A esperança ou valor esperado de uma variável aleatória contínua \(X\) com função de distribuição \(F\) é
definida como
\begin{equation*}
\mbox{E}(X) \, = \, \int_\Omega X(\omega)\mbox{d}P(\omega) \, = \, \int_\mathbb{R} x\mbox{d}F(x)
\end{equation*}
desde que a integral seja finita. Se \(X\) tiver uma densidade, então \(\mbox{E}(X) =\int_\mathbb{R} xf(x)\mbox{d}x\) e a integral é a integral de Riemann
padrão; caso contrário, integrais em \(\mbox{d}P\) ou \(\mbox{d}F\) devem ser pensadas como integrais no sentido abstrato.
Se \(\Omega\) for enumerável, o valor esperado é definido como
\begin{equation*}
\mbox{E}(X) \, = \, \sum_{\omega\in\Omega} X(\omega)P(\omega)
\end{equation*}
ou, equivalentemente, quando \(X\) é uma variável aleatória discreta, o valor esperado reduz para \(\mbox{E}(X) = \sum_{x\in\mbox{I}} x P(X=x)\),
onde \(\mbox{I}\) é o conjunto de valores possíveis de \(X\).
A variância é definida como
\begin{equation*}
\mbox{Var}(X) \, = \, \mbox{E}\big(X-\mbox{E}(X)\big)^2 \, = \, \int_\Omega \big(X(\omega)-\mbox{E}(X)\big)^2\mbox{d}P(\omega),
\end{equation*}
e o \(k\)-ésimo momento é definido como
\begin{equation*}
\mbox{E}(X^k) \, = \, \int_\Omega X^k(\omega)\mbox{d}P(\omega)\cdot
\end{equation*}
Em geral, para qualquer função \(g(\cdot)\) mensurável, \(\mbox{E}\big(g(X)\big)\) é definida como
\begin{equation*}
\mbox{E}\big(g(X)\big) \, = \, \int_\Omega g\big(X(\omega)\big)\mbox{d}P(\omega),
\end{equation*}
desde que a integral seja finita.
Tipos de convergência estocástica
Seja \(\{F_n\}_{n\in\mathbb{N}}\) uma sequência de funções de distribuição para a sequência de variáveis
aleatórias \(\{X_n\}_{n\in\mathbb{N}}\). Assuma que
\begin{equation*}
\lim_{n\to\infty} F_n(x) \, = \, F(x)
\end{equation*}
para todo \(x\in\mathbb{R}\) tal que \(F(\cdot)\) é contínua em \(x\), onde \(F\) é a função de distribuição
de alguma variável aleatória \(X\). Então, diz-se que a sequência \(X_n\) converge em distribuição para a variável
aleatória \(X\), e isso é denotado por \(X_n\overset{D}{\rightarrow} X\).
Convergência em distribuição significa apenas que as distribuições \(F_n\) das variáveis aleatórias convergem
para outra distribuição \(F\), mas nada é dito sobre as próprias variáveis aleatórias. Portanto, essa convergência
é apenas sobre o comportamento probabilístico das variáveis aleatórias em alguns intervalos \((−\infty,x]\), \(x\in\mathbb{R}\).
Diz-se que uma sequência de variáveis aleatórias \(X_n\) converge em probabilidade para uma variável aleatória \(X\) se, para
qualquer \(\epsilon > 0\),
\begin{equation*}
\lim_{n\to\infty} P\big( |X_n-X|\geq \epsilon\big) \, = \, 0\cdot
\end{equation*}
Denota-se por \(X_n \overset{P}{\rightarrow} X\) e é uma convergência pontual das probabilidades. Essa convergência implica a convergência em
distribuição. Às vezes usamos a notação
\begin{equation*}
p - \lim_{n\to\infty} |X_n - X | \, = \, 0
\end{equation*}
para a convergência em probabilidade.
Um tipo mais forte de convergência é definido como a probabilidade do limite no sentido \(P(\lim_{n\to\infty} X_n = X) = 1\) ou, mais precisamente,
\begin{equation*}
P\left( \{\omega\in\Omega \, : \, \lim_{n\to\infty} X_n(\omega) = X(\omega)\}\right) = 1\cdot
\end{equation*}
Quando isso acontece, diz-se que \(X_n\) converge para \(X\) quase com certeza e é denotado por \(X_n \overset{q.c.}{\rightarrow} X\). Convergência quase certa
implica convergência em probabilidade.
Uma sequência de variáveis aleatórias \(X_n\) é dita convergir na \(r\)-ésima média para uma variável aleatória \(X\)
se
\begin{equation*}
\lim_{n\to\infty} \mbox{E}\left( |X_n-X|^r \right) \, = \, 0, \qquad r\geq 1\cdot
\end{equation*}
A convergência na \(r\)-ésima média implica a convergência em probabilidade graças à desigualdade de Chebyshev e se \(X_n\)
converge para \(X\) na \(r\)-ésima média, então também converge na \(s\)-ésima média para todos \(r> s\geq 1\). A convergência
quadratica média é a caso particular de interesse e corresponde ao caso \(r = 2\). Este tipo de convergência será usado na Seção I.9
para definir a integral Itô.
I.1.2 Mudança de medida e derivada Radon-Nikodým
Em algumas situações, por exemplo em matemática financeira, é necessário reatribuir as probabilidades aos eventos em \(\Omega\), mudando de uma
medida \(P\) para outra \(\widetilde{P}\). Isso é feito com a ajuda de uma variável aleatória, digamos \(Z\), que reponderá aos elementos em \(\Omega\).
Esta mudança de medida deve ser feita conjunto a conjunto em vez de \(\omega\) a \(\omega\) como
\begin{equation*}
\widetilde{P}(A)=\int_A Z(\omega)\mbox{d}P(\omega),
\end{equation*}
onde \(Z\) é assumida como quase certamente não negativa e tal que \(\mbox{E}(Z) = 1\). O novo \(\widetilde{P}\) é então uma medida de probabilidade
verdadeira e, para qualquer variável aleatória não negativa \(X\), a igualdade
\begin{equation*}
\widetilde{\mbox{E}}(X)=\mbox{E}(XZ),
\end{equation*}
é válida, onde
\begin{equation*}
\widetilde{\mbox{E}}(X) \, = \, \int_\Omega X(\omega)\mbox{d}\widetilde{P}(\omega)\cdot
\end{equation*}
Duas medidas \(P\) e \(\widetilde{P}\) de proabilidade são consideradas equivalentes se atribuírem probabilidade 0 aos mesmos conjuntos. A mudança anterior da
medida de \(P\) para \(\widetilde{P}\) garante trivialmente que as duas medidas são equivalentes quando \(Z\) é estritamente positivo.
Outra maneira de ler a mudança de medida é dizer que \(Z\) é a derivada Radon-Nikodým de \(\widetilde{P}\) em relação a \(P\). De fato,
uma diferenciação formal nos permite escrever
\begin{equation*}
Z \, = \, \dfrac{\mbox{d}\widetilde{P}}{\mbox{d}P}\cdot
\end{equation*}
Teorema I.1.
Sejam \(P\) e \(\widetilde{P}\) duas medidas de probabilidade equivalentes em \((\Omega,\mathcal{A})\). Então, existe uma variável aleatória \(Z\),
quase certamente positiva, tal que \(\mbox{E}(Z) = 1\) e
\begin{equation*}
\widetilde{P}(A) \, = \, \int_A Z(\omega)\mbox{d}P(\omega),
\end{equation*}
para todo \(A\in\mathcal{A}\).
Demonstração.
Ver Shreve, S.E. (2004).
▉
A derivada Radon-Nikodým é um requisito essencial em estatística porque \(Z\) desempenha o papel da razão de verossimilhança na
inferência para processos de difusão.
I.2 Gerador de números aleatórios
Cada livro sobre simulação chama a atenção do leitor para a qualidade dos geradores de números aleatórios. Este é,
obviamente, um ponto central nos estudos de simulação. Os desenvolvedores e usuários de R são, na verdade, bastante cuidadosos nas
implementações e no uso de geradores de números aleatórios. Não entraremos em detalhes, apenas alertamos o leitor sobre as
possibilidades disponíveis no R e o que é utilizado nos exemplos deste livro.
O gerador de números aleatórios pode ser especificado no R por meio da função RNGkind. O gerador padrão de números
pseudo-aleatórios uniformes é o Mersenne-Twister e é aquele usado ao longo do livro. Outros métodos disponíveis no momento da
redação deste artigo são Wichmann-Hill, Marsaglia-Multicarry, Super-Duper e duas versões de geradores de números aleatórios
Knuth-TAOCP. O usuário também pode implementar e fornecer seu próprio método. Especificamente, para os geradores de números
aleatórios normais, os métodos disponíveis são Kinderman-Ramage, Buggy Kinderman-Ramage, Ahrens-Dieter, Box-Muller e o método
padrão de Inversão, conforme explicado em Wichura, M.J. (1988). Também neste caso, o usuário pode fornecer seu próprio algoritmo.
Para outras variáveis diferentes da normal, R implementa geradores de números pseudo-aleatórios bastante avançados. Para cada um deles,
o leitor deve olhar a página de manual das funções correspondentes, por exemplo, rgamma, rt, rbeta,
etc.
Para reprodutibilidade de todos os resultados numéricos no livro, escolhemos usar uma semente de inicialização fixa antes de qualquer listagem de código R.
Usamos em todos os lugares a função set.seed(123) e o leitor deve fazer o mesmo se quiser obter os mesmos resultados.
I.3 O método Monte Carlo
Suponha que recebamos uma variável aleatória \(X\) e estejamos interessados na avaliação de \(\mbox{E}\big(g(X)\big)\) onde \(g(\cdot)\)
é alguma função conhecida. Se formos capazes de obter \(n\) números pseudo-aleatórios \(x_1,\cdots, x_n\) da distribuição
de \(X\), então podemos pensar em aproximar \(\mbox{E}\big(g(X)\big)\) com a média da amostra de \(g(x_i)\),
\begin{equation*}
\mbox{E}\big(g(X)\big) \, \approx \, \dfrac{1}{n}\sum_{i=1}^n g(x_i) \, = \, \overline{g}_n\cdot
\end{equation*}
A expressão acima não é apenas simbólica, mas é verdadeira no sentido da Lei dos Grandes Números sempre que \(\mbox{E}\big(g(X)\big)<\infty\).
Além disso, o Teorema do Limite Central garante que
\begin{equation*}
\overline{g}_n \sim N\Big( \mbox{E}\big(g(X)\big), \dfrac{1}{n}\sum_{i=1}^n \mbox{Var}\big(g(x_i)\big)\Big),
\end{equation*}
onde \(N(\mu,\sigma^2)\) denota a distribuição Gaussiana com esperança \(\mu\) e variância \(\sigma^2\).
No final, o número que estimamos com simulações terá um desvio em relação ao verdadeiro valor esperado \(\mbox{E}\big(g(X)\big)\)
de ordem \(1/\sqrt{n}\). Dado que \(P(|Z| <1.96)\approx 0.95\), sendo \(Z\sim N(0,1)\), pode-se construir um intervalo para a estimativa \(\overline{g}_n\) da forma
\begin{equation*}
\Big( \mbox{E}\big(g(X)\big)-1.96\dfrac{\sigma}{\sqrt{n}};\mbox{E}\big(g(X)\big)+1.96\dfrac{\sigma}{\sqrt{n}}\Big),
\end{equation*}
com \(\sigma=\sqrt{\mbox{Var}\big(g(X)\big)}\), que é interpretado como que a estimativa de Monte Carlo de \(\mbox{E}\big(g(X)\big)\) acima estute; incluída no intervalo
acima 95% do tempo. A confiança o intervalo depende de \(\mbox{Var}\big(g(X)\big)\) e geralmente essa quantidade também deve ser estimada por meio da amostra. Na
verdade, pode-se estimar como a variância da amostra de replicações de Monte Carlo como
\begin{equation*}
\widehat{\sigma}^2 \, = \, \dfrac{1}{n-1}\sum_{i=1}^n \big( g(x_i)-\overline{g}_n\big)^2
\end{equation*}
e use o seguinte intervalo de confiança de Monte Carlo de nível de 95% para \(\mbox{E}\big(g(X)\big)\):
\begin{equation*}
\Big( \overline{g}_n-1.96\dfrac{\widehat{\sigma}}{\sqrt{n}};\overline{g}_n+1.96\dfrac{\widehat{\sigma}}{\sqrt{n}}\Big)\cdot
\end{equation*}
A quantidade \(\widehat{\sigma}/\sqrt{n}\) é chamada de erro padrão. O próprio erro padrão é uma quantidade aleatória e, portanto, sujeito
à variabilidade; portanto, deve-se interpretar esse valor como uma medida qualitativa de precisão.
Mais uma observação é que a taxa de convergência \(\sqrt{n}\) não é particularmente rápida, mas pelo
menos é independente da suavidade de \(g(\cdot)\). Além disso, se precisarmos aumentar a qualidade de nossa aproxima¸ão, precisamos
apenas desenhar amostras adicionais em vez de executar novamente toda a simulação. Uma nota de advertência: é claro que se deve cuidar
da semente do gerador de números aleatórios para evitar amostras duplicadas. Se já executamos \(n\) replicações e queremos
adicionar \(n'\) novas amostras, não podemos simplesmente reexecutar o algoritmo para um comprimento de \(n'\) com a mesma semente original porque, neste
caso, estamos apenas replicando as primeiras \(n'\) amostras entre as \(n\) originais, portanto, induzindo viés sem aumentar a precisão.
Sobre o comprimento dos intervalos de Monte Carlo
Em alguns casos, os intervalos Monte Carlo não são muito informativos se a variância de \(Y = g(X)\) for muito grande. O próximo exemplo
é um desses casos. Seja
\begin{equation*}
Y = g(X) = e^{\beta X},
\end{equation*}
com \(X\sim N(0,1)\) e suponha que estamos interessados em \(\mbox{E}\big(g(X)\big)\) com \(\beta= 5\). O valor analítico pode ser calculado como
\(e^{\beta^2/2} = 268337.3\) e o desvio padrão verdadeiro \(\sigma = \sqrt{e^{2\beta^2} - e^{\beta^2}} = 72004899337\), um número bastante grande
em relação à média de \(Y\).
Suponha que queremos estimar \(\mbox{E}\big(g(X)\big)\) por meio do método de Monte Carlo usando 100.000 replicações e construir intervalos
de confiança de 95% usando o verdadeiro desvio padrão e o erro padrão estimado.
O seguinte código R faz o trabalho.
> # ex1 .01. R
> set.seed(123)
> n <- 1000000
> beta <-5
> x <- rnorm(n)
> y <- exp(beta*x)
> # true value of E(Y)
> exp(beta^2/2)
[1] 268337.3
> # MC estimation of E(Y)
> mc.mean <- mean(y)
> mc.mean
[1] 199659.2
> mc.sd <- sd(y)
> true.sd <- sqrt( exp(2*beta^2) - exp(beta^2))
> # MC conf . interval based on true sigma
> mc.mean - true.sd*1.96/sqrt(n)
[1] -140929943
> mc.mean + true.sd*1.96/sqrt(n)
[1] 141329262
> # MC conf.interval based on estimated sigma
> mc.mean - mc.sd* 1.96/sqrt(n)
[1] 94515.51
> mc.mean + mc.sd* 1.96/sqrt(n)
[1] 304802.9
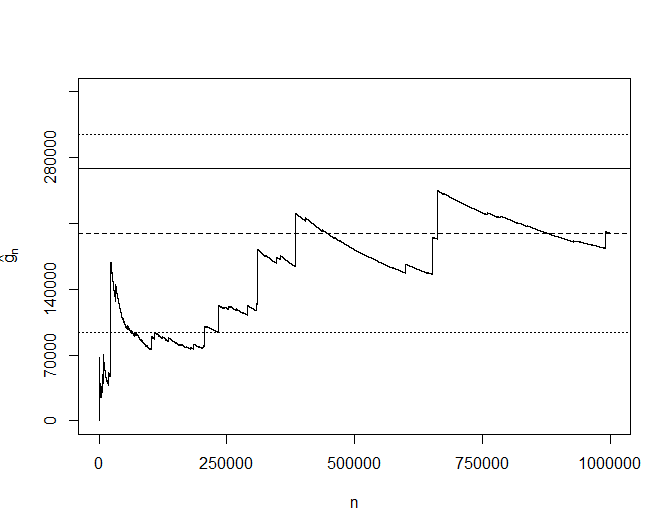
> plot(1:n, cumsum(y)/(1:n), type ="l",axes =F, xlab ="n",
+ ylab = expression(hat(g)[n]), ylim =c (0 ,350000))
> axis(1, seq(0,n, length =5))
> axis(2, seq(0,350000 , length =6))
> abline(h =268337.3) # verdadeiro valor
> abline(h=mc.mean -mc.sd*1.96/sqrt(n), lty =3) # intervalo Monte Carlo
> abline(h=mc.mean +mc.sd*1.96/sqrt(n), lty =3)
> abline(h=mc.mean, lty =2) # estimativa Monte Carlo
> box()
Figura I.1: A convergência muito lenta da estimativa de Monte Carlo associada a um valor verdadeiro alvo
com variabilidade muito alta (consulte a Seção I.3). A linha sólida é o valor alvo, as linhas pontilhadas são os
limites superior e inferior do intervalo de confiança Monte Carlo de 95% e a linha tracejada é o valor estimado \(\widehat{g}_n\).
I.4 Técnicas de redução de variância
O exemplo na última seção fornece evidências de que, para ter menos variabilidade nos métodos de Monte Carlo e, portanto, usar um número
menor de replicações nas simulações é necessário tentar reduzir a variabilidade com alguma solução alternativa.
Existem vários métodos de redução da variância para estimadores de Monte Carlo. Revisamos aqui apenas aqueles que podem ser aplicados em nosso contexto,
mas revisões interessantes sobre métodos para outras classes de problemas e processos podem ser encontradas, por exemplo, em Lapayre, B., Pardoux, É., Sentis,
R. (2003) e Jäckel, P. (2002).
Aqui, mostramos apenas as idéias básicas, enquanto as aplicações às equações diferenciais
estocásticas são postergadas para a Seção II.15. Não incluímos o tratamento de sequências com baixa discrepância porque isso
está além do escopo deste livro. Discrepância é uma medida de qualidade de ajuste para variáveis aleatórias uniformes em dimensões
altas. As sequências de baixa discrepância são tais que a integração numérica nesta grade de pontos permite uma redução direta
da variância. O leitor pode consultar o artigo de revisão L’Ecuyer, P. & Lemieux, C. (2002).
I.4.1 Amostragem preferencial
A ideia deste método é expressar \(\mbox{E}\big(g(X)\big)\) de uma forma diferente para reduzir sua variância. Seja \(f(\cdot)\) a densidade de \(X\); portanto
\begin{equation*}
\mbox{E}\big(g(X)\big) \, = \, \int_\mathbb{R} g(x)f(x)\mbox{d}x\cdot
\end{equation*}
Apresentamos agora outra densidade estritamente positiva \(h(\cdot)\). Então,
\begin{equation*}
\mbox{E}\big(g(X)\big) \, = \, \int_\mathbb{R} \dfrac{g(x)f(x)}{h(x)}h(x)\mbox{d}x
\end{equation*}
e
\begin{equation*}
\mbox{E}\big(g(X)\big) \, = \, \mbox{E}\left( \dfrac{g(Y)f(Y)}{h(Y)}\right) \, = \, \mbox{E}\big( \widetilde{g}(Y)\big),
\end{equation*}
com \(Y\) uma variável aleatória com densidade \(h(\cdot)\) e denotamos \(\widetilde{g}(\cdot) = g(\cdot)f(\cdot)/h(\cdot)\). Se formos capazes de determinar um
\(h(\cdot)\) tal que \(\mbox{Var}\big(\widetilde{g}(Y)\big) < \mbox{Var}\big(g(X)\big)\), então alcançamos nosso objetivo.
Mas vamos calcular \(\mbox{Var}\big(\widetilde{g}(Y)\big)\),
\begin{equation*}
\mbox{Var}\big(\widetilde{g}(Y)\big) \, = \, \mbox{E}\big(\widetilde{g}(Y)\big)^2-\mbox{E}^2\big(\widetilde{g}(Y)\big)
\, = \, \int_\mathbb{R} \dfrac{g^2(x)f^2(x)}{h(x)}\mbox{d}x - \mbox{E}^2\big(g(X)\big),
\end{equation*}
Se \(g(\cdot)\) for estritamente positivo, escolhendo \(h(x) = g(x)f(x)/\mbox{E}\big(g(X)\big)\), obtemos como resposta \(\mbox{Var}\big(\widetilde{g}(Y)\big) = 0\), o que é bom apenas
em teoria porque, é claro , não sabemos \(\mbox{E}\big(g(X)\big)\).
Mas a expressão de \(h(x)\) sugere uma maneira de obter uma aproximação útil: basta escolher \(\widetilde{h}(x) = |g(x)f(x) |\), ou algo próximo a isso,
normalize-o pelo valor de sua integral e use
\begin{equation*}
h(x) \, = \, \dfrac{\widetilde{h}(x)}{\displaystyle \int_\mathbb{R} \widetilde{h}(x)\mbox{d}x}\cdot
\end{equation*}
Claro que isso é simples de dizer e difícil de resolver em problemas específicos, já que a integração deve ser feita
analiticamente e não usando a teacute;cnica de Monte Carlo novamente. Além disso, a escolha de \(h(\cdot)\) muda de caso para caso. Mostramos um exemplo,
novamente retirado de Lapayre, B., Pardoux, É. & Sentis, R. (2003), que é bastante interessante e é uma aplicação padrão do
método em finanças.
