- A natureza dos dados da série temporal
- Modelos estatísticos de séries temporais
- Medidas de dependência: autocorrelação e correlação cruzada
- Série temporal estacionária
- Estimação da correlação
- Séries multidimensionais
- Exercícios
I.1 A natureza dos dados da série temporal
Alguns dos problemas e questões de interesse para o analista prospectivo de séries temporais podem ser melhor expostos considerando dados experimentais reais extraídos de diferentes áreas temáticas. Os casos a seguir ilustram alguns dos tipos comuns de dados de séries temporais experimentais, bem como algumas das perguntas estatísticas que podem ser feitas sobre esses dados.
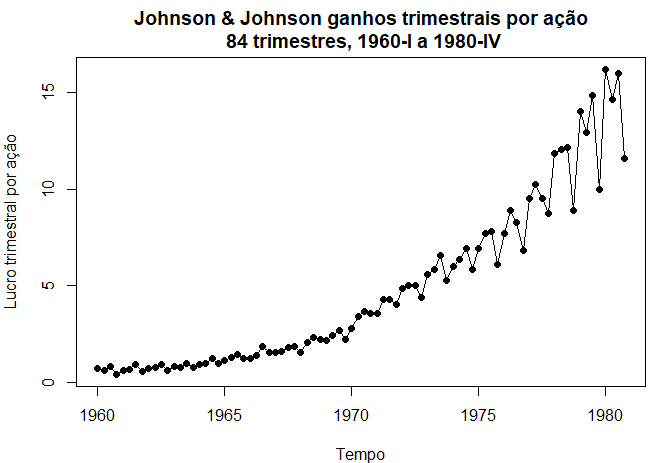
Exemplo I.1. Lucro trimestral da Johnson & Johnson
A figura abaixo mostra o lucro trimestral por ação da empresa norte-americana Johnson & Johnson, fornecido pelo professor Paul Griffin (comunicação pessoal) da Graduate School of Management, Universidade da Califórnia, Davis. Há 84 trimestres (21 anos) medidos desde o primeiro trimestre de 1960 até o último trimestre de 1980. A modelagem de tais séries começa observando os padrões primários na história do tempo. Nesse caso, observe a tendência subjacente gradualmente crescente e a variação bastante regular sobreposta à tendência que parece se repetir ao longo dos trimestres. Métodos para analisar dados como estes são explorados no Capítulo II usando técnicas de regressão e no Capítulo VI, usando modelagem de equações estruturais.
 |
|---|
É claro que os dados no arquivo jj estão preparados como uma série temporal trimestral. Caso essa não seja a situação, ou seja, caso os dados que você tiver não estiverem nesse formato e sejam somente uma sequência de números, podemos convertê-los no formato de série temporal da seguinte forma:
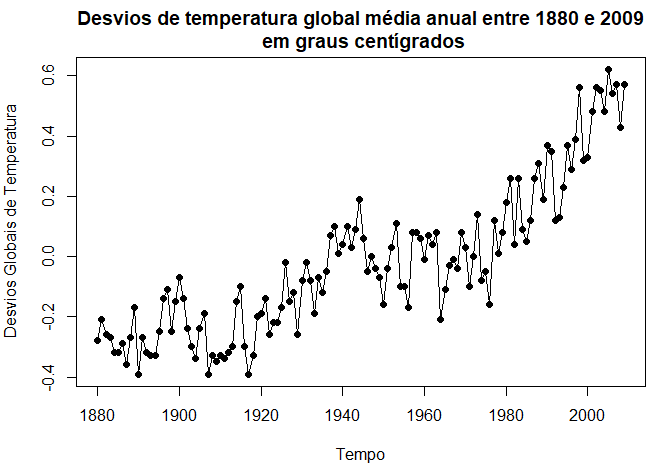
Exemplo I.2. Aquecimento global
Considere o registro da série de temperatura global mostrado na figura abaixo. Os dados são o índice médio global da temperatura do oceano entre 1880 e 2009, com o período base de 1951-1980. Em particular, os dados são desvios, medidos em graus centígrados, da média de 1951-1980 e são uma atualização de Hansen et al. (2006). Notamos uma aparente tendência ascendente na série durante a última parte do século XX que tem sido usada como um argumento para a hipótese do aquecimento global. Note-se também o nivelamento por volta de 1935 e, em seguida, outra tendéncia bastante acentuada em 1970. A questão de interesse dos defensores do aquecimento global e dos oponentes é se a tendência geral é natural ou se é causada por alguma interface induzida pelo homem. O problema II.8 examina 634 anos de dados de sedimentos glaciais que podem ser considerados como um proxy de temperatura de longo prazo. Tais mudanças percentuais na temperatura não parecem ser incomuns durante um período de 100 anos. Mais uma vez, a questão da tendência é mais interessante do que periodicidades específicas.
 |
|---|
Questões mais envolvidas desenvolvem-se em aplicações às ciências físicas.
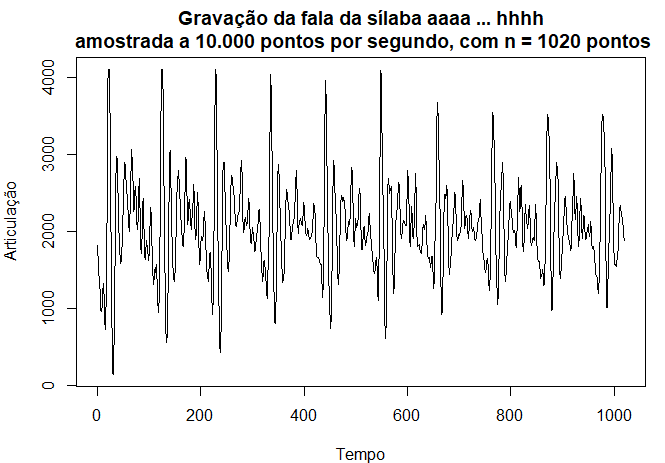
Exemplo I.3. Dados de fala
A figura abaixo mostra uma pequena amostra de 0.1 segundo e equivalem a 1000 pontos de fala gravada para a frase aaa ... hhh, e notamos a natureza repetitiva do sinal e as periodicidades regulares. Um problema atual de grande interesse é o reconhecimento por computador da fala, o que exigiria a conversão desse sinal específico na frase gravada aaa ... hhh. A análise espectral pode ser usada neste contexto para produzir uma assinatura dessa frase que pode ser comparada com assinaturas de várias sílabas da biblioteca para procurar uma correspondência.
Pode-se notar imediatamente a repetição bastante regular de pequenas ondas. A separação entre os pacotes é conhecida como o período do piche e representa a resposta do trato vocal a uma sequência periódica de pulsos estimulada pela abertura e fechamento da glote.
 |
|---|
O seguinte exemplo utiliza o conceito de retornos ou mudança percentual para dados financeiros. Seja \(P_t\) o preço de um ativo no período \(t\). O log retorno ou simplesmente retorno de um ativo financeiro é definido como \begin{equation} r_t=\ln(P_t/P_{t-1})\cdot \end{equation} Na prática, é preferível trabalhar com retornos, que são livres de escala e supostamente têm propriedades estatísticas mais interessantes, como estacionariedade.
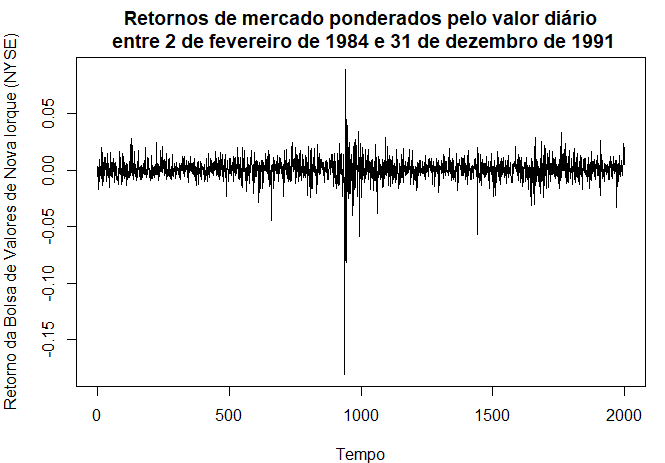
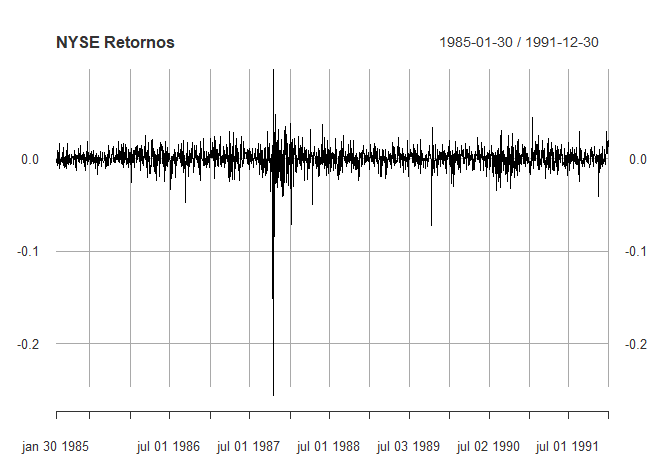
Exemplo I.4. Bolsa de Valores de Nova Iorque
Como exemplo de dados de séries temporais financeiras, a figura abaixo mostra os dados diários dos retornos ou mudança percentual da Bolsa de Valores de Nova York (NYSE) de 2 de Fevereiro de 1984 a 31 de Dezembro de 1991. Detectamos o crash de 19 de Outubro de 1987. Os dados mostrados na figura são típicos de dados de retornos. A média da série parece ser estável, com uma média de retorno de aproximadamente zero, porém a volatilidade ou variabilidade dos dados apresenta variações ao longo do tempo.
De fato, os dados mostram um agrupamento de volatilidade, ou seja, os períodos altamente voláteis tendem a ser agrupados. Um problema na análise de este tipo de dados financeiros é para prever a volatilidade dos retornos futuros. Modelos como os ARCH e GARCH (Engle, 1982; Bollerslev, 1986) e modelos estocásticos de volatilidade (Harvey, Ruiz e Shephard, 1994) têm sido desenvolvidos para lidar com estes problemas. Vamos discutir estes modelos e a análise dos dados financeiros nos Capítulo V e Capítulo VI destas notas.
Os dados mostrados são os retornos do mercado ponderados pelo valor diário entre 2 de fevereiro de 1984 e 31 de dezembro de 1991, ou seja, 2000 dias de negociação. O crash de 19 de outubro de 1987 ocorreu no instante t = 938.
 |
|---|
Pode-se utiizar o fato de que, se \(X_t\) é o valor real do índice da Bolsa de Valores de Nova York (NYSE) e \begin{equation*} r_t = \dfrac{X_t-X_{t-1}}{X_{t-1}} \end{equation*} é o retorno, então \(1+r_t = X_t/X_{t-1}\) e \(\log(1+r_t)=\log(X_t/X_{t-1})=\log(X_t)-\log(X_{t-1})\approx r_t\). Isto pode ser observado pela decomposição \begin{equation} \log(1+p)=p-\frac{p^2}{2}+\frac{p^3}{3}-\cdots \end{equation} para \(-1< p\leq 1\). Caso \(p\) esteja próximo de zero, os termos de ordem mais alta na expansão são insignificantes.
O conjunto de dados, como mencionamos, está disponível no pacote astsa, mas pode-se utilizar o pacote quantmod da seguinte forma:
 |
|---|
Observemos que os dados mais antigos ainda disponíveis desta forma correspondem a 30 de janeiro de 1985.
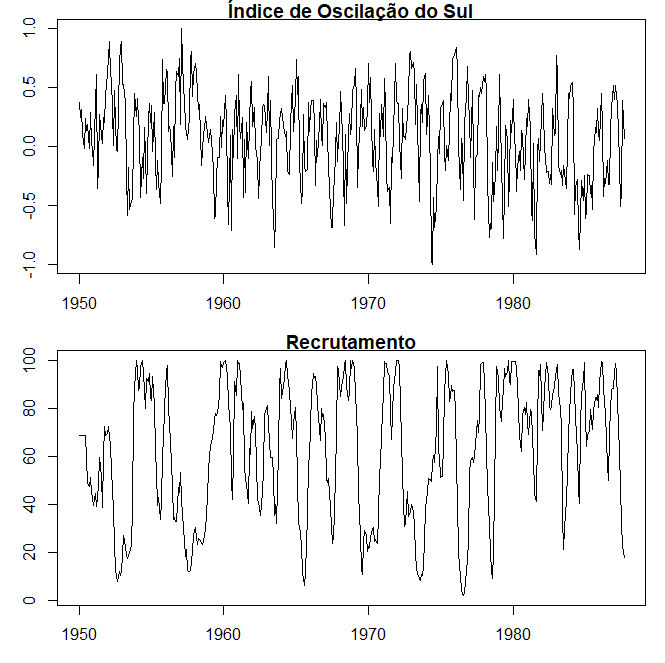
Exemplo I.5. El Niño e a População de Peixes
Podemos também estar interessados em analisar várias séries temporais ao mesmo tempo. A figura abaixo mostra os valores mensais de uma série ambiental chamada Índice de Oscilação do Sul (SOI) e Recrutamento associado, ou seja, o número de novos peixes, fornecidas pelo Dr. Roy Mendelssohn do Pacific Environmental Fisheries Group (comunicação pessoal). Ambas as séries são para um período de 453 meses, variando ao longo dos anos 1950 a 1987. A SOI mede as mudanças na pressão atmosférica, relacionadas com as temperaturas da superfície do mar no Oceano Pacífico central.
O Oceano Pacífico central aquece a cada três a sete anos devido ao efeito do El Niño, que tem sido responsável, em particular, pelas inundações de 1997 nas regiões do centro-oeste dos Estados Unidos. Ambas as séries da Figura tendem a exibir repetitivos ciclos regulares que são facilmente visíveis. Este períodico é de interesse porque os processos subjacentes de interesse podem ser regulares e a taxa ou frequência de oscilação que caracteriza o comportamento da série subjacente ajudaria a identificá-los. Também se pode observar que os ciclos da SOI estão a repetir-se a um ritmo mais rápido do que os ciclos da série de recrutamento. A série de recrutamento também apresenta vários tipos de oscilações, uma frequência mais rápida que parece repetir-se a cada 12 meses e uma que parece repetir-se a cada 50 meses. O estudo dos tipos de ciclos e as suas resistências são objeto do Capítulo IV. As duas séries também tendem a estar um pouco relacionadas; é fácil imaginar que, de alguma forma a população de peixes é dependente do SOI. Talvez até mesmo uma relação desfasada exista, com a SOI sinalizando mudanças na população de peixes. Esta possibilidade sugere tentar alguma versão da análise de regressão como um procedimento para relacionar as duas séries.
