- Modelos autorregressivos de médias móveis
- Equações em diferenças
- Autocorrelação e autocorrelação parcial
- Previsão
- Estimação
- Modelos integrados para dados não estacionários
- Diagnóstico de resíduos para modelos ARIMA
- Regressão com erros autocorrelacionados
- Modelos ARIMA sazonais multiplicativos
- Exercícios
III.1 Modelos autorregressivos de médias móveis
O modelo de regressão clássico no Capítulo II foi desenvolvido para o caso estático, ou seja, apenas permitimos que a variável dependente seja influenciada pelos valores atuais das variáveis independentes. No caso de séries temporais, é desejável permitir que a variável dependente seja influenciada pelos valores passados das variáveis independentes e, possivelmente, pelos seus próprios valores passados. Se o presente puder ser modelado de maneira plausível em termos apenas dos valores passados dos insumos independentes, teremos a perspectiva sedutora de que a previsão será possível.
Introdução aos modelos autoregressivos
Os modelos autorregressivos baseiam-se na ideia de que o valor atual da série \(X_t\), pode ser explicado como uma função de \(p\) valores passados, \(X_{t-1},X_{t-2},\cdots,X_{t-p}\), onde \(p\) determina o número de etapas no passado necessárias para prever o valor atual. Como um caso típico, lembremos do Exemplo I.10, no qual os dados foram gerados usando o modelo \begin{equation} X_t=X_{t-1}-0.90 X_{t-2}+W_t, \end{equation} onde \(W_t\) é um ruído branco gaussiano com \(\sigma_{_W}^2=1\).
Agora assumimos que o valor atual é uma função linear particular de valores passados. A regularidade que persiste na figura do Exemplo I.9 dá uma indicação de que a previsão para tal modelo pode ser uma possibilidade distinta, digamos, através de alguma versão como \begin{equation} \widehat{X}_{n+1}^n = X_n - 0.90 X_{n-1}, \end{equation} onde a quantidade no lado esquerdo indica a previsão no próximo período \(n + 1\) com base nos dados observados, \(X_1,X_2,\cdots,X_n\). Vamos tornar essa noção mais precisa em nossa discussão sobre previsão.
A medida em que pode ser possível prever uma série de dados reais a partir de seus próprios valores passados pode ser avaliada examinando-se a função de autocorrelação e as matrizes do gráfico de dispersão discutidas na Parte II. Por exemplo, a matriz de dispersão defasada do Índice de Oscilação Meridional (SOI), mostrado na Figura II.8, fornece uma indicação distinta de que as defasagens 1 e 2, por exemplo, estão linearmente associadas ao valor atual. O ACF mostrado na Figura II.16 mostra valores positivos relativamente grandes nas defasagens 1, 2, 12, 24 e 36 e grandes valores negativos em 18, 30 e 42. Notamos também a possível relaç&ailde;o entre as séries de SOI e Recrutamento indicadas na matriz de dispersão mostrada na Figura II.9. Vamos indicar em seções posteriores sobre a função de transferência e modelagem do vetor AR como lidar com a dependência de valores obtidos por outras séries.
A discussão anterior motiva a seguinte definição.
Dizemos que \(\{X_t\}\) satisfaz um modelo autorregressivo de ordem \(p\) ou simplesmente \(AR(p)\) se \begin{equation} X_t=\phi_1 X_{t-1}+\phi_2 X_{t-2}+\cdots+\phi_p X_{t-p}+W_t, \end{equation} onde \(X_t\) é estacionário, \(W_t\sim N(0,\sigma_{_W}^2)\) é um ruído branco e \(\phi_1,\phi_2,\cdots,\phi_p\) são constantes tais que \(\phi_p\neq 0\).
A esperança de \(X_t\) satisfazendo um modelo autorregressivo é zero. Caso seja \(\mbox{E}(X_t)=\mu\neq 0\) podemos substituir \(X_t\) por \(X_t-\mu\) e temos \begin{equation} X_t-\mu=\phi_1 (X_{t-1}-\mu)+\phi_2 (X_{t-2}-\mu)+\cdots+\phi_p (X_{t-p}-\mu)+W_t \end{equation} ou escrevemos \begin{equation} X_t=\alpha + \phi_1 X_{t-1}+\phi_2 X_{t-2}+\cdots+\phi_p X_{t-p}+W_t, \end{equation} sendo \(\alpha=\mu(1-\phi_1-\phi_2-\cdots-\phi_p)\).
Notamos que o modelo acima é semelhante ao modelo de regressão da Seção II.1. Algumas dificuldades técnicas, entretanto, se desenvolvem na aplicação desse modelo porque os regressores \(X_{t-1},X_{t-2},\cdots,X_{t-p}\), são componentes aleatórios, enquanto \(Z_t\) foi considerado fixo. Uma forma útil segue usando o operador de retardo \(B\) para escrever o modelo \(AR(p)\) como \begin{equation} (1-\phi_1 B-\phi_2 B^2-\cdots-\phi_p B^p)X_t = W_t \end{equation} ou ainda de forma mais concisa como \(\phi(B)X_t=W_t\).
As propriedades de \(\phi(B)\) são importantes na resolução da equação acima para \(X_t\). Isso leva à seguinte definição.
Definimos o operador autorregressivo de ordem \(p\) como \begin{equation} \phi(B)=(1-\phi_1 B-\phi_2 B^2-\cdots-\phi_p B^p)\cdot \end{equation}
Exemplo III.1. Modelo \(AR(1)\).
Iniciamos a investigação de modelos de AR considerando o modelo de primeira ordem, \(AR(1)\), dado por \(X_t=\phi X_{t-1}+W_t\). Iterando para trás \(k\) vezes, conseguimos \begin{equation} \begin{array}{rcl} X_t & = & \phi X_{t-1} +W_t \, = \, \phi(\phi X_{t-2}+W_{t-1})+W_t \\ & = & \phi^2 X_{t-2}+\phi W_{t-1}+W_t \\ & = & \vdots \\ & = & \displaystyle \phi^k X_{t-k} + \sum_{j=0}^{k-1} \phi^j W_{t-j}\cdot \end{array} \end{equation}
Este método sugere que, continuando a iterar para trás e, desde que, \(|\phi|< 1\) e \(\sup_t \mbox{Var}(X_t)< \infty\), podemos representar o modelo \(AR(1)\) como um processo linear da forma \begin{equation} X_t \, = \, \sum_{j=0}^\infty \phi^j W_{t-j}\cdot \end{equation} Observe que \begin{equation} \lim_{k\to\infty} \mbox{E}\Big( X_t-\sum_{j=0}^{k-1}\phi^j W_{t-j}\Big)^2 \, = \, \lim_{k\to\infty} \phi^2\mbox{E}\big( X_{t-k}^2\big) \, = \, 0, \end{equation} de maneira que a expressão acima existe no sentido de média quadrádita, ver Anexo A para a definição.
A representação \(X_t \, = \, \sum_{j=0}^\infty \phi^j W_{t-j}\) é chamada de solução estacionária do modelo. De fato, por simples substituição, \begin{equation} \underbrace{\displaystyle\sum_{j=0}^\infty \phi^j W_{t-j}}_{X_t} \, = \, \phi \underbrace{\displaystyle\sum_{k=0}^\infty \phi^k W_{t-i-k}}_{X_{t-1}} \, + \, W_t\cdot \end{equation}
O modelo \(AR(1)\) definido acima é estacionário com média \begin{equation} \mbox{E}(X_t) \, = \, \sum_{j=0}^\infty \phi^j \mbox{E}(W_{t-j}) \, = \, 0 \end{equation} e função de autocovariância \begin{equation} \begin{array}{rcl} \gamma(h)& = & \mbox{Cov}(X_{t+h},X_t) \, = \, \displaystyle\mbox{E}\left( \Big(\sum_{j=0}^\infty \phi^j W_{t+h-j}\Big)\Big(\sum_{k=0}^\infty \phi^k W_{t-k}\Big)\right) \\ & = & \displaystyle\mbox{E}\left( \Big(W_{t+h}+\cdots+\phi^h W_t+\phi^{h+1} W_{t-1}+\cdots\Big)\Big(W_t+\phi W_{t-1}+\cdots\Big)\right) \\ & = & \displaystyle\sigma_{_W}^2\sum_{j=0}^\infty \phi^{h+j}\phi^j \, = \, \sigma_{_W}^2\phi^h\sum_{j=0}^\infty \phi^{2j} \, = \, \dfrac{\sigma_{_W}^2 \phi^h}{1-\phi^2}, \qquad h\geq 0\cdot \end{array} \end{equation}
Recordemos que \(\gamma(h)=\gamma(-h)\), então vamos exibir apenas a função de autocovariância para \(h\geq 0\). Assim, obtemos que o ACF de um modelo \(AR(1)\) é da forma \begin{equation} \rho(h) \, = \, \dfrac{\gamma(h)}{\gamma(0)} \, = \, \phi^h, \qquad h\geq 0, \end{equation} e \(\rho(h)\) satisfaz a recursão \begin{equation} \rho(h) \, = \, \phi \rho(h-1), \qquad h=1,2,\cdots \cdot \end{equation} Discutiremos o ACF de um modelo geral \(AR(p)\) na Seção III.3.
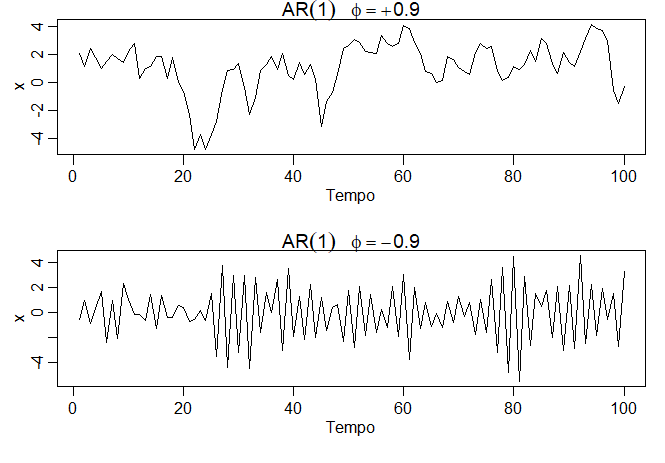
Exemplo III.2. O caminho da amostra de um processo \(AR(1)\).
A figura abaixo mostra um gráfico no tempo de dois processos \(AR(1)\), um com \(\phi=0.9\) e um com \(\phi=-0.9\); em ambos os casos, \(\sigma_{_W}^2 = 1\). No primeiro caso, \(\rho(h)=0.9^h\), para \(h\geq 0\), então as observações próximas no tempo estão positivamente correlacionadas entre si. Esse resultado significa que as observações em pontos de tempo contíguos tenderão a estar próximas em valor umas às outras; este fato aparece no topo da figura abaixo como um caminho amostral muito suave para \(X_t\).
Agora, compare isso com o caso em que \(\phi=-0.9\), de modo que \(\rho(h)=(-0.9)^h\), para \(h\geq 0\). Esse resultado significa que as observações em pontos de tempo contíguos são negativamente correlacionadas, mas observações em dois pontos de tempo distintos estão positivamente correlacionados. Este fato aparece na parte inferior da figura abaixo, onde, por exemplo, se uma observação \(X_t\), é positiva, a próxima observação \(X_{t+1}\) é tipicamente negativa, e a próxima observação, \(X_{t+2}\) é tipicamente positiva. Assim, neste caso, o caminho da amostra é muito instável.
 |
|---|
Exemplo III.3. Modelos AR Explosivos e Causalidade.
No Exemplo I.18, descobriu-se que a caminhada aleatória \(X_t = X_{t-1}+W_t\) não é estacionária. Podemos nos perguntar se existe um processo estacionário \(AR(1)\) com \(|\phi|> 1\). Tais processos são chamados de explosivos porque os valores da série temporal rapidamente se tornam grandes em magnitude. Claramente, porque \(|\phi|^j\) aumenta sem limite quando \(j\to\infty\), \(\sum_{j=0}^{k-1} \phi^j W_{t-j}\) não irá convergir em média quadrada quando \(k\to\infty\), então a intuição usada para obter que \( X_t \, = \, \sum_{j=0}^\infty \phi^j W_{t-j}\) não funcionará diretamente. Podemos, no entanto, modificar esse argumento para obter um modelo estacionário da seguinte forma. Escreva \(X_{t+1} = \phi X_t + W_{t+1}\), nesse caso, \begin{equation} \begin{array}{rcl} X_t & = & \displaystyle\frac{1}{\phi}X_{t+1} - \frac{1}{\phi}W_{t+1} \, = \, \frac{1}{\phi}\Big(\frac{1}{\phi}X_{t+2}-\frac{1}{\phi}W_{t+2} \Big) -\frac{1}{\phi}W_{t+1} \\ & \vdots & \vdots \\ & = & \displaystyle\frac{1}{\phi^k}X_{t+k} -\sum_{j=1}^{k-1} \frac{1}{\phi^j} W_{t+j}, \end{array} \end{equation} por iterar passos \(k\) para a frente. Porque \(|\phi|^{-1} <1\), este resultado sugere o modelo dependente estacionário futuro \(AR(1)\) \begin{equation} X_t \, = \, -\sum_{j=1}^\infty \frac{1}{\phi^j} W_{t+j}\cdot \end{equation}
O leitor pode verificar que este modelo é estacionário e da forma \(AR(1)\) com \(X_t = \phi X_{t-1}+W_t\). Infelizmente, esse modelo é inútil porque requer que saibamos o futuro para podermos prever o futuro. Quando um processo não depende do futuro, como o \(AR(1)\) quando \(|\phi| < 1\), diremos que o processo é causal. No caso explosivo deste exemplo, o processo é estacionário, mas também depende do futuro e não é causal.
Exemplo III.4. Toda explosão tem uma causa.
Excluir modelos explosivos da consideração não é um problema porque os modelos têm contrapartes causais. Por exemplo, se \begin{equation} X_t \, = \, \phi X_{t-1}+W_t, \qquad \mbox{com} \qquad |\phi|>1, \end{equation} e \(W_t\sim N(0,\sigma_{_W}^2)\), independentes igualmente distribuídos. Então utilizando o modelo \(X_t = -\sum_{j=1}^\infty \phi^{-j} W_{t+j}\) \(\{X_t\}\) é um processo Gaussiano estacionário não causal com \(\mbox{E}(X_t)=0\) e \begin{equation} \begin{array}{rcl} \gamma_{_X}(h) & = & \mbox{Cov}(X_{t+h},X_t) \, = \, \displaystyle\mbox{Cov}\left( -\sum_{j=1}^\infty \frac{1}{\phi}W_{t+h+j} -\sum_{k=1}^\infty \frac{1}{\phi^k}W_{t+k}\right) \\ & = & \dfrac{\sigma_{_W}^2}{\phi^2\phi^h(1-\phi^{-2})}\cdot \end{array} \end{equation}
Assim, o processo causal definido por \begin{equation} Y_t \, = \, \frac{1}{\phi}Y_{t-1}+V_t, \end{equation} onde \(V_t\sim N(0,\sigma_{_W}^2\phi^{-2})\) é estocasticamente igual ao processo \(X_t\), ou seja, todas as distribuições finitas dos processos são as mesmas. Por exemplo, se \(X_t = 2X_{t-1}+W_t\) com \(\sigma_{_W}^2=1\), então \(Y_t = \frac{1}{2}Y_{t-1}+V_t\) com \(\sigma_{_V}^2 = 1/4\) é um processo causal equivalente, ver o Exercício III.3. Este conceito generaliza para ordens superiores, mas é mais fácil de mostrar usando técnicas na Parte IV; veja o Exemplo IV.8.
A técnica de iterar para obter uma idéia da solução estacionária de modelos \(AR\) funciona bem quando \(p = 1\), mas não para ordens maiores. Uma técnica geral é a dos coeficientes correspondentes. Considere o modelo \(AR(1)\) na forma de operador \begin{equation} \phi(B)X_t \, = \, W_t, \end{equation} onde \(\phi(B)=1-\phi B\) e \(|\phi|< 1\). Também podemos escrever, utilizando o operador de forma \begin{equation} X_t \, = \, \sum_{j=0}^\infty \psi_j W_{t-j} \, = \, \psi(B)W_t, \end{equation} onde \(\psi(B)=\sum_{j=0}^\infty \psi_j B^j\) e \(\psi_j=\phi^j\). Suponha que não soubéssemos que \(\psi_j=\phi^j\). Substituindo, temos que \begin{equation} \phi(B)\psi(B)W_t \, = \, W_t\cdot \end{equation}
Os coeficientes de \(B\) no lado esquerdo e direito devem ser iguais, o que significa \begin{equation} (1-\phi B)\big( 1+\psi_1 B+\psi_2 B^2 + \cdots+\psi_j B^j+\cdots\big) \, = \, 1\cdot \end{equation} Reorganizando os coeficientes acima, temos \begin{equation} 1+(\psi_1-\phi)B+(\psi_2-\psi_1\phi)B^2+\cdots+(\psi_j-\psi_{j-1}\phi)B^j+\cdots \, = \, 1, \end{equation} vemos que para cada \(j = 1,2,\cdots\), o coeficiente de \(B^j\) à esquerda deve ser zero porque é zero à direita. O coeficiente de \(B\) à esquerda é de \(\psi_1-\phi\), e igualando isso a zero, \(\psi_1-\phi=0\), leva a \(\psi_1=\phi\). Continuando, o coeficiente de \(B^2\) é \(\psi_2-\psi_1\phi\), então \(\psi_2=\phi^2\). Em geral, \begin{equation} \psi_j=\psi_{j-1}\phi, \end{equation} com \(\psi_0=1\), o qual nos leve à solução \(\psi_j=\phi^j\).
Outra maneira de pensar sobre as operações que acabamos de realizar é considerar o modelo \(AR(1)\) na forma de operador, \(\phi(B)X_t = W_t\). Agora multiplique ambos os lados por \(\phi^{-1}(B)\), assumindo que o operador inverso exista, para obter \begin{equation} \phi^{-1}(B)\phi(B)X_t \, = \, \phi^{-1}(B)W_t, \end{equation} ou \begin{equation} X_t \, = \, \phi^{-1}(B)W_t\cdot \end{equation}
Nós já sabemos que \begin{equation} \phi^{-1}(B) \, = \, 1+\phi B+\phi^2 B^2 +\cdots+\phi^j B^j +\cdots, \end{equation} isto é, \(\phi^{-1}(B)=\psi(B)\) acima. Assim, notamos que trabalhar com operadores é como trabalhar com polinômios. Isto é, considere o polinômio \(\phi(z)=1-\phi z\), onde \(z\) é um número complexo e \(|\phi|< 1\). Então \begin{equation} \phi^{-1}(z) \, = \, \displaystyle\frac{1}{1-\phi z} \, = \, 1+\phi z+\phi^2 z^2+\cdots + \phi^j z^j +\cdots, \qquad |z|\leq 1, \end{equation} e os coeficientes de \(B^j\) em \(\phi^{-1}(B)\) são os mesmos que os coeficientes de \(z^j\) em \(\phi^{-1}(z)\). Em outras palavras, podemos tratar o operador de retrocesso \(B\), como um número complexo \(z\). Esses resultados serão generalizados em nossa discussão sobre os modelos ARMA. Os polinômios correspondentes aos operadores serão úteis para explorar as propriedades gerais dos modelos ARMA.
