Como mencionado, uma característica atraente dos HMMs é que as distribuições condicionais e as distribuições de previsão estão
disponíveis. Isso torna mais fácil, por exemplo, verificar se há outliers ou fazer previsões por intervalos. Aqui, primeiro mostramos como calcular
as distribuições condicionais de um HMM (Seção IV.1). Então, com base na fórmula para a distribuição condicional, derivamos a distribuição
das previsões de um HMM (Seção IV.2). Finalmente, na última seção (Seção IV.3), demonstramos como se podem obter informações
sobre os estados ocultos da Cadeia de Markov subjacente, dado o valor de HMM. Esta inferência é chamada decodificação.
Utilizando a verossimilhança de um HMM tal como previsto na seção II.3 e a definição das probabilidades para a frente e para trás (ver Seção III.1),
é possível obter uma fórmula para a distribuição de \(S_t\) condicionada às outras observações do HMM.
Isto significa que \(S^{-u}\) e \(s^{-u}\) denotam as sequências das variáveis aleatórias \(S_t\) e as observações, respectivamente, com \(S_u\)
e \(s_u\) excluídos. Então, para \(u = 1,2,\cdots,T\) a distribuição condicional de \(S_u\), dadas todas as outras observações,
\(P\big(S_u = s \, | \, S^{(-u)} = s^{(-u)}\big)\), é dada por
\begin{equation}
P\big(S_u = s \, | \, S^{(-u)} = s^{(-u)}\big) \, = \, \dfrac{\displaystyle \alpha_{u-1}\Gamma \, P(s)\beta_u^\top}{\displaystyle \alpha_{u-1}\Gamma \, \beta_u^\top}\cdot
\end{equation}
Esta expressão mostra que a probabilidade condicional pode ser considerada como a razão de duas verossimilhanças de um HMM que, a fim de evitar subfluxo
numérico, ambas podem ser avaliadas usando o algoritmo de escalonamento delineado na Seção III.3. O numerador é a verossimilhança da série
cronológica observada, mas com a observação \(s_u\) substituída por \(s\); o denominador é a verossimilhança da série cronológica
observada, mas com a observação \(s_u\) considerada como ausente.
Outra interpretação da probabilidade condicional é a de uma mistura das distribuições de probabilidade estado-dependentes. É possível
mostrar que a fórmula acima pode ser
reescrito como
\begin{equation}
P\big(S_u = s \, | \, S^{(-u)} = s^{(-u)}\big) \, = \, \sum_{i=1}^m \zeta_u(i)p_i(s),
\end{equation}
onde os coeficientes de mistura \(\zeta_u(i)\) são funções das observações \(s^{(-u)}\) e dos parâmetros do modelo, a prova é deixada
como exercício.
Exemplo IV.1: Distribuição condicional no caso das vendas de sabão.
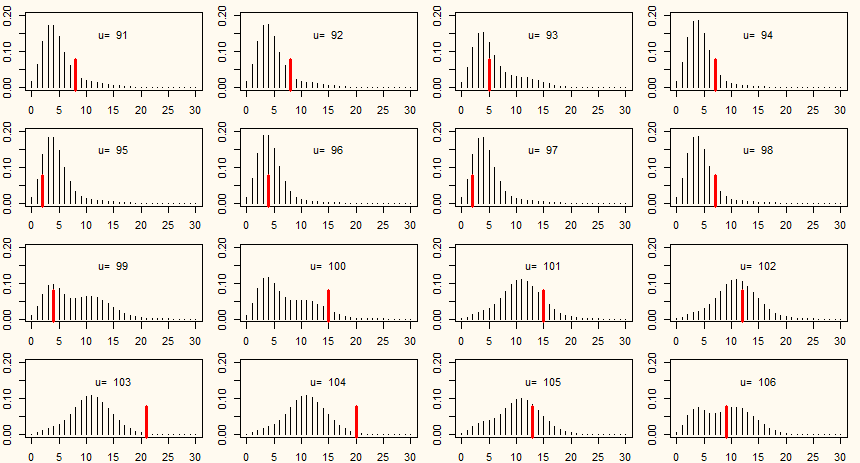
Mostraremos a distribuição condicional no caso das vendas de sabão com apenas dois estados nos instantes \(u\in\{91,\cdots,119\}\). Nós ajustamos
a estes dados um HMM Poisson com dois estados no Exemplo III.2. Será este ajuste o utilizado para gerarmos o gráfico a seguir.
Figura IV.1: Distribuição condicional de \(S_u\) para \(u\in \{91,\cdots,106\}\). A marca vermelha em cada gráfico
indica a observação. Impressiona que algumas das observações reais, que nesta figura são marcados como barras vermelhas, ficam perto
do centro das probabillidades condicionais.