A modelagem da função de transferência, conforme considerado no Capítulo V, pode ser aplicado neste caso para obter um modelo relativo ao recrutamento segundo seu próprio passado e os valores passados da SOI.
 |
|---|
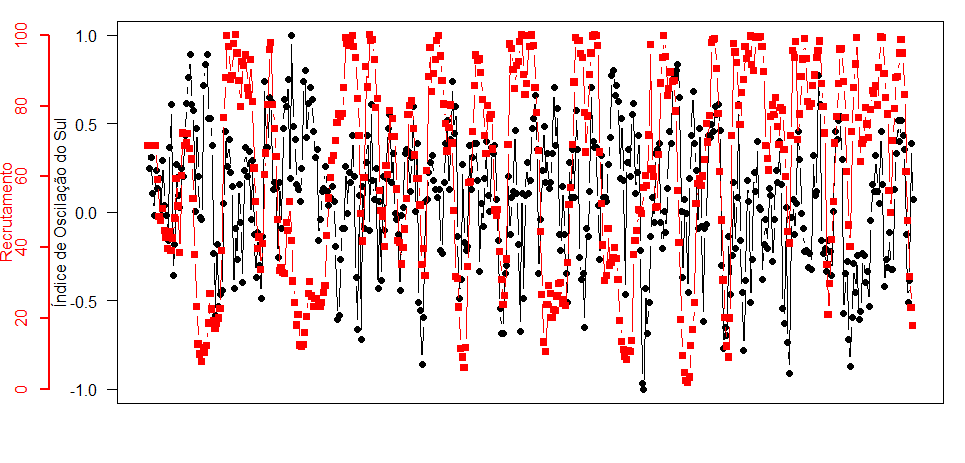
Uma outra forma de mostrar duas ou mais séries, supostamente relacionadas, é apresentando-as no mesmo gráfico com eixos diferentes segundo os comandos a seguir:
 |
|---|
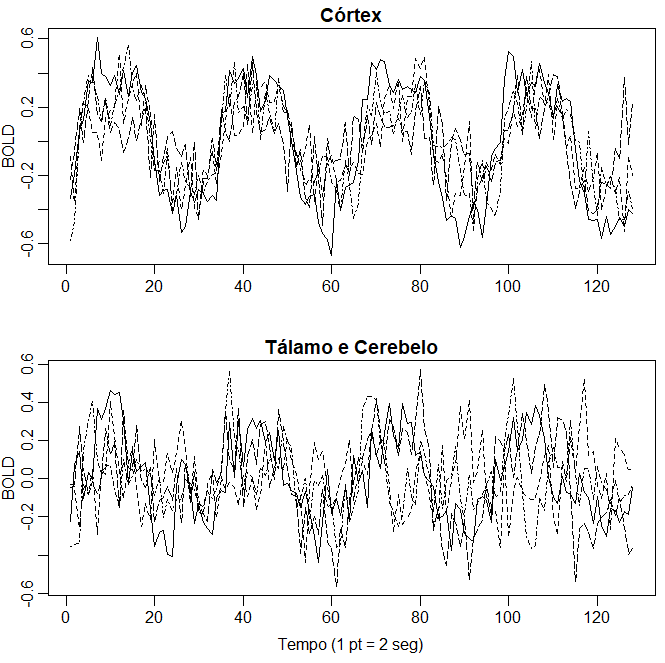
Exemplo I.6. Imagem fMRI
Um problema fundamental na estatística clássica ocorre quando nos é dada uma coleção de séries independentes ou vetores de séries, gerados sob diferentes condições experimentais ou configurações de tratamento. Tal conjunto de séries é mostrado na figura abaixo onde observamos os dados coletados em vários locais no cérebro através da ressonância magnética funcional (fMRI). Neste exemplo, os sujeitos foram submetidos a escovação periódica na mão. O estímulo foi aplicado durante 32 segundos e depois parado durante 32 segundos; assim, o período do sinal é de 64 segundos. A taxa de amostragem foi de uma observação a cada 2 segundos durante 256 segundos (n = 128). Para este exemplo, calculamos a média dos resultados sobre sujeitos.
As séries mostradas na figura abaixo são medidas consecutivas de intensidade de sinal dependente do nível de oxigenação do sangue (BOLD), que mede áreas de ativação no cérebro. Observe que as periodicidades aparecem fortemente no córtex motor e menos fortemente no tálamo e no cerebelo. O fato de alguém ter séries de diferentes áreas do cérebro sugere testar se as áreas estão respondendo de maneira diferente ao estímulo da escova. A Análise de Variância realiza isso em estatística clássicas e mostraremos, na Capítulo VII, como essas técnicas clássicas se estendem ao caso das séries temporais, levando a uma Análise Espectral de Variância.
 |
|---|
Observe que neste exemplo ambos os gráficos têm a mesma escala, por isso, caso consideremos apresentá-los juntos se sobrepoêm, o que não deve permitir interpretá-los.
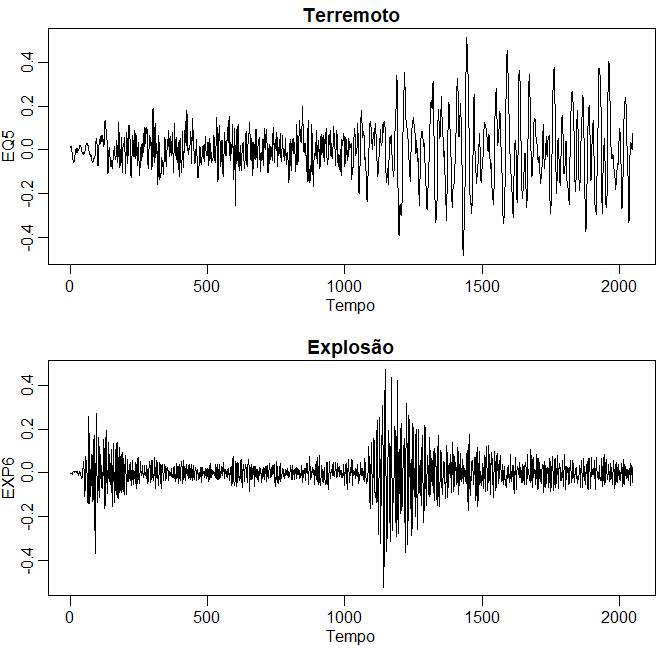
Exemplo I.7. Terremotos e explosões
Como exemplo final, as séries da figura abaixo representam duas fases ou chegadas ao longo da superfície, denotadas por \(P\), \(t = 1,\cdots,1024\) e \(S\), \(t = 1025,\cdots,2048\), em uma estação de gravação sísmica. Os instrumentos de gravação na Escandinávia estão observando terremotos e explosões de mineração mostradas na figura. O problema geral de interesse é distinguir ou discriminar entre formas de onda geradas por terremotos e aquelas geradas por explosões.
As características que podem ser importantes são as amplas taxas de amplitude da primeira fase \(P\) para a segunda fase \(S\), que tendem a ser menores para terremotos do que para explosões. No caso dos dois eventos na figura abaixo, a relação de amplitudes máximas parece ser um pouco menor que 0.5 para o terremoto e cerca de 1 para a explosão. Caso contrário, observe que existe uma diferença sutil na natureza periódica da fase \(S\) do terremoto. Podemos novamente pensar em análise espectral da variância para testar a igualdade dos componentes periódicos de terremotos e explosões. Gostaríamos também de poder classificar os futuros componentes \(P\) e \(S\) de eventos de origem desconhecida, levando à análise discriminante de séries temporais desenvolvido no Capítulo VII.
 |
|---|
I.2 Modelos estatísticos de séries temporais
O objetivo principal da análise de séries temporais é desenvolver modelos matemáticos que forneçam descrições plausíveis para dados amostrais, como os encontrados na seção anterior. A fim de fornecer um cenário estatístico para descrever o caráter de dados que aparentemente flutuam de maneira aleatória ao longo do tempo, assumimos que uma série temporal pode ser definida como uma coleção de variáveis aleatórias indexadas de acordo com a ordem em que são obtidos no tempo. Por exemplo, podemos considerar uma série temporal como uma sequência de variáveis aleatórias \(X_1,X_2,X_3,\cdots\), onde a variável aleatória \(X_1\) denota o valor tomado pela série no primeiro ponto de tempo, a variável \(X_2\) denota o valor para o segundo período de tempo, \(X_3\) denota o valor para o terceiro período de tempo e assim por diante. Em geral, uma coleção de variáveis aleatórias \(\{X_t\}\), indexadas por \(t\) é referida como um processo estocástico. Neste texto, \(t\) será tipicamente discreto e variará sobre os inteiros \(t = 0, \pm 1,\pm 2,\cdots\) ou algum subconjunto dos inteiros. Os valores observados de um processo estocástico são referidos como uma realização do processo estocástico. Como ficará claro no contexto de nossas discussões, usamos o termo série temporal se estamos nos referindo genericamente ao processo ou a uma realização particular e não fazemos nenhuma distinção notacional entre os dois conceitos.
É convencional exibir uma série temporal amostral graficamente, plotando os valores das variáveis aleatórias no eixo vertical ou ordenadas, com a escala de tempo como a abscissa. Geralmente, é conveniente conectar os valores em períodos de tempo adjacentes para reconstruir visualmente algumas séries temporais contínuas hipotéticas originais que podem ter produzido esses valores como uma amostra discreta. Muitas das séries discutidas na seção anterior, por exemplo, poderiam ter sido observadas em qualquer ponto contínuo no tempo e são conceitualmente mais adequadamente tratados como séries temporais contínuas. A aproximação dessas séries por séries com parâmetro de tempo discreto amostradas em pontos de tempo igualmente espaçados é simplesmente um reconhecimento de que os dados amostrados serão, na maior parte dos casos, discretos devido a restrições inerentes ao método de coleta.
Além disso, as técnicas de análise são viáveis usando computadores, que são limitados a cálculos digitais. Os desenvolvimentos teóricos também se apóiam na idéia de que uma série temporal de parâmetros contínuos devem ser especificadas em termos de funções de distribuição de dimensão finita definidas ao longo de um número infinito de pontos no tempo. Isso não quer dizer que a seleção do intervalo ou taxa de amostragem não seja de consideração extremamente importante. A aparência dos dados pode ser alterada completamente, adotando-se uma taxa de amostragem insuficiente. Esse fenômeno leva a uma distorção chamada efeito de aliasing, que será considerado na Seção IV.2.
A característica visual fundamental que distingue as diferentes séries mostradas nos exemplos é seus diferentes graus de suavidade. Uma explicação possível para essa suavidade é que esteja sendo induzida pela suposição de que pontos adjacentes no tempo são correlacionados, de modo que o valor da série no tempo \(t\), digamos, \(X_t\), depende de alguma forma dos valores passados \(X_{t-1},X_{t-2},\cdots\). Este modelo expressa uma maneira fundamental em que podemos pensar em gerar séries temporais de aparência realista. Para começar a desenvolver uma abordagem para usar coleções de variáveis aleatórias para modelar séries temporais, considere o seguinte exemplo.
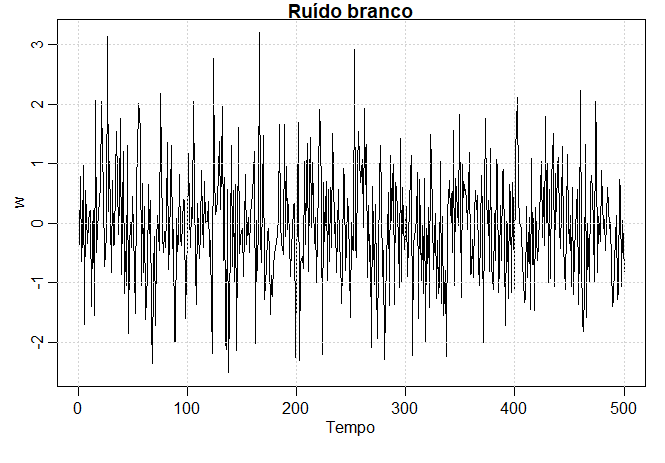
Exemplo I.8. Ruído branco
Um tipo simples de série simulada pode ser uma coleção de variáveis aleatórias não correlacionadas \(W_t\), com média 0 e variância finita \(\sigma_{_W}^2\). A série temporal gerada a partir de variáveis não correlacionadas é usada como modelo para o ruído em aplicações de engenharia, onde é chamado ruído branco. A designação branco origina-se da analogia com a luz branca e indica que todas as possíveis oscilações periódicas estão presentes com igual força.
Às vezes, também exigiremos que o ruído branco sejam variáveis aleatórias independente e identicamente distribuídas com média 0 e variância \(\sigma_{_W}^2\). Vamos distinguir este caso dizendo ruído branco independente. Uma série de ruído branco particularmente útil é o ruído branco gaussiano, em que o peso é uma variável aleatória normal independente, com média 0 e variância \(\sigma_{_W}^2\); ou mais sucintamente, com \(N(0,\sigma_{_W}^2)\).
A figura abaixo mostra uma coleção de 500 variáveis aleatórias, esperança 0 e \(\sigma^2_{_W}=1\), plotadas na ordem em que foram geradas. A série resultante tem uma leve semelhança com a explosão no Exemplo I.7, mas não é suave o suficiente para servir como um modelo plausível para qualquer outra série experimental. O enredo tende a mostrar visualmente uma mistura de muitos tipos diferentes de oscilações na série de ruído branco.
 |
|---|
Se o comportamento estocástico de todas as séries temporais pudesse ser explicado em termos do modelo de ruído branco, os métodos estatísticos clássicos seriam suficientes. Duas maneiras de introduzir correlação serial e mais suavidade em modelos de séries temporais são fornecidas nos Exemplos I.9 e I.10.
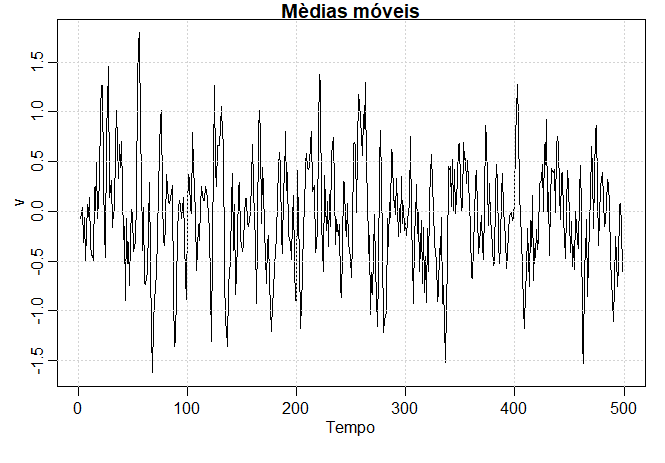
Exemplo I.9. Médias Móveis
Podemos substituir a série de ruído branco por uma média móvel que suaviza a série. Por exemplo, considere a substituição de \(W_t\) no Exemplo I.8 por uma média de seu valor atual e seus vizinhos imediatos no passado e no futuro. Isto é, \begin{equation} V_t=\dfrac{1}{3}\Big( W_{t-1}+W_t+W_{t+1}\Big), \end{equation} que leva à série mostrada na figura logo abaixo. Inspecionar a série mostra uma versão mais suave da primeira série, refletindo o fato de que as oscilações mais lentas são mais aparentes e algumas das oscilações mais rápidas são removidas. Começamos a notar uma semelhança com o SOI no Exemplo I.5, ou talvez, com algumas das séries de fMRI no Exemplo I.6.
Para reproduzir a figura em R, use os seguintes comandos. Com o comando filter construímos a combinação linear dos valores de uma sére, como indica o modelo de médias móveis.
 |
|---|
A série de fala no Exemplo I.3 e a série de Recrutamento no Exemplo I.5, bem como algumas das séries de fMRI na Figura I.6, diferem da série de média móvel porque um tipo particular de comportamento oscilatório parece predominar, produzindo um tipo de comportamento sinusoidal. Existem vários métodos para gerar séries com esse comportamento quase periódico; ilustramos um popular método baseado no modelo autoregressivo considerado no Capítulo III.
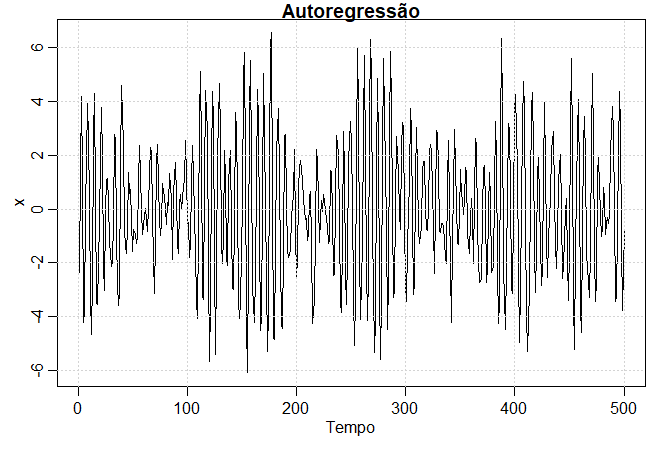
Exemplo I.10. Autoregressões
Suponha que consideremos a série de ruído branco do Exemplo I.8 como entrada e calculemos a saída usando a equação de segunda ordem \begin{equation} X_t \, = \, X_{t-1}-0.9 X_{t-2}+W_t, \end{equation} sucessivamente para \(t = 1,2,\cdots,500\). Esta equação representa uma regressão ou predição do valor atual \(X_t\) de uma série temporal como uma função dos dois últimos valores da série e, portanto, o termo autoregressão é sugerido como modelo. Existe um problema com os valores de inicialização; porque a equação acima também depende das condições iniciais \(X_0\) e \(X_1\), mas assumindo que temos esses valores, geramos os valores sucessivos por substituição. A série de resultados resultante é mostrada na figura a seguir, e notamos o comportamento periódico da série, que é semelhante ao exibido pela série de fala no Exemplo I.3. O modelo autorregressivo acima e suas generalizações podem ser usados como um modelo subjacente para muitas séries observadas e serão estudados em detalhes no Capítulo III.
 |
|---|
Como no exemplo anterior, os dados são obtidos por um filtro de ruído branco. A função filter usa zeros para os valores iniciais. Nesse caso, \(X_1 = W_1\) e \(X_2 = X_1 + W_2 = W_1 + W_2\) e assim por diante, de maneira que os primeiros valores não satisfazem a equação de segunda ordem acima. Uma solução fácil é executar o filtro por mais tempo do que o necessário e remover os valores iniciais.
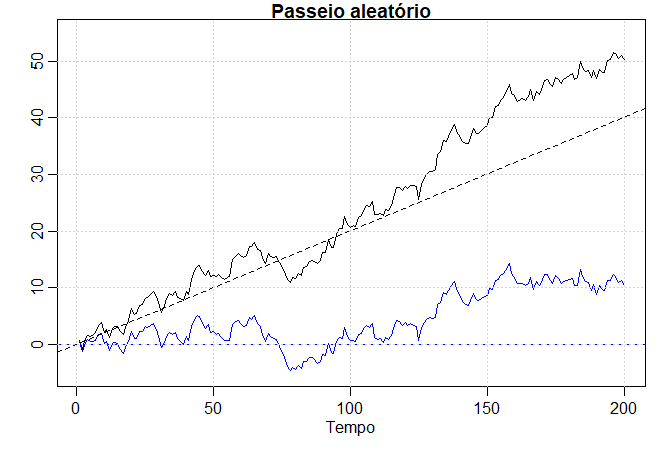
Exemplo I.11. Passeio aleatório com tendência
Um modelo para analisar a tendência, como visto nos dados de temperatura global no Exemplo I.2, é o passeio aleatório com modelo de tendência dado por \begin{equation} X_t = \delta+X_{t-1}+W_t, \end{equation} para \(t = 1,2,\cdots\), com condição inicial \(X_0 = 0\) e onde \(W_t\) é ruído branco. A constante \(\delta\) é chamada de tendência e quando \(\delta= 0\) o modelo acima é chamado simplesmente de um passeio aleatório.
O termo passeio aleatório vem do fato de que, quando \(\delta = 0\), o valor da série temporal no tempo \(t\) é o valor da série no tempo \(t-1\) mais um movimento completamente aleatório determinado por \(W_t\). Observe que podemos reescrever o modelo acima como uma soma cumulativa de variações de ruído branco. Isto é, \begin{equation} X_t \, = \, \delta t + \sum_{j=1}^t W_j, \end{equation} para \(t = 1,2,\cdots\).
A figura mostra 200 observações geradas a partir do modelo acima com \(\delta = 0\) e \(\delta = 0.2\), e com \(\sigma_W = 1\). Para comparação, também sobrepomos a linha reta \(0.2t\) no gráfico. Para reproduzir a figura abaixo em R, use o seguinte código, observe o uso de vários comandos por linha usando um ponto-e-vírgula.
 |
|---|
Exemplo I.12. Sinal no ruído
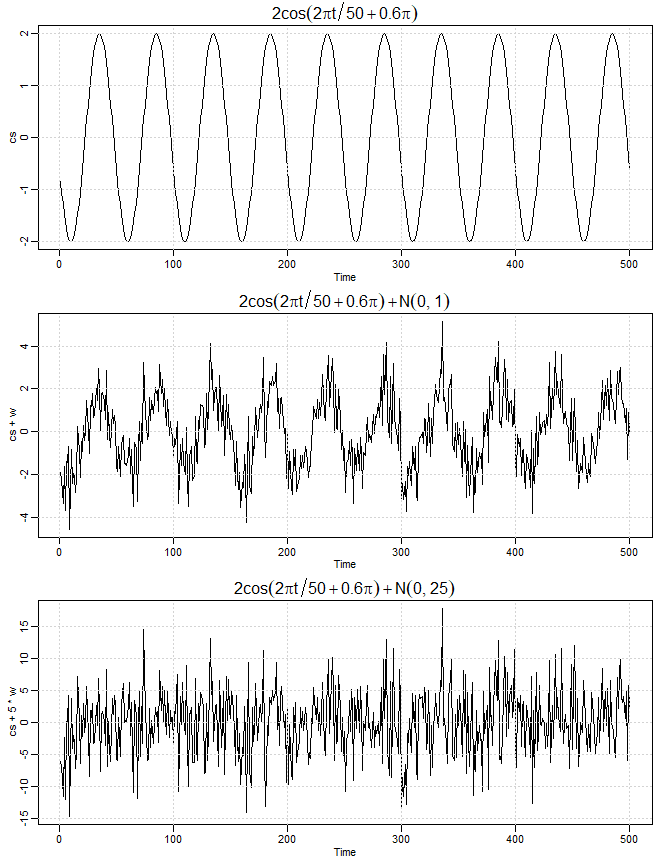
Muitos modelos realistas para gerar séries temporais assumem um sinal subjacente com alguma variação periódica consistente, contaminada pela adição de um ruído aleatório. Por exemplo, podemos detectar o ciclo regular na série de fMRI exibida no topo do figura no Exemplo I.6.
Considere o modelo \begin{equation} X_t = 2\cos\big( 2\pi (t+15)/50\big)+W_t, \end{equation} para \(t=1,2,\cdots,500\) onde o primeiro termo é considerado como o sinal, mostrado no painel superior da figura abaixo.
Notamos que uma forma de onda sinusoidal pode ser escrita como \begin{equation} A\cos \big( 2\pi \omega t+\phi\big), \end{equation} onde \(A\) é a amplitude, \(\omega\) a frequência de oscilação e \(\phi\) é uma mudança de fase. Na expressão acima \(A = 2\), \(\omega = 1/50\), ou seja, um ciclo a cada 50 pontos no tempo e \(\phi= 2\pi 15/50=0.6\pi\).
Um termo de ruído aditivo foi considerado ruído branco com \(\sigma_{_W} = 1\), isso no painel central e \(\sigma_{_W} = 5\) no painel inferior, retirado de uma distribuição normal. Adicionando os dois juntos obscurece o sinal, como mostrado nos painéis inferiores da figura abaixo. Naturalmente, o grau em que o sinal é obscurecido depende da amplitude do sinal e do tamanho de \(\sigma_{_W}\). A razão da amplitude do sinal para \(\sigma_{_W}\) ou alguma função de razão é às vezes chamado de relação sinal-ruído (SNR); quanto maior o SNR, mais fácil é detectar o sinal. Observe que o sinal é facilmente discernível no painel central da figura, enquanto o sinal é obscurecido no painel inferior. Normalmente, não observaremos o sinal, mas o sinal obscurecido pelo ruído.
 |
|---|
No Capítulo IV estudaremos o uso da análise espectral como uma possível técnica para detectar sinais regulares ou periódicos, como o descrito no Exemplo I.12. Em geral, enfatizamos a importância de modelos aditivos simples, como os dados acima, na forma \begin{equation} X_t=S_t+V_t, \end{equation} onde \(S_t\) denota algum sinal desconhecido e \(V_t\) indica uma série temporal que pode ser um ruído branco ou correlacionada ao longo do tempo. Os problemas de detectar um sinal e depois estimar ou extrair a forma de onda de \(S_t\) são de grande interesse em muitas áreas da engenharia e das ciências físicas e biológicas. Em economia, o sinal subjacente pode ser uma tendência ou pode ser um componente sazonal de uma série. Modelos como o acima, onde o sinal tem uma estrutura autoregressiva, formam a motivação para o modelo de espaço de estados no Capítulo VI.
Nos exemplos acima, tentamos motivar o uso de várias combinações de variáveis aleatórias emulando dados de séries temporais. As características de suavidade das séries temporais observadas foram introduzidas pela combinação das variáveis aleatórias de várias maneiras. Calcular a méédia de variáveis aleatórias independentes sobre pontos de tempo adjacentes, como no Exemplo I.9 ou olhando para a saída de equações diferenciais que respondem a entradas de ruído branco, como no Exemplo I.10, são formas comuns de gerar dados correlacionados. Na próxima seção, apresentamos várias medidas teóricas usadas para descrever como as séries temporais se comportam. Como é habitual nas estatísticas, a descrição completa envolve a função de distribuição multivariada dos valores amostrados em conjunto \(X_1,X_2,\cdots,X_n\), enquanto descrições mais económicas podem ser obtidas em termos das funções de média e autocorrelação. Como a correlação é uma característica essencial da análise de séries temporais, as medidas descritivas mais úteis são aquelas expressas em termos de funções de covariância e correlação.
I.3 Medidas de dependência: autocorrelação e correlação cruzada
Uma descrição completa de uma série temporal, observada como uma coleção de \(n\) variáveis aleatórias em pontos de tempo inteiros arbitrários \(t_1,t_2,\cdots,t_n\), para qualquer inteiro positivo \(n\), é fornecida pela função de distribuição conjunta, avaliada como a probabilidade de que os valores das séries sejam juntos menores que as \(n\) constantes, \(c_1,c_2,\cdots,c_n\); ou seja, \begin{equation} F(c_1,c_2,\cdots,c_n) = P(X_{t_1}\leq c_1,X_{t_2}\leq c_2, \cdots,X_{t_n}\leq c_n)\cdot \end{equation}
Infelizmente, a função de distribuição multidimensional geralmente não pode ser escrita facilmente, a menos que as variáveis aleatórias sejam conjuntamente normais, caso em que a densidade conjunta tem forma bem conhecida.
Embora a função de distribuição conjunta descreva os dados completamente, é uma ferramenta difícil de exibir e analisar dados de séries temporais. A função de distribuição, mostrada acima, deve ser avaliada como uma função de \(n\) argumentos, portanto, qualquer plotagem das funções de densidade multivariadas correspondentes é virtualmente impossível. As funções de distribuição marginal \begin{equation} F_t(x)=P(X_t\leq x) \end{equation} ou as correspondentes funções de densidade marginal \begin{equation} f_t(x)=\dfrac{\partial F_t(x)}{\partial x}, \end{equation} quando elas existem, são frequentemente informativas para examinar o comportamento marginal de uma série.
Por exemplo, caso \(X_t\) seja gaussiana com média \(\mu_t\) e variância \(\sigma^2_t\), abreviadamente \(X_t\sim N(\mu_t,\sigma^2_t)\), a função de densidade marginal é dada por \begin{equation} f_t(x)=\dfrac{1}{\sigma_t\sqrt{2\pi}}\exp \Big( -\frac{1}{2\sigma_t^2}(x_t-\mu_t)^2\Big)\cdot \end{equation}Outra medida descritiva marginal informativa é a função de média.
Caso \(W_t\) denote uma série de médias móveis, então \(\mu_{_{W_t}}=\mbox{E}(W_t)=0\) para todo \(t\). A série superior da Figura 1.8 reflete isso, já que a série claramente flutua em torno de um valor médio de zero. Suavizar a série como no Exemplo 1.9 não altera a média porque podemos escrever \begin{equation} \mu_{_{V_t}}=\mbox{E}(V_t)=\dfrac{1}{3}\Big(\mbox{E}(W_{t-1})+\mbox{E}(W_t)+\mbox{E}(W_{t+1})\Big) \, = \, 0\cdot \end{equation}
Exemplo I.14. Função de média de um passeio aleatório com tendência
Considere o passeio aleatório com modelo de tendéncia dado no Exemplo I.11, \begin{equation} X_t \, = \, \delta t \, + \, \sum_{j=1}^t W_j, \qquad t=1,2,\cdots \cdot \end{equation} Como \(\mbox{E}(W_t)=0\) para todo \(t\) e \(\delta\) é uma constante, temos \begin{equation} \mu_{_{X_t}}=\mbox{E}(X_t)=\delta t+\sum_{j=1}^t \mbox{E}(W_j)=\delta t \end{equation} a qual é uma linha reta com inclinação \(\delta\). A realização de uma caminhada aleatória com tendência pode ser comparada à sua função de média na figura do Exemplo I.11.
Exemplo I.15. Função de média do sinal mais ruído
Muitas aplicações práticas dependem de assumir que os dados observados foram gerados por uma forma de onda de sinal fixo sobreposta a um processo de ruído de média zero, levando a um modelo de sinal aditivo da forma mostrada no Exemplo I.12. Está claro, porque o sinal no Exemplo I.12 é uma função fixa do tempo, assim temos \begin{equation} \begin{array}{rclcl} \mu_{_{X_t}} & = & \mbox{E}(X_t) & = & \mbox{E}\Big( 2\cos\big( 2\pi (t+15)/50 \big)+W_t\Big) \\ & & & = & 2\cos\big( 2\pi (t+15)/50 \big) + \mbox{E}(W_t) \, = \, 2\cos\big( 2\pi (t+15)/50 \big), \end{array} \end{equation} e a função de média é apenas a onda cosseno.
A falta de independência entre dois valores adjacentes \(X_s\) e \(X_t\) pode ser avaliada numericamente, como na estatística clássica, usando as noções de covariância e correlação. Assumindo que a variância de \(X_t\) é finita, temos a seguinte definição.
A autocovariancia mede a dependência linear entre dois pontos na mesma série observada em diferentes momentos. Séries muito suaves exibem funções de autocovariância que permanecem grandes mesmo quando \(t\) e \(s\) estão distantes, enquanto que as séries agitadas tendem a ter funções de autocovariância que são quase zero para grandes separações. Lembre-se de estatísticas clássicas que se \(\gamma_{_X}(s,t)=0\), \(X_s\) e \(X_t\) não estão linearmente relacionados, mas ainda pode haver alguma estrutura de dependência entre eles. Se, no entanto, \(X_s\) e \(X_t\) são normais bivariados, \(\gamma_{_X}(s,t) = 0\) garante sua independência. É claro que, para \(s = t\), a autocovariância se reduz à variância, suposta finita, porque \begin{equation} \gamma_{_X}(s,t) \, = \, \mbox{E}\big( (X_t-\mu_t)^2\big) \, = \, \mbox{Var}(X_t)\cdot \end{equation}
Exemplo I.16. Autocovariância do ruído branco
A sÉrie de ruído branco \(W_t\) satisfaz que \(\mbox{E}(W_t)=0\) e \begin{equation} \gamma_{_W}(s,t) \, = \, \mbox{Cov}(W_s,W_t) \, = \, \left\{ \begin{array}{rl} \sigma^2_{_W}, & s=t \\ 0, & s\neq t \end{array}\right.\cdot \end{equation} Uma realização de ruído branco com \(\sigma^2_{_W} = 1\) é mostrada no painel superior da Figura I.8.
Muitas vezes, precisamos calcular a autocovariância entre as séries filtradas. Um resultado útil é dado a seguir.
Se as variáveis aleatórias \begin{equation} U \, = \, \displaystyle \sum_{j=1}^m a_j X_j \qquad \mbox{e} \qquad V \, = \, \sum_{k=1}^r b_k Y_k, \end{equation} são combinações lineares das variáveis aleatórias \(\{X_j\}\) e \(\{Y_k\}\), todas de variâncias finitas, respectivamente, então \begin{equation} \mbox{Cov}(U,V) \, = \, \displaystyle \sum_{j=1}^m \sum_{k=1}^r a_jb_k \mbox{Cov}(X_j,Y_k)\cdot \end{equation} Além disso, \(\mbox{Var}(U)=\mbox{Cov}(U,U)\).