Introdução aos modelos de médias móveis
Como uma alternativa à representação autorregressiva na qual os \(X_t\) no lado esquerdo da equação são combinados linearmente, o modelo de médias móveis de ordem \(q\), abreviado como \(MA(q)\), assume o ruído branco \(W_t\) do lado direito da equação definidora seja combinado linearmente para formar os dados observados.
O modelo de médias móveis de ordem \(q\) ou \(MA(q)\) é definido como \begin{equation} X_t \, = \, W_t + \theta_1 W_{t-1}+\theta_2 W_{t-2}+\cdots+\theta_q W_{t-q}, \end{equation} onde \(W_t\sim N(0,\sigma_{_W}^2)\) independentes e \(\theta_1,\theta_2,\cdots,\theta_q\), \(\theta_q\neq 0\) são parâmetros.
Em alguns textos e pacotes define-se o modelo \(MA(q)\) com coeficientes negativos; isso é, \begin{equation} X_t \, = \, W_t - \theta_1 W_{t-1}-\theta_2 W_{t-2}-\cdots-\theta_q W_{t-q}\cdot \end{equation}
O sistema é o mesmo que o da média móvel infinita definida como o processo linear \begin{equation*} X_t \, = \, \sum_{j=0}^\infty \psi_j W_{t-j} \, = \, \psi(B)W_t, \end{equation*} onde \(\psi_0 = 1\), \(\psi_j = \theta_j\), para \(j = 1,\cdots,q\) e \(\psi_j = 0\) para outros valores. Podemos também escrever o processo \(MA(q)\) na forma equivalente \begin{equation} X_t \, = \, \theta(B)W_t, \end{equation} utilizando a seguinte definição.
O operador de médias móveis é definido como \begin{equation} \theta(B) \, = \, 1+\theta_1 B+\theta_2 B^2 + \cdots + \theta_q B^q\cdot \end{equation}
Ao contrário do processo autoregressivo, o processo de médias móveis é estacionário para quaisquer valores dos parâmetros \(\theta_1,\cdots,\theta_q\); detalhes desse resultado são fornecidos na Seção III.3.
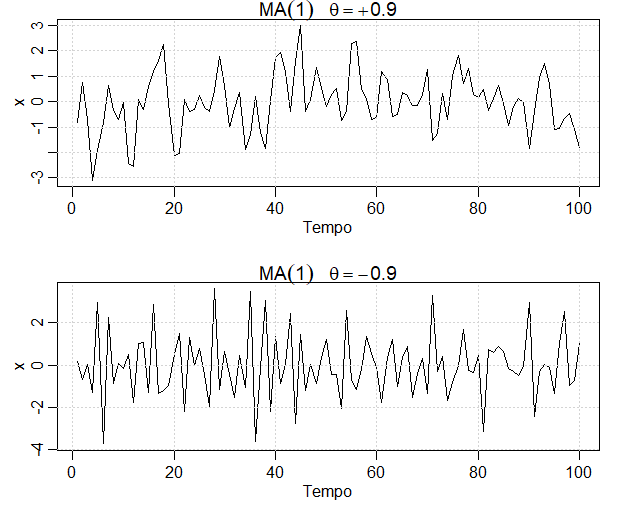
Exemplo III.5. O processo \(MA(1)\).
Consideremos o modelo \(MA(1)\) \(X_t=W_t+\theta W_{t-1}\). Então \(\mbox{E}(X_t)=0\), \begin{equation} \gamma(h) \, = \, \left\{\begin{array}{ccl} (1+\theta^2)\sigma_{_W}^2, & \mbox{quando} & h=0 \\ \theta\sigma_{_W}^2, & \mbox{quando} & h=1 \\ 0, & \mbox{quando} & h>1 \end{array}\right., \end{equation} e o ACF é \begin{equation} \rho(h) \, = \, \left\{\begin{array}{ccl} \displaystyle\frac{\theta}{1+\theta^2}, & \mbox{quando} & h=1 \\ 0, & \mbox{quando} & h>1 \end{array}\right.\cdot \end{equation}
Observemos que \(|\rho(1)|\leq 1/2\) para todos os valores de \(\theta\). Além disso, \(X_t\) está correlacionado com \(X_{t-1}\), mas não com \(X_{t-2},X_{t-3},\cdots\). Compare isso com o caso do modelo \(AR(1)\) no qual a correlação entre \(X_t\) e \(X_{t-k}\) nunca é zero. Quando \(\theta=0.9\), por exemplo, \(X_t\) e \(X_{t-1}\) estão positivamente correlacionados e \(\rho(1)=0.497\). Quando \(\theta=-0.9\), \(X_t\) e \(X_{t-1}\) são correlacionados negativamente e \(\rho(1)=-0.497\). A figura abaixo mostra um gráfico de tempo destes dois processos com \(\sigma_{_W}^2 = 1\). Perceba que a série para qual \(\theta=0.9\) é mais suave que a série para a qual \(\theta=-0.9\).
 |
|---|
Exemplo III.6. Não unicidade dos modelos MA e da invertibilidade.
Usando o Exemplo III.5, notamos que para um modelo \(MA(1)\), \(\rho(h)\) é o mesmo para \(\theta\) e \(1/\theta\); tente 5 e 15, por exemplo. Além disso, o par \(\sigma_{_W}^2=1\) e \(\theta = 5\) produzem a mesma função de autocovariância que o par \(\sigma_{_W}^2 = 25\) e \(\theta= 1/5\), \begin{equation} \gamma(h) \, = \, \left\{ \begin{array}{ccl} 26, & \mbox{para} & h=0, \\ 5, & \mbox{pata} & h=1, \\ 0, & \mbox{para} & h>1\cdot \end{array}\right.\cdot \end{equation}
Portanto, o processo \(MA(1)\) \begin{equation} X_t \, = \, W_t+\frac{1}{5}W_{t-1}, \qquad W_t\sim N(0,25) \end{equation} independentes e \begin{equation} Y_t \, = \, V_t+5V_{t-1}, \qquad V_t\sim N(0,1), \end{equation} independentes são os mesmos por causa da normalidade, ou seja, todas as distribuições finitas são as mesmas. Somente podemos observar as séries temporais, \(X_t\) ou \(Y_t\), e não o ruído, \(W_t\) ou \(V_t\), então não podemos distinguir entre os modelos. Por isso, teremos que escolher apenas um deles. Por conveniência, imitando o critério de causalidade para modelos de AR, escolheremos o modelo com uma representação AR infinita. Tal processo é chamado de processo inversível.
Para descobrir qual modelo é invertível, podemos inverter os papéis de \(X_t\) e \(W_t\), isso porque estamos imitando o caso \(AR\) e escrever o modelo \(MA(1)\) como \(W_t = -\theta W_{t-1}+X_t\).
Se \(|\theta|< 1\), então \(W_t = \sum_{j=0}^\infty (-\theta)^j X_{t-j}\), que é a representação \(AR\) infinita desejada do modelo. Assim, dada uma escolha, escolheremos o modelo com \(\sigma_{_W}^2= 25\) e \(\theta= 1/5\) porque é invertível.
No caso AR, o polinômio, \(\theta(z)\) correspondente aos operadores de médias móveis, \(\theta(B)\) será útil na exploração das propriedades gerais dos processos de MA. Por exemplo, podemos escrever o modelo \(MA(1)\) como \(X_t = \theta(B)W_t\), onde \(\theta(B) = 1 + \theta B\). Se \(|\theta|< 1\), então podemos escrever o modelo como \(\pi(B) X_t = W_t\), onde \(\pi(B)=\theta^{-1}(B)\).
Seja \(\theta(z)=1 + \theta z\), para \(|z|\leq 1\), então \begin{equation} \pi(z) \, = \,\theta^{-1}(z)=\dfrac{1}{1+\theta z}=\sum_{j=0}^\infty (-\theta)^j z^j \end{equation} e determinamos que \(\pi(B)=\sum_{j=0}^\infty (-\theta)^j B^j\).
Modelos autorregressivos de médias móveis
Prosseguimos agora com o desenvolvimento do modelo geral de médias móveis autoregressivos e o modelo de médias móveis autorregressivos mistos (ARMA), modelos para séries temporais estacionárias.
A série temporal \(\{X_t \, : \, t=0,\pm 1,\pm 2,\cdots\}\) é \(ARMA(p,q)\) se é estacionária e \begin{equation} X_t \, = \, \phi_1 X_{t-1}+\cdots+\phi_p X_{t-p}+W_t+\theta_1 W_{t-1}+\cdots+\theta_q W_{t-q}, \end{equation} onde \(\phi_p\neq 0\), \(\theta_q\neq 0\) e \(\sigma_{_W}^2>0\). Os parâmetros \(p\) e \(q\) são chamados ordens autorregressivas e de médias móveis, respectivamente. Se \(X_t\) tiver uma média \(\mu\) diferente de zero, definimos \(\alpha=\mu(1-\phi_1-\cdots-\phi_p)\) e escrevemos o modelo como \begin{equation} X_t \, = \, \alpha+\phi_1 X_{t-1}+\cdots+\phi_p X_{t-p}+W_t+\theta_1 W_{t-1}+\cdots+\theta_q W_{t-q}, \end{equation} onde \(W_t\sim N(0,\sigma_{_W}^2)\) independentes.
Como observado anteriormente, quando \(q = 0\), o modelo é chamado de modelo autorregressivo de ordem \(p\) ou \(AR(p)\), e quando \(p = 0\), o modelo é chamado de modelo de médias móveis de ordem \(q\) ou \(MA(q)\). Para auxiliar na investigação de modelos ARMA, será útil escrevê-los usando o operador AR e o operador MA. Em particular, o modelo \(ARMA(p,q)\) pode então ser escrito de forma concisa \begin{equation} \phi(B)X_t \, = \, \theta(B)W_t\cdot \end{equation}
A forma concisa do modelo aponta para um problema potencial em que podemos complicar desnecessariamente o modelo multiplicando ambos os lados por outro operador, digamos \begin{equation} \eta(B)\phi(B)X_t \, = \, \eta(B)\theta(B)W_t, \end{equation} sem mudar a dinâmica. Considere o seguinte exemplo.
Exemplo III.7. Redundância de parâmetros.
Considere o processo de ruído branco \(X_t=W_t\). Multiplicando ambos os lados pela equação \(\eta(B)=1-0.5 B\), então o modelo torna-se \((1-0.5 B)X_t=(1-0.5 B)W_t\) ou \begin{equation} X_t \, = \, 0.5 X_{t-1}-0.5 W_{t-1}+W_t, \end{equation} que se parece com um modelo \(ARMA(1,1)\). Claro, \(X_t\) ainda é ruído branco; nada mudou a esse respeito, ou seja, \(X_t = W_t\) é a solução para o modelo acima, mas ocultamos o fato de que \(X_t\) é ruído branco por causa da redundância de parâmetros ou parametrização excessiva.
A consideração da redundância de parâmetros será crucial quando discutirmos a estimativa para modelos gerais ARMA. Como este exemplo aponta, podemos ajustar um modelo \(ARMA(1,1)\) para dados de ruído branco e descobrir que as estimativas dos parâmetros são significativos. Se não estivéssemos cientes da redundância de parâmetros, poderíamos afirmar que os dados estão correlacionados quando na verdade não são. Embora ainda não tenhamos discutido a estimação, apresentamos a seguinte demonstração do problema. Geramos 150 amostras normais independentes identicamente distribuídas e depois ajustamos um \(ARMA(1,1)\) aos dados. Note que \(\widehat{\phi}=-0.96\) e \(\widehat{\theta}=0.95\) e ambos são significativos.
Abaixo está o código R , note que a estimativa chamada intercept é realmente a estimativa da média.Assim, esquecendo a estimativa da média, o modelo ajustado parece \begin{equation} (1+0.96B)X_t \, = \, (1+0.96B)W_t, \end{equation} que devemos reconhecer como um modelo super-parametrizado.
Os exemplos III.3, III.6 e III.7 apontam para um número de problemas possíveis com a definição geral de modelos \(ARMA(p,q)\). Para resumir, vimos os seguintes problemas:
- (a) modelos redundantes de parâmetros,
- (b) modelos estacionários AR que dependem do futuro e
- (c) modelos MA que não são exclusivos.
Para superar esses problemas, vamos exigir algumas restrições adicionais nos parâmetros do modelo. Primeiro, fazemos as seguintes definições.
Os polinômios AR e MA são definidos como \begin{equation} \phi(z) \, = \, 1-\phi_1 z-\cdots -\phi_p z^p, \qquad \phi_p\neq 0, \end{equation} e \begin{equation} \theta(z) \, = \, 1+\theta_1 z+\cdots +\theta_q z^q, \qquad \theta_q\neq 0, \end{equation} respectivamente, onde \(z\) é um número complexo.
Para resolver o primeiro problema, iremos nos referir a um modelo \(ARMA(p,q)\) para significar que ele está em sua forma mais simples. Ou seja, além da definição original também exigiremos que \(\phi(z)\) e \(\theta(z)\) não tenham fatores comuns. Assim, o processo, \(X_t = 0.5 X_{t-1}-0.5 W_{t-1}+W_t\), discutido no Exemplo III.7 não é referido como um processo \(ARMA(1,1)\) porque, em sua forma reduzida, \(X_t\) é ruído branco.
Para abordar o problema dos modelos dependentes do futuro, introduzimos formalmente o conceito de causalidade.
Um modelo \(ARMA(p,q)\) é considerado causal, se a série temporal \(\{X_t \, : \, t = 0,\pm 1,\pm 2,\cdots\}\) pode ser escrito como um processo linear unilateral: \begin{equation} X_t \, = \, \sum_{j=0}^\infty \psi_j W_{t-j} \, = \, \psi(B) W_t, \end{equation} onde \(\psi(B)=\sum_{j=0}^\infty \psi_j B^j\) e \(\sum_{j=0}^\infty |\psi_j|< \infty\), escolhemos \(\psi_0=1\).
No Exemplo III.3, o processo \(AR(1)\), \(X_t = \phi X_{t-1}+W_t\) é causal apenas quando \(|\phi|< 1\). Equivalentemente, o processo é causal apenas quando a raiz de \(\phi(z)=1-\phi z\) é maior que um em valor absoluto. Ou seja, a raiz \(z_0\) de \(\phi(z)\) é \(z_0 = 1/\phi\), porque \(\phi(z_0) = 0\) e \(|z_0|> 1\) porque \(|\phi|< 1\). Em geral, temos a seguinte propriedade.
Um modelo \(ARMA(p,q)\) é causal se, e somente se, \(\phi(z)\neq 0\) para \(|z|\leq 1\). Os coeficientes do processo linear na Definição III.7 podem ser determinados resolvendo-se \begin{equation} \psi(z) \, = \, \displaystyle\sum_{j=0}^\infty \psi_j z^j \, = \, \dfrac{\theta(z)}{\phi(z)}, \qquad |z|\leq 1\cdot \end{equation}
Outra maneira de expressar o Teorema III.1 é que um processo ARMA é causal apenas quando as raízes de \(\phi(z)\) estão fora do círculo unitário; isto é, \(\phi(z)=0\) somente quando \(|z|>1\). Finalmente, para resolver o problema de unicidade discutido no Exemplo III.6, escolhemos o modelo que permite uma representação autorregressiva infinita.
Um modelo \(ARMA(p,q)\) é dito invertível se a série temporal \(\{X_t \, : \, t=0,\pm 1,\pm 2,\cdots\}\) pode ser escrita como \begin{equation} \pi(B)X_t \, = \, \sum_{j=0}^\infty \pi_j X_{t-j} \, = \, W_t, \end{equation} onde \(\pi(B)=\sum_{j=0}^\infty \pi_j B^j\) e \(\sum_{j=0}^\infty |\pi_j|< \infty\), escolhemos \(\pi_0=1\).
Analogamente ao Teorema III.1, temos a seguinte propriedade.
Um modelo \(ARMA(p,q)\) é invertível se, e somente se, \(\theta(z)\neq 0\) para \(|z|\leq 1\). Os coeficientes \(\pi_j\) de \(\pi(B)\) dados na Definição III.8 podem ser determinados resolvendo-se \begin{equation} \pi(z) \, = \, \displaystyle\sum_{j=0}^\infty \pi_j z^j \, = \, \dfrac{\phi(z)}{\theta(z)}, \qquad |z|\leq 1\cdot \end{equation}
Outra maneira de expressar o Teorema III.2 é que um processo ARMA é invertível somente quando as raízes de \(\theta(z)\) estão fora do círculo unitário; isto é, \(\theta(z)=0\) somente quando \(|z|> 1\).
Os exemplos a seguir ilustram esses conceitos.
Exemplo III.8. Redundância de parâmetros, causalidade, invertibilidade.
Considere o processo \begin{equation} X_t \, = \, 0.4 X_{t-1}+0.45 X_{t-2}+W_t+W_{t-1}+0.25 W_{t-2}, \end{equation} ou, na forma de operador \begin{equation} (1-0.4B-0.45B^2)X_t \, = \, (1+B+0.25B^2)W_t \cdot \end{equation}
Primeiramente, \(X_t\) parece ser um processo \(ARMA(2,2)\). Mas observe que \begin{equation} \phi(B) \, = \, 1-0.4B-0.45B^2 \, = \, (1+0.5B)(1-0.9B) \end{equation} e \begin{equation} \theta(B) \, = \, (1+B+0.25B^2) \, = \, (1+0.5B)^2, \end{equation} tem um fator comum que pode ser cancelado.
Após o cancelamento, os operadores são \(\phi(B)=(1-0.9B)\) e \(\theta(B)=(1+0.5B)\), portanto o modelo é um \(ARMA(1,1)\), \((1-0.9B)X_t = (1+0.5B)W_t\) ou \begin{equation} X_t \, = \, 0.9X_{t-1}+0.5W_{t-1}+W_t\cdot \end{equation}
O modelo é causal porque \(\phi(z)=(1-0.9z) = 0\) quando \(z = 10/9\), que está fora do círculo unitário. O modelo também é invertível porque a raiz de \(\theta(z)=(1+0.5z)\) é \(z = -2\); que está fora do círculo unitário.