> library(HiddenMarkov)
> prob.conditional = function(mod, u, s = seq(0,30))
+ {
+ fb = forwardback(mod$x, mod$Pi, delta = compdelta(mod$Pi), distn = "pois",
+ pm = list(lambda = mod$pm$lambda))
+ probabilidades = array(0, dim = length(s))
+ for (i in 1:length(s)) {
+ num = exp(fb$logalpha[u-1,])%*%(mod$Pi)
+ %*%diag(dpois(s[i], lambda = mod$pm$lambda))%*%exp(fb$logbeta[u,]);
+ denom = exp(fb$logalpha[u-1,])%*%(mod$Pi)%*%exp(fb$logbeta[u,]);
+ probabilidades[i] = num/denom
+ }
+ return(probabilidades)
+ }
> par(mfrow=c(4,4),mar=c(2,2,1,1), bg="floralwhite")
> for(i in 1:16) {
+ plot(seq(0,30),prob.conditional(mod = soap.ajuste1, u = 90+i, s = seq(0,30)),
+ ylim = c(0, 0.2), type="h", xlab = "", ylab = "");
+ text(15,0.15,paste("u= ", 90+i));rug(soap.ajuste1$x[90+i], ticksize = 0.4, lwd = 3.5, col = "red")
+ }
A função prob.condicional acima escrita em código R nos permite obter a probabilidade condicional
\begin{equation}
P\big(S_u = s \, | \, S^{(-u)} = s^{(-u)}\big) \, = \, \dfrac{\displaystyle \alpha_{u-1}\Gamma \, P(s)\beta_u^\top}{\displaystyle \alpha_{u-1}\Gamma \, \beta_u^\top},
\end{equation}
especificamente no caso com distribuição estado dependente Poisson. O restante do código nos permite gerar o gráfico.
É óbvio que cada distribuição condicional tem uma forma diferente, pelo que a forma pode mudar visivelmente de uma vez para a seguinte. Na verdade,
as distribuições condicionais podem ser interpretadas como misturas das distribuições de probabilidade dependentes do estado do HMM com diferentes
parâmetros de mistura. Além disso, é impressionante que algumas das observações reais, que na Figura IV.1 são marcados como barras
negras, ficam perto dos limites do domínio positivo das probabillidades condicionais. Isto faz com que seja razoável utilizar as distribuições
condicionais para verificações de outliers, como será demonstrado na Seção V.2.
A seguir, vamos recorrer a um tipo especial de distribuição condicional, a distribuição das previsões de um HMM.
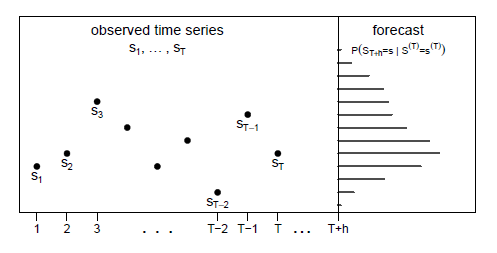
A idéia da previsão é calcular a probabilidade de certas observações ocorrerem no futuro. Ou seja, alguém está interessado na
derivação da função de probabilidade condicional de \(S_{t+h}\), dado \(S^{(T)} = s^{(T)}\), em que \(h\) é chamado horizonte de previsão.
Isso é demonstrado na Figura IV.2.
Figura IV.2: Previsão da distribuição de um HMM. Figura retirada do livro Zucchini & MacDonald (2009)
Como a distribuição da previsão \(P\big(\{S_{T+h} = s \, | \, S^{(T)} = s^{(T)}\}\big)\) de um HMM é um caso especial de uma distribuição
condicional, ela pode ser calculada de maneira semelhante à distribuição condicional \(P(S_u = s \, | \, S^{(-u)} = s^{(-u)})\) derivada na seção
anterior:
\begin{array}{rcl}
P\big(\{S_{T+h} = s \, | \, S^{(T)} = s^{(T)}\}\big) & = & \dfrac{\displaystyle P\big(\{S_{T+h} = s, S^{(T)} = s^{(T)}\}\big)}
{P\big(\{S^{(T)} = s^{(T)}\}\big)} \\[0.6em]
& = & \dfrac{\displaystyle \delta B_1 \cdots B_T \, \Gamma^h \, P(s)\pmb{1}^\top}{\displaystyle \delta B_1 \cdots B_T \pmb{1}^\top} \\[0.6em]
& = & \dfrac{\displaystyle \alpha_T \, \Gamma^h \, P(s)\pmb{1}^\top}{\displaystyle \alpha_T \pmb{1}^\top}\cdot
\end{array}
Usando a igualdade \(\displaystyle \phi_T=\dfrac{\alpha_T}{\alpha_T\pmb{1}^\top}\), isso pode ser reescrito como
\begin{equation}
P\big(\{S_{T+h} = s \, | \, S^{(T)} = s^{(T)}\}\big) \, = \, \phi_T \, \Gamma^h \, P(s)\pmb{1}^\top\cdot
\end{equation}
Aqui também, o algoritmo de dimensionamento da Seção III.3 pode ser usado para evitar subfluxo numérico.
A probabilidade de previsão também pode ser interpretada como uma mistura das distribuições dependentes do estado, ou seja,
\begin{equation}
P\big(\{S_{t+h} = s \, | \, S^{(T)} = s^{(T)}\}\big) \, = \, \displaystyle \sum_{i=1}^m \xi_i p_i(s),
\end{equation}
onde o coeficiente de mistura \(\xi_i\) da \(i\)-ésima componente é dado pela \(i\)-ésima entrada do vetor \(\phi_T \, \Gamma^h\).
Como toda a distribuição das probabilidades da previsão é conhecida, é possível fazer previsões por intervalo e não
apenas previsões pontuais. Teoricamente, é até possível fornecer distribuições conjuntas de previsões, no entanto, isso pode
exigir muita computação.