Exemplo I.17. Autocovariância de um modelo de médias móveis
Considere aplicar um modelo de médias móveis de três pontos à série de ruído branco do exemplo anterior, como no Exemplo I.9. Nesse caso, \begin{equation} \gamma_{_V}(s,t) \, = \, \mbox{Cov}(V_s,V_t) \, = \, \mbox{Cov}\Big( \frac{1}{3}(W_{s-1}+W_s+W_{s+1}), \frac{1}{3}(W_{t-1}+W_t+W_{t+1})\Big)\cdot \end{equation}
Quando \(s=t\) temos \begin{equation} \begin{array}{rcl} \gamma_{_V}(t,t) & = & \displaystyle \frac{1}{9}\mbox{Cov}\big( (W_{s-1}+W_s+W_{s+1}), (W_{t-1}+W_t+W_{t+1})\big) \\ & = & \displaystyle \frac{1}{9}\Big( \mbox{Cov}\big( W_{t-1}, W_{t-1}\big) + \mbox{Cov}\big( W_{t}, W_{t}\big) + \mbox{Cov}\big( W_{t+1}, W_{t+1}\big) \Big) \\ & = & \displaystyle \frac{3}{9}\sigma^2_{_W}\cdot \end{array} \end{equation}
Quando \(s=t+1\) temos \begin{equation} \begin{array}{rcl} \gamma_{_V}(t+1,t) & = & \displaystyle \frac{1}{9}\mbox{Cov}\big( (W_{t}+W_{t+1}+W_{t+2}), (W_{t-1}+W_t+W_{t+1})\big) \\ & = & \displaystyle \frac{1}{9}\Big( \mbox{Cov}\big( W_{t}, W_{t}\big) + \mbox{Cov}\big( W_{t+1}, W_{t+1}\big) \Big) \\ & = & \displaystyle \frac{2}{9}\sigma^2_{_W}\cdot \end{array} \end{equation}
Cálculos similares dão \(\gamma_{_V}(t-1,t)=2\sigma^2_{_W}/9\), \(\gamma_{_V}(t+2,t)=\gamma_{_V}(t-2,t)=\sigma^2_{_W}/9\) e zero quando \(|t-s|>2\). Resumimos os valores para todos os \(s\) e \(t\) como \begin{equation} \gamma_{_V}(s,t) \, = \, \left\{ \begin{array}{ccc} \frac{3}{9}\sigma^2_{_W}, & quando & s=t \\ \frac{2}{9}\sigma^2_{_W}, & quando & |s-t|=1 \\ \frac{1}{9}\sigma^2_{_W}, & quando & |s-t|=2 \\ 0, & quando & |s-t|>2 \end{array}\right. \end{equation}
O Exemplo I.17 mostra claramente que a operação de suavização introduz uma função de covariância que diminui à medida que a separação entre os dois pontos de tempo aumenta e desaparece completamente quando os pontos são separados por três ou mais pontos de tempo. Esta autocovariância em particular é interessante porque depende apenas da separação de tempo ou atraso e não da localização absoluta dos pontos ao longo da série. Veremos mais adiante que essa dependência sugere um modelo matemático para o conceito de estacionaridade fraca.
Exemplo I.18. Autocovariância de um passeio aleatório
Para o modelo de passeio aleatóorio \(X_t=\sum_{j=1}^t W_j\), temos que \begin{equation} \gamma_{_X}(s,t) \, = \, \mbox{Cov}(X_s,X_t) \, = \, \displaystyle \mbox{Cov}\Big( \sum_{j=1}^s W_j,\sum_{k=1}^t W_k\Big) \, = \, \min\{s,t\}\sigma^2_{_W}, \end{equation} porque os \(W_t\) são variáveis aleatórias não correlacionadas. Observe que, ao contrário dos exemplos anteriores, a função de autocovariância de uma caminhada aleatória depende dos valores de tempo específicos \(s\) e \(t\) e não da separação de tempo ou atraso. Além disso, observe que a variância do passeio aleatório \(\mbox{Var}(X_t)=\gamma_{_X}(t,t)=t\sigma^2_{_W}\), aumenta sem limite à medida que o tempo \(t\) aumenta. O efeito desse aumento de variância pode ser visto na figura no Exemplo I.11, onde os processos começam a se afastar de suas funções médias \(\delta t\), note que \(\delta = 0\) e \(\delta =0.2\) nesse exemplo.
Como nas estatísticas clássicas, é mais conveniente lidar com uma medida de associação entre -1 e 1, e isso leva à seguinte definição.
A função de autocorrelação (ACF) é definida como \begin{equation} \rho(s,t)=\dfrac{\gamma(s,t)}{\sqrt{\gamma(s,s)\gamma(t,t)}}\cdot \end{equation}
O função de autocorrelação mede a previsibilidade linear da série no tempo \(t\), digamos \(X_t\), usando apenas o valor \(X_s\). Podemos mostrar que \(-1<\rho(s,t) < 1\) usando a desigualdade de Cauchy-Schwarz. Se podemos prever \(X_t\) perfeitamente de \(X_s\) através de uma relação linear, \(X_t = \beta_0+\beta_1 X_s\); então a correlação será +1 quando \(\beta_1> 0\) e -1 quando \(\beta_1<0\). Portanto, temos uma medida aproximada da capacidade de prever a série no tempo \(t\) do seu valor no tempo \(s\).
Frequentemente, gostaríamos de medir a previsibilidade de outra série \(Y_t\) da série \(X_s\). Supondo que ambas as séries tenham variâncias finitas, temos a seguinte definição.
A função de covariância cruzada entre duas séries \(X_t\) e \(Y_t\) é dada por \begin{equation} \gamma_{_{XY}}(s,t)=\mbox{Cov}(X_s,Y_t)=\mbox{E}\Big( \big(X_s-\mu_{_{X_s}}\big)(Y_t-\mu_{_{Y_t}})\Big)\cdot \end{equation}
Desta há também uma versão em escala, a função de correlação cruzada.
A função de correlação cruzada (CCF) é definida como \begin{equation} \rho_{_{XY}}(s,t)=\dfrac{\gamma_{_{XY}}(s,t)}{\sqrt{\gamma_{_X}(s,s)\gamma_{_Y}(t,t)}}\cdot \end{equation}
Podemos facilmente estender as idéias acima para o caso de mais de duas séries, digamos, \(X_{t_1},X_{t_2},\cdots,X_{t_r}\), isto é, séries temporais multivariadas com \(r\) componentes.
Nas definições acima, as funções de autocovariância e de covariância cruzada podem mudar à medida que se move ao longo da série, porque os valores dependem de \(s\) e \(t\), as localizações dos pontos no tempo. No Exemplo I.17, a função de autocovariância depende da separação de \(X_s\) e \(X_t\), digamos, \(h = |s-t|\), e não de onde os pontos estão localizados no tempo. Contanto que os pontos estejam separados por \(h\) unidades, a localização dos dois pontos não importa. Essa noção, chamada de estacionariedade fraca, quando a média é constante, é fundamental para nos permitir analisar dados de séries temporais quando apenas uma única série está disponível.
I.4 Série temporal estacionária
As definições anteriores das funções de média e autocovariância são completamente gerais. Embora não tenhamos feito nenhuma suposição especial sobre o comportamento da série temporal, muitos dos exemplos anteriores sugeriram que um tipo de regularidade pode existir ao longo do tempo no comportamento de uma série temporal. Introduzimos a noção de regularidade usando um conceito chamado estacionariedade.
Uma série temporal estritamente estacionária é aquela para a qual o comportamento probabilístico de cada coleção de valores \(X_{t_1},X_{t_2},\cdots,X_{t_k}\) é idêntico ao do conjunto de deslocamentos temporais \(X_{t_1+h},X_{t_2+h},\cdots,X_{t_k+h}\). Isto é, \begin{equation} P\Big( X_{t_1}\leq c_1,X_{t_2}\leq c_2,\cdots,X_{t_k}\leq c_k\Big) = P\Big( X_{t_1+h}\leq c_1,X_{t_2+h}\leq c_2,\cdots,X_{t_k+h}\leq c_k\Big), \end{equation} para todos \(k = 1,2,\cdots\), todos os instantes de tempo \(t_1,t_2,\cdots,t_k\), todos os números \(c_1,c_2,\cdots,c_k\) e todos os deslocamentos de tempo \(h = 0, \pm 1, \pm 2,\cdots \).
Se uma série temporal for estritamente estacionária, todas as funções de distribuição multivariadas para subconjuntos de variáveis devem concordar com suas contrapartes no conjunto comutado para todos os valores do parâmetro de deslocamento \(h\). Por exemplo, quando \(h=1\), implica que \begin{equation} P(X_s\leq c) = P(X_t\leq c) \end{equation} para quaisquer pontos de tempo \(s\) e \(t\). Esta declaração implica, por exemplo, que a probabilidade de o valor de uma série temporal amostrada por hora ser negativa agrave; 1 da manhã é a mesma que às 10 da manhã.
Além disso, se a função de média \(\mu_t\) da série existir, isso implica que \(\mu_s = \mu_t\) para todos os \(s\) e \(t\) e, portanto, \(\mu_t\) deve ser constante. Note, por exemplo, que um processo de passeio aleatório com tendência não é estritamente estacionário porque sua função de média muda com o tempo; veja o Exemplo I.14.
Quando \(k=2\), podemos escrever \begin{equation} P(X_s\leq c_1, X_t\leq c_2) = P(X_{s+h}\leq c_1, X_{t+h}\leq c_2), \end{equation} para quaisquer pontos instantes de tempo \(s\) e \(t\) e defasagem \(h\). Assim, se a função de variância do processo existir, a estacionaridade estrita implica que a função de autocovariância da série \(X_t\) satisfaz \begin{equation} \gamma(s,t)=\gamma(s+h,t+h), \end{equation} para todos os \(s\) e \(t\) e \(h\). Podemos interpretar esse resultado dizendo que a função de autocovariância do processo depende apenas da diferença de tempo entre \(s\) e \(t\), e não dos tempos reais.
A versão da estacionariedade na Definição I.6 é muito forte para a maioria das aplicações. Além disso, é difícil avaliar a estacionariedade estrita de um único conjunto de dados. Em vez de impor condições em todas as distribuições possíveis de uma série temporal, usaremos uma versão mais branda que impõe condições apenas nos dois primeiros momentos da série. Agora temos a seguinte definição.
Uma série temporal fracamente estacionária é um processo de variância finita tal que:
- \((i)\) a função de média \(\mu_t\), é constante e não depende do tempo \(t\), e
- \((ii)\) a função de autocovariância \(\gamma(s,t)\), depende de \(s\) e \(t\) somente através de sua diferença \(|s-t|\).
A estacionariedade exige regularidade nas funções de média e de autocorrelação para que essas quantidades, pelo menos, possam ser estimadas pela média. Deve ficar claro, a partir da discussão da estacionariedade estrita, seguindo a Definição I.6, que uma série temporal estritamente estacionária, com variância finita, também é estacionária. O contrário não é verdade a menos que haja outras condições. Um caso importante em que a estacionariedade estrita implica estacionariedade é se a série temporal é Gaussiana, significando que todas as distribuições finitas das séries são Gaussianas. Vamos tornar este conceito mais preciso no final desta seção.
Devido a que a função de média \(\mbox{E}(X_t)=\mu_t\) de uma série temporal estacionária \(X_t\) depende de \(s\) e \(t\) somente através de sua diferença \(|s-t|\), podemos simplificar a notação. Seja \(s = t + h\), onde \(h\) representa o deslocamento de tempo ou atraso. Então \begin{equation} \gamma(t+h,t)=\mbox{Cov}(X_{t+h},X_t)=\mbox{Cov}(X_h,X_t)=\gamma(h,0), \end{equation} porque a diferença de tempo entre os instantes \(t + h\) e \(t\) é a mesma que a diferença de tempo entre os instantes \(h\) e 0. Assim, a função de autocovariância de uma série temporal estacionária não depende do argumento de tempo \(t\). Daqui em diante, por conveniência, abandonaremos o segundo argumento de \(\gamma(h,0)\).
Escrevemos a função de autocovariância de uma série estacionária como \begin{equation} \gamma(h)=\mbox{Cov}(X_{t+h},X_t)=\mbox{E}\big( (X_{t+h}-\mu)(X_t-\mu)\big)\cdot \end{equation}
Escrevemos a função de autocorrelação de uma série estacionária como \begin{equation} \rho(h)=\frac{\gamma(t+h,t)}{\sqrt{\gamma(t+h,t+h)\gamma(t,t)}}=\dfrac{\gamma(h)}{\gamma(0)}\cdot \end{equation}
A desigualdade de Cauchy-Schwarz mostra novamente que \(-1\leq \rho(h)\leq 1\) para todos os \(h\), permitindo avaliar a importância relativa de um determinado valor de autocorrelação comparando com os valores extremos -1 e 1.
Exemplo I.19. Estacionaridade do ruído branco
As funções de média e autocovariância das séries de ruído branco discutidas no Exemplo I.8 e no Exemplo I.16 são facilmente avaliadas como \(\mu_{_{W_t}}=0\) e \begin{equation} \gamma_{_W}(h)=\mbox{Cov}(W_{t+h},W_t)=\left\{ \begin{array}{cl} \sigma_{_W}^2, & h=0 \\ 0, & h\neq 0\end{array}\right.\cdot \end{equation} Assim, o ruído branco satisfaz as condições da Definição I.7 e é fracamente estacionária ou estacionária. Se as variações do ruído branco também são normalmente distribuídas ou gaussianas, a série também é estritamente estacionária. A função de autocorrelação é dada por \(\rho_{_W}(0)=1\) e \(\rho(h) = 0\), para \(h\neq 0\).
Exemplo I.20. Estacionaridade da média móvel
O processo de média móvel de três pontos do Exemplo I.9 é estacionário porque, do Exemplo I.13 e Exemplo I.17, as funções de média e autocovariância são \(\mu_{_{V_t}}=0\) e \begin{equation} \gamma_{_V}(h)=\left\{ \begin{array}{cl} \displaystyle \frac{3}{9}\sigma_{_W}^2, & h=0 \\ \displaystyle \frac{2}{9}\sigma_{_W}^2, & h=\pm 1 \\ \displaystyle \frac{1}{9}\sigma_{_W}^2, & h=\pm 2 \\ 0, & |h|>2 \end{array}\right., \end{equation} são independentes do tempo \(t\), satisfazendo as condições da Definição I.7.
A função de autocorrelação é dada por \begin{equation} \rho_{_V}(h)=\left\{ \begin{array}{cl} 1, & h=0 \\ \displaystyle \frac{2}{3}, & h=\pm 1 \\ \displaystyle \frac{1}{3}, & h=\pm 2 \\ 0, & |h|>2 \end{array}\right., \end{equation}
A figura mostra um gráfico das autocorrelações em função do lag \(h\). Observe que a função de autocorrelação é simétrica em relação ao desfasamento zero.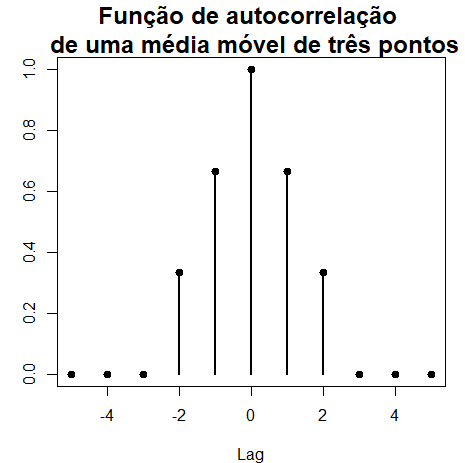 |
|---|
Exemplo I.21. Um passeio aleatório não é estacionário
Um passeio aleatório não é estacionário porque sua função de autocovariância é \(\gamma(s,t)=\min\{s,t\}\sigma_{_W}^2\), depende do tempo; veja o Exemplo I.18. Além disso, o passeio aleatório com tendéncia viola ambas as condições da Definição I.7 porque, como mostrado no Exemplo I.14, a função de média, \(\mu_{_{X_t}} = \delta t\), também é uma função do tempo \(t\).
Exemplo I.22. Estacionariedade de tendência
Por exemplo, se \(X_t=\alpha+\beta t+Y_t\), onde \(Y_t\) é estacionário, então a função de média é \(\mu_{_{X_t}}=\mbox{E}(X_t)=\alpha+\beta t+\mu_{_Y}\), que não é independente do tempo. Portanto, o processo não é estacionário. A função de autocovariância, no entanto, é independente do tempo, porque \begin{equation} \gamma_{_X}(h)=\mbox{E}(X_{t+h},X_t)=\mbox{E}\big((X_{t+h}-\mu_{_{X,t+h}})(X_t-\mu_{_{X,t}})\big)= \mbox{E}\big( (Y_{t+h}-\mu_{_Y})(Y_t-\mu_{_Y})\big)=\gamma_{_Y}(h)\cdot \end{equation}
Assim, o modelo pode ser considerado como tendo comportamento estacionário em torno de uma tendência linear; esse comportamento é às vezes chamado de estacionariedade de tendência. Um exemplo de tal processo é o preço das séries de frango exibido na figura do Exemplo II.1.
A função de autocovariância de um processo estacionário possui várias propriedades especiais. Primeiro, \(\gamma (h)\) é definido não-negativo assegurando que variações de combinações lineares das variáveis \(X_t\) nunca serão negativas. Ou seja, para qualquer \(n\geq 1\) e constantes \(a_1,\cdots,a_n\), \begin{equation} 0\leq \mbox{Var}(a_1 X_1+\cdots+a_n X_n)=\displaystyle \sum_{j=1}^n \sum_{k=1}^n a_j a_k \gamma(j-k), \end{equation} utilizando a Propriedade I.1. Além disso, o valor em \(h = 0\), ou seja, \begin{equation} \gamma(0)=\mbox{E}\big((X_t-\mu)^2\big), \end{equation} é a variância da série temporal e a desigualdade de Cauchy-Schwarz implica \(|\gamma(h)|\leq \gamma(0)\).
Uma propriedade útil final, observada em um exemplo anterior, é que a função de autocovariância de uma série estacionária é simétrica em torno da origem; isso é, \begin{equation} \gamma(h)=\gamma(-h), \end{equation} para todo \(h\). Esta propriedade segue porque \begin{equation} \gamma\big( (t+h)-h\big)=\mbox{Cov}(X_{t+h},X_t)=\mbox{Cov}(X_t,X_{t+h})=\gamma\big( t-(t+h)\big), \end{equation} que mostra como usar a notação, bem como provar o resultado.
Quando várias séries estão disponíveis, uma noção de estacionariedade ainda se aplica com condições adicionais.
Duas séries \(X_t\) e \(Y_t\) são ditas conjuntamente estacionárias se ambas foram estacionárias e a função de covariância cruzada for da forma \begin{equation} \rho_{_{XY}}(h)= \mbox{Cov}(X_{t+h},Y_t)=\mbox{E}\big( (X_{t+h}-\mu_X)(Y_t-\mu_Y)\big), \end{equation} sendo esta uma função apenas de \(h\), denominado de lag ou defasagem no tempo.
A função de correlação cruzada (CCF) conjunta das séries temporais conjuntamente estacionárias \(X_t\) e \(Y_t\) é definida como \begin{equation} \rho_{_{XY}}(h)=\frac{\gamma_{_{XY}}(h)}{\sqrt{\gamma_{_X}(0)\gamma_{_Y}(0)}}\cdot \end{equation}
Mais uma vez, temos o resultado \(-1\leq \rho_{_{XY}}(h)\leq 1\), que permite a comparação com os valores extremos -1 e 1, quando olhamos para a relação entre \(X_{t+h}\) e \(Y_t\). A função de correlação cruzada geralmente não é simétrica em torno de zero, isto é, tipicamente \(\rho_{_{XY}}(h)\neq \rho_{_{XY}}(-h)\). Esse é um conceito importante; deve ficar claro que \(\mbox{Cov}(X_2,Y_1)\) e \(\mbox{Cov}(X_1,Y_2)\) não precisam ser iguais. É o caso, no entanto, que \begin{equation} \rho_{_{XY}}(h)= \rho_{_{XY}}(-h)\cdot \end{equation}
Exemplo I.23. Estacionariedade conjunta.
Consideremos duas séries \(X_t\) e \(Y_t\), formadas a partir da soma e diferença de dois valores sucessivos de um processo de ruído branco, digamos, \begin{equation} X_t=W_t+W_{t-1} \qquad \mbox{e} \qquad Y_t=W_t-W_{t-1}, \end{equation} onde \(W_t\) são variáveis aleatórias independentes com médias zero e variância \(\sigma_{_W}^2\). Pode-se mostrar que \(\gamma_{_X}(0)=\gamma_{_Y}(0)=2\sigma_{_W}^2\) e que \(\gamma_{_X}(1)=\gamma_{_X}(-1)=\sigma_{_W}^2\), \(\gamma_{_Y}(1)=\gamma_{_Y}(-1)=-\sigma_{_W}^2\). Também \begin{equation} \gamma_{_{XY}}(1)=\mbox{Cov}(X_{t+1},Y_t)=\mbox{Cov}(W_{t+1}+W_t,W_t-W_{t-1})=\sigma^2_{_W}, \end{equation} porque apenas um termo é diferente de zero.
Similarmente, \(\gamma_{_{XY}}(0)=0\), \(\gamma_{_{XY}}(-1)=-\sigma^2_{_W}\). Obtemos que \begin{equation} \rho_{_{XY}}(h)=\left\{\begin{array}{cc} 0,& h=0, \\ \frac{1}{2}, & h=1, \\ -\frac{1}{2}, & h=-1, \\ 0, & |h|\geq 2, \end{array}\right.\cdot \end{equation} Claramente, as funções de autocovariância e de covariância cruzada dependem apenas da separação por atraso ou lag \(h\), de modo que as séries são conjuntamente estacionárias.
Exemplo I.24. Previsão usando Correlação Cruzada.
Como um exemplo simples de correlação cruzada, considere o problema de determinar possíveis relações iniciais ou atrasadas entre duas séries \(X_t\) e \(Y_t\). Se o modelo \begin{equation} Y_t=A X_{x-\ell}+W_t, \end{equation} for válido, a série \(X_t\) é dita que leva \(Y_t\) para \(\ell>0\) e é dito que vai para \(Y_t\) se \(\ell < 0\). Por isso, a análise das relações de avanço e atraso pode ser importante na previsão do valor de \(Y_t\) de \(X_t\). Assumindo que o ruído não é correlacionado com a série \(X_t\), a função de covariância cruzada pode ser calculada como \begin{equation} \begin{array}{rcl} \gamma_{_{XY}}(h) & = & \mbox{Cov}(Y_{t+h},X_t) \, = \, \mbox{Cov}(A X_{t+h-\ell}+W_{t+h},X_t) \\ & = & \mbox{Cov}(A X_{t+h-\ell},X_t) \, = \, A \gamma_{_X}(h-\ell)\cdot \end{array} \end{equation}
utilizando a desigualdade de Cauchy-Schwarz, obtemos que o maior valor absoluto de \(\gamma_{_X}(h-\ell)\) é \(\gamma_{_X}(0)\), ou seja, quando \(h = \ell\) a função de covariâância cruzada se parecerá com a autocovariância da série de entrada \(X_t\) e terá um pico no lado positivo se \(X_t\) conduzir \(Y_t\) e um pico no lado negativo se \(X_t\) retardar \(Y_t\).
Abaixo está o código R de um exemplo onde \(X_t\) é ruído branco, \(\ell=5\) e com \(\widehat{\gamma}_{_{XY}}(h)\) mostrado na figura abaixo.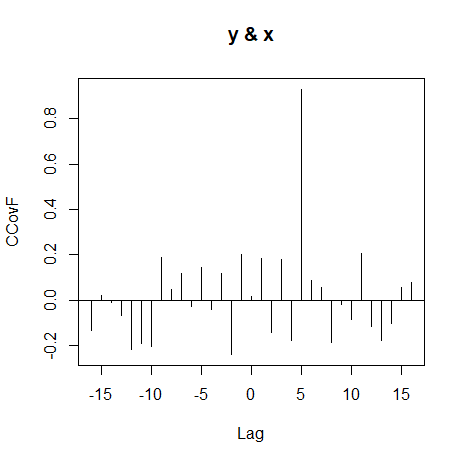 |
|---|
O conceito de estacionaridade fraca constitui a base de grande parte da análise realizada com séries temporais. As propriedades fundamentais das funções de média e autocovariância são satisfeitas por muitos modelos teóricos que parecem gerar realizações de amostras plausíveis. No Exemplo I.9 e no Exemplo I.10, foram geradas duas séries que produziram realizações de aparência estacionária e no Exemplo I.20, mostramos que a série no Exemplo I.9 era, de fato, fracamente estacionária. Ambos os exemplos são casos especiais do chamado processo linear.
Um processo linear \(X_t\) é definido como uma combinação linear de variações de um ruído branco \(W_t\), é dado por \begin{equation} X_t=\mu+\sum_{j=-\infty}^\infty \psi_j W_{t-j}, \qquad \sum_{j=-\infty}^\infty |\psi_j|<\infty\cdot \end{equation}
Para o processo linear podemos mostrar que a função de autocovariância é dada por \begin{equation} \gamma_{_X}(h)=\sigma_{_W}^2 \sum_{j=-\infty}^\infty \psi_{j+h}\psi_j, \end{equation} para \(h\geq 0\), lembremmos que \(\gamma_{_X}(h)=\gamma_{_X}(-h)\). Este método exibe a função de autocovariância do processo em termos dos produtos defasados dos coeficientes. Precisamos somente que \(\sum_{j=-\infty}^\infty \psi_j^2<\infty\) para o processo ter variância finita, mas vamos discutir isso no Capítulo V.
Note que, para no Exemplo I.9, temos \(\psi_0 = \psi_{-1} = \psi_1 = 1/3\) e o resultado no Exemplo I.20 sai imediatamente. A série autoregressiva no Exemplo I.10 também pode ser colocada nesta forma, assim como os processos de médias móveis autoregressivos considerados no Capítulo III.
Observe que o processo linear depende do futuro, quando \(j <0\), do presente \(j = 0\) e do passado \(j> 0\). Para fins de previsão, um modelo dependente do futuro será inútil. Consequentemente, nos concentraremos em processos que não dependem do futuro. Tais modelos são chamados causais, e um processo linear causal tem \(j = 0\) para \(j <0\); discutiremos isso mais detalhadamente no Capítulo III.
Finalmente, como mencionado anteriormente, um caso importante em que uma série fracamente estacionária é também estritamente estacionária é a série normal ou gaussiana.
Um processo, \(\{X_t\}\) é dito ser um processo Gaussiano se os vetores \(n\)-dimensionais \(X = (X_{t_1},X_{t_2},\cdots,X_{t_n})^\top\), para qualquer coleção de pontos temporais distintos \(t_1,t_2,\cdots,t_n\) e todo inteiro positivo \(n\), tem distribuição normal multivariada.
Definindo o vetor \(n\times 1\) de médias \(\mbox{E}(X)=\mu=(\mu_{t_1},\mu_{t_2},\cdots,\mu_{t_n})\) e a matriz \(n\times n\) de variâncias e covariâncias como \(\mbox{Var}(X)=\Gamma=\{\gamma(t_i,t_j)\}_{i,j=1}^n \) que é assumida como definida positiva, a função de densidade normal multivariada pode ser escrita como \begin{equation} f(x)=\frac{1}{\sqrt{(2\pi)^n|\Gamma|}}\exp\Big( -\frac{1}{2}(x-\mu)^\top\Gamma^{-1}(x-\mu)\Big), \end{equation} para \(x\in\mathbb{R}^n\), onde \(|\cdot|\) denota o determinante.
Listamos alguns itens importantes em relação aos processos lineares e gaussianos.
- Se uma série temporal Gaussiana \(\{X_t\}\), é fracamente estacionária, então \(\mu_t\) é constante e \(\gamma(t_i,t_j)=\gamma(|t_i-t_j|)\), de modo que o vetor \(\mu\) e a matriz \(\Gamma\) são independentes do tempo. Estes fatos implicam que todas as distribuições gaussianas finitas da série \(\{X_t\}\) dependem apenas do tempo decorrido e não dos tempos atuais e, portanto, a série deve ser estritamente estacionária. De certo modo, a estacionariedade e a normalidade fracas andam de mãos dadas, pois basearemos nossas análises na ideia de que é suficiente que os dois primeiros momentos se comportem bem. Usamos a densidade normal multivariada na forma dada acima, bem como em uma versão modificada, aplicável a variáveis aleatórias complexas ao longo do texto.
- Um resultado chamado de Decomposição de Wold (Teorema B.5) afirma que uma série temporal não determinística estacionária é um processo linear causal, mas com \(\sum_{j=-\infty}^\infty \psi_j^2<\infty\). Um processo linear não precisa ser Gaussiano, mas se uma série temporal é Gaussiana, então é um processo linear causal com \(W_t\sim N(0,1)\) independentes. Assim, os processos estacionários Gaussianos formam a base da modelagem de muitas séries temporais.
- Não é suficiente que as distribuições marginais sejam Gaussianas para que o processo seja Gaussiano. Pode-se construir uma situação em que \(X\) e \(Y\) são normais, mas \((X,Y)\) não é normal bivariado; por exemplo, seja \(X\) e \(Z\) normais independentes e seja \(Y = Z\) se \(XZ> 0\) e \(Y = -Z\) se \(XZ\leq 0\).
I.5 Estimação da correlação
Embora as funções teóricas de autocorrelação e correlação cruzada sejam úteis para descrever as propriedades de certos modelos hipotéticos, a maioria das análises devem ser realizadas usando dados amostrados. Esta limitação significa os pontos amostrados \(X_1,X_2,\cdots,X_n\) estão disponíveis apenas para estimar as funções de média, autocovariância e autocorrelação. Do ponto de vista da estatística clássica, isso representa um problema, porque normalmente não temos cópias independentes e identicamente distribuídas de \(X_t\) disponíveis para estimar as funções de covariância e correlação. Na situação usual com apenas uma realização, no entanto, a suposição de estacionariedade se torna crítica. De alguma forma, devemos usar médias sobre essa única realização para estimar as médias populacionais e as funções de covariância.
Assim, se uma série temporal é estacionária, a função média \(\mu_t=\mu\) é constante para que a possamos estimar pela média amostral, \begin{equation} \overline{X}=\frac{1}{n}\sum_{t=1}^n X_t\cdot \end{equation} No nosso caso, \(\mbox{E}(\overline{X})=\mu\) e o erro padrão da estimativa é a raiz quadrada de \(\mbox{Var}(\overline{X})\), que é dada por \begin{equation} \begin{array}{rcl} \mbox{Var}(\overline{X}) & = & \displaystyle \mbox{Var}\Big(\frac{1}{n}\sum_{t=1}^n X_t\Big) \, = \, \frac{1}{n^2}\mbox{Cov}\Big(\sum_{t=1}^n X_t,\sum_{s=1}^n X_s\Big) \\ & = & \displaystyle \frac{1}{n^2}\big( n\gamma_{_X}(0)+(n-1)\gamma_{_X}(1)+(n-2)\gamma_{_X}(2)+\cdots+\gamma_{_X}(n-1)\big. \\ & & \displaystyle \qquad \qquad \qquad +(n-1)\gamma_{_X}(-1)+(n-2)\gamma_{_X}(-2)+\cdots+\gamma_{_X}(1-n)\big)\\ & = & \displaystyle \frac{1}{n}\sum_{h=-n}^n \Big( 1-\frac{|h|}{n}\Big)\gamma_{_X}(h)\cdot \end{array} \end{equation}
Se o processo for ruído branco a expressão acima se reduzirá ao familiar \(\sigma_{_X}^2/n\) recordando que \(\gamma_{_X}(0)=\sigma^2_{_X}\). Note que, no caso de dependência, o erro padrão de \(\overline{X}\) pode ser menor ou maior que o caso de ruído branco, dependendo da natureza da estrutura de correlação.
A função de autocovariância teórica é estimada pela função de autocovariância amostral, definida a seguir.
A função de autocovariância amostral é definida como \begin{equation} \widehat{\gamma}(h)=\frac{1}{n}\sum_{t=1}^{n-h} \big( x_{t+h}-\overline{x}\big)\big(x_{t}-\overline{x}\big), \end{equation} com \(\widehat{\gamma}(-h)=\widehat{\gamma}(h)\), para \(h=0,1,2,\cdots,n-1\).
A soma na Definição I.14 é executada em um intervalo restrito porque \(x_{t+h}\) não está disponível para \(t + h> n\). O estimador acima é o preferido do que aquele que seria obtido dividindo por \(n-h\) porque a soma é uma função definida não negativa. Lembre-se de que a função de autocovariância de um processo estacionário é definida não negativa, assegurando que as variações das combinações lineares das variáveis \(X_t\) nunca serão negativas. E como uma variação nunca é negativa, a estimativa dessa variância \begin{equation} \widehat{\mbox{Var}}(a_1 x_1+\cdots+a_n x_n)=\displaystyle \sum_{j=1}^n\sum_{k=1}^n a_j a_k\widehat{\gamma}(j-k), \end{equation} também deve ser não negativa. O estimador da função de autocovariância garante este resultado, mas tal garantia não existe se dividirmos por \(n-h\). Note que nem dividir por \(n\) nem por \(n-h\) no estimador da função de autocovariância produz um estimador não-viesado de \(\gamma(h)\).
A função de autocorrelação amostral é definida como \begin{equation} \widehat{\rho}(h)=\frac{\widehat{\gamma}(h)}{\widehat{\gamma}(0)}\cdot \end{equation}
A função de autocorrelação amostral tem uma distribuição amostral que nos permite avaliar se os dados provêm de uma série completamente aleatória ou branca ou se as correlações são estatisticamente significativas em algumas defasagens.
Exemplo I.25. Função de autocorrelação amostral (ACF) e gráficos de dispersão.
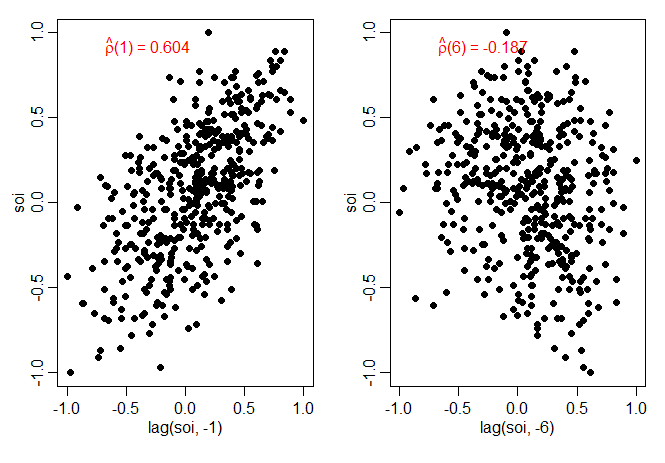
Estimar a autocorrelação é semelhante à estimativa de correlação na configuração usual, onde temos pares de observações \((x_i,y_i)\), para \(i = 1,2,\cdots,n\). Por exemplo, se tivermos dados de séries temporais \(x_t\) para \(t = 1,2,\cdots,n\), então os pares de observações para estimação de \(\rho(h)\) são os \(n-h\) pares de dados \(\{(x_t,x_{t+h})\}_{t=1}^{n-h}\). A figura abaixo mostra um exemplo usando a série SOI, onde \(\widehat{\rho}(1)=0.604\) e \(\widehat{\rho}(6)=-0.187\).
 |
|---|
Sob condições gerais, se \(X_t\) é ruído branco, então para \(n\) grande, a função de autocorrelação amostral \(\widehat{\rho}(h)\), para \(h = 1,2,\cdots,H\), onde \(H\) é fixo mas arbitrário, é aproximadamente normalmente distribuído com média zero e desvio padrão dado por \begin{equation} \sigma_{\widehat{\rho}(h)}=\dfrac{1}{\sqrt{n}}\cdot \end{equation}
Demonstração As condições gerais são que \(X_t\) é independente identicamente distribuída com quarto momento finito. Uma condição suficiente para isso é que \(X_t\) seja ruído branco. Detalhes precisos são dados no Teorema A.7 do Apêndice A ▉
Com base no resultado anterior, obtemos um método aproximado de avaliar se os picos em \(\widehat{\rho}(h)\) são significativos, determinando se o pico observado está fora do intervalo \(\pm 2/\sqrt{n}\) ou mais/menos dois erros padrão. Para uma sequência de ruído branco, aproximadamente 95% da função de autocorrelação amostral deve estar dentro desses limites. As aplicações dessa propriedade se desenvolvem porque muitos procedimentos de modelagem estatística dependem da redução de uma série temporal para uma série de ruído branco usando vários tipos de transformações. Depois que tais procedimentos serem aplicados, a função de autocorrelação amostral plotada nos resíduos deve então ficar aproximadamente dentro dos limites dados acima.
Exemplo I.26. Uma série temporal simulada.
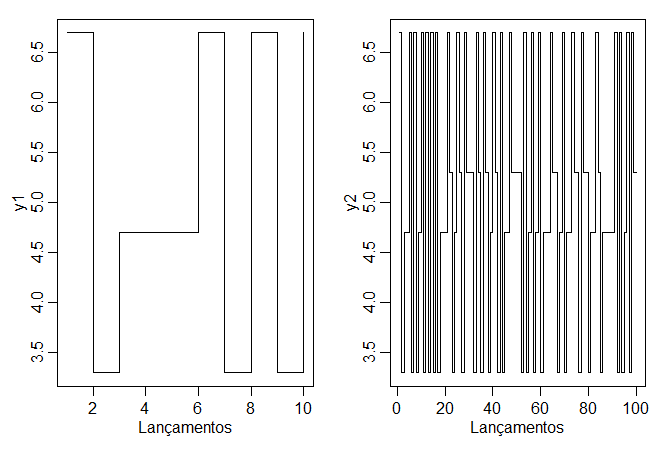
Para comparar funções de autocorrelação amostral para vários tamanhos de amostra com funções de autocorrelaçãoo teóricas, considere um conjunto artificial de dados gerados pelo lançamento de uma moeda justa, selecionado \(X_t = 1\) quando uma cara é obtida e \(X_t = -1\) quando uma coroa é obtida. Então, construa \(Y_t\) como \begin{equation} Y_t=5+X_t-0.7 X_{t-1}\cdot \end{equation}
Para simular os dados, consideramos dois casos, um com um tamanho de amostra pequeno \(n = 10\) e outro com um tamanho de amostra moderado \(n = 100\).
 |
|---|
O ACF teórica pode ser obtido a partir do modelo usando o fato de que a média é zero e a variância é um. Pode ser mostrado que \begin{equation} \rho_Y(1) \, = \, \frac{-0.7}{1+0.7^2} \, = \, -0.47, \end{equation} e \(\rho_Y(h) = 0\) para \(|h|>1\). É interessante comparar o ACF teórico com a ACF amostral para a realização onde \(n = 10\) e a outra realização onde \(n = 100\); observe a variabilidade aumentada na amostra de tamanho menor.
Exemplo I.27. ACF de um sinal de fala.
A função de autocorrelação amostral, como no exemplo anterior, pode ser considerada como combinando as séries temporais \(h\) unidades no futuro, digamos, \(X_{t+h}\) contra si mesmo, \(X_t\). A figura abaixo mostra a função de autocorrelação amostral (ACF) da série de fala do Exemplo I.3. A série original parece conter uma sequência de repetições de sinais curtos. A ACF confirma este comportamento, mostrando picos repetidos espaççados em cerca de 106-109 pontos. A função de autocorrelação dos sinais curtos aparecem espaçadas nos intervalos mencionados acima. A distância entre os sinais repetidos é conhecida como o período do tom e é um parâmetro fundamental de interesse em sistemas que codificam e decifram a fala. Como a série é amostrada em 10.000 pontos por segundo, o período de tom parece estar entre 0.0106 e 0.0109 segundos.
Para calcular a ACF amostral em R, use: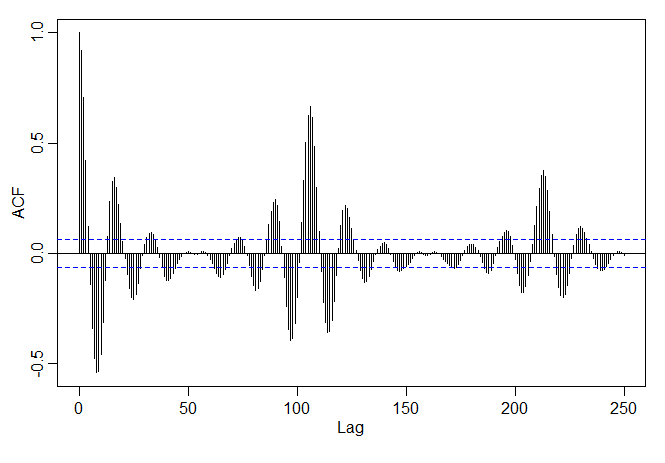 |
|---|
Os estimadores para as funções de covariância e correlação cruzada são, respectivamente, dados por \begin{equation} \widehat{\gamma}_{_{XY}}(h)=\frac{1}{n}\sum_{t=1}^{n-h}\big( x_{t+h}-\overline{x}\big)\big( y_{t}-\overline{y}\big), \end{equation} onde \(\widehat{\gamma}_{_{XY}}(-h)=\widehat{\gamma}_{_{YX}}(h)\) determina a função para atrasos ou lags negativos e a função de correlação cruzada amostral é \begin{equation} \widehat{\rho}_{_{XY}}(h)=\frac{\widehat{\gamma}_{_{XY}}(h)}{\sqrt{\widehat{\gamma}_{_{X}}(0)\widehat{\gamma}_{_{Y}}(0)}}\cdot \end{equation}
A função de correlação cruzada amostral pode ser examinada graficamente como uma função do lag ou atraso \(h\) para procurar por relações de avanço ou atraso nos dados usando a propriedade mencionada no Exemplo I.24 para a função de covariância cruzada teórica. Porque \(-1\leq \widehat{\rho}_{_{XY}}(h)\leq 1\), a importância prática dos picos pode ser avaliada comparando suas magnitudes com seus valores máximos teóricos. Além disso, para os processos lineares independentes \(X_t\) e \(Y_t\) na Definição I.12, temos a seguinte propriedade.
Sob condiçães gerais de \(X_t\) e \(Y_t\), para \(n\) grande, a função de correlação cruzada amostral \(\widehat{\rho}_{_{XY}}\), têm distribuição normal com esperança zero e desvio padrão dado por \begin{equation} \sigma_{\widehat{\rho}_{_{XY}}}=\dfrac{1}{\sqrt{n}}, \end{equation} se, pelo menos, um dos processos for um ruído branco independente.
Exemplo I.28. Análise de Correlação de SOI e Recrutamento.
As funções de autocorrelação e correlação cruzada também são úteis para analisar o comportamento conjunto de duas séries estacionárias cujo comportamento pode estar relacionado de alguma forma não especificada. No Exemplo I.5, consideramos as leituras mensais simultâneas do SOI e o número de novos peixes, chado de Recrutamento, calculados a partir de um modelo. A figura abaixo mostra as funções de autocorrelação e correlação cruzada (ACFs e CCF) para essas duas séries. Ambos os ACFs exibem periodicidades correspondentes à correlação entre valores separados por 12 unidades. Observações com 12 meses ou um ano de intervalo são fortemente correlacionadas positivamente, assim como observações em múltiplos como \(24,36,48,\cdots\). As observações separadas por seis meses são negativamente correlacionadas, mostrando que as excursões positivas tendem a estar associadas a excursões negativas aos seis meses removidos.
A funções de correlação cruzada amostral (CCF) na figura abaixo, no entanto, mostra uma certa distância do componente cíclico de cada série e há um pico óbvio em \(h = -6\). Este resultado implica que o SOI medido no tempo \(t-6\) meses está associado à série Recrutamento no tempo \(t\). Poderíamos dizer que o SOI lidera a série Recrutamento por seis meses. O sinal da CCF é negativo, levando à conclusão de que as duas séries se movem em direções diferentes; isto é, aumentos no SOI levam a diminuições no Recrutamento e vice-versa. Descobriremos no Capítulo II que existe uma relação entre as séries, mas a relação não é linear. As linhas tracejadas mostradas nos gráficos indicam \(\pm 2/\sqrt{453}\), mas como nenhuma das séries é ruído, essas linhas não se aplicam.
Mostramos a funções de autocorrelação amostra ou ACF da série SOI no gráfico superior e da série Recrutamento no gráfico intermediário. A funções de correlação cruzada amostral ou CCF das duas séries mostra-se no gráfico inferior; lags negativos indicam que SOI conduz o Recrutamento. Os lags nos eixos são em termos de estações (12 meses).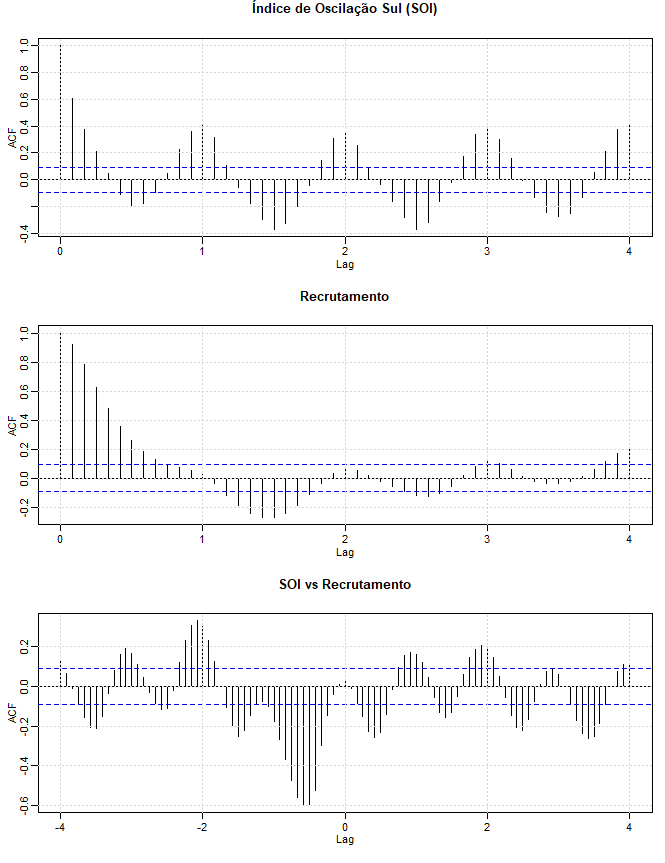 |
|---|
Exemplo I.29. Análise Pré-Branqueamento e Correlação Cruzada.
Embora ainda não tenhamos todas as ferramentas necessárias, vale a pena discutir a ideia de pré-aperfeiçoar uma série antes de uma análise de correlação cruzada. A idéia básica é simples; para usar a Propriedade I.3, pelo menos uma das séries deve ser ruído branco. Se esse não for o caso, não há uma maneira simples de saber se a estimativa de correlação cruzada é significativamente diferente de zero. Assim, no Exemplo I.28, estávamos apenas adivinhando na relação de dependência linear entre SOI e Recrutamento.
Por exemplo, na figura abaixo, geramos duas séries, \(X_t\) e \(Y_t\), para \(t = 1,2,\cdots,120\) independentemente como \begin{equation} X_t=2\cos \big( 2\pi t\frac{1}{12}\big)+W_{t1} \qquad \mbox{e} \qquad Y_t=2\cos \big( 2\pi (t+5)\frac{1}{12}\big)+W_{t2}, \end{equation} onde \(\{W_{t1},W_{t1}\}_{t=1}^{120}\) são todas normais padrão independentes.
As séries foram pensadas para se assemelhar às séries SOI e Recrutamento. Os dados gerados são mostrados na linha superior da figura. A linha do meio da figura mostra as ACF amostrais de cada série, cada uma das quais exibe a natureza cíclica de cada série. A linha inferior esquerda da figura mostra o CCF amostral entre \(X_t\) e \(Y_t\), que parece mostrar correlação cruzada mesmo que as séries sejam independentes. A linha inferior direita também exibe a CCF amostral entre \(X_t\) e o \(Y_t\) pré-branqueada, o que mostra que as duas sequências não são correlacionadas. Por pré-branqueamento de \(Y_t\), queremos dizer que o sinal foi removido dos dados executando uma regressão de \(Y_t\) em \(\cos(2\pi t)\) e \(\sin(2\pi t)\) e, em seguida, colocando \(\widetilde{Y}_t = Y_t - \widehat{Y}_t\), onde \(\widehat{Y}_t\) são os valores previstos da regressão.
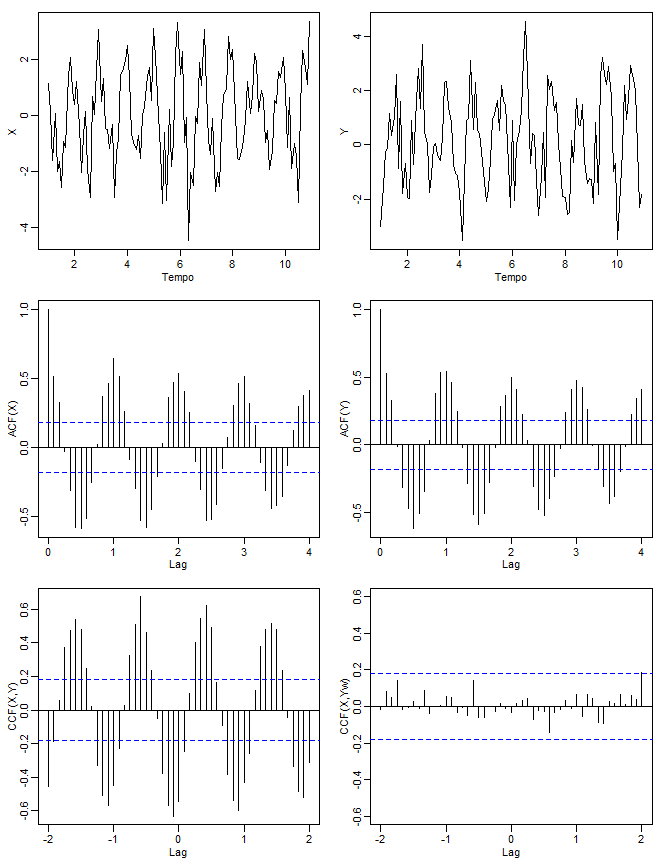 |
|---|
I.6 Séries multidimensionais
Frequentemente encontramos situações nas quais os relacionamentos entre um número de séries temporais conjuntamente medidas são de interesse. Por exemplo, nas seções anteriores, consideramos descobrir as relações entre as séries SOI e Recrutamento. Portanto, será útil considerar a noção de um vetor de séries temporais \(X_t = (X_{t1},X_{t2},\cdots,X_{tp})^\top\), que contém como componentes \(p\) séries temporais univariadas.
Denotamos o vetor \(p\times 1\) coluna da série multivariada observada como \(X_t\). O vetor de linha \(X_t^\top\) é sua transposta. Para o caso estacionário, o vetor \(p\times 1\) de médias é \begin{equation} \mu=\mbox{E}(X_t) \end{equation} da forma \(\mu=(\mu_{t1},\mu_{t2},\cdots,\mu_{tp})^\top\) e a matriz \(p\times p\) de variâncias e covariâncias \begin{equation} \Gamma(h)=\mbox{E}\Big(\big(X_{t+h}-\mu\big)\big(X_{t}-\mu\big)^\top\Big), \end{equation} onde seus elementos são as funções de covariância cruzada \begin{equation} \gamma_{_{ij}}(h)=\mbox{E}\Big(\big(X_{t+h,i}-\mu_i\big)\big(X_{tj}-\mu_j\big)^\top\Big), \end{equation} para \(i,j=1,2,\cdots,p\). Devido a que \(\gamma_{_{ij}}(h)=\gamma_{_{ji}}(-h)\), segue que \begin{equation} \Gamma(-h)=\Gamma^\top(h)\cdot \end{equation}
A matriz de autocovariância amostral da série de vetores \(X_t\) é a matriz \(p\times p\) de covariâncias cruzadas amostral, definida como \begin{equation} \widehat{\Gamma}(h)=\frac{1}{n}\sum_{t=1}^{n-h}\big(x_{t+h}-\overline{x}\big)\big(x_{t}-\overline{x}\big)^\top, \end{equation} onde \(\overline{x}=\frac{1}{n}\sum_{t=1}^n x_t\) denota o vetor \(p\times 1\) de médias amostral. A propriedade de simetria da autocovariância teórica se estende à autocovariância amostral, que é definida para valores negativos como \begin{equation} \widehat{\Gamma}(-h)=\widehat{\Gamma}^\top(h)\cdot \end{equation}
Em muitos problemas aplicados, uma série observada pode ser indexada por mais do que apenas o tempo. Por exemplo, a posição no espaço de uma unidade experimental pode ser descrita por duas coordenadas, digamos, \(s_1\) e \(s_2\). Podemos prosseguir nestes casos definindo um processo multidimensional \(X_s\) como uma função do vetor \(s = (s_1,s_2,\cdots,s_r)^\top\), dimensão \(r\times 1\), onde \(s_i\) denota a coordenada do índice \(i\).
Exemplo I.30. Temperaturas da Superfície do Solo.
Como exemplo, a série bidimensional, ou seja, \(r=2\), de temperatura mostrada na figura abaixo é indexada por um número de linha \(s_1\) e um número de coluna \(s_2\) que representam posições em uma grade espacial \(64\times 36\) estabelecida em um campo agrícola. O valor da temperatura medida na linha \(s_1\) e na coluna \(s_2\) é indicado como \(x_s = x_{s_1,s_2}\). Podemos notar a partir do gráfico bidimensional que uma mudança distinta ocorre no caráter da superfície bidimensional começando na linha 40, onde as oscilações ao longo do eixo da linha se tornam bastante estáveis e periódicas. Por exemplo, calculando a média das 36 colunas, podemos calcular um valor médio para cada \(s_1\), como na figura mais abixo. É claro que o ruído presente na primeira parte da série bidimensional está bem rateado e vemos um sinal de temperatura claro e consistente.
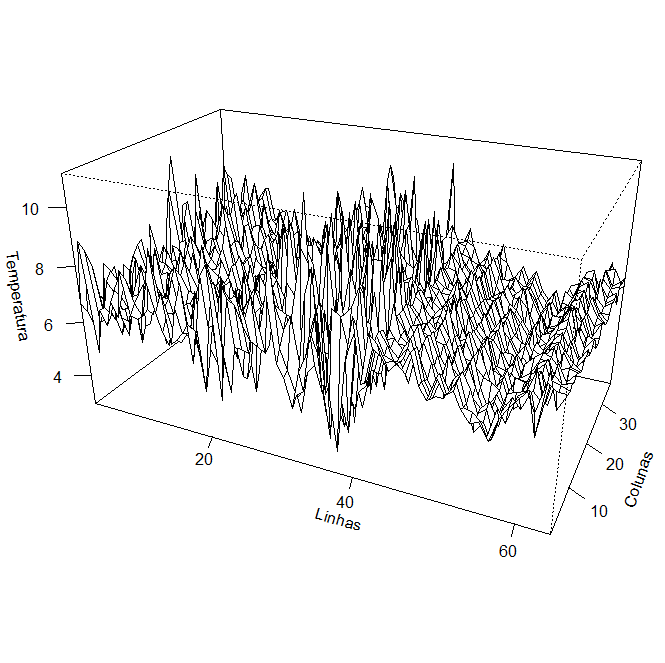 |
|---|
Na figura acima mostramos as séries temporais bidimensionais de medições de temperatura feitas em um campo retangular de \(64\times 36\), com espaçamento de 17 pés. Os dados são de Bazza et al. (1988). Agora mostramos a média das linhas do perfil bidimensional da temperatura do solo, sendo que \(\overline{x}_{s_1}=\sum_{s_2} x_{s_1,s_2}/36\).
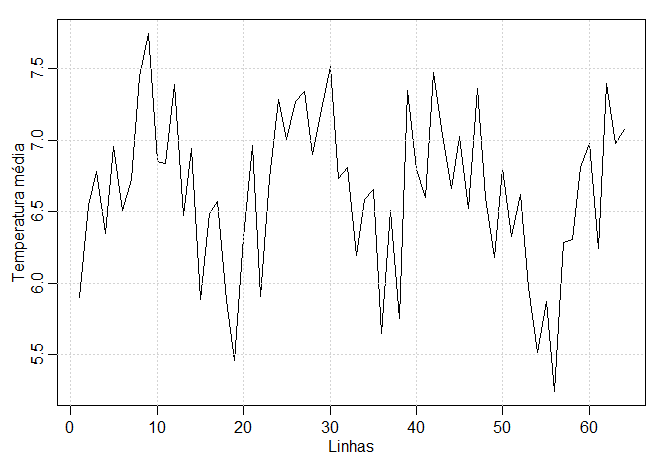 |
|---|
A função de autocovariâância de um processo estacionário multidimensional \(X_s\), pode ser definida como uma função do vetor de atraso multidimensional, digamos, \(h=(h_1,h_2,\cdots,h_r)^\top\) como \begin{equation} \gamma(h)=\mbox{E}\big( (X_{s+h}-\mu)(x_s-\mu)\big), \end{equation} onde \(\mu=\mbox{E}(X_s)\) não depende da coordenada espacial \(s\). Para o processo de temperatura bidimensional, no Exemplo I.30, torna-se \begin{equation} \gamma(h_1,h_2)=\mbox{E}\big( (X_{s_1+h_1,s_2+h_2}-\mu)(x_{s_1,s_2}-\mu)\big), \end{equation} que é uma função do atraso ou lag, tanto na linha em \(h_1\) quanto na coluna em \(h_2\).
A função de autocovariância amostral multidimensional é definida como \begin{equation} \widehat{\gamma}(h)=\frac{1}{S_1 S_2 \cdots S_r}\sum_{s_1}\sum_{2_2}\cdots \sum_{s_r}(x_{s+h}-\overline{x})(x_s-\overline{x}), \end{equation} onde \(s = (s_1,s_2,\cdots,s_r)^\top\) e o intervalo de soma para cada argumento é \(1\leq s_i\leq S_i-h_i\), para \(i = 1,\cdots,r\). A média é calculada sobre o vetor \(r\)-dimensional, isto é, \begin{equation} \overline{x}=\frac{1}{S_1 S_2 \cdots S_r}\sum_{s_1}\sum_{2_2}\cdots \sum_{s_r} x_{s_1,s_2,\cdots,s_r}\cdot \end{equation} A função de autocorrelação amostral multidimensional segue, como de costume, tomando a razão escalonada \begin{equation} \widehat{\rho}(h)=\frac{\widehat{\gamma}(h)}{\widehat{\gamma}(0)}\cdot \end{equation}
Exemplo I.31. Função de Autocorrelação Amostral da Temperatura da Superfície do Solo.
A função de autocorrelação do processo bidimensional da temperatura da superfície do solo pode ser escrita na forma \begin{equation} \widehat{\rho}(h_1,h_2)=\frac{\widehat{\gamma}(h_1,h_2)}{\widehat{\gamma}(0,0)}, \end{equation} onde \begin{equation} \widehat{\gamma}(h_1,h_2)=\frac{1}{S_1S_2}\sum_{s_1}\sum_{s_2}(x_{s_1+h1,s_2+h_2}-\overline{x})(x_{s_1,s_2}-\overline{x})\cdot \end{equation}
A figura abaixo mostra a função de autocorrelação para os dados de temperatura, e notamos a variação periódica sistemática que aparece ao longo das linhas. A autocovariância sobre colunas parece ser mais forte para \(h_1 = 0\), o que implica que as colunas podem formar réplicas de algum processo subjacente que tenha uma periodicidade sobre as linhas. Essa ideia pode ser investigada examinando-se as séries médias sobre as colunas, como mostra a segunda figura no Exemplo I.30.
A maneira mais fácil, que conhecemos, de calcular a ACF bidimensional no R é usando a transformada rápida de Fourier (FFT) como mostrado abaixo. Infelizmente, o material necessário para entender essa abordagem é dado na Seção IV.3. A função de autocovariância bidimensuonal é obtida em duas etapas e está contida em cs abaixo. Observando que \(\widehat{\gamma}(0,0)\) é o elemento \((1,1)\) de modo que \(\widehat{\rho}(h_1,h_2)\) é obtido dividindo cada elemento por esse valor. A ACF bidimensional está contido em rs abaixo, e o resto do código é simplesmente para organizar os resultados para produzir uma boa exibição.
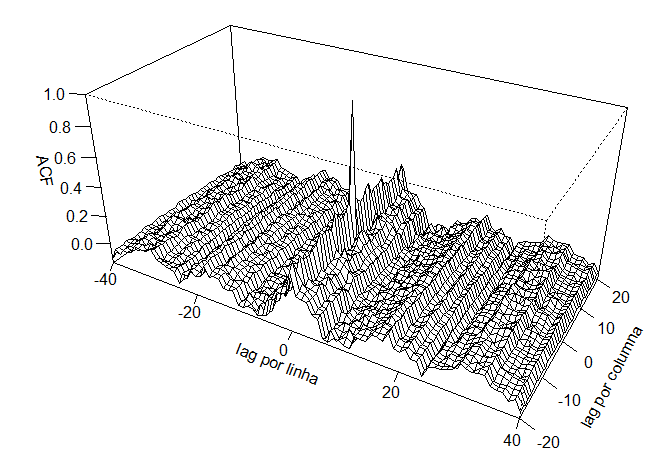 |
|---|
Os requisitos de amostragem para processos multidimensionais são bastante severos porque os valores devem estar disponíveis em alguma grade uniforme para calcular o ACF. Em algumas áreas de aplicação, como na ciência do solo, podemos preferir amostrar um número limitado de linhas ou transectos e esperar que sejam essencialmente réplicas do fenómeno subjacente básico de interesse. Métodos unidimensionais podem ser aplicados.
Quando as observações são irregulares no espaço de tempo, modificações nos estimadores precisam ser feitas. Abordagens sistemáticas para os problemas introduzidos por observações espaçadas irregularmente foram desenvolvidas por Journel e Huijbregts (1978) ou Cressie (1993). Nós não devemos estudar tais métodos em detalhes aqui, mas vale a pena notar que a introdução do variograma \begin{equation} 2V_{_X}(h)=\mbox{Var}(X_{s+h}-X_s), \end{equation} e seu estimador amostral \begin{equation} 2\widehat{V}_{_X}(h)=\frac{1}{N(h)}\sum_s (x_{s+h}-x_s)^2, \end{equation} desempenha um papel-chave, onde \(N(h)\) indica o número de pontos localizados em \(h\) e a soma percorre os pontos da vizinhança. Evidentemente, desenvolver-se-ão dificuldades substanciais de indexação a partir de estimadores deste tipo e, frequentemente, será difícil encontrar estimadores definidos não negativos para a função de covariância.
I.7 Exercícios
- Considere um modelo sinal-mais-ruído da forma geral \(X_t = S_t + W_t\), onde \(W_t\) é o ruído branco gaussiano
com \(\sigma^2_{_W} = 1\). Simule e mostre gráficamnte o resultado de \(n = 200\) observações de cada um dos dois
modelos a seguir.
- (a) \(X_t=S_t+W_t\), para \(t=1,\cdots,200\), onde
\begin{equation}
S_t=\left\{ \begin{array}{cl} 0, & t=1,2,\cdots,100 \\
10\exp\Big( -\frac{t-100}{20}\Big)\cos\Big(2\pi \frac{t}{4} \Big), & t=101,\cdots,200 \end{array}\right.\cdot
\end{equation}
Sugestão: utilizar o seguinte código em R:
> s = c(rep(0,100), 10*exp(-(1:100)/20)*cos(2*pi*(101:200)/4))
> x = s + rnorm(200)
> plot.ts(x) - (b) \(X_t=S_t+W_t\), para \(t=1,\cdots,200\), onde \begin{equation} S_t=\left\{ \begin{array}{cl} 0, & t=1,2,\cdots,100 \\ 10\exp\Big( -\frac{t-100}{200}\Big)\cos\Big(2\pi \frac{t}{4} \Big), & t=101,\cdots,200 \end{array}\right.\cdot \end{equation}
- Compare a aparência geral das séries em (a) e em (b) com a série sísmica e a série de explosões mostradas no Exemplo I.7. Além disso, mostrar e comparar os moduladores de sinal (a) \(\exp(-t/20)\) e (b) \(\exp(-t/200)\), para \(t = 1,2,\cdots,100\).
- (a) \(X_t=S_t+W_t\), para \(t=1,\cdots,200\), onde
\begin{equation}
S_t=\left\{ \begin{array}{cl} 0, & t=1,2,\cdots,100 \\
10\exp\Big( -\frac{t-100}{20}\Big)\cos\Big(2\pi \frac{t}{4} \Big), & t=101,\cdots,200 \end{array}\right.\cdot
\end{equation}
Sugestão: utilizar o seguinte código em R:
-
- (a) Gerar \(n = 100\) observações da autorregressão \(X_t=-0.9X_{t-2}+W_t\) com \(\sigma^2_{_W}=1\), usando o método
descrito no Exemplo I.10. Em seguida, aplique o filtro médio móvel
\begin{equation}
\dfrac{V_t=(X_t+X_{t-1}+X_{t-2}+X_{t-3}}{4}
\end{equation}
para \(X_t\), aos dados que você gerou. Agora mostre \(X_t\) como uma linha e sobreponha \(V_t\) como uma linha tracejada. Comente sobre o comportamento de \(X_t\)
e como aplicar o filtro de média móvel altera esse comportamento.
Sugestão: > v = filter(x, rep(1/4, 4), sides = 1). - (b) Repetir (a) mas com \(X_t=\cos(2\pi t/4)\).
- (c) Repetir (b) mas com adição de ruído \(N(0,1)\), \(X_t=\cos(2\pi t/4)+W_t\).
- (d) Compare e contraste (a) - (c); isto é, como a média móvel muda cada série.
- (a) Gerar \(n = 100\) observações da autorregressão \(X_t=-0.9X_{t-2}+W_t\) com \(\sigma^2_{_W}=1\), usando o método
descrito no Exemplo I.10. Em seguida, aplique o filtro médio móvel
\begin{equation}
\dfrac{V_t=(X_t+X_{t-1}+X_{t-2}+X_{t-3}}{4}
\end{equation}
para \(X_t\), aos dados que você gerou. Agora mostre \(X_t\) como uma linha e sobreponha \(V_t\) como uma linha tracejada. Comente sobre o comportamento de \(X_t\)
e como aplicar o filtro de média móvel altera esse comportamento.
- Mostre que a função de autocovariância pode ser escrita como \begin{equation} \gamma(s,t)=\mbox{E}\big( (X_s-\mu_s)(X_t-\mu_t)\big)=\mbox{E}(X_sX_t)-\mu_s\mu_t, \end{equation} onde \(\mbox{E}(X_t)=\mu_t\).
- Para as duas séries \(X_t\), no Exercício 2 (a) e (b):
- (a) Calcular e traçar as funções de médias \(\mu_{_X}(t)\), para \(t = 1,2,\cdots,200\).
- (b) Calcular a função de autocovariância \(\gamma(s,t)\), para \(s,t = 1,\cdots,200\).
- Considere a série temporal \(X_t=\beta_0+\beta_1 t+W_t\), onde \(\beta_0\) e \(\beta_1\) são constantes e \(W_t\)
é um processo de ruído branco com variância \(\sigma^2_{_W}\).
- (a) Determine se \(X_t\) é estacionário.
- (b) Mostre que o processo \(Y_t = X_t - X_{t-1}\) é estacionário.
- (c) Mostre que a média do processo de média móvel \begin{equation} V_t=\frac{1}{2q+1}\sum_{j=-q}^q X_{t-j}, \end{equation} é \(\beta_0+\beta_1 t\) e apresente uma expressão simplificada para a função de autocovariância.
- Para um processo de médias móveis da forma \(X_t=W_{t-1}+2W_{t}+W_{t+1}\), onde \(W_t\) são independentes com média zero e variância \(\sigma_{_W}^2\), determine as funções de autocovariância e autocorrelação como uma função do atraso ou lag \(h = s-t\) e mostre gráficamente o ACF como uma função de \(h\).
- Considere o modelo de passeio aleatório com tendência \(X_t=\delta+X_{t-1}+W_t\), para \(t=1,2,\cdots\), com \(X_0=0\),
onde \(W_t\) é um ruído branco com variância \(\sigma^2_{_W}\).
- (a) Mostre que o modelo pode ser escrito como \(X_t=\delta+\sum_{k=1}^t W_t\).
- (b) Encontre a função de média e de autocovariância de \(X_t\).
- (c) Argumente que \(X_t\) não é estacionário.
- (d) Mostre que \(\rho_{_X}(t-1,t)=\sqrt{\frac{t-1}{t}}\), satisfaz \(\lim_{t\to\infty} \rho_{_X}(t-1,t)=1\). Qual é a implicação desse resultado?
- (e) Sugira uma transformação para tornar a série estacionária e prove que a série transformada é estacionária.
- Uma série temporal com um componente periódico pode ser construída a partir do modelo \begin{equation} X_t=U_1 \sin(2\pi \omega_0 t)+U_2 \cos(2\pi \omega_0 t), \end{equation} onde \(U_1\) e \(U_2\) são variáveis aleatórias independentes com médias zero e \(\mbox{E}(U_1^2) = \mbox{E}(U_2^2) = \sigma^2\). A constante \(\omega_0\) determina o período ou o tempo que leva o processo para fazer um ciclo completo. Mostre que esta série é fracamente estacionária com função de autocovariância \(\gamma(h)=\sigma^2 \cos(2\pi \omega_0 h)\).
- Suponha que gostaríamos de prever uma única série estacionária \(X_t\) com função de média zero e
função de autocorrelação \(\rho(h)\) em algum momento no futuro, digamos, \(t + \ell\), para \(\ell> 0\).
- (a) Se prevermos usando apenas \(X_t\) e algum multiplicador de escala \(A\), mostre que o erro médio de predição \begin{equation} \mbox{MSE}(A)=\mbox{E}\big( (X_{t+\ell}-A X_t)^2\big), \end{equation} é minimizado pelo valor \(A=\rho(\ell)\).
- (b) Mostre que o mínimo do erro médio de predição é \begin{equation} \mbox{MSE}(A)=\gamma(0)\big( 1-\rho^2(\ell)\big)\cdot \end{equation}
- (c) Mostre que se \(X_{t+\ell}=A X_t\), então \(\rho(\ell)=1\) se \(A>0\) e \(\rho(\ell)=-1\) se \(A<0\).
- Considere as duas séries \(X_t=W_t\) e \(Y_t=W_t-\theta W_{t-1}+U_t\), onde \(W_t\) e \(U_t\) são dois
ruídos brancos independentes com variâncias \(\sigma^2_{_W}\) e \(\sigma^2_{_U}\), respectivamente e \(\theta\) é uma
constante não especificada.
- (a) Expressar a ACF, \(\rho_{_Y}(h)\), para \(h=0,\pm 1, \pm 2, \cdots\) da série \(Y_t\) como função de \(\sigma^2_{_W}\), \(\sigma^2_{_U}\) e \(\theta\).
- (b) Determine a CCF, \(\rho_{_{XY}}(h)\) relacionando as séries \(X_t\) e \(Y_t\).
- (c) Mostre que \(X_t\) e \(Y_t\) são conjuntamente estacionárias.
- Seja \(X_t\) um processo normal estacionário com a função de média \(\mu_{_X}\) e autocovariância \(\gamma_{_X}(h)\).
Defina a série temporal não linear \(Y_t=\exp (X_t)\).
- (a) Expresse a função de média \(\mbox{E}(Y_t)\) em termos de \(\mu_X\) e \(\gamma(0)\). A função geradora de momentos de uma variável aleatória \(Normal(\mu,\sigma^2)\) é \begin{equation} \mbox{M}_X(t)=\mbox{E}\big( \exp(tX)\big) = \exp\Big( \mu t+\frac{1}{2}\sigma^2 t^2\Big)\cdot \end{equation}
- (b) Determine a função de autocovariância de \(Y_t\). Lembrando que a soma de duas variáveis aleatórias normais \(X_{t+h}\) e \(X_t\), ainda é uma variável aleatória normal.
- Seja \(W_t\), para \(t=0,\pm 1,\pm 2,\cdots\) um processo ruído branco normal e considere a série temporal \begin{equation} X_t=W_t W_{t-1}\cdot \end{equation} Determine a função de média e de autocovariância de \(X_t\) e indique se ela é estacionária.
- Considere a série \(X_t=\sin(2\pi U t)\), para \(t=1,2,\cdots\) onde \(U\sim U(0,1)\), ou seja, \(U\) é uma variável aleatória
distribuição uniforme no intervalo \((0,1)\).
- (a) Prove que \(X_t\) é fracamente estacionária.
- (b) Prove que \(X_t\) não é estritamente estacionária.
- Suponha que tenhamos o processo linear \(X_t\) gerado por \(X_t=W_t-\theta W_{t-1}\), para \(t=0,1,2,\cdots\) onde \(W_t\) são
independentes e identicamente distribuídas com função característica \(\varphi_{_W}(\cdot)\) e \(\theta\) é uma
constante fixa.
- (a) Expresse a função característica conjunta de \(X_1,X_2,\cdots,X_n\) digamos \begin{equation} \varphi_{_{X_1,X_2,\cdots,X_n}}(t_1,t_2,\cdots,t_n), \end{equation} em termos de \(\varphi_{_W}(\cdot)\).
- (b) Deduzir de (a) se \(X_t\) é estritamente estacionária.
- Suponha que \(X_t\) seja um processo linear. Prove que \begin{equation} \sum_{h=-\infty}^\infty |\gamma(h)|<\infty\cdot \end{equation}
- Suponha que \(X_t=\mu+W_t+\theta W_{t-1}\), onde \(W_t\sim N(0,\sigma_{_W}^2)\) é um ruído branco.
- (a) Mostre que a função de média é \(\mbox{E}(X_t)=\mu\).
- (b) Mostre que a função de autocovariância de \(X_t\) é dada por \(\gamma_{_X}(0)=\sigma^2_{_W} (1+\theta^2)\), \(\gamma_{_X}(\pm 1)=\sigma^2_{_W}\theta\) e que \(\gamma_{_X}(h)=0\) caso contrário.
- (c) Mostre que \(X_t\) é estacionário para todo valor de \(\theta\in\mathbb{R}\).
- (d) Calcule \(\mbox{Var}(\overline{X})\) como estimador de \(\mu\) quando (i) \(\theta=1\), (ii) \(\theta=0\) e (iii) \(\theta=-1\).
- (e) Em séries temporais, o tamanho da amostra \(n\) é tipicamente grande, de modo que \((n-1)/n\approx 1\). Com isso em consideração, comente os resultados da parte (d); em particular, como é que a precisão na estimativa da média muda para os três casos diferentes?
-
- (a) Simule uma série de \(n = 500\) observações de um processo ruído branco Gaussiano como no Exemplo I.8 e calcule a função ACF mostral \(\widehat{\rho}(h)\), para até o lag 20. Compare a ACF amostral que você obteve com o ACF real \(\rho(h)\).
- (b) Repita a parte (a) usando apenas \(n = 50\). Como mudar \(n\) afeta os resultados?
-
- (a) Simule uma série de \(n = 500\) observações de um processo de médias móveis como no Exemplo I.9 e calcule a função ACF mostral \(\widehat{\rho}(h)\), para até o lag 20. Compare a ACF amostral que você obteve com o ACF real \(\rho(h)\).
- (b) Repita a parte (a) usando apenas \(n = 50\). Como mudar \(n\) afeta os resultados?
- Embora o modelo no Exercício 2 (a) não seja estacionário, a função ACF amostral pode ser informativa. Para os dados gerados nesse problema, calcule e mostre a ACF amostral e, em seguida, comente.
- Para a série temporal \(Y_t\) descrita no Exemplo I.26, verifique o resultado declarado: \(\rho_{_Y}(1)=0.47\) e que \(\rho_{_Y}(h)=0\), para \(h>1\).
- Uma função real \(g(t)\), definida nos inteiros, é dita definida não negativa se, e somente se,
\begin{equation}
\sum_{i=1}^n \sum_{j=1}^n a_i g(t_i-t_j)a_j\geq 0,
\end{equation}
para todos os números inteiros \(n\) e para todos os vetores \(a=(a_1,a_2,\cdots,a_n)^\top\) e \(t=(t_1,t_2,\cdots,t_n)^\top\).
Para a metriz \(G=\{g(t_i-t_j)\}_{i,j=1}^n\) implica que \(a^\top G a\geq 0\) para todos os vetores \(a\). É chamado de positiva
definida se substituímos \(\geq\) por \(>\), para todo \(a\neq 0\), o vetor nulo.
- (a) Prove que \(\gamma(h)\), a função de autocovariância de um processo estacionário, é uma função definida não negativa.
- (b) Verifique que a função de autocovariância amostral \(\widehat{\gamma}(h)\) é uma função definida não negativa.
- Considere a coleção de séries temporais \(X_{1t},X_{2t},\cdots,X_{Nt}\) que estão observando algum sinal
comum \(\mu_t\) observado em processos de ruído \(\epsilon_{1t},\epsilon_{2t},\cdots,\epsilon_{Nt}\), com o modelo para a \(j\)-ésima
série observada dada por
\begin{equation}
X_{jt}=\mu_t+\epsilon_{jt}\cdot
\end{equation}
Suponha que as séries de ruído tenham média zero e não sejam correlacionadas para diferentes \(j\). As funções
de autocovariância comum de todas as séries é dada por \(\gamma_{_\epsilon}(s,t)\). Definir a média amostral como
\begin{equation}
\overline{X}_t=\frac{1}{N}\sum_{j=1}^N X_{jt}\cdot
\end{equation}
- (a) Prove que \(\mbox{E}(\overline{X}_t)=\mu_t\).
- (b) Prove que \(\mbox{E}\Big(\big(\overline{X}_t-\mu_t\big)^2\Big)=\frac{1}{N}\gamma_{_\epsilon}(t,t)\).
- Como podemos usar os resultados para estimar o sinal comum?
- Um conceito usado em geoestatística, veja Journel e Huijbregts (1978) ou Cressie (1993), é o do variograma, definido para um processo espacial \(X_s\), \(s=(s_1,s_2)\), e \(s_1,s_2=0,\pm 1,\pm 2,\cdots\) como \begin{equation} V_{_X}(h)=\frac{1}{2}\mbox{E}\big( (X_{s+h}-X_s)^2\big), \end{equation} onde \(h=(h_1,h_2)\), para \(h_1,h_2=0,\pm 1,\pm 2,\cdots\). Mostre que, para um processo estacionário, as funções de variograma e autocovariância podem ser relacionadas como \begin{equation} V_{_X}(h)=\gamma(0)-\gamma(h), \end{equation} onde \(\gamma(h)\) é a função usual de covariância no lag \(h\) e \(0 = (0,0)\). Observe a extensão a qualquer dimensão espacial.
- Suponhamos que \(X_t=\beta_0+\beta_1 t\), onde \(\beta_0\) e \(\beta_1\) são constantes. Prove que \begin{equation} \lim_{n\to\infty} \widehat{\rho}(h)=1, \end{equation} para \(h\) fixo, onde \(\widehat{\rho}(h)\) é a função de autocorrelação amostral definida na Definição I.15.
-
- (a) Suponha que \(X_t\) seja uma série temporal fracamente estacionária com função de média zero função de autocovariância absolutamente convergente \(\gamma(h)\), tal que \begin{equation} \sum_{h=-\infty}^\infty \gamma(h)=0\cdot \end{equation} Prove que \begin{equation} \lim_{n\to\infty} P(\sqrt{n}|\overline{X}|>\epsilon)=0, \end{equation} para todo \(\epsilon >0\), onde \(\overline{X}\) é a média amostral.
- (b) Dêê um exemplo de um processo que satisfaça as condições da parte (a). O que há de especial nesse processo?