Para escrever o modelo como um processo linear, podemos obter os pesos \(\psi\) usando o enunciado no Teorema III.1, \(\phi(z)\psi(z)=\theta(z)\), ou \begin{equation} (1-0.9z)(1+\psi_1 z+\psi_2 z^2+\cdots+\psi_j z^j +\cdots) \, = \, 1+0.5z\cdot \end{equation}
Reorganizando, ficamos \begin{equation} 1+(\psi_1-0.9)z+(\psi_2-0.9\psi_1)z^2+\cdots+(\psi_j-0.9\psi_{j-1})z^j+\cdots \, = \, 1+0.5z\cdot \end{equation}
Combinando os coeficientes de \(z\) nos lados esquerdo e direito, obtemos \(\psi_1-0.9=0.5\) e \(\psi_j-0.9\psi_{t-1}=0\) para \(j>1\). Portanto, \(\psi_j=1.4(0.9)^{j-1}\) para \(j\geq 1\) e podemos escrever \begin{equation} X_t \, = \, W_t+1.4 \sum_{j=1}^\infty 0.9^{j-1}W_{t-j}\cdot \end{equation}
Os valores de \(\psi_j\) podem ser calculados em R da seguinte forma:
A representação invertível usando o Teorema III.1 é obtida através da correspondência dos coeficientes em \(\theta(z)\pi(z)=\phi(z)\), \begin{equation} (1+0.5z)(1+\pi_1 z+\pi_2 z^2+\pi_3 z^3+\cdots) \, = \, 1-09.z\cdot \end{equation} Neste caso, os \(\pi\)-pesos são dados por \(\pi_j = (-1)^j1.4(0.5)^{j-1}\), para \(j\geq 1\) e daí, porque \(W_t=\sum_{j=0}^\infty \pi_j X_{t-j}\), também podemos escrever \begin{equation} X_t \, = \, 1.4\sum_{j=1}^\infty (-0.5)^{j-1}X_{t-j}+W_t\cdot \end{equation}
Os valores dos \(\pi_j\) podem ser calculados em R como segue, revertendo os papéis de \(W_t\) e \(X_t\), ou seja, escrevendo o modelo como \(W_t=-0.5W_{t-1}+X_t-0.9X_{t-1}\):
Exemplo III.9. Condições causais para o processo \(AR(2)\).
Para o modelo \(AR(1)\), \((1-\phi B)X_t=W_t\), ser causal, a raiz de \(\phi(z)=1-\phi z\) deve ficar fora do círculo unitário. Nesse caso, \(\phi(z)=0\) quando \(z=1/\phi\), por isso é fácil ir a partir do requisito causal na raiz, \(|1/\phi|> 1\), a um requisito no parâmetro, \(|\phi|< 1\). Não é tão fácil estabelecer essa relação para modelos de ordem superior.
Por exemplo, o modelo \(AR(2)\), é causal quando as duas raízes de \(\phi(z)=1-\phi_1 z-\phi_2 z^2\) ficam fora do círculo unitário. Usando a fórmula quadrática, este requisito pode ser escrito como \begin{equation} \left| \frac{\phi_1\pm \sqrt{\phi_1^2+4\phi_2}}{-2\phi_2}\right|> 1\cdot \end{equation}
As raizes de \(\phi(z)\) podem ser reais e distintas, reais e iguais ou um par conjugado complexo. Se denotarmos essas raízes por \(z_1\) e \(z_2\), podemos escrever \(\phi(z)=(1-z_1^{-1}z)(1-z_2^{-1}z)\), observe que \(\phi(z_1)=\phi(z_2)=0\).
O modelo pode ser escrito em forma de operador como \((1-z_1^{-1}B)(1-z_2^{-1}B)X_t=W_t\). A partir dessa representação, segue-se que \(\phi_1=(z_1^{-1}+z_2^{-1})\) e \(\phi_2=-(z_1 z_2)^{-1}\). Essa relação e o fato de que \(|z_1|> 1\) e \(|z_2|> 1\) podem ser usados para estabelecer a seguinte condição equivalente para causalidade: \begin{equation} \phi_1+\phi_2< 1, \qquad \phi_2-\phi_1< 1 \qquad \mbox{e} \qquad |\phi_2|< 1\cdot \end{equation} Essa condição de causalidade especifica uma região triangular no espaço paramétrico.
III.2 Equações em diferenças
O estudo do comportamento dos processos ARMA e seus ACFs é bastante aprimorado por um conhecimento básico de equações de diferenças, simplesmente porque são equações de diferença. Vamos dar um breve e heurístico relato do tópico, juntamente com alguns exemplos da utilidade da teoria. Para detalhes, o leitor é referido a Mickens (1990).
Suponhamos que a sequência de números \(u_0,u_1,u_2,\cdots\) sejam tais que \begin{equation} u_n-\alpha u_{n-1} \, = \, 0, \qquad \alpha\neq 0, \qquad n=1,2,\cdots\cdot \end{equation} Por exemplo, recordemos que a função ACF de um processo \(AR(1)\) é uma sequência \(\rho(h)\) satisfazendo \begin{equation} \rho(h)-\phi\rho(h-1)=0, \qquad h=1,2,\cdots\cdot \end{equation} A equação \(u_n-\alpha u_{n-1} \, = \, 0, \, \alpha\neq 0, \, n=1,2,\cdots\) representa uma equação de diferença homogênea de ordem 1. Para resolver a equação, escrevemos: \begin{equation} \begin{array}{rcl} u_1 & = & \alpha u_0 \\ u_2 & = & \alpha u_1 \, = \, \alpha^2 u_0 \\ \cdots & & \cdots \\ u_n & = & \alpha u_{n-1} \, = \, \alpha^n u_0\cdot \end{array} \end{equation} Dada uma condição inicial \(u_0 = c\), podemos resolver estas equações, ou seja, \(u_n = \alpha^n c\).
Na notação do operador, podemos escrever como \((1-\alpha B)u_n=0\). O polinômio associado é \(\alpha(z)=1-\alpha z\) e a raíz, digamos \(z_0\) deste polinômio é \(z_0=1/\alpha\), isto é \(\alpha(z_0)=0\). Sabemos que a solução, com a condição inicial \(u_0=c\), é \begin{equation} u_n \, = \, \alpha^n c \, = \, \dfrac{c}{z_0^n}\cdot \end{equation} Ou seja, a solução para a equação de diferença depende apenas da condição inicial e do inverso da raiz para o polinômio associado \(\alpha(z)\).
Agora suponha que a sequência satisfaça \begin{equation} u_n-\alpha_1 u_{n-1} -\alpha_2 u_{n-2} \, = \, 0, \qquad \alpha_2 \neq 0, \qquad n=2,3,\cdots\cdot \end{equation} Esta equação é uma equação de diferença homogênea de ordem 2. O polinômio correspondente é \begin{equation} \alpha(z) \, = \, 1-\alpha_1 z -\alpha_2 z^2, \end{equation} que tem duas raízes \(z_1\) e \(z_2\); isto é, \(\alpha(z_1)=\alpha(z_2)=0\). Vamos considerar dois casos. Primeiro suponha \(z_1\neq z_2\). Então a solução geral é \begin{equation} u_n \, = \, \dfrac{c_1}{z_1^n}+\dfrac{c_2}{z_2^n}, \end{equation} onde \(c_1\) e \(c_2\) dependem das condições iniciais. A alegação de que é uma solução pode ser verificada por substituição direta: \begin{array}{l} \underbrace{c_1z_1^{-n}+c_2z_2^{-n}}_{u_n}-\alpha_1\underbrace{\big(c_1z_1^{-(n-1)}+c_2z_2^{-(n-1)}\big)}_{u_{n-1}} -\alpha_2\underbrace{\big(c_1z_1^{-(n-2)}+c_2z_2^{-(n-2)}\big)}_{u_{n-2}} \, = \\ \qquad \qquad \qquad \qquad \qquad \qquad = \, c_1z_1^{-n}\big( 1-\alpha_1z_1-\alpha_2z_1^{2}\big)+c_2z_2^{-n}\big(1-\alpha_1z_2-\alpha_2z_2^2 \big) \\ \qquad \qquad \qquad \qquad \qquad \qquad = \, c_1z_1^{-n}\alpha(z_1)+c_2z_2^{-n}\alpha(z_2) \, = \, 0\cdot \end{array}
Dadas duas condições iniciais \(u_0\) e \(u_1\), podemos resolver para \(c_1\) e \(c_2\): \begin{equation} u_0 = c_1+c_2 \qquad \mbox{e} \qquad u_1 = c_1z_1^{-1}+c_2z_2^{-1}, \end{equation} onde \(z_1\) e \(z_2\) pode ser resolvido em termos de \(\alpha_1\) e \(\alpha_2\) usando a fórmula quadrática, por exemplo.
Quando as raízes são iguais, \(z_1=z_2=z_0\), uma solução geral é \begin{equation} u_n=\frac{c_1+c_2 n}{z_0^n}\cdot \end{equation} Esta alegação também pode ser verificada por substituição direta: \begin{array}{l} \underbrace{z_0^{-n}(c_1+c_2 n)}_{u_n}-\alpha_1\underbrace{\Big(z_0^{-(n-1)}\big(c_1+c_2(n-1)\big) \Big)}_{u_{n-1}} -\alpha_2\underbrace{\Big(z_0^{-{n-2}}\big(c_1+c_2(n-2) \big)\Big)}_{u_{n-2}} \, = \\ \qquad \qquad \qquad \qquad \qquad \qquad = \, z_0^{-n}(c_1+c_2 n)\big(1-\alpha_1z_0-\alpha_2z_0^2 \big) +c_2z_0^{-n+1}(\alpha_1+2\alpha_2z_0) \\ \qquad \qquad \qquad \qquad \qquad \qquad = \, c_2z_0^{-n+1}(\alpha_1+2\alpha_2z_0)\cdot \end{array}
Para mostrar que \(\alpha_1+2\alpha_2z_0=0\), escrevemos \(1-\alpha_1z-\alpha_2z^2=(1-z_0^{-1}z)^2\) e tomando derivados em relação a \(z\) em ambos os lados da equação para obter \(\alpha_1+2\alpha_2z=2z_0^{-1}(1-z_0^{-1}z)\). Portanto, \(\alpha_1+2\alpha_2z_0=2z_0^{-1}(1-z_0^{-1}z_0)\), como queriamos demonstrar. Finalmente, dadas duas condições iniciais \(u_0\) e \(u_1\), podemos resolver para \(c_1\) e \(c_2\): \begin{equation} u_0 \, = \, c_1 \qquad \mbox{e} \qquad u_1 \, = \, \frac{c_1+c_2}{z_0}\cdot \end{equation} Também pode ser mostrado que essas soluções são únicas.
Para resumir estes resultados, no caso de raízes distintas, a solução para a equação em diferenças homogênea de grau dois é \begin{array}{rcl} u_n & = & \dfrac{1}{z_1^n}\times (\mbox{um polinômio em } n \, \mbox{de grau} \, m_1-1)+\displaystyle \frac{1}{z_2^n}\times (\mbox{um polinômio em } n \, \mbox{de grau} \, m_2-1), \end{array} onde \(m_1\) é a multiplicidade da raiz \(z_1\) e \(m_2\) é a multiplicidade da raiz \(z_2\). Neste exemplo, é claro, \(m_1 = m_2 = 1\), e chamamos os polinômios de grau zero \(c_1\) e \(c_2\), respectivamente. No caso da raiz repetida, a solução foi \begin{equation} u_n \, = \, \frac{1}{z_0^n}\times (\mbox{um polinômio em } n \, \mbox{de grau} \, m_0-1), \end{equation} onde \(m_0\) é a multiplicidade da raiz \(z_0\), isto é, \(m_0 = 2\). Neste caso, escrevemos o polinômio de grau um como \(c_1 + c_2n\). Em ambos os casos, resolvemos para \(c_1\) e \(c_2\) dadas duas condições iniciais, \(u_0\) e \(u_1\).
Estes resultados generalizam para a equação em diferença homogênea de ordem \(p\): \begin{equation} u_n-\alpha_1 u_{n-1}-\cdots-\alpha_p u_{n-p} \, = \, 0, \qquad \alpha_p\neq 0, \qquad n=p,p+1,\cdots \cdot \end{equation} O polinômio associado é \(\alpha(z)=1-\alpha_1 z-\cdots-\alpha_p z^p\). Suponha que \(\alpha(z)\) tem raízes distintas, \(z_1\) com multiplicidade \(m_1\), \(z_2\) com multiplicidade \(m_2\), \(\cdots\) e \(z_r\) com multiplicidade \(m_r\), tal que \(m_1 + m_2 +\cdots + m_r = p\). A solução geral para a equação em diferença é \begin{equation} u_n \, = \, \frac{1}{z_1^n}P_1(n)+\frac{1}{z_2^n}P_2(n)+\cdots+\frac{1}{z_r^n}P_r(n), \end{equation} onde \(P_j(n)\), para \(j=1,\cdots,r\) é um polinômio em \(n\), de grau \(m_j-1\). Dadas as \(p\) condições iniciais \(u_0,\cdots,u_{p-1}\), podemos resolver para o \(P_j\) explicitamente.
Exemplo III.10. O ACF do processo \(AR(2)\).
Suponhamos que \(X_t=\phi_1 X_{t-1}+\phi_2 X_{t-2}+W_t\) seja um processo \(AR(2)\) causal. Multiplicando cada lado do modelo por \(X_{t-h}\) para \(h>0\) e tomado esperança obtemos \begin{equation} \mbox{E}(X_t X_{t-h}) \, = \, \phi_1\mbox{E}(X_{t-1}X_{t-h})+\phi_2\mbox{E}(X_{t-2}X_{t-h})+\mbox{E}(W_tX_{t-h})\cdot \end{equation} O resultado é \begin{equation} \gamma(h) \, = \, \phi_1 \gamma(h-1)+\phi_2 \gamma(h-2), \qquad h=1,2,\cdots \cdot \end{equation}
Para encontrarmos o resultado acima utilizamos o fato de que \(\mbox{E}(X_t)=0\) e que para \(h>0\), \begin{equation} \mbox{E}(W_t X_{t-h}) \, = \, \mbox{E}\Big( W_t\sum_{j=0}^\infty \phi_j W_{t-h-j}\Big) \, = \, 0\cdot \end{equation} Obtemos assim \begin{equation} \rho(h) -\phi_1 \rho(h-1)-\phi_2 \rho(h-2) \, = \, 0, \qquad h=1,2,\cdot\cdot \end{equation} As condições iniciais são \(\rho(0)=1\) e \(\rho(-1)=\phi_1/(1-\phi_2)\), as quais obtemos avaliando a expressão acima para \(h=1\) e notando que \(\rho(1)=\rho(-1)\).
Utilizando os resultados para a equação em diferença homogênea de ordem dois, sejam \(z_1\) e \(z_2\) as raízes do polinômio associado, \(\phi(z)=1-\phi_1 z-\phi_2 z^2\). Como o modelo é causal, sabemos que as raízes estão fora do círculo unitário \(|z_1|>1\) e \(|z_2|> 1\). Agora, considere a solução para três casos:
- (i) Quando \(z_1\) e \(z_2\) são reais distintos, então-estacioná \begin{equation} \rho(h)=\frac{c_1}{z_1^h}+\frac{c_2}{z_2^h}, \end{equation} assim \(\rho(h)\to 0\) exponencialmente rápido quando \(h\to\infty\).
- (ii) Quando \(z_1=z_2=z_0\) sejam reais e iguais, então \begin{equation} \rho(h)=\frac{c_1+c_2 h}{z_0^h}, \end{equation} assim \(\rho(h)\to 0\) exponencialmente rápido quando \(h\to\infty\).
- (iii) Quando \(z_1=\overline{z}_2\) são um de complexos conjugados, então \(c_2=\overline{c}_1\) porque \(\rho(h)\) é uma função real e \begin{equation} \rho(h)=\frac{c_1}{z_1^h}+\frac{\overline{c}_1}{\overline{z}_1^h}\cdot \end{equation} Escrevendo \(c_1\) e \(z_1\) em coordenadas polares, por exemplo, \(z_1 = |z_1|e^{i\theta}\), onde \(\theta\) é o ângulo cuja tangente é a razão entre a parte imaginária e a parte real de \(z_1\), às vezes chamada de \(arg(z_1)\), o intervalo de \(\theta\) é \([-\pi,\pi]\). Então, usando o fato de que \(e^{i\alpha} + e^{-i\alpha} = 2 \cos(\alpha)\), a solução tem a forma \begin{equation} \rho(h) \, = \, \dfrac{a}{|z_1|^h}\cos(h\theta+b), \end{equation} onde \(a\) e \(b\) são determinados pelas condições iniciais. Mais uma vez, \(\rho(h)\) amortece a zero exponencialmente rápido quando \(h\to\infty\), mas o faz de forma sinusoidal. A implicação desse resultado é mostrada no próximo exemplo.
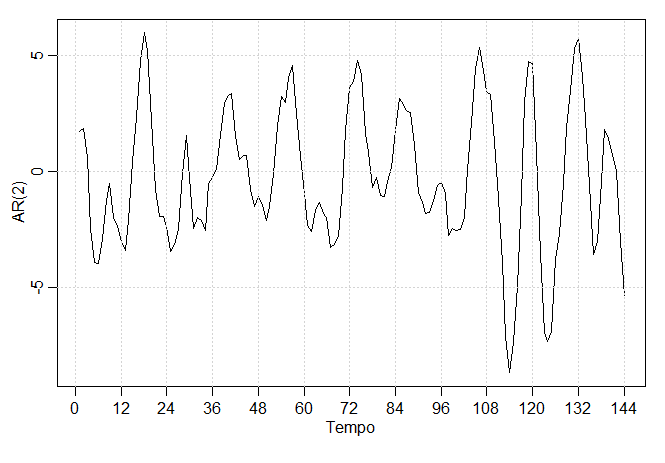
Exemplo III.11. O processo \(AR(2)\) com raízes complexas.
A figura abaixo mostra \(n=144\) observações do modelo \(AR(2)\) \begin{equation} X_t \, = \, 1.5 X_{t-1}-0.75 X_{t-2}+W_t, \end{equation} com \(\sigma_{_W}^2=1\) e com raízes complexas escolhidas para que o processo exiba um comportamento pseudocíclico à taxa de um ciclo a cada 12 pontos de tempo. O polinômio autoregressivo para este modelo é \(\phi(z)=1-1.5 z+0.75 z^2\). As raízes de \(\phi(z)\) são \(1\pm i/\sqrt{3}\) e \(\theta=\tan^{-1}(1/\sqrt{3})=2\pi/12\) radianos por unidade de tempo. Para converter o ângulo em ciclos por unidade de tempo, divida por 2 para obter 1/12 ciclos por unidade de tempo.
 |
|---|
Para calcular as raízes do polinômio e resolver para \(arg\) em R:
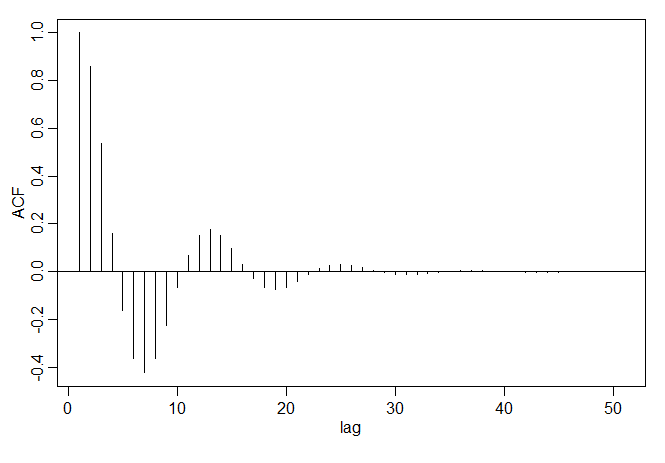
O ACF para este modelo é:
 |
|---|
Exemplo III.12. Os \(\psi\)-pesos para um modelo ARMA.
