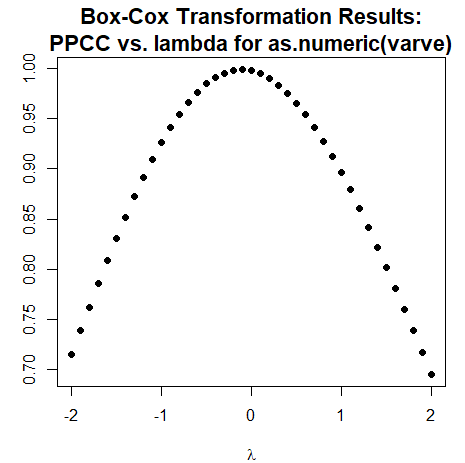O modelo linear e suas aplicações são pelo menos tão dominantes no contexto de séries temporais quanto na
estatística clássica. Modelos de regressão são importantes para os modelos de domínio no tempo discutidos
nos Capítulo III, Capítulo V e Capítulo VI e nos modelos de domínio de frequência considerados
nos Capítulo IV e Capítulo VII. As ideias primárias dependem da capacidade de expressar uma série de respostas,
digamos \(X_t\), como uma linear combinação de entradas, digamos \(Z_{t_1},Z_{t_2},\cdots,Z_{t_q}\). Estimando os coeficientes
\(\beta_1,\beta_2,\cdots,\beta_q\) nas combinações lineares por mínimos quadrados fornece um método para modelar
\(X_t\) em termos das entradas.
Nas aplicações no domínio do tempo no Capítulo III, por exemplo, expressaremos \(X_t\) como uma combinação
linear dos valores anteriores \(X_{t-1},X_{t-2},\cdots,X_{t-p}\), da série atualmente observada. As saídas \(X_t\) também
podem depender de valores defasados de outra série, digamos \(Y_{t-1},Y_{t-2},\cdots,Y_{t-q}\), que têm influência. É fácil
ver que a previsão se torna uma opçõo quando os modelos de previsão podem ser formulados dessa forma. A suavização
e a filtragem de séries temporais podem ser expressos em termos de modelos de regressão locais. Polinômios e regressão splines
também fornecem técnicas importantes para suavização.
Se alguém admite senos e cosenos como entradas, as ideias do domínio da frequência que levam ao periodograma e espectro no
Capítulo IV seguem a partir de um modelo de regressão. Extensões para filtros de extensão infinita podem
ser tratadas usando regressão no domínio da frequência. Em particular, muitos problemas de regressão no domínio
da frequência podem ser realizados em função dos componentes periódicos das séries de entrada e saída,
fornecendo uma intuição científica útil em campos como acústica, oceanografia, engenharia, biomedicina e
geofísica.
As considerações acima nos motivam a incluir uma parte separada sobre regressão e algumas de suas aplicações que
são escritas em um nível elementar e são formuladas em termos de séries temporais. A suposição de linearidade,
estacionariedade e homogeneidade de variâncias ao longo do tempo é crítica no contexto de regressão e, portanto, incluímos
algum material sobre transformações e outras técnicas úteis na análise exploratória de dados.
II.1 Regressão clássica no contexto de séries temporais
Começamos nossa discussão de regressão linear no contexto de séries temporais, assumindo alguma saída ou séries
temporais dependentes, digamos que \(X_t\), para \(t = 1,\cdots,n\), está sendo influenciado por uma coleção de entradas possíveis
ou séries independentes, digamos \(Z_{t_1},Z_{t_2},\cdots,Z_{t_q}\), onde primeiro consideramos as entradas como fixas e conhecidas. Essa
suposição, necessária para aplicar a regressão linear convencional, será relaxada posteriormente. Expressamos essa
relação através do modelo de regressão linear
\begin{equation}
X_t \, = \, \beta_1 Z_{t_1}+\beta_2 Z_{t_2}+\cdots+\beta_q Z_{t_q}+W_t
\end{equation}
onde \(\beta_1,\beta_2,\cdots,\beta_q\) são coeficientes de regressão fixos desconhecidos e \(\{W_t\}\) é um erro aleatório
ou processo de ruído consistindo em variáveis normais independentes e identicamente distribuídas (iid) com média zero e
variância \(\sigma_{_W}^2\). Vamos relaxar a idéia iid mais tarde. Um cenário mais geral dentro do qual incorporar a estimação por
mínimos quadrados e a regressão linear é dado no Apêndice B, onde apresentamos os espaços de Hilbert e o
Teorema da Projeção.
Exemplo II.1. Estimando uma tendência linear
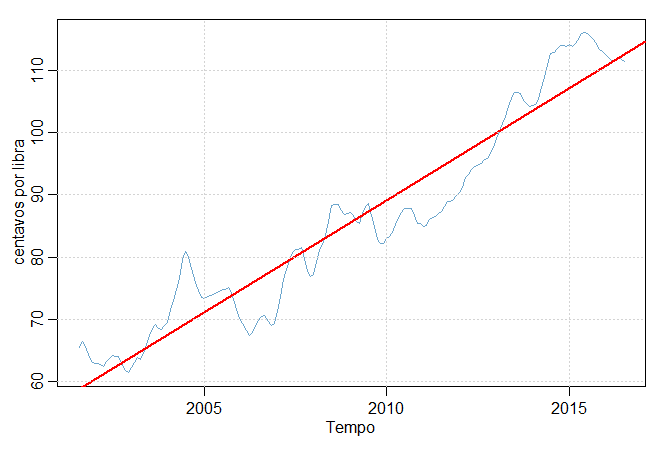
Considere o preço mensal, em libras, de um frango nos EUA entre meados de 2001 e meados de 2016, ou seja, por 180 meses, digamos \(X_t\),
mostrado na figura abaixo. Há uma tendência ascendente óbvia na série, e podemos usar a regressão linear
simples para estimar essa tendência ajustando o modelo
\begin{equation}
X_t \, = \, \beta_0+\beta_1 z_t+W_t, \qquad z_t=2001\frac{7}{12},2001\frac{8}{12},\cdots,2016\frac{6}{12}\cdot
\end{equation}
Isso está na forma do modelo de regressão com \(q = 1\). Observe que estamos supondo que os erros \(W_t\), são uma sequência
normal, o que pode não ser verdade. O problema dos erros autocorrelacionados é discutido em detalhes no Capítulo III.
Em mínimos quadrados ordinários (OLS), minimizamos a soma dos quadrados de erros
\begin{equation}
Q \, = \, \displaystyle\sum_{t=1}^n w_t^2 \, = \, \sum_{t=1}^n \Big(x_t-\big(\beta_0+\beta_1 z_t\big)\Big)^2,
\end{equation}
com respeito a \(\beta_i\), \(i=0,1\). Neste caso, podemos usar cálculos simples para avaliar \(\partial Q/\partial \beta_i=0\) para \(i = 0,1\),
e assim obter duas equações para resolver os \(\beta\)s. As estimativas OLS dos coeficientes são explícitas e
dadas por
\begin{equation}
\widehat{\beta}_1=\dfrac{\sum_{t=1}^n (x_t-\overline{x})(z_t-\overline{z})}{\sum_{t=1}^n (z_t-\overline{z})^2},
\qquad \mbox{e} \qquad \widehat{\beta}_0=\overline{x}-\widehat{\beta}_1\overline{z},
\end{equation}
onde \(\overline{x}=\sum_{t=1}^n x_t\) e \(\overline{z}=\sum_{t=1}^n z_t\) são as respectivas médias amostrais.
Usando R, obtivemos o coeficiente de declive estimado de \(\widehat{\beta}_1 = 3.592\) com um erro padrão de 0.08, resultando em
um aumento estimado de aproximadamente 3.6 centavos por ano.
Finalmente, a figura acima mostra os dados do preço do frango: preço spot mensal de aves inteiras, docas da Geórgia, US centavos por
libra, agosto de 2001 a julho de 2016, com com a linha de tendência estimada sobreposta. Código R:
> summary(fit <- lm(chicken~time(chicken), na.action=NULL))
Call:
lm(formula = chicken ~ time(chicken), na.action = NULL)
Residuals:
Min 1Q Median 3Q Max
-8.7411 -3.4730 0.8251 2.7738 11.5804
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -7.131e+03 1.624e+02 -43.91 <2e-16 ***
time(chicken) 3.592e+00 8.084e-02 44.43 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 4.696 on 178 degrees of freedom
Multiple R-squared: 0.9173, Adjusted R-squared: 0.9168
F-statistic: 1974 on 1 and 178 DF, p-value: < 2.2e-16
> par(mfrow=c(1,1), mar=c(4,3,1,1), mgp=c(1.6,.6,0))
> plot(chicken, xlab="Tempo", ylab="centavos por libra", pch=19, col="skyblue3")
> abline(fit, lwd=2, col="red") # adicionando a linha estimada
> grid()
O modelo de regressão linear descrito acima pode ser convenientemente escrito em notação matricial, definindo os vetores
coluna \(Z_t = (Z_{t_1},Z_{t_2},\cdots,Z_{t_q})^\top\) e \(\beta= (\beta_1,\beta_2,\cdots,\beta_q)^\top\). Então podemos escrever
na forma alternativa
\begin{equation}
X_t=\beta^\top Z_t+W_t,
\end{equation}
onde \(W_t\sim N(0,\sigma_{_W}^2)\) independentes identicamente distribuídas. É natural considerar a estimativa do vetor de coeficientes desconhecidos, minimizando a soma dos quadrados dos
erros
\begin{equation}
Q=\sum_{t=1}^n W_t^2=\sum_{t=1}^n\big( x_t-\beta^\top z_t\big)^2,
\end{equation}
com relação a \(\beta_1,\beta_2,\cdots,\beta_q\). Minimizar \(Q\) produz o estimador de mínimos quadrados ordinários de \(\beta\).
Esta minimização pode ser realizada diferenciando a expressão acima em relação ao vetor \(\beta\) ou usando
as propriedades das projeções. Na notação acima, este procedimento fornece as equações normais
\begin{equation}
\Big( \sum_{t=1}^n z_t z_t^\top\Big)\widehat{\beta}=\sum_{t=1}^n z_t x_t \cdot
\end{equation}
A notação pode ser simplificada definndo-se \(Z=(Z_1|Z_2|\cdots|Z_n)^\top\) como a matriz \(n\times q\) composta das \(n\) amostras
das variáveis de entrada, o vetor \(n\times 1\) observado \(x = (x_1,x_2,\cdots,x_n)\) e o vetor \(n\times 1\) de erros \(w=(w_1,w_2,\cdots,w_n)^\top\).
Neste caso, o modelo de regressão pode ser escrito como
\begin{equation}
x = Z\beta+w\cdot
\end{equation}
As equações normais podem ser escritas como \(Z^\top Z\widehat{\beta}=Z^top x\) e a solução é
\begin{equation}
\widehat{\beta}=(Z^\top Z)^{-1}Z^\top x
\end{equation}
quando a matriz \(Z^\top Z\) é não singular. A soma dos erros quadrados minimizada, denotada por \(SSE\), pode ser escrita como
\begin{equation}
\begin{array}{rcl}
SSE & = & \displaystyle \sum_{t=1}^n \big( x_t-\widehat{\beta}^\top z_t\big)^2 \, = \, \big( x-\widehat{\beta}\big)^\top \big( x-\widehat{\beta}\big) \\
& = & x^\top x-\widehat{\beta}^\top Z^\top x \, = \, x^\top x-x^\top Z(Z^\top Z)^{-1} Z^\top x,
\end{array}
\end{equation}
para dar algumas versões úteis para referência posterior. Os mínimos quadrados ordinários são estimadores
não-viesados., ou seja, \(\mbox{E}(\widehat{\beta})=\beta\) e têm a menor variância dentro da classe de estimadores lineares
não-viesados.
Se o vetor de erro \(W_t\) for normalmente distribuído, \(\widehat{\beta}\) é também o estimador de máxime verossimilhança
de \(\beta\) e é normalmente distribuído com
\begin{equation}
\mbox{Cov}(\widehat{\beta})=\sigma_{_W}^2\Big(\sum_{t=1}^n Z_t^\top z_t\Big)^{-1} = \sigma_{_W}^2 (Z^\top Z)^{-1} = \sigma_{_W}^2 C,
\end{equation}
onde \(C=(Z^\top Z)^{-1}\) é uma notação conveniente para equações posteriores.
Um estimador não-viesadoo para a variância \(\sigma^2_{_W}\) é
\begin{equation}
\sigma^2_{_W} = MSE = \dfrac{SSE}{n-q},
\end{equation}
onde \(MSE\) denota o erro quadrático médio, que é contrastado com o estimador de máxima verossimilhança
\(\sigma^2_{_W} = SSE/n\). Sob a suposição de normalidade, \(\sigma^2_{_W}\) é distribuído proporcionalmente a uma
variável aleatória qui-quadrado com \(n-q\) graus de liberdade, denotada por \(\chi^2_{n-q}\) e independentemente de \(\widehat{\beta}\).
Segue que
\begin{equation}
t_{n-q}=\dfrac{\widehat{\beta}_i-\beta_i}{s_{_W}\sqrt{c_{ii}}},
\end{equation}
tem a distribuição \(t-Student\) com \(n-q\) graus de liberdade e \(c_{ii}\) denota o \(i\)-ésimo elemento diagonal
da matriz \(C\).
Fonte
g.l.
Soma de Quadrados
Quadrados Médios
\(z_{t,r+1},\cdots,z_{t,q}\)
q-r
\(SSR=SSE_r-SSE\)
\(MSR=SSR/(q-r)\)
Erro
n-q
\(SSE\)
\(MSR=SSE/(n-q)\)
Total
n-r
\(SSE_r\)
Tabela II.1. Análise de Variância para a Regressão
Vários modelos concorrentes são de interesse para isolar ou selecionar o melhor subconjunto de variáveis independentes.
Suponha que um modelo proposto especifique que apenas um subconjunto \(r < q\) variáveis independentes, digamos, \(z_{t:r} = (z_{t1},z_{t2},\cdots,z_{tr})^\top\)
está influenciando a variável dependente \(X_t\). O modelo reduzido é
\begin{equation}
X=Z_r \beta_r+W,
\end{equation}
onde \(\beta_r=(\beta_1,\beta_2,\cdots,\beta_r)^\top\) é um subconjunto de coeficientes das \(q\) variáveis originais e \(Z_r=(Z_{1:r}|\cdots|z_{n:r})^\top\)
é a matriz \(n\times r\) de entradas.
A hipótese nula neste caso é \(H_0: \beta_{r+1}=\cdots=\beta_{q} = 0\). Podemos testar o modelo reduzido contra o modelo
completo comparando as somas de erro dos quadrados sob os dois modelos usando a estatística \(F\), dada por
\begin{equation}
F_{q-r,n-q}=\dfrac{\dfrac{SSE_r-SSE}{q-r}}{\dfrac{SSE}{n-q}},
\end{equation}
a qual tem distribuição \(F-Fisher\) central com \(q-r\) e \(n-q\) graus de liberdade, quando é o modelo correto.
Note que \(SSE_r\) é a soma de erros dos quadrados sob o modelo reduzido e pode ser calculado substituindo \(Z\) por \(Z_r\). A
estatística, que segue da aplicação do critério da razão de verossimilhanças, tem a melhoria por
número de parâmetros adicionados no numerador em comparação com a soma dos quadrados de erros sob o modelo completo
no denominador. A informação envolvida no procedimento de teste é frequentemente resumida em uma tabela de Análise de
Variância (ANOVA) para este caso particular. A diferença no numerador é geralmente chamada de soma dos quadrados da regressão.
Em termos da tabela ANOVA é convencional escrever a estatística \(F\) como a razão dos dois quadrados médios, obtendo-se
\begin{equation}
F_{q-r,n-q}=\dfrac{MSR}{MSE},
\end{equation}
onde \(MSR\) é a regressão quadrática média. Um caso especial de interesse é \(r = 1\) e \(z_{t1}=1\),
quando o modelo se torna
\begin{equation}
X_t=\beta_1+W_t,
\end{equation}
e podemos medir a proporção da variação expliacada pelas outras variáveis usando
\begin{equation}
R^2= \dfrac{SSE_1-SSE}{SSE_1},
\end{equation}
onde a soma de quadrados residual sob o modelo reduzido \(SSE_1=\sum_{t=1}^n(x_t-\overline{x})^2\), neste caso, é apenas
a soma dos desvios quadrados da média \(\overline{x}\). A medida \(R^2\) é também a correlação múltipla
ao quadrado entre \(x_t\) e as variáveis \(z_{t2},z_{t3},\cdots,z_{tq}\).
> aov(fit)
Call:
aov(formula = fit)
Terms:
time(chicken) Residuals
Sum of Squares 43547.11 3925.94
Deg. of Freedom 1 178
Residual standard error: 4.696366
Estimated effects may be unbalanced
As técnicas discutidas no parágrafo anterior podem ser usadas para testar vários modelos uns contra os outros usando o
teste \(F\) dado e a tabela ANOVA. Esses testes foram usados no passado de maneira gradual, onde as variáveis são adicionadas ou
excluídas quando os valores do teste \(F\) excedem ou não níveis predeterminados. O procedimento, chamado de regressão
múltipla gradual ou stepwise, é útil para se chegar a um conjunto de variáveis úteis. Uma alternativa é
focar em um procedimento para seleção de modelos que não prossiga sequencialmente, mas simplesmente avalia cada modelo
por seus próprios méritos.
Suponha que consideremos um modelo de regressão normal com \(k\) coeficientes e denote o estimador de máxima verossimilhança
para a variância como
\begin{equation}
\widehat{\sigma}_k^2=\frac{SSE_k}{n},
\end{equation}
onde \(SSE_k\) denota a soma de quadrados residual sob o modelo com \(k\) coeficientes de regressão. Então, Akaike (1969, 1973, 1974)
sugeriu medir a adequação do ajuste para este modelo específico, equilibrando o erro do ajuste com o número de
parâmetros no modelo; definimos o seguinte.
Definição II.1. Critério de Informação de Akaike (AIC)
O Critério de Informação de Akaike ou AIC é definido como
\begin{equation}
AIC=\log\big( \widehat{\sigma}_k^2\big)+\frac{n+2k}{n},
\end{equation}
onde \(\widehat{\sigma}_k^2=SSE_k/n\), \(k\) é o número de parâmetros no modelo e \(n\) é o tamanho da amostra.
Formalmente, o AIC é definido como \(-2\log(\ell_k) + 2k\), em que \(\ell_k\) é a log-verossimilhança maximizada e \(k\) é o
número de parâmetros no modelo. Para o problema de regressão normal, o AIC pode ser reduzido para a forma dada acima. O AIC é
uma estimativa da discrepância de Kullback-Leibler entre o modelo verdadeiro e um modelo candidato, veja os Exercícios II.4 e II.5 para
maiores detalhes.
O valor de \(k\) que gera o mínimo do AIC especifica o melhor modelo. A idéia é que a minimização de \(\widehat{\sigma}_k^2\)
seria um objetivo razoável, exceto que diminui monotonicamente à medida que \(k\) aumenta. Portanto, devemos penalizar a variância do erro
por um termo proporcional ao número de parâmetros. A escolha do termo de penalidade não é o único, e uma considerável
literatura está disponível defendendo termos de penalidade diferentes.
Uma forma corrigida, sugerida por Sugiura (1978) e expandida por Hurvich e Tsai (1989), pode ser baseada em resultados da distribuição de amostras pequenas
para o modelo de regressão linear os detalhes são fornecidos nos Exercícios II.4 e II.5. A forma corrigida é definida da seguinte maneira.
Definição II.2. Critério de Informação de Akaike Corrigido (AICc)
O Critério de Informação de Akaike Corrigido ou AICc é definido como
\begin{equation}
AICc=\log\big( \widehat{\sigma}_k^2\big)+\frac{n+k}{n-k-2},
\end{equation}
onde \(\widehat{\sigma}_k^2=SSE_k/n\), \(k\) é o número de parâmetros no modelo e \(n\) é o tamanho da amostra.
Podemos também derivar um termo de correção baseado em argumentos bayesianos, como em Schwarz (1978), que leva ao
seguinte.
Definição II.3. Critério de Informação Bayesiana (BIC)
O Critério de Informação de Akaike Corrigido ou AICc é definido como
\begin{equation}
BIC=\log\big( \widehat{\sigma}_k^2\big)+\frac{k\log(n)}{n},
\end{equation}
onde \(\widehat{\sigma}_k^2=SSE_k/n\), \(k\) é o número de parâmetros no modelo e \(n\) é o tamanho da amostra.
O BIC também é chamado de Critério de Informação Schwarz (SIC); veja também Rissanen (1978) para
uma abordagem que produz a mesma estatística baseada em um argumento de tamanho mínimo de descrição. Vários estudos
de simulação tendem a verificar que o BIC faz bem em obter a ordem correta em amostras grandes, enquanto o AICc tende a ser
superior em amostras menores, onde o número relativo de parâmetros é grande. Veja McQuarrie e Tsai (1998) para
comparações detalhadas. Em modelos de regressão, duas medidas que foram usadas no passado são o \(R^2\) ajustado, que
é essencialmente \(\sigma^2_{_W}\) e o \(C_p\) de Mallows, Mallows (1973), que não consideramos neste contexto.
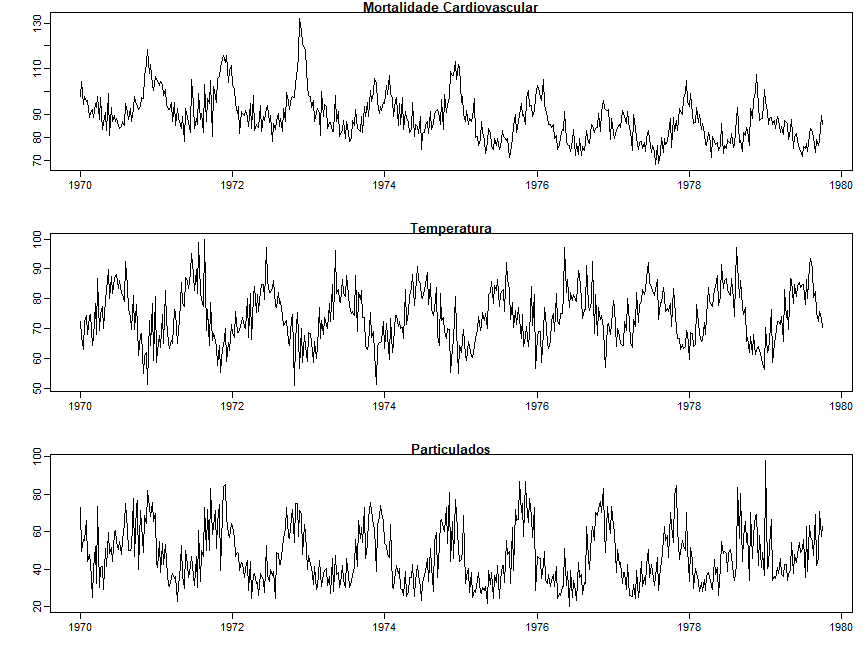
Exemplo II.2. Poluição, Temperatura e Mortalidade
Os dados mostrados na figura abaixo foram extraídos de um estudo de Shumway et al. (1988) dos possíveis efeitos da temperatura e
a poluição na mortalidade semanal no Condado de Los Angeles. Observe os fortes componentes sazonais em todas as séries,
correspondentes às variações inverno-verão no hemisfério norte e a tendência de queda na mortalidade
cardiovascular no período de 10 anos.
Nesta figura mostra-se o gráfico da mortalidade cardiovascular média semanal (topo), a temperatura média e a poluição
por partículas ao fundo, no condado de Los Angeles. Existem 508 médias suavizadas de seis dias obtidas pelo lastreamento dos valores
diários ao longo do período de 10 anos, de 1970 a 1979.
Para plotar os dados digite os seguintes comandos:
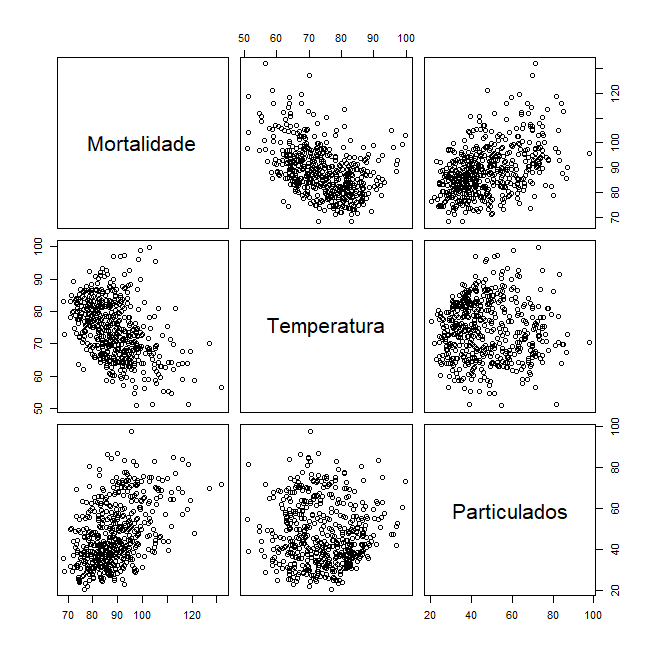
Uma matriz de dispersão, mostrada na figura a seguir, indica uma possível relação linear entre a mortalidade e as
partículas poluentes e uma possível relação com a temperatura. Observe a forma curvilínea da curva de mortalidade por
temperatura, indicando que temperaturas mais altas e temperaturas mais baixas estão associadas ao aumento da mortalidade cardiovascular.
Para plotar os dados digite os seguintes comandos:
> dev.new() # abrindo um novo dispositivo gráfico para a matriz do gráfico de dispersão
NULL
> pairs(cbind(Mortalidade=cmort, Temperatura=tempr, Particulados=part))
Com base na matriz do gráfico de dispersão, entretemos, experimentalmente, quatro modelos em que \(M_t\) denota a mortalidade cardiovascular, \(T_t\)
denota temperatura e \(P_t\) indica os níveis de partículas. Eles são
\begin{equation}
\begin{array}{rcl}
(A) \quad M_t & = & \beta_1+\beta_2 t+W_t \\
(B) \quad M_t & = & \beta_1+\beta_2 t+\beta_3(T_t-T_{\cdot})+W_t \\
(C) \quad M_t & = & \beta_1+\beta_2 t+\beta_3(T_t-T_{\cdot})+\beta_4(T_t-T_{\cdot})^2+W_t \\
(D) \quad M_t & = & \beta_1+\beta_2 t+\beta_3(T_t-T_{\cdot})+\beta_4(T_t-T_{\cdot})^2+\beta_5P_t+W_t \\
\end{array}
\end{equation}
onde ajustamos a temperatura por sua média, \(T_{\cdot} = 74.26041\), para evitar problemas de escala. É claro que o modelo em (A) é um
modelo somente de tendência, (B) é a temperatura linear, (C) é a temperatura curvilínea e (D) é a temperatura
curvilínea e a poluição. Resumimos algumas das estatísticas dadas para este caso particular na tabela abaixo. Os
valores de \(R^2\) foram computados observando que \(SSE_1 = 50687\).
Modelo
k
SSE
df
MSE
\(R^2\)
AIC
BIC
(A)
2
40020
506
79.0
0.21
5.38
5.40
(B)
3
31413
505
62.2
0.38
5.14
5.17
(C)
4
27985
504
55.5
0.45
5.03
5.07
(D)
5
20508
503
40.8
0.60
4.72
4.77
Tabela II.2. Estatísticas resumidas para modelos de mortalidade
Mostramos o código pata ajustar o modelo de regressão final e computar os valores correspondentes fazendo uso de na.action em lm() com o obajetivo de reter os atributos da série temporal
para os valores residuais e ajustados.
> temp = tempr-mean(tempr) # centralizando a temperatura
> temp2 = temp^2
> trend = time(cmort) # tempo
> fit = lm(cmort~ trend + temp + temp2 + part, na.action=NULL)
> summary(fit) # resultados da regressão
Call:
lm(formula = cmort ~ trend + temp + temp2 + part, na.action = NULL)
Residuals:
Min 1Q Median 3Q Max
-19.0760 -4.2153 -0.4878 3.7435 29.2448
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.831e+03 1.996e+02 14.19 < 2e-16 ***
trend -1.396e+00 1.010e-01 -13.82 < 2e-16 ***
temp -4.725e-01 3.162e-02 -14.94 < 2e-16 ***
temp2 2.259e-02 2.827e-03 7.99 9.26e-15 ***
part 2.554e-01 1.886e-02 13.54 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 6.385 on 503 degrees of freedom
Multiple R-squared: 0.5954, Adjusted R-squared: 0.5922
F-statistic: 185 on 4 and 503 DF, p-value: < 2.2e-16
> summary(aov(fit)) # tabela ANOVA (compare com a próxima linha)
Df Sum Sq Mean Sq F value Pr(>F)
trend 1 10667 10667 261.62 <2e-16 ***
temp 1 8607 8607 211.09 <2e-16 ***
temp2 1 3429 3429 84.09 <2e-16 ***
part 1 7476 7476 183.36 <2e-16 ***
Residuals 503 20508 41
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
> summary(aov(lm(cmort~cbind(trend, temp, temp2, part))))
Df Sum Sq Mean Sq F value Pr(>F)
cbind(trend, temp, temp2, part) 4 30178 7545 185 <2e-16 ***
Residuals 503 20508 41
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Notamos que cada modelo é substancialmente melhor do que o anterior e que o modelo incluindo temperatura, temperatura ao quadrado e partículas
é o melhor, representando cerca de 60% da variabilidade e com o melhor valor para AIC e BIC, por causa do grande tamanho da amostra,
AIC e AICc são quase os mesmos. Note que é possível comparar quaisquer dois modelos usando as somas residuais de quadrados. Assim, um
modelo com apenas tendência poderia ser comparado ao modelo completo usando \(q = 5\), \(r = 2\) e \(n = 508\), então
\begin{equation}
F_{3,503} \, = \, \frac{(40020-20508)/3}{20508/503} \, = \, 159.52,
\end{equation}
e \(p-valor=2.2e-16\), altamente significativo; isto implica que os modelos são diferentes.
> anova(lm(cmort~cbind(trend)),lm(cmort~cbind(trend, temp, temp2, part)))
Analysis of Variance Table
Model 1: cmort ~ cbind(trend)
Model 2: cmort ~ cbind(trend, temp, temp2, part)
Res.Df RSS Df Sum of Sq F Pr(>F)
1 506 40020
2 503 20508 3 19511 159.52 < 2.2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Obtemos assim o melhor modelo de previsão
\begin{equation}
\widehat{M}_t \, = \, 81.59 - 0.027_{(0.002)}t-0.473_{(0.032)}(T_t-74.6)+0.023_{(0.003)}(T_t-74.6)^2+0.255_{(0.019)}P_t,
\end{equation}
para mortalidade, onde os erros padrão são dados entre parênteses. Como esperado, uma tendência negativa está presente
no tempo, bem como um coeficiente negativo para a temperatura ajustada. O efeito quadrático da temperatura pode ser visto claramente nos
gráficos de dispersão. A poluição pesa positivamente e pode ser interpretada como a contribuição incremental
para mortes diárias por unidade de poluição particulada. Ainda seria essencial verificar a autocorrelação dos
resíduos \(\widehat{W}_t = M_t-\widehat{M}_t\), da qual há uma quantidade substancial, mas nós submetemos essa questão na Seção V.6
quando discutimos a regressão com erros correlacionados.
Abaixo está o código R para calcular os valores correspondentes de AIC, BIC e AICc.
Como mencionado anteriormente, é possível incluir variáveis defasadas em modelos de regressão de séries temporais
e continuaremos a discutir esse tipo de problema ao longo do texto. Este conceito é mais explorado nos Exercícios II.2 e II.11. A
seguir, um exemplo simples de regressão defasada.
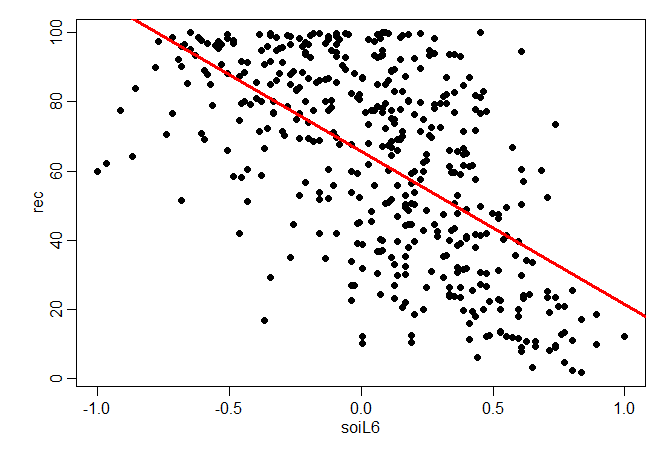
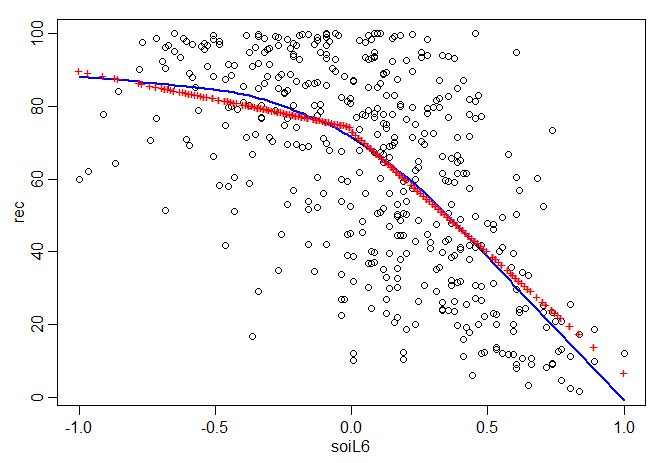
Exemplo II.3. Regressão com variáveis com defasagem
No Exemplo I.25, descobrimos que o Índice de Oscilação do Sul (SOI) medido no tempo \(t-6\) meses está associado à
série Recrutamento no tempo \(t\), indicando que o SOI lidera a série Recrutamento por seis meses. Embora haja evidências
de que a relação não é linear, podemos considerar a seguinte regressão
\begin{equation}
R_t=\beta_1+\beta_2 S_{t-6}+W_t,
\end{equation}
onde \(R_t\) denota o Recrutamento no tempo \(t\) e \(S_{t-6}\) denota o SOI seis meses antes. Assumindo que a sequência \(W_t\) é um
ruído branco, o modelo estimado é
\begin{equation}
\widehat{R}_t=65.790 - 44.283_{(2.781)}S_{t-6},
\end{equation}
com \(\widehat{\sigma}_{_W}=22.5\) e 445 graus de liberdade.
Para ajustar o modelo e plotar os dados digite os seguintes comandos:
> fish = ts.intersect(rec, soiL6=lag(soi,-6), dframe=TRUE)
> summary(fit1 <- lm(rec~soiL6, data=fish, na.action=NULL))
Call:
lm(formula = rec ~ soiL6, data = fish, na.action = NULL)
Residuals:
Min 1Q Median 3Q Max
-65.187 -18.234 0.354 16.580 55.790
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 65.790 1.088 60.47 <2e-16 ***
soiL6 -44.283 2.781 -15.92 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 22.5 on 445 degrees of freedom
Multiple R-squared: 0.3629, Adjusted R-squared: 0.3615
F-statistic: 253.5 on 1 and 445 DF, p-value: < 2.2e-16
> par(mar=c(4,4,1,1),mgp=c(1.6,.6,0))
> plot(fish$soiL6, fish$rec, xlab="soiL6", ylab="rec", pch=19)
> abline(fit1, col="red", lwd=3)
Esse resultado indica a forte capacidade preditiva do SOI para Recrutamento com seis meses de antecedência. É claro que ainda
é essencial verificar as premissas do modelo, mas novamente adiamos isso para mais tarde.
Realizar a regressão defasada no R é um pouco difícil porque as séries devem ser alinhadas antes de executar a
regressão. A maneira mais fácil de fazer isso é criar um objeto de dados que chamamos de fish usando ts.intersect,
que alinha a série com atraso.
A dor de cabeça de alinhar a série com atraso pode ser evitada usando o pacote R dynlm, como a seguir:
> library(dynlm)
> summary(fit2 <- dynlm(rec~ L(soi,6)))
Time series regression with "ts" data:
Start = 1950(7), End = 1987(9)
Call:
dynlm(formula = rec ~ L(soi, 6))
Residuals:
Min 1Q Median 3Q Max
-65.187 -18.234 0.354 16.580 55.790
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 65.790 1.088 60.47 <2e-16 ***
L(soi, 6) -44.283 2.781 -15.92 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 22.5 on 445 degrees of freedom
Multiple R-squared: 0.3629, Adjusted R-squared: 0.3615
F-statistic: 253.5 on 1 and 445 DF, p-value: < 2.2e-16
Observamos que o objeto fit2 é semelhante ao objeto fit1, mas os atributos da série temporal
são mantidos sem nenhum comando adicional.
II.2 Análise exploratória de dados
Em geral, é necessário que os dados das séries temporais sejam estacionários, de modo que a média dos produtos
defasados ao longo do tempo, como na seção anterior, será uma coisa sensata a ser feita. Com dados de séries temporais,
é a dependência entre os valores da série que é importante medir; devemos, pelo menos, ser capazes de estimar as
autocorrelações com precisão. Seria difícil medir essa dependência se a estrutura de dependência não
for regular ou estiver mudando a cada momento. Assim, para obter qualquer análise estatística significativa dos dados de séries
temporais será crucial que, ao menos, a média e a autocovariância satisfazem as condições de estacionariedade, pelo
menos durante um período razoável de tempo, estabelecidas na Definição I.7. Muitas vezes, esse não é o caso,
e mencionaremos alguns métodos nesta seção para minimizar os efeitos da não-estacionariedade, para que as propriedades
estacionárias da série possam ser estudadas.
Alguns dos nossos exemplos vieram de séries claramente não-estacionárias. A série da Johnson & Johnson, Exemplo I.1, tem uma
média que aumenta exponencialmente ao longo do tempo e o aumento na magnitude das flutuações em torno dessa tendência
causa mudanças na função de covariância; a variância do processo, por exemplo, aumenta claramente à medida
que se avança ao longo da duração da série. Além disso, a série da temperatura global mostrada no Exemplo I.2
contém algumas evidências de uma tendência ao longo do tempo; defensores do aquecimento global induzidos pelo homem aproveitam isso
como evidência empírica para avançar sua hipótese de que as temperaturas estão aumentando.
Talvez a forma mais fácil de não-estacionaridade seja trabalhar com o modelo estacionário de tendência, em que o processo
tem um comportamento estacionário em torno de uma tendência. Podemos escrever esse tipo de modelo como
\begin{equation}
X_t=\mu_t+Y_t,
\end{equation}
onde \(X_t\) são as observações, \(\mu_t\) denota a tendência e \(Y_t\) é um processo estacionário. Muitas vezes,
a tendência forte \(\mu_t\), obscurecerá o comportamento do processo estacionário, como veremos em numerosos exemplos. Assim,
há alguma vantagem em remover a tendência como primeiro passo em uma análise exploratória de tais séries temporais.
As etapas envolvidas são obter uma estimativa razoável da componente de tendência, digamos \(\widehat{\mu}_t\), e depois trabalhar
com os resíduos
\begin{equation}
\widehat{Y}_t=X_t-\widehat{\mu}_t\cdot
\end{equation}
Considere o seguinte exemplo.
Exemplo II.4. Preços do Frango
Aqui supomos que o modelo é da forma
\begin{equation}
X_t=\mu_t-Y_t,
\end{equation}
onde, como sugerimos na análise dos dados de temperatura global apresentados no Exemplo II.1, uma linha reta pode ser um modelo
razoável para a tendência, ou seja,
\begin{equation}
\mu_t=\beta_1+\beta_2 t\cdot
\end{equation}
Nesse exemplo, estimamos a tendência usando mínimos quadrados ordinários e encontramos
\begin{equation}
\widehat{\mu}_t=-7131+3.592 t,
\end{equation}
onde utilizamos \(t\) em vez de \(Z_t\) para o tempo. A figura no Exemplo II.1 mostra os dados com a linha de tendência estimada sobreposta. Para
obter as séries deduzidas, simplesmente subtraímos \(\widehat{\mu}_t\) das observações \(X_t\), para obter a
série
\begin{equation}
\widehat{Y}_t=x_t+7131-3.592 t\cdot
\end{equation}
Como o termo de erro, \(Y_t\), não é assumido como independente identicamente distribuído, o leitor pode achar que os
mínimos quadrados ponderados deveriam ser aplicados neste caso. O problema é que não sabemos o comportamento de \(Y_t\) e
é precisamente isso que estamos tentando avaliar neste estágio. Um resultado notável de Grenander e Rosenblatt (1957, Ch7),
entretanto, é que sob condições moderadas em \(Y_t\), para a regressão polinomial ou regressão periódica,
assintoticamente, mínimos quadrados ordinários são equivalentes a mínimos quadrados ponderados em relação
à eficiência.
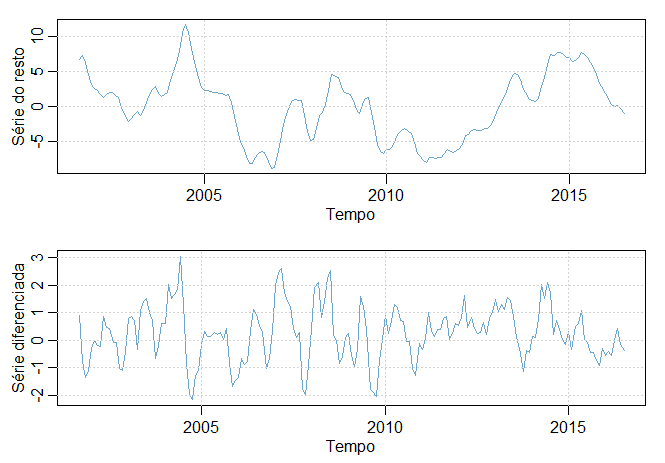
O gráfico superior da figura abaixo mostra a série retificada, ou seja, a diferença entre os dados orignais e a tendência estimada, chamada
também de série do resto. Na mesma figura, no gráfico inferior mostramos a primeira diferença da série.
Figura II.4 Série retificada (topo) e diferenciada (inferior) de preços de frango. Os dados originais são mostrados no Exemplo II.1.
Para diminuir a influência da tendência nas séries em R, use os seguintes comandos. Mostramos os resíduos e como diferenciar e plotar
os dados diferenciados. Discutimos a diferenciação após este exemplo.
No Exemplo I.11 vimos que um passeio aleatório também poderia ser um bom modelo para tendência. Ou seja, em vez de modelar a
tendência como fixa, como no Exemplo II.4, poderíamos modelar a tendência como um componente estocástico usando o modelo de
passeio aleatório com deslocamento aleatório,
\begin{equation}
\mu_t=\delta+\mu_{t-1}+W_t,
\end{equation}
onde \(W_t\) é um ruído branco independente de \(Y_t\). Se o modelo apropriado é \(X_t=\mu_t+Y_t\), então, diferenciar
os dados \(X_t\), produz um processo estacionário; isso é,
\begin{equation}
\begin{array}{rcl}
X_t-X_{t-1} & = & (\mu_t+Y_t)-(\mu_{t-1}+Y_{t-1}) \\
& = & \delta+W_t+Y_t-Y_{t-1}\cdot
\end{array}
\end{equation}
Pode-se mostrar \(Z_t = Y_t - Y_{t-1}\) é estacionário. Isto é, porque \(Y_t\) é estacionário,
\begin{equation}
\begin{array}{rcl}
\gamma_{_Z}(h) & = & \mbox{Cov}(Z_{t+h},Z_t) \, = \, \mbox{Cov}(Y_{t+h}-Y_{t+h-1},Y_t-Y_{t-1}) \\
& = & 2\gamma_{_Y}(h)-\gamma_{_Y}(h+1)-\gamma_{_Y}(h-1),
\end{array}
\end{equation}
é independente do tempo; deixamos isso como um exercício para mostrar que \(X_t-X_{t-1}\) acima é estacionário.
Uma vantagem da diferenciação em remover a tendência é que nenhum parâmetro é estimado na operação
de diferenciação. Uma desvantagem, no entanto, é que a diferenciação não produz uma estimativa do
processo estacionário \(Y_t\). Se uma estimativa de \(Y_t\) é essencial, então a desvantagem pode ser mais apropriada.
Se o objetivo é coagir os dados para a estacionaridade, então a diferenciação pode ser mais apropriada. A
diferenciação também é uma ferramenta viável se a tendência for fixa, como no Exemplo II.4. Isto é,
por exemplo, se \(\mu_t = \beta_1 + \beta_2 t\), diferenciar os dados produz estacionariedade, ver Exercício II.6:
\begin{equation}
X_t-X_{t-1} \, = \, (\mu_t+Y_t)-(\mu_{t-1}+Y_{t-1}) \, = \, \beta_2 +Y_t-Y_{t-1}\cdot
\end{equation}
Como a diferenciação desempenha um papel central na análise de séries temporais, ela recebe sua própria
notação. A primeira diferença é denotada como
\begin{equation}
\nabla X_t = X_t-X_{t-1}\cdot
\end{equation}
Como vimos, a primeira diferença elimina uma tendência linear. Uma segunda diferença, isto é, a diferença da primeira
diferença, pode eliminar uma tendência quadrática e assim por diante. Para definir diferenças maiores, precisamos
de uma variação na notação que usaremos com frequência em nossa discussão dos modelos \(ARIMA\) no Capítulo III.
Definição II.4. Operador de retardo.
Definimos o operador de retardo como
\begin{equation}
BX_t=X_{t-1},
\end{equation}
e o estendemos às potência \(B^2 X_t=B(B X_t)=BX_{t-1}=X_{t-2}\), e assim por diante. Então,
\begin{equation}
B^kX_t=X_{t-k}\cdot
\end{equation}
A ideia de um operador inverso também pode ser dada se precisarmos \(B^{-1}B=1\), de maneira que
\begin{equation}
X_t \, = \, B^{-1}B X_t \, = \, B^{-1} X_{t-1}\cdot
\end{equation}
Isto é, \(B^{-1}\) é o operador de deslocamento para a frente.
É claro que podemos então reescrever a operação de diferenciação como
\begin{equation}
\nabla X_t=(1-B)X_t,
\end{equation}
e podemos ampliar a noção ainda mais. Por exemplo, a segunda diferença se torna
\begin{equation}
\begin{array}{rcl}
\nabla^2 X_t & = & (1-B)^2X_t \, = \, (1-2B+B^2)X_t \\
& = & X_t-2X_{t-1}+X_{t-2},
\end{array}
\end{equation}
pela linearidade do operador. Para verificar, basta ter a diferença da primeira diferença
\begin{equation}
\nabla(\nabla X_t)=\nabla(X_t-X_{t-1})=(X_t-X_{t-1})-(X_{t-1}-X_{t-2})\cdot
\end{equation}
Definição II.5. Diferença de ordem \(d\)
Definimos o operador de diferença de ordem \(d\) como
\begin{equation}
\nabla^d X_t=(1-B)^d,
\end{equation}
onde podemos expandir o operador \((1-B)^d\) algebricamente para avaliar valores inteiros mais altos de \(d\).
A primeira diferença é um exemplo de um filtro linear aplicado para eliminar uma tendência. Outros filtros, formados
pela média dos valores próximos de \(X_t\), podem produzir séries ajustadas que eliminam outros tipos de flutuações
indesejadas, como no Capítulo III. A técnica de diferenciação é um componente importante do modelo
\(ARIMA\) de Box e Jenkins (1970) e Box et. al. (1994), a ser discutido no Capítulo III.
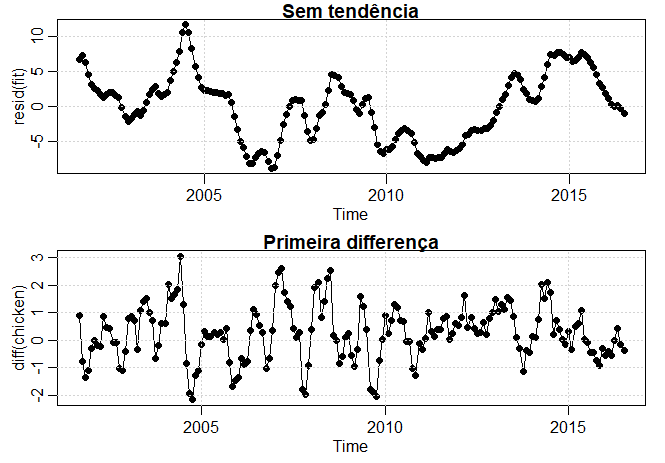
Exemplo II.5. Diferenciando os preços do frango.
A primeira diferença da série dos preços do frango, também mostrada abaixo, produz resultados diferentes do que
remover a tendência, prejudicando a regressão. Por exemplo, as séries diferenciadas não contém o ciclo longo,
de cinco anos, que observamos nas séries selecionadas. O ACF desta série também é mostrado na figura mais embaixo.
Nesse caso, as séries diferenciadas exibem um ciclo anual que foi obscurecido nos dados originais ou desmembrados.
Série dos restos (topo) e diferenciada (inferior) de preços de frango. Os dados originais são mostrados no Exemplo II.1.
O código R para reproduzir a figura o Exemplo II.4 (acima) e a figura abaixo é o seguinte :
> fit = lm(chicken~time(chicken), na.action=NULL) # regressão do preço dos frangos no tempo
> par(mfrow=c(2,1))
> plot(resid(fit), type="o", main="Sem tendência")
> grid()
> plot(diff(chicken), type="o", main="Primeira differença")
> grid()
> par(mfrow=c(3,1), mar=c(4,3,3,1)) # ACFs
> acf(chicken, 48, main="Frangos")
> acf(resid(fit), 48, main="Sem tendência")
> acf(diff(chicken), 48, main="Primeira differença")
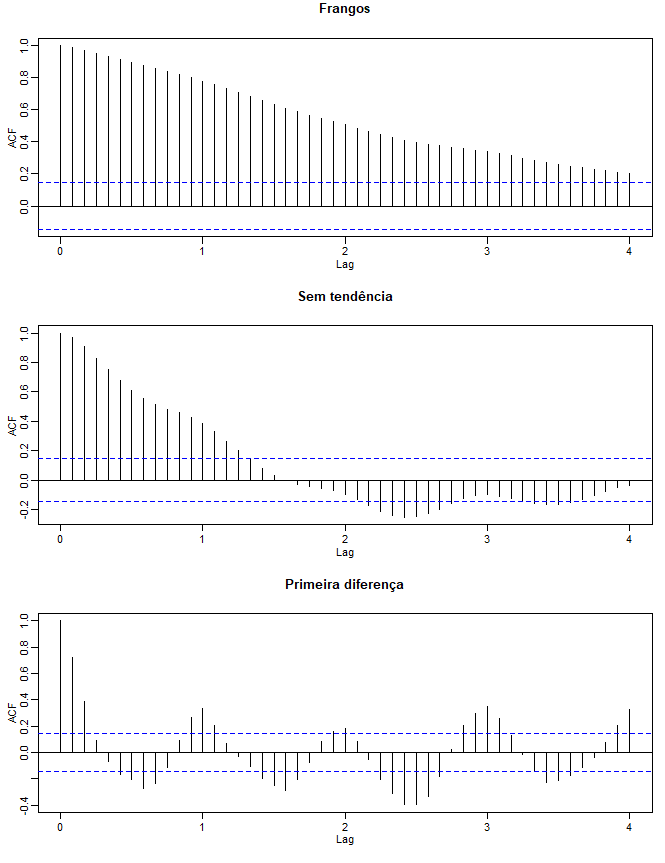
Figura II.5 ACFs amostral dos preços de frango (superior) e das séries retificada (médio) e diferenciada (inferior). Compare o
gráfico superior com a ACF amostral de uma linha reta: > acf(1:100).
Exemplo II.6. Diferenciando a Temperatura Global
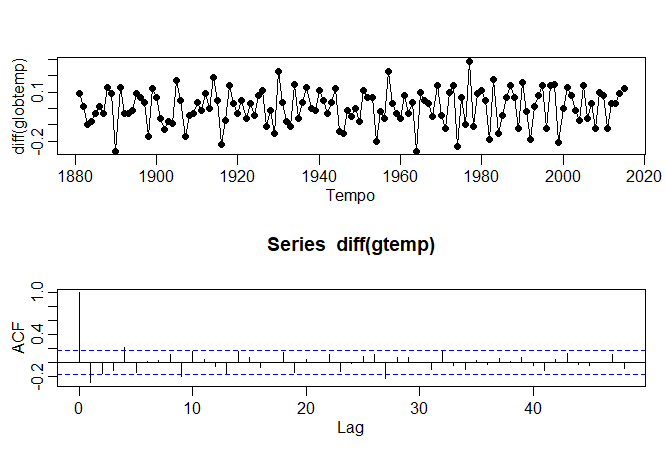
A primeira diferença da série da temperatura global foi mostrada no Exemplo II.4, produz resultados diferentes do que remover a
tendência via a regressão. Por exemplo, as séries diferenciadas não contém o longo ciclo médio
que observamos nas séries com tendência. A função de autocorrelação (ACF) desta série também foi mostrada.
Neste caso, parece que o processo diferenciado mostra autocorrelação mínima, o que pode implicar que a série da temperatura
global é quase uma caminhada aleatória com desvio. É interessante notar que, se a série é uma caminhada aleatória
com desvio, a média da série diferenciada, que é uma estimativa do desvio, é de cerca de 0.008 ou um aumento de
um grau centígrado por 100 anos.
Figura II.6 Série de temperatura global diferenciada e sua ACF amostral.
> par(mfrow=c(2,1), mar=c(4,3,3,1))
> plot(diff(globtemp), xlab="Tempo", type="o", pch=19)
> mean(diff(globtemp)) # média da diferença = .008
> acf(diff(gtemp), 48)
Uma alternativa à diferenciação é uma operação menos grave que ainda assume a estacionariedade da
série temporal subjacente. Essa alternativa, chamada de diferenciação fracionária, estende a noção do
operador de diferença para potências fracionárias \(-0.5 <d < 0.5\), que ainda definem processos estacionários. Granger
e Joyeux (1980) e Hosking (1981) introduziram séries temporais de memória longa, o que corresponde ao caso quando \(0 <d <0.5\).
Este modelo é freqüentemente usado para séries temporais ambientais decorrentes de hidrologia. Discutiremos os processos de
memória longa em mais detalhes na Seção V.1.
Frequentemente, há aberrações óbvias que podem contribuir para o comportamento não-estacionário e não-linear
das séries temporais observadas. Em tais casos, as transformações podem ser úteis para equalizar a variabilidade ao
longo do comprimento de uma única série. Uma transformação particularmente útil é
\begin{equation}
Y_t=\log(X_t),
\end{equation}
que tende a suprimir flutuações maiores que ocorrem em partes da série em que os valores subjacentes são maiores. Outras
possibilidades são as transformações de poder da família Box-Cox, definidas como
\begin{equation}
Y_t \, = \, \displaystyle \left\{ \begin{array}{rcl} \frac{X_t^\lambda -1}{\lambda}, & \mbox{caso} & \lambda\neq 0, \\
\log(X_t), & \mbox{caso} & \lambda = 0 \end{array}\right.\cdot
\end{equation}
Métodos para escolher o poder \(\lambda\) estão disponíveis, ver por exemplo, Johnson e Wichern (1992), §4.7). Frequentemente, as
transformações também são usadas para melhorar a aproximação à normalidade ou para melhorar
a linearidade na previsão do valor de uma série a partir da outra.
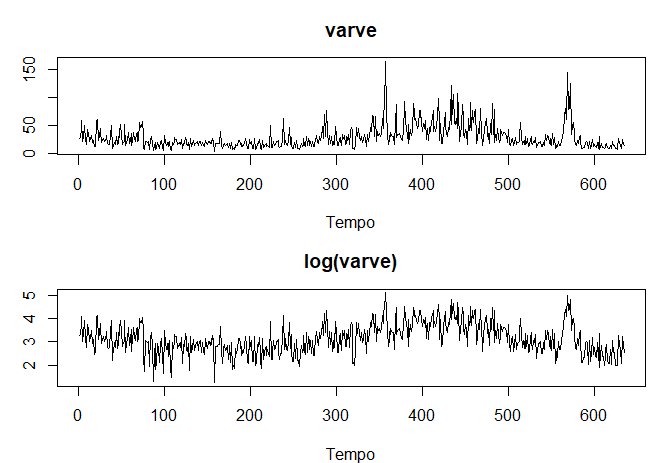
Geleiras derretem e depositam camadas anuais de areia e silte durante as estações de derretimento da primavera, que podem ser
reconstruídas anualmente durante um período que vai desde o início da deglaciação na Nova Inglaterra (cerca de
12.600 anos atrás) até o final (cerca de 6.000 anos atrás). Tais depósitos sedimentares, denominados varves, podem
ser usados como proxies para parâmetros paleoclimáticos, como a temperatura, porque, em um ano quente, mais areia e sedimentos
são depositados na geleira em recuo. A figura abaixo mostra as espessuras das variedades anuais coletadas de um local em Massachusetts
por 634 anos, começando 11.834 anos atrás. Para mais informações, ver Shumway e Verosub (1992). Porque a variação
nas espessuras aumenta em proporção ao quantia depositada, uma transformação logarítmica poderia remover a
não-estacionariedade observável na variância como uma função do tempo. A figura mostra as variáveis
originais e transformadas, e está claro que essa melhoria ocorreu. Também podemos mostra o histograma dos dados originais e
transformados, para argumentar que a aproximação à normalidade é melhorada.
Figura II.7 variedades glaciais (parte superior) de Massachusetts por \(n = 634\) anos em comparação
com variedades transformadas via logaritmo (parte inferior).
As primeiras diferenças ordinárias também são calculadas no Exercício II.8, e notamos que as primeiras
diferenças têm uma correlação negativa significativa no desfasamento \(h = 1\). Posteriormente, no Capítulo V,
mostraremos que talvez a série variante tenha memória longa e proporemos utilizar a diferenciação fracionária.
Mostramos a seguir como realizar a transformação Box-Cox no R
Percebemos que o poder estimado é próximo do zero, ou seja, \(\widehat{\lambda}\approx 0\) e dessa forma justifica-se a transformação
logarítmica dos dados.
Em seguida, consideramos outra técnica preliminar de processamento de dados que é usada com o propósito de visualizar as
relações entre séries em diferentes lags, a saber, matrizes de dispersão. Na definição do ACF, estamos essencialmente
interessados nas relações entre \(X_t\) e \(X_{t-h}\). A função de autocorrelação nos diz se existe
uma relação linear substancial entre a série e seus próprios valores defasados. O ACF dá um perfil da
correlação linear em todos os possíveis atrasos e mostra quais valores de \(h\) levam à melhor previsibilidade.
A restrição dessa idéia à previsibilidade linear, no entanto, pode mascarar uma possível relação não-linear
entre valores atuais, \(X_t\) e valores anteriores, \(X_{t-h}\). Esta ideia estende-se a duas séries onde se pode estar interessado
em examinar gráficos de dispersão de \(Y_t\) versus \(X_{t-h}\).
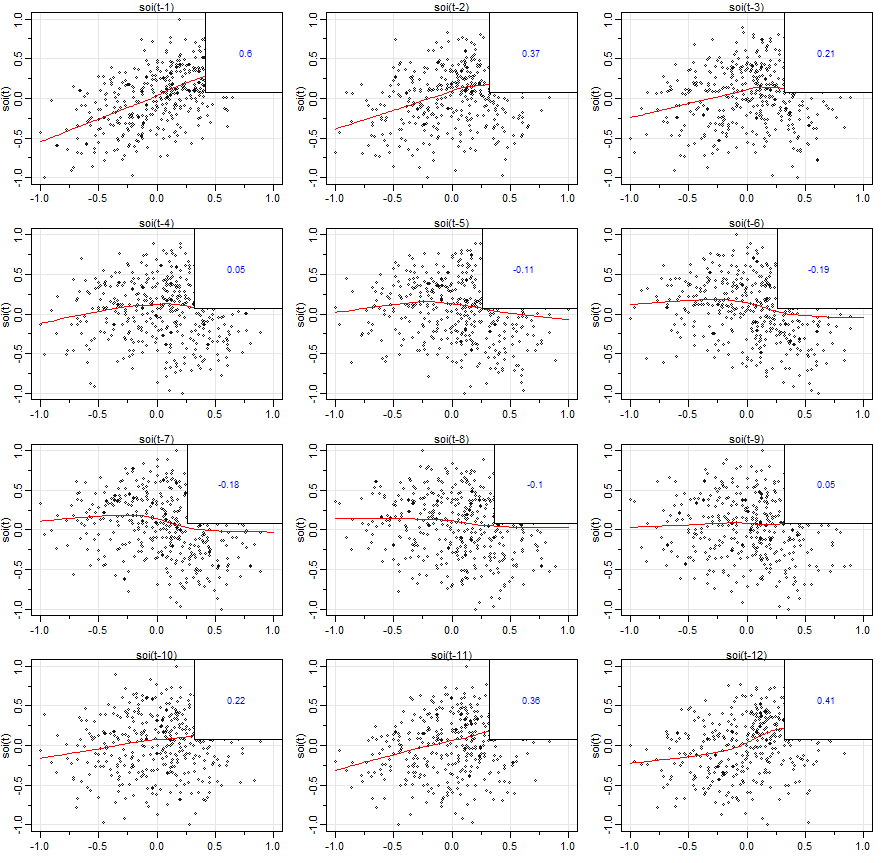
Exemplo II.8. Matrizes de Scatterplot, SOI e Recrutamento.
Para verificar relações não-lineares dessa forma é conveniente exibir uma matriz de dispersão defasada, como
na figura abaixo, que exibe valores de SOI, \(S_t\), no eixo vertical em relação a \(S_{t-h}\) no eixo horizontal. As autocorrelações
amostrais sã exibidas no canto superior direito e sobrepostas nos gráficos de dispersão são linhas de suavização
(lowess) de ponto de dispersão ponderadas localmente que podem ser usadas para ajudar a descobrir quaisquer não-linearidades.
Discutiremos a suavização na próxima seção mas, por enquanto, pensemos no lowess como um método robusto
para ajustar a regressão local.
Figura II.8 Gráfico da matriz de dispersão que relaciona valores atuais de SOI, \(S_t\) a valores de SOI anteriores, \(S_{t-h}\), em lags
\(h = 1,2,\cdots,12\). Os valores no canto superior direito são as autocorrelações amostrais e as linhas são um ajuste simples.
> lag1.plot(soi, 12)
Na figura notamos que os ajustes de baixa intensidade são aproximadamente lineares, de modo que as autocorrelações amostrais
são significativas. Além disso, vemos fortes relações lineares positivas em lags \(h = 1,2,11,12\), isto é, entre
\(S_t\) e \(S_{t-1}\), \(S_{t-2}\), \(S_{t-11}\),\(S_{t-12}\) e uma relação linear negativa em lags \(h = 6,7\). Esses resultados
combinam bem com os picos observados no ACF na figura do Exemplo I.28.
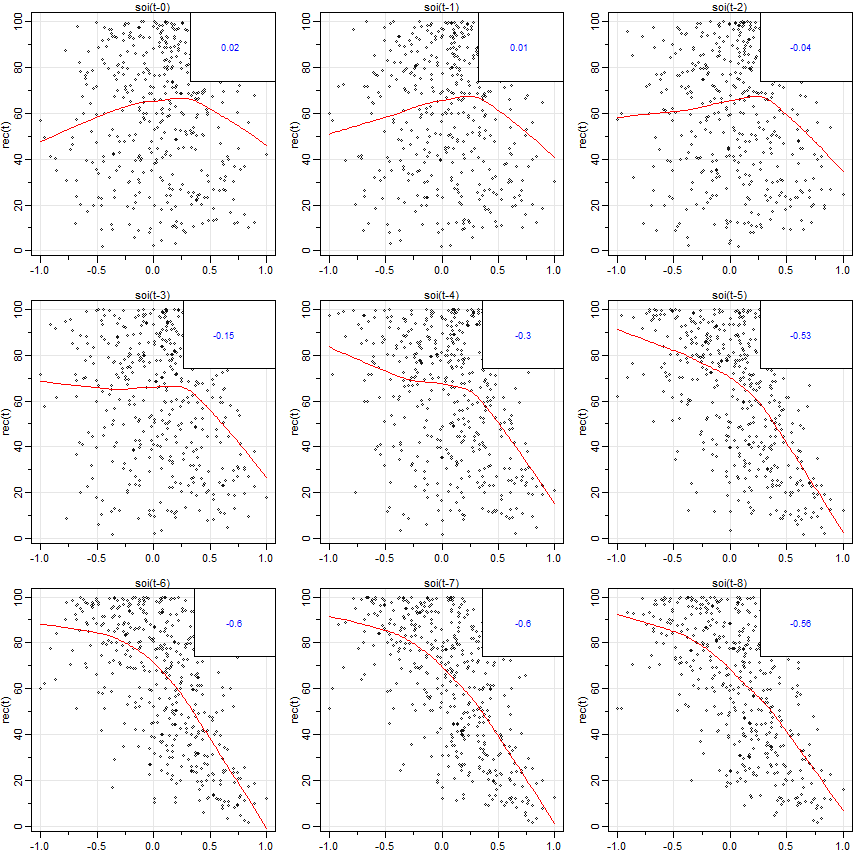
Da mesma forma, poderíamos querer olhar para os valores de uma série, digamos Recrutamento, denotando \(R_t\), contra outra série
em vários lags, diz o SOI, \(S_{t-h}\), para procurar possíveis relações não-lineares entre as duas séries.
Porque, por exemplo, poderíamos querer prever a série de Recrutamento, \(R_t\), a partir de valores atuais ou passados da série SOI,
\(S_{t-h}\), para \(h = 0,1,2,\cdots\) valeria a pena examinar o gráfico da matriz de dispersão. A figura abaixo mostra o gráfico
de dispersão defasado da série de Recrutamento \(R_t\) no eixo vertical em relação ao índice SOI \(S_{t-h}\) no eixo
horizontal. Além disso, a figura exibe as correlações cruzadas da amostra, bem como os ajustes de baixa intensidade.
Figura II.9 Gráfico da matriz de dispersão da série Recrutamento, \(R_t\), no eixo vertical representado graficamente em relação
à série SOI, \(S_{t-h}\), no eixo horizontal em lags \(h = 0,1,\cdots,8\). Os valores no canto superior direito são as correlações
cruzadas amostrais e as linhas são um ajuste simples.
> lag2.plot(soi, rec, 8)
A Figura acima mostra uma relação não-linear bastante forte entre Recrutamento, \(R_t\) e a série SOI em \(S_{t-5}\), \(S_{t-6}\), \(S_{t-7}\) e \(S_{t-8}\),
indicando que a série SOI tende a liderar a série Recrutamento e os coeficientes são negativos, o que implica que os aumentos
no SOI levam a diminuições no Recrutamento. A não-linearidade observada nos gráficos de dispersão, com a ajuda
dos ajustes de baixa sobreposiçã, indica que o comportamento entre Recrutamento e SOI é diferente para valores positivos
de SOI do que para valores negativos de SOI.
Matrizes de dispersão simples para uma série podem ser obtidas em R usando o comando lag.plot.
Exemplo II.9. Regressão com variáveis defasadas.
No Exemplo II.3 fizemos a regressão de variáveis com defasagem do Recrutamento em SOI atrasado
\begin{equation}
R_t \, = \, \beta_0+\beta_1 S_{t-6} + W_t\cdot
\end{equation}
No entanto, no Exemplo II.8, vimos que o relacionamento é não-linear e diferente quando o SOI é positivo ou negativo.
Nesse caso, podemos considerar a adição de uma variável fictícia para considerar essa alteração.
Em particular, ajustamos o modelo
\begin{equation}
R_t \, = \, \left\{ \begin{array}{rcl} \beta_0 +\beta_1 S_{t-6}+W_t, & \mbox{caso} & S_{t-6} < 0 \\
(\beta_0+\beta_2)+(\beta_1+\beta+3)S_{t-6}+W_t, & \mbox{caso} & S_{t-6}\geq 0 \end{array}\right.\cdot
\end{equation}
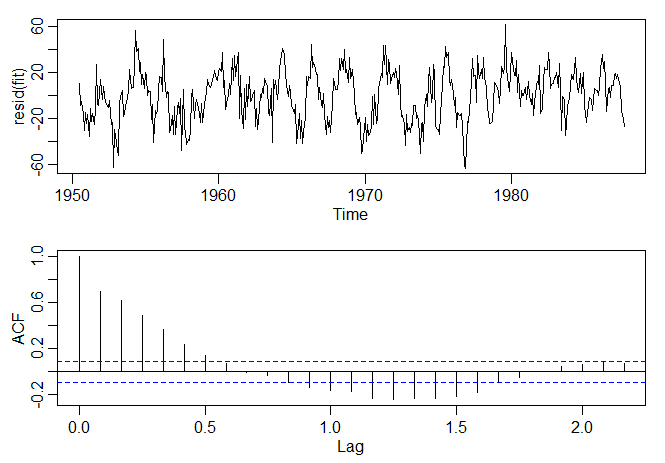
O resultado do ajuste é dado no código R abaixo. A figura mostra \(R_t\) vs \(S_{t-6}\) com os valores ajustados da regressão
e um ajuste de baixa sobreposição. O ajuste de regressão por partes é similar ao ajuste de baixa densidade, mas
notamos que os resíduos não são ruído branco. Isso é seguido no Exemplo III.45.
Figura II.10 Gráfico do Recrutamento (\(R_t\)) vs SOI com defasagem de 6 meses (\(S_{t-6}\)) com os valores ajustados da regressão como
pontos (+) e ajuste de baixa (-).
Gráfico dos resíduos e do ACF dos resíduos do ajuste de Recrutamento \(R_t\) vs SOI com defasagem de 6 meses \(S_{t-6}\).
> par(mfrow=c(2,1), mar=c(3,3,1,1), mgp=c(1.6,.6,0))
> plot(resid(fit))
> acf(resid(fit)) # ... mas obviamente não é ruído
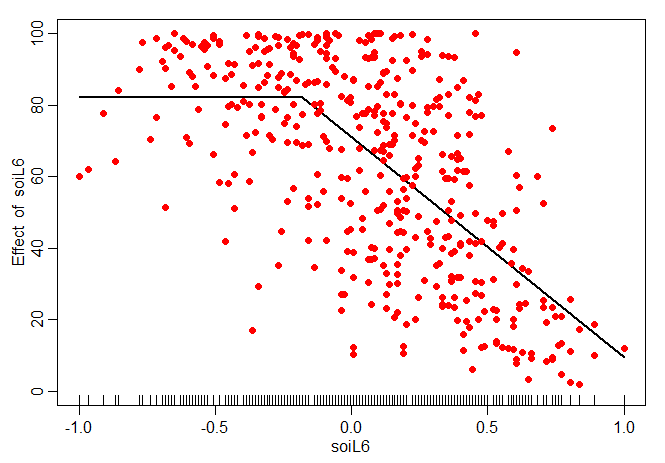
Uma outra forma de fazer este tipo de ajuste com variáveis defasadas utiliza a regressão segmentada da seguinte forma:
> library(segmented)
> ajuste = lm(rec~ soiL6, data=fish, na.action=NULL)
> ajuste1 = segmented(ajuste, seg.Z = ~ soiL6, psi = 0)
> summary(ajuste1)
***Regression Model with Segmented Relationship(s)***
Call:
segmented.lm(obj = ajuste, seg.Z = ~soiL6, psi = 0)
Estimated Break-Point(s):
Est. St.Err
-0.180 0.068
Meaningful coefficients of the linear terms:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 82.2057 5.1737 15.889 <2e-16 ***
soiL6 -0.1364 10.9147 -0.012 0.99
U1.soiL6 -61.6258 11.8543 -5.199 NA
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 21.75 on 443 degrees of freedom
Multiple R-Squared: 0.4072, Adjusted R-squared: 0.4031
Convergence attained in 4 iterations with relative change 0
> slope(ajuste1)
$soiL6
Est. St.Err. t value CI(95%).l CI(95%).u
slope1 -0.13643 10.9150 -0.0125 -21.588 21.315
slope2 -61.76200 4.6253 -13.3530 -70.852 -52.672
> intercept(ajuste1)
$soiL6
Est.
intercept1 82.210
intercept2 71.111
> plot.segmented(ajuste1, ylim=c(0,100), lwd=2)
> points(soiL6,rec, pch=19, col="red")
Resultando a seguinte figura.
Observemos alguns detalhes. Primeiro vemos que o modelo segmentado ajustado acima é diferente daquele proposto, assim estimamos o modelo
\begin{equation}
\widehat{R}_t \, = \, \left\{ \begin{array}{rcl} 82.210 -0.13643 S_{t-6}, & \mbox{caso} & S_{t-6} < -0.180 \\
71.111-61.76200 S_{t-6}, & \mbox{caso} & S_{t-6}\geq -0.180 \end{array}\right.,
\end{equation}
sendo que o coeficiênte -0.13643 não é estatísticamente significativo. Mais ainda, o modelo estimado pela regressão
segmentada não impõe qual será exatamente o ponto de mudança da regressão, somente sugerimos o ponto inicial
da estimação do ponto de corte na opção \(psi=0\).
Como uma ferramenta exploratória final, discutimos a avaliação do comportamento periódico em dados de séries temporais
usando análise de regressão. No Exemplo I.12, discutimos brevemente o problema de identificar sinais cíclicos ou periódicos
em séries temporais. Algumas das séries temporais que vimos até agora exibem comportamento periódico. Por exemplo, os dados
do exemplo do estudo de poluição mostrado na figura do Exemplo II.2 exibem fortes ciclos anuais. Os dados da Johnson & Johnson mostrados
na figura do Exemplo I.1 fazem um ciclo a cada ano (quatro trimestres) em cima de uma tendência crescente e os dados de fala na figura do Exemplo I.3
são altamente repetitivos. As séries mensais de SOI e Recrutamento na figura do Exemplo I.6 mostram fortes ciclos anuais, o que obscurece o
ciclo mais lento do El Niño.
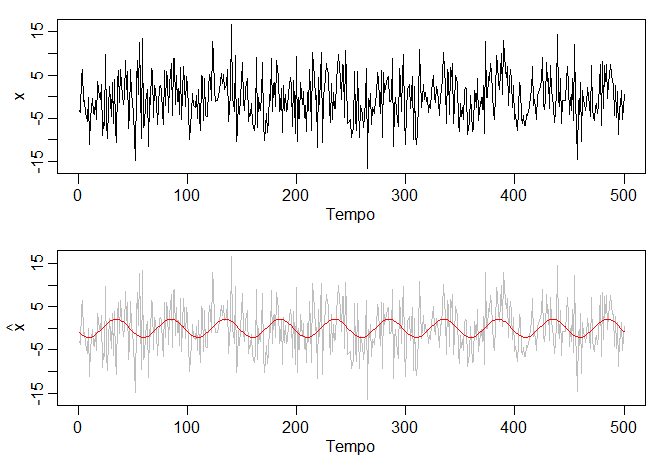
Exemplo II.10. Usando a regressão para descobrir um sinal no ruído.
No Exemple I.12, geramos \(n = 500\) observações do modelo
\begin{equation}
X_t \, = \, A \cos(2\pi \, \omega \, t+\phi)+W_t,
\end{equation}
onde \(\omega=1/50\), \(A=2\), \(\phi=0.6\pi\) e \(\sigma_W=5\). Os dados foram mostrados no painel inferior da figura do Exemplo I.12. Neste ponto,
assumimos a frequência de oscilação \(\omega = 1/50\) é conhecido, mas \(A\) e \(\phi\) são parâmetros
desconhecidos. Neste caso, os parâmetros aparecem na expressão acima de maneira não-linear, então usamos a identidade
trigonométrica \(\cos(\alpha\pm \beta)=\cos(\alpha)\cos(\beta)\mp \sin(\alpha)\sin(\beta)\) e escrevemos
\begin{equation}
A \cos(2\pi \, \omega \, t+\phi) \, = \, \beta_1 \cos(2\pi \, \omega \, t) \, + \, \beta_2\sin(2\pi \, \omega \, t),
\end{equation}
onde \(\beta_1=A\cos(\phi)\) e \(\beta_2=-A\sin(\phi)\). O modelo acima pode ser escrito como um modelo de regressão linear da forma
\begin{equation}
X_t \, = \, \beta_1\cos(2\pi \, t/50) \, + \, \beta_2\sin(2\pi \, t/50) \, + \, W_t,
\end{equation}
sendo que o termo de intercepto não é necessário.
Usando a regressão linear, encontramos \(\widehat{\beta}_1=-0.74_{(0.33)}\), \(\widehat{\beta}_2=-01.99_{(0.33)}\) com \(\widehat{\sigma}_W=5.18\);
os valores entre parênteses são os erros padrão. Notamos que os valores reais dos coeficientes para este exemplo são
\(\beta_1 = 2\cos(0.6\pi)=-0.62\) e \(\beta_2=-2\sin(0.6\pi)=-1.90\). É claro que somos capazes de detectar o sinal no ruído usando
a regressão, mesmo que a relação sinal-ruído seja pequena. A figura abaixo mostra dados gerados segundo o modelo com
a linha ajustada sobreposta.
Figura II.11 Dados gerados segundo o modelo proposto (topo) e a linha ajustada sobreposta aos dados (inferior).
> set.seed(90210) # para reproduzir esses resultados
> x = 2*cos(2*pi*1:500/50 + .6*pi) + rnorm(500,0,5)
> z1 = cos(2*pi*1:500/50)
> z2 = sin(2*pi*1:500/50)
> summary(fit <- lm(x~0+z1+z2)) # zero para excluir a intercepto
Call:
lm(formula = x ~ 0 + z1 + z2)
Residuals:
Min 1Q Median 3Q Max
-14.8584 -3.8525 -0.3186 3.3487 15.5440
Coefficients:
Estimate Std. Error t value Pr(>|t|)
z1 -0.7442 0.3274 -2.273 0.0235 *
z2 -1.9949 0.3274 -6.093 2.23e-09 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 5.177 on 498 degrees of freedom
Multiple R-squared: 0.07827, Adjusted R-squared: 0.07456
F-statistic: 21.14 on 2 and 498 DF, p-value: 1.538e-09
> par(mfrow=c(2,1), mar=c(3,3,1,1), mgp=c(1.6,.6,0))
> plot.ts(x, xlab="Tempo")
> plot.ts(x, col=8, ylab=expression(hat(x)), xlab="Tempo")
> lines(fitted(fit), col=2)
II.3 Suavização de Séries Temporais
Na Seção I.2, introduzimos o conceito de filtragem ou suavização de uma série temporal e, no Exemplo I.9, discutimos
o uso de uma média móvel para suavizar o ruído branco. Esse método é útil para descobrir certas
características em uma série temporal, como componentes sazonais e tendências de longo prazo. Em particular, se \(X_t\) representa
as observações, então
\begin{equation}
m_t=\sum_{j=-k}^k a_j X_{t-j},
\end{equation}
onde \(a_j=a_{-j}\geq 0\) e \(\sum_{j=-k}^k a_j=1\) é uma média móvel simétrica dos dados.
Exemplo II.11. Suavizamento por Médias Móveis.
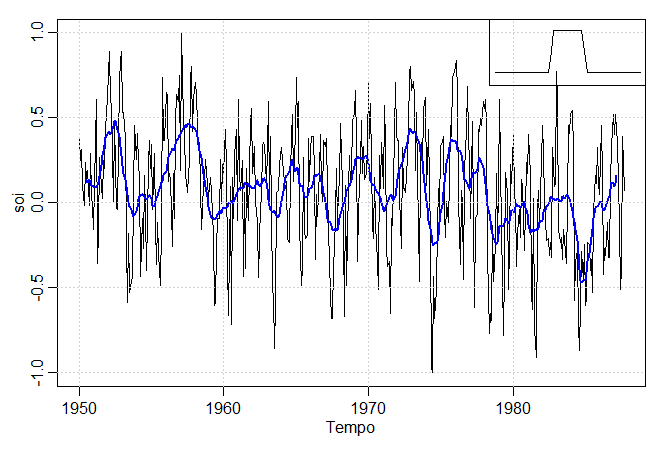
Mostramos na figura abaixo a série mensal de SOI discutida no Exemplo I.5 suavizada utilizando a função \(m_t\) com pesos
\(a_0 = a_{\pm 1} = \cdots = a_{\pm 5} = 1/12\) e \(a_{\pm 6} = 1/24\); \(k = 6\). Esse método específico remove (filtra) o ciclo
de temperatura anual óbvio e ajuda a enfatizar o ciclo El Niño.
Para restaurar as configurações gráficas padrão utilize o código a seguir no console:
> dev.off()
Embora a média móvel mais suave faça um bom trabalho ao destacar o efeito El Niño, pode ser considerado muito
instável. Podemos obter um ajuste mais suave usando a distribuição normal para os pesos, em vez de pesos do tipo
vagão boxcar de \(m_t\).
Exemplo II.12. Suavizamento por Kernel.
A suavização kernel é um suavizador de média móvel que usa uma função de peso ou kernel, para
calcular a média das observações. A figura mostra a suavização kernel da série SOI, onde \(m_t\) é agora
\begin{equation}
m_t=\sum_{i=1}^n w_i(t) x_i,
\end{equation}
onde
\begin{equation}
w_i(t)=K\Big(\frac{t-i}{b}\Big)\Big/ \sum_{j=1}^n K\Big(\frac{t-j}{b}\Big),
\end{equation}
são os pesos e \(K(\cdot)\) é uma função kernel. Este estimador, que foi originalmente explorado por Parzen (1962)
e Rosenblatt (1956b), é frequentemente chamado de estimador Nadaraya-Watson (Watson, 1966). Neste exemplo, e normalmente, o kernel normal,
\(K(z)=\frac{1}{\sqrt{2\pi}}\exp\big( -z^2/2\big)\), é utilizado.
> par(mar=c(4,3,1,1),mgp=c(1.6,.6,0))
> plot(soi, xlab = "Tempo")
> lines(ksmooth(time(soi), soi, "normal", bandwidth=1), lwd=2, col=4)
> grid()
> par(fig = c(.65, 1, .65, 1), new = TRUE) # the insert
> gauss = function(x) { 1/sqrt(2*pi) * exp(-(x^2)/2) }
> x = seq(from = -3, to = 3, by = 0.001)
> plot(x, gauss(x), type ="l", ylim=c(-.02,.45), xaxt='n', yaxt='n', ann=FALSE)
Para implementar a suavização kernel em R, use a função ksmooth onde uma largura de banda bandwidth ou
b pode ser escolhida. Quanto maior a largura de banda \(b\), mais suave será o resultado. A partir do arquivo de ajuda R do ksmooth
sabemos que os kernels são escalonados de forma que seus quartis, vistos como densidades de probabilidade, estejam na largura de banda de \(\pm 0.25*\mbox{bandwidth}\). Para a
distribuição normal padrão, os quartis são \(\pm 0.674\). No nosso caso, estamos suavizando com o tempo, que é da forma \(t/12\)
para a série temporal do SOI. Na figura do Exemplo II.12, usamos o valor de \(b = 1\) para corresponder aproximadamente a suavizar um pouco
mais de um ano. Maiores informações acerca da estimação kernel podem ser encontradas aqui.
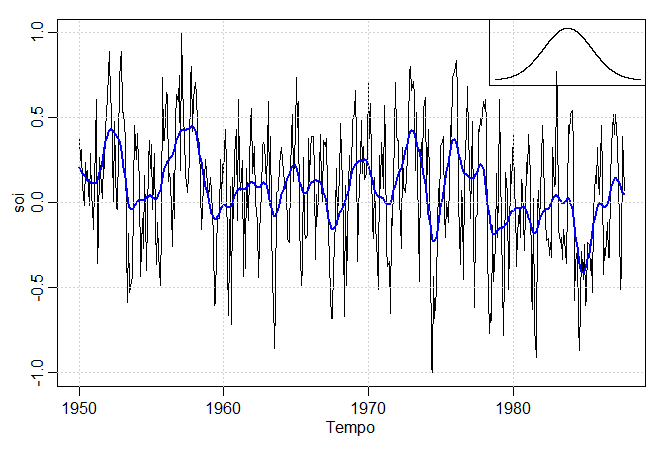
Exemplo II.13. Lowess.
Outra abordagem para suavizar um gráfico de tempo é a regressão do vizinho mais próximo ou lowess. A técnica é baseada
na regressão de \(k\)-vizinhos mais próximos, em que se utilizam apenas os dados \(\{X_{t-k/2},\cdots,X_t,\cdots,X_{t+k/2}\}\) para prever
\(X_t\) via regressão e, em seguida, definir \(m_t =\widehat{X}_t\).
O Lowess é um método de suavização bastante complexo, mas a ideia básica é próxima à regressão
do vizinho mais próximo. A figura abaixo mostra o alisamento do SOI usando a função R lowess, veja Cleveland (1979). Primeiro,
uma certa proporção dos vizinhos mais próximos de \(X_t\) está incluída em um esquema de ponderação; valores
próximos de \(X_t\) no tempo ganham mais peso. Em seguida, uma regressão ponderada robusta é usada para prever \(X_t\) e obter os
valores suavizados \(m_t\). Quanto maior a fração de vizinhos mais próximos incluídos, mais suave será o alisamento.
Na figura abaixo, o alisamento mais suave usa 5% dos dados para obter uma estimativa do ciclo El Niño dos dados.
Além disso, uma tendência negativa no SOI indicaria o aquecimento de longo prazo do Oceano Pacífico. Para investigar isso, usamos o
método lowess com o intervalo padrão mais suave de \(f = 2/3\) dos dados.
A figura acima pode ser reproduzida em R como segue:
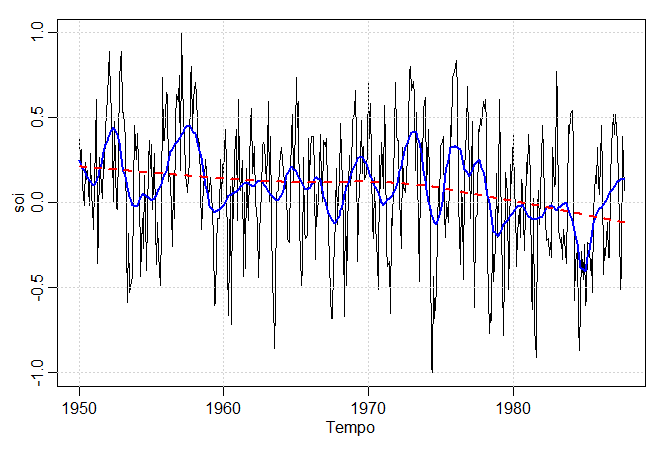
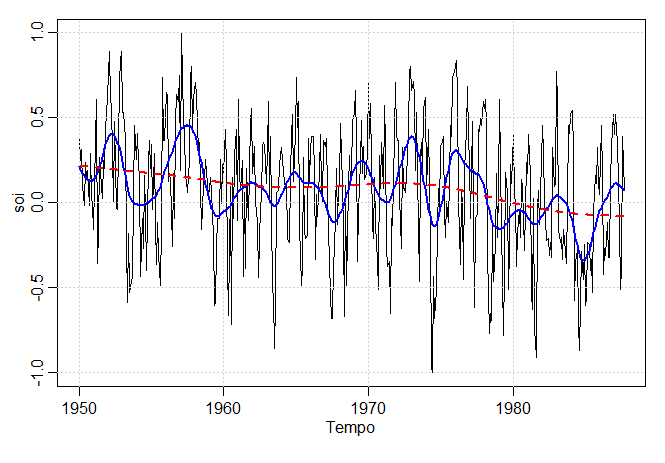
Uma maneira óbvia de suavizar dados seria ajustar uma regressão polinomial em termos de tempo. Por exemplo, um polinômio cúbico
teria \(X_t = m_t + W_t\) onde
\begin{equation}
m_t=\beta_0+\beta_1 t+\beta_2 t^2+\beta_3 t^3\cdot
\end{equation}
Poderíamos então estimar \(m_t\) através de mínimos quadrados ordinários.
Uma extensão da regressão polinomial é dividir primeiro o tempo \(t = 1,\cdots,n\), em \(k\) intervalos \([t_0 = 1, t_1]\),
\([t_1 + 1, t_2]\),\(\cdots\),\([t_{k-1} + 1, t_k = n]\); os valores \(t_0, t_1,\cdots,t_k\) são chamados de nós. Então, em cada
intervalo, ajusta-se uma regressão polinomial, tipicamente a ordem é \(3\) e isso é chamado de splines cúbicos.
O método relatado é chamado de suavização por splines, o que minimiza um compromisso entre o ajuste e o grau
de suavidade dado por
\begin{equation}
\sum_{t=1}~n \big( x_t-m_t\big)^2+\lambda \int (m_t'')^2 \mbox{d}t
\end{equation}
onde \(m_t\) é uma spline cúbica com um nó em cada \(t\). O grau de suavidade é controlado por \(\lambda > 0\).
Pense em tomar uma longa viagem onde \(m_t\) é a posição do seu carro no tempo \(t\). Neste caso, \(m_t''\) é a
aceleração/desaceleração instantânea e \(\int (m_t'')^2 \mbox{d}t\) é uma medida da quantidade total
de aceleração e desaceleração em sua viagem. Um acionamento suave seria aquele em que uma velocidade constante
fosse mantida, ou seja, \(m_t'' = 0\). Um passeio agitado seria quando o motorista está constantemente acelerando e desacelerando, como
os motoristas iniciantes tendem a fazer.
Se \(\lambda= 0\), não nos importamos com o quão agitado é o passeio e isso leva a \(m_t = X_t\), os dados, que não
são suaves. Se \(\lambda=\infty \), insistimos em nenhuma aceleração ou desaceleração \(m_t'' = 0\); neste
caso, nosso motorista deve estar em velocidade constante \(m_t = c + vt\) e, consequentemente, muito suave. Assim, é visto como um
trade-off entre a regressão linear, um modelo completamente suave, e os dados em si, sem suavidade. Quanto maior o valor de \(\lambda\),
mais suave é o ajuste.
Em R, o parâmetro de suavização é chamado spar e está monotonicamente relacionado a \(\lambda\);
digite
> ?smooth.spline
para visualizar o arquivo de ajuda e obter detalhes. A figura acima mostra os ajustes spline de
suavização na série SOI usando spar = .5 para enfatizar o ciclo El Niño e spar = 1 para
enfatizar a tendência. A figura pode ser reproduzida em R como segue:
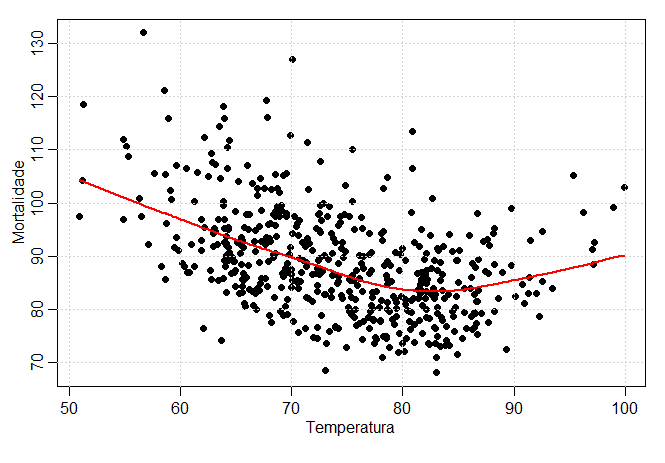
Exemplo II.15. Suavização de uma série como função de outra.
Além de suavizar os gráficos de tempo, as técnicas de suavização podem ser aplicadas para suavizar uma
série temporal como uma função de outra série temporal. Vimos essa idéia usada no Exemplo II.8 quando
usamos o lowess para visualizar a relação não linear entre Recrutamento e SOI em vários defasagens. Neste exemplo,
suavizamos o gráfico de dispersão de duas séries temporais medidas contemporaneamente, a mortalidade em função
da temperatura. No Exemplo II.2, descobrimos uma relação não linear entre mortalidade e temperatura.
A figura abaixo mostra um gráfico de dispersão de mortalidade \(M_t\) e temperatura \(T_t\), juntamente com \(M_t\) suavizado
como uma função de \(T_t\) usando lowess. Note que a mortalidade aumenta a temperaturas extremas, mas de maneira assimétrica; a mortalidade
é maior em temperaturas mais frias do que em temperaturas mais quentes. A taxa de mortalidade mínima parece ocorrer em aproximadamente
83°F ou 26.6667°C.
A figura acima pode ser reproduzida em R, da seguinte maneira, usando os padrões.
Um Modelo Estrutural Para os dados da Johnson & Johnson \(y_t\), mostrados na figura do Exemplo I.1, considere \(x_t = \log(y_t)\). Neste problema,
vamos ajustar um tipo especial de modelo estrutural, \(X_t = T_t + S_t + N_t\), em que \(T_t\) é um componente de tendência, \(S_t\)
é um componente sazonal e \(N_t\) é ruído. No nosso caso, o tempo \(t\) está nos trimestres \(1960.00, 1960.25,\cdots\)
então uma unidade de tempo é um ano.
(a) Ajuste o modelo de regressão
\begin{equation}
x_t=\underbrace{\beta t}_{\text{tendência}}+\underbrace{\alpha_1 Q_1(t)+\alpha_2 Q_2(t)+\alpha_3 Q_3(t)+\alpha_4 Q_4(t)}_{sazonalidade}+\underbrace{W_t}_{ruído},
\end{equation}
onde \(Q_i(t)=1\) se o tempo \(t\) corresponde ao trimestre \(i=1,2,3,4\) e zero caso contrário. Os \(Q_i(t)\)s são chamados de variáveis indicadoras. Vamos
assumir por enquanto que \(W_t\) é uma sequência de ruído branco gaussiano.
(b) Se o modelo estiver correto, qual é o aumento médio anual estimado do lucro por ação registrado?
(c) Se o modelo estiver correto, a taxa de lucro média registrada aumenta ou diminui do terceiro para o quarto trimestre? E,
por qual porcentagem aumenta ou diminui?
(d) O que acontece se você incluir um termo de intercepto no modelo em (a)? Explique por que houve um problema.
(e) Represente graficamente os dados \(X_t\), e sobreponha os valores ajustados, digamos \(\widehat{X}_t\), no gráfico.