Suponha que queremos calcular \(\mbox{E}\big(g(X)\big)\) com
\begin{equation*}
g(x) \, = \, \max(0, K−e^{\beta X}) \, = \, (K − e^{\beta X})_+,
\end{equation*}
sendo \(K\), \(\beta\) constantes e \(X\sim N(0,1)\).
Este é o preço de uma opção de venda na estrutura de Black, F. & Scholes, M.S. (1973), ver também Merton, R.C. (1973), e a solução
explícita, que é conhecida, é
\begin{equation*}
\mbox{E}\big(K-e^{\beta X}\big)_+ \, = \, K\Phi\left(\dfrac{\log(K)}{\beta}\right)-e^{\frac{1}{2}\beta^2}\Phi\left(\dfrac{\log(K)}{\beta}-\beta\right),
\end{equation*}
onde \(\Phi\) é a função de distribuição cumulativa da lei Gaussiana padrão; isto é, \(\Phi(x) = P(Z <z)\) com \(Z\sim N(0, 1)\).
O valor verdadeiro, no caso \(K = \beta= 1\), é \(\mbox{E}\big(g(X)\big) = 0.2384217\). Vamos ver o que acontece nas simulações de Monte Carlo.
> set.seed(123)
> n <- 10000
> beta <- 1
> K <- 1
> x <- rnorm(n)
> y <- sapply(x, function (x) max(0,K- exp(beta*x)))
> # verdadeiro valor
> K*pnorm(log(K)/beta)- exp(beta^2/2)*pnorm( log(K)/beta - beta )
[1] 0.2384217
> t.test(y[1:100]) # primeiras 100 simulações
One Sample t-test
data: y[1:100]
t = 7.701, df = 99, p-value = 1.043e-11
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
0.1526982 0.2586975
sample estimates:
mean of x
0.2056978
> t.test(y[1:1000]) # primeiras 1000 simulações
One Sample t-test
data: y[1:1000]
t = 24.877, df = 999, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
0.2131347 0.2496388
sample estimates:
mean of x
0.2313868
> t.test(y) # resultado com todas as simulações
One Sample t-test
data: y
t = 80.356, df = 9999, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
0.2326121 0.2442446
sample estimates:
mean of x
0.2384284
Os resultados das simulações são relatados na Tabela I.1 (a). Observe que no algoritmo usamos a função sapply em vez
da linha de código, aparentemente mais natural, mas errada
y <- max(0, K-exp(beta*x))
pois isso retornará apenas um valor, na verdade o valor máximo entre 0 e todos os \(y_i = K - e^{\beta x_i}\). Este é um lugar onde as funções
vetoriais precisam ser usadas na ordem correta. Observe também o uso de t.test, que realmente executa a estimação e a construção
dos intervalos de confenciais para \(Y = \mbox{E}\big(g(X)\big)\).
Tabela I.1. Avaliação do preço de uma opção de venda pelo método de Monte Carlo. O
valor verdadeiro é 0.2384217, com (b) e sem (a) aplicando a técnica de redução da variância da Seção I.4.1.
\(n\)
\(\widehat{g}_n\)
intervalo confidencial 95%
\(n\)
\(\widehat{g}_n\)
intervalo confidencial 95%
100
0.206
(0.153; 0.259)
100
0.234
(0.222; 0.245)
1000
0.231
(0.213; 0.250)
1000
0.236
(0.233; 0.240)
10000
0.238
(0.232; 0.244)
10000
0.238
(0.237; 0.239)
(a)
(b)
Agora tentamos reescrever \(\mbox{E}\big(g(X)\big)\) como \(\mbox{E}\big(g'(X)\big)\), onde \(g'\) é uma função diferente de \(g\), para reduzir sua
variância. Na verdade, \(\mbox{E}\big(g(X)\big)\) pode ser reescrita como
\begin{equation*}
\int_\mathbb{R} \dfrac{\big(1-e^{\beta x}\big)_+}{\beta |x|}\beta |x|\dfrac{e^{-\frac{1}{2}x^2}}{\sqrt{2\pi}}\mbox{d}x,
\end{equation*}
definindo \(K = 1\) e observando que \(e^x - 1 \approx x\) para \(x\) próximo de 0. Pela mudança da variável \(x = \sqrt{y}\) para \(x> 0\) e \(x = −\sqrt{y}\)
para \(x < 0\), a integral acima pode ser reescrita como
\begin{equation*}
\int_0^\infty \dfrac{\big(1-e^{\beta\sqrt{y}}\big)_++\big(1-e^{-\beta\sqrt{y}}\big)_+}{\sqrt{2\pi}\sqrt{y}}\dfrac{e^{-\frac{1}{2}y}}{2}\mbox{d}y,
\end{equation*}
a partir da qual observamos que \(f(y) =\lambda e^{−\lambda y}\), com \(\lambda=\frac{1}{2}\), é a densidade da distribuição Exponencial. Portanto
\begin{equation*}
\mbox{E}\big(g(X)\big) \, = \, \mbox{E}\left(\frac{\big(1-e^{\beta \sqrt{Y}}\big)_++\big(1-e^{-\beta\sqrt{Y}}\big)_+}{2\pi \sqrt{Y}} \right),
\end{equation*}
pode ser avaliada como o valor esperado de uma função da variável aleatória Exponencial \(Y\). O algoritmo a seguir executa o
cálculo e os resultados são relatados na Tabela I.1 (b), da qual a redução na variância é bastante evidente.
> set.seed(123)
> n <- 10000
> beta <- 1
> K <- 1
> x <- rexp(n, rate =0.5)
> h <- function(x) ( max(0,1-exp( beta*sqrt(x))) + max(0, 1-exp(-beta*sqrt(x))))/sqrt(2*pi*x)
> y <- sapply(x, h)
> # verdadeiro valor
> K*pnorm(log(K)/beta)- exp(beta^2/2)*pnorm(log(K)/beta - beta)
[1] 0.2384217
> t.test(y[1:100]) # primeiras 100 simulações
One Sample t-test
data: y[1:100]
t = 41.129, df = 99, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
0.2225011 0.2450578
sample estimates:
mean of x
0.2337795
> t.test(y[1:1000]) # primeiras 1000 simulações
One Sample t-test
data: y[1:1000]
t = 127.57, df = 999, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
0.2328097 0.2400837
sample estimates:
mean of x
0.2364467
> t.test(y) # rsultado com todas as simulações
One Sample t-test
data: y
t = 408.6, df = 9999, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
0.2369481 0.2392325
sample estimates:
mean of x
0.2380903
I.4.2 Variáveis de controle
O caso muito simples de redução de variância via variáveis de controle é o seguinte. Suponha que queremos calcular \(\mbox{E}\big(g(X)\big)\).
Se pudermos reescrevê-lo na forma
\begin{equation*}
\mbox{E}\big(g(X)\big) \, = \, \mbox{E}\big(g(X)-h(X)\big) + \mbox{E}\big(h(X)\big),
\end{equation*}
onde \(\mbox{E}\big(h(X)\big)\) pode ser calculado explicitamente e \(g(X) - h(X)\) tem variância menor que \(g(X)\); então estimando
\(\mbox{E}\big(g(X)-h(X)\big)\) através do método Monte Carlo, obtemos uma redução na variância.
Exemplo de paridade de chamada
Continuando com o exemplo da seção anterior, considere o preço de uma opção de chamada
\begin{equation*}
c(X) \, = \, \mbox{E}\big( e^{\beta X}-K\big)_+\cdot
\end{equation*}
Pode-se mostrar que \(c(X) - p(X) = e^{\frac{1}{2}\beta^2}- K\), onde \(p\) é o preço da opção.
Portanto, podemos escrever \(c(X) = p(X) + e^{\frac{1}{2}\beta^2}- K\). Também é conhecido, ver por exemplo, Lamberton, D. & Lapayre, B. (1991) que a variância de \(p(X)\)
é menor que a variância de \(c(X)\). Assim, obtivemos um estimador de \(c(X)\) com viés reduzido. A fórmula exata para \(c(X)\) também
é conhecida como sendo
\begin{equation*}
\mbox{E}\big( e^{\beta X}-K\big)_+ \, = \, e^{\frac{1}{2}\beta^2}\Phi\left(\beta-\dfrac{\log(K)}{\beta} \right) - K\Phi\left(-\dfrac{\log(K)}{\beta} \right)\cdot
\end{equation*}
O código R a seguir mostra isso empiricamente, e os resultados são relatados na Tabela I.2.
> set.seed(123)
> n <- 10000
> beta <- 1
> K <- 1
> x <- rnorm(n)
> y <- sapply(x, function (x) max(0, exp(beta*x)-K))
> # verdadeiro valor
> exp(beta^2/2)*pnorm(beta - log(K)/beta)-K*pnorm(-log(K)/beta)
[1] 0.887143
> t.test(y[1:100]) # primeiras 100 simulações
One Sample t-test
data: y[1:100]
t = 5.3876, df = 99, p-value = 4.833e-07
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
0.5421608 1.1743259
sample estimates:
mean of x
0.8582433
> t.test(y[1:1000]) # primeiras 1000 simulações
One Sample t-test
data: y[1:1000]
t = 14.375, df = 999, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
0.7797965 1.0263504
sample estimates:
mean of x
0.9030735
> t.test(y) # resultado com todas as simulações
One Sample t-test
data: y
t = 42.918, df = 9999, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
0.8443946 0.9252193
sample estimates:
mean of x
0.884807
> set.seed(123)
> x <- rexp(n, rate = 0.5)
> h <- function(x)( max(0, 1 - exp(beta*sqrt(x))) + max(0, 1-exp(-beta*sqrt(x))))/sqrt(2*pi*x)
> y <- sapply(x, h)
> # redução da variância
> z <- y + exp(0.5*beta^2) - K
> t.test(z[1:100]) # primeiras 100 simulações
One Sample t-test
data: z[1:100]
t = 155.26, df = 99, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
0.8712224 0.8937790
sample estimates:
mean of x
0.8825007
> t.test(z[1:1000]) # primeiras 1000 simulações
One Sample t-test
data: z[1:1000]
t = 477.59, df = 999, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
0.8815309 0.8888050
sample estimates:
mean of x
0.885168
> t.test(z) # resultado com todas as simulações
One Sample t-test
data: z
t = 1521.9, df = 9999, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
0.8856693 0.8879537
sample estimates:
mean of x
0.8868115
Tabela I.2. Avaliação do preço de uma opção de venda pelo método de Monte Carlo. O
valor verdadeiro é 0.887143, com (b) e sem (a) aplicando a técnica de redução da variância desta seção.
\(n\)
\(\widehat{g}_n\)
intervalo confidencial 95%
\(n\)
\(\widehat{g}_n\)
intervalo confidencial 95%
100
0.858
(0.542; 1.174)
100
0.882
(0.871; 0.894)
1000
0.903
(0.780; 1.026)
1000
0.885
(0.881; 0.889)
10000
0.885
(0.844; 0.925)
10000
0.887
(0.886; 0.888)
(a)
(b)
I.4.3 Amostragem antitética
A ideia de amostragem antitéica pode ser aplicada quando é possível encontrar transformações de \(X\) que deixam sua medida
inalterada, por exemplo, se \(X\) é Gaussiana, então \(-X\) é Gaussiana também. Suponha que queremos calcular
\begin{equation*}
\mbox{I} \, = \, \int_0^1 g(x)\mbox{d}x \, = \, \mbox{E}\big(g(X)\big),
\end{equation*}
com \(X\sim U(0,1)\).
A transformação \(x\to 1-x\) deixa a medida inalterada, ou seja, \(1 - X\sim U(0,1)\) e \(\mbox{I}\) pode ser reescrita como
\begin{equation*}
\mbox{I} \, = \, \dfrac{1}{2}\int_0^1 \big(g(x)+g(1-x)\big)\mbox{d}x \, = \, \frac{1}{2}\mbox{E}\big(g(X)+g(1-X)\big) \, = \,
\frac{1}{2}\mbox{E}\big(g(X)+g(h(X)) \big)\cdot
\end{equation*}
Portanto, temos uma redução da variância se
\begin{equation*}
\mbox{Var}\left( \frac{1}{2}\big(g(X)+g(h(X)) \big)\right) \, < \, \mbox{Var}\left(\frac{1}{2}g(X) \right),
\end{equation*}
o que equivale a dizer que \(\mbox{Cov}\big(g(X), g(h(X))\big) < 0\).
>/p>
Se \(h(x)\) é uma função monotônica de \(x\), como no exemplo acima, esse é sempre o caso. Este procedimento
tem o efeito de reduzir a variância, mas também de aumentar a precisão do cálculo da média. No entanto, ele
não corrige a estimativa de momentos de ordem superior.
Voltando ao exemplo do cálculo do preço de uma opção de venda, deve-se calculá-lo usando \(X\) e \(−X\) e,
em seguida, calculando a média da seguinte forma:
> set.seed(123)
> n <- 10000
> beta <- 1
> K <- 1
> x <- rnorm(n)
> y1 <- sapply(x, function(x) max(0, K- exp(beta*x)))
> y2 <- sapply(-x, function(x) max(0, K- exp(beta*x)))
> y <- (y1+y2)/2
> # verdadeiro valor
> K*pnorm(log(K)/beta)- exp(beta^2/2)*pnorm(log(K)/beta - beta)
[1] 0.2384217
> t.test(y[1:100]) # primeiras 100 simulações
One Sample t-test
data: y[1:100]
t = 18.865, df = 99, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
0.2028654 0.2505560
sample estimates:
mean of x
0.2267107
> t.test(y[1:1000]) # primeiras 1000 simulações
One Sample t-test
data: y[1:1000]
t = 58.471, df = 999, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
0.2268490 0.2426043
sample estimates:
mean of x
0.2347266
> t.test(y) # resultado com todas as simulações
One Sample t-test
data: y
t = 189.62, df = 9999, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
0.2352945 0.2402100
sample estimates:
mean of x
0.2377523
Os resultados são relatados na Tabela I.3 abaixo. Observe que aplicamos esse método ao estimador de Monte Carlo ingênuo e não ao construído
na distribuição exponencial \(Y\), pois, nesse caso, \(−Y\) não têm mais distribuição exponencial.
Tabela I.3. Avaliação do preço de uma opção de venda pelo método de Monte Carlo. O
valor verdadeiro é 0.887143, com (b) e sem (a) aplicando a técnica de redução da variância da Seção I.4.2.
\(n\)
\(\widehat{g}_n\)
intervalo confidencial 95%
\(n\)
\(\widehat{g}_n\)
intervalo confidencial 95%
100
0.858
(0.542; 1.174)
100
0.882
(0.871; 0.894)
1000
0.903
(0.780; 1.026)
1000
0.885
(0.881; 0.889)
10000
0.885
(0.844; 0.925)
10000
0.887
(0.886; 0.888)
(a)
(b)
I.5 Generalidades de processos estocásticos
Seja \((\Omega,\mathcal{A},P)\) um espaço de probabilidade. Um processo estocástico de valor real é uma família de variáveis aleatórias
\(\{X_\gamma, \gamma\in\Gamma\}\) definidas em \(\Omega\times \Gamma\) assumindo valores em \(\mathbb{R}\). Assim, as variáveis aleatórias da família, mensuráveis
para cada \(\gamma\in\Gamma\), são funções da forma
\begin{equation*}
X(\gamma,\omega) \, : \, \Gamma\times \Omega \to \mathbb{R}\cdot
\end{equation*}
Para \(\Gamma = \mathbb{N}\), temos um processo de tempo discreto e para \(\Gamma\subset\mathbb{R}\) temos um processo de tempo contínuo. Estamos principalmente interessados
em processos de tempo contínuo com \(\Gamma = [0,\infty)\) e sempre pensamos em \([0,\infty)\) como o eixo do tempo. Denotaremos um processo estocástico de tempo contínuo
como \(X = \{X_t: t\geq 0\}\). Às vezes, para evitar múltiplos subscritos, também adotaremos a notação usual \(X(t)\) para denotar \(X_t\).
Para um valor fixo de \(\omega\), digamos \(\widetilde{\omega}\), \(\{X(t,\widetilde{\omega}): t\geq 0\}\), respectivamente \(\{X(n,\widetilde{\omega}):n\in\mathbb{N}\}\) para o caso discreto,
é chamado de caminho ou trajetória do processo e representa uma evolução possível do processo. Para um \(t\) fixo, digamos \(\widetilde{t}\), o conjunto de
valores \(\{X(\widetilde{t},\omega):\omega\in\Omega\}\), respectivamente \(\{X(\widetilde{n},\omega):\omega\in\Omega\}\), representa o conjunto de estados possíveis do processo no tempo
\(\widetilde{t}\), respectivamente \(n\).
I.5.1 Filtros
Considere o espaço de probabilidade \((\Omega,\mathcal{A},P)\). Um filtro \(\{\mathcal{F}_t: t\geq 0\}\) é uma família crescente de sub-\(\sigma\)-álgebras de \(\mathcal{A}\)
indexada por \(t\geq 0\); ou seja, para cada \(s, t\geq 0\) tais que \(s <t\), temos \(\mathcal{F}_s\subset\mathcal{F}_t\) com \(\mathcal{F}_0 = \{\Omega,\emptyset\}\). Para cada processo
\(\{X(t):t\geq 0\}\) e para cada \(t\), podemos associar uma \(\sigma\)-álgebra denotada por \(\mathcal{F}_t = \sigma\big(X(s): 0\leq s\leq t\big)\), que é a \(\sigma\)-álgebra
gerada pelo processo \(X\) até o tempo \(t\); ou seja, a menor \(\sigma\)-álgebra de \(\mathcal{A}\) que torna \(X(s,\omega)\) mensurável para cada \(0\leq s\leq t\). Esta \(\sigma\)-álgebra
é o menor conjunto de subconjuntos de \(\Omega\) que permite atribuir probabilidades a todos os eventos relacionados ao processo \(X\) até o tempo \(t\).
Dado um processo estocástico \(\{X_t: t\geq 0\}\) e um filtro \(\{\mathcal{F}_t: t\geq 0\}\), não necessariamente a gerado por \(X\), diz-se que o processo \(X\) está adaptado a
\(\{\mathcal{F}:t\geq 0\}\) se para cada \(t\geq 0\), \(X(t)\) é \(\mathcal{F}_t\)-mensurável ou mensurável por \(\mathcal{F}_t\).
I.5.2 Variação simples e quadrática de um processo
A noção de variação total ou variação de primeira ordem de um processo \(V(X)\) está ligada à diferenciabilidade de seus caminhos.
Seja \(\Pi_n = \Pi_n([0,t]) = \{0 = t_0 < \cdots < t_i < \cdots < t_n = t\}\) qualquer partição do intervalo \([0,t]\) em \(n\) intervalos e denotamos por
\begin{equation*}
||\Pi_n|| \, = \, \max_{j=0,\cdots,n-1} (t_{j+1}-t_j)
\end{equation*}
o tamanho máximo do passo da partição \(\Pi_n\), ou seja, a malha da partição. A variação de \(X\) é definida como
\begin{equation*}
V_t(X) \, = \, p=\lim_{||\Pi_n||\to 0} \sum_{k=0}^{n-1} \big| X(t_{k+1})-X(t_k)\big|\cdot
\end{equation*}
Se \(X\) é diferenciável, então \(V_t(X) = \displaystyle \int_0^t |X'(u)|\mbox{d}u\). Se \(V_t(X) <\infty\), então \(X\) é considerado de variação
limitada em \([0,t]\). Se isso for verdade para todo \(t\geq 0\), então \(X\) é considerado uma variação limitada.
A variação quadrática \([X,X]_t\) no tempo \(t\) de um processo \(X\) é definida como
\begin{equation*}
[X,X]_t \, = \, p-\lim_{||\Pi_n||\to 0} \sum_{k=0}^{n-1} \big| X(t_{k+1})-X(t_k)\big|^2\cdot
\end{equation*}
O limite existe para processos estocásticos com caminhos contínuos. Nesse caso, a notação \(<X,X>_t\) é geralmente adotada. A variação quadrática
também pode ser introduzida como
\begin{equation*}
<X,X>_t \, = \, p-\lim_{n\to\infty} \sum_{k=1}^{2^n} \big( X_{t∧ k/2^n}-X_{t∧ (k-1)/2^n}\big)^2,
\end{equation*}
onde \(a∧ b=\min(a,b)\).
A segunda definição será usada no Capítulo III. Se um processo \(X\) é diferenciável, então ele tem variação
quadrática igual a zero. Além disso, a variação total e quadrática estão relacionadas pela seguinte desigualdade
\begin{equation*}
\sum_{k=1}^{n-1} \big| X(t_{k+1})-X(t_k)\big| \, \geq \, \dfrac{\displaystyle \sum_{k=0}^{n-1} \big| X(t_{k+1})-X(t_k)\big|^2}
{\displaystyle \max_{\Pi_n}\big| X(t_{k+1})-X(t_k)\big|}\cdot
\end{equation*}
Portanto, se \(X\) é contínuo e tem variação quadrática finita, então sua variação total é necessariamente
infinita. Observe que \(V_t(X)\) e \([X,X]_t\) também são processos estocásticos.
I.5.3 Momentos, covariância e incrementos de processos estocásticos
O valor esperado e a variância de um processo estocástico são definidos como
\begin{equation*}
\mbox{E}(X_t) \, = \, \int_\Omega X(t,\omega)\mbox{d}P(\omega), \qquad t\in[0,T]
\end{equation*}
e
\begin{equation*}
\mbox{Var}(X_t) \, = \, \mbox{E}\big( X_t-\mbox{E}(X_t)\big)^2, \qquad t\in[0,T]\cdot
\end{equation*}
O \(k\)-ésimo momento de \(X_t\), \(k\geq 1\), é definido, para todo \(t\in [0,T]\), como \(\mbox{E}(X_t^k)\). Essas quantidades são bem definidas
quando as integrais correspondentes são finitas. A função de covariância do processo para dois valores de tempo \(s\) e \(t\) é definida
como
\begin{equation*}
\mbox{Cov}(X_s, X_t) \, = \, \mbox{E}\big( (X_s - \mbox{E}(X_s))(X_t - \mbox{E}(X_t))\big)\cdot
\end{equation*}
A quantidade \(X_t − X_s\) é chamada de incremento do processo de \(s\) para \(t\), \(s <t\).
Essas quantidades são úteis na descrição de processos estocásticos que geralmente são introduzidos para modelar a evolução
sujeita a alguns choques estocásticos. Existem diferentes maneiras de introduzir processos com base nas características que se deseja modelar. Algumas das
abordagens mais comumente usadas são a modelagem de incrementos e/ou a escolha da função de covariância.
I.5.4 Esperança condicional
A probabilidade condicional de \(A\) dado \(B\) é definida como \(P(A|B) = P(A\cap B)/P(B)\) para \(P(B)> 0\). Da mesma forma, é possível introduzir a
distribuição condicional de uma variável aleatória \(X\) em relação ao evento \(B\) como
\begin{equation*}
F_X(x|B) \, = \, \dfrac{P(X\leq x \cap B)}{P(B)}, \qquad x\in\mathbb{R},
\end{equation*}
e a esperança com relação a esta distribuição condicional é naturalmente introduzida como (ver Mikosch, T. (1998) para um
tratado semelhante)
\begin{equation*}
\mbox{E}(X|B) \, = \, \dfrac{\mbox{E}(X\pmb{1}_B)}{P(B)},
\end{equation*}
onde \(\pmb{1}_B\) é a função indicadora do conjunto \(B\), o que significa que \(\pmb{1}_B(\omega) = 1\) se
\(\omega\in B\) e 0 caso contrário. Para variáveis aleatórias discretas, a espetança condicional assume
a forma
\begin{equation*}
\mbox{E}(X|B) \, = \, \sum_i x_i \dfrac{P\big(\{\omega : X(\omega)=x_i\}\cap B\big)}{P(B)} \, = \, \sum_i x_i P(X=x_i |B)\cdot
\end{equation*}
Para variáveis aleatórias contínuas com densidade \(f_X\), temos
\begin{equation*}
\mbox{E}(X|B) \, = \, \dfrac{1}{P(B)}\int_\mathbb{R} x\pmb{1}_B(x)f_X(x)\mbox{d}x \, = \, \dfrac{1}{P(B)}\int_B x f_X(x)\mbox{d}x\cdot
\end{equation*}
Considere agora uma variável aleatória discreta \(Y\) que assume valores distintos nos conjuntos \(A_i\), ou seja, cada
\(A_i = A_i(\omega) = \{\omega : Y(\omega) = y_i\}\), \(i = 1, 2,\cdots\) e assuma que todos os \(P(A_i)\) são positivos.
Seja \(\mbox{E}\big(|X|\big) < \infty\). Então, uma nova variável aleatória \(Z\) pode ser definida como segue:
\begin{equation*}
Z(\omega) \, = \, \mbox{E}(X|Y)(\omega) \, = \, \mbox{E}\big(X|A_i(\omega)\big) \, = \, \mbox{E}\big(X|Y(\omega)=y_i\big), \qquad \omega\in A_i\cdot
\end{equation*}
Para cada fixo \(\omega\in A_i\) a esperança condicional \(\mbox{E}(X|Y)\) coincide com \(\mbox{E}(X|A_i)\) mas, como um todo, é uma variável
aleatória em si porque depende dos eventos gerados por \(Y\).
Se, em vez de um único elemento \(A_i\), considerarmos uma \(\sigma\)-álgebra completa de eventos, por exemplo, aquela gerada pela
variável aleatória genérica \(Y\), chegamos à definição geral de esperança condicional:
seja \(X\) uma variável aleatória tal que \(\mbox{E}\big(|X|\big) <\infty\).
Uma variável aleatória \(Z\) é chamada de esperança condicional de \(X\) em relação à \(\sigma\)-álgebra
\(\mathcal{F}\) se:
i) \(Z\) é \(\mathcal{F}\)-mensurável e
ii) \(Z\) é tal que \(\mbox{E}(Z\pmb{1}_A)=\mbox{E}(X\pmb{1}_A)\) para todo \(A\in\mathcal{F}\).
A esperança condicional é única e será denotada como \(Z = \mbox{E}(X|\mathcal{F})\). Com esta notação, a
equivalência acima pode ser escrita como
\begin{equation*}
\mbox{E}\big(\mbox{E}(X|\mathcal{F})\pmb{1}_A\big) \, = \, \mbox{E}(X\pmb{1}_A), \quad \mbox{ para todo } \quad A\in\mathcal{F}\cdot
\end{equation*}
Como observamos, a esperança condicional é uma variável aleatória e a igualdade acima é verdadeira até em conjuntos de
medida nula.
Entre as propriedades da esperança condicional, notamos apenas o seguinte. Sejam \(X, X_1, X_2\) variáveis aleatórias e \(\alpha, \beta\) duas constantes.
Então,
\begin{array}{rcl}
\mbox{E}\big(\alpha X_1+\beta X_2 |\mathcal{F}\big) \, = \, \alpha \mbox{E}(X_1|\mathcal{F})+\beta\,\mbox{E}(X_2|\mathcal{F}), \\
\mbox{E}(X|\mathcal{F}_0) \, = \, \mbox{E}(X),
\end{array}
se \(\mathcal{F}_0=\{\Omega,\emptyset\}\). Além disso, se \(Y\) for \(\mathcal{F}\)-mensurável, então
\begin{equation*}
\mbox{E}(Y\times X|\mathcal{F}) \, = \, Y\times\mbox{E}(X|\mathcal{F}),
\end{equation*}
e, scolhendo \(X=1\), segue que
\begin{equation*}
\mbox{E}(Y|\mathcal{F}) \, = \, Y\cdot
\end{equation*}
Se \(X\) é independente de \(\mathcal{F}\), segue-se que \(\mbox{E}(X|\mathcal{F})=\mbox{E}(X)\) e, em particular, se \(X\) e \(Y\)
forem independentes, temos \(\mbox{E}(X|Y) = \mbox{E}\big(X|\sigma(Y)\big) = \mbox{E}(X)\), onde \(\sigma(Y)\) é a \(\sigma\)-álgebra
gerada pela variável aleatória \(Y\).
I.5.5 Martingales
Dado um espaço de probabilidade \((\Omega,\mathcal{F},P)\) e um filtro \(\{\mathcal{F}_t : t\geq 0\}\) em \(\mathcal{F}\), um martingale
é um processo estocástico \(\{X_t : t\geq 0\}\) tal que \(\mbox{E}\big(|X_t|\big) <\infty\) para todo \(t\geq 0\), é adaptado ao
filtro \(\{\mathcal{F}_t : t\geq 0\}\) e, para cada, \(0\leq s\leq t < \infty\), é verdade que
\begin{equation*}
\mbox{E}(X_t | \mathcal{F}_s) = X_s,
\end{equation*}
ou seja, \(X_s\) é o melhor preditor de \(X_t\) dado \(\mathcal{F}_s\). Se na definição acima a igualdade = for substituída por
\(\geq\), o processo é denominado submartingale e se for substituído por \(\leq\), denominado supermartingale. Das propriedades do operador de
valor esperado, segue-se que, se \(X\) for um martingale, então
\begin{array}{rcl}
\mbox{E}(X_s) & = & \mbox{por definição de martingale} \, = \, \mbox{E}\big(\mbox{E}(X_t |\mathcal{F}_s)\big) \\
& = & \mbox{por } X_t \mbox{ ser } \mathcal{F}_t-\mbox{mensurável} \, = \, \mbox{E}(X_t),\\
\end{array}
o que significa que os martingales têm uma média constante para todo \(t\geq 0\).
I.6 Movimento Browniano
O ingrediente básico de um modelo que descreve a evolução estocástica é o chamado movimento Browniano ou processo de Wiener.
Este processo foi batizado em homenagem ao botânico Robert Brown. Em 1827, Brown descreveu o movimento caótico de um grão de pólen
suspenso na água e repetidamente atingido por moléculas de água, um movimento bem modelado com o movimento Browniano.
Louis Bachelier em 1900 e, independentemente, Albert Einstein, estudaram os detalhes do ponto de vista matemático. O movimento Browniano também é um processo
de Wiener, ou seja, um processo Gaussiano de tempo contínuo com incrementos independentes.
Existem várias formas alternativas de caracterizar e definir o processo de Wiener \(W = \{W(t) : t\geq 0\}\), e uma delas é a seguinte: é
um processo Gaussiano com caminhos contínuos e com incrementos independentes tais que \(W(0) = 0\) com probabilidade 1, \(\mbox{E}\big(W(t)\big) = 0\) e
\(\mbox{Var}\big(W(t) − W(s)\big) = t - s\) para todo \(0\leq s\leq t\). Na prática, o que é relevante para nossos propósitos é que
\(W(t) - W(s)\sim N(0, t - s)\), para \(0\leq s\leq t\) e que em quaisquer dois intervalos disjuntos, digamos \((t_1, t_2)\) , \((t_3, t_4)\) com \(t_1\leq t_2\leq t_3\leq t_4\),
os incrementos \(W(t_2) −W(t_1)\) e \(W(t_4) −W(t_3)\) são independentes.
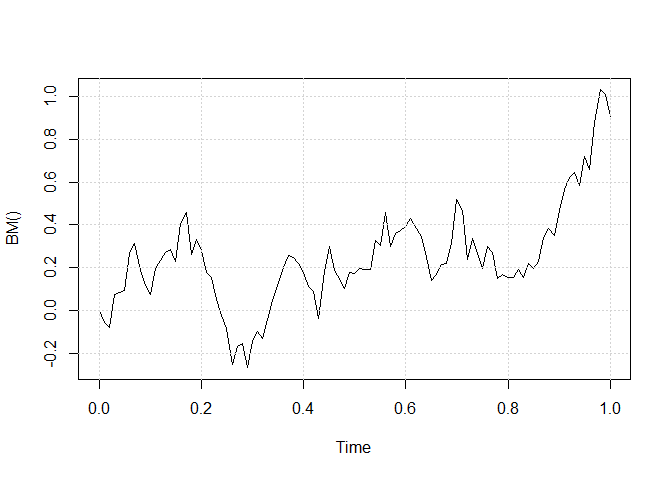
Simulação da trajetória do movimento Browniano
Dado um incremento de tempo fixo \(\Delta t> 0\), pode-se simular uma trajetória do processo de Wiener no intervalo de tempo \([0,T]\). Na verdade,
para \(W_{\Delta t}\) é verdade que
\begin{equation*}
W(\Delta t) \, = \, W(\Delta t)-W(0) \sim N(0,\Delta t) \sim \sqrt{\Delta t} N(0,1)
\end{equation*}
e o mesmo também é verdadeiro para qualquer outro incremento \(W(t+\Delta t)-W(t)\), ou seja,
\begin{equation*}
W(t+\Delta t)-W(t) \sim N(0,\Delta t) \sim \sqrt{\Delta t} N(0,1)\cdot
\end{equation*}
Assim, podemos simular um desses caminhos da seguinte maneira. Divida o intervalo \([0,T]\) em uma grade como \(0 = t_1 < t_2 < \cdots < t_{N−1} < t_N = T\)
com \(t_{i+1} - t_i = t\). Defina \(i = 1\) e \(W(0) = W(t_1) = 0\) e itere o seguinte algoritmo:
Gere um número aleatório \(z\) a partir da distribuição Gaussiana padrão.
\(i= i + 1\).
Defina \(W(t_i) = W(t_{i−1}) + z \times \sqrt{\Delta t}\).
Se \(i\leq N\), repita a partir da etapa 1.
Este método de simulação é válido apenas nos pontos da grade, mas entre quaisquer dois pontos \(t_i\) e \(t_{i+1}\) a
trajetória é geralmente aproximada por interpolação linear.
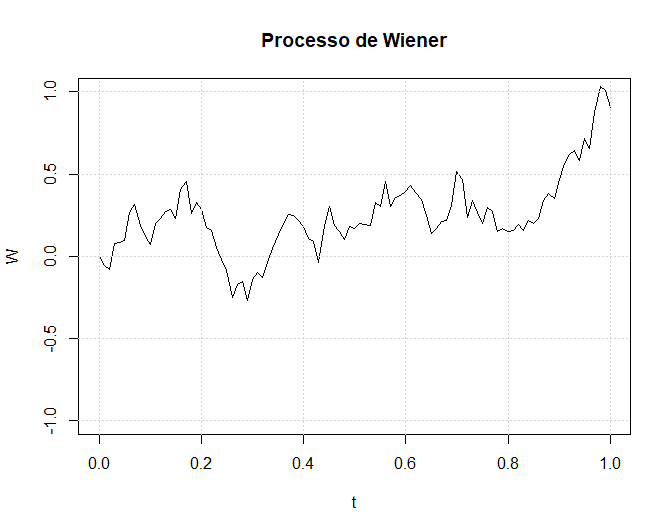
O seguinte código R faz o trabalho.
> set.seed(123)
> N <- 100 # número de pontos finais da grade, incluindo T
> T <- 1 # duração do intervalo [0,T] em unidades de tempo
> Delta <- T/N # incremento de tempo
> W <- numeric(N+1) # inicialização do vetor W
> t <- seq (0,T, length = N+1)
> for(i in 2:( N +1)) W[i] <- W[i-1] + rnorm(1)*sqrt(Delta)
> plot(t,W, type ="l", main ="Processo de Wiener" , ylim =c(-1 ,1))
> grid()
Figura I.2: Um caminho simulado do processo Wiener.
A interpolação entre os pontos da trajetória de \(W\) foi realizada graficamente especificando-se, na função plot, o
parâmetro type = "l". Deve-se notar que definimos ylim = c(-1,1) no comando plot. O intervalo
\((-1, +1)\) é o intervalo 1-\(\sigma\) para a posição do processo de Wiener no tempo \(t = 1\); ou seja, deve-se esperar encontrar pelo menos 68%
de todas as realizações possíveis do processo de Wiener até o tempo \(t = 1\), de modo que essa especificação de limite do eixo
vertical nos permite ter, com alta probabilidade, uma exibição de toda a trajetória de \(W\).
Mas o código acima pode ser considerado altamente ineficiente, pois implementa uma iteração usando uma instrução for quando
isso não é necessário. Neste caso simples, toda a trajetória pode ser simulada em uma linha de código R como segue.
> W <- c(0, cumsum(sqrt(Delta)*rnorm(N)))
devido ao fato de que o algoritmo está apenas simulando um passeio aleatório com incrementos Gaussianos de tamanho \(\sqrt{\Delta t}\times N(0,1)\). O leitor
pode verificar se os dois algoritmos produzem exatamente a mesma trajetória, definindo a semente do gerador de números aleatórios com o mesmo valor,
definindo-o com set.seed(123) ou qualquer outro valor, antes de executar cada um dos dois scripts R.
Trajetórias do movimento Browniano podem ser obtidas por meio de outras caracterizações do processo. Nós os revisamos apenas para completar
e para mostrar algumas técnicas de programação.
I.6.1 Movimento Browniano como o limite de um passeio aleatório
Uma caracterização do movimento Browniano diz que ele pode ser visto como o limite de um passeio aleatório no seguinte sentido. Dada uma sequência
de variáveis aleatórias independentes e distribuídas de forma idêntica \(X_1,X_2,\cdots,X_n\), assumindo apenas dois valores +1 e −1 com probabilidade
igual e considerando a soma parcial,
\begin{equation*}
S_n=X_1+X_2+\cdots+X_n\cdot
\end{equation*}
Então, quando \(n\to\infty\),
\begin{equation*}
P\left(\dfrac{S_{[nt]}}{\sqrt{n}} < x \right) \to P\big(W(t) < x\big),
\end{equation*}
onde \([x]\) é a parte inteira do número real \(x\). Observe que este resultado é um refinamento do Teorema do Limite Central que, em nosso caso, afirma
que \(S_n/\sqrt{n}\to N(0,1)\).
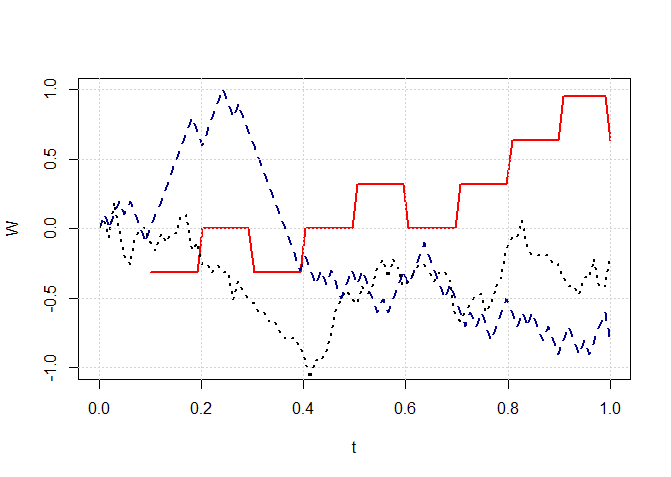
O seguinte código R fornece uma representação gráfica de quantas variáveis aleatórias \(X_1,X_2,\cdots,X_n\), precisarmos gerar para
obter uma boa aproximação.
> set.seed(123)
> n <- 10 # longe do Teorema do Limite Central
> T <- 1
> t <- seq(0,T, length =100)
> S <- cumsum(2*( runif(n) >0.5) -1)
> W <- sapply(t, function(x) ifelse(n*x >0,S[n*x] ,0))
> W <- as.numeric(W)/sqrt(n)
> plot(t,W, type ="l", ylim =c(-1 ,1), col = "red", lwd = 2)
> n <- 100 # próximo do Teorema do Limite Central
> S <- cumsum (2*( runif (n ) >0.5) -1)
> W <- sapply (t, function (x) ifelse (n*x >0,S[n*x] ,0))
> W <- as.numeric(W)/sqrt(n)
> lines(t,W, lty =2, col = "darkblue", lwd = 2)
> n <- 1000 # bem perto do limite
> S <- cumsum(2*( runif (n ) >0.5) -1)
> W <- sapply(t, function (x) ifelse (n*x >0,S[n*x] ,0))
> W <- as.numeric(W)/sqrt(n)
> lines(t,W, lty =3, lwd = 2)
> grid()
Figura I.3: Caminho do processo Wiener como limite de um passeio aleatório; linha contínua vermelha \(n = 10\),
linha tracejada \(n = 100\), linha pontilhada \(n = 1000\).
Acima, simulamos primeiro uma sequência de variáveis aleatórias \(X_i\) tomando valores +1 e -1 com igual probabilidade por meio da distribuição
uniforme. O comando R runif(n) gera \(n\) números aleatórios da distribuição uniforme em (0,1), e runif(n)> 0.5 os
transforma em uma sequência de zeros e uns, na verdade, FALSO e VERDADEIRO. Agora, se \(x\) é 0 ou 1, a função \(2*(x-1)\)
mapeia 0 a −1 e 1 a 1. Assim, agora temos uma sequência de \(n\) números aleatórios igualmente distribuídos −1 e 1 e cumsum calcula \(S_n\)
para nós. A Figura I.3 mostra os resultados da aproximação para \(n = 10\), \(n = 100\) e \(n = 1000\).
I.6.2 Movimento Browniano como expansão em \(L^2[0,T]\)
Outra caracterização do processo Wiener bastante útil em conjunto com processos empíricos em estatística é a expansão Karhunen-Loève
de \(W\). A expansão Karhunen-Loève é uma ferramenta poderosa que nada mais é do que uma expansão em \(L^2[0,T]\) de processos aleatórios em
termos de uma sequência de variáveis aleatórias independentes e coeficientes. Isso é particularmente útil para processos de tempo contínuo que são
uma coleção de incontáveis variáveis aleatórias, como o processo de Wiener que é de fato uma coleção de inúmeras variáveis
Gaussianas.
A expansão Karhunen-Loève é de fato uma série de apenas um número enumerável de termos e é útil para representar um processo em
algum intervalo fixo [0,T]. Lembramos que \(L^2([0,T])\), ou simplesmente \(L^2\), é o espaço de funções de [0,T] a \(\mathbb{R}\) definidas como
\begin{equation*}
L^2 \, = \, \{f:[0,T]\to\mathbb{R} \, : \, ||f||_2 < \infty\},
\end{equation*}
onde
\begin{equation*}
||f||_2 \, = \, \left(\int_0^T |f(t)|^2\mbox{d}t \right)^{\frac{1}{2}}\cdot
\end{equation*}
Denotemos por \(X(t)\) a trajetória do processo aleatório \(X(t,\omega)\) para um dado \(\omega\). O processo Wiener \(W(t)\) tem trajetórias
pertencentes a \(L^2([0,T])\) para quase todos os \(\omega\) e a expansão Karhunen-Loève para ele assume a forma
\begin{equation*}
W(t) \, = \, W(t,\omega) \, = \, \sum_{i=0}^\infty Z_i(\omega)\phi_i(t), \qquad 0\leq t\leq T,
\end{equation*}
com
\begin{equation*}
\phi_i(t) \, = \, \dfrac{2\sqrt{2T}}{(2i+1)\pi}\sin\left(\dfrac{(2i+1)\pi t}{2T}\right)\cdot
\end{equation*}
As funções \(\phi_i\) formam uma base de funções ortogonais e \(Z_i\) uma sequência de variáveis aleatórias
independentes igualmente distribuídas Gaussianas.
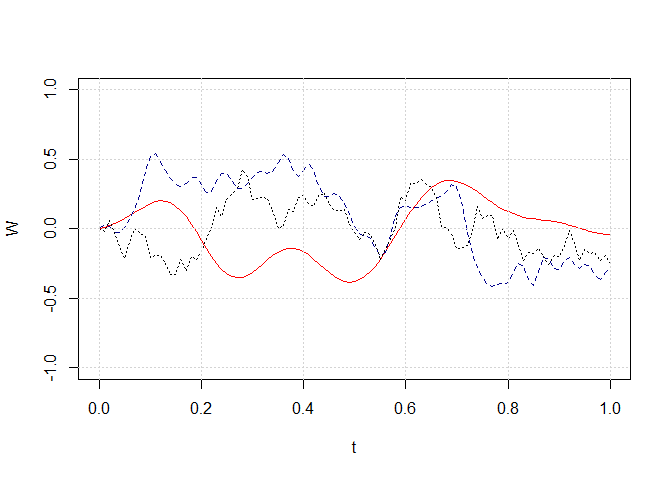
> set.seed(123)
> phi <- function(i,t,T){ (2*sqrt(2*T))/((2*i+1)*pi)*sin(((2*i+1)*pi*t)/(2*T)) }
> T <- 1
> N <- 100
> t <- seq(0,T, length = N+1)
> W <- numeric(N +1)
> n <- 10
> Z <- rnorm(n)
> for(i in 2:(N+1)) W[i] <- sum(Z*sapply(1:n, function(x) phi(x,t[i],T )))
> plot(t,W, type ="l",ylim =c( -1 ,1), col = "red")
> n <- 50
> Z <- rnorm(n)
> for(i in 2:( N +1)) W[i] <- sum(Z*sapply(1:n, function(x) phi(x,t[i],T )))
> lines(t,W, lty =2, col="darkblue")
> n <- 100
> Z <- rnorm (n)
> for(i in 2:(N+1)) W[i] <- sum(Z*sapply(1:n, function(x) phi(x,t[i],T )))
> lines(t,W, lty =3)
> grid()
Figura I.4: Aproximação de Karhunen-Loève do caminho do processo de Wiener com \(n = 10\) (linha contínua vermelha), \(n = 50\)
(linha tracejada) e \(n = 100\) (linha pontilhada) termos na expansão.
Na Figura I.4, três aproximações diferentes do caminho de Wiener com base na expansão de Karhunen-Loève são apresentadas. Quanto maior o número de termos, melhor
será a aproximação. Outros métodos \(L^2\), com base na teoria fractal e sistemas de funções iteradas, foram recentemente introduzidos, veja, por exemplo, Iacus, S.M. & La Torre, D. (2006).
Qual método escolher?
Quando é necessário apenas simular a posição do movimento Browniano em um ponto de tempo fixo, o que é bastante comum em finanças na avaliação do pagamento de contingentes de reivindicações
com um tempo de exercício fixo; então o primeiro método deve ser usado, pois é preciso o suficiente. Os dois outros métodos, em particular o último, são úteis se alguém precisar de mais informações e,
em particular, se precisar de informações sobre todo o caminho de \(W\), novamente em finanças, por exemplo, na avaliação do retorno de opções asiáticas e de barreira, mas também na física, quando
se precisa da evolução completa de um sistema.
A expansão Karhunen-Loèeve é obviamente mais cara em termos de tempo de CPU e sua confiabilidade também depende, em princípio, da confiabilidade da implementação das funções trigonométricas. Mas
o método de expansão Karhunen-Loèeve também é bastante poderoso para simular caminhos de processos sem incrementos independentes ou funcionais do movimento Browniano; quando as expansões \(L^2\) são conhecidas.
Isso é particularmente uacute;til em problemas de teste de adequação ver, por exemplo, Shorack, G. & Wellner, J. (1986).
I.6.3 Caminhos de movimento Browniano não são diferenciáveis em nenhum lugar
O movimento Browniano tem variação simples infinita, ou seja, \(\mbox{Var}_t(W) = \infty\) e função de covariância \(\mbox{Cov}\big(W(s), W(t)\big) = t∧ s\), onde \(s∧ t = \min(s,t)\). Seus caminhos são
contínuos, mas em nenhum lugar diferenciáveis. Para visualizar graficamente a estranheza da trajetória do movimento Browniano e entender porque ele não é diferenciável em nenhum lugar, podemos fazer o
seguinte experimento emprestado de Kloden, P., Platen, E. & Schurz, H. (2000).
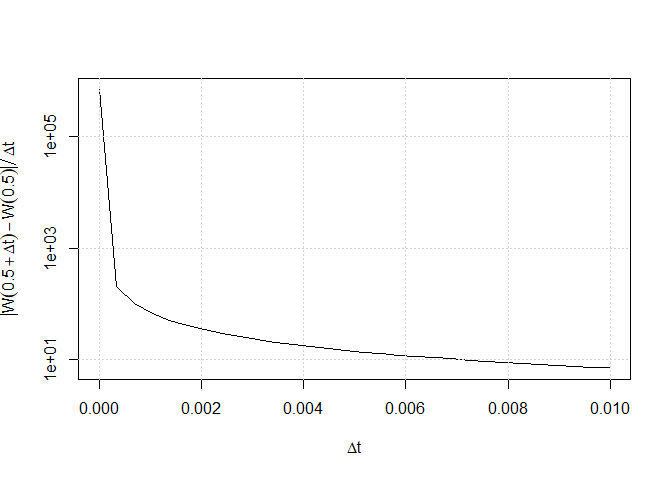
Simulamos os incrementos do movimento Browniano em dois pontos de tempo subsequentes defasados em um tempo \(\Delta t\), digamos \(W(0.5)\) e \(W(0.5+\Delta t)\) e fazemos \(\Delta t\to 0\). A Figura I.5 mostra o
comportamento explosivo de
\begin{equation*}
\lim_{\Delta t\to 0} \dfrac{|W(0.5 + \Delta t) - W(0.5)|}{\Delta t} = \infty\cdot
\end{equation*}
Isso ocorre devido à independência dos incrementos do movimento Browniano e também, mais importante, porque os incrementos \(W(t+\Delta t) −W(t)\) se
comportam como \(\sqrt{\Delta t}\) em vez de \(\Delta t\).
Figura I.5: Evidência gráfica de que a trajetória do movimento Browniano não é diferenciável.
O gráfico mostra o comportamento de \(\lim_{\Delta t\to 0} |W(t + \Delta t) - W(t)|/\Delta t = \infty\).
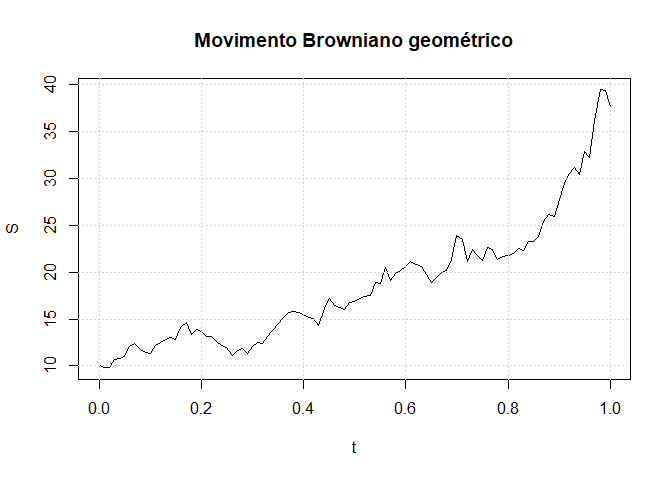
I.7 Movimento Browniano geométrico
Um processo usado com bastante frequência em finanças para modelar a dinâmica de algum ativo é o chamado movimento Browniano geométrico. Este
processo tem a propriedade de ter incrementos multiplicativos independentes e é definido como uma função do movimento Browniano padrão.
\begin{equation*}
S(t) \, = \, x\exp\left(\Big(r-\frac{\sigma^2}{2}\Big)t+\sigma W(t)\right), \qquad t>0,
\end{equation*}
com \(S(0) = x\), \(x\in\mathbb{R}\) como o valor inicial \(\sigma> 0\), interpretado como a volatilidade e \(r\), interpretado como a taxa de juros; sendo duas constantes. Foi introduzido nas finanças em
Osborne, M.F.M. (1959).
Uma implementação para simular um caminho do movimento Browniano geométrico pode ser baseada em algoritmos anteriores. Assumindo que \(W\) contém uma
trajetória de \(W\) e \(t\) é o vetor que contém todos os pontos no tempo, um caminho pode ser desenhado, veja a Figura I.6, como segue:
> set.seed(123)
> r <- 1
> sigma <- 0.5
> x <- 10
> N <- 100 # número de pontos finais da grade, incluindo T
> T <- 1 # duração do intervalo [0,T] em unidades de tempo
> Delta <- T/N # incremento de tempo
> W <- numeric(N+1) # inicialização do vetor W
> t <- seq(0, T, length = N+1)
> for(i in 2:(N+1)) W[i] <- W[i-1] + rnorm(1)*sqrt(Delta)
> S <- x*exp((r- sigma^2/2)*t + sigma*W)
> plot (t,S, type ="l",main =" Movimento Browniano geométrico ")
> grid()
Figura I.6: Trajetória do movimento Browninano geométrico obtido a partir da simulação da trajetória
do processo de Wiener.
Uma maneira equivalente de simular uma trajetória do movimento browniano geométrico é simular os incrementos de S. Na verdade,
\begin{equation*}
S(t+\Delta t) \, = \, S(t)e^{\big(r-\frac{\sigma^2}{2}\big)(t+\Delta t -t)+\sigma\big((W(t+\Delta t)-W(t)\big)},
\end{equation*}
que simplifica para
\begin{equation*}
S(t+\Delta t) \, = \, S(t)\exp\left(\Big(r-\frac{\sigma^2}{2}\Big)\Delta t+\sigma\sqrt{\Delta t}Z\right),
\end{equation*}
com \(Z\sim N(0,1)\).
A expressão acima, que derivaremos formalmente mais tarde, é um caso particular do movimento Browniano geométrico generalizado, que é um processo
que começa de \(x\) no tempo \(s\) cuja dinâmica é
\begin{equation*}
Z_{s,x}(t) \ = \, x\exp\left(\Big( r-\frac{\sigma^2}{2}\Big)(t-s)+\sigma\big(W(t)-W(s) \big)\right), \qquad t\geq s\cdot
\end{equation*}
Claro, \(Z_{0,S(0)}(t) = S(t)\). Da mesma maneira, podemos considerar o movimento Browniano transladado. Dado um movimento Browniano \(W(t)\), definimos um novo processo
\begin{equation*}
W_{0,x}(t) \, = \, s+W(t),
\end{equation*}
com \(x\) uma constante. Então \(W_{0,x}(t)\) é um movimento Browniano começando de \(x\) em vez de 0. Se ainda quisermos que isso aconteça em
algum tempo fixo \(t_0\) em vez de no tempo 0, precisamos transladar o processo ainda mais por \(W(t_0)\). Assim,
\begin{equation*}
W_{t_0,x}(t) \, = \, x+W(t)-W(t_0), \qquad t\geq t_0,
\end{equation*}
é um movimento Browniano começando em \(x\) no tempo \(t_0\).
Mais precisamente, este é o processo \(W_{t_0,x} = \{W(t) : t_0\leq t\leq T | W(t_0) = x\}\) e, é claro, \(W_{0,W(0)}(t) = W(t)\). Pelas propriedades do
movimento Browniano, \(W_{t_0,x}(t)\) é igual em distribuição a \(x + W(t − t_0)\), e uma maneira de simular isso é simular um movimento
Browniano padrão, adicionar a constante \(x\) e, em seguida, transladar o tempo.
I.8 Ponte Browniana
Outra manipulação útil e interessante do processo de Wiener é a chamada ponte Browniana, que é um movimento Browniano começando em \(x\)
no tempo \(t_0\) e passando por algum ponto \(y\) no tempo \(T\), \(T> t_0\).
É definido como
\begin{equation*}
W_{t_0,x}^{T,y} \, = \, x+W(t-t_0)-\dfrac{t-t_0}{T-t_0}\big( W(T-t_0)-y+x\big)\cdot
\end{equation*}
Mais precisamente, este é o processo \(\{W(t) : t_0\leq t\leq T | W(t_0) = x, W(T) = y\}\). Este processo é simulado usando a trajetória
simulada do processo Wiener.
> set.seed(123)
> N <- 100 # número de pontos finais da grade, incluindo T
> T <- 1 # duração do intervalo [0,T] em unidades de tempo
> Delta <- T/N # incremento de tempo
> W <- numeric(N +1) # inicializando o vetor W
> t <- seq(0, T, length = N+1)
> for(i in 2:(N +1)) W[i] <- W[i-1] + rnorm(1)*sqrt(Delta)
> x <- 0
> y <- -1
> BB <- x + W - (t/T)*(W[N+1] - y +x)
> plot(t,BB , type ="l")
> grid()
> abline(h=-1, lty =3)
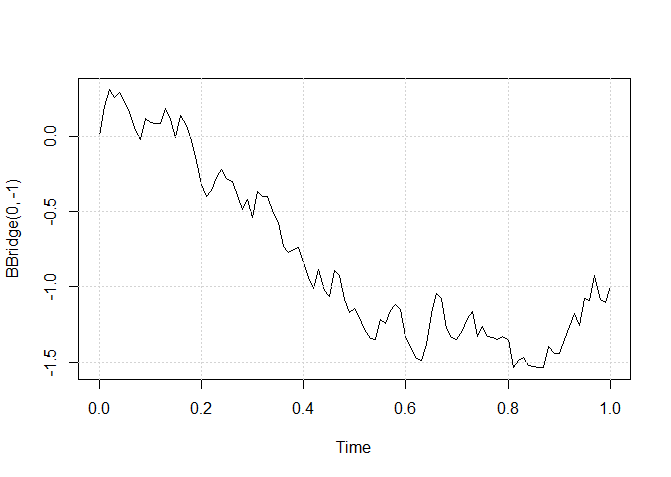
Figura I.7: Uma trajetória simulada da ponte Browniana começando em \(x\) no tempo 0 e terminando sua execução em \(y = -1\) no tempo \(T\).
A Figura I.7 mostra um caminho simulado da ponte Browniana começando em \(x = 0\) no tempo 0 e terminando em \(y = −1\) no tempo \(T\). Para concluir esta seção, fornecemos algumas
funções para gerar caminhos do Wiener e outros processos relacionados. As funções, chamadas BM, GBM e BBridge, retornam um
objeto invisível da classe ts, ou seja, um objeto de série temporal regular da linguagem R. Objetos invisíveis retornados por funções R são cópias
do objeto que podem ser atribuídas a alguns outros objetos sem serem impressos no console R; ou seja, BM() não imprime nada no console, atribuindo X <- BM(), digitando
\(X\) imprime todo o caminho simulado no console R, plot(X) plota o caminho no dispositivo gráfico, etc.
As funções BM, GBM e BBridge, contidas no pacote sde e de uso intuitivo constroem, respectivamente, uma trajetória de
\(W_{t_0,x} = \{W(t): t_0\leq t\leq T | W(t_0) = x\}\), \(W_{t_0,x}^{T,y}=\{W(t): t_\leq t\leq T| W(t_0) = x, W(T) = y\}\) e do movimento Browniano geométrico.
Uma trajetória simulada de \(W_{t_0,x} = \{W(t): t_0\leq t\leq T | W(t_0) = x\}\) utilizando a função BM.
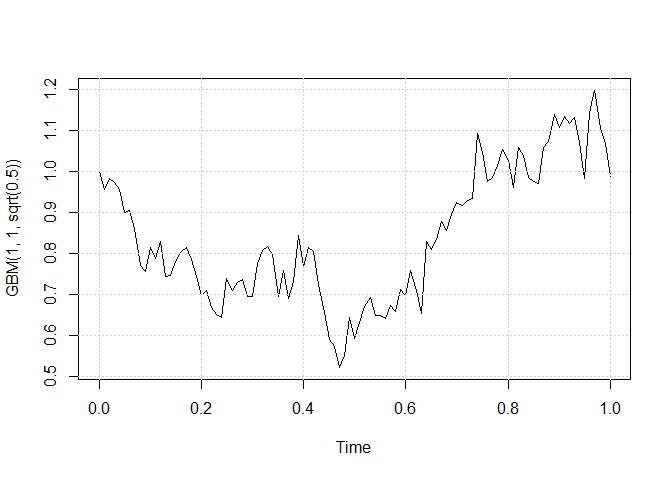
> plot(GBM(1,1,sqrt(0.5)))
> grid()
Uma trajetória simulada de \(W_{t_0,x}^{T,y}=\{W(t): t_\leq t\leq T| W(t_0) = x, W(T) = y\}\) utilizando a função GBM.
> plot(BBridge(0,-1))
> grid()
Uma trajetória simulada do movimento Browniano geométrico utilizando a função BBridge.
I.9 Integrais estocásticas e equações diferenciais estocásticas
Integrais estocásticas e, em particular, integrais de Itô são naturalmente introduzidos para definir corretamente uma equação
diferencial estocástica. Apresentamos primeiro as heurísticas por trás da noção de equações diferenciais
estocásticas com um exemplo clássico de matemática financeira.
Vamos supor que temos a quantidade \(S(t)\), \(t\geq 0\), que representa o valor de um ativo no tempo \(t\). Considere agora a variação
\(\Delta S = S(t+\Delta t) - S(t)\) de \(S\) em um pequeno intervalo de tempo \([t, t +\Delta t)\). Os retornos do ativo para o qual \(S\) é a dinâmica
são definidos como a razão \(\Delta S/S\). Podemos modelar os retornos como
\begin{equation*}
\dfrac{\Delta S}{S} \, = \, \mbox{contribuição determinística + contribuição estocástica}\cdot
\end{equation*}
A contribuição determinística pode ser assumida como ligada à taxa de juros de atividades não arriscadas e, portanto, proporcional
ao tempo com alguma taxa constante \(\mu\), portanto
\begin{equation*}
\mbox{contribuição determinística} \, = \, \mu \Delta t,
\end{equation*}
veremos mais tarde que \(μ\) pode se tornar uma função de \(t\) ou de \(S(t)\). A contribuição estocástica é
assumida como estando relacionada com a variação de alguma fonte de ruído e com a variabilidade natural do mercado, a volatilidade. Denotamos
por \(\Delta X = X(t +\Delta t) −X(t)\) a variação do processo ruidoso, ou seja, os choques e o tornamos proporcional à volatilidade
do mercado \(\sigma\); portanto
\begin{equation*}
\mbox{contribuição estocástica} \, = \, \sigma \Delta X,
\end{equation*}
também pode ser uma função de \(t\) e/ou \(S\).
A hipótese natural é assumir o comportamento Gaussiano do ruído, ou seja, \(X\sim N(0,1)\), o que implica a suposição de \(X\)
sendo o processo de Wiener se os choques forem, além disso, supostamente independentes. Finalmente, temos
\begin{equation*}
\dfrac{\Delta S}{S} \, = \, \mu\Delta t+\sigma\Delta W\cdot
\end{equation*}
Agora, é uma tentação considerar a equação de diferença acima para intervalos de tempo infinitesimais, ou seja, para \(\Delta t\to 0\),
a fim de obter uma equação diferencial estocástica, da forma
\begin{equation*}
\dfrac{S'(t)}{S(t)} \, = \, \mu+\sigma W'(t),
\end{equation*}
isto é
\begin{equation*}
S'(t) \, = \, \mu S(t)+\sigma S(t)W'(t),
\end{equation*}
que também podemos escrever em forma diferencial como
\begin{equation*}
\mbox{d}S(t) \, = \, \mu S(t)\mbox{d}t+\sigma S(t)\mbox{d}W(t)\cdot
\end{equation*}
A equação anterior é um exemplo de equação diferencial estocástica, mas infelizmente esta expressão
não tem significado matemático, pois já mencionamos que a variação do processo de Wiener \(\mbox{d}W(t)\) não
é finita e o processo de Wiener tem caminhos contínuos, mas em nenhum lugar diferenciáveis.
Para dar sentido à equação diferencial estocástica acima, mudamos para sua forma integral
\begin{equation*}
S(t) \, = \, S(0)+\mu\int_0^t S(u)\mbox{d}u+\sigma\int_0^t S(u)\mbox{d}W(u)\cdot
\end{equation*}
Esta equação introduz a integral estocástica
\begin{equation*}
\pmb{I}(X) \, = \, \int_0^T X(u)\mbox{d}W(u),
\end{equation*}
com relação ao movimento Browniano.
A definição de \(\pmb{I}(X)\) é bastante fácil para processos \(X\) simples, ou seja, constantes por partes,
mas requer mais atenção para processos genéricos. Mesmo que não vamos entrar em detalhes da construção da
integral estocástica, o leitor pode se referir a Øksendal, B. (1998) ou Karatzas, I. & Shrevre, S.E. (1988); iremos delinear
as etapas básicas para entender o que \(\pmb{I}(X)\) realmente significa e encontrar uma maneira de simular isso.
Dado um integrando genérico \(f: [0,T]\times\Omega\to\mathbb{R}\), \(\pmb{I}(f)\) é definido como o limite da sequência das
integrais \(\pmb{I}(f^{(n)})\), onde \(f^{(n)}\), chamados processos simples, são definidos como
\begin{equation*}
f^{(n)}(t,\omega) \, = \, f(t_j,\omega), \qquad t_j\leq t < t_{j+1},
\end{equation*}
onde \(t_j\in \Pi_n([0,1])\) e tal que \(\Pi_n\to 0\) quando \(n\to\infty\). Pode-se mostrar que \(f^{(n)}\) converge para \(f\) na média
quadrática.
Então \(\pmb{I}(f^{(n)})\) é definido como
\begin{equation*}
\pmb{I}(f^{(n)}) \, = \, \sum_{j=0}^{n-1} f^{(n)}(t_j)\big(W(t_{j+1})-W(t_j) \big) \, = \,
\sum_{j=0}^{n-1} f(t_j)\big(W(t_{j+1})-W(t_j) \big),
\end{equation*}
conhecido como somas de Itô.
Esta equação não converge no sentido usual, pois \(W\) não tem variação finita. Ao contrário, se
considerarmos a convergência em média quadrática, o limite existe.
Na verdade, para cada \(n\), temos que
\begin{equation*}
\mbox{E}\Big(\pmb{I}(f^{(n)})\Big)^2 \, = \, \sum_{j=0}^{n-1} \mbox{E}\big(f(t_j)\big)^2\big(t_{j+1}-t_j\big),
\end{equation*}
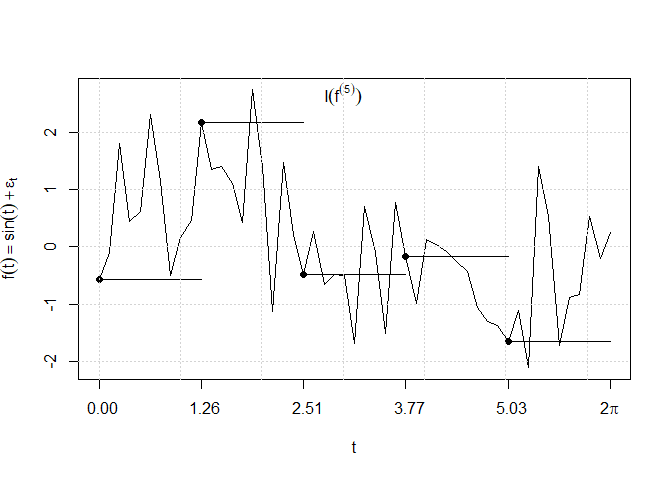
do que se segue que \(\pmb{I}(f^{(n)})\to \pmb{I}(f)\) em média quadrática, sendo o limite único. A Figura I.8 é uma
representação do processo simples \(f^{(5)}(t)\) aproximando-se o alvo \(f(t) = \sin(t) + \epsilon_t\), com \(\epsilon\) um ruído Gaussiano.
Da construção tosca descrita acima, poucas coisas importantes emergem como essenciais na definição de \(\pmb{I}(f)\).
Em primeiro lugar, é necessário que \(f\) seja um processo adaptado ao filtro natural do processo de Wiener; ou seja, \(f\) é
\(\mathcal{F}_t\)-mensurável para cada \(t\). Isso é exigido a fim de ter um processo bem definido e é a razão pela qual, nas somas
de Itô, a função é calculada no início do intervalo \([t_j, t_{j+1})\) em vez de no meio. Esta construção alternativa
da integral estocástica realmente existe e leva à integral estocástica de Stratonovich, que infelizmente não compartilha as mesmas
propriedades da integral Itô. Em particular, não é um martingale. Além disso, o comportamento do processo integrando precisa compensar a
estranheza do caminho do movimento Browniano. Este segundo fato implica na condição técnica
\begin{equation*}
\mbox{E}\left( \int_0^t X^2(u)\mbox{d}u\right) <\infty\cdot
\end{equation*}
A Figura I.8 foi gerada com as seguintes linhas de código R:
Figura I.8: O processo simples; ou seja, constante por partes, \(f^{(5)}(t)\) aproximando \(f(t) = \sin(t) + \epsilon_t\) usado
para construir integrais Itô. Observe que \(f^{(n)}(t)\) é definido como contínuo à direita.
I.9.1 Propriedades da integral estocástica e dos processos Itô
Seja \(\{X(t) : 0\leq t\leq T\}\) um processo estocástico adaptado ao filtro gerado pelo movimento Browniano e tal que
\begin{equation*}
\int_0^T \mbox{E}\big(X^2(s)\big)\mbox{d}s < \infty\cdot
\end{equation*}
A integral estocástica de \(X\) é definida como
\begin{equation*}
\mbox{I}_t(X) \, = \, \int_0^T X_s\mbox{d}W_s \, = \, \lim_{||\Pi_n||\to 0} \sum_{i=0}^{n-1} X(t_i)\big( W(t_{i+1})-W(t_i)\big),
\end{equation*}
onde a convergência está definida na média quadrática e \(t_i\in \Pi_n\). Mostraremos na Seção I.13.1 como simular uma
integral de Itô, mas resumimos aqui, sem prova, algumas propriedades interessantes da integral de Itô que usaremos em um estágio posterior.
Itô isometria
Se \(X\) for Itô integrável, então
\begin{equation*}
\mbox{E}\left(\int_0^T X(s)\mbox{d}W(s)\right) \, = \, 0
\end{equation*}
e
\begin{equation*}
\mbox{Var}\left(\int_0^T X(s)\mbox{d}W(s)\right) \, = \, \int_0^T \mbox{E}\big(X^2(t)\big)\mbox{d}t\cdot
\end{equation*}
Linearidade
Se \(X\) e \(Y\) são dois processos Itô integráveis e \(\alpha\) e \(\beta\) duas constantes, então
\begin{equation*}
\int_0^T \big(\alpha X(t)+\beta Y(t)\big)\mbox{d}W(t) \, = \, \alpha\int_0^T X(t)\mbox{d}W(t)+\beta\int_0^T Y(t)\mbox{d}W(t)\cdot
\end{equation*}
Segue-se da propriedade de linearidade acima que
\begin{equation*}
\int_0^T \alpha\mbox{d}W(t) \, = \, \alpha\int_0^T \mbox{d}W(t) \, = \, \alpha W(T)\cdot
\end{equation*}
Como mostraremos mais tarde na Seção I.11, pode-se provar que
\begin{equation*}
\int_0^T W(t)\mbox{d}W(t) \, = \, \frac{1}{2}W^2(t) -\dfrac{1}{2}T\cdot
\end{equation*}
O processo \(M(t) = M(0) + \displaystyle \int_0^t X(s)\mbox{d}W(s)\) é um martingal com \(M(0)\) uma constante.
Um processo de Itô \(\{X_t: 0\leq t\leq T\}\) é um processo estocástico que pode ser escrito na forma
\begin{equation*}
X_t \, = \, X_0+\int_0^t g(s)\mbox{d}s+\int_0^t h(s)\mbox{d}W_s,
\end{equation*}
onde \(g(t,\omega)\) e \(h(t,\omega)\) são duas funções aleatórias adaptadas e progressivamente mensuráveis de modo que
\begin{equation*}
P\left( \int_0^T |g(t,\omega)|\mbox{d}t<\infty\right) \, = \, 1 \qquad \mbox{ e } \qquad P\left( \int_0^T h^2(t,\omega)\mbox{d}t<\infty\right) \, = \, 1\cdot
\end{equation*}
I.10 Processos de difusão
A classe de processos considerada neste livro é a de soluções de processos de difusão para equações diferenciais estocásticas
da forma
A condição inicial pode ser aleatória ou não. Se aleatória, digamos \(X(0) = Z\), deve ser independente da \(\sigma\)-álgebra
gerada por \(W\) e satisfazer a condição \(\mbox{E}\big(|Z|\big)^2 < \infty\). As duas funções determinísticas \(b(\cdot,\cdot)\) e \(\sigma^2(\cdot,\cdot)\) são
chamadas, respectivamente, de coeficientes de impulso e de difusão da equação diferencial estocástica. Em todo o texto, mesmo quando não
mencionados, devem ser mensuráveis e de tal forma que
\begin{equation*}
P\left( \int_0^T \sup_{|x|\leq R} \big(|b(t,x)|+\sigma^2(t,x)\big)\mbox{d}t < \infty \right) \, = \, 1,
\end{equation*}
para todo \(T,R\in[0,\infty)\).
Apresentamos agora duas condições globais que permitirão a demonstração do Teorema de Existência e Unicidade, apresentado a seguir:
Suposição 1: (Lipschitz Global) Para todos os \(x,y\in\mathbb{R}\) e \(t\in [0,T]\), existe uma constante \(K < \infty\) tal que
\begin{equation*}
|b(t,x)-b(t,y)|+|\sigma(t,x)-\sigma(t,y)| \, < \, K|x-y|\cdot
\end{equation*}
Suposição 2: (Crescimento linear) Para todos os \(x,y\in\mathbb{R}\) e \(t\in [0,T]\), existe uma constante \(C < \infty\) tal que
\begin{equation*}
|b(t,x)|+|\sigma(t,x)| \, < \, C(1+|x|)\cdot
\end{equation*}
A condição de crescimento linear controla o comportamento da solução para que \(X_t\) não exploda em um tempo finito.
Teorema I.2.
Sob as suposições 1 e 2 acima, a equação diferencial estocástica tem uma solução forte única,
contínua e adaptada de modo que
\begin{equation*}
\mbox{E}\left( \int_0^T |X_t|^2 \mbox{d}t \right) \, < \, \infty\cdot
\end{equation*}
Demonstração.
Ver Øksendal, B. (1998).
▉
Chamamos esse processo \(X\) de processo de difusão. O resultado acima afirma que a solução \(X\) é do tipo forte. Isso implica
essencialmente na singularidade do caminho do resultado. Também é possível obter soluções fracas sob diferentes hipóteses.
Em muitos casos em estatísticas, as condições para soluções fracas são suficientes porque implicam que quaisquer
duas soluções fracas \(X^{(1)}\) e \(X^{(2)}\) não são necessariamente idênticas no caminho, enquanto suas distribuições
são, e isso é suficiente para inferência de verossimilhança. Claro, soluções fortes também são soluções
fracas, mas o contrário não é necessariamente verdadeiro.
A maior parte deste livro se concentrará na versão homogênea da equação diferencial estocástica com condição
inicial não aleatória, digamos \(X(0) = x\). Para manter a notação mais simples, usaremos a seguinte notação ao longo do texto:
\begin{equation*}
X_t \, = \, x+\int_0^t b(X_u)\mbox{d}u + \int_0^t \sigma(X_u)\mbox{d}W_u
\end{equation*}
e
\begin{equation*}
\mbox{d}X_t \, = \, b(X_t)\mbox{d}t + \sigma(X_t)\mbox{d}W_t\cdot
\end{equation*}
As condições acima podem ser muito restritivas em alguns casos, como (ver, por exemplo, Kutoyants, Y. (2004)),
\begin{equation*}
\mbox{d}X_t \, = \, -\theta X_t^3\mbox{d}t + \sigma \mbox{d}W_t\cdot
\end{equation*}
Em muitos casos, as versões locais das mesmas condições são suficientes.
Apresentamos agora duas condições locais que permitirão a demonstração do Teorema de Existência e Unicidade, apresentado a seguir:
Suposição 3: (Lipschitz Local) Para qualquer \(N <\infty\) e \(|x|,|y|\leq N\) existe uma constante \(L_N>0\) tal que
\begin{equation*}
|b(x)-b(y)|+|\sigma(x)-\sigma(y)| \, \leq \, L_N|x-y|
\end{equation*}
e
\begin{equation*}
2xb(x)+\sigma^2(x) \, \leq \, B(1+x^2)\cdot
\end{equation*}
De fato, essas condições são satisfeitas no exemplo acima \(\mbox{d}X_t = -\theta X_t^3\mbox{d}t + \sigma \mbox{d}W_t\). Para a classe de
processos de difusão ergódica que será discutida posteriormente, geralmente é verdade que \(xb(x) < 0\). Portanto, a segunda expressão
acima é apenas uma condição no crescimento do coeficiente de difusão.
Suposição 4: Seja \(b(\cdot)\) limitado localmente, \(\sigma^2(\cdot)\) cont&iaute;nuo e positivo e para algum \(A\) a seguinte condição
é válida:
\begin{equation*}
xb(x)+\sigma^2(x) \, \leq \, A(1+x^2)\cdot
\end{equation*}
Teorema I.3.
De acordo com a suposição 4, as equações integrais de Itô tem uma solução fraca única.
Demonstração.
Ver Duffie, D. & Glynn, P. (2004).
▉
Para uma discussãoo sobre soluções fortes e fracas, o leitor pode considerar referências Kutoyants, Y. (2004),
Krylov, N.V. & Zvonkin, A.K. (1981), Karatzas, I. & Shrevre, S.E. (1988) e Stroock, D.W. & Varadhan, S.R.S. (1979).
I.10.1 Ergodicidade
Os processos de difusão possuem a propriedade de Markov e podem ou não ser ergódicos. A propriedade ergódica implica que, para
qualquer função mensurável \(h(\cdot)\), o seguinte resultado é válido com probabilidade 1:
\begin{equation*}
\dfrac{1}{T}\int_0^T h(X_t)\mbox{d}t \, \to \, \int_{-\infty}^{+\infty} h(x)\pi(x)\mbox{d}x \, = \, \mbox{E}\big(h(\xi)\big),
\end{equation*}
onde \(\pi(\cdot)\) é chamada de densidade invariante ou estacionária do processo de difusão e \(\xi\) é alguma variável aleatória
com \(\pi(\cdot)\) como densidade. Os processos de difusão têm a boa propriedade de que a distribuição estacionária, quando existe,
pode ser expressa em termos de medida de escala e medida de velocidade. Às vezes, ambas são chamadas de medida ou densidade; definidas respectivamente como
\begin{equation*}
s(x) \, = \, \exp\left(-2\int_{x_0}^x \dfrac{b(y)}{\sigma^2(y)}\mbox{d}y \right)
\end{equation*}
e
\begin{equation*}
m(x) \, = \, \dfrac{1}{\sigma^2(x)s(x)}\cdot
\end{equation*}
Em particular, a densidade da distribuição invariante \(\pi(\cdot)\) é proporcional, até uma constante de normalização, à medida
de velocidade \(m(\cdot)\); ou seja,
\begin{equation*}
\pi(x) \, = \, \dfrac{m(x)}{M},
\end{equation*}
onde \(M=\int m(x)\mbox{d}x\).
Suposição 5: Seja \((\ell,r)\), com \(-\infty < \ell\leq r < \infty\) o espaço de estados do processo de difusão \(X\),
solução das equações diferenciais estocásticas assumindo que
\begin{equation*}
\int_\ell^r m(x)\mbox{d}x < \infty\cdot
\end{equation*}
Seja \(x^*\) um ponto arbitrário no espaço de estados de \(X\), de modo que
\begin{equation*}
\int_{x^*}^r s(x)\mbox{d}x \, = \, \int_\ell {x^*} s(x)\mbox{d}x \, = \, \infty\cdot
\end{equation*}
Se uma ou ambas as integrais acima forem finitas, o limite correspondente é assumido como refletindo instantaneamente.
Sob a Suposição 5, o processo \(X\) é ergódico e tem uma função de distribuição invariante.
I.10.2 Propriedade Markoviana
A partir da propriedade Markoviana da difusão, também é possível definir a densidade de transição do valor \(x\) no tempo \(s\) para o valor \(y\)
no tempo \(t\) por \(p(t,y | s, x)\) ou, quando conveniente, como \(p(t−s, y | x)\). Para modelos paramétricos, usaremos posteriormente a notação \(p(t, y | s, x;\theta)\) ou
\(p_\theta (t, y | s, x)\) e \(p (t - s, y | x;\theta)\) ou \(p_\theta (t - s, y | x)\), respectivamente.
A densidade de transição satisfaz a equação direta de Kolmogorov
\begin{equation*}
\dfrac{\partial }{\partial t}p(t,y|s,x) \, = \, -\dfrac{\partial}{\partial y} \big(b(y)p(t,y|s,x)\big)+
\dfrac{1}{2}\dfrac{\partial^2}{\partial y^2} \big(\sigma^2(y)p(t,y|s,x)\big)
\end{equation*}
e a equação reversa de Kolmogorov
\begin{equation*}
-\dfrac{\partial}{\partial s}p(t,y|s,x) \, = \, b(y)\dfrac{\partial}{\partial x} p(t,y|s,x)+
\dfrac{1}{2}\sigma^2(x)\dfrac{\partial^2}{\partial x^2} p(t,y|s,x),
\end{equation*}
veja Øksendal, B. (1998).
Fazendo \(t\to -\infty\) na equação direta de Kolmogorov, é possível obter
\begin{equation*}
\dfrac{\mbox{d}}{\mbox{d}x^2} \big(\sigma^2(x)\pi(x) \big) \, =\, 2\dfrac{\mbox{d}}{\mbox{d}x} \big( b(x)\pi(x)\big),
\end{equation*}
onde \(\pi(x)\) é a densidade estacionária. A equação acima estabelece uma relação entre a inclinação \(b(\cdot)\),
o coeficiente de difusão \(\sigma(\cdot)\) e a densidade invariante \(\pi(\cdot)\). Portanto, em princípio, dado qualquer um dos dois, pode-se obter o terceiro.
Por exemplo, integrando a expressão acima, obtemos (ver Banon, G. (1978))
\begin{equation*}
b(x) \, = \, \dfrac{1}{2\pi(x)}\dfrac{\mbox{d}}{\mbox{d}x} \big( \sigma^2(x)\pi(x)\big),
\end{equation*}
e integrando novamente; obtemos (ver Aït-Sahalia, Y. (1996))
\begin{equation*}
\sigma^2(x) \, = \, \dfrac{2}{\pi(x)}\int_0^x b(u)\pi(u)\mbox{d}u\cdot
\end{equation*}
Todos esses fatos e relaçães serão úteis para os algoritmos de simulação e nos capítulos sobre inferência paramétrica e não paramétrica que se seguem.
I.10.3 Variação quadrática
Pode ser visto em Öksendal, B. (1998) que a variação quadrática de uma solução de processo de difusão para
equações diferenciais estocásticas, como na Definição 1, é dada por
\begin{equation*}
<X,X>_t \, = \, \int_0^t \sigma^2(u,X_u)\mbox{d}u\cdot
\end{equation*}
I.10.4 Gerador infinitesimal de um processo de difusão
Dado um processo de difusão \(X\) solução para \(\mbox{d}X_t=b(X_t)\mbox{d}t+\sigma(X_t)\mbox{d}t\), \(X_0=x\),
um operador diferencial \(\mathcal{L}\) da forma
\begin{equation*}
\big( \mathcal{L}f\big)(x) \, = \, \dfrac{\sigma^2(x)}{2}f''(x)+b(x) f'(x),
\end{equation*}
com \(f\) duas vezes diferenciével é chamado de gerador infinitesimal do processo de difusão \(X\).
I.10.5 Como obter um martingal a partir de um processo de difusão
Se \(Z\) é um processo definido como
\begin{equation*}
Z(t) \, = \, f(X_t) -\int_0^t \big( \mathcal{L}f\big)(X_s)\mbox{d}s,
\end{equation*}
onde \(X\) é um processo de difusão e \(f(\cdot)\in C_0^2(\mathbb{R})\), então \(Z\) é um martingal com relação
ao movimento Browniano. Mais ainda, temos que
\begin{equation*}
\mbox{E}\big( f(X_t)\big) \, = \, f(x)+\mbox{E}\left( \int_0^t \big( \mathcal{L}f\big)(X_s)\mbox{d}s\right)\cdot
\end{equation*}
I.11 Fórmula de Itô
Uma importante ferramenta de cálculo estocástico que também é útil em simulações é a fórmula de Itô. Esta fórmula pode
ser vista como a versão estocástica de uma expansão de Taylor de \(f(X)\) até a segunda ordem, onde \(X\) é um processo de difusão. O Lema de itô diz
que se \(f(t, x)\) é uma função duas vezes diferenciável em \(t\) e \(x\), então
\begin{equation*}
f(t,X_t) \, = \, f(0,X_0) + \int_0^t f_t(u,X_u)\mbox{d}u + \int_0^t f_x(u,X_u)\mbox{d}X_u+\frac{1}{2}\int_0^t f_{xx}(u,X_u)\big(\mbox{d}X_u\big)^2,
\end{equation*}
onde
\begin{equation*}
\dfrac{\partial f(t,x)}{\partial t} = f_t(t,x), \quad \dfrac{\partial f(t,x)}{\partial x} = f_x(t,x), \quad
\dfrac{\partial^2 f(t,x)}{\partial x^2} = f_{xx}(t,x)
\end{equation*}
ou, em forma diferencial,
\begin{equation*}
\mbox{d}f(t,X_t)=f_t(t,X_t)\mbox{d}t+f_x(t,X_t)\mbox{d}X_t+\frac{1}{2}f_{xx}(t,X_t)\big(\mbox{d}X_t\big)^2\cdot
\end{equation*}
Caso \(X_t\) seja um amovimento Browniano, isso se simplifica na forma
\begin{equation*}
f(t,W_t) = f(0,0)+\int_0^t \left( f_t(u,W_u)+\frac{1}{2}f_{xx}(u,W_u)\right)\mbox{d}u+\int_0^t f_x(u,W_u)\mbox{d}W_u
\end{equation*}
ou, em forma diferencial,
\begin{equation*}
\mbox{d}f(t,W_t)=\left( f_t(t,W_t)+\frac{1}{2}f_{xx}(t,W_t)\right)\mbox{d}t+f_x(t,W_t)\mbox{d}W_t\cdot
\end{equation*}
Como exemplo, considerando a função \(f(t,x)=f)=x^2\). A fórmula de Itô aplicada à \(f(W_t)\) leva a
\begin{equation*}
W_t^2= 0^2+\int_0^t 2W_s \mbox{d}W_s +\frac{1}{2}\int_0^t 2\mbox{d}s,
\end{equation*}
e portanto
\begin{equation*}
\int_0^t W_s\mbox{d}W_s= \frac{1}{2}W_t^2 -\frac{1}{2}t,
\end{equation*}
conforme já mencionado na propriedade 4.
I.11.1 Ordem dos diferenciais na fórmula Itô
Apesar da aparente simplicidade da fórmula de Itô, termos como \(\big(\mbox{d}X_t\big)^2\) não são fáceis de derivar em muitos casos concretos sem algum
conhecimento adicional sobre a integral estocástica. Em particular, do ponto de vista da aplicação da fórmula de Itô, deve-se ter em mente que \(\mbox{d}t \cdot\mbox{d}W_t\)
e \((\mbox{d}t)^2\) são da ordem \(O(\mbox{d}t)\), o que significa que após desenvolver o termo \(\big(\mbox{d}X_t\big)^2\), todos os termos da fórmula para os quais
a parte diferencial é \(\mbox{d}t\cdot \mbox{d}W_t\) ou \((\mbox{d}t)^2\) podem ser desconsiderados.
Além disso, os termos de ordem \(\big(\mbox{d}W_t\big)^2\) se comportam como \(\mbox{d}t\) para as propriedades do movimento Browniano. Portanto, a parte diferencial
\(\big(\mbox{d}W_t\big)^2\) pode ser substituída em qualquer lugar simplesmente por \(\mbox{d}t\).
A aplicação direta da fórmula de Itô ajuda a descobrir a solução de equações diferenciais estocásticas. Considere a
equação diferencial estocástica
\begin{equation*}
\mbox{d}X_t = b_1(t)X_t \mbox{d}t + \sigma_1(t)X_t \mbox{d}W_t\cdot
\end{equation*}
Essa equação é chamada de equação diferencial estocástica com ruído multiplicativo.
Considere agora a versão não homogênea da equação diferencial estocástica com ruído multiplicativo
\begin{equation*}
\mbox{d}X_t = \big(b_1(t)X_t +b_2(t)\big)\mbox{d}t + \big(\sigma_1(t)X_t +\sigma_2(t)\big)\mbox{d}W_t,
\end{equation*}
e seja \(Y_t=\displaystyle \exp\left(\int_0^t \Big(b_1(s)-\frac{1}{2}\sigma_1(s) \Big)\mbox{d}s+\int_0^t \sigma_1(s)\mbox{d}W_s\right)\). Então a solução
da equação acima é
\begin{equation*}
X_t=Y_t\left(X_0+\int_0^t \Big(b_2(s)-\sigma_1(s)\sigma_2(s) \Big)Y_s^{-1}\mbox{d}s+\int_0^t \sigma_2(s)Y_s^{-1}\mbox{d}W_s\right)\cdot
\end{equation*}
Uma derivação simples deste fato pode ser encontrada em Mikosch, T. (1998). É claro que o movimento Browniano geométrico é um caso
particular com coeficientes constantes \(b_1(t) = \mu\) e \(\sigma_1(t) =\sigma\).
I.11.3 Derivação das equações diferenciais estocásticas para o movimento Browniano geométrico
Agora podemos derivar a equaçã diferencial estocástica para o movimento Browniano geométrico,
\begin{equation*}
S_t \, = \, S_0\exp\left( \Big(r-\dfrac{\sigma^2}{2} \Big)t+\sigma W_t\right), \qquad t>0,
\end{equation*}
escolhendo
\begin{equation*}
f(t,x)=S_0\exp\left( \Big(r-\dfrac{\sigma^2}{2} \Big)t+\sigma x\right)\cdot
\end{equation*}
Há uma aplicação particular da fórmula de Itô que é de interesse em muitos dos métodos de simulação e estimação
que iremos descrever nos próximos capítulos, por exemplo, esta transformação foi usada em Florens, D. (1999), Shoji, L. & Ozaki, T. (1998) e Aït-Sahalia, Y. (2002).
Suponha que temos a equação diferencial estocástica
\begin{equation*}
\mbox{d}X_t \, = \, b(t,X_t)\mbox{d}t+\sigma(X_t)\mbox{d}W_t,
\end{equation*}
onde onde o coeficiente de difusão depende apenas da variável de estado. Essa equação diferencial estocática pode sempre ser transformada em uma com
um coeficiente de difusão unitário aplicando a transformada de Lamperti
\begin{equation*}
Y_t \, = \, F(X_t) \, = \, \int_z^{X_t} \dfrac{1}{\sigma(u)}\mbox{d}u\cdot
\end{equation*}
Aqui, \(z\) é qualquer valor arbitrário no espaço de estados de \(X\). De fato, o processo \(Y_t\) resolve a equação diferencial estocástica
\begin{equation*}
\mbox{d}Y_t \, = \, b_Y(t,Y_t)\mbox{d}t+\mbox{d}W_t,
\end{equation*}
onde
\begin{equation*}
b_Y(t,y) \, = \, \dfrac{b\big(t,F^{-1}(y)\big)}{\sigma\big(F^{-1}(y)\big)}-\dfrac{1}{2}\sigma_x\big(F^{-1}(y)\big),
\end{equation*}
que também podemos escrever como
\begin{equation*}
\mbox{d}Y_t \, = \, \left(\dfrac{b(t,X_t)}{\sigma(X_t)}-\dfrac{1}{2}\sigma_x(X_t)\right)\mbox{d}t+\mbox{d}W_t\cdot
\end{equation*}
Para obter o resultado, deve-se usar a fórmula Itô com
\begin{equation*}
f(t,x)=\int_z^x \dfrac{1}{\sigma(u)}\mbox{d}u, \qquad f_t(t,x)=0, \qquad f(t,x)=\dfrac{1}{\sigma(x)}, \qquad
f_{xx}(t,x)=-\dfrac{\sigma_x(x)}{\sigma^2(x)}\cdot
\end{equation*}
Portanto
\begin{array}{rcl}
\mbox{d}f(t,x) & = & 0\cdot\mbox{d}t +f_x(t,X_t)\mbox{d}X_t+\dfrac{1}{2}f_{xx}(t,X_t)(\mbox{d}X_t)^2 \\
& = & \dfrac{b(t,X_t)\mbox{d}t+\sigma(X_t)\mbox{d}W_t}{\sigma(X_t)}-\dfrac{1}{2}\dfrac{\sigma_x(t,X_t)}{\sigma^2(X_t)}
\Big( b(t,X_t)\mbox{d}t+\sigma(X_t)\mbox{d}W_t\Big)^2 \\
& = & \dfrac{b(t,X_t)}{\sigma(X_t)}\mbox{d}t+\mbox{d}W_t-\dfrac{1}{2}\dfrac{\sigma_x(t,X_t)}{\sigma^2(X_t)}
\Big( b(t,X_t)(\mbox{d}t)^2+2\cdot b(t,X_t)\sigma(X_t)\mbox{d}t\cdot\mbox{d}W_t+\sigma^2(x)(\mbox{d}W_t)^2\Big)\cdot
\end{array}
Agora lembre-se de que os termos \((\mbox{d}t)^2\) e \((\mbox{d}t\cdot \mbox{d}W_t)\) podem ser descartados e \((\mbox{d}W_t)^2\) substituído por
\(\mbox{d}t\). Portanto, o resultado é obtido.
I.12 Teorema de Girsanov e razão de verossimilhança para processos de difusão
O Teorema de Girsanov é um teorema de mudança de medida para processos estocásticos. Na inferência para processos de difusão, isso é usado para obter a
razão de verossimilhança na qual a inferência de verossimilhança é baseada. Existem diferentes versões deste teorema, e aqui vamos dar uma útil em estatística para processos de difusão Kutoyants, Y. (2004).
Considere as três equações diferenciais estocásticas:
\begin{array}{rclll}
\mbox{d}X_t & = & b_1(X_t)\mbox{d}t+\sigma(X_t)\mbox{d}W_t, & X_0^{(1)}, & 0\leq t\leq T, \\
\mbox{d}X_t & = & b_2(X_t)\mbox{d}t+\sigma(X_t)\mbox{d}W_t, & X_0^{(2)}, & 0\leq t\leq T, \\
\mbox{d}X_t & = & \sigma(X_t)\mbox{d}W_t, & X_0, & 0\leq t\leq T,
\end{array}
e denote por \(P_1\), \(P_2\) e \(P\) as três medidas de probabilidade induzidas pelas soluções das três equações.
Teorema I.4. (Teorema de Girsanov)
Suponha que os coeficientes satisfaçam as suposições 1 e 2 ou a suposição 4 ou qualquer outro conjunto de condições
que garantam a existência da solução de cada equação diferencial estocástica. Suponha ainda que os valores iniciais sejam
variáveis aleatórias com densidades \(f_1(\cdot)\), \(f_2(\cdot)\) e \(f(\cdot)\) com o mesmo suporte comum ou não aleatório e igual à
mesma constante. Então, as três medidas \(P_1\), \(P_2\) e \(P\) são todas equivalentes e as derivados Radon-Nikodým correspondentes são
\begin{equation*}
\dfrac{\mbox{d}P_1}{\mbox{d}P}(X) \, = \, \dfrac{f_1(X_0)}{f(X_0)}\exp\left( \int_0^T \dfrac{b_1(X_s)}{\sigma^2(X_s)}\mbox{d}X_s
-\frac{1}{2}\int_0^T\dfrac{b_1^2(X_s)}{\sigma^2(X_s)}\mbox{d}s\right)
\end{equation*}
e
\begin{equation*}
\dfrac{\mbox{d}P_2}{\mbox{d}P}(X) \, = \, \dfrac{f_2(X_0)}{f(X_0)}\exp\left( \int_0^T \dfrac{b_2(X_s)-b_1(X_s)}{\sigma^2(X_s)}\mbox{d}X_s
-\frac{1}{2}\int_0^T\dfrac{b_2^2(X_s)-b_1^2(X_s)}{\sigma^2(X_s)}\mbox{d}s\right)\cdot
\end{equation*}
Demonstração.
Ver Jacod, J. & Shiryayev, A.N. (1987) e Lipster, R.S. & Shiryayev, A.N. (1997).
▉
Uma primeira versão para famílias paramétricas \(P_1 = P_1(\theta)\) com \(b_1(x) = b_1(x;\theta)\) é geralmente adotada
como a razão de verossimilhanças para encontrar estimadores de máxima verossimilhança. Para entender por que essas
expressões podem ser assimiladas como a verossimilhança, considere o seguinte exemplo inspirado por M. Keller-Ressel e T. Steiner.
Suponhamos que temos um movimento Browniano padrão \(W_t\) em [0,1] reescalado por uma constante \(\sigma\),
\begin{equation*}
X_t \, = \, \sigma W_t,
\end{equation*}
e o mesmo movimento Browniano reescalonado com inclinação
\begin{equation*}
Y_t \, = \, \nu t+\sigma W_t, \qquad 0\leq t\leq 1,
\end{equation*}
com \(\nu < 0\) e \(\sigma>0\).
Aplicamos a segunda fórmula de Girsanov para ponderar as trajetórias do processo \(Y_t\) e no nosso caso \(b_1(x) = \nu\) para o processo \(Y_t\),
\(b_2(x) = 0\) para \(X_t\) e \(\sigma(x) =\sigma\). Temos com isso
\begin{array}{rcl}
\dfrac{\mbox{d}P_2}{\mbox{d}P_1}(Y) & = & \displaystyle \exp\left( \int_0^1 \dfrac{0-\nu}{\sigma^2}\mbox{d}Y_s-\dfrac{1}{2}\int_0^1\dfrac{0^2-\nu^2}{\sigma^2}\mbox{d}t\right) \\
& = & \displaystyle \exp\left( \dfrac{-\nu}{\sigma^2}\int_0^1 \big(\nu \mbox{d}s+ \sigma\mbox{d}W_s\big)+\dfrac{1}{2}\dfrac{\nu^2}{\sigma^2}\right) \\
& = & \displaystyle \exp\left( -\Big(\dfrac{\nu}{\sigma}\Big)^2+ \dfrac{-\nu}{\sigma}W_1+\dfrac{1}{2}\dfrac{\nu^2}{\sigma^2}\right) \\
& = & \displaystyle \exp\left( -\dfrac{\nu W_1}{\sigma}-\dfrac{1}{2}\Big(\dfrac{\nu}{\sigma}\Big)^2\right)\cdot
\end{array}
Os pesos anteriores dependem do valor final de \(W_1\). Obviamente, quanto menor e mais negativo for \(W_1\), maior será a probabilidade de que uma trajetória observada \(Y\) realmente
venha do modelo \(Y_t\) porque \(\nu < 0\). O código a seguir simula 30 caminhos de \(X_t\) e \(Y_t\) com \(\nu= −0.7\) e \(\sigma= 0.5\) e calcula os pesos usando a fórmula de Girsanov.
Finalmente, ele traça os caminhos de \(Y_t\) e os mesmos caminhos com uma cor proporcional aos pesos: as trajetórias mais escuras são mais prováveis de vir do modelo
verdadeiro \(Y_t\). O resultado é mostrado na Figura I.9.
> set.seed(123)
> par(mar=c(3 ,2 ,1 ,1), mfrow =c (2 ,1))
> npaths <- 30
> N <- 1000
> sigma <- 0.5
> nu <- -0.7
> require(sde)
> X <- sde.sim( drift = expression(0), sigma = expression(0.5), pred = F, N = N, M = npaths )
> Y <- X + nu*time(X)
> girsanov <- exp(0.25*(-nu/sigma*X[N,] - 0.5*(nu/sigma)^2))
> girsanov <- (girsanov - min(girsanov))/diff(range(girsanov))
> col.girsanov <- gray(girsanov)
> require(grDevices)
> matplot(seq(0:N)/N,Y, type = "l", lty = 1, col = "black", xlab = "t")
> grid()
> matplot(seq(0:N)/N,Y, type = "l", lty = 1, col = col.girsanov, xlab = "t")
> grid()
No código R anterior, os pesos são redimensionados um pouco para aumentar o contraste visual e são posteriormente normalizados para um.
Figura I.9: Caminhos simulados de movimento Browniano com inclinação (painel superior) e os mesmos caminhos (painel inferior) coloridos usando os pesos de Girsanov.
As trajetórias mais escuras são mais prováveis de vir do modelo de movimento Browniano com inclinação.
I.13 Algumas famílias paramétricas de processos estocásticos
Nesta seção, apresentamos algumas das soluções de processos estocásticos bem conhecidas e amplamente utilizadas para as equações
diferenciais estocástica gerais
\begin{equation*}
\mbox{d}X_t \, = \, b(X_t)\mbox{d}t + \sigma(X_t)\mbox{d}W_t,
\end{equation*}
com uma rápida revisão de suas propriedades principais.
Quando possível, descreveremos cada processo em termos de seus primeiros momentos e função de covariância, em termos da densidade estacionária
\(\pi(x)\) e em termos de sua distribuição condicional \(p(t-s, y | x;\theta )\) ou \(p_\theta (t − s, y | x)\) de \(X_t\) dado algum estado anterior do processo
\(X_s = x_s\). Em alguns casos, será mais simples expressar a densidade estacionária \(\pi(x)\) de uma difusão em termos da medida de escala \(s(\cdot
)\) e a medida de velocidade \(m(\cdot)\) da difusão.
I.13.1 Processos de Ornstein-Uhlenbeck ou Vasicek
O processo de Uhlenbeck, G.E. & Ornstein, L.S. (1930) ou Vasicek, O. (1977) é a única solução para a seguinte equação diferencial estocástica
\begin{equation*}
\mbox{d}X_t \, = \, (\theta_1-\theta_2 X_t)\mbox{d}t+\theta_3 \mbox{d}W_t, \qquad X_0=x_0,
\end{equation*}
com
com \(\theta_3\in\mathbb{R}_+\) e \(\theta_1,\theta_2\in\mathbb{R}\).
O modelo com \(\theta_1 = 0\) foi originalmente proposto por Uhlenbeck, G.E. & Ornstein, L.S. (1930) no contexto da física e então generalizado por Vasicek, O. (1977) para modelar taxas
de juros. Para \(\theta_2> 0\), este é um processo de reversão à média, o que significa que o processo tende a oscilar em torno de algum estado de equilíbrio. Outra
propriedade interessante do processo Ornstein-Uhlenbeck é que, ao contrário do movimento Browniano, é um processo com variância finita para todo \(t\geq 0\).
Outra parametrização do processo de Ornstein-Uhlenbeck mais comum na modelagem financeira é
\begin{equation*}
\mbox{d}X_t \, = \, \theta(\mu-X_t)\mbox{d}t+\sigma\mbox{d}W_t, \qquad X_0=x_0,
\end{equation*}
onde \(\sigma\) é interpretado como a volatilidade, \(\mu\) é o valor de equilíbrio de longo prazo do processo e \(\theta\) é a velocidade de reversão.
Como uma aplicação do lema de Itô, podemos mostrar a solução explícita de \(\mbox{d}X_t = (\theta_1-\theta_2 X_t)\mbox{d}t+\theta_3 \mbox{d}W_t \) escolhendo \(f(t,x) = xe^{\theta_2 t}\).
De fato,
\begin{equation*}
f_t(t,x)=\theta_2 f(t,x), \qquad f_x(t,x)=e^{\theta_2 t} \qquad \mbox{ e } \qquad f_{xx}(t,x)=0\cdot
\end{equation*}
Para \(\theta_2> 0\), o processo também é ergódico e sua lei invariante é a densidade Gaussiana com esperança \(\theta_1/\theta_2\) e
variância \(\theta_2^3/2\theta_2\), ou seja,
\begin{equation*}
X_t \sim N(\theta_1/\theta_2,\theta_2^3/2\theta_2)\cdot
\end{equation*}
A função de covariância é \(\mbox{Cov}(X_t, X_s) = \theta^2_3 e^{−\theta_2 | t − s |}/2\theta_2\). Às vezes, é conveniente
reescrever o processo como o processo Wiener transformado em escala de tempo
\begin{equation*}
X_t \, = \, \dfrac{\theta_1}{\theta_2}+\dfrac{\theta_3 e^{-\theta_2 t}}{\sqrt{2\theta_2}} W\big( e^{2\theta_2 t}\big)\cdot
\end{equation*}
Essa relação vem diretamente das propriedades do movimento Browniano.
A lei condicional
Para qualquer \(t\geq 0\), o processo de Ornstein-Uhlenbeck tem uma densidade de transição Gaussiana ou condicional \(p(t, X_t | X_0 = x_0)\); ou seja, a
densidade da distribuição de \(X_t\) dado \(X_0 = x_0\), com esperança e variância, respectivamente
\begin{equation*}
m(t,x) \, = \, \mbox{E}_\theta(X_t|X_0=x_0) \, = \, \dfrac{\theta_1}{\theta_2}+\left(x_0-\dfrac{\theta_1}{\theta_2} \right)e^{-\theta_2 t}
\end{equation*}
e
\begin{equation*}
\nu(t,x) \, = \, \mbox{Var}_\theta(X_t|X_0=x_0) \, = \, \dfrac{\theta_3^2\big( 1-e^{-2\theta_2 t}\big)}{2\theta_2}\cdot
\end{equation*}
A função de covariância condicional é
\begin{equation*}
\mbox{Cov}(X_s,X_t|X_0=x_0) \, = \, \dfrac{\theta_3^2}{2\theta_2}e^{-\theta_2 (s+t)} \big( e^{2\theta_2(s∧ t)}-1\big),
\end{equation*}
e sua representação Wiener escalada e transformada no tempo é
\begin{equation*}
X_t \, = \, \dfrac{\theta_1}{\theta_2}+\left(x_0-\dfrac{\theta_1}{\theta_2} \right)e^{-\theta_2 t}+\dfrac{\theta_3}{\sqrt{2\theta_2}}W\big(e^{2\theta_2 t} -1 \big) e^{-\theta_2 t}\cdot
\end{equation*}
Exemplo de simulação da integral estocástica
Pode-se ver que para \(\theta_1 = 0\) a trajetória de \(X_t\) é essencialmente uma exponencial negativa perturbada pela integral estocástica. Uma
forma de simular trajetórias do processo de Ornstein-Uhlenbeck é, de fato, por meio da simulação da integral estocástica. Conforme
prometido na Seção I.9, agora mostramos como simular uma integral estocástica, mas o próximo capítulo cobrirá outras maneiras
diferentes e preferidas de simular caminhos do processo de Ornstein-Uhlenbeck e outros. O script a seguir essencialmente simula somas de Itô. O resultado é
mostrado na Figura a seguir.
> W <- BM()
> t <- time(W)
> N <- length(t)
> x <- 10
> theta <- 5
> sigma <- 3.5
> X <- numeric(N)
> X[1] <- x
> ito.sum <- c(0, sapply(2:N, function(x) { exp(- theta*(t[x]-t[x-1]))*(W[x]-W[x-1])} ) )
> X <- sapply(1:N, function(x) {X[1]*exp(-theta*t[x]) + sum(ito.sum[1:x])} )
> X <- ts(X, start = start(W), deltat = deltat(W))
> plot(X, main =" Processo Ornstein - Uhlenbeck ", xlab = "Tempo")
> grid()
Figura I.10: Caminho simulado do processo de Ornstein-Uhlenbeck \(\mbox{d}X_t = -\theta X_t + \sigma \mbox{d}W_t\) com \(X_0 = 10\),
\(\theta= 5\) e \(\sigma= 3.5\).
I.13.2 O modelo de movimento Black-Scholes-Merton ou Browniano geométrico
Apresentamos a derivação do movimento Browniano geométrico na Seção I.7; portanto, aqui apenas relembramos os fatos básicos. Este processo
é algumas vezes chamado de modelo Black-Scholes-Merton após sua introduçãão no contexto financeiro para modelar preços de ativos, ver Black, F. &
Scholes, M.S. (1973) e Merton, R.C. (1973).
O processo é a solução para a equação diferencial estocástica
\begin{equation*}
\mbox{d}X_t \, = \, \theta_1 X_t \mbox{d}t + \theta_2 X_t \mbox{d}W_t, \qquad X_0=x_0,
\end{equation*}
com \(\theta_2> 0\). O parâmetro \(\theta_1\) é interpretado como a taxa de juros constante e \(\theta_2\) como a volatilidade das atividades de risco. A
solução explícita é
\begin{equation*}
X_t \, = \, x_0 \exp\left( \Big(\theta_1-\frac{1}{2}\theta_2^2\Big)t+\theta_2 W_t\right)\cdot
\end{equation*}
A função de densidade condicional é log-normal com esperança e variância de sua transformação logarítmica, isto é,
a esperança logarítmica e a variância logarítmica, dada por
\begin{equation*}
\mu \, = \, \log(x_0)+\Big(\theta_1-\frac{1}{2}\theta_2^2\Big)t, \qquad \sigma^2=\theta_2^2 t,
\end{equation*}
com esperança e variância
\begin{array}{rcl}
m(t,x_0) & = & e^{\mu+\frac{1}{2}\sigma^2} \, = \, x_0 e^{\theta_1 t}, \\
\nu(t,x_0) & = & e^{2\mu+\sigma^2}\Big( e^{\sigma^2} -1\Big) \, = \, x_0^2 e^{2\theta_1 t}\Big(e^{\theta_2^2 t}-1 \Big)\cdot
\end{array}
Portanto
\begin{equation*}
p_\theta(t,y|x_0) \, = \, \dfrac{1}{y\sigma\sqrt{2\pi t}}\exp\left(-\dfrac{(\log(y)-\mu)^2}{2\sigma^2} \right) \, = \,
\dfrac{1}{y\theta_2\sqrt{2\pi t}}\exp\left(-\dfrac{\big(\log(y)-(\log(x_0)+(\theta_1-\frac{1}{2}\theta_2^2)t )\big)^2}{2\theta_2^2 t} \right)\cdot
\end{equation*}
I.13.3 O modelo Cox-Ingersoll-Ross
Outra família interessante de modelos paramétricos é a do processo Cox-Ingersoll-Ross. Este modelo foi introduzido por Feller como um modelo para o
crescimento populacional, ver Feller, W. (1951a) e Feller, W. (1951b) e se tornou bastante popular nas finanças depois que Cox, J.C., Ingersoll, J.E. amp; Ross, S.A. (1985)
o propuseram para modelar taxas de juros de curto prazo. Foi recentemente adotado para modelar a emissão de oacute;xido nitroso do solo por Pedersen, A.R. (2000) e para
modelar a variação da taxa evolutiva entre locais em evolução Lepage, T., Law, S., Tupper, P. & Bryant, D. (2006).
O processo CIR é a solução para a equação diferencial estocástica
\begin{equation*}
\mbox{d}X_t \, = \, (\theta_1-\theta_2 X_t)\mbox{d}t+\theta_3 \sqrt{X_t} \mbox{d}W_t, \qquad X_0 = x_0>0,
\end{equation*}
às vezes parametrizado como
\begin{equation*}
\mbox{d}X_t \, = \, \theta(\beta- X_t)\mbox{d}t+\sigma \sqrt{X_t} \mbox{d}W_t, \qquad X_0 = x_0>0,
\end{equation*}
onde \(\theta_1,\theta_2,\theta_3\in\mathbb{R}_+\).
Se \(2\theta_1> \theta_3^2\), o processo é estritamente positivo, caso contrário, é não negativo, o que significa que pode chegar ao estado 0. Claro, o
último caso não é admitido em finanças quando o processo CIR é usado para modelar taxas de juros. A equa&ccedul;ão diferencial estocástica
acima tem a solução explícita
\begin{equation*}
X_t \, = \, \Big( X_0-\frac{\theta_1}{\theta_2}\Big)e^{-\theta_2 t}+\theta_3 e^{-\theta_2 t} \int_0^t e^{\theta_2 u}\sqrt{X_u}\mbox{d}W_t\cdot
\end{equation*}
A distribuição condicional
Na hipótese \(2\theta_1> \theta_3^2\), o processo também é estacionário. Além disso, a densidade de transição condicional existe de forma
explícita. O processo \(Y_t = 2cX_t\), com \(c = 2\theta_2/(\theta^2_3 (1 − e^{−\theta_2 t}))\), tem uma distribuição condicional \(Y_t | Y_0 = y_0\), que segue
a lei da distribuição não central qui-quadrado com \(\nu= 4\theta_1/\theta^2_3\) graus de liberdade e parâmetro de não centralidade \(y_0e^{−\theta_2 t}\).
A densidade de transição do processo original, ou seja, a distribuição de \(X_t | X_0 = x_0\) pode ser obtida a partir da distribuição de
\(Y_t | Y_0 = y_0\), e o resultado é
\begin{equation*}
p_\theta(t,y|x_0) \, = \, c e^{-(u+\nu)}\Big(\frac{u}{\nu}\Big)^{q/2}\mbox{I}_q\big(2\sqrt{u\nu}\big),
\end{equation*}
com \(u=cx_0 e^{-\theta_2 t}\), \(\nu=cy\), \(q=2\theta_1/\theta_3^2-1\), onde \(\mbox{I}q(\cdot)\) é a função de Bessel modificada do primeiro tipo de ordem \(q\) ver,
por exemplo, Abramowitz, M. & Stegun, I.A. (1964)
\begin{equation*}
\mbox{I}_q(x) \, = \, \sum_{k=0}^\infty \Big( \frac{x}{2}\Big)^{2k+q} \dfrac{1}{k! \Gamma(k+q+1)}, \qquad x\in\mathbb{R},
\end{equation*}
e \(\Gamma(\cdot)\) a função gama, ou seja, \(\displaystyle\Gamma(z=\int_0^\infty x^{z-1}e^{-z}\mbox{d}x\), \(z\in\mathbb{R}_+\). Essas derivações podem ser encontradas,
por exemplo, em Feller, W. (1951a).
Comportamento da distribuição condicional
Do ponto de vista da inferência de verossimilhança, deve-se notar que, mesmo que a distribuição qui-quadrada não central seja uma distribuição de probabilidade
especial, mas bem conhecida, seu cálculo real não é uma tarefa fácil. Na verdade, quando \(t\to 0\), tanto \(u\) quanto \(\nu\) explodem, o que significa que quando a distribuição
precisa ser calculada para argumentos muito grandes, isso implica na avaliação da distribuição qui-quadrada na cauda direita. O contrário também é verdade. Se \(t\to\infty\),
\(u\to 0\) e \(u\to 2\theta_2 x/\theta^2_3\), quando a cauda esquerda da distribuição está interessada nos cálculos ver, por exemplo, Dyrting, S. (2004).
Sendo que a distribuição qui-quadrada é baseada na função de Bessel modificada do primeiro tipo \(\mbox{I}_q(\cdot)\), o problema está essencialmente na avaliação de
\(\mbox{I}_q(\cdot)\) para argumentos muito pequenos e grandes. Discutiremos a implementação numérica da densidade CIR posteriormente na Seção II.3.2.
Para o processo Cox-Ingersoll-Ross, a esperança da densidade condicional é a do processo Ornstein-Uhlenbeck
\begin{equation*}
m(t,x_0) \, = \, \dfrac{\theta_1}{\theta_2}+\Big( x-0-\dfrac{\theta_1}{\theta_2}\Big)e^{-\theta_2 t}
\end{equation*}
e a variância é
\begin{equation*}
\nu(t,x_0) \, = \, x_0\dfrac{\theta_3^2\big(e^{-\theta_2 t}-e^{-2\theta_2 t}\big)}{\theta_2}+\dfrac{\theta_1\theta_3^2\big(1-e^{-2\theta_2 t}\big)}{2\theta_2^2}\cdot
\end{equation*}
A função de covariância é dada por
\begin{equation*}
\mbox{Cov}(X_s,X_t) \, = \, x_0\dfrac{\theta_3^2}{\theta_2}\Big(e^{-\theta_2 t}-e^{-\theta_2 (s+t)}\Big)+\dfrac{\theta_1\theta_3^2\big(e^{-\theta_2 (t-s)}-e^{-\theta_2 (t+s)}\big)}{2\theta_2^2}\cdot
\end{equation*}
A lei estacionária
A distribuição estacionária do processo CIR é uma lei Gama com parâmetro de forma \(2\theta_1/\theta^2_3\) e parâmetro
de escala \(\theta^2_3/2\theta_2\). Portanto, a lei estacionária tem média igual a \(\theta_1/\theta_2\) e variância \(\theta_1\theta^2_3/2\theta_2^2\).
A função de covariância no caso estacionário é dada por
\begin{equation*}
\mbox{Cov}(X_s,X_t) \, = \, \dfrac{\theta_1\theta_3^2}{2\theta_2^2}e^{-\theta_2 (t-s)}\cdot
\end{equation*}
I.13.4 A família de modelos Chan-Karolyi-Longstaff-Sanders
A família de modelos Chan, K.C., Karolyi, G.A., Longstaff, F.A. & Sanders, A.B. (1992), chamados de modelos Chan-Karolyi-Longstaff-Sanders ou CKLS é uma classe de equações
diferenciais estocásticas paramétricas amplamente utilizadas em muitas aplicações financeiras, em particular para modelar taxas de juros ou preços de ativos.
O processo CKLS resolve a equação diferencial estocástica
\begin{equation*}
\mbox{d}X_t \, = \, (\theta_1+\theta_2 X_t)\mbox{d}t + \theta_3 X_t^{\theta_4}\mbox{d}W_t\cdot
\end{equation*}
Este modelo CKLS é mais uma extensão do modelo Cox-Ingersoll-Ross e, portanto, incorpora todos os modelos anteriores. A Tabela I.4 apresenta alguns casos. Este modelo
não admite uma densidade de transição explícita, a menos que \(\theta_1 = 0\) ou \(\theta_4 = 1/2\). Aceita valores em \((0, +\infty)\) se \(\theta_1,\theta_2> 0\) e
\(\theta_4> 1/2\). Em todos os casos, \(\theta_3\) é considerado positivo.
Tabela I.4. A família de processos CKLS e seus elementos embutidos sob diferentes especificações paramétricas. Em todos os casos, \(\theta_3> 0\).
\(\theta_1\)
\(\theta_2\)
\(\theta_4\)
Ver
Merton
qualquer
0
0
Devroye, L. (1986)
Vasicek ou Ornstein-Uhlenbeck
qualquer
qualquer
0
Vasicek, O. (1977)
CIR ou processo raiz quadrada
qualquer
qualquer
1/2
Cox, J.C., Ingersoll, J.E., Ross, S.A. (1985)
Dothan
0
0
1
Dothan, U.L. (1978)
BM geométrico
0
qualquer
1
Black, F. & Scholes, M.S. (1973)
Brennan and Schwartz
qualquer
qualquer
1
Brennan, M.J. &, Schwartz, E. (1980)
CIR VR
0
0
3/2
Cox, J.C., Ingersoll, J.E. & Ross, S.A. (1980)
CEV
0
qualquer
qualquer
Cox, J.C. (1996)
I.13.5 O modelo Cox-Ingersoll-Ross modificado e os processos hiperbólicos
Outro exemplo de uma aplicação da transformada de Lamperti ver, por exemplo, Comte, F., Genon-Catalot, V. & Rozenholc, Y. (2007) é a solução do processo Cox-Ingersoll-Ross
modificada para
\begin{equation*}
\mbox{d}X_t \, = \, -\theta_1 X_t \mbox{d}t + \theta_2\sqrt{1+X_t^2}\mbox{d}W_t,
\end{equation*}
com \(\theta_1+\theta_2^2/2>0\), isso é necessário para tornar o processo recorrente positivo. Este processo possui uma distribuição estacionária cuja
densidade \(\pi(\cdot)\) é proporcional a
\begin{equation*}
\pi(x) \, ∝ \, \dfrac{1}{(1+x^2)^{1+\theta_1/\theta_2^2}}\cdot
\end{equation*}
Escolhendo \(\nu=1+\theta_1/\theta_2^2\), então \(X_t\sim t(\nu)/\sqrt{\nu}\), onde \(t\) representa a distribuição
\(t\)-Student com \(\nu\) graus de liberdade. Aplicando a transformada de Lamperti
\begin{equation*}
F(x) \, = \, \int_0^x \dfrac{1}{\theta_2 \sqrt{1+u^2}}\mbox{d}u \, = \, \dfrac{\mbox{arcsinh}(x)}{\theta_2} \, = \,
\dfrac{1}{\theta_2}\log\Big( x+\sqrt{1+x^2}\Big),
\end{equation*}
da equação diferencial estocástica acima, temos que \(Y_t=F(X_t)\) satisfaz a equação diferencial estocástica
\begin{equation*}
\mbox{d}F(X_t) \, = \, -(\theta_1/\theta_2+\theta_2/2)\dfrac{X_t}{\sqrt{1+X_t^2}}\mbox{d}t+\mbox{d}W_t,
\end{equation*}
que pode ser rescrita em termos do processo \(Y_t\) como
\begin{equation*}
\mbox{d}Y_t \, = \, -(\theta_1/\theta_2+\theta_2/2)\tanh(\theta_2 Y_t)+\mbox{d}W_t,
\end{equation*}
com \(Y_0=F(X_0)\).
I.13.6 Os processos hiperbólicos
O processo \(X_t\) satisfazendo
\begin{equation*}
\mbox{d}X_t \, = \, \dfrac{\theta X_t}{\sqrt{1+X_t^2}}\mbox{d}t +\mbox{d}W_t,
\end{equation*}
com \(\theta>0\) é chamado de processo hiperbólico.
Este processo é um caso especial da difusão hiperbólica geral introduzida em Barndorff-Nielsen, O.E. (1978) e solução de
\begin{equation*}
\mbox{d}X_t \, = \, \dfrac{\sigma^2}{2}\left( \beta-\gamma\dfrac{X_t}{\sqrt{\delta^2+(X_t-\mu)^2}}\right)\mbox{d}t+\sigma\mbox{d}W_t\cdot
\end{equation*}
Sua densidade invariante é
\begin{equation*}
\pi(x) \, = \, \dfrac{\sqrt{\gamma^2-\beta^2}}{2\gamma\delta K_1\big( \delta\sqrt{\gamma^2-\beta^2}\big)}
\exp\left(-\gamma\sqrt{\delta^2+(x-\mu)^2}+\beta(x-\mu) \right),
\end{equation*}
onde \(K_\nu(\cdot)\) é a função de Bessel modificada do segundo tipo de índice \(\nu\) ver, por exemplo, Abramowitz, M., Stegun, I.A. (1964).
Os parâmetros \(\gamma > 0\) e \(0\leq |\beta|< \gamma\) determinam a forma da distribuição e \(\delta > 0\) e \(\mu\) são, respectivamente,
os parâmetros de escala e locação da distribuição. Este processo foi usado para modelar log-retornos dos preços dos ativos nos
mercados de ações em Eberlein, E. & Keller, U. (1995) e Bibby, B.M. & Sørensen, M. (1997).
Uma generalização adicional do processo hiperbólico é a solução para a equação diferencial estocástica
\begin{equation*}
\mbox{d}X_t \, = \, -\dfrac{\alpha X_t}{\sqrt{1+X_t^2}}\mbox{d}t+\dfrac{\beta+X_t^2}{1+X_t^2}\mbox{d}W_t,
\end{equation*}
com \(X_0=0\), \(\alpha>0\) e \(\beta\geq 1\). Este processo, introduzido em Masuda, H. (2006), também é ergódico.
I.13.7 O modelo de reversão média não linear Aït-Sahalia
Este modelo satisfaz a equação diferencial estocástica não linear
\begin{equation*}
\mbox{d}X_t \, = \, \big(\alpha_{-1}X_t^{-1}+\alpha_0+\alpha_1 X_t + \alpha_2 X_t^2 \big)\mbox{d}t+\beta_1 X_t^p \mbox{d}W_t\cdot
\end{equation*}
Em geral, não há resultados distribucionais exatos, embora, como explicado no Capítulo III, as densidades de transição aproximadas
possam ser obtidas via expansão polinomial de Hermite. Este modelo foi proposto por Aït-Sahalia para modelar as taxas de juros em Aït-Sahaia, Y. & Lo, W. (1998)
e Aït-Sahaia, Y. (1999). O mesmo autor Aït-Sahalia, Y. (1996) propôs uma nova generalização que inclui mais estrutura no coeficiente de difusão.
A segundo modelo é da forma
\begin{equation*}
\mbox{d}X_t \, = \, \big(\alpha_{-1}X_t^{-1}+\alpha_0+\alpha_1 X_t + \alpha_2 X_t^2 \big)\mbox{d}t+\sqrt{\beta_0+\beta_1 X_t \beta_2 X_t^{\beta_3}} \mbox{d}W_t\cdot
\end{equation*}
Algumas restrições naturais nos parâmetros são necessárias para ter uma especificação significativa do modelo. Além disso, a
markovianidade é concedida apenas sob restrições adicionais. É claro que o modelo CKLS é apenas um caso particular do modelo Aïıt-Sahalia.
I.13.8 O modelo de potencial de poço duplo
Este modelo é interessante pelo fato de sua densidade ser bimodal. O processo satisfaz a equação diferencial estocástica
\begin{equation*}
\mbox{d}X_t \, = \, \big( X_t-X_t^3\big)\mbox{d}t +\mbox{d}W_t\cdot
\end{equation*}
Este modelo é desafiador no sentido de que a aproximação de Euler padrão que discutiremos na Seção II.1 não poderia funcionar devido
à alta não linearidade da equação diferencial estocástica e à alta não gaussianidade de suas distribuições dimensionais finitas.
I.13.9 O processo de difusão de Jacobi
O processo de difusão de Jacobi é a solução para a equação diferencial estocástica
\begin{equation*}
\mbox{d}X_t \, = \, -\theta\left( X_t-\dfrac{1}{2}\right)\mbox{d}t+\sqrt{\theta X_t(1-X_t)}\mbox{d}W_t,
\end{equation*}
para \(\theta > 0\). Este processo tem uma distribuição invariante que é uniforme em (0,1). O peculiar é que, dada qualquer função
de distribuição \(F\) duas vezes diferenciável, a difusão transformada \(Y_t = F^{−1}(X_t)\) tem uma densidade
invariante \(\pi(\cdot)\) que é a densidade de \(F\); ou seja, \(\pi= F^T\).
I.13.10 Modelo de Ahn & Gao ou inverso do modelo de raiz quadrada de Feller
Outra generalização é o modelo proposto em Ahn, D.H. & Gao, B. (1999), que é uma transformação adequada do modelo de Cox-Ingersoll-Ross.
O processo é a solução para a equação diferencial estocástica
\begin{equation*}
\mbox{d}X_t \, = \, X_t\big(\theta_1 - (\theta_3^3-\theta_1\theta_2)X_t\big)\mbox{d}t+\theta_3 X_t^{\frac{3}{2}}\mbox{d}W_t\cdot
\end{equation*}
A distribuição condicional deste processo está relacionada ao modelo de Cox-Ingersoll-Ross como
\begin{equation*}
p_\theta(t,y|x_0) \, = \, \dfrac{1}{y^2}p_\theta^\mbox{CII}(t,1/y|1/x_0),
\end{equation*}
onde \(p_\theta^\mbox{CII}(\cdot|\cdot)\) é a densidade condicional descrita anteriormente.
I.13.11 Processo radial Ornstein-Uhlenbeck
O processo radial de Ornstein-Uhlenbeck é a solução para a equação diferencial estocástica
\begin{equation*}
\mbox{d}X_t \, = \, \big( \theta X_t^{-1}-X_t\big)\mbox{d}t+\mbox{d}W_t,
\end{equation*}
para \(\theta>0\).
Este modelo é um caso especial daquele descrito na Seção I.13.7, mas ainda interessante porque alguns resultados de distribuição
são conhecidos. Em particular, a distribuição condicional tem a forma explícita
\begin{equation*}
p_\theta(t,y|x_0) \, = \, \dfrac{\Big(\dfrac{y}{x}\Big)^\theta \sqrt{xy}e^{-y^2+\big(\theta+\frac{1}{2}\big)t}}{\sinh(t)}
\exp\left( -\dfrac{x^2+y^2}{e^{\theta t}-1}\right)\mbox{I}_{\theta-\frac{1}{2}}\left(\frac{xy}{\sinh(t)}\right),
\end{equation*}
onde \(\mbox{I}_\nu\) representa a função de Bessel modificada de ordem \(\nu\).
I.13.12 Difusões de Pearson
Uma classe que generaliza ainda mais os processos de Ornstein-Uhlenbeck e Cox-Ingersoll-Ross é a classe de difusão de Pearson. Esta classe de modelos e suas
propriedades estatísticas foram analisadas em Forman, J.L. & Sørensen, M. (2006) e seu nome se deve ao fato de que, quando existe uma solução
estacionária para este modelo, sua densidade invariante pertence ao sistema Pearson (Pearson, K., 1895). O sistema Pearson permite uma grande variedade de distribuições
que podem assumir valores positivos e/ou negativos e podem ser limitadas, simétricas ou enviesadas e de cauda pesada ou leve. Em particular, a distribuição de
Pearson tipo IV é um tipo de distribuição \(t\) enviesada que parece se ajustar muito bem a séries financeiras. As difusões de Pearson também
foram estudadas apenas do ponto de vista probabilístico em Bibby, B.M., Skovgaard, I.M. & Sørensen, M. (2005) e Wong, E. (1964).
Usando a parametrização em Forman, J.L. & Sørensen, M. (2006), essas difusões resolvem a seguinte equação diferencial estocástica
\begin{equation*}
\mbox{d}X_t \, = \, -\theta(X_t-\mu)\mbox{d}t+\sqrt{2\theta(a X_t^2+b X_t+c )}\mbox{d}W_t,
\end{equation*}
com \(\theta> 0\) e \(a\),\(b\) e \(c\) de modo que o coeficiente de difusão seja bem definido, ou seja, a raiz quadrada pode ser extraída; para todos os valores do espaço de
estados de \(X_t\).
As difusões de Pearson são caracterizadas como tendo uma inclinação linear reversa média e um coeficiente de difusão quadrado que é
um polinômio de segunda ordem do estado do processo. Uma outra propriedade interessante desses modelos é que eles são fechados sob translação e
transformações de escala: se \(X_t\) é uma difusão ergódica de Pearson, então também será \(\widetilde{X}_t = \gamma X_t + \delta\) uma difusão
de Pearson que satisfaz a equação diferencial estocástica acima com os parâmetros \(\widetilde{a} = a\), \(\widetilde{b} = b\gamma - 2a\delta\),
\(\widetilde{c} = c\gamma^2 - b\gamma\delta + a\delta^2\), \(\widetilde{\theta} = \theta\) e \(\widetilde{μ} = \gamma\mu +\delta\).
O parâmetro \(\gamma\) também pode ser negativo e, nesse caso, o espaço de estado de \(\widetilde{X}_t\) mudará seu sinal. A escala e as medidas de
velocidade desses processos têm as formas
\begin{equation*}
s(x) \, = \, \exp\left( \int_{x_0}^x \dfrac{u-\mu}{au^2+bu+c}\right)
\end{equation*}
e
\begin{equation*}
m(x) \, = \, \dfrac{1}{2\theta s(x)(ax^2+bx+c)},
\end{equation*}
onde \(x_0\) é algum valor tal que \(ax_0^2 + bx_0 + c> 0\). Seja \((\ell, r)\) um intervalo tal que para \(x\in (\ell, r)\) temos \(ax^2 + bx + c> 0\). Como visto antes, uma
única distribuição ergódica invariante com valores em \((\ell, r)\) existe apenas se
\begin{equation*}
\int_{x_0}^r s(s)\mbox{d}x = \infty, \quad \int_\ell^{x_0} s(x)\mbox{d}x = \infty \qquad \mbox{ e } \qquad
M = \int_\ell^r m(x)\mbox{d}x < \infty\cdot
\end{equation*}
Nesse caso, a distribuição invariante tem densidade \(m(x)/M\). A relação entre isso e a família de distribuições de Pearson
é que \(m(x)\) resolve a seguinte equação diferencial que caracteriza o sistema de distribuições de Pearson:
\begin{equation*}
\dfrac{\mbox{d} m(x)}{\mbox{d}x} \, = \, \dfrac{(2a+1)x-\mu+b}{ax^2+bx+c}m(x)\cdot
\end{equation*}
Alguns casos interessantes estão incluídos nesta família. Para uma descrição abrangente de todos os casos, consulte Forman, J.L. & Sørensen, M. (2006). Em particular:
Quando o coeficiente de difusão \(\sigma^2(x) = 2\theta\), recuperamos o processo Ornstein-Uhlenbeck.
Para \(\sigma^2(x) = 2\theta x\) e \(0 < \mu \leq 1\), obtemos o processo de Cox-Ingersoll-Ross, sob algumas condições de reflexão adicionais e se
\(\mu > 1\) a distribuição invariante é uma lei Gama com parâmetro de escala 1 e parâmetro de forma \(\mu\).
Para \(a> 0\) e \(\sigma^2(x) = 2\theta a (x^2 + 1)\), a distribuição invariante sempre existe na linha real e para \(\mu = 0\) a distribuição invariante
é uma distribuição \(t\) escalonada com \(\nu= 1 + a^{−1}\) graus de liberdade e parâmetro de escala \(\nu^{−1/2}\), enquanto para \(\mu \neq 0\)
a distribuição é uma forma de distribuição \(t\) enviesada que é chamada de distribuição tipo IV de Pearson.
Para \(a> 0\), \(\mu> 0\) e \(\sigma^2(x) = 2\theta ax^2\), a distribuição é definida na meia linha positiva e é uma distribuição Gamma inversa com
parâmetro de forma \(1 + a^{−1}\) e parâmetro de escala \(a/\mu\).
Para \(a> 0\), \(\mu > a\) e \(\sigma^2(x) = 2\theta ax(x + 1)\), a distribuição invariante é a distribuição \(F\) escalonada com
\(2\mu/a\) e \(2/a+2\) graus de liberdade e parâmetro de escala \(\mu/(1 + a)\). Para \(0 < \mu < 1\), algumas condições de reflexão nos limites
também são necessárias.
Se \(a < 0\) e \(\mu> 0\) são tais que \(\min(\mu, 1 − \mu)\geq −a\) e \(\sigma^2(x) = 2\theta ax (x − 1)\), a distribuição invariante existe no
intervalo (0,1) e é uma distribuição Beta com parâmetros \(−\mu/a\) e \((\mu - 1)/a\). A solução da difusão de Jacobi
\begin{equation*}
\mbox{d}X_t \, = \, -\theta\left( X_t-\dfrac{1}{2}\right)\mbox{d}t+\sqrt{\theta X_t(1-X_t)}\mbox{d}W_t,
\end{equation*}
para \(\theta > 0\) é um caso particular dessa classe de difusão de Pearson, que na verdade é chamada de difusão geral de Jacobi. Se \(F(x) = e^x/(1 + e^x)\)
é a distribuição logística, o processo transformado \(Y_t = F^{−1}(X_t)\) com \(F^{−1}(y) = \log(y/(1−y))\) tem densidade invariante, que é a
distribuição logística generalizada apresentada em Barndorff-Nielsen, O.E., Kent, J. & Sørensen, M. (1982),
\begin{equation*}
\pi(x) \, = \, \dfrac{e^{\alpha x}}{(1+e^x)^{\alpha+\beta}B(\alpha,\beta)},
\end{equation*}
com \(\alpha = (\mu - 1)/a\), \(\beta = \mu/a\) e \(B(\cdot,\cdot)\) a função Beta.
Quando o segundo momento da distribuição existe, a função de autocorrelação assume a forma
\begin{equation*}
\mbox{Corr}(X_s,X_{s+t}) \, = \, e^{-\theta t}\cdot
\end{equation*}
Os momentos \(\mbox{E}(|X_t|^k)\) existem se, e somente se, \(a < (k - 1)^{−1}\). Portanto, se \(a\leq 0\), todos os momentos existem, enquanto para \(a> 0\) apenas os momentos
até a ordem \(k < a^{−1} + 1\) existem. Se \(\mbox{E}(X^{2n}_t) < \infty\), então os momentos satisfazem a fórmula recorrente
\begin{equation*}
\mbox{E}(X_{t}^n) \, = \, \dfrac{1}{a_n}\big(b_n\mbox{E}(X_n^{n-1})+c_n \mbox{E}(X_t^{n-2})\big),
\end{equation*}
onde \(a_n=n\big(1-(n-1)a\big)\theta\), \(b_n=n\big( \mu+(n-1)b\big)\theta\), \(c_n=n\big(n-1\big)c\theta\) para \(n=0,1,2,\cdots\) com condição inicial
\(\mbox{E}(X_t^0)=1\) e \(\mbox{E}(X_t)=\mu\).
Finalmente, para esses processos, é possível derivar a autofunção do operador infinitesimal das difusões que são úteis para
construir funções de estimação, como será explicado na Seção III.5.6.
I.13.13 Outra classificação de sistemas estocásticos lineares
Nas ciências sociais, a quantidade de interesse é freqüentemente a distribuição estacionária do processo estocástico que descreve o
equilíbrio de algumas dinâmicas. Na maioria dos casos ver, por exemplo, Bartholomew, D.J. (1973) e Cobb, L. (1978), o coeficiente de difusão é
escolhido para modelar algum tipo de variabilidade relacionada ao estado do processo. Para essas disciplinas, o interesse está na forma das distribuições
estacionárias e nos índices estatísticos a elas relacionados: média, moda, etc.
As equações diferenciais estocásticas usadas para modelar processos sociais em Cobb, L. (1981) geralmente têm uma inclinação linear
da forma \(b(x) = r (\theta- x)\) com \(r> 0\). Por esta razão, os modelos são chamados de modelos de feedback linear. O coeficiente de difusão \(\sigma^2(x)\)
pode ser constante, linearmente dependendo de \(x\) ou do tipo polinomial, levando, respectivamente, a distribuições estacionárias Gaussiana, Gama ou Beta.
Elas correspondem à seguinte família de distribuições de Pearson: Gama = tipo III, Beta = tipo I e Gaussiana = limite do tipo I, III, IV, V ou VI.
Claro, todos esses modelos se enquadram em um ou mais dos as classes anteriores, mas coletamos algumas de suas propriedades a seguir.
Modelo Tipo N
Para este modelo, temos:
coeficiente de inclinação: \(b(x) = r (\theta- x)\), \(r> 0\).
coeficiente de difusão: \(\sigma^2(x)=\epsilon\), \(\epsilon>0\).
equação diferencial estocástica: \(\mbox{d}X_t=r (\theta- X_t)\mbox{d}t+\sqrt{\epsilon}\mbox{d}W_t\).
distribuição estacionária: \(\pi(x)=\dfrac{1}{2\pi\delta}\exp\left(-\dfrac{(x-\theta)^2}{2\delta}\right)\), \(\delta=\epsilon/r\).
estatísticas: média=\(\theta\), moda=\(\theta\), variância= \(\delta\).
Modelo Tipo G
Para este modelo, temos:
coeficiente de inclinação: \(b(x) = r (\theta- x)\), \(r> 0\).
coeficiente de difusão: \(\sigma^2(x)=\epsilon x\), \(\epsilon>0\).
equação diferencial estocástica: \(\mbox{d}X_t=r (\theta- X_t)\mbox{d}t+\sqrt{\epsilon X_t}\mbox{d}W_t\).
distribuição estacionária: \(\pi(x)=\Big(\dfrac{x}{\delta}\Big)^{-1+\frac{\theta}{\delta}}\exp\left(-\dfrac{x}{\delta}\right)\Gamma^{-1}\big(\frac{\theta}{\delta}\big)\), \(\delta=\epsilon/r\).
estatísticas: média=\(\theta\), moda=\(\theta-\delta\), variância= \(\delta\theta\).
Modelo Tipo B
Para este modelo, temos:
coeficiente de inclinação: \(b(x) = r (\theta- x)\), \(r> 0\).
coeficiente de difusão: \(\sigma^2(x)=\epsilon x(1-x)\), \(\epsilon>0\).
equação diferencial estocástica: \(\mbox{d}X_t=r (\theta- X_t)\mbox{d}t+\sqrt{\epsilon X_t(1-X_t)}\mbox{d}W_t\).
distribuição estacionária: \(\pi(x)=\dfrac{\Gamma\big(\frac{1}{\delta}\big)}{\Gamma\big(\frac{\theta}{\delta}\big)\Gamma\big(\frac{1-\theta}{\delta}\big)}x^{-1+\frac{\theta}{\delta}}(1-x)^{-1+\frac{1-\theta}{\delta}} \), \(\delta=\epsilon/r\).
estatísticas: média=\(\theta\), moda=\(\dfrac{\theta-\delta}{1-2\delta}\), variância= \(\dfrac{\theta(1-\theta)}{1+\delta}\).
O modelo Tipo B é usado como um modelo de polarização política, onde \(X_t\) é a persuasão política de um sujeito. A persuasão é
medida no eixo hipotético da convicção, digamos \(X_t = 0\) se for liberal e \(X_t = 1\) caso seja conservador. A escolha de \(\sigma(x)\) neste modelo é motivada pelo
fato de que as pessoas que sustentam pontos de vista extremos estão muito menos sujeitas a flutuações aleatórias do que aquelas próximas ao centro. A tendência
explica o movimento em direção& à persuasão média de toda a população. A proporção controla a extensão da polarização.
Se \(\mu\) é a média e \(\sigma^2\) a variância, o modelo pode ser reparametrizado de acordo e \(\delta= \sigma^2/(\mu (1 - \mu) -\sigma^2)\).
I.13.14 Um modelo de epidemia
A teoria matemática da epidemiologia, veja Bailey, N.T.J. (1957), contém muitos tipos de modelos, tanto determinísticos quanto estocásticos, que foram adaptados
e expandidos nas ciências sociais, veja Bartholomew, D.J. (1973). Apenas mencionamos aqui um modelo epidêmico simples.
Seja \(X_t\) a fração de uma população que tem uma doença infecciosa no tempo \(t\). Se a doença não confere imunidade, por exemplo, gonorreia,
a taxa de mudança geralmente segue a equação diferencial não estocástica
\begin{equation*}
\mbox{d}x_t \, = \, a x_t(1-x_t)\mbox{d}t - b x_t\mbox{d}t + c(1-x_t)\mbox{d}t,
\end{equation*}
onde \(a> 0\) é a taxa de transmissão de pessoa a pessoa, \(b> 0\) é a taxa de recuperação ou esquecimento e \(c> 0\) é a taxa de transmissão
de uma fonte externa.
A transformação do modelo determinístico em estocástico motiva a escolha do coeficiente de difusão como nos modelos Tipo B. Portanto, a equação
diferencial estocástica correspondente é
\begin{equation*}
\mbox{d}X_t \, = \, \mu(X_t)\mbox{d}t - \sigma(X_t)\mbox{d}W_t,
\end{equation*}
onde
\begin{array}{rcl}
\mu(x) & = & ax(1-x)-bx+c(1-x), \\
\sigma^2(x) & = & \epsilon x(1-x), \quad \epsilon>0\cdot
\end{array}
Neste caso, a densidade da distribuição estacionária assume a forma
\begin{equation*}
\pi(x) \, = \, \dfrac{M}{x(1-x)}\exp\left( \int_0^x \Big(\dfrac{a}{\epsilon}-\dfrac{b}{\epsilon(1-u))}+\dfrac{c}{\epsilon u} \Big)\mbox{d}u \right),
\end{equation*}
onde \(M\) é a constante de normalização sobre o espaço de estado [0,1].
Esta distribuição pode ser bimodal dependendo do número de soluções reais de \(d\pm \sqrt{d^2-(\epsilon-c)/a}\), onde \(d = (a − b − c + 2\epsilon)/2a\).
Quando há duas soluções reais positivas, menor é o limiar da epidemia e maior é a dimensão da epidemia. Este é um modelo de limite estocástico
quando \(0 < c <\epsilon\). É improvável que a epidemia aconteça se o modelo o número de pessoas infectadas na população, permanecer abaixo
do modo mais baixo. Quando o modelo está acima dele, o tamanho da epidemia gira em torno do segundo modo. Quando \(c>\epsilon\), alta taxa de infecção de fontes externas, a
epidemia está garantida.
I.13.15 O modelo estocástico de cúspide catastrófica
Ao contrário do que o nome sugere, a teoria da catástrofe tem pouco ou nada a ver com desastres, veja Poston, T. & Stewart, I.N. (1978); mas mais com a classificação de singularidades
não degeneradas, como mínimos, máximos ou pontos de sela e também singularidades degeneradas, por exemplo, quando a segunda derivada desaparece. Do ponto de vista dos sistemas dinâmicos,
a dinâmica de um modelo de catástrofe é geralmente escrita em termos de uma função potencial: o sistema se comporta como se estivesse se movendo em direção ao ponto de
menor potencial.
Se \(V(x)\) denota o potencial, a dinâmica é então \(\mbox{d}x/\mbox{d}t = -\partial V/\partial x\). A equação diferencial estocástica correspondente é da forma
\begin{equation*}
\mbox{d}X_t \, = \, -\dfrac{\partial V}{\partial x}(X_t)\mbox{d}t+\sqrt{\epsilon}\mbox{d}W_t,
\end{equation*}
com densidade estacionária dada por
\begin{equation*}
\pi(x) \, = \, M \exp\left( V(x)/\epsilon\right),
\end{equation*}
com \(M\) a constante de normalização.
Singularidades do sistema determinístico são as soluções de \(\partial V/\partial x = 0\) e o equilíbrio do sistema é estável ou instável de acordo
com se \(\partial^2 V/\partial x^2\) é positivo ou negativo, enquanto os pontos de catástrofe são aqueles valores de \(x\) para os quais \(\partial^2 V/\partial x^2=0\). O potencial \(V\) é
geralmente aproximado por meio de polinômios.
O modelo cúspide ou Zeeman, E.C. (1977) considera um polinômio de terceira ordem
\begin{equation*}
\dfrac{\mbox{d}x}{\mbox{d}t} \, = \, - (a_1 + a_2x + a_3x^2 + a_4x^3),
\end{equation*}
que geralmente é parametrizado na chamada forma padrão
\begin{equation*}
\mbox{d}X_t \, = \, r\big(\alpha+\beta(X_t-\lambda)-(X_t-\lambda)^3 \big)\mbox{d}t+\sqrt{\epsilon}\mbox{d}W_t,
\end{equation*}
onde \(\alpha\) e \(\beta\) são chamados de fatores normais e de divisão, respectivamente. A densidade estacionária tem a forma
\begin{equation*}
\pi(x) \, = \, M\exp\left( \dfrac{\alpha(x-\lambda)+\frac{1}{2}\beta(x-\lambda)^2-\frac{1}{4}(x-\lambda)^4}{\delta}\right), \qquad \delta=\dfrac{\epsilon}{r}\cdot
\end{equation*}
Os quatro parâmetros \((\alpha,\beta,\lambda,\delta)\) caracterizam a densidade da cúspide via discriminante de Cardan \(C = 27\alpha^2 - 4\beta^3\). Em particular,
de acordo com a terminologia de Zeeman:
Assimetria \(\alpha\): Se \(C < 0\), a densidade da cúspide é bimodal e \(\alpha\) é a altura relativa dos dois modos. Se \(C> 0\), a densidade da
cúspide é unimodal e \(\alpha\) mede a assimetria.
Bifurcação \(\beta\): Se \(C < 0\), então \(\beta\) determina a separação dos dois modos; se \(C> 0\), então \(\beta\)
mede a curtose.
Localização \(\lambda\): Os pontos de cúspide da catástrofe estão localizados em \(x = \lambda\) com \(\alpha = 0\) e \(\beta = 0\). O
movimento desloca a densidade da cúspide horizontalmente no eixo \(x\) sem alterar a forma.
Dispersão \(\delta\): O parâmetro determina a variação sobre os dois modos de uma densidade de cúspide bimodal como a variância
faz na lei de Gauss, mas não é um parâmetro de escala.
I.13.16 Famílias exponenciais de difusões
Famílias exponenciais de processos de difusão foram introduzidas em Sørensen, M. (2007) e são soluções para a equação
diferencial estocástica
\begin{equation*}
\mbox{d}X_t \, = \, \sum_{i=1}^p \beta_i b_i(X_t)\mbox{d}t +\lambda \nu(X_t)\mbox{d}W_t,
\end{equation*}
com \(\lambda>0\), \(\nu>0\) e \(b_i(\cdot)\) funções de tal forma que existe uma solução fraca única. Esses modelos não são
famílias exponenciais de processos estocásticos no sentido de Küchler, U. & Sørensen, M. (1997).
Utilizando a reparametrização \(\theta_i=\beta_i/\lambda^2\) e as funções
\begin{equation*}
T_i(x) \, = \, 2\int_{x_0}^x \dfrac{b_i(y)}{\nu^2(y)}\mbox{d}y,
\end{equation*}
para algum \(x_0\) no espaço de estados de \(X\), a medida de escala tem a seguinte representação
\begin{equation*}
s(x) \, = \, \exp\left( -\sum_{i=1}^p \theta_i T_i(x)\right)
\end{equation*}
e a medida de velocidade é
\begin{equation*}
m(x) \, = \, \dfrac{1}{\nu^2(x)}\exp\left( \sum_{i=1}^p \theta_i T_i(x)\right)\cdot
\end{equation*}
Se denotarmos por \(\phi(\theta)\) a constante de normalização
\begin{equation*}
\phi(\theta) \, = \, \int m(x)\mbox{d}x,
\end{equation*}
a distribuição invariável desta classe de modelos assume a forma canônica de uma família exponencial, ou seja,
\begin{equation*}
\pi(x) \, = \, \exp\left(\sum_{i=1}^p \theta_i T_i(x)-2\log\big( \nu(x)\big) -\phi(\theta) \right)\cdot
\end{equation*}
Esses modelos são ergódicos e, portanto, a densidade invariante \(\pi(x)\) existe sob condições adequadas nos
parâmetros \(\theta_i\), \(i = 1,\cdots, p\); ver Sørensen, M. (2007) para detalhes.
I.13.17 Difusões Gaussiana inversa generalizada
A família exponencial de difusões também engloba alguns modelos interessantes e peculiares como as difusões Gaussianas inversas
generalizadas que são soluções para a equação diferencial estocástica
\begin{equation*}
\mbox{d}X_t \, = \, \big(\beta_1 X_t^{2\alpha-1}-\beta_2 X_t^{2\beta}+\beta_3 X_t^{2(\alpha-1)} \big)\mbox{d}t+\lambda X_t^\alpha \mbox{d}W_t, \qquad X_0 >0\cdot
\end{equation*}
Com a reparametrização \(\theta_i=2\beta_i\lambda^{-2}\), \(i=1,2,3\), a medida da escala assume a forma
\begin{equation*}
s(x) \, = \, x^{-\theta_i}\exp\big( \theta_2 x +\theta_3 x^{-1}\big), \qquad x>0
\end{equation*}
e a medida de velocidade é
\begin{equation*}
m(x) \, = \, x^{\theta_1-2\alpha}\exp\big( -\theta_2 x -\theta_3 x^{-1}\big)\cdot
\end{equation*}
A densidade invariante, sob condições adequadas sobre os parâmetros, assume a forma da distribuição Gaussiana inversa generalizada
introduzida em Good, I.J. (1953), ver também Jørgensen, B. (1982) para uma análise estatística extensa.