Em geral, os parâmetros de um HMM são estimados usando o método de máxima verossimilhança; isto significa que se selecionam aqueles parâmetros
que maximizam a verossimilhança das observações dadas, condicionadas nos parâmetros. Infelizmente, em quase todos os casos, não éé possível
encontrar uma solução explícita para as estimativas de máxima verossimilhança de um HMM por meios analíticos, pois as equações
de verossimilhança têm uma estrutura altamente não linear.
Porém, como a log-verossimilhança pode ser avaliada rotineiramente, mesmo para seqüências muito longas de observações, é possível
realizar a estimativa de parâmetros nos HMMs por maximização numérica direta da log-verossimilhança. Esse método possui boas propriedades,
especialmente no que diz respeito ao tratamento de observações ausentes e à facilidade com que o software de um modelo específico pode ser modificado
para se ajustar a modelos alternativos e mais complexos.
Uma alternativa popular à maximização numérica direta, usada rotineiramente em aplicativos de processamento de fala, é o algoritmo Baum-Welch, um
exemplo do que mais tarde ficou conhecido como algoritmo EM (Baum et al., 1970). A seguir, apresentaremos as chamadas probabilidades de avanço (forward) e retrocesso (backward)
de um HMM, necessárias para o cálculo do algoritmo EM, mas também para a derivação de distribuições condicionais e a decodificação
dos estados subjacentes, como será mostrado no próximo capítulo. Em seguida, forneceremos uma breve visão geral do algoritmo EM. Por fim, nosso foco
principal será a introdução da maximização numérica da log-verossimilhança, juntamente com alguns problemas que podem ocorrer,
e sua implementação simples, mas flexível.
Como vimos na Seção II.3, a verossimilhança \(L_T\) de um HMM com base nas observações \(s_1,s_2,\cdots,s_T\) pode ser escrita como
\begin{equation}
L_T \, = \, P(S_1=s_1, \cdots, S_T=s_T) \, = \, \delta B_1\cdots B_T\pmb{1}^\top,
\end{equation}
onde
\begin{equation}
B_t \, = \, \Gamma P(s_t) \, = \, \begin{pmatrix} \gamma_{1,1} & \cdots & \gamma_{1,m} \\ \vdots & \ddots & \vdots \\ \gamma_{m,1} & \cdots & \gamma_{m,m} \end{pmatrix}
\begin{pmatrix} p_1(s_t) & \cdots & 0 \\ \vdots & \ddots & \vdots \\ 0 & \cdots & p_m(s_t) \end{pmatrix}\cdot
\end{equation}
Agora, lembre-se que no início da Seção II.1 introduzimos a notação para a história de um HMM \(\{S_t\}\) até o tempo \(t\), ou seja,
\(S^{(t)}\). A mesma notação pode ser usada para o histórico das observações e se obtém:
\begin{equation}
\left. \begin{array}{rcl} S^{(t)} & = & \{S_1,\cdots, S_t\} \\ s^{(t)} & = & \{s_1,\cdots, s_t\} \end{array}\right\} \mbox{história até ao tempo t}\cdot
\end{equation}
Além disso, é possível introduzir uma nova notação também para a \(L_T\). A verossimilhança \(L_T\) pode ser reescrita como
\begin{equation}
L_T \, = \, \underbrace{\delta B_1 \cdots B_t}_{\alpha_t} \underbrace{B_{t+1}\cdots B_T \pmb{1}^\top}_{\beta_t^\top} \, = \, \alpha_t\beta_t^\top
\qquad \mbox{para qualquer} \quad t\in \{1,2,\cdots,T\},
\end{equation}
onde \(\beta_T\) é definida como \(\beta_T^\top=\pmb{1}^\top\) e \(\alpha_0=\delta\). Note que tanto \(\alpha_t\) como \(\beta_t\) são vectores com \(m\) entradas,
nomeadamente \(\alpha_t = (\alpha_t(1),\cdots, \alpha_t(m))\) e \(\beta_t = (\beta_t(1),\cdots,\beta_t(m))\), respectivamente. No que se segue, a principal preocupação
é a interpretação dos vetores \(\alpha_t\) e \(\beta_t\).
Teorema III.1. Seja \(\{S_t, C_t \, : \, t\in\mathbb{N}\}\) um Modelo Oculto de Markov. Então, o vetor \(\alpha_t = (\alpha_t(1),\cdots, \alpha_t(m))\)
contém os seguintes vetores, chamados probabilidades forward:
\begin{equation}
\alpha_t \, = \, \big( P(S^{(t)}=s^{(t)}, C_t=1), \cdots, P(S^{(t)}=s^{(t)}, C_t=m)\big)\cdot
\end{equation}
Demonstração.
Este resultado pode ser provado através de indução matemática. Por razões de legibilidade, a prova foi dada para o caso \(m = 2\), no
entanto, a prova para o caso geral pode ser derivada de forma análoga.
O enunciado do Teorema III.1 significa que cada componente \(\alpha_t(i)\), \(i = 1,2,\cdots,m\) do vector \(\alpha_t\) pode ser interpretado como a probabilidade de a história do HMM até
o tempo \(t\) e da Cadeia de Markov estar no estado \(i\) no tempo \(t\). Por exemplo, para \(t = 10\), \(\alpha_{10}(2)\) é a probabilidade do histórico até
\(t = 10\) e a Cadeia de Markov estar no estado 2 quando \(t = 10\).
Observe que na demonstração, a propriedade de independência condicional dos HMMs foi usada duas vezes. Omitimos a avaliação de \(\alpha_{t+1}(2)\) por
ser semelhante à a avaliação de \(\alpha_{t+1}(1)\). No entanto, pode ser um exercício útil para o leitor.
O vetor \(\beta_t=\big( \beta_t(1), \beta_t(2), \cdots,\beta_t(i),\cdots,\beta_t(m)\big)\) pode ser intrepretado de maneira similar. Ele contém as chamadas probabilidades de backward
\(\beta_t(i)\), onde
\begin{equation}
\beta_t(i) \, = \, P\big( S_{t+1}=s_{t+1}, S_{t+2}=s_{t+2}, \cdots, S_T=s_T \, | \, C_t=i\big)\cdot
\end{equation}
Isso significa que \(\beta_t(i)\) representa uma probabilidade condicional, isto é, a probabilidade das futuras observações \(s_{t+1},\cdots,s_T\) dado que
a Cadeia de Markov está no estado \(i\) no momento \(t\). A prova que é análoga à de \(\alpha_t\) e é deixada como um exercício para o
leitor.