Examine os resíduos \(X_t - \widehat{X}_t\), e exponha suas conclusões. Parece que o modelo se ajusta bem aos dados, ou seja,
os resíduos parecem um ruído branco?
Para os dados de mortalidade examinados no Exemplo II.2:
(a) Adicionar outro componente à regressão em (D) que contabiliza a contagem de partículas quatro semanas antes;
isto é, adicione \(P_{t-4}\) à regressão em (D). Diga sua conclusão.
(b) Mostre a matriz de dispersão do \(M_t\), \(T_t\), \(P_t\) e \(P_{t-4}\) e, em seguida, calcule as correlações
pareadas entre as séries. Compare a relação entre \(M_t\) e \(P_t\) versus \(M_t\) e \(P_{t-4}\).
Neste problema, exploramos a diferença entre um passeio aleatório e um processo estacionário de tendência.
(a) Gere quatro séries que sejam passeio aleatório com tendência como no Exemplo I.11, ou seja, da forma \(X_t=\delta t+\sum_{j=1}^t W_j\),
de comprimento \(n = 100\) com \(\delta=0.01\) e \(\sigma^2_{_W} = 1\). Chame os dados \(X_t\) para \(t = 1,2,\cdots,100\). Ajuste a regressão
\(X_t = \beta t + W_t\) usando mínimos quadrados. Mostre gráficamente os dados, a função de média real, isto é,
\(\mu_t =0.01 t\) e a linha ajustada, \(\widehat{x}_t = \widehat{\beta} t\), no mesmo gráfico.
Dica: O seguinte código R pode ser útil.
> par(mfrow=c(2,2), mar=c(2.5,2.5,0,0)+.5, mgp=c(1.6,.6,0)) # configurando a janela gráfica
> for (i in 1:4){
x = ts(cumsum(rnorm(100,.01,1))) # gerando os dados
regx = lm(x~0+time(x), na.action=NULL) # regressões
plot(x, ylab='Passeio aleatória com tendência') # gráficos
abline(a=0, b=.01, col=2, lty=2) # média teórica (em vermelho - linhas tracejadas)
abline(regx, col=4) # reta ajustada (azul - linha sólida)
}
(b) Gere quatro séries de comprimento \(n = 100\) que tenham tendência linear mais ruído, digamos \(Y_t = 0.01 t + W_t\),
onde \(t\) e \(W_t\) sejam como na parte (a). Ajuste a regressão \(Y_t = \beta t + W_t\) usando mínimos quadrados. Mostre os dados,
a função de média real, isto é, \(\mu_t =0.01 t\) e a linha ajustada, \(\widehat{Y}_t = \widehat{\beta} t\), no
mesmo gráfico.
(c) Comente o que você aprendeu com essa tarefa.
Informação de Kullback-Leibler Dado o vetor aleatório \(Y\) de dimensão \(n\times 1\), definimos a
informação para discriminar entre duas densidades \(f(y;\theta_1)\) e \(f(y;\theta_2)\) na mesma família, indexadas pelo
parâmetro \(\theta\), como
\begin{equation}
KL(\theta_1;\theta_2) \, = \, \displaystyle \dfrac{1}{n}\mbox{E}_1 \left( \log\Big( \frac{f(y;\theta_1)}{f(y;\theta_2)}\Big)\right),
\end{equation}
onde \(\mbox{E}_1\) denota a esperança em relação à densidade determinada por \(\theta_1\). Para o modelo de regressão
gaussiano, os parâmetros são \(\theta=(\beta^\top,\sigma^2)^\top\). Mostre que
\begin{equation}
KL(\theta_1;\theta_2) \, = \, \displaystyle \frac{1}{2}\left(\dfrac{\sigma^2_1}{\sigma^2_2}-\log\Big(\dfrac{\sigma^2_1}{\sigma^2_2}\Big)-1\right) \, + \,
\frac{1}{2}\dfrac{(\beta_1-\beta_2)^\top Z^\top Z (\beta_1-\beta_2)}{n\sigma^2_2}\cdot
\end{equation}
Seleção de Modelos Ambos os critérios de seleção AIC e AICc são derivados de
argumentos teóricos da informação, baseados no critério de informação de Kullback-Leibler (ver Kullback e
Leibler, 1951; Kullback, 1958) e também devido a Hurvich e Tsai (1989). Pensamos na medida obtida no Exercício 4 como a medida da
discrepância entre as duas densidades, caracterizada pelos valores dos parâmetros \(\theta_1^\top=(\beta_1^\top,\sigma^2_1)^\top\) e
\(\theta_2^\top=(\beta_2^\top,\sigma^2_2)^\top\). Agora, se o valor verdadeiro do vetor de parâmetros for \(\theta_1\), argumentamos que
o melhor modelo seria aquele que minimiza a discrepância entre o valor teórico e a amostra, digamos \(KL(\theta_1;\widehat{\theta}_1)\).
Como \(\theta_1\) não é conhecido, Hurvich e Tsai (1989) consideraram encontrar um estimador não-viesado para
\(\mbox{E}_1\Big( KL\big(\beta_1,\sigma^2_1;\widehat{\beta},\widehat{\sigma}^2\big)\Big)\), onde
\begin{equation}
KL\big(\beta_1,\sigma^2_1;\widehat{\beta},\widehat{\sigma}^2\big) \, = \, \displaystyle \frac{1}{2}\left(\dfrac{\sigma^2_1}{\sigma^2_2}-\log\Big(\dfrac{\sigma^2_1}{\sigma^2_2}\Big)-1\right) \, + \,
\frac{1}{2}\dfrac{(\beta_1-\beta_2)^\top Z^\top Z (\beta_1-\beta_2)}{n\sigma^2_2},
\end{equation}
e \(\beta\) é o vetor \(k\times 1\) de parâmetros da regressão. Mostre que
\begin{equation}
\mbox{E}_1\Big( KL\big(\beta_1,\sigma^2_1;\widehat{\beta},\widehat{\sigma}^2\big)\Big) \, = \, \displaystyle
\dfrac{1}{2}\left(-\log(\sigma_1^2)+\mbox{E}_1\big(\log(\widehat{\sigma}^2) \big)+\dfrac{n+k}{n-k-2}-1 \right),
\end{equation}
usando as propriedades distribuicionais dos estimadores dos coeficientes de regressão e da variância do erro. Um estimador não-viesado
para \(\mbox{E}_1\big(\log(\widehat{\sigma}^2)\big)\) é \(\log(\widehat{\sigma}^2)\). Portanto, mostramos que a esperança da informação
de discriminação acima é como reivindicada. Como modelos com \(k\) dimensões diferentes são considerados, apenas o
segundo e terceiro termos da esperança acima irão variar e só precisamos de estimadores não-viesados para esses dois termos.
Isto dá a forma do AICc citado na Definição II.2. Serão necessários os dois resultados a seguir
\begin{equation}
\dfrac{n\widehat{\sigma}^2}{\sigma_1^2}\sim \chi^2_{n-k} \qquad \mbox{e} \qquad \displaystyle
\dfrac{(\widehat{\beta}-\beta_1)^\top Z^\top Z (\widehat{\beta}-\beta_1)}{\sigma^2_1}\sim \chi^2_k,
\end{equation}
As duas quantidades são independentes com distribuições qui-quadrado com os graus de liberdade indicados. Se \(X\sim \chi^2_n\),
então \(\mbox{E}(1/X)=1/(n-2)\).
Considere um processo que consiste em uma tendência linear com um termo de ruído aditivo que consiste em variáveis
aleatórias independentes \(W_t\) com médias zero e variâncias \(\sigma^2_{_W}\), ou seja,
\begin{equation}
X_t=\beta_0+\beta_1 t +W_t,
\end{equation}
onde \(\beta_0\) e \(\beta_1\) são constantes.
(a) Prove que \(X_t\) é não-estacionário.
(b) Prove que a série da primeira diferença \(\nabla X_t = X_t - X_{t-1}\) é estacionária, encontrando sua
função de média e de autocovariância.
(c) Repita a parte (b) se \(W_t\) for substituído por um processo estacionário geral, digamos \(Y_t\), com função de
média \(\mu_{_Y}\) e função de autocovariância \(\gamma_{_Y}(h)\).
O registro das variedades glacias mostrado na figura do Exemplo II.7 exibe alguma não-estacionariedade que pode ser melhorada
pela transformação em logaritmos e alguma não-estacionariedade adicional que pode ser corrigida pela diferenciação
dos logaritmos.
(a) Argumente que a série de variedades glacial \(X_t\), exibe heterocedasticidade calculando a variância amostral
na primeira metade e na segunda metade dos dados. Argumente que a transformação \(Y_t = \log(X_t)\) estabiliza a variância
sobre a série. Mostre os histogramas de \(X_t\) e \(Y_t\) para ver se a aproximação à normalidade é
melhorada pela transformação dos dados.
(b) Mostre o gráfico da série \(Y_t\). Existe algum intervalo de tempo, da ordem de 100 anos, em que se pode observar um comportamento
comparável ao observado nos registros de temperatura global da figura do Exemplo I.2?
(c) Examine o ACF amostral de \(Y_t\) e comente.
(d) Calcule a diferença \(U_t = Y_t - Y_{t-1}\), examine seu gráfico e o ACF amostral e argumente que diferenciar
os dados defasados registrados produz uma série razoavelmente estacionária. Você consegue pensar em uma interpretação
prática para \(U_t\)?
(e) Com base no ACF amostral da série transformada diferenciada computada em (c), argumenta-se que uma generalização do modelo
dado pelo Exemplo I.26 pode ser razoável. Assumindo que
\begin{equation}
U_t \, = \, \mu+W_t+\theta W_{t-1},
\end{equation}
seja estacionária quando as entradas são assumidas independentes com média \(0\) e variância \(\sigma^2_{_W}\). Mostre que
\begin{equation}
\gamma_{_U}(h) \, = \, \left\{ \begin{array}{ccl} \sigma^2_{_W} (1+\theta^2), & \mbox{se} & h=0 \\
\theta\sigma^2_{_W}, & \mbox{se} & h=\pm 1\\ 0, & \mbox{se} & |h|>1 \end{array}\right.
\end{equation}
(f) Com base na parte (e), utilize \(\widehat{\rho}_{_U}(1)\) e a estimativa da variância de \(U_t\), \(\widehat{\gamma}_{_U}(0)\), para
obter estimativas de \(\theta\) e \(\sigma^2_{_W}\). Trata-se de uma aplicação do m&eacutodo clássico de estimação
dos momentos, onde estimadores dos parâmetros são derivados através da comparação entre momentos amostrais e
momentos teóricos.
Neste problema, vamos explorar a natureza periódica de \(S_t\), a série SOI exibida na figura do Exemplo I.5.
(a) Elimine a tendência da série ajustando uma regressão de \(S_t\) no tempo \(t\). Existe uma tendência significativa
na temperatura da superfície do mar? Comente.
(b) Calcule o periodograma para a série retificada obtida na parte (a). Identifique as frequências dos dois picos principais, com um
óbvio na frequência de um ciclo a cada 12 meses. Qual é o provável ciclo El Niño indicado pelo pico menor?
Considere as duas séries temporais de petróleo oil e gás gas. A série de petróleo
é em dólares por barril, enquanto a série de gás é em centavos por galão.
(a) Mostre os dados no mesmo gráfico. Quais das séries simuladas exibidas na Seção I.2 essas séries mais se parecem?
Você acredita que as séries são estacionárias, explique sua resposta?
(b) Em economia, muitas vezes é a variação percentual no preço, denominada taxa de crescimento ou retorno,
em vez da mudança absoluta de preço, que é importante. Argumente que uma transformação da forma \(Y_t = \nabla \log(X_t)\)
pode ser aplicada aos dados, onde \(X_t\) é a série de preços do petróleo ou gás.
(c) Transforme os dados conforme descrito na parte (b), mostre os dados no mesmo gráfico, observe os exemplos de ACFs dos dados transformados e comente.
(d) Grafique o CCF dos dados transformados e comente. Os valores pequenos, mas significativos, quando o gás conduz o petróleo podem ser
considerados como explicativos.
(e) Exiba gráficos de dispersão da série de taxas de crescimento de petróleo e gás por até três semanas
do prazo de entrega dos preços do petróleo; inclua um suavizador não paramétrico em cada gráfico e comente os resultados,
por exemplo, existem outliers? As relações são lineares?
(f) Tem havido uma série de estudos questionando se os preços da gasolina respondem mais rapidamente quando os preços do petróleo
estão subindo do que quando os preços do petróleo estão caindo, chamamos esse efeito de assimetria dor preços. Vamos tentar
explorar essa questão aqui com regressão retardada simples. Ignorando alguns problemas óbvios, como outliers e erros autocorrelacionados,
por isso não será uma análise definitiva. Considre \(G_t\) e \(O_t\) denotar as taxas de crescimento de gás e petróleo.
(i) Ajuste o seguinte modelo de regressão e comente os resultados:
\begin{equation}
G_t \, = \, \alpha_1+\alpha_2 I_t + \beta_1 O_t+\beta_2 O_{t-1}+W_t,
\end{equation}
onde \(I_t=1\) se \(O_t\geq 0\) e 0 (zero) caso contrário, ou seja, \(I_t\) é o indicador de ausência de crescimento ou crescimento
positivo no preço do petróleo.
Dica: O seguinte código R pode ser útil.
(ii) Qual é o modelo ajustado quando há um crescimento negativo no preço do petróleo no tempo t? Qual é o modelo ajustado quando não há crescimento positivo do preço do petróleo? Esses resultados suportam a hipótese de assimetria?
(iii) Analise os resíduos do ajuste e comente.
Use duas técnicas diferentes de suavização descritas na Seção II.3 para estimar a tendência na
série de temperatura global globtemp. Comente.