Além disso, pode-se mostrar que, à medida que o horizonte de previsão \(h\) aumenta, a distribuição da previsão converge para a
distribuição estacionária do HMM, ou seja,
\begin{equation}
\displaystyle \lim_{h\to\infty} P\big(\{S_{t+h} = s \, | \, S^{(T)} = s^{(T)}\}\big) \, = \, \delta \, P(s)\pmb{1}^\top\cdot
\end{equation}
Para uma demonstração deste limite veja o Exercício IV.4.3. Normalmente, a distribuição das previsões se aproxima da distribuição
estacionária do HMM relativamente rápido, como será demonstrado no seguinte exemplo.
Exemplo IV.2: Distribuição das previsões no caso das vendas de sabão.
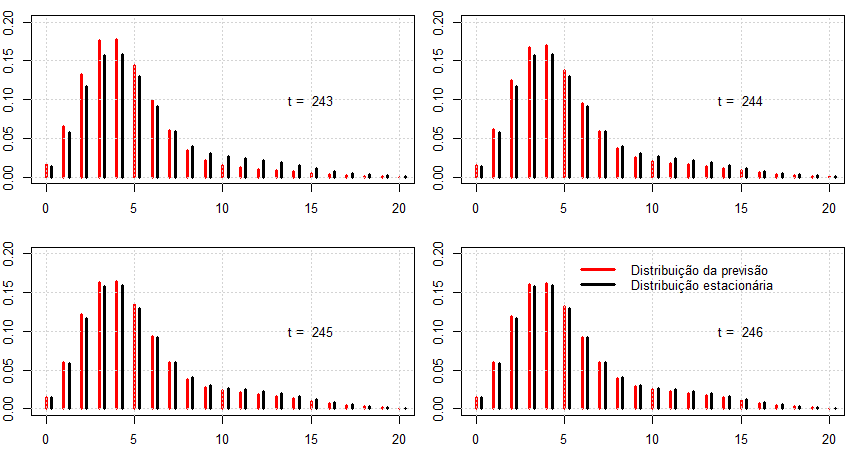
Continuando no exemplo da vendas de sabão, mostraremos o comportamente da distribuição das previsões quando utilizamos apenas dois estados e horizonte de
previsão \(h=4\) isto é, \(t = 243,\cdots,246\). Nós ajustamos a estes dados um HMM Poisson com dois estados no Exemplo III.2. Será este ajuste o utilizado
para gerarmos o gráfico a seguir.
Figura IV.3: Distribuição das previsões para um horizonte de previsão \(h = 4\), ou seja, para os instantes futuros \(t\in \{243,\cdots,246\}\). Em
vermelho apresentamos a distribuição das previsões comparada com a distribuição estacionária do HMM, em preto. Percebe-se que para um curto período de previsão, \(h=3,4\) estas
distribuições praticamente coincidem.
> prob.prevista = function(mod, h = 1, s = seq(0,20))
+ {
+ fb = forwardback(mod$x, mod$Pi, delta = compdelta(mod$Pi), distn = "pois",
+ pm = list(lambda = mod$pm$lambda))
+ Cadeia = new("markovchain", states = c("1", "2"), transitionMatrix = mod$Pi)
+ probabilidades = array(0, dim = length(s))
+ for (i in 1:length(s)) {
+ num = exp(fb$logalpha[length(mod$x),])%*%((Cadeia^h)[])%*%diag(dpois(s[i],lambda=mod$pm$lambda));
+ probabilidades[i] = sum(num)/exp(fb$LL)
+ }
+ return(probabilidades)
+ }
> prob.estacion = function(mod, s = seq(0,20))
+ {
+ estacion = array(0, dim = length(s))
+ for(i in 1:length(s)) {
+ estacion[i] = sum(compdelta(mod$Pi)%*%diag(dpois(s[i], lambda = mod$pm$lambda)))
+ }
+ return(estacion)
+ }
> estacionaria = prob.estacion(mod = soap.ajuste1)
> par(mfrow=c(2,2),mar=c(3,2,1,1), bg="white")
> for(i in 1:4) {
+ plot(seq(0,20), prob.prevista(mod = soap.ajuste1, h = i, s = seq(0,20)),
+ ylim = c(0, 0.2), xlab = "", ylab = "", col = "red", type="h", lwd = 3.5);
+ grid();
+ points(seq(0,20)+0.3, estacionaria, type="h", lwd = 3.5, col = "black")
+ text(15,0.10, paste("t = ", 242+i))
+ }
> legend(5,0.20, legend = c("Distribuição da previsão","Distribuição estacionária"),
+ col = c("red", "black"), lty = 1, lwd = 3.5, bty = "n")
A função prob.prevista acima escrita em código R nos permite obter a probabilidade das previsões
\begin{equation}
P\big(\{S_{T+h} = s \, | \, S^{(T)} = s^{(T)}\}\big) \, = \, \dfrac{\displaystyle \alpha_T \, \Gamma^h \, P(s)\pmb{1}^\top}{\displaystyle \alpha_T \pmb{1}^\top},
\end{equation}
especificamente no caso com distribuição estado dependente Poisson. Por sua vez, a função prob.estacion acima escrita em
código R nos permite obter a distribuição estacionária do HMM
\begin{equation}
\displaystyle \lim_{h\to\infty} P\big(\{S_{t+h} = s \, | \, S^{(T)} = s^{(T)}\}\big) \, = \, \delta \, P(s)\pmb{1}^\top,
\end{equation}
também específica para o caso com distribuição estado dependente Poisson. O restante do código nos permite gerar o gráfico. Chamamos
atenção novamente ao fato de que a distribuição da previsão para \(h = 4\) é quase igual à distribuição
estacionária do HMM.
Na seguinte seção, consideraremos outro tipo de inferência para HMMs, a inferência para os estados da Cadeia de Markov subjacente, chamada decodificação.
Uma questão muito natural que surge no contexto de muitas aplicações, por exemplo, todos os tipos de reconhecimento, quais são, considerando o
HMM estimado, os estados mais prováveis da Cadeia de Markov subjacente?
Por exemplo, no campo do reconhecimento de fala onde os HMMs foram aplicados pela primeira vez, os estados subjacentes da Cadeia de Markov representam as sílabas das
palavras que devem ser reconhecidas, enquanto as observações são palavras faladas e barulhos. Portanto, a matriz de probabilidades de transição
\(\Gamma\) pode ser gerada analisando palavras, por exemplo, de um dicionário e contando a aparência de certas sequências de sílabas. Em seguida, as
observações ruidosas devem ser analisadas e uma sequência adequada de estados da Cadeia de Markov, ou seja, uma sequência de sílabas e, portanto, de
palavras, devem ser encontradas.
Esse tipo de investigação de um HMM é chamado de decodificação. Distingue-se entre decodificação local que determina o estado
mais provável no tempo \(t\), independente dos outros tempos, e decodificação global que deriva a sequência mais provável de estados. Esses
dois serão descritos nas seções a seguir.
Reconsidere as probabilidades de avanço (forward) e retrocesso (backward), \(\alpha_t\) e \(\beta_t\), conforme definidas na Seção III.1. Para a derivação
do estado mais provável da Cadeia de Markov no momento \(t\), a seguinte declaração sobre essas probabilidades é muito útil:
\begin{equation}
\alpha_t(i) \beta_t(i) \, = \, P(\big( S^{(T)}=s^{(T)}, C_T=i\big)\cdot
\end{equation}
Usando as interpretações de \(\alpha_t(i)\) e \(\beta_t(i)\), como derivado na Seção III.1, a prova é feita por cálculo direto:
\begin{array}{rcl}
\alpha_t(i) \beta_t(i) & = & P\big(S_1=s_1,\cdots, S_t=s_t, C_t=i\big)\times P\big(S_{t+1}=s_{t+1},\cdots, S_T=s_T \, | \, C_t=i \big) \\
& = & P\big(S_1=s_1,\cdots, S_t=s_t \, | \, C_t=i\big)P\big( C_t=i\big)\times P\big(S_{t+1}=s_{t+1},\cdots, S_T=s_T \, | \, C_t=i \big) \\
& = & P(S_1=s_1,\cdots,S_T=s_T \, | \, C_t=i)P(C_t=i) \, = \, P(S_1=s_1,\cdots,S_T=s_T, C_t=i),
\end{array}
onde o terceiro passo decorre da propriedade de independência condicional do HMM.
Este resultado pode ser interpretado da seguinte maneira. \(\alpha_t(i)\beta_t(i)\) é a probabilidade conjunta das observações \(S^{(T)} = s^{(T)}\)
e a Cadeia de Markov \(C_t\) estar no estado \(i\) no momento \(t\). Portanto, a distribuição condicional de \(C_t\), dadas as observações,
\(P\big(\{C_t = i \, | \, S^{(T)} = s^{(T)}\}\big)\), pode ser obtida como
\begin{equation}
P\big(\{C_t = i \, | \, S^{(T)} = s^{(T)}\}\big) \, = \, \dfrac{\displaystyle P\big(\{C_t = i, S^{(T)} = s^{(T)}\}\big)}{\displaystyle P\big(\{S^{(T)} = s^{(T)}\}\big)}
\, = \, \dfrac{\alpha_t(i)\beta_t(i)}{L_T}\cdot
\end{equation}
Aqui, o \(L_T\) pode ser calculado usando o algoritmo de dimensionamento apresentado na Seção III.3. No entanto, para impedir o subfluxo numérico na
avaliação do termo \(\alpha_t(i)\beta_t(i)\), é necessário definir um novo algoritmo de escala para o cálculo do \(\beta_t(i)\). Isso pode,
por exemplo, ser alcançado usando os mesmos fatores de escala obtidos para o \(\alpha_t(i)\) no algoritmo da Seção III.3.
Assim, para cada vez que \(t\in \{1,\cdots,T\}\) pode-se determinar toda a distribuição do estado \(C_t\), dado o HMM observado. Por exemplo, no caso de dois
estados, temos
\begin{array}{rcl}
P\big(\{C_t = 1 \, | \, S^{(T)} = s^{(T)}\}\big) & = & \dfrac{\alpha_t(1)\beta_t(1)}{L_T}, \\[0.4em]
P\big(\{C_t = 2 \, | \, S^{(T)} = s^{(T)}\}\big) & = & \dfrac{\alpha_t(2)\beta_t(2)}{L_T}\cdot
\end{array}
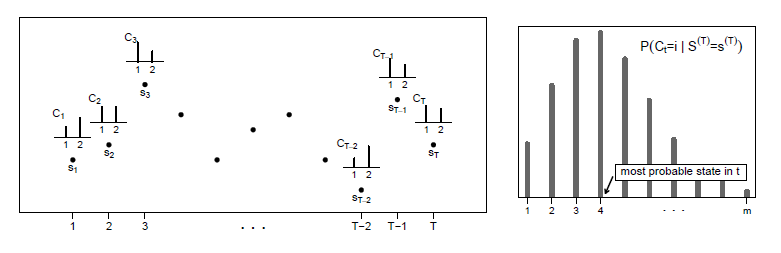
Isso é demonstrado no gráfico esquerdo da Figura IV.4.
Figura IV.4: Decodificação local para um HMM. Figura retirada do livro Zucchini & MacDonald (2009).
No caso mais geral de \(m\)-estados, \(P\big(\{C_t = i \, | \, S^{(T)} = s^{(T)}\}\big)\) é uma função de probabilidade discreta assumindo valores em \(1,\cdots,m\),
como mostrado no gráfico à direita da Figura IV.4.
Então, para cada \(t\in\{1,\cdots,m\}\) o estado mais provável \(i_t^*\), dadas as observações, é definido como
\begin{equation}
i_t^* \, = \, \underset{i\in \{1,\cdots,m\}}{\mbox{argmax}} P\big(\{C_t = i \, | \, S^{(T)} = s^{(T)}\}\big)\cdot
\end{equation}
Exemplo IV.3: Decodificação local no caso das vendas de sabão.
Continuando no exemplo da vendas de sabão, mostraremos o comportamente o resultado da decodificação local quando utilizamos o modelo de apenas dois estados.
Nós ajustamos a estes dados um HMM Poisson com dois estados no Exemplo III.2. Será este ajuste o utilizado para gerarmos o gráfico a seguir.
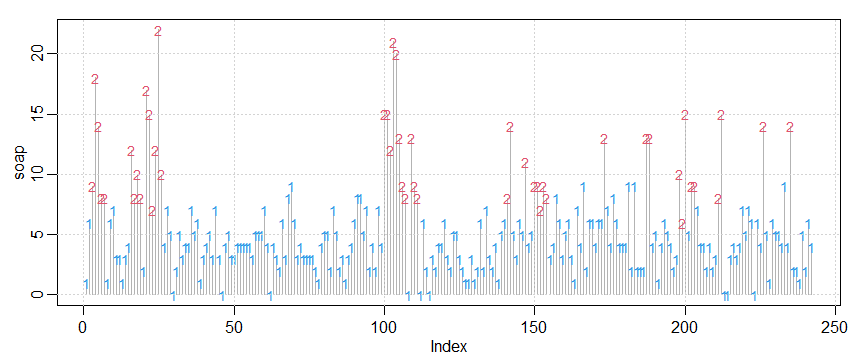
Figura IV.5: Resultado da decodificação local. Em vermelho claro aparece sempre o valor 2, representado os instantes
onde este foi o valor do estado estimado e em azul claro o valor 1, representando similarmente os instantes nos quais este foi o estado estimado.
> local.decoding = function(mod){
+ estados = array(0, dim = c(length(mod$x)))
+ for(i in 1:length(mod$x)){
+ estados[i] = which.max(Estep(mod$x, mod$Pi, mod$delta, "pois", list(lambda=mod$pm$lambda))$u[i,])}
+ return(estados)
+ }
> l.estados = local.decoding(mod = soap.ajuste1)
> par(mar = c(3,3,1,1), mgp = c(1.6,.6,0), mfrow=c(1,1))
> # dados e estados
> plot(soap, main="", ylab='soap', type='h', col=gray(.7))
> text(soap, col=6*l.estados-2, labels=l.estados, cex=.9)
> grid()
A função R, local.decoding, serve para identificarmos \(i_t^*\), \(t\in\{1,\cdots,m\}\) que maximiza
\begin{equation*}
P\big(\{C_t = i \, | \, S^{(T)} = s^{(T)}\}\big),
\end{equation*}
ou seja, realiza o procedimento chamado de decodificação local. O restante do código serve para criarmos o gráfico apresentado na Figura IV.5.
Esta abordagem determina o estado mais provável separadamente para cada \(t\), maximizando a probabilidade condicional \(P\big(\{C_t = i \, | \, S^{(T)} = s^{(T)}\}\big)\) e,
portanto, é chamada de decodificação local. No entanto, em muitas aplicações, é mais razoável considerar a probabilidade condicional
de todos os estados simultaneamente, isto é, determinar a sequência mais provável de estados. Essa abordagem é chamada decodificação
global e será descrita na seção a seguir.
Em muitas aplicações, especialmente em todos os campos de reconhecimento, não estamos interessados pelo estado mais provável para um tempo separado
\(t\), conforme fornecido pela decodificação local, mas pela sequência mais provável de estados ocultos. Isso significa que, em vez de maximizar o
valor da probabilidade condicional de um estado, \( P\big(\{C_t = i \, | \, S^{(T)} = s^{(T)}\}\big)\), tenta-se determinar a sequência de estados \((i_1^*,\cdots,i_T^*)\)
que maximiza a probabilidade condicional
\begin{equation}
(i_1^*,\cdots,i_T^*) \, = \, \underset{(i_1^*,\cdots,i_T^*)\in \{1,\cdots,m\}}{\mbox{argmax}} P\big(\{C_1 = i_1,\cdots,C_T=i_T \, | \, S^{(T)} = s^{(T)}\}\big)
\end{equation}
ou de forma equivalente e mais conveniente, a probabilidade conjunta
\begin{array}{rcl}
(i_1^*,\cdots,i_T^*) & = & \underset{(i_1^*,\cdots,i_T^*)\in \{1,\cdots,m\}}{\mbox{argmax}} P\big(\{C_1 = i_1,\cdots,C_T=i_T, S^{(T)} = s^{(T)}\}\big) \\
& = & \underset{(i_1^*,\cdots,i_T^*)\in \{1,\cdots,m\}}{\mbox{argmax}} (\delta_{_{i_1}}\gamma_{_{i_1,t_2}},\cdots,\gamma_{_{i_{T-1},i_T}})\big(p_{_{i_1}}(s_1)\cdots,p_{_{i_T}}(s_T)\big)\cdot
\end{array}
À primeira vista, pode-se supor que esse problema seja igual à realização da decodificação local para todos os \(t\in\{1,\cdots,T\}\), no
entanto, este método não produz o resultado correto. Isso se deve ao fato de a decodificação local ignorar parcialmente a matriz de probabilidades
de transição subjacente \(\Gamma\). Por exemplo, se de acordo com \(\Gamma\) algumas transições não forem possíveis, o caminho obtido
a partir da decodificação local pode ser impossível de ocorrer, ou seja, um caminho com probabilidade zero, mesmo que para cada \(t\) considerado separadamente
o estado mais provável seja escolhido.
Por essa razão, de fato, é preciso considerar todos os estados simultaneamente e maximizar a probabilidade conjunta fornecida acima. No entanto, como a avaliação
de todas as \(m^T\) probabilidades conjuntas exigiria computação muito intensiva, é razoável e viável usar um algoritmo de programação
dinâmica eficiente para a determinação da sequência mais provável de estados.
Um método de programação dinâmica eficiente que pode ser aplicado no contexto dos HMMs é o algoritmo de Viterbi. Para aplicar esse algoritmo,
precisamos definir uma variável auxiliar \(\nu_t(i)\):
\begin{equation}
\nu_t(i) \, = \, \underset{i_1,\cdots,i_{t-1}}{\mbox{max}} P\big(\{C_1 = i_1,\cdots,C_{t-1}=i_{t-1},C_t=i, S^{(t)} = s^{(t)}\}\big), \qquad t\in\{2,\cdots,T\},
\end{equation}
onde \(\nu_t(1)\) é dado por \(\nu_t(1)=P(C_1=i, S_1=s_1)\).
Isto significa que \(\nu_t(i)\) é a verossimilhança da distribuição conjunta das observações \(S^{(t)} = s^{(t)}\), a sequência
de estados \(C_1 = i_1,\cdots,C_{t-1} = i_{t-1}\) e o estado \(C_t = i\), maximizado em todas as sequências de estados possíveis \(i_1,\cdots,i_{t-1}\). Pode-se
demonstrar que as probabilidades \(\nu_t(i)\) satisfazem a seguinte recursão para \(t\in\{2,\cdots,T-1\}\):
\begin{equation}
\nu_{t+1}(j) \, = \, \left[ \underset{i}{\mbox{max}\big(\nu_t(i)\gamma_{i,j}\big)}\right] \big( p_j(s_{t+1})\big)\cdot
\end{equation}
Esta recursão fornece um meio eficiente de calcular a matriz \(T\times m\) dos valores \(\nu_t(j)\), \(t = 1,\cdots,T\); \(j = 1,\cdots,m\). A sequência necessária
de estados \(i_1^*,\cdots,i_T^*\) pode então ser determinada recursivamente a partir de
\begin{equation}
i_T^* \, = \, \underset{i\in\{1,\cdots,m\}}{\mbox{argmax}} \nu_T(i)
\end{equation}
e
\begin{equation}
i_t^* \, = \, \underset{i\in\{1,\cdots,m\}}{\mbox{argmax}} \nu_t(i)\gamma_{_{i,i_{t+1}^*}}, \qquad t=T-1,\cdots,1\cdot
\end{equation}
As etapas do algoritmo Viterbi podem ser interpretadas da seguinte maneira. A partir dos valores \(\nu_1(i)\); \(i = 1,\cdots,m\), isto é, as probabilidades conjuntas da
primeira observação e o primeiro estado da Cadeia de Markov sendo igual a \(i\); em cada uma das etapas a seguir da primeira recursão, para \(j = 1,\cdots,m\),
o estado \(i\) para o tempo \(t\) é determinado, o que maximiza a probabilidade conjunta da história das observações e os estados da Cadeia de Markov
até o tempo \(t\), e a observação e o estado no tempo \(t + 1\) são \(s_{t+1}\) e \(j\) respectivamente; então, as probabilidades resultantes
são denotadas como \(\nu_{t+1}(j)\); \(j = 1,\cdots,m\). Assim, no último passo da primeira recursão, obtém-se um vetor de probabilidades máximas,
um para cada estado \(j\) no tempo \(T\) e selecionamos \(i_T^*\) de modo que a probabilidade máxima seja maximizada. Então, em uma segunda recursão, que se
move para trás do tempo \(T-1\) até o tempo \(1\), em cada etapa o estado \(i_t^*\) é obtido de modo que a verossimilhança das observações
e os estados até o tempo \(t + 1\), onde o estado em \(t + 1\) é dado por \(i_{t+1}^*\), é maximizado. Essa segunda recursão é chamada de caminho
de retorno e a sequência ótima de estados resultante é chamada de caminho de Viterbi.
Observe que, como a verossimilhança a ser maximizada na decodificação global é um simples produto de probabilidades, conforme indicado no início
desta seção, também é possível maximizar a respectiva log-verossimilhança, a fim de evitar o influxo numérico. O algoritmo Viterbi
pode facilmente ser reescrito usando os logaritmos das probabilidades.
Também devemos mencionar que o algoritmo de Viterbi é aplicável para Cadeias de Markov subjacentes estacionárias e não estacionárias,
desde que neste último caso seja especificada a distribuição inicial \(\delta(1)\).
Finalmente, gostaríamos de nos referir à Figura IV.1 novamente, onde as cores de fundo das distribuições condicionais indicam os estados subjacentes
da Cadeia de Markov. Esses estados foram calculados usando o algoritmo Viterbi, ou seja, fazem parte da sequência de estados mais provável.
Na última seção, reconsideraremos a decodificação local e a aplicaremos na previsão de estados futuros.
Na Seção IV.3.1, mostramos como as informações sobre os estados subjacentes únicos da Cadeia de Markov podem ser obtidas usando a
decodificação local. Nisto sugerimos que alguém estava interessado em um dos estados passados. No entanto, o método de decodificação
local também pode ser usado para fornecer informações sobre estados no futuro.
Dadas as observações \(s_1,\cdots,s_n\) as seguintes declarações sobre estados passados, presentes ou futuros podem ser feitas a partir da
decodificação local:
\begin{equation}
P\big( C_t=i \, | \, S^{(T)}=s^{(T)}\big) \, = \, \left\{
\begin{array}{ccc}
\dfrac{\displaystyle \alpha_T\big(\Gamma^{t-T}(,i)\big)}{L_T} & \mbox{ para } t>T & \mbox{previsão de estado} \\[0.8em]
\dfrac{\displaystyle \alpha_T(i)}{L_T} & \mbox{ para } t=T & \mbox{filtro} \\[0.6em]
\dfrac{\displaystyle \alpha_t(i)\beta_t(i)}{L_T} & \mbox{ para } 1\leq t < T & \mbox{alisamento}
\end{array}\right.,
\end{equation}
onde \(\Gamma^{t-T}(,i)\) denota a \(i\)-ésima coluna da matriz \(\Gamma^{t-T}\).
As partes de filtragem e suavização para estados passados ou presentes são idênticas à decodificação local descrita acima. A
parte de previsão do estado é simplesmente uma generalização da decodificação local para \(t> T\).
Exemplo IV.4: Decodificação global do caso das vendas de sabão.
Utilizando os dados e resultados do Exemplo III.1 mostramos os estados estimados pelo algoritmo Viterbi, os dados correspondem à uma série de vendas semanais de
um produto específico de sabão em um supermercado. Dados fornecidos pelo Kilts Center for Marketing da Escola de Pós-Graduação em
Administração da Universidade de Chicago.
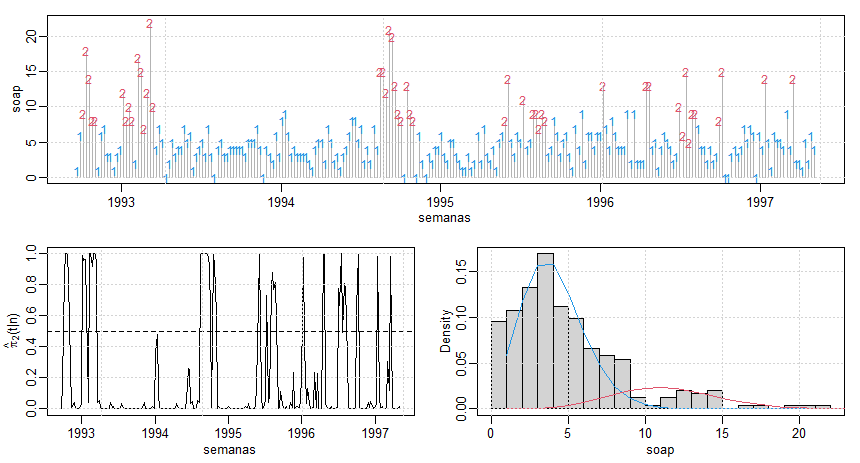
Figura IV.6: Superior: Série de vendas semanais de um produto de sabão específico e estados estimados. Em baixo,
à esquerda: Probabilidades de suavização. Em baixo à direita: histograma dos dados com as duas densidades estimadas sobrepostas (linhas sólidas).
Mostre que a distribuição condicional de \(S_u \, | \, s^{(-u)}\), ou seja, mostrar que a distribuição condicional de \(S_u\) dadas todas
as outras observações, \(s^{(-u)} = s_1,s_2,\cdots,s_{u-1},s_{u+1},\cdots,s_T\), pode ser obtida como
(a) a razão de duas verossimilhanças:
\begin{equation}
P\big( S_u=s \, | \, S^{(-u)}=s^{(-u)}\big) \, = \, \dfrac{\displaystyle \alpha_{u-1}\Gamma \, P(s)\beta_u^\top}
{\displaystyle \alpha_{u-1}\Gamma \, \beta_u^\top}, \qquad u=1,2,\cdots,T,
\end{equation}
onde \(\alpha_0=\delta\) e \(\beta_T=1\).
Observe que esta expressão mostra que a probabilidade condicional pode ser considerada como a razão de duas verossimilhanças de um HMM; o numerador
é a verossimilhança da série temporal observada, mas com a observação \(s_u\) substituída por \(s\); o denominador é a
verossimilhança da série temporal observada, mas com a observação \(s_u\) considerada ausente.
(b) uma mistura das distribuições de dependentes do estado:
\begin{equation}
P\big( S_u=s \, | \, S^{(-u)}=s^{(-u)}\big) \, = \, \sum_{i=1}^m \xi_u(i)p_i(s),
\end{equation}
onde \(\xi_u(i)=\displaystyle \dfrac{d_u(i)}{\displaystyle \sum_{j=1}^m d_u(j)}\) e \(d_u(i)\) é o produto da \(i\)-ésima entrada do vetor \(\alpha_{u-1}\Gamma\)
e da \(i\)-ésima entrada do vetor \(\beta_u\).
Essa expressão mostra que a probabilidade condicional pode ser considerada como uma mistura das distribuições dependentes do estado, \(p_i(s)\), em que
os coeficientes da mistura, \(\xi_u(i)\), são funções das observações \(s^{(-u)}\) e, de claro, os parâmetros do modelo.
Demonstrar que as probabilidades \(\nu_t(i)\) satisfazem a seguinte recursão para \(t\in\{2,\cdots,T-1\}\):
\begin{equation}
\nu_{t+1}(j) \, = \, \left[ \underset{i}{\mbox{max}\big(\nu_t(i)\gamma_{i,j}\big)}\right] \big( p_j(s_{t+1})\big)\cdot
\end{equation}
Considere um modelo HMM Poisson estacionário de \(m\) estados com os parâmetros \(\Gamma\) e \(\lambda=(\lambda_1,\lambda_2,\cdots,\lambda_m)\) e seja
\begin{equation}
p_{_{T+h}}(s) \, = \, P\big( S_{T+h}=s \, | \, S^{(T)}=s^{(T)}\big), \qquad s=0,1,2,\cdots,h, \quad h=1,2,\cdots
\end{equation}
a distribuição de previsão \(h\)-passos à frente.
(a) Mostre que a distribuição da previsão \(h\)-passos à frente é dada por
\begin{equation}
p_{_{T+h}}(s) \, = \, \sum_{i=1}^m \xi_i p_i(s),
\end{equation}
onde \(xi_i\) é a \(i\)-ésima entrada do vetor \(\dfrac{\displaystyle \alpha_T \Gamma^h}{\displaystyle \alpha_T \pmb{1}^\top}\).
(b) Mostre que, à medida que o horizonte de previsão, \(h\), se torna grande, a distribuição da previsão se aproxima
\begin{equation}
\delta P(s)\pmb{1}^\top \, = \, \sum_{i=1}^m \delta_i p_i(s),
\end{equation}
onde \(P(s)\) é uma matriz diagonal com entradas diagonais \(p_i(s)=P(S_t=s \, | \, C_t=i)\), \(i=1,2,\cdots,m\) e \(\delta\) é a distribuição
estacionária da Cadeia de Markov, isto é, a solução para o sistema de equações \(\delta = \delta \Gamma\) sujeita a \(\delta\pmb{1}^\top = 1\).
Use o fato de que, para um vetor arbitrário, digamos \(\eta\), cujas entradas somam um, o vetor \(\eta\Gamma^h\) se aproxima de \(\delta\) à medida que
\(h\) aumenta.
Aplique a decodificação local e global a um modelo de três estados para a série de vendas de sabão apresentada na introdução
e calcule os resultados para ver como as conclusões diferem.
Calcule as previsões do estado \(h\) passos à frente para a série de vendas sabão, para \(h = 2\) a 5. Qual é a proximidade dessas
distribuições da distribuição estacionária da Cadeia de Markov?
(a) Usando a mesma sequência de números aleatórios em cada caso, gere sequências de comprimento 1000 a partir dos HMMs de Poisson com
\begin{equation}
\Gamma \, = \, \begin{pmatrix} 0.8 & 0.1 & 0.1 \\ 0.1 & 0.8 & 0.1 \\ 0.1 & 0.1 & 0.8 \end{pmatrix}
\end{equation}
e (i) \(\lambda=(10, 20, 30)\) e (ii) \(\lambda=(15, 20, 25)\). Mantenha um registro da sequência de estados, que deve ser a mesma em (i) e (ii).
(b) Use o algoritmo Viterbi para inferir a sequência mais provável de estados em cada caso e compare essas duas sequências com a verdadeira
sequência subjacente, ou seja, a geradora.
(c) Que conclusões você tira sobre a precisão do algoritmo Viterbi?
Distribuição de previsões bivariadas para HMMs:
(a) Encontre a distribuição conjunta de \(S_{T+1}\) e \(S_{T+2}\), dada \(S^{(T)}\), da forma mais simples possível.
(b) Para os dados da série de vendas de sabão, encontre \(P\big(S_{T+1}\leq 10, S_{T+2}\leq 10 \, | \, S^{(T)} \big)\).
Prove que
\begin{equation}
P\big( C_{T+h}=i \, | \, S^{(T)}=s^{(T)}\big) \, = \, \dfrac{\displaystyle \alpha_T\big(\Gamma^{h}(,i)\big)}{L_T}
\, = \, \phi_T \big(\Gamma^{h}(,i)\big) \, = \, \phi_T \Gamma^h,
\end{equation}
onde \(\phi_T=\alpha_T/\alpha_T\pmb{1}^\top\). Isto significa que, quando \(h\to\infty\), \(\phi_T \Gamma^h\) se aproxima da distribuição estacionária da Cadeia de Markov.