Finalmente, gostaríamos de justificar os nomes de \(\alpha_t(i)\) e \(\beta_t(i)\). Os \(\alpha_t(i)\) são chamados de probabilidades forward, uma vez que o \(\alpha_t\)
pode ser computado em uma recursividade para a frente:
\begin{array}{lcl}
\mbox{inicio:} & & \alpha_0 \, = \, \delta, \\
\mbox{atualização:} & & \alpha_t \, = \, \alpha_{t-1} B_t, \qquad \text{para} \quad t=1,2,\cdots,T\cdot
\end{array}
Analogamente, os vetores \(\beta_t\) contendo as probabilidades backward podem ser avaliados usando a seguinte recursividade para trás:
\begin{array}{lcl}
\mbox{inicio:} & & \beta_T \, = \, \pmb{1}^\top, \\
\mbox{atualização:} & & \beta_t \, = \, B_{t+1} \beta_{t+1}, \qquad \text{para} \quad t=T-1,T-2,\cdots,1\cdot
\end{array}
Exemplo III.1: Exemplo simulado (continuação do Exemplo II.1).
Os dadaos no Exemplo II.1 foram simulados utilizando o pacote de funções HiddenMarkov. Vamos utilizar esses dados com o objetivo de mostrar o cálculo
dos vetores \(\alpha_t\) e \(\beta_t\), os vetores com as probabilidades de avanço (forward) e retrocesso (backward), respectivamente.
O algoritmo nos fornece como reposta o logaritmo dos vetores \(\alpha_t\) e \(\beta_t\) por isso, para mostrar os valores das probabilidades, utilizamos a função
exponencial. Decidimos mostrar também os valores inicias e finais. Lembremos que \(\alpha_0 \, = \, \delta\) e, então, \(\alpha_1 \, = \, \alpha_{0} B_1\), lembremos
também que \(\beta_T \, = \, \pmb{1}^\top\). A continuação mostramos o cálculo de \(\alpha_1\). Veja que coincide com o resultado mostrado acima, da mesma
forma que \(\beta_{100} \, = \, \pmb{1}^\top\).
A função forwardback além de fornecer como resposta os vetores logalpha e logbeta, fornece também
o valor da log-verossimilhança em LL, por isso mostramos o cálculo da verossimilhança em dois intanstes de tempo, \(L_{100} = \alpha_{90}\beta_{90}^\top\) e
\(L_{100}=\alpha_{80}\beta_{80}^\top\).
Um método para estimar os parâmetros de um HMM é o algoritmo Baum-Welch, um exemplo do que mais tarde se tornou conhecido como o Algoritmo EM (Baum et al., 1970).
No entanto, como gostaríamos de nos concentrar na estimação de parâmetros com base na maximização numérica direta da verossimilhança,
apenas apresentamos a ideia básica do algoritmo EM sem fornecer detalhes. Para detalhes da descrição do algoritmo EM e sua implementação
no contexto dos HMMs nos referimos a Baum et al. (1970) e MacDonald and Zucchini (1997).
Originalmente, o algoritmo EM foi desenvolvido para estimar os parâmetros de um modelo no caso de dados faltantes. Por exemplo, imagine a situação em que
uma ou mais observações estão faltando para uma certa experiência. Seja \(Y = (Y^{obs}; Y^{mis})\) denotando todas as observações,
\(Y^{obs}\) denota as observações conhecidas e \(Y^{mis}\) os valores dos dados em falta. Considere também que o desenho do experimento leva a supor que
todas as observações são distribuídas de acordo com uma função de distribuição paramétrica com o parâmetro
\(\theta\). Em seguida, ocorrem os seguintes problemas.
Os procedimentos padrão não podem ser aplicados para realizar a estimação de \(\theta\). O estimador \(\widehat{\theta}\) é afetado
pelo fato de que uma ou mais observações estão faltando.
As observações em falta \(Y^{mis}\) não podem ser facilmente substituídas porque não estão disponíveis estimativas
fiáveis para \(\theta\). A soluçõo para isto seria substituir \(Y^{mis}\) pela média \(\overline{Y^{obs}}\), o que pode levar a um estimador
tendencioso, este procedimento somente deve ser realizado se for possível assumir que \(Y^{mis}\) está faltando ao acaso.
O algoritmo EM lida com estes problemas da seguinte forma. Primeiramente, um palpite inicial para o parâmetro \(\theta\) tem que ser feito, denotado por \(\theta^0\). Ele
pode basear-se na experiência ou ser uma escolha aleatória. Então, os dois passos seguintes têm de ser executados alternadamente.
Passo E
Calcular a esperança condicional das observações em falta, tendo em conta os dados observados e \(\theta^t\), \(\mbox{E}\big( Y^{mis} \, | \, Y^{obs}, \theta^t\big)\),
onde \(\theta^t = \theta^0\) no início do algoritmo. Em seguida, avaliar a log-verossimilhança dos dados completos, substituindo as funções dependendo
de \(Y^{mis}\) pelas funções correspondentes dependendo da esperança condicional; isto produz a esperada log-verossimilhança. Para ilustrar o que acontece,
pode-se imaginar que os valores em falta sejam substituídos por valores estimados com base no parâmetro \(\theta^t\) assumido e das observações \(Y^{obs}\)
conhecidas, mesmo que isso não seja correto do ponto de vista matemático.
Passo M
Maximizar a esperança da log-verossimilhança em relação a \(\theta\). O resultado é um aumento da esperança da log-verossimilhança, bem como
um novo parâmetro \(\theta^{t+1}\).
Os dois passos se repetem até que o aumento da log-verossimilhança caia abaixo de um determinado limite ou um certo número de repetições sejam
levados a cabo. As estimativas resultantes de \(\theta\) convergem para valores que maximizam a verossimilhança do modelo. A propriedade de maior endereçamento do
algoritmo EM é que a log-verossimilhança aumenta monotonicamente na sequência de iterações e converge para um valor estacionário. No entanto,
a taxa de convergência pode tornar-se muito lenta se faltarem muitas observações.
No contexto dos HMMs, os estados não observados ocupados pela Cadeia de Markov são considerados como as observações em falta. Então, os dois
passos do algoritmo EM podem ser implementados usando as probabilidades de avanço (forward) e recuo (backward) se soluções fechadas estiverem disponíveis
para o passo M e os valores em falta não ocorrerem. Entretanto, o esforço necessário para estimar os parâmetros das distribuições de
estado dependentes depende do modelo particular usado para o processo de observação e em modelos complexos a aplicação de métodos numéricos
pode ser necessária.
Também temos de mencionar que o algoritmo padrão do EM desenvolvido para HMMs não funciona para Cadeias de Markov com distribuição inicial a estacionária, ou seja, as probabilidades
para o estado inicial, \(\delta(1)\), não são iguais à distribuição estacionária da Cadeia de Markov, mas tem de ser estimada. Esta é
uma restrição em contraste com o método de maximização numérica directa da verossimilhança que pode ser implementada tanto para
Cadeias de Markov com distribuição inicial a estacionárias ou não. Além disso, se algumas das observações \(s_t\) faltam a implementação do algoritmo EM torna-se
bastante complicada enquanto a falta de observações pode ser tratado na maximização directa. Portanto, aqui concentramo-nos no método de maximização
numérica direta da verossimilhança que será delineada em a seção seguinte. Para mais detalhes sobre a implementação precisa do algoritmo
EM para a estimação de parâmetros em HMMs ver Baum et al. (1970) ou MacDonald and Zucchini (1997).
Exemplo III.2: Algoritmo EM.
Utilizamos os dados de série de vendas semanais de um produto de sabão específico, que foram apresentados na Figura 1, na Introdução
deste artigo, para mostrarmos uma das formas de estimar os parâmetros de um modelo HMMs Poisson com dois estados. Continuamos utilizando o pacote de funções
HiddenMarkov e nele utilizamos dthmm, como mostrado antes esta função serve para especificarmos o modelo a ser ajustado na
forma de Modelo Oculto de Markov. Definimos a variável auxiliar m para especificarmos o número de estados na Cadeia de Markov oculta e com a
opção distn que o modelo seja Poisson.
> # Valores inicias
> # No. de estados m = 2
> m = 2
> modelo.soap = dthmm(soap, Pi = matrix(rep(1/m,m), ncol=m, nrow=m), delta = matrix(rep(1/m,m), ncol=m),
+ distn = "pois", pm = list(lambda = matrix(seq(1,m), ncol=m)))
> str(modelo.soap)
List of 8
$ x : num [1:242] 1 6 9 18 14 8 8 1 6 7 ...
$ Pi : num [1:2, 1:2] 0.5 0.5 0.5 0.5
$ delta : num [1, 1:2] 0.5 0.5
$ distn : chr "pois"
$ pm :List of 1
..$ lambda: int [1, 1:2] 1 2
$ pn : NULL
$ discrete: logi TRUE
$ nonstat : logi TRUE
- attr(*, "class")= chr "dthmm"
Agora utilizamos o comando BaumWelch para executar o algoritmo EM construído anteriormente e guardado em modelo.soap. Posteriormente, com
summary mostramos as estimativas da matriz de probabilidades de transição e dos parâmetros \(\lambda\) das funções de
probabilidade Poisson.
Esclarecemos que, na função de ajuste BaumWelch, a opção control = bwcontrol(prt = FALSE) serve para
impedir que as informações sejam impressas em cada iteração. Como resposta temos a matriz de probabilidades de transição
estimada em Pi, as estimativas dos parâmetros \(\lambda\) das distribuições de estado dependentes, Poisson nesta situação,
em pm$lambda e outras informações.
Os modelos são ajustados pelo algoritmo EM (Baum-Welch) se não houverem restrições sobre os parâmetros.
Exemplo III.3: Retornos.
S&P 500, abreviação de Standard & Poor's 500, trata-se de um índice composto por quinhentos ativos (ações)
cotados nas bolsas de NYSE ou NASDAQ, qualificados devido ao seu tamanho de mercado, sua liquidez e sua representação de grupo industrial.
No Yahoo finance, a fonte de dados, o ticker do S&P 500 é ^GSPC.
Aqui não estamos interessados nem no valor do índice nem no seu retorno, estamos interessados na codificação resultante da Cadeia
de Markov subjacente, não observada, a qual deve indicar os períodos de alta, estável ou baixa do mercado; caso a cadeia seja de três
estados e alta ou baixa, caso seja de dois estados a cadeia do modelo estimado adequado aos dados.
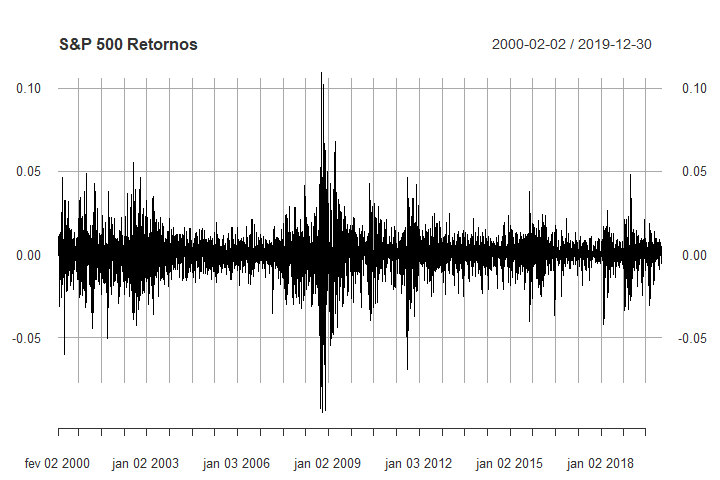
Com a lista de comandos acima lemos os dados do índice S&P 500 diretamente do site Yahoo finance, estes dados foram transformados em log-retornos,
guardados na variável GSPCr e mostrados na Figura III.1.
Figura III.1: Retornos (log-retornos) do índice S&P 500.
> # Valores inicias
> # No. de estados inciais m = 3
> m = 3
> modelo.retornos = dthmm(GSPCr, Pi = matrix(rep(1/m,m), ncol=m, nrow=m),
+ delta = matrix(rep(1/m,m), ncol=m), distn = "norm",
+ pm = list(mean = c(-0.01,0,0.01), sd = c(0.1,0.1,0.1)))
> str(modelo.retornos)
List of 8
$ x :An ‘xts’ object on 2010-02-02/2019-12-30 containing:
Data: num [1:2495, 1] 0.01289 -0.00549 -0.03164 0.00289 -0.0089 ...
- attr(*, "dimnames")=List of 2
..$ : NULL
..$ : chr "GSPC.Close"
Indexed by objects of class: [Date] TZ: UTC
xts Attributes:
List of 2
..$ src : chr "yahoo"
..$ updated: POSIXct[1:1], format: "2020-09-29 19:59:00"
$ Pi : num [1:3, 1:3] 0.333 0.333 0.333 0.333 0.333 ...
$ delta : num [1, 1:3] 0.333 0.333 0.333
$ distn : chr "norm"
$ pm :List of 2
..$ mean: num [1:3] -0.01 0 0.01
..$ sd : num [1:3] 0.1 0.1 0.1
$ pn : NULL
$ discrete: logi FALSE
$ nonstat : logi TRUE
- attr(*, "class")= chr "dthmm"
> retornos.ajuste1 = BaumWelch(modelo.retornos, control = bwcontrol(prt = FALSE))
> summary(retornos.ajuste1)
$delta
[1] 1.000000e+00 3.463808e-151 0.000000e+00
$Pi
[,1] [,2] [,3]
[1,] 0.962848228 0.03715177 6.325487e-33
[2,] 0.009367500 0.92071597 6.991653e-02
[3,] 0.002013301 0.06371969 9.342670e-01
$nonstat
[1] TRUE
$distn
[1] "norm"
$pm
$pm$mean
[1] -0.0016437398 0.0003630519 0.0011638210
$pm$sd
[1] 0.017664334 0.009075237 0.004143338
$discrete
[1] FALSE
$n
[1] 2495
O ajuste acontece quando executamos o comando BaumWelch, ou seja, o algoritmo EM e perceba que antes do ajuste devemos indicar o modelo, isto é feito com o comando dthmm.
Nesta situação podemos interpretar os estados da Cadeia de Markov não observada ou subjacente como -1, se o mercado estiver em baixa (urso na gíria do mercado de açoes), 0
se o mercado estiver estável e 1, caso o mercado estiver em alta (toro). Logicamente, primero devemos selecionar o modelo mais adequado e verificar seu ajuste.
Uma outra possibilidade seria escolher como modelo aquele com 2 estados, os quais interpretamos como mercado em baixa ou -1 e mercado em alta ou 1. Isso o faremos a seguir.
Observemos que obtivemos por resposta duas médias, uma negativa -0.0007 que representaria as situações do mercado em baixa e uma outra
média positiva 0.0010, indicando instantes do mercado em alta. Também temos por resposta os desvios padrão respectivos. Verificaremos
depois como escolher entre diversos modelos candidatos e como estimar esses estados para cada instante de tempo.
A maximização numérica direta da verossimilhança tem algumas vantagens sobre o algoritmo EM, não menos importante sendo a facilidade com que
o software para um modelo específico pode ser modificado para se adequar a modelos alternativos e mais complexos. Outra vantagem é que o método lida
facilmente com observações ausentes. Por sua vez, isto facilita, por exemplo, a verificação de outliers.
No entanto, dois grandes problemas ocorrem quando se aplica a maximização numérica direta da verossimilhança para estimar os parâmetros de um HMM.
Os parâmetros são limitados, ou seja, as estimativas de máxima verosimilhança para a matriz de probabilidades de transição \(\Gamma\)
e a maioria dos parâmetros da distribuição de estado dependente, por exemplo, \(\lambda\) no caso de um HMM Poisson, não é permitido tomar
todos os valores em \(\mathbb{R}\).
Ocorre subfluxo numérico, ou seja, à medida que o \(T\) aumenta a \(L_T\) torna-se menor e pode ser arredondada a zero pelo software para o \(T\) grande.
Nas duas seções seguintes, demonstraremos como superar esses problemas. Em seguida forneceremos um algoritmo eficiente para realizar a maximização
numérica direta da verossimilhança que pode ser implementado usando algum software estatístico padrão.
Como já mencionado acima, usando a maximização numérica direta da verossimilhança para a estimação dos parâmetros tem
de se considerar que, como a maioria dos parâmetros são restritos, é necessário realizar uma otimização linearmente limitada ou
reparametrizar o modelo para utilizar algoritmos do tipo quase-Newton oferecidos nos software estatístico padrão como o R (Zucchini and MacDonald, 1998).
A seguir mostraremos como reparamatrizar os parâmetros de um HMM de Poisson com um procedimento que pode ser transferido para outros HMMs.
No caso de um HMM de Poisson, as restrições dos parâmetros são dadas por
\(\lambda_i>0\), \(\forall \, i \in \{1,2,\cdots,m\}\).
A primeira restrição assegura que \(\Gamma\) é de fato uma matriz de probabilidades de transição, ou seja, todos os elementos de \(\Gamma\)
devem estar dentro do intervalo \([0;1]\) e as filas de \(\Gamma\) devem somar 1. É uma restrição genérica que se aplica a todos os HMMs.
A segunda restrição garante que os parâmetros das distribuições de Poisson componentes \(\lambda_i\) permaneçam dentro de sua faixa
admissível, ou seja, sejam positivos. Esta restrição difere dependendo de qual distribuição foi escolhida para as distribuições
de componentes; por exemplo para um HMM Binomial muda para \(\pi_i \in [0;1]\).
A fim de satisfazer a segunda restrição, pode-se introduzir uma simples transformação dos parâmetros \(\lambda_i\):
\begin{equation}
\eta_i \, = \, \log\big( \lambda_i\big), \quad \mbox{o qual é equivalente a} \quad \lambda_i \, = \, e^{\eta_i}, \quad \forall \, i\in \{1,2,\cdots,m\}\cdot
\end{equation}
Então, \(\eta_i\in \mathbb{R}\) e pode-se maximizar a verossimilhança usando os parâmetros \(\eta_i\) sem restriçães e obter as respectivas
estimativas dos parâmetros condicionados, \(\lambda_i\), através da transformação inversa e estimar os parâmetros não restritos
\(\widehat{\eta}_i\) de acordo com a fórmula acima. Este procedimento pode ser facilmente adaptado a outras distribuições que não a Poisson. Por
exemplo, no caso de um HMM Binomial pode-se usar uma transformação logito dos parâmetros \(\pi_i\).
A reparametrização das probabilidades de transição \(\gamma_{i,j}\) é um pouco mais exigente. Note que a matriz \(\Gamma\) tem \(m^2\)
entradas, mas \(m(m-1)\) parâmetros livres, apenas porque as restrições de soma de linhas acima devem ser cumpridas. A seguir, vamos mostrar uma possível
transformação
\begin{equation}
\gamma_{i,j}\in [0;1] \quad \mbox{transformamos em} \quad \tau_{i,j}\in \mathbb{R}, \quad \underbrace{\forall \, i,j\in\{1,2,\cdots,m\}, i\neq j}_{m(m-1) \; \mbox{pares de índices}},
\end{equation}
para os elementos não-diagonais da matriz de probabilidades de transição. Para uma melhor legibilidade, restringimos a nossa atenção ao
caso \(m = 3\), no entanto, os mesmos trabalhos de transformação funcionam também no caso geral.
Seja \(T\) uma matriz \(3\times 3\) com elementos não diagonais \(\tau_{i,j}\), \(i,j\in \{1,2,3\}\), \(i\neq j\) são números reais arbitrários, ou seja,
\(\tau_{i,j}\in \mathbb{R}\):
\begin{equation}
T \, = \, \begin{pmatrix} - & \tau_{1,2} & \tau_{1,3} \\ \tau_{2,1} & - & \tau_{2,3} \\ \tau_{3,1} & \tau_{3,2} & - \end{pmatrix}\cdot
\end{equation}
Agora, seja \(g \, : \, \mathbb{R}\to\mathbb{R}^+\) uma função monotonamente crescente, ou seja, \(g(x)=e^x\) e
\begin{equation}
\xi_{i,j} \, = \, \left\{ \begin{array}{ccl} g\big(\tau_{i,j}\big) & \mbox{para} & i\neq j \\ 1 & \mbox{para} & i=j \end{array}\right. \cdot
\end{equation}
Por esta transformação, a nova matriz \(R\) é gerada onde todos os elementos \(\xi_{i,j}\) , \(i,j\in\{1,2,3\}\) são estritamente positivos:
\begin{equation}
R \, = \, \begin{pmatrix} 1 & \xi_{1,2} & \xi_{1,3} \\ \xi_{2,1} & 1 & \xi_{2,3} \\ \xi_{3,1} & \xi_{3,2} & 1 \end{pmatrix}\cdot
\end{equation}
Finalmente, dividindo todos os elementos de \(R\) pelas suas respectivas somas por linha, ou seja,
\begin{equation}
\gamma_{i,j} \, = \, \dfrac{\xi_{i,j}}{\displaystyle\sum_{k=1}^3 \xi_{i,k}}, \quad \forall \, i,j \in\{1,2,3\}\cdot
\end{equation}
Isto produz uma matriz \(\Gamma\) que tem as propriedades de uma matriz de probabilidades de transição:
\begin{equation}
\Gamma \, = \, \begin{pmatrix} \gamma_{1,1} & \gamma_{1,2} & \gamma_{1,3} \\ \gamma_{2,1} & \gamma_{2,2} & \gamma_{2,3} \\
\gamma_{3,1} & \gamma_{3,2} & \gamma_{3,3} \end{pmatrix},
\end{equation}
onde \(\gamma_{i,j}\in [0,1]\), para todo \(i,j\in \{1,2,3\}\) e \(\displaystyle \sum_{j=1}^3 \gamma_{i,j}=1\), para todo \(i\in \{1,2,3\}\). A demonstração disso
é deixada como um exercício ao leitor.
Esta transformação pode ser facilmente revertida. Dada a matriz de probabilidades de transição \(\Gamma\), a matriz \(T\) com o \(\tau_{i,j}\) como
elementos fora da diagonal pode ser obtida dividindo cada elemento \(\gamma_{i,j}\) de \(\Gamma\) pelo respectivo elemento diagonal \(\gamma_{i,i}\), que produz a matriz \(R\) e
depois aplicando o inverso da função acima referida, por exemplo, \(g(x)\), ou seja, \(g^{-1}(x) = \log(x)\), aos elementos fora da diagonal de \(R\). A derivação
detalhada da transformação inversa também é deixada ao leitor como exercício.
Agora, usando as transformações de \(\lambda\) e \(\Gamma\) esboçadas acima, os estimadores de máxima verossimilhança para o caso geral m
podem ser obtidos em duas etapas.
Maximizar a verossimilhança \(L_T\) no que diz respeito aos novos parâmetros sem restrições \(\eta=(\eta_1,\cdots,\eta_m)\) e
\(T=\big\{\tau_{i,j}, \, i,j\in \{1,\cdots,m\}, \, i\neq j \}\big\}\).
Converter os parâmetros estimados sem restrições de volta aos parâmetros restritos:
\begin{equation}
\widehat{T} \, \to \, \widehat{\Gamma}, \quad \widehat{\eta} \, \to \, \widehat{\lambda}\cdot
\end{equation}
Para uma implementação das transformações utilizando a linguajem de programação R ver o exemplo a seguir.
Tendo superado as restrições dos parâmetros, normalmente é preciso lidar com um segundo problema, ou seja, um subfluxo numérico. Como mostrado
anteriormente, a verossimilhança de um HMM é dada pela expressão
\begin{equation}
L_T \, = \, \delta B_1 \cdots B_t \pmb{1}^\top\cdot
\end{equation}
A partir da definição das chamadas probabilidades futuras (forward) introduzidas na Seção III.1, segue-se que \(L_T = \alpha_T\), uma forma de avaliar \(L_T\) é
calcular as probabilidades futuras através da seguinte repetição:
\begin{array}{lcl}
\text{início: } & & \alpha_0 \, = \, \delta\ \\
\text{atualização: } & & \alpha_t \, = \, \alpha_{t-1} B_t, \qquad \mbox{para} \quad t=1,2,3,\cdots,T\cdot
\end{array}
No entanto, o problema é que o ajuste se torna muito pequeno para grandes \(t\), o que leva a um subfluxo numérico quando se calcula a verossimilhança de uma
série longa; pode até acontecer que o \(L_T\) seja arredondado para zero o que torna impossível estimar os parâmetros do HMM.
A solução usual para o problema do subfluxo numérico, ou seja, a maximização da log-verossimilhança em vez da maximização da
verossimilhança, não pode ser implementada tão facilmente uma vez que a verossimilhança é um produto de matrizes. No entanto, pode-se derivar uma
fórmula fechada para a log-verossimilhança de um HMM aplicando um truque que, basicamente, produz um algoritmo alternativo para avaliar a verossimilhança
recursivamente via probabilidades escalonadas para frente. Isto será demonstrado a seguir.
Primeiro, precisamos de introduzir uma nova notação. Definamos
\begin{equation}
\omega_t \, = \, \alpha_t\pmb{1}^\top \qquad \mbox{ e } \qquad \phi_t \, = \, \dfrac{\alpha_t}{\omega_t}\cdot
\end{equation}
Portanto, \(\omega_t\) é um escalar, ou seja, a soma dos elementos de \(\alpha_t\), que em seguida será usado como fator de escala e \(\phi_t\) é um vetor
contendo as probabilidades de redimensionamento para frente, ou seja, as probabilidades futuras divididas pela sua soma.
Executando esta recorrência até a \(\phi_T\) obtém-se:
\begin{array}{rcl}
\phi_T & = & \dfrac{\omega_{T-1}}{\omega_T}\dfrac{\omega_{T-2}}{\omega_{T-1}}\cdots \dfrac{\omega_{0}}{\omega_1}\delta B_1 B_2\cdots B_{T-1}B_T \\
& = & \dfrac{\omega_{T-1}}{\omega_T}\dfrac{\omega_{T-2}}{\omega_{T-1}}\cdots \dfrac{\omega_{0}}{\omega_1}\alpha_T\cdot
\end{array}
Claro que agora seria possível cancelar todos os factores de escala excepto \(\omega_T\) e \(\omega_0\), no entanto, isso não nos ajudaria na construção
de um algoritmo de redimensionamento para o cálculo da verossimilhança. Em vez disso, a igualdade acima pode ser convertida da seguinte forma:
\begin{array}{rcl}
\phi_T & = & \dfrac{\omega_{T-1}}{\omega_T}\dfrac{\omega_{T-2}}{\omega_{T-1}}\cdots \dfrac{\omega_{0}}{\omega_1}\alpha_T \\[0.5em]
\dfrac{\omega_{T}}{\omega_{T-1}}\dfrac{\omega_{T-1}}{\omega_{T-2}}\cdots \dfrac{\omega_{1}}{\omega_0}\phi_T & = & \alpha_T \\[0.5em]
\dfrac{\omega_{T}}{\omega_{T-1}}\dfrac{\omega_{T-1}}{\omega_{T-2}}\cdots \dfrac{\omega_{1}}{\omega_0}\phi_T\pmb{1}^\top & = & \alpha_T\pmb{1}^\top \\[0.5em]
\dfrac{\omega_{T}}{\omega_{T-1}}\dfrac{\omega_{T-1}}{\omega_{T-2}}\cdots \dfrac{\omega_{1}}{\omega_0} & = & L_T \\[0.5em]
\displaystyle \prod_{t=1}^T \dfrac{\omega_t}{\omega_{t-1}} \, = \, L_T\cdot
\end{array}
O último passo decorre do fato de, devido à sua definição, o \(\phi_T\) ter um comprimento unitário, ou seja, \(\phi_T\pmb{1}^\top=1\).
Agora que a verossimilhança \(L_T\) foi reescrita como um produto de escalares é possível tomar o logaritmo da verossimilhança, e obtém-se
\begin{equation}
\log\big( L_T\big) \, = \, \displaystyle \sum_{t=1}^T \log \Big( \dfrac{\omega_t}{\omega_{t-1}}\Big)\cdot
\end{equation}
No entanto, ainda é preciso avaliar os termos da soma, ou seja, os quocientes da escalada de fatores. Em relação à recorrência para \(\phi_T\) e
usando a igualdade \(\phi_T\pmb{1}^\top = 1\) novamente, os quocientes podem ser obtidos através de
\begin{array}{rcl}
\phi_t & = & \dfrac{\omega_{t-1}}{\omega_t}\phi_{t-1}B_t, \\[0.5em]
\phi_t\pmb{1}^\top & = & \dfrac{\omega_{t-1}}{\omega_t}\phi_{t-1}B_t\pmb{1}^\top, \\[0.5em]
\dfrac{\omega_{t}}{\omega_{t-1}} & = & \phi_{t-1}B_t\pmb{1}^\top \cdot
\end{array}
Tendo fórmulas para as derivadas da log-verossimilhança de um HMM e para os termos da log-verossimilhança, ou seja, os quocientes \(\omega_t/\omega_{t-1}\),
pode-se desenvolver um algoritmo eficiente para avaliar a log-verossimilhança recursivamente usando as probabilidades escalonadas para frente (forward). Este algoritmo
será apresentado na seção seguinte.
As fórmulas derivadas na seção anterior podem ser implementadas eficientemente através do seguinte algoritmo recursivo:
\begin{array}{rcl}
\text{início} & t=0 & \log\big( L_0\big)=0, \\[0.5em]
\text{atualização} & t=1,2,\cdots,T & \nu_t \, = \, \phi_{t-1}B_t, \\[0.5em]
& & u_t \, = \, \nu_t \pmb{1}^\top \, = \, \phi_{t-1}B_t\pmb{1}^\top \, = \, \dfrac{\omega_t}{\omega_{t-1}} \\[0.5em]
& & \log\big(L_t\big) \, = \, \log\big( L_{t-1}\big)+\log(u_t) \, = \, \log\big( L_{t-1}\big)+\log\Big( \dfrac{\omega_t}{\omega_{t-1}}\Big) \\[0.5em]
& & \phi_t \, = \, \dfrac{\nu_t}{u_t} \, = \, \dfrac{\omega_{t-1}}{\omega_t}\phi_{t-1} B_t\cdot
\end{array}
A repetição do laço para \(t = 1,2,\cdots,T\) leva ao valor da log-verossimilhança \(\log\big(L_T\big)\) requerida.
Implementando este algoritmo e usando as transformações de parâmetros descritas nesta seção pode-se estimar os parâmetros por
máxima verosimilhança de um HMM através da maximização numérica direta usando R ou outros pacotes de software
estatístico que forneçam funções para a maximização numérica, ou minimização em alternativa.
Para uma implementação do algoritmo e das transformações descritas acima e para a programação de uma função
que realiza a estimação de máxima verosimilhança para a Poisson HMM veja os Problemas III.5.4, III.5.6 e III.5.7.
Com o conhecimento das seções anteriores, as estimativas dos parâmetros \(\widehat{\Theta}=(\widehat{\Gamma},\widehat{\Lambda})\) podem ser obtidas maximizando
a verossimilhança dos dados fornecidos, observe que a definição de \(\widehat{\Theta}\) implica que se está lidando com um HMM Poisson. Para outros
modelos o vetor \(\widehat{\Lambda}\), na definição de \(\widehat{\Theta}\) tem que ser substituído pelo vetor de parâmetros apropriado. A precisão
das estimativas não pode ser calculada facilmente, apenas alguns resultados assintóticos estão disponíveis. Sob certas condições, \(\widehat{\Theta}\)
é consistente e assintoticamente normal, para detalhes ver MacDonald and Zucchini (1997). Contudo, para aplicações práticas, os resultados levam
a alguns problemas.
A amostra é geralmente de tamanho finito \(T\), portanto a intensidade do comportamento assintótico torna-se um aspecto importante.
Assumindo a normalidade, como pode ser calculado o erro padrão \(SE(\widehat{\Theta})\)?
As entradas de \(\widehat{\Theta}\) estão correlacionadas. Portanto, a interpretação não é trivial uma vez que os parâmetros
estão ligados. Este problema, também ocorrendo em outros contextos, leva ao fato de que as declarações podem ser feitas para os erros padrão
dos parâmetros individuais, separadamente, enquanto o erro de todo o modelo, que é mais interessante, não pode ser calculado diretamente.
Uma solução possível para os problemas acima mencionados é o uso do método paramétrico bootstrap.
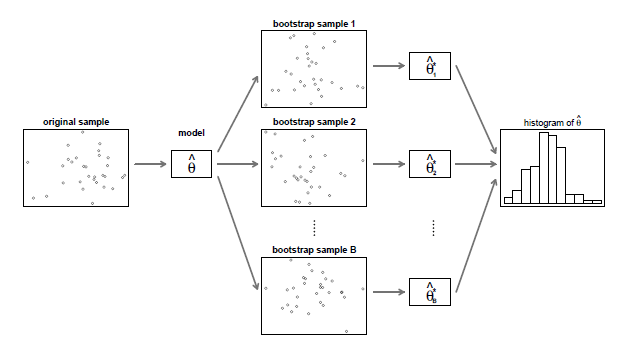
O bootstrap paramétrico assume que o modelo ajustado com os parâmetros estimados \(\widehat{\Theta}\) é o verdadeiro modelo dos dados. Então, a fim de
obter as propriedades distribucionais de \(\widehat{\Theta}\) os seguintes passos são repetidos para \(b\in \{1,2,\cdots,B\}\).
Gerar uma nova amostra \(b\) de observações de comprimento \(T\) a partir do modelo ajustado com parâmetros \(\widehat{\Theta}\), normalmente, o comprimento
deve ser o mesmo que o número de observações originais. Esta amostra é chamada de amostra de bootstrap \(b\).
Estimar o vector dos parâmetros \(\widehat{\Theta}^*_b\) para a amostra bootstrap \(b\).
Este procedimento que produz \(B\) vectores de estimativas dos parâmetros, \(\widehat{\Theta}^*_1,\cdots,\widehat{\Theta}^*_B\), e portanto uma distribuição empírica
das estimativas dos parâmetros \(\widehat{\Theta}\), é ilustrada na figura abaixo.
Figura III.2: Bootstrap paramétrico. Figura retirada do livro Zucchini & MacDonald (2009).
Então, dadas as estimativas dos parâmetros para as amostras de bootstrap, as propriedades distribucionais de \(\widehat{\Theta}\) podem ser analisadas. Por exemplo,
o erro padrão de \(\widehat{\theta}\), ou seja, um dos parâmetros, pode ser estimado pelo desvio padrão de \(\widehat{\theta}_b^*\), \(b = 1,\cdots,B\),
\begin{equation}
\widehat{SE}(\widehat{\theta}) \, = \, \sqrt{\dfrac{1}{B-1}\displaystyle \sum_{b=1}^B\big(\widehat{\theta}_b^*-\widehat{\theta}_{(\cdot)}^* \big)^2},
\end{equation}
onde \(\widehat{\theta}_{(\cdot)}^*=\dfrac{1}{B}\displaystyle \sum_{b=1}^B \widehat{\theta}_b^*\) denota a média das estimativas dos respectivos parâmetros
\(\widehat{\theta}_b^*\).
De forma mais geral, a matriz de variâncias e covariâncias de \(\widehat{\Theta}\) pode ser obtida de forma semelhante:
\begin{equation}
\widehat{\mbox{Cov}}(\widehat{\Theta}) \, = \, \dfrac{1}{B}\displaystyle \sum_{b=1}^B\big(\widehat{\Theta}_b^*-\widehat{\Theta}_{(\cdot)}^* \big)^\top
\big(\widehat{\Theta}_b^*-\widehat{\Theta}_{(\cdot)}^* \big),
\end{equation}
onde \(\widehat{\Theta}_{(\cdot)}^*\) é o vetor das médias das estimativas dos parâmetros para as amostras do bootstrap. Por exemplo, para um HMM Poisson
de dois estados, \(\Theta\) é dado por \(\Theta = (\gamma_{1,2},\gamma_{2,1},\lambda_1,\lambda_2)\) e o resultado da matriz de variâncias e covariância seria
da forma:
\begin{equation}
\widehat{\mbox{Cov}}(\widehat{\Theta}) \, = \, \begin{pmatrix} \widehat{\mbox{Var}}(\widehat{\gamma}_{1,2}) & \widehat{\mbox{Cov}}(\widehat{\gamma}_{1,2},\widehat{\gamma}_{2,1}) &
\widehat{\mbox{Cov}}(\widehat{\gamma}_{1,2},\widehat{\lambda}_{1}) & \widehat{\mbox{Cov}}(\widehat{\gamma}_{2,1},\widehat{\lambda}_{2})\\
\widehat{\mbox{Cov}}(\widehat{\gamma}_{2,1},\widehat{\gamma}_{1,1}) & \widehat{\mbox{Var}}(\widehat{\gamma}_{2,1}) & \widehat{\mbox{Cov}}(\widehat{\gamma}_{2,1},\widehat{\lambda}_{1}) &
\widehat{\mbox{Cov}}(\widehat{\gamma}_{2,1},\widehat{\lambda}_{2}) \\
\widehat{\mbox{Cov}}(\widehat{\lambda}_{1},\widehat{\gamma}_{1,2}) & \widehat{\mbox{Cov}}(\widehat{\lambda}_{1},\widehat{\gamma}_{2,1}) & \widehat{\mbox{Var}}(\widehat{\lambda}_{1}) &
\widehat{\mbox{Cov}}(\widehat{\lambda}_{1},\widehat{\lambda}_{2}) \\
\widehat{\mbox{Cov}}(\widehat{\lambda}_{2},\widehat{\gamma}_{1,2}) & \widehat{\mbox{Cov}}(\widehat{\lambda}_{2},\widehat{\gamma}_{2,1}) &
\widehat{\mbox{Cov}}(\widehat{\lambda}_{2},\widehat{\lambda}_{1})& \widehat{\mbox{Var}}(\widehat{\lambda}_{2})\end{pmatrix}\cdot
\end{equation}
Exemplo III.4: Bootstrap.
Utilizando os dados e resultados do Exemplo III.2, mostramos como implementar as estimativas bootstrap nesta situação.
Observe que, para melhor visualização, \(B=10\) neste caso, ou seja, o número de réplicas bootstraps é 10 um valor pequeno, em situações
práticas costuma-se utilizar 100, 500 ou mais réplicas Monte Carlo. O resultado deste exercício indica que o desvio padrão dos parâmetros da matriz de
probabilidades de transição é 0.025 na primeira linha e 0.075 na segunda linha. Os desvios padrão dos coeficientes \(\lambda\) da distribuição
Poisson são 0.220 e 0.553, respectivamente.
Considere que \(\{S_t \, : \, t=1,2,\cdots\}\) é um processo HMM de Poisson estacionário com \(m\) estados, sendo \(\Gamma\) a matriz de probailidade de
transição, \(\lambda=(\lambda_1,\cdots,\lambda_m)\) os parâmetros do processo estado-dependentes e distribuição estacionáaria da
Cadeia de Markov dada por \(\delta=(\delta_1,\cdots,\delta_m)\).
Seja \(D=\mbox{diag}(\delta)\) uma matriz diagonal com elementos diagonais \(\delta_1,\cdots,\delta_m\) e \(\Lambda=\mbox{diag}(\lambda)\) uma outra matriz diagonal com elementos diagonais
\(\lambda_1,\cdots,\lambda_m\).
Derive as seguintes expressões para os momentos de \(S_t\):
(f) \(\rho_k=\mbox{Corr}(S_t,S_{t+k})=\displaystyle\dfrac{\delta\Lambda \Gamma^k \lambda^\top-(\delta\lambda^\top)^2}
{\delta\Lambda \lambda^\top+\delta\lambda^\top-(\delta\lambda^\top)^2}\). Mostre também que, para o caso específico de \(m=2\),
\(\rho_k=\dfrac{\delta_1\delta_2(\lambda_2-\lambda_1)^2(1-\gamma_{1,2}-\gamma_{2,1})^k}{\delta_1\lambda_1+\delta_2\lambda_2+\delta_1\delta_2(\lambda_2-\lambda_1)^2}\).
Considere o processo Poisson HMM estacionário com parâmetros: \(\Gamma=\begin{pmatrix} 0.1 & 0.9 \\ 0.4 & 0.6 \end{pmatrix}\) e
\(\lambda=\begin{pmatrix} 1 & 3 \end{pmatrix}\). Calcule a probabilidade de as três primeiras observações deste modelo serem 0, 2, 1 em cada uma das
seguintes maneiras.
(a) Considere todas as sequências possíveis de estados da Cadeia de Markov que poderiam ter ocorrido. Calcule a probabilidade de cada sequência
e multiplique pela probabilidade das observações dadas a cada sequência. Finalmente, some as probabilidades.
Considere novamente o modelo definido no Exercício 2. Nesse problema, você foi solicitado a calcular \(P(S_1=0, S_2=2,S_3=1)\). Agora calcule
\(P(S_1=0, S_3=1)\) de cada uma das seguintes maneiras.
(a) Considere todas as sequências possíveis de estados da Cadeia de Markov que poderiam ter ocorrido. Calcule a probabilidade de cada sequência e
multiplique pela probabilidade das observações dadas a cada sequência. Finalmente, some as probabilidades.
(b) Aplique a fórmula \(P(S_1=0,S_3=1)=\delta P(0) \, \Gamma\, \mbox{I} \, \Gamma P(1)\pmb{1}^\top=\delta P(0)\Gamma^2 P(1)\pmb{1}^\top\) onde \(\mbox{I}\)
é a matriz \(2\times 2\) indentidade e verifique se essa probabilidade é igual à sua resposta em (a).
Cosidere a sequinte parametrização de uma matriz de probilidades de transição de uma Cadeia de Markov com \(m\)-estados. Sejam
\(\tau_{i,j}\in \mathbb{R}\), \(i,j=1,2,\cdots,m; \, i\neq j\), \(m(m-1)\) números reais arbitrários. Seja \(g \, : \, \mathbb{R}\to \mathbb{R}^+\) uma
função estritamente crescente, por exemplo, \(g(x)=e^x\). Definamos
\begin{equation}
\xi_{i,j} \, = \, \left\{ \begin{array}{ccl} g\big(\tau_{i,j}\big) & \mbox{para} & i\neq j \\ 1 & \mbox{para} & i=j \end{array}\right.
\end{equation}
e
\begin{equation}
\gamma_{i,j} \, = \, \dfrac{\xi_{i,j}}{\displaystyle\sum_{k=1}^m \xi_{i,k}}, \quad \forall \, i,j \in\{1,2,\cdots,m\}\cdot
\end{equation}
(a) Mostre que a matriz \(\Gamma\) com entradas \(\gamma_{i,j}\) como construídas desta maneira é uma matriz de probabilidades de transição,
isto é, mostre que \(0\leq \gamma_{i,j}\leq 1\) para todo \(i\) e \(j\) e que as somas por linhas de \(\Gamma\) são iguais a 1.
(b) Dada a matriz de probabilidades de transição \(\Gamma=\{\gamma_{i,j} \, : \, i,j=1,2,\cdots,m\}\), derive uma expressão para os parâmetros
\(\tau_{i,j}\), para \(i,j=1,2,\cdots,m\), \(i\neq j\).
O objetivo deste exercício é investigar o comportamento numérico de uma avaliação não escalada da verossimilhança de um HMM
e comparar isso com o comportamento de um algoritmo alternativo que aplica a escala.
Considere um modelo HMM estacionário com dois estados e parâmetros
\begin{equation}
\Gamma \, = \, \begin{pmatrix} 0.9 & 0.1 \\ 0.2 & 0.8 \end{pmatrix}, \qquad \lambda \, = \, \begin{pmatrix} 1 & 5 \end{pmatrix}\cdot
\end{equation}
Calcule a verosimilhança \(L_{10}\) da seguinte sequência de dez observações de duas maneiras: 2, 8, 6, 3, 6, 1, 0, 0, 4, 7.
(a) Utilize o método não escalado \(L_{10}=\alpha_{10}\pmb{1}^\top\), onde \(\alpha_0=\delta\) e \(\alpha_t=\alpha_{t-1}B_t\);
\begin{equation}
B_t \, = \, \begin{pmatrix} 0.9 & 0.1 \\ 0.2 & 0.8 \end{pmatrix}\begin{pmatrix} p_1(s_t) & 0 \\ 0 & p_2(s_t) \end{pmatrix}
\end{equation}
e
\begin{equation}
p_i(s_t) \, = \, \dfrac{\lambda_i^{s_t}e^{-\lambda_i}}{s_t!}, \quad i=1,2, \qquad t=1,2,\cdots,10\cdot
\end{equation}
Examine os valores numéricos dos vetores \(\alpha_0,\alpha_1,\cdots,\alpha_{10}\).
(b) Use o algoritmo fornecido na Seção III.3.2 Subfluxo numérico para calcular \(\log(L_{10})\).
Examine os valores numéricos dos vetores \(\phi_0,\phi_1,\cdots,\phi_{10}\). É mais fácil armazenar esses vetores como linhas em uma matriz \(11\times 2\).
Considere as seguintes transformações:
\begin{array}{rcl}
\omega_1 & = & \sin^2(\theta_1) \\[0.8em]
\omega_2 & = & \displaystyle\left( \prod_{j=1}^{i-1} \cos^2(\theta_j) \right)\sin^2(\theta_i), \qquad i= 1, 2, \cdots, m-1 \\[0.8em]
\omega_m & = & \displaystyle\prod_{i=1}^{m-1} \cos^2(\theta_i)\cdot
\end{array}
Mostrar como essas transformações podem ser usadas para converter as restrições
\begin{equation}
\sum_{i=1}^m \omega_i \, = \, 1, \qquad \omega_i\geq 0, \qquad i=1,2,\cdots,m,
\end{equation}
em restrições simples, ou seja, restrições da forma \(a\leq \theta_i\leq b\).
Como isso pode ser usado no contexto da estimação nos HMMs?
(a) Considere uma Cadeia de Markov estacionária com matriz de probabilidades de transição \(\Gamma\) e distribuição estacionária \(\delta\).
Mostre que o número esperado de transições do estado \(i\) para o estado \(j\) em uma série de \(T\) observações, ou seja, em \(T-1\)
transições é \((T-1)\delta_i\gamma_{i,j}\).
Lembre que esta esperança é \(\displaystyle\sum_{t=2}^T P(S){t-1}=i, S_{t}=j)\).
(b) Mostre que, para \(\delta_3=0.152\) e \(T=107\), esta esperança é menor do que 1 se \(\gamma_{3,1} < 0.062\).
As probabilidades de retrocesso (backward) de um HMM são definidas como
\begin{equation}
\beta_t^\top \, = \, B_{t+1}B_{t+2}\cdots B_{T}\pmb{1}^\top \quad \mbox{para} \quad t=T-1, T-2, \cdots, 1 \quad \mbox{e} \quad \beta_T = 1\cdot
\end{equation}
Mostre que a \(i\)-ésima entrada do vetor \(\beta_t\) é igual a
\begin{equation}
P\big( S_{t+1}=s_{t+1}, S_{t+2}=s_{t+2},\cdots, S_T=s_T \, | \, C_t=i\big), \qquad i\in\{1,2,\cdots,m\}\cdot
\end{equation}