Para o modelo causal \(ARMA(p,q)\), \(\phi(B)X_t=\theta(B)W_t\), onde os zeros de \(\phi(B)\) estão fora do círculo unitário, lembre-se de que podemos escrever \begin{equation} X_t \, = \, \sum_{j=0}^\infty \psi_j W_{t-j}, \end{equation} sendo que os \(\psi\)-pesos são determinados pela Propriedade III.1
Para o modelo \(MA(p)\) puro, \(\psi_0=1\), \(\psi_j=\theta_j\), quando \(j=1,2,\cdots,q\) e \(\psi_j=0\), caso contrário. Para o caso geral de modelos \(ARMA(p,q)\), a tarefa de resolver para os \(\psi\)-pesos é muito mais complicada, como foi demonstrado no Exemplo III.8. O uso da teoria das equações em diferença homogêneas pode ajudar aqui. Para resolver para os \(\psi\)-pesos em geral, devemos combinar os coeficientes em \(\phi(z)\psi(z)=\theta(z)\): \begin{equation} (1-\phi z-\phi_2 z^2-\cdots)(\psi_0+\psi_1 z+\psi_2 z^2+ \cdots) \, = \, (1+\theta_1 z+\theta_2 z^2+\cdots)\cdot \end{equation}
Os primeiros valores são \begin{array}{rcl} \psi_1 & = & 1 \\ \psi_1-\phi_1\psi_0 & = & \theta_1 \\ \psi_2-\phi_1\psi_2-\phi_2\psi_1-\phi_3\psi_0 & = & \theta_2 \\ \psi_3-\phi_1\psi_2-\phi_2\psi_1-\phi_3\psi_0 & = & \theta_3 \\ \vdots & & \vdots \end{array} onde assumimos \(\phi_j=0\), para \(j>p\) e \(\theta_j=0\) caso \(j>p\). Os \(\psi\)-pesos satisfazem as equações em diferença homogêneas dadas por \begin{equation} \psi_j - \sum_{k=1}^p \phi_k \psi_{j-k} \, = \, 0, \qquad j\geq \max\{p,q+1\}, \end{equation} com condições iniciais \begin{equation} \psi_j - \sum_{k=1}^j \phi_k \psi_{j-k} \, = \, \theta_k, \qquad 0\leq j< \max\{p,q+1\}\cdot \end{equation} A solução geral depende das raízes do polinômio \(AR\), \(\phi(z)=1-\phi_1 z-\cdots-\phi_p z^p\). A solução específica dependerá, claro, das condições iniciais.
Considere o processo ARMA dado acima \(X_t=0.9X_{t-1}+0.5W_{t-1}+W_t\). Devido a \(\max\{p,q+1\}=2\), temos que \(\psi_0=1\) e \(\psi_1=0.9+0.5=1.4\). Pelo resultado das equações em diferença homogêneas para \(j=2,3,\cdots\), os \(\psi\)-pesos satisfazem \(\psi_j-0.9\psi_{j-1}=0\). A solução geral é \(\psi_j=c 0.9^j\). Para encontrar a solução específica, usamos a condição inicial \(\psi_1=1.4\), de manerira que \(1.4=0.9 c\) ou \(c=1.4/0.9\). Finalmente, \(\psi_j=1.4 (0.9)^{j-1}\) para \(j\geq 1\), como vimos no Exemplo III.8.
Para ver, por exemplo, os primeiros 50 \(\psi\)-pesos em R, use: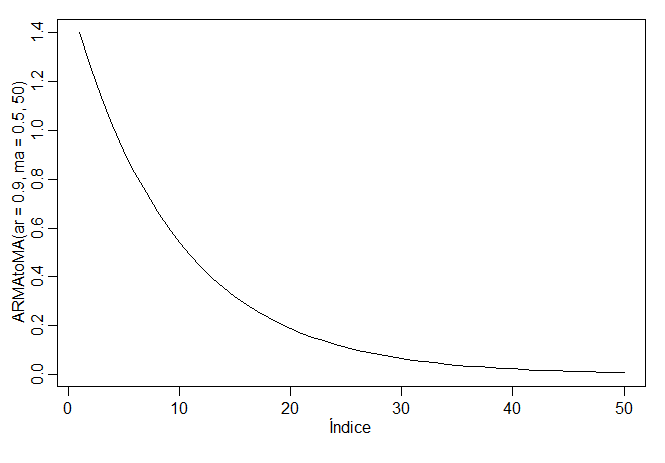 |
|---|
III.3 Autocorrelação e autocorrelação parcial
Começamos exibindo o ACF de um processo \(MA(q)\), \(X_t=\theta(B)W_t\), onde \(\theta(B)=1+\theta_1 B+\cdots+\theta_q B^q\). Porque \(X_t\) é uma combinação linear finita de termos de ruído branco, o processo é estacionário com média \begin{equation} \mbox{E}(X_t) \, = \, \sum_{j=0}^q \theta_j \mbox{E}(W_{t-j}) \, = \, 0, \end{equation} onde escrevemos \(\theta_0=1\) e com função de autocovariância \begin{equation} \begin{array}{rcl} \gamma(h) \, = \, \mbox{Cov}(X_{t+h},X_t) & = & \mbox{Cov}\left( \displaystyle \sum_{j=0}^q \theta_jW_{t+h-j}, \sum_{k=0}^q \theta_k W_{t-k}\right) \\ & = & \displaystyle \left\{ \begin{array}{ccl} \displaystyle \sigma_{_W}^2\sum_{j=0}^{q-h} \theta_j\theta_{j+h}, & \mbox{quando} & 0\leq h\leq q \\ 0, & \mbox{quando} & h>q \end{array}\right.\cdot \end{array} \end{equation}
Lembrando que \(\gamma(h)=\gamma(-h)\), por isso somente exibiremos os valores para \(h\geq 0\). Observe que \(\gamma(q)\) não pode ser zero porque \(\theta_q\neq 0\). O corte de \(\gamma(h)\) após \(q\) lags é a assinatura do modelo \(MA(q)\). Dividindo a expressão acima por \(\gamma(0)\) produz o ACF de um \(MA(q)\): \begin{equation} \rho(h) \, = \, \displaystyle\left\{ \begin{array}{ccc} \frac{\displaystyle\sum_{j=0}^{q-h}\theta_j\theta_{j+h}}{\displaystyle1+\theta_1^2+\cdots+\theta_q^2}, & \mbox{quando} & 1\leq h\leq q \\ 0, & \mbox{quando} & h> q \end{array}\right. \end{equation}
Para um modelo \(ARMA(p,q)\) causal, \(\phi(B)X_t = \theta(B)W_t\), onde os zeros de \(\phi(z)\) estão fora do círculo unitário, escrevamos \begin{equation} X_t \, = \, \sum_{j=0}^\infty \psi_j W_{t-j}\cdot \end{equation} Segue-se imediatamente que \(\mbox{E}(X_t) = 0\) e a função de autocovariância de \(X_t\) é \begin{equation} \gamma(h) \, = \, \mbox{Cov}(X_{t+h},X_t) \, = \, \sigma_{_W}^2\sum_{j=0}^\infty \psi_j \psi_{j+h}, \qquad h\geq 0\cdot \end{equation} Poderíamos então utilizar equações acima para resolver os pesos. Por sua vez, poderíamos resolver por \(\gamma(h)\) e o ACF \(\rho(h)=\gamma(h)/\gamma(0)\). Como no Exemplo III.10, também é possível obter uma equação em diferença homogênea diretamente em termos de \(\gamma(h)\). Primeiro, escrevemos \begin{equation} \begin{array}{rcl} \gamma(h) & = & \mbox{Cov}(X_{t+h},X_t) \, = \, \mbox{Cov}\left( \displaystyle\sum_{j=1}^p\phi_j X_{t+h-j}+\sum_{j=0}^q\theta_j W_{t+h-j}, X_t\right) \\ & = & \displaystyle\sum_{j=1}^p \phi_j\gamma(h-j) \, + \, \sigma_{_W}^2\sum_{j=k}^q \theta_j\psi_{j-h}, \qquad h\geq 0, \end{array} \end{equation} onde usamos o fato de que, para \(h\geq 0\), \begin{equation} \mbox{Cov}(W_{t+h-j},X_t) \, = \, \displaystyle\mbox{Cov}(W_{t+h-j},\sum_{k=0}^\infty \psi_k W_{t-k}) \, = \, \psi_{j-h}\sigma_{_W}^2\cdot \end{equation}
Assim, podemos escrever a equação homogênea geral para o ACF de um processo \(ARMA\) causal: \begin{equation} \gamma(h) - \phi_1 \gamma(h-1)-\cdots-\phi_p\gamma(h-p) \, = \, 0, \qquad h\geq \max\{p,q+1\}, \end{equation} com condições iniciais \begin{equation} \gamma(h)-\sum_{j=1}^p \phi_j \gamma(h-j) \, = \, \sigma_{_W}^2\sum_{j=h}^q\theta_j \psi_{j-h}, \qquad 0\leq h < \max\{p,q+1\} \end{equation} Dividindo por \(\gamma(0)\) nos permitirá resolver para o ACF, \(\rho(h)=\gamma(h)/\gamma(0)\).
Exemplo III.13. O ACF para um modelo \(AR(p)\).
No Exemplo III.10 consideramos o caso \(p=2\). Numa situação geral, segue que \begin{equation} \rho(h) -\phi_1\rho(h-1)-\cdots-\phi_p \rho(h-p)\, = \, 0, \qquad h\geq p\cdot \end{equation}
Sejam \(z_1,\cdots,z_r\) as raízes de \(\phi(z)\), cada com multiplicidade \(m_1,\cdots,m_r\), respectivamente, onde \(m_1+\cdots+m_r=p\). Então, a solução geral é \begin{equation} \rho(h) \, = \, \frac{1}{z_1^h}P_1(h)+\frac{1}{z_2^h}P_2(h)+\cdots+\frac{1}{z_r^h}P_r(h), \qquad h\geq p, \end{equation} onde \(P_j(h)\) é um polinômio em \(h\) de grau \(m_j-1\).
Lembre-se que, para um modelo causal, todas as raízes estão fora do círculo unitário, \(|z_i|>1\), \(i=1,\cdots,r\). Se todas as raízes são reais, então \(\rho(h)\) amortece exponencialmente rápido a zero quando \(h\to\infty\). Se algumas das raízes são complexas, então elas estarão em pares conjugados e \(\rho(h)\) irá amortecer, de uma maneira sinusoidal, exponencialmente rápido a zero quando \(h\to\infty\). No caso de raízes complexas, a série temporal parecerá ser de natureza cíclica. Isso, é claro, também é verdadeiro para modelos ARMA nos quais a parte AR possui raízes complexas.
Exemplo III.14. O ACF para um modelo \(ARMA(1,1)\).
Consideremos o processo \(ARMA(1,1)\) dado por \(X_t=\phi X_{t-1}+\theta W_{t-1}+W_t\), onde \(|\phi|< 1\). Com base na equação homogênea geral para o ACF de um processo ARMA causal, a função de autocovariância satisfaz \begin{equation} \gamma(h)-\phi \gamma(h-1) \, = \, 0, \qquad h=2,3,\cdots, \end{equation} e segue que, a solução geral é \begin{equation} \gamma(h) \, = \, c\phi^h, \qquad h=1,2,\cdots, \end{equation} com condições iniciais \begin{equation} \gamma(0) \, = \, \phi\gamma(1)+\sigma_{_W}^2 \big( 1+\theta\phi+\theta^2\big) \qquad \mbox{e} \qquad \gamma(1) \, = \, \phi\gamma(0)+\sigma_{_W}^2\theta\cdot \end{equation}
Resolvendo para \(\gamma(0)\) e \(\gamma(1)\), obtemos que: \begin{equation} \gamma(0) \, = \, \sigma_{_W}^2\dfrac{1+2\theta\phi+\theta^2}{1-\phi^2} \qquad \mbox{e} \qquad \gamma(1) \, = \, \sigma_{_W}^2\dfrac{(1+\theta\phi)(\phi+\theta)}{1-\phi^2}\cdot \end{equation} Resolvendo para \(c\), temos \(\gamma(1)=c\phi\) ou \(c=\gamma(1)/\phi\). Portanto, a solução específica para \(h\geq 1\) é \begin{equation} \gamma(h) \, = \, \frac{\gamma(1)}{\phi}\phi^h \, = \, \sigma_{_W}^2\dfrac{(1+\theta\phi)(\phi+\theta)}{1-\phi^2}\phi^{h-1}\cdot \end{equation}
Finalmente, dividindo por \(\gamma(0)\) produz o ACF \begin{equation} \rho(h) \, = \, \dfrac{(1+\theta\phi)(\phi+\theta)}{1+2\theta\phi+\theta^2}\phi^{h-1}, \qquad h\geq 1\cdot \end{equation} Observe que o padrão geral de \(\rho(h)\) versus \(h\) acima não é diferente do de um \(AR(1)\). Portanto, é improvável que possamos diferenciar entre um \(ARMA(1,1)\) e um \(AR(1)\) baseado somente em um ACF estimado a partir de uma amostra. Essa consideração nos levará à função de autocorrelação parcial.
A função de autocorrelação parcial (PACF)
Vimos que para modelos \(MA(q)\), o ACF será zero para defasagens maiores que \(q\). Além disso, porque \(\theta_q\neq 0\), o ACF não será zero no atraso ou lag \(q\). Assim, o ACF fornece uma quantidade considerável de informações sobre a ordem da dependência quando o processo é de médias móveis. Se o processo, no entanto, é ARMA ou AR, o ACF sozinho nos diz pouco sobre as ordens de dependência. Assim, vale a pena buscar uma função que se comportará como o ACF dos modelos MA, mas para os modelos AR, a saber, a função de autocorrelação parcial (PACF).
Lembre-se que se \(X\), \(Y\) e \(Z\) forem variáveis aleatórias, então a correlação parcial entre \(X\) e \(Y\), dada por \(Z\), é obtida pela regressão de \(X\) em \(Z\) para obter \(\widehat{X}\), regredindo \(Y\) em \(Z\) para obter \(\widehat{Y}\) e então calculando \begin{equation} \rho_{_{XY|Z}} \, = \, \mbox{Corr}\big(X-\widehat{X},Y-\widehat{Y} \big)\cdot \end{equation}
A idéia é que \(\rho_{_{XY|Z}}\) mede a correlação entre \(X\) e \(Y\) com o efeito linear de \(Z\) removido ou parcialmente excluído. Se as variáveis são multivariadas normais, então esta definição coincide com \begin{equation} \rho_{_{XY|Z}} \, = \, \mbox{Corr}(X,Y|Z)\cdot \end{equation}
Para motivar a ideia para séries temporais, considere um modelo causal \(AR(1)\), \(X_t=\phi X_{t-1}+W_t\). Então, \begin{equation} \begin{array}{rcl} \gamma_{_X}(2) \, = \, \mbox{Cov}(X_t,X_{t-2}) & = & \mbox{Cov}(\phi X_{t-1}+W_t,X_{t-2}) \\ & = & \mbox{Cov}(\phi^2 X_{t-2}+\phi W_{t-1}+W_t, X_{t-2}) \, = \, \phi^2 \gamma_{_X}(0)\cdot \end{array} \end{equation}
Este resultado é decorrente da causalidade, pois \(X_{t-2}\) envolve \(\{W_{t-2},W_{t-3},\cdots\}\) que são todos não correlacionados com \(W_t\) e \(W_{t-1}\). A correlação entre \(X_t\) e \(W_{t-1}\) não é zero, como seria para um \(MA(1)\), porque \(X_t\) é dependente de \(X_{t-2}\) através de \(X_{t-1}\). Suponha que quebremos essa cadeia de dependência removendo ou retirando o efeito de \(X_{t-1}\). Ou seja, consideramos a correlação entre \(X_t-\phi X_{t-1}\) e \(X_{t-2}-\phi X_{t-1}\), porque é a correlação entre \(X_t\) e \(X_{t-2}\) com a dependência linear removida de cada um em \(X_{t-1}\). Desta forma, quebramos a cadeia de dependência entre \(X_t\) e \(X_{t-2}\). De fato, \begin{equation} \mbox{cov}(X_t-\phi X_{t-1},X_{t-2}-\phi X_{t-1}) \, = \, \mbox{Cov}(W_t, X_{t-2}-\phi X_{t-1}) \, = \, 0\cdot \end{equation} Assim, a ferramenta que precisamos é a autocorrelação parcial, que é a correlação entre \(X_s\) e \(X_t\) com o efeito linear de tudo no meio removido.
Para definir formalmente o PACF para séries temporais estacionárias de média zero, seja \(\widehat{X}_{t+h}\), para \(h\geq 2\), denote a regressão de \(X_{t+h}\) em \(\{X_{t+h-1},X_{t+h-2},\cdots,X_{t+1}\}\), que escrevemos como \begin{equation} \widehat{X}_{t+h} \, = \, \beta_1 X_{t+h-1}+\beta_2 X_{t+h-2}+\cdots+\beta_{h-1} X_{t+1}\cdot \end{equation} O termo regressão aqui se refere à regressão no sentido da população. Isso é, \(\widehat{X}_{t+h}\) é a combinação linear de \(\{X_{t+h-1},X_{t+h-2},\cdots,X_{t+1}\}\) que minimiza o erro quadrático médio \begin{equation} \mbox{E}\Big(X_{t+h}-\sum_{j=1}^{h-1} \alpha_j X_{t+j}\Big)^2\cdot \end{equation}
Observe que nenhum termo de intercepto é necessário porque a média de \(X_t\) é zero, caso contrário, substitua \(X_t\) por \(X_t\mu_X\) nesta discussão. Além disso, se \(\widehat{X}_t\) denota a regressão de \(X_t\) em \(\{X_{t+h-1},X_{t+h-2},\cdots,X_{t+1}\}\) então \begin{equation} \widehat{X}_t \, = \, \beta_1 X_{t+1}+\beta_2 X_{t+2}+\cdots+\beta_{h-1} X_{t+h-1}\cdot \end{equation}
Por causa da estacionariedade, os coeficientes, \(\beta_1,\cdots,\beta_{h-1}\) são os mesmos nos modelos de regressão acima. Vamos explicar este resultado na próxima seção, mas será evidente a partir dos exemplos.
A função de autocorrelação parcial (PACF) de um processo estacionário, \(X_t\), denotada por \(\phi_{h,h}\), para \(h=1,2,\cdots\) é \begin{equation} \phi_{1,1} \, = \, \mbox{Corr}(X_{t+1},X_t) \, = \, \rho(1) \end{equation} e \begin{equation} \phi_{h,h} \, = \, \mbox{Corr}\big(X_{t+h}-\widehat{X}_{t+h},X_t-\widehat{X}_t\big), \qquad h\geq 2\cdot \end{equation}
A razão para usar um subscrito duplo ficará evidente na próxima seção. O PACF \(\phi_{h,h}\) é a correlação entre \(X_{t+h}\) e \(X_t\) com a dependência linear de \(\{X_{t+1},\cdots,X_{t+h-1}\}\) em cada, removido. Se o processo \(X_t\) é gaussiano, então \(\phi_{h,h}=\mbox{Corr}(X_{t+h},X_t|X_{t+1},\cdots,X_{t+h-1})\), isto é, \(\phi_{h,h}\) é o coeficiente de correlação entre \(X_{t+h}\) e \(X_t\) na distribuição bivariada de \((X_{t+h},X_t)\) condicional em \(\{X_{t+1},\cdots,X_{t+h-1}\}\).
Exemplo III.15. A PACF para um modelo \(AR(1)\).
Considere a PACF do processo \(AR(1)\) dado por \(X_t=\phi X_{t-1}+W_t\), com \(|\phi|<1\). Por definição, \(\phi_{1,1}=\rho(1)=\phi\). Para calcular \(\phi_{2,2}\), considere a regressão de \(X_{t+2}\) em \(X_{t+1}\), digamos \(\widehat{X}_{t+2}=\beta X_{t+1}\). Escolhemos \(\beta\) minimizando \begin{equation} \mbox{E}\big( X_{t+2}-\widehat{X}_{t+2}\big)^2 \, = \, \mbox{E}\big( X_{t+2}-\beta X_{t+1}\big)^2 \, = \, \gamma(0)-2\beta \gamma(1)+\beta^2\gamma(0)\cdot \end{equation}
Tomando derivadas em relação a \(\beta\) e definindo o resultado igual a zero, temos \(\beta=\gamma(1)/\gamma(0)=\rho(1)=\phi\). Em seguida, considere a regressão de \(X_t\) em \(X_{t+1}\), digamos \(\widehat{X}_t=\beta X_{t+1}\). Escolhemos \(\beta\) minimizando \begin{equation} \mbox{E}\big( X_t-\widehat{X}_t\big)^2 \, = \, \mbox{E}\big( X_{t}-\beta X_{t+1}\big)^2 \, = \, \gamma(0)-2\beta\gamma(1)+\beta^2\gamma(0)\cdot \end{equation} Esta é a mesma equação de antes, então \(\beta=\phi\). Consequentemente, \begin{equation} \begin{array}{rcl} \phi_{2,2} & = & \mbox{Corr}\big(X_{t+2}-\widehat{X}_{t+2},X_t-\widehat{X}_t\big) \, = \, \mbox{Corr}(X_{t+2}-\phi X_{t+1},X_t-\phi X_{t+1}) \\ & = & \mbox{Corr}(W_{t+2}, X_t-\phi X_{t+1}) \, = \, 0, \end{array} \end{equation} por causalidade. Portanto, \(\phi_{2,2}=0\). No próximo exemplo, veremos que neste caso, \(\phi_{h,h}=0\) para todo \(h>1\).
Exemplo III.16. O PACF para um modelo \(AR(p)\).
Este modelo implica que \(X_{t+h}=\sum_{j=1}^p \phi_j X_{t+h-j}+W_{t+h}\), onde as raízes de \(\phi(z)\) estão fora do círculo unitário. Quando \(h>p\), a regressão de \(X_{t+h}\) em \(\{X_{t+1},\cdots,X_{t+h-1}\}\), é \begin{equation} \widehat{X}_{t+h} \, = \, \sum_{j=1}^p \phi_j X_{t+h-j}\cdot \end{equation}
Ainda não provamos este resultado, mas vamos provar isso na próxima seção. Assim, quando \(h>p\), \begin{equation} \phi_{h,h} \, = \, \mbox{Corr}\big( X_{t+h}-\widehat{X}_{t+h}, X_t-\widehat{X}_t\big) \, = \, \mbox{Corr}\big( W_{t+h},X_t-\widehat{X}_t\big) \, = \, 0, \end{equation} porque, pela causalidade, \(X_t-\widehat{X}_t\) depende somente de \(\{W_{t+h-1},W_{t+h-2},\cdots\}\). Quando \(h\leq p\), \(\phi_{h,h}\) é não zero e \(\phi_{1,1},\cdots,\phi_{p-1,p-1}\) não são necessariamente zero. Veremos mais tarde que, de fato, \(\phi_{p,p}=\phi_p\). Mostramos na figura abaixo as funções ACFe PACF para o modelo \(AR(2)\) presente no Exemplo III.11.
Para reproduzir a figura em R, use os seguintes comandos: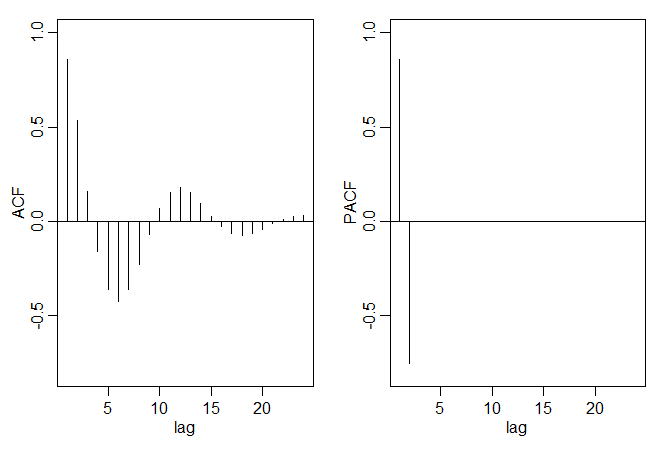 |
|---|
Exemplo III.17. A PACF para um modelo \(MA(q)\) invertível.
Para um modelo \(MA(q)\) invertível, escrevemos \begin{equation} X_t=-\sum_{j=1}^\infty \phi_j X_{t-j}+W_t\cdot \end{equation} Além disso, não existe representação finita. A partir deste resultado, deve ficar claro que o PACF nunca será cortado, como no caso do \(AR(p)\).
Para um \(MA(1)\), \(X_t=W_t+\theta W_{t-1}\), com \(|\theta|< 1\), cálculos semelhantes ao Exemplo III.15 produzirão \begin{equation} \phi_{2,2}=-\frac{\theta^2}{1+\theta^2+\theta^4}\cdot \end{equation} Para o \(MA(1)\) em geral, podemos mostrar que \begin{equation} \phi_{h,h} \, = \, -\frac{(-\theta)^h(1-\theta^2)}{1-\theta^{2(h+1)}}, \qquad h\geq 1\cdot \end{equation}
Na próxima seção, discutiremos métodos de cálculo da função de autocorrelação parcial (PACF). A função de autocorrelação parcial (PACF) para modelos MA se comporta de maneira semelhante ao ACF para modelos AR. Além disso, o PACF para modelos de AR comporta-se muito como o ACF para os modelos MA. Como um modelo ARMA invertível tem uma representação AR infinita, o PACF não será cortado. Podemos resumir esses resultados na tabela a seguir.
| \(AR(p)\) | \(MA(q)\) | \(ARMA(p,q)\) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| \(ACF\) | Caudas fora | Corta fora | Caudas fora | ||||||
| depois lag \(q\) | |||||||||
| \(PACF\) | Corta fora | Caudas fora | Caudas fora | ||||||
| depois lag \(p\) |
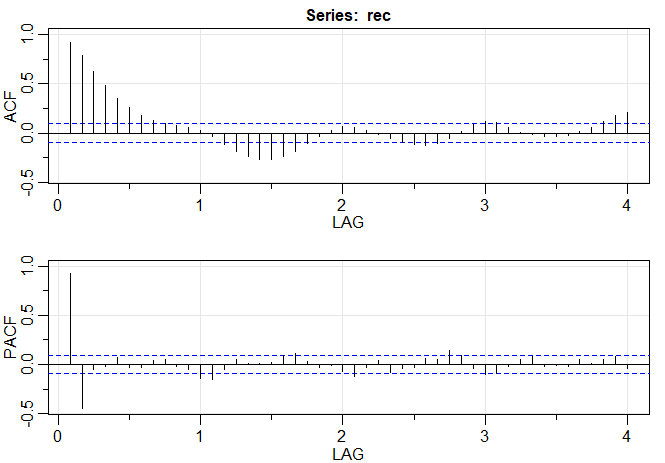
Exemplo III.18. Análise preliminar da série de Recrutamento.
Consideramos o problema de modelagem da série Recrutamento mostrada no Exemplo I.5. Há 453 meses de Recrutamento observado variando ao longo dos anos 1950 a 1987. O ACF e o PACF amostrais, mostrados na figura abaixo, são consistentes com o comportamento de um \(AR(2)\). O ACF tem ciclos correspondendo aproximadamente a um período de 12 meses e o PACF tem valores grandes para \(h = 1,2\) e, em seguida, é essencialmente zero para atrasos ou lag de ordem superior. Com base na Tabela III.1, esses resultados sugerem que um modelo autorregressivo de segunda ordem, ou seja, \(p = 2\) pode fornecer um bom ajuste. Embora discutiremos a estimação em detalhes na Seção III.5, executamos uma regressão usando os trios de dados \(\{(X;Z_1,Z_2) \, : \,(X_3;X_2,X_1),(X_4;X_3,X_2),\cdots,(X_{453};X_{452},X_{451})\}\) para ajustar um modelo da forma \begin{equation} X_t \, = \, \phi_0 +\phi_1 X_{t-1}+\phi_2 X_{t-2} +W_t, \end{equation} para \(t=3,4,\cdots,453\). As estimativas e os erros padrão (entre parênteses) são \(\widehat{\phi}_0=6.74_{(1.11)}\), \(\widehat{\phi}_1=1.35_{(0.04)}\), \(\widehat{\phi}_2=-0.46_{(0.04)}\) e \(\widehat{\sigma}_{_W}^2=89.72\).
 |
|---|
III.4 Previsão
Na previsão, o objetivo é prever valores futuros de uma série temporal \(X_{n+m}\), \(m=1,2,\cdots\) com base nos dados coletados até o presente, \(X_{1:n}=\{X_1,X_2,\cdots,X_n\}\). Ao longo desta seção, assumiremos que \(X_t\) é estacionário e os parâmetros do modelo são conhecidos. O problema de previsão quando os parâmetros do modelo são desconhecidos será discutido na próxima seção. O preditor de erro quadrático médio mínimo de \(X_{n+m}\) é \begin{equation} X_{n+m}^n \, = \, \mbox{E}(X_{n+m} \, | \, X_{1:n}), \end{equation} porque a esperança condicional minimiza o erro quadrático médio \begin{equation} \mbox{E}\big(X_{n+m}-g(X_{1:n}) \big)^2, \end{equation} onde \(g(\cdot)\) é uma função das observações \(X_{1:n}\).
Primeiro, vamos restringir a atenção aos preditores que sejam funções lineares dos dados, ou seja, preditores da forma \begin{equation} X_{n+m}^n \, = \,\alpha_0 +\sum_{k=1}^n \alpha_k X_k, \end{equation} onde \(\alpha_0,\alpha_1,\cdots,\alpha_n\) são números reais. Notamos que os \(\alpha\)'s dependem de \(n\) e \(m\), mas por enquanto abandonamos a dependência da notação. Por exemplo, se \(n = m = 1\), então \(X_2^1\) é a previsão linear de um passo à frente de \(X_2\) dado \(X_1\). Em termos da expressão acima, \(X_2^1=\alpha_0 +\alpha_1 X_1\). Mas se \(n=2\), \(X_3^2\) é a previsão linear de um passo à frente de \(X_3\) dado \(X_1\) e \(X_2\), ou seja, \(X_3^2=\alpha_0+\alpha_1 X_1+\alpha_2 X_2\) e, em geral, os \(\alpha\)'s em \(X_2^1\) e \(X_3^2\) são diferentes.
Os preditores lineares que minimizam o erro quadrático médio são chamados de melhores preditores lineares (BLPs). Como veremos, a previsão linear depende apenas dos momentos de segunda ordem do processo, que são fáceis de estimar a partir dos dados. Grande parte do material desta seção é aprimorada pelo material teórico apresentado no Apêndice B. Por exemplo, o Teorema B.3 afirma que, se o processo for Gaussiano, os preditores de erro quadrático médio mínimo e os melhores preditores lineares serão os mesmos. A seguinte propriedade, baseada no Teorema da Projeção, Teorema B.1, é um resultado chave.
Dados os dados \(X_1,X_2,\cdots,X_n\), o melhor preditor linear \(\displaystyle X_{n+m}^n=\alpha_0+\sum_{k=1}^n \alpha_k X_k\), de \(X_{n+m}\) para \(m\geq 1\), é encontrado resolvendo \begin{equation} \mbox{E}\big( (X_{n+m}-X_{n+m}^n)X_k\big) \, = \, 0, \qquad k=0,1,\cdots,n, \end{equation} onde \(X_0=1\), para \(\alpha_0,\alpha_1,\cdots,\alpha_n\).
As equações especificadas no Teorema III.3 são chamadas de equações de predição e são usadas para resolver os coeficientes \(\{\alpha_0,\alpha_1,\cdots,\alpha_n\}\). Os resultados do Teorema III.3 também podem ser obtidos através de mínimos quadrados; isto é, minimizando \(Q = \mbox{E}(X_{n+m}-\sum_{k=0}^n \alpha_k X_k)^2\) com respeito aos \(\alpha\)'s, resolvendo \(\partial Q/\partial \alpha_j = 0\) para \(\alpha_j\), \(j = 0,1,\cdots,n\). Isso leva ao resultado no Teorema III.3.
Se \(\mbox{E}(X_t)=\mu\), a primeira equação (k=0) na Proposição III.3 implica que \begin{equation} \mbox{E}(X_{n+m}^n) \, = \, \mbox{E}(X_{n+m}) \, = \, \mu\cdot \end{equation} Então, tomando esperança, temos \begin{equation} \mu \, = \, \alpha_0+\sum_{k=1}^n \alpha_k \mu \qquad \mbox{ou} \qquad \alpha_0 \,= \, \mu\Big( 1-\sum_{k=1}^n \alpha_k\Big)\cdot \end{equation} Assim, a forma do BLP é \begin{equation} X_{n+m}^n \, = \, \mu +\sum_{k=1}^n \alpha_k (X_k-\mu)\cdot \end{equation} Assim, até discutirmos a estimação, não há perda de generalidade ao considerar o caso que \(\mu= 0\), em cujo caso, \(\alpha_0 = 0\).
Primeiro, considere a previsão de um passo à frente. Isto é, dado \(\{X_1,\cdots,X_t\}\), desejamos prever o valor da série temporal no próximo ponto de tempo, \(X_{n+1}\). O BLP de \(X_{n+1}\) é da forma \begin{equation} X_{n+1}^n \, = \, \phi_{n,1} X_n+\phi_{n,2}X_{n-1}+\cdots+\phi_{n,n}X_1, \end{equation} onde agora mostramos a dependência dos coeficientes em \(n\); nesse caso \(\alpha_k\) no preditor linear é \(\phi_{n,n+1-k}\) na expressão acima, para \(k=1,\cdots,n\). Utilizando o Teorema III.3, os coeficientes \(\{\phi_{n,1},\phi_{n,2},\cdots,\phi_{n,n}\}\) satisfazem \begin{equation} \displaystyle\mbox{E}\left( \Big( X_{n+1}-\sum_{j=1}^n \phi_{n,j}X_{n+1-j}\Big)X_{n+1-k} \right)\, = \, 0, \qquad k=1,\cdots,n, \end{equation} ou \begin{equation} \sum_{j=1}^n \phi_{n,j}\gamma(k-j) \, = \, \gamma(k), \qquad k=1,2\cdots,n\cdot \end{equation}
As equações de predição acima podem ser escritas em notação matricial como \begin{equation} \Gamma_n \phi_n \, = \, \gamma_n, \end{equation} onde \(\displaystyle\Gamma_n=\{\gamma(k-j)\}_{j,k=1}^n\) é uma matriz \(n\times n\), \(\phi_n=(\phi_{n,1},\cdots,\phi_{n,n})^\top\) é um vetor \(n\times 1\) e \(\gamma_n=(\gamma(1),\cdots,\gamma(n))^\top\) é um vetor \(n\times 1\).
A mariz \(\Gamma_n\) é definida não negativa. Se \(\Gamma_n\) é singular, existem muita soluções mas, pelo Teorema de projeção (Teorema B.1), \(X_{n+1}^n\) é única. Se \(\Gamma_n\) é não singular, os elementos de \(\phi_n\) são únicos e dados por \begin{equation} \phi_n \, = \, \Gamma_n^{-1}\gamma_n\cdot \end{equation}
Para os modelos \(ARMA\), o fato de \(\sigma_{_W}^2>0\) e \(\lim_{h\to\infty}\gamma(h)=0\) é o suficiente para garantir que \(\Gamma_n\) seja definido positivo. Às vezes é conveniente escrever a previsão de um passo à frente na notação vetorial \begin{equation} X_{n+m}^n \, = \, \phi_n^\top X, \end{equation} onde \(X=(X_n,X_{n-1},\cdots,X_1)^\top\).
O erro médio de previsão quadrado de um passo à frente é \begin{equation} P_{n+1}^n \, = \, \mbox{E}\big(X_{n+1}-X_{n+1}^n \big)^2 \, = \, \gamma(0)-\gamma_n^\top \Gamma_n^{-1}\gamma_n\cdot \end{equation} Para verifiarmos a expressão acima, vemos que \begin{equation} \begin{array}{rcl} \mbox{E}\big(X_{n+1}-X_{n+1}^n \big)^2 & = & \mbox{E}\big(X_{n+1}-\phi_n^\top X \big)^2 \, = \, \mbox{E}\big(X_{n+1}-\gamma_n^\top \Gamma_n^{-1}X \big)^2 \\ & = & \mbox{E}\big(X_{n+1}^2-2\gamma_n^\top \Gamma_n^{-1}X X_{n+1}+\gamma_n^\top\Gamma_n^{-1}X X^\top \Gamma_n^{-1}\gamma_n \big) \\ & = & \gamma(0)-2\gamma_n^\top \Gamma_n^{-1}\gamma_n+\gamma_n^\top \Gamma_n^{-1}\Gamma_n\Gamma_n^{-1}\gamma_n \\ & = & \gamma(0)-\gamma_n^\top \Gamma_n^{-1}\gamma_n\cdot \end{array} \end{equation}
Exemplo III.19. Previsão para o modelo \(AR(2)\).
Suponhamos o processo \(AR(2)\) causal, \(X_t=\phi_1 X_{t-1}+\phi_2 X_{t-2} +W_t\) e uma observação \(X_t\). Então, usando \(\phi_n \, = \, \Gamma_n^{-1}\gamma_n\), a previsão um passo à frente de \(X_2\) baseada em \(X_1\) é \begin{equation} X_2^1 \, = \, \phi_{1,1}X_1 \, = \, \frac{\gamma(1)}{\gamma(0)}X_1 \, = \, \rho(1)X_1\cdot \end{equation}
Agora, suponha que queremos a previsão de \(X_3\) com um passo à frente com base em duas observações \(X_1\) e \(X_2\), ou seja, \(X_3^2 \, = \, \phi_{2,1}X_2 +\phi_{2,2} X_1\). Poderíamos usar que \(\sum_{j=1}^n \phi_{n,j}\gamma(k-j) \, = \, \gamma(k)\), para \(k=1,2\cdots,n\), \begin{equation} \begin{array}{rcl} \psi_{2,1}\gamma(0)+\phi_{2,2}\gamma(1) & = & \gamma(1) \\ \phi_{2,1}\gamma(1)+\phi_{2,2}\gamma(0) & = & \gamma(2), \end{array} \end{equation} para resolver por \(\phi_{2,1}\) e \(\phi_{2,2}\) ou utilizando a forma matricial e resolver \begin{equation} \begin{pmatrix} \phi_{2,1} \\ \phi_{2,2}\end{pmatrix} \, = \, \begin{pmatrix} \gamma(0) & \gamma(1) \\ \gamma(1) & \gamma(0)\end{pmatrix}^{-1} \begin{pmatrix} \gamma(1) \\ \gamma(2) \end{pmatrix}, \end{equation} mas, deve ser aparente do modelo que \(X_3^2 = \phi_1 X_2+\phi_2 X_1\). Devido a que \(\phi_1 X_2+\phi_2 X_1\) satisfaz as equações de predição no Teorema III.3, \begin{equation} \begin{array}{rcl} \mbox{E}\left( \big( X_3-(\phi_1 X_2+\phi_2 X_1)\big)X_1\right) & = & \mbox{E}(W_3 X_1) \, = \, 0, \\ \mbox{E}\left( \big( X_3-(\phi_1 X_2+\phi_2 X_1)\big)X_2\right) & = & \mbox{E}(W_3 X_2) \, = \, 0, \end{array} \end{equation} segue-se que, de fato, \(X_3^2 = \phi_1 X_2+\phi_2 X_1\) e pela unicidade dos coeficientes, neste caso, \(\phi_{2,1}=\phi_1\) e \(\phi_{2,2}=\phi_2\). Continuando desta forma, verificamos que, para \(n\geq 2\), \begin{equation} X_{n+1}^n \, = \, \phi_1 X_n+\phi_2 X_{n-1}\cdot \end{equation} Isto é, \(\phi_{n,1}=\phi_1\), \(\phi_{n,2}=\phi_2\) e \(\phi_{n;j}=0\), para \(j=3,4,\cdots,n\).
A partir do Exemplo III.19, deve ficar claro que, se a série temporal é um processo causal \(AR(p)\), então, para \(n\geq p\), \begin{equation} X_{n+1}^n \, = \, \phi_1 X_n+\phi_2 X_{n-1}+\cdots+\phi_p X_{n-p+1}\cdot \end{equation} Para os modelos ARMA em geral, as equações de predição não serão tão simples quanto o caso AR puro. Além disso, para \(n\) grande, o uso de sistemas de equações é proibitivo porque requer a inversão de uma matriz grande. Existem, no entanto, soluções iterativas que não exigem nenhuma inversão de matrizes. Em particular, mencionamos a solução recursiva devido a Levinson (1947) e Durbin (1960).
As equações \(\phi_n = \Gamma_n^{-1}\gamma_n\) e \(P_{n+1}^n = \mbox{E}\big(X_{n+1}-X_{n+1}^n \big)^2 \, = \, \gamma(0)-\gamma_n^\top \Gamma_n^{-1}\gamma_n\) podem ser resolvidas iterativamente como segue: \begin{equation} \phi_{0,0} \, = \, 0, \qquad P_1^0 \, = \, \gamma(0)\cdot \end{equation} Para \(n\geq 1\), \begin{equation} \phi_{n,n} \, = \, \frac{\displaystyle \rho(n)-\sum_{k=1}^{n-1} \phi_{n-1,k}\, \rho(n-k)} {\displaystyle 1-\sum_{k=1}^{n-1} \phi_{n-1,k}\, \rho(k)}, \qquad P_{n+1}^n \, = \, P_{n}^{n-1}(1-\phi_{n,n}^2), \end{equation} onde, para \(n\geq 2\) \begin{equation} \phi_{n,k} \, = \, \phi_{n-1,k} -\phi_{n,n}\phi_{n-1,n-k}, \qquad k=1,2,\cdots,n-1\cdot \end{equation}
Exemplo III.20. Utilizando o algoritmo de Durbin-Levinson.
Para usar o algoritmo, começamos com \(\phi_{0,0}=0\), \(P_1^0=\gamma(0)\). Então, para \(n=1\) \begin{equation} \phi_{1,1}=\rho(1), \qquad P_2^1=\gamma(0)\big( 1-\phi_{1,1}^2\big)\cdot \end{equation}
Para \(n=2\), \begin{equation} \begin{array}{c} \phi_{2,2} \, = \, \dfrac{\rho(2)-\phi_{1,1}\rho(1)}{1-\phi_{1,1}\rho(1)}, \qquad \phi_{2,1} \, = \, \phi_{1,1} -\phi_{2,2}\phi_{1,1}, \\ P_3^2 \, = \, P_2^1\big(1-\phi_{2,2}^2\big) \, = \, \gamma(0)\big(1-\phi_{1,1}^2\big)\big(1-\phi_{2,2}^2\big)\cdot \end{array} \end{equation}
Para \(n=3\), \begin{equation} \begin{array}{c} \phi_{3,3} \, = \, \dfrac{\rho(3)-\phi_{2,1}\rho(2)-\phi_{2,2}\rho(1)}{1-\phi_{2,1}\rho(1)-\phi_{2,2}\rho(2)}, \qquad \phi_{3,2} \, = \, \phi_{2,2} -\phi_{3,3}\phi_{2,1}, \qquad \phi_{3,1} \, = \, \phi_{2,1}-\phi_{3,3}\phi_{2,2},\\ P_4^3 \, = \, P_3^2\big(1-\phi_{3,3}^2\big) \, = \, \gamma(0)\big(1-\phi_{1,1}^2\big)\big(1-\phi_{2,2}^2\big)\big(1-\phi_{3,3}^2\big) \end{array} \end{equation} e assim por diante. Observe que, em geral, o erro padrão da previsão de um passo à frente é a raiz quadrada de \begin{equation} P_{n+1}^n \, = \, \gamma(0)\prod_{j=1}^n \big( 1-\phi_{j,j}^2\big)\cdot \end{equation}
Uma consequência importante do algoritmo de Durbin-Levinson é o resultado segue.
O PACF de um processo estacionário \(X_t\), pode ser obtido iterativamente via o Teorema III.4 como \(\phi_{n,n}\), para \(n=1,2,\cdots\).
Usando o Teorema III.5 e colocando \(n = p\), segue que para um modelo \(AR(p)\), \begin{equation} \begin{array}{rcl} X_{p+1}^p & = & \phi_{p,1} X_p + \phi_{p,2} X_{p-1}+\cdots+\phi_{p,p}X_ 1\\ & = & \phi_1 X_p + \phi_2 X_{p-1}+\cdots+ \phi_p X_1\cdot \end{array} \end{equation} O resultado acima mostra que, para um modelo \(AR(p)\), o coeficiente de autocorrelação parcial na defasagem \(p\), \(\phi_{p,p}\), também é o último coeficiente no modelo, \(\phi_p\), como foi reivindicado no Exemplo III.16.
Exemplo III.21. O PACF de um modelo \(AR(2)\).
Utilizaremos o resultado do Exemplo III.20 e do Teorema III.5 para calcular os três primeiros valores \(\phi_{1,1}\), \(\phi_{2,2}\) e \(\phi_{3,3}\) do PACF. Lembremos do Exemplo III.10 e \(\rho(h)-\phi_1 \rho(h-1)-\phi_2\rho(h-2)=0\) para \(h\geq 1\). Quando \(h=1,2,3\), temos que \(\rho(1)=\phi_1/(1-\phi_2)\), \(\rho(2)=\phi_1\rho(1)+\phi_2\), \(\rho(3)-\phi_1\rho(2)-\phi_2\rho(1)=0\). Portanto, \begin{equation} \begin{array}{rcl} \phi_{1,1} & = & \rho(1) \, = \, \displaystyle\frac{\phi_1}{1-\phi_2}, \\ \phi_{2,2} & = & \displaystyle\frac{\rho(2)-\rho(1)^2}{1-\rho(1)^2} \, = \, \frac{\displaystyle\left( \phi_1\Big(\frac{\phi_1}{1-\phi_2}\Big)^2+\phi_2\right)-\Big(\frac{\phi_1}{1-\phi_2}\Big)^2}{\displaystyle1-\Big(\frac{\phi_1}{1-\phi_2}\Big)^2} \, = \, \phi_2, \\ \phi_{2,1} & = & \rho(1)\big( 1-\phi_2\big) \, = \, \phi_1, \\ \phi_{3,3} & = & \frac{\displaystyle\rho(3)-\phi_1\rho(2)-\phi_2\rho(1)}{\displaystyle 1-\phi_1\rho(1)-\phi_2\rho(2)} \, = \, 0\cdot \end{array} \end{equation}
Observe que, como mostrado, \(\phi_{2,2} = \phi_2\) para um modelo \(AR(2)\).Até agora, nos concentramos na previsão de um passo à frente, mas o Teorema III.3 nos permite calcular o melhor preditor linear de \(X_{n+m}\) para qualquer \(m\geq 1\). Fornecidos os dados \(\{X_1,\cdots,X_n\}\), o preditor \(m\)-passos-à-frente é \begin{equation} X_{n+m}^n \, = \, \phi_{n,1}^{(m)}X_n + \phi_{n,2}^{(m)}X_n+\cdots+\phi_{n,n}^{(m)}X_1, \end{equation} onde \(\{ \phi_{n,1}^{(m)},\phi_{n,2}^{(m)},\cdots,\cdots,\phi_{n,n}^{(m)}\}\) satisfaz as equações de predição \begin{equation} \sum_{j=1}^n \phi_{n,j}^{(m)} \mbox{E}(X_{n+1-j}X_{n+1-k}) \, =\, \mbox{E}(X_{n+m}X_{n+1-k}), \qquad k=1,\cdots,n, \end{equation} ou \begin{equation} \sum_{j=1}^n \phi_{n,j}^{(m)} \gamma(k-j) \, =\, \gamma(m+k-1), \qquad k=1,\cdots,n\cdot \end{equation}
As equações de predição podem ser novamente escritas em notação matricial como \begin{equation} \Gamma_n\phi_n^{(m)} \, = \, \gamma_n^{(m)}, \end{equation} onde \(\gamma_n^{(m)}=(\gamma(m),\cdots,\gamma(m+n-1))^\top\) e \(\phi_n^{(m)}=(\phi_{n,1}^{(m)},\cdots,\phi_{n,n}^{(m)})^\top\) são vetores \(n\times 1\). O erro médio de predição \(m\) passos à frente é \begin{equation} P_{n+m}^n \, = \, \mbox{E}\big(X_{n+m}-X_{n+m}^n\big)^2 \, = \, \gamma(0)-\gamma_n^{(m)\top} \Gamma_n^{-1}\gamma_n^{(m)}\cdot \end{equation}
Outro algoritmo útil para calcular previsões foi dado por Brockwell e Davis (1991). Esse algoritmo segue diretamente da aplicação do teorema da projeção (Teorema B.1) às inovações, \(X_t-X_t^{t-1}\), para \(t = 1,\cdots,n\), usando o fato de que as inovações\(X_t-X_t^{t-1}\) e \(X_s-X_s^{s-1}\) não são correlacionadas para \(s\neq t\). Apresentamos o caso em que \(X_t\) é uma série temporal estacionária de média zero.
Os preditores de um passo à frente \(X_{t+1}^t\) e seus erros quadráticos médios \(P_{t+1}^t\), podem ser calculados iterativamente como \begin{equation} X_1^0 \, = \, 0, \qquad P_1^0 \, = \, \gamma(0), \end{equation} \begin{equation} X_{t+1}^t \, = \, \sum_{j=1}^t \theta_{t,j}\big( X_{t+1-j}-X_{t+1-j}^{t-j}\big), \qquad t=1,2,\cdots \end{equation} e \begin{equation} P_{t+1}^t \, = \, \gamma(0)-\sum_{j=0}^{t-1} \theta_{t,t-j}^2 P_{j+1}^{j}, \qquad t=1,2,\cdots, \end{equation} onde, para \(j=0,1,\cdots,t-1\), \begin{equation} \theta_{t,t-j} \, = \, \frac{\displaystyle \gamma(t-j)-\sum_{k=0}^{j-1} \theta_{j,j-k}\theta_{t,t-k}P_{k+1}^k}{P_{j+1}^j}\cdot \end{equation}
Dados \(X_1,\cdots,X_n\), o algoritmo de inovações pode ser calculado sucessivamente para \(t = 1\), então \(t = 2\) e assim por diante, caso em que o cálculo de \(X_{n+1}^n\) e \(P_{n+1}^n\) é feito na etapa final \(t = n\). O preditor de \(m\) passos à frente e seu erro quadrático médio baseado no algoritmo de inovações são dados por \begin{equation} X_{n+m}^n \, = \, \sum_{j=m}^{n+m-1} \theta_{n+m-1,j} \big( X_{n+m-j}-X_{n+m-j}^{n+m-j-1}\big) \end{equation} e \begin{equation} P_{n+m}^n \, = \, \gamma(0)-\sum_{j=m}^{n+m-1} \theta_{n+m-1,j}^2 P_{n+m-j}^{n+m-j-1}, \end{equation} onde os \(\theta_{n+m-1,j}\) são obtidos por iteração continuada.
Exemplo III.22. Predição para o \(MA(1)\).
O algoritmo de inovações presta-se bem à previsão de processos médios móveis. Considere um modelo \(MA(1)\), \(X_t=W_t+\theta W_{t-1}\). Lembre-se de que, \(\gamma(0)=(1+\theta^2)\sigma_{_W}^2\), \(\gamma(1)=\theta\sigma_{_W}^2\) e \(\gamma(h)=0\), para \(h\geq 0\). Então, usando a Proposição III.6, temos \begin{equation} \begin{array}{rcl} \theta_{n,1} & = & \displaystyle\frac{\displaystyle\theta\sigma_{_W}^2}{\displaystyle P_{n}^{n-1}}, \\ \theta_{n,j} & = & 0, \qquad j=2,\cdots,n, \\ P_1^0 & = & (1+\theta^2)\sigma_{_W}^2, \\ P_{n+1}^n & = & (1+\theta^2-\theta\theta_{n,1})\sigma_{_W}^2\cdot \end{array} \end{equation}
Finalmente, o preditor um passo à frente é \begin{equation} X_{n+1}^n \, = \, \frac{\displaystyle \theta\big( X_n-X_{n}^{n-1}\big)\sigma_{_W}^2}{\displaystyle P_{n}^{n-1}}\cdot \end{equation}
Previsão de processos ARMA
As equações gerais de predição fornecem pouca informação sobre previsão para modelos ARMA em geral. Existem várias maneiras diferentes de expressar essas previsões e cada uma delas ajuda a entender a estrutura especial da predição do ARMA.
Ao longo do tempo, assumimos que \(X_t\) é um processo causal e inversível \(ARMA(p,q)\), \(\phi(B)X_t=\theta(B)W_t\), onde \(W_t\sim N(0,\sigma_{_W}^2)\) independentes. No caso de média não zero \(\mbox{E}(X_t)=\mu_t\), simplesmente substitua \(X_t\) com \(X_t-\mu_t\) no modelo. Primeiro, consideramos dois tipos de previsões. Escrevemos \(X_{n+m}^n\) para significar o preditor de erro quadrático médio mínimo de \(X_{n+m}\) com base nos dados \(\{X_n,\cdots,X_1\}\), isto é, \begin{equation} X_{n+m}^n \, = \, \mbox{E}(X_{n+m}|X_n,\cdots,X_1)\cdot \end{equation}
Para modelos ARMA, é mais fácil calcular o preditor de \(X_{n+m}\) assumindo que temos a história completa do processo \(\{X_n,X_{n-1},\cdots,X_1,X_0,X_{-1},\cdots\}\). Vamos denotar o preditor de \(X_{n+m}\) com base no passado infinito como \begin{equation} \widetilde{X}_{n+m}^n \, = \, \mbox{E}(X_{n+m} \, | \, X_n,X_{n-1},\cdots,X_1,X_0,X_{-1},\cdots)\cdot \end{equation}
Em geral, \(X_{n+m}^n\) e \(\widetilde{X}_{n+m}^n\) não são iguais, mas a ideia aqui é que, para grandes amostras, \(\widetilde{X}_{n+m}^n\) proporcionará uma boa aproximação para \(X_{n+m}^n\).
Agora, vamoes escrever \(X_{n+m}\) em suas formas causal \begin{equation} X_{n+m} \, = \, \sum_{j=0}^\infty \psi_j W_{n+m-j}, \qquad \psi_0 = 1, \end{equation} e invertível \begin{equation} W_{n+m} \, = \, \sum_{j=0}^\infty \pi_j X_{n+m-j}, \qquad \pi_0 = 1\cdot \end{equation} Então, tomando esperança condicionais na forma causal, temos \begin{equation} \widetilde{X}_{n+m} \, = \, \sum_{j=0}^\infty \psi_j \widetilde{W}_{n+m-j} \, = \, \sum_{j=m}^\infty \psi_j W_{n+m-j}, \end{equation} porque, por causalidade e invertibilidade, \begin{equation} \widetilde{W}_j \, = \, \mbox{E}(W_t|X_n,X_{n-1},\cdots,X_0,X_{-1},\cdots) \, = \, \left\{ \begin{array}{cl} 0, & t>n \\ W_t, & t\leq n \end{array}\right.\cdot \end{equation} Da mesma forma, tendo esperanças condicionais na forma invertível, temos \begin{equation} 0 \, = \, \widetilde{X}_{n+m}+\sum_{j=1}^\infty \pi_j\widetilde{X}_{n+m-j}, \end{equation} ou \begin{equation} \widetilde{X}_{n+m} \, = \, -\sum_{j=1}^{m-1} \pi_j\widetilde{X}_{n+m-j}-\sum_{j=m}^\infty \pi_j X_{n+m-j}, \end{equation} usando o fato \(\mbox{E}(X_t|X_n,X_{n-1},\cdots,X_0,X_{-1},\cdots)=X_t\), para \(t\leq n\). A previsão é realizada recursivamente usando a expressão anterior, começando com o preditor de um passo à frente, \(m = 1\), e continuando para \(m = 2,3,\cdots\). Utilizando a expressão que \(\displaystyle\widetilde{X}_{n+m} = \sum_{j=m}^\infty \psi_j W_{n+m-j},\), podemos escrever \begin{equation} X_{n+m}-\widetilde{X}_{n+m} \, = \, \sum_{j=0}^{m-1} \psi_j W_{n+m-j}, \end{equation} então o erro de predição quadrático médio pode ser escrito como \begin{equation} P_{n+m}^n \, = \, \mbox{E}\big(X_{n+m}-\widetilde{X}_{n+m} \big)^2 \, = \, \sigma_{_W}^2\sum_{j=0}^{m-1} \psi_j^2\cdot \end{equation} Além disso, notamos que, para um tamanho de amostra fixo \(n\), os erros de previsão são correlacionados. Isto é, \begin{equation} \mbox{E}\Big(\big(X_{n+m}-\widetilde{X}_{n+m} \big)\big(X_{n+m+k}-\widetilde{X}_{n+m+k} \big) \Big) \, = \, \sigma_{_W}^2\sum_{j=0}^{m-1}\psi_j\psi_{j+k}\cdot \end{equation}
Exemplo III.23. Previsões de longo alcance.
Considere prever o processo ARMA com a média \(\mu_X\). Substituindo \(X_{n+m}\) por \(X_{n+m}-\mu_X\) e considerando a esperança condicional, deduzimos que a previsão \(m\)-passos à frente pode ser escrita como \begin{equation} \widetilde{X}_{n+m} \, = \, \mu_X+\sum_{j=m}^\infty \psi_j W_{n+m-j}\cdot \end{equation} Observando que os \(\psi\)-pesos diminuem exponencialmente rápido, é claro que \(\widetilde{X}_{n+m}\to\mu_X\) exponencialmente rápido, no sentido quadrado médio, quando \(m\to\infty\). Além disso, o erro quadrático médio de predição \begin{equation} P_{n+m}^n \, \to \, \sigma_{_W}^2\sum_{j=0}^\infty \psi_j^2 \, = \, \gamma_{_X}(0) \, = \, \sigma_{_W}^2, \end{equation} exponencialmente rápido quando \(m\to\infty\).
Deve ficar claro que as previsões do ARMA se ajustam rapidamente à média com um erro de previsão constante à medida que o horizonte de previsão, \(m\), cresce. Esse efeito pode ser visto na figura do Exemplo III.25, onde a série Recrutamento está prevista para 24 meses.
Quando \(n\) é pequeno, as equações gerais de predição podem ser usadas facilmente. Quando \(n\) é grande, usaríamos \begin{equation} \widetilde{X}_{n+m} \, = \, -\sum_{j=1}^{m-1} \pi_j\widetilde{X}_{n+m-j}-\sum_{j=m}^\infty \pi_j X_{n+m-j}, \end{equation} truncando, porque não observamos \(X_0,X_{-1},X_{-2},\cdots\) e somente os dados \(X_1,X_2,\cdots,X_n\) estáo disponíveis. Nesse caso, podemos truncar definindo \(\sum_{j=n+m}^\infty \pi_j X_{n+m-j}=0\). O preditor truncado é então escrito como \begin{equation} \widetilde{X}_{n+m}^n \, = \, -\sum_{j=1}^{m-1} \pi_j\widetilde{X}_{n+m-j}^n-\sum_{j=m}^{n+m-1} \pi_j X_{n+m-j}, \end{equation} que também é calculado recursivamente, \(m = 1,2,\cdots\). O erro quadrático médio de predição, neste caso, é aproximado.
Para modelos \(AR(p)\), e quando \(n> p\), produzimos o preditor exato \(X_{n+m}^n\) de \(X_{n+m}\), e não há necessidade de aproximações. Ou seja, para \(n> p\), \(\widetilde{X}_{n+m}^n = \widetilde{X}_{n+m} = X_{n+m}^n\). Também, neste caso, o erro de predição de um passo à frente é \(\mbox{E}\big(X_{n+1}-X_{n+1}^n \big)^2=\sigma_{_W}^2\). Para modelos \(MA(q)\) ou \(ARMA(p,q)\) puros, a previsão truncada tem uma forma razoavelmente boa.
Para modelos \(ARMA(p,q)\), os preditores truncados para \(m=1,2,\cdots\) são \begin{equation} \widetilde{X}_{t+1}^n \, = \, \phi_1 \widetilde{X}_{n+m-1}^n+\cdots+\phi_p \widetilde{X}_{n+m-p}^n+\theta_1 \widetilde{W}_{n+m-1}^n + \cdots+\theta_q \widetilde{W}_{n+m-q}^n, \end{equation} onde \(\widetilde{X}_t^n=X_t\), para \(1\leq t\leq n\) e \(\widetilde{X}_t^n=0\) para \(t\leq 0\). Os erros de previsãão truncados são dados por \(\widetilde{W}_t^n=0\) para \(t\leq 0\) ou \(t>n\) e \begin{equation} \widetilde{W}_t^n \, = \, \phi(B)\widetilde{X}_t^n-\theta_1\widetilde{W}_{t-1}^n -\cdots -\theta_q \widetilde{W}_{t-q}^n, \end{equation} para \(1\leq t\leq n\).
Exemplo III.24. Previsões de uma série \(ARMA(1,1)\).
Dados dados \(X_1,\cdots,X_n\), para fins de previsão, escrevamos o modelo como \begin{equation} X_{n+1} \, = \, \phi X_n +W_{n+1}+\theta W_n\cdot \end{equation} Então, a previsão truncada de um passo à frente é \begin{equation} \widetilde{X}_{n+1}^n \, = \, \phi X_n +0+\theta \widetilde{W}_n^n\cdot \end{equation}
Para \(m\geq 2\), temos \begin{equation} \widetilde{X}_{n+m}^n \, = \, \phi \widetilde{X}_{n+m-1}^n, \end{equation} que pode ser calculado recursivamente, \(m = 2,3,\cdots\).
Para calcular \(\widetilde{W}_n^n\), que é necessário para inicializar as previsões sucessivas, o modelo pode ser escrito como \(W_t = X_t-\phi X_{t-1}-\theta W_{t-1}\) para \(t = 1,\cdots,n\). Para previsão truncada, assumimos \(\widetilde{W}_0^n = 0\), \(X_0 = 0\) e, em seguida, iterar os erros para frente no tempo \begin{equation} \widetilde{W}_t^n \, = \, X_t-\phi X_{t-1}-\theta\widetilde{W}_{t-1}^n, \qquad t=1,\cdots,n\cdot \end{equation}
A variância da previsão aproximada é calculada usando os \(\psi\)-pesos determinados como no Exemplo III.12. Em particular, os \(\psi\)-pesos satisfazem \(\psi_j = (\phi+\theta)\phi^{j-1}\), para \(j\geq 1\). Este resultado dá \begin{equation} P_{n+m}^n \, = \, \sigma_{_W}^2\left( 1+(\phi+\theta)^2\displaystyle\sum_{j=1}^{m-1} \phi^{2(j-1)}\right) \, = \, \sigma_{_W}^2\left( 1+\frac{\displaystyle (\phi+\theta)^2\big(1-\phi^{2(m-1)}\big)}{\displaystyle 1-\phi^2}\right)\cdot \end{equation}
Para avaliar a precisão das previsões, os intervalos de previsão são normalmente calculados junto com as previsões. Em geral, os intervalos de previsão com probabilidade de cobertura \(1-\alpha\), são da forma \begin{equation} X_{n+m}^n \pm c_{\alpha/2}\sqrt{P_{n+m}^n}, \end{equation} onde \(c_{\alpha/2}\) é escolhido para obter o grau de confiança desejado. Por exemplo, se o processo for gaussiano, escolher \(c_{\alpha/2} = 2\) produz um intervalo de previsão de aproximadamente 95% para \(X_{n+m}\). Se o interesse é envolver os intervalos de previsão para o longo de um período de tempo, então ele deve ser convenientemente ajustado, por exemplo, usando a desigualdade de Bonferroni (ver Johnson and Wichern, 1992, Capítulo 5).
Exemplo III.25. Previsões da série de Recrutamento.
Usando as estimativas dos parâmetros como os valores reais dos parâmetros, a figura abaixo mostra o resultado da previsão da série de Recrutamentos fornecida no Exemplo III.18 em um horizonte de 24 meses, \(m = 1,2,\cdots,24\). As previsões reais são calculadas como \begin{equation} X_{n+m}^n \, = \, 6.74+1.35 X_{n+m-1}^n -0.46 X_{n+m-2}^n, \end{equation} para \(n=453\) e \(m=1,2,\cdots,12\). Recordemos que \(X_t^s=X_t\) quando \(t\leq s\). Os erros de previsão \(P_{n+m}^n\) são calculados usando \(P_{n+m}^n = \sigma_{_W}^2\sum_{j=0}^{m-1} \psi_j^2\). Encontramos que \(\widehat{\sigma}_W^2=89.72\) e do Exemplo III.12, temos que \begin{equation} \psi_j \,= \, 1.35\psi_{j-1}-0.46 \psi_{j-2} \end{equation} para \(j\geq 2\), onde \(j\geq 2\) sendo \(\psi_0=1\) e \(\psi_1=1.35\). Portanto, para \(n=453\), \begin{equation} \begin{array}{rcl} P_{n+1}^n & = & 89.72, \\ P_{n+2}^n & = & 89.72(1+1.35^2), \\ P_{n+3}^3 & = & 89.72\big(1+1.35^2+(1.35^2-0.46^2)\big), \end{array} \end{equation} e assim por diante.
Observe como a previsão se estabiliza rapidamente e os intervalos de previsão são amplos, embora neste caso os limites de previsão sejam baseados apenas em um erro padrão; isto é, \(X_{n+m}^n\pm \sqrt{P_{n+m}^n}\).
Para reproduzir a análise e a figura, use os seguintes comandos: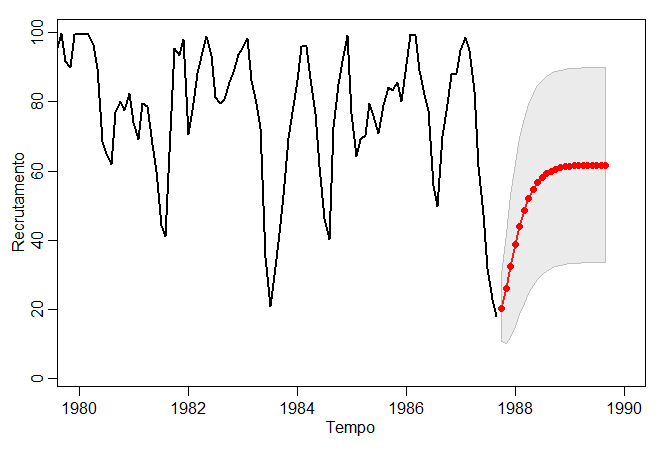 |
|---|
Completamos esta seção com uma breve discussão sobre previsão reversa (backcasting). Na previsão reversa, queremos prever \(X_{1-m}\), para \(m = 1,2,\cdots\), com base nos dados \(\{X_1,\cdots,X_n\}\). Escreva a previsão reversa como \begin{equation} X_{1-m}^n \, = \, \sum_{j=1}^n \alpha_j X_j\cdot \end{equation}
De maneira anâloga, as equações de previção reversa, assumindo \(\mu_X=0\), são \begin{equation} \sum_{j=1}^n \alpha_j \mbox{E}(X_j X_k) \, = \, \mbox{E}(X_{1-m} X_k), \qquad k=1,\cdots,n, \end{equation} ou \begin{equation} \sum_{j=1}^n \alpha_j \gamma(k-j) \, = \, \gamma(m+k-1), \qquad k=1,\cdots,n\cdot \end{equation}
Essas equações são precisamente as equações de previção para a previsão direta. Isto é \(\alpha_j=\phi_{n,j}^{(m)}\), para \(j=1,\cdots,n\), onde \(\phi_{n,j}^{(m)}\) foram dadas anteriormente. Finalmente, os backcasts são dados por \begin{equation} X_{1-m}^n \, = \, \phi_{n,1}^{(m)}X_1+\cdots+\phi_{n,n}^{(m)}X_n, \qquad m=1,2,\cdots\cdot \end{equation}
Exemplo III.26. Previsão reversa no modelo \(ARMA(1,1)\).
Considere um processo \(ARMA(1,1)\), \(X_t = \phi X_{t-1} + \theta W_{t-1} + W_t\). Vamos chamar isso de modelo de encaminhamento. Acabamos de ver que a melhor previsão linear para trás no tempo é a mesma que a melhor previsão linear para frente no tempo para modelos estacionários. Assumindo que os modelos são gaussianos, também temos que o erro quadrático médio mínimo da previsão para trás no tempo é a mesma do modelo anterior para modelos ARMA. Lembremos que no caso gaussiano estacionário, (a) a distribuição de \(\{X_{n+1},X_n,\cdots,X_1\}\) é a mesma que (b) a distribuição de \(\{X_0,X_1,\cdots,X_n\}\). Na previsão usamos (a) para obter \(\mbox{E}(X_{n+1}|X_n,\cdots,X_1)\), em backcasting ou previsão reversa usamos (b) para obter \(\mbox{E}(X_0|X_1,\cdots,X_n)\). Porque (a) e (b) são os mesmos, os dois problemas são equivalentes.
Assim, o processo pode ser gerado de forma equivalente pelo modelo backward ou de encaminhamento, \begin{equation} X_t \, = \, \phi X_{t+1}+\theta V_{t+1}+V_t, \end{equation} onde \(\{V_t\}\) é um processo de ruído branco gaussiano com variância \(\sigma_{_W}^2\). Podemos escrever \(X_t=\sum_{j=0}^\infty \psi_j V_{t+j}\), onde \(\psi_0=1\). Isto significa que \(X_t\) são não correlacionados com \(\{V_{-1},V_{t-2},\cdots\}\), em analogia ao modelo para a frente.
Dados dados \(\{X_1,\cdots,X_n\}\), truncado \(V_n^n = \mbox{E}(V_n|X_1,\cdots,X_n)\) para zero e depois iterar para trás. Ou seja, coloque \(\widetilde{V}_n^n = 0\) como uma aproximação inicial e, em seguida, gere os erros para trás \begin{equation} \widetilde{V}_t^n \, = \, X_t-\phi X_{t+1}-\theta \widetilde{V}_{t+1}^n, \qquad t=n-1,n-2,\cdots,1\cdot \end{equation} Então \begin{equation} \widetilde{X}_0^n \, = \, \phi X_1+\theta\widetilde{V}_1^n+\widetilde{V}_0^n \, = \, \phi X_1+\theta \widetilde{V}_1^n, \end{equation} porque \(\widetilde{V}_t^n=0\) para \(t\leq 0\). Continuando, os backcasts gerais truncados são dados por \begin{equation} \widetilde{X}_{1-m}^n \, = \, \phi \widetilde{X}_{2-m}^n, \qquad m=2,3,\cdots\cdot \end{equation}
Para fazer backcast de dados em R, basta inverter os dados, ajustar o modelo e prever. A seguir, fizemos backcast de um processo \(ARMA(1,1)\) simulado; veja a figura abaixo.
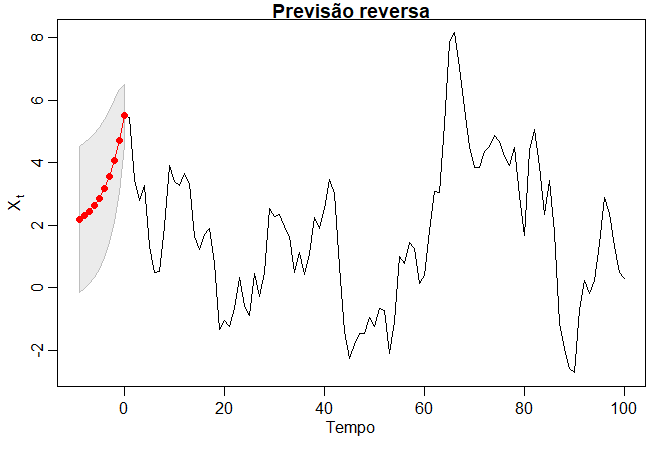 |
|---|
III.5 Estimação
Ao longo desta seção, assumimos que temos \(n\) observações, \(X_1,\cdots,X_n\), a partir de um processo \(ARMA(p,q)\) gaussiano causal e invertível, no qual, inicialmente, os parâmetros de ordem \(p\) e \(q\) são conhecidos. Nosso objetivo é estimar os parâmetros, \(\phi_1,\cdots,\phi_p,\theta_1,\cdots,\theta_q\) e \(\sigma_{_W}^2\). Discutiremos o problema de determinar \(p\) e \(q\) mais adiante nesta seção.
Começamos com o método dos estimadores de momentos. A ideia por trás desses estimadores é a de igualar os momentos da população aos momentos da amostra e depois resolver os parâmetros em termos dos momentos da amostra. Vemos imediatamente que, se \(\mbox{E}(X_t)=\mu\), então o método de estimador de momentos é a média amostral \(\overline{X}\). Assim, enquanto se discute o método dos momentos, assumimos \(\mu= 0\). Embora o método dos momentos possa produzir bons estimadores, eles podem levar a estimadores sub-ótimos. Primeiro, consideramos o caso em que o método leva a estimadores ótimos (eficientes), isto é, modelos \(AR(p)\), \begin{equation} X_t \, = \, \phi_1 X_{t-1}+\cdots+\phi_p X_{t-p}+W_t, \end{equation} onde as primeiras \(p+1\) equações homogêneas gerais levam à seguinte definição.
As equações de Yule-Walker são dadas por \begin{equation} \begin{array}{rcl} \gamma(h) & = & \phi_1 \gamma(h-1)+\cdots+\phi_p \gamma(h-p), \qquad h=1,2,\cdots,p, \\ \sigma_{_W}^2 & = & \gamma(0)-\phi_1\gamma(1)-\cdots-\phi_p \gamma(p)\cdot \end{array} \end{equation}
Em notação matricial, as equações de Yule-Walker são \begin{equation} \Gamma_p \phi \,= \, \gamma_p, \qquad \sigma_{_W}^2 \, = \, \gamma(0)-\phi^\top \gamma_p, \end{equation} onde \(\Gamma_p=\{\gamma(k-j)\}_{j,k=1}^p\) é uma matriz \(p\times p\), \(\phi=(\phi_1,\cdots,\phi_p)^\top\) é um vetor \(p\times 1\) e \(\gamma_p=(\gamma(1),\cdots,\gamma(p))^\top\) é um veotr \(p\times 1\). Usando o método dos momentos, substituímos \(\gamma(h)\) por \(\widehat{\gamma}(h)\) e resolvemos \begin{equation} \widehat{\phi} \, = \, \widehat{\Gamma}_p^{-1}\widehat{\gamma}_p, \qquad \widehat{\sigma}_W^2 \, = \, \widehat{\gamma}(0)-\widehat{\gamma}_p^\top \widehat{\Gamma}_p^{-1}\widehat{\gamma}_p\cdot \end{equation}
Esses estimadores são tipicamente chamados de estimadores Yule-Walker. Para fins de cálculo, às vezes é mais conveniente trabalhar com a ACF amostral. Ao fatorar \(\widehat{\gamma}(0)\) na expressão acima, podemos escrever os estimadores de Yule-Walker como \begin{equation} \widehat{\phi} \, = \, \widehat{R}^{-1}\widehat{\rho}_p, \qquad \widehat{\sigma}_W^2 \, = \, \widehat{\gamma}(0)\Big(1-\widehat{\rho}_p^\top \widehat{R}_p^{-1}\widehat{\rho}_p\Big), \end{equation} onde \(\widehat{R}_p=\{\widehat{\rho}(k-j)\}_{j,k=1}^p\) é uma matriz \(p\times p\), \(\widehat{\phi}_p=(\widehat{\rho}(1),\cdots,\widehat{\rho}(p)^\top\) é um vetor \(p\times 1\)
Para os modelos \(AR(p)\), se o tamanho da amostra for grande, os estimadores de Yule-Walker são aproximadamente normalmente distribuídos e \(\widehat{\sigma}_W^2\) está próximo ao valor real de \(\sigma_{_W}^2\). Declaramos esses resultados no Teorema III.8.
O comportamento assintótico, ou seja, para \(n\to\infty\), dos estimadores de Yule-Walker no caso de processos causais \(AR(p)\) é o seguinte: \begin{equation} \sqrt{n}(\widehat{\phi} -\phi) \, \overset{D}{\longrightarrow} N\big(0,\sigma_{_W}^2 \Gamma_p^{-1}\big), \qquad \widetilde{\sigma}_{_W}^2 \, \overset{P}{\longrightarrow} \, \sigma_{_W}^2\cdot \end{equation}
O algoritmo de Durbin-Levinson pode ser usado para calcular \(\widehat{\phi}\) sem inverter \(\widehat{\Gamma}_p\) ou \(\widehat{R}_p\), substituindo \(\gamma(h)\) por \(\widehat{\gamma}(h)\) no algoritmo. Ao executar o algoritmo, calcularemos iterativamente o vetor \(h\times 1\), \(\widehat{\phi}_h=(\widehat{\phi}_{h,1},\cdots,\widehat{\phi}_{h,h})^\top\), para \(h = 1,2,\cdots\). Assim, além de obter as previsões desejadas, o algoritmo de Durbin-Levinson produz \(\widehat{\phi}_{h,h}\), o PACF amostral.
Para o processos causal \(AR(p)\), assintóticamente, ou seja, para \(n\to\infty\), temos o seguinte: \begin{equation} \sqrt{n}\widehat{\phi}_{h,h} \, \overset{D}{\longrightarrow} N(0,1)\, \qquad h>p\cdot \end{equation}
Exemplo III.27. Estimadores de Yule-Walker para o processo \(AR(2)\).
No Exemplo III.11 mostramos \(n=144\) dados simulados obtidos do modelo \(AR(2)\) \begin{equation} X_t \, = \, 1.5 X_{t-1}-0.75 X_{t-2}+W_t, \end{equation} onde \(W_t\sim N(0,1)\) independentes. Para esses dados, \(\widehat{\gamma}(0)=8.903\), \(\widehat{\rho}(1)=0.849\) e \(\widehat{\rho}(2)=0.519\). Portanto \begin{equation} \widehat{\phi} \, = \, \begin{pmatrix} \widehat{\phi}_1 \\ \widehat{\phi}_2 \end{pmatrix} \, = \, \begin{pmatrix} 1 & 0.849 \\ 0.849 & 1 \end{pmatrix}^{-1} \begin{pmatrix} 0.849 \\ 0.519 \end{pmatrix} \, = \, \begin{pmatrix} 1.463 \\ -0.723 \end{pmatrix} \end{equation} e \begin{equation} \widehat{\sigma}_{_W}^2 \, = \, 8.903\left(1-(0.849 \, , \, 0.519)\begin{pmatrix} 1.463 \\ -0.723 \end{pmatrix} \right) \, = \, 1.187\cdot \end{equation} Pela Proposição III.8, a matriz de variância e covariância assintótica de \(\widehat{\phi}\) é \begin{equation} \frac{1}{144}\times \frac{1.187}{8.903}\begin{pmatrix} 1 & 0.949 \\ 0.849 & 1 \end{pmatrix}^{-1} \, = \, \begin{pmatrix} 0.058^2 & -0.003 \\ -0.003 & 0.589^2 \end{pmatrix}, \end{equation} e pode ser usado para obter regiões de confiança ou fazer inferências sobre \(\widehat{\phi}\) e seus componentes. Por exemplo, um intervalo de confiança de aproximadamente 95% para \(\phi_2\) é \(-0.723\pm 2(0.058)\) ou \(-0.838,-0.608\), que contém o valor real de \(\phi_2 = -0.75\).
Para esses dados, as três primeiras autocorrelações parciais amostrais são: \(\widehat{\phi}_{1,1}=\widehat{\rho}(1)=0.849\), \(\widehat{\phi}_{2,2}=\widehat{\phi}_2=-0.721\) e \(\widehat{\phi}_{3,3}=-0.085\). De acordo com a Proposição III.9, o erro padrão assintótico de \(\widehat{\phi}_{3,3}\) é \(1/\sqrt{144}=0.083\) e o valor observado \(-0.085\), é apenas um desvio padrão de \(\phi_{3,3} = 0\).
Exemplo III.28. Estimadores de Yule-Walker para a série de Recrutamento.
No Exemplo III.18, ajustamos um modelo \(AR(2)\) à série de Recrutamento usando mínimos quadrados ordinários (OLS). Para os modelos AR, os estimadores obtidos via OLS e Yule-Walker são quase idênticos; veremos isso quando discutirmos a estimação de soma condicional de quadrados.
Abaixo estão os resultados da adaptação do mesmo modelo usando estimativa de Yule-Walker em R, que são quase idênticos aos valores obtidos no Exemplo III.18.
Para obter as previsões de 24 meses à frente e seus erros padrão e, em seguida, plotar os resultados como no Exemplo III.25, use os comandos R:
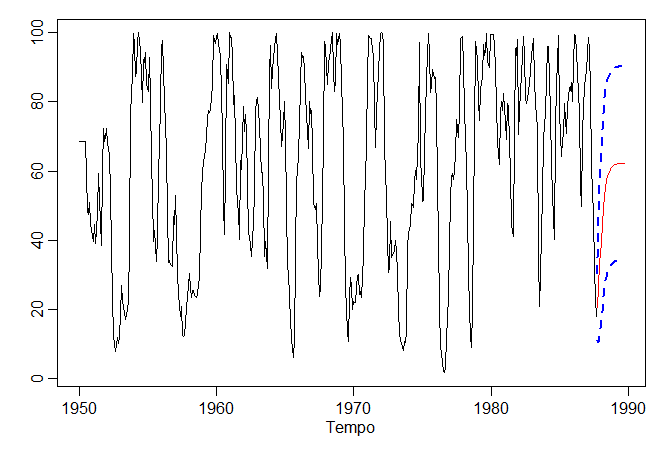 |
|---|
No caso dos modelos \(AR(p)\), os estimadores Yule-Walker são ótimos no sentido de que a distribuição assintótica é a melhor distribuição normal assintótica. Isso porque, dadas as condições iniciais, os modelos \(AR(p)\) são modelos lineares e os estimadores Yule-Walker são essencialmente estimadores de mínimos quadrados. Se usarmos o método dos momentos para os modelos MA ou ARMA, não obteremos estimadores ótimos porque tais processos não são lineares nos parâmetros.
Exemplo III.29. Estimadores obtidos pelo método dos momentos para o modelo \(MA(1)\).
Considere a série temporal \begin{equation} X_t \, = \, W_t +\theta W_{t-1}, \end{equation} onde \(|\theta|< 1\). O modelo pode ser escrito como \begin{equation} X_t \, = \, \sum_{j=1}^\infty (-\theta)^j X_{t-j}+W_t, \end{equation} que não é linear em \(\theta\). As duas primeiras autocovariâncias populacionais são \(\gamma(0)=\sigma_{_W}^2(1+\theta^2)\) e \(\gamma(1)=\sigma_{_W}^2\theta\), então o estimador de \(\theta\) é encontrado resolvendo: \begin{equation} \widehat{\rho}(1) \, = \, \frac{\widehat{\gamma}(1)}{\widehat{\gamma}(0)} \, = \, \frac{\widehat{\theta}}{1+\widehat{\theta}^2}\cdot \end{equation}
Existem duas soluções, então escolheríamos a invertível. Se \(|\widehat{\rho}(1)|< \frac{1}{2}\), as soluções são reais, caso contrário, soluções reais não existem. Mesmo que \(|\rho(1)|< \frac{1}{2}\) para um \(MA(1)\) invertível, pode acontecer que \(|\widehat{\rho}(1)|\geq \frac{1}{2}\) porque é um estimador. Por exemplo, a seguinte simulação em R produz um valor de \(\widehat{\rho}(1)=0.507\) quando o valor verdadeiro é \(\rho(1)=0.9/(1+0.9^2)=0.497\).
Quando \(|\widehat{\rho}(1)|< \frac{1}{2}\), o estimador invertível é \begin{equation} \widehat{\theta} \, = \, \frac{\displaystyle 1-\sqrt{1-4\widehat{\rho}(1)^2}}{2\widehat{\rho}(1)}\cdot \end{equation}
O resultado a continuação segue do Teorema A.7 e do método delta. Veja a demonstração do Teorema A.7 para detalhes sobre o método delta, \begin{equation} \widehat{\theta} \, \sim \, N\left(\theta, \frac{\displaystyle 1+\theta^2+4\theta^4+\theta^6+\theta^8}{\displaystyle n(1+\theta^2)^2}\right), \qquad \mbox{quando} \qquad n \, \to \, \infty\cdot \end{equation} Significa que \(\widehat{\theta}\) é assintoticamente normal e isso é definido na Definição A.5. O estimador de máxima verossimilhança de \(\theta\), que discutiremos a seguir, neste caso, tem uma variância assintótica de \((1-\theta^2)/n\). Quando \(n= 5\), por exemplo, a razão entre a variância assintótica do estimador do métodos de momentos e o estimador de máxima verossimilhança é de aproximadamente 3.5. Ou seja, para grandes amostras, a variância do estimador do método de momentos é cerca de 3.5 vezes maior que a variância do estimador de máxima verossimilhança quando \(\theta=0.5\).
Estimação de máxima verossimilhança e dos mínimos quadrados
Para fixar ideia, vamos focar no modelo causal \(AR(1)\). Seja \begin{equation} X_t \, = \, \mu+\phi (X_{t-1}-\mu)+W_t, \end{equation} onde \(|\phi|< 1\) e \(W_t\sim N(0,\sigma_{_W}^2)\) independentes. Dados os dados \(X_1,X_2,\cdots,X_n\). A função de verossimilhança é \begin{equation} L(\mu,\phi,\sigma_{_W}^2) \, = \, f(X_1,X_2,\cdots,X_n;\mu,\phi,\sigma_{_W}^2), \end{equation} ou seja, a função de densidade ou de probabilidade conjunta. No caso do modelo \(AR(1)\), podemos escrever a verossimilhança como \begin{equation} L(\mu,\phi,\sigma_{_W}^2) \, = \, f(X_1)f(X_2|X_1)\cdots f(X_n|X_{n-1}), \end{equation} onde deixamos de escrever os parâmetros nas densidades, \(f(\cdot)\), para facilitar a notação. Dado que \(X_t|X_{t-1}\sim N(\mu+\phi(X_{t-1}-\mu),\sigma_{_W}^2)\), temos \begin{equation} f(X_t|X_{t-1}) \, = \, f_W\big((X_t-\mu)-\phi(X_{t-1}-\mu) \big), \end{equation} onde \(f_W(\cdot)\) é a função de densidade de \(W_t\), isto é, a densidade normal com média zero e variáncia \(\sigma_{_W}^2\). Podemos então escrever a verossimilhança como \begin{equation} L(\mu,\phi,\sigma_{_W}^2) \, = \, \displaystyle f(X_1)\prod_{t=2}^n f_W\big((X_t-\mu)-\phi(X_{t-1}-\mu) \big)\cdot \end{equation}
Para encontrarmos \(f(X_1)\), podemos usar a representação causal \begin{equation} X_1 \, = \, \mu+\sum_{j=0}^\infty \phi^j W_{1-j}, \end{equation} para ver que \(X_1\) é normal, com média \(\mu\) e variância \(\sigma_{_W}^2/(1-\phi^2)\). Finalmente, para um \(AR(1)\), a verossimilhança é \begin{equation} L(\mu,\phi,\sigma_{_W}^2) \, = \, \displaystyle \frac{\sqrt{1-\phi^2}}{\big(2\pi \sigma_{_W}^2 \big)^\frac{n}{2}}\exp\left( -\frac{S(\mu,\phi)}{2\sigma_{_W}^2}\right), \end{equation} onde \begin{equation} S(\mu,\phi) \, = \, (1-\phi^2)(X_1-\mu)^2\sum_{t=2}^n \big( (X_t-\mu)-\phi(X_{t-1}-\mu)\big)^2\cdot \end{equation}
Tipicamente, \(S(\mu,\phi)\) é chamado a soma de quadrados incondicional. Poderíamos também ter considerado a estimação e o uso de mínimos quadrados incondicionais, isto é, estimar minimizando \(S(\mu,\phi)\).
Tomando a derivada parcial do \(\log\big( L(\mu,\phi,\sigma_{_W}^2)\big)\) com respeito a \(\sigma_{_W}^2\) e definindo o resultado igual a zero, obtemos o resultado típico normal que, para quaisquer valores dados de \(\mu\) e \(\phi\) no espaço de parâmetros, \(\sigma_{_W}^2=n^{-1}S(\mu,\phi)\) maximiza a verossimilhança. Assim, a estimativa da máxima verossimilhança de \(\sigma_{_W}^2\) é \begin{equation} \widehat{\sigma}_W^2 \, = \, \frac{1}{n}S(\widehat{\mu},\widehat{\phi}), \end{equation} sendo que \(\widehat{\mu}\) e \(\widehat{\phi}\) são os estimadores de máxima verossimilhança de \(\mu\) e \(\phi\), respectivamente. Se substituirmos \(n\), na expressão acima, por \(n-2\), obteríamos o estimador de mínimos quadrados incondicionais de \(\sigma_{_W}^2\).
Se em \(L(\mu,\phi,\sigma_{_W}^2)\) tomamos logaritmo, substituímos \(\sigma_{_W}^2\) por \(\widehat{\sigma}_W^2\) e ignoramos constantes, \(\widehat{\mu}\) e \(\widehat{\phi}\) são os valores que minimizam a função critério \begin{equation} \ell(\mu,\phi) \, = \, \log\left( \frac{1}{n}S(\mu,\phi)\right) -\frac{1}{n}\log(1-\phi^2), \end{equation} isto é, \(\ell(\mu,\phi)\approx -2\log\big( L(\mu,\phi,\widehat{\sigma}_W^2)\big)\). A função critério é às vezes chamada de perfilada ou verossimilhança concentrada.
Fica claro que a função de verossimilhança é complicada nos parâmetros, a minimização de \(\ell(\mu,\phi)\) ou \(S(\mu,\phi)\) é realizada numericamente. No caso dos modelos \(AR\), temos a vantagem de, condicionalmente aos valores iniciais, serem modelos lineares. Ou seja, podemos descartar o termo na verossimilhança que causa a não-linearidade. Condicionado em \(X_1\), a verossimilhança condicional torna-se \begin{equation} \begin{array}{rcl} L(\mu,\phi,\sigma_{_W}^2) & = & \displaystyle \prod_{t=2}^n f_W\big((X_t-\mu)-\phi(X_{t-1}-\mu) \big) \\ & = & \dfrac{1}{(2\pi\sigma_{_W}^2)^\frac{n-1}{2}}\exp\left( \displaystyle -\frac{S_c(\mu,\phi)}{2\sigma_{_W}^2}\right), \end{array} \end{equation} onde a soma de quadrados condicional é \begin{equation} S_c(\mu,\phi) \, = \, \sum_{t=2}^n \big( (X_t-\mu)-\phi(X_{t-1}-\mu)\big)^2\cdot \end{equation}
O estimador de máxima verossimilhança condicional de \(\sigma_{_W}^2\) é \begin{equation} \widehat{\sigma}_{_W}^2 \, = \, \dfrac{S_c(\widehat{\mu},\widehat{\phi})}{n-1}, \end{equation} e \(\widehat{\mu}\) e \(\widehat{\phi}\) são os valores que minimizam a soma de quadrados condicional, \(S_c(\mu,\phi)\). Escrevendo \(\alpha=\mu(1-\phi)\), a soma de quadrados condicional pode ser escrita como \begin{equation} S_c(\mu,\phi) \, = \, \sum_{t=2}^n \big( X_t-(\alpha+\phi X_{t-1})\big)^2\cdot \end{equation}
O problema agora é a regressão linear exposto na Seção II.1. Seguindo os resultados da estimação por mínimos quadrados, temos \(\widehat{\alpha}=\overline{X}_{(2)}-\widehat{\phi}\overline{X}_{(1)}\), onde \begin{equation} \overline{X}_{(1)}=\frac{1}{n-1}\sum_{t=1}^{n-1} X_t \end{equation} e \begin{equation} \overline{X}_{(2)}=\frac{1}{n-1}\sum_{t=2}^{n} X_t \end{equation} e os estimadores condicionais são então \begin{equation} \widehat{\mu} \, = \, \displaystyle \frac{\overline{X}_{(2)}-\widehat{\phi}\overline{X}_{(1)}}{1-\widehat{\phi}} \end{equation} e \begin{equation} \widehat{\phi} \, = \, \frac{\displaystyle \sum_{t=2}^n \big(X_t-\overline{X}_{(2)}\big)\big(X_{t-1}-\overline{X}_{(1)}\big)} {\displaystyle \sum_{t=2}^n \big(X_{t-1}-\overline{X}_{(1)}\big)^2}\cdot \end{equation}
Das expressões acima, vemos que \(\widehat{\mu}\approx \overline{X}\) e \(\widehat{\phi}\approx \widehat{\rho}(1)\). Ou seja, os estimadores de Yule-Walker e os estimadores de mínimos quadrados condicionais são aproximadamente os mesmos. A única diferença é a inclusão ou exclusão de termos envolvendo os terminais, \(X_1\) e \(X_n\). Podemos também ajustar os estimadores de \(\sigma_{_W}^2\) para ser equivalente ao estimador de mínimos quadrados, isto é, dividir \(S_c(\widehat{\mu},\widehat{\phi})\) por \(n-3\) em vez de \(n-1\).
Para os modelos \(AR(p)\) gerais, a estimação por máxima verossimilhança, os mínimos quadrados incondicionais e os mínimos quadrados condicionais seguem analogamente ao exemplo \(AR(1)\). Para modelos \(ARMA\) gerais, é difícil escrever a verossimilhança como uma função explícita dos parâmetros. Em vez disso, é vantajoso escrever a verossimilhança em termos das inovações ou erros de previsão em um passo à frente, \(X_t - X_t^{t-1}\). Isso também será útil no Capítulo VI quando estudarmos modelos de espaço de estados.
Para um modelo \(ARMA(p,q)\) normal, seja \(\beta=(\mu,\phi_1,\cdots,\phi_p,\theta_1,\cdots,\theta_q)^\top\) o vetor de dimensão \(p+q+1\) dos parâmetros do modelo. A verossimilhança pode ser escrita como \begin{equation} L(\beta,\sigma_{_W}^2) \, = \, \prod_{t=1}^n f(X_t|X_{t-1},\cdots,X_1)\cdot \end{equation} A distribuição condicional de \(X_t\) dado \(X_{t-1},\cdots,X_1\) é gaussiana com média \(X_t^{t-1}\) e variância \(P_t^{t-1}\). Lembre-se de que \begin{equation} P_t^{t-1} \, = \, \gamma(0)\prod_{j=1}^{t-1} \big(1-\phi_{j,j}^2\big)\cdot \end{equation}
Para modelos ARMA, \(\displaystyle\gamma(0)=\sigma_{_W}^2\sum_{j=0}^\infty \psi_j^2\),caso no qual podemos escrever \begin{equation} P_t^{t-1} \, = \, \sigma_{_W}^2\left( \Big(\sum_{j=0}^\infty \psi_j^2\Big)\Big(\prod_{j=1}^{t-1} \big(1-\phi_{j,j}^2\big)\Big)\right) \, = \, \sigma_{_W}^2 r_t, \end{equation} onde \(r_t\) é o termo entre as chaves. Note que os termos \(r_t\) são apenas funções dos parâmetros de regressão e que podem ser computados recursivamente como \begin{equation} r_{t+1} \, = \, (1-\phi_{t,t}^2)r_t, \end{equation} com condição inicial \(\displaystyle r_1=\sum_{j=0}^\infty \psi_j^2\).
A verossimilhança dos dados pode agora ser escrita como \begin{equation} L(\beta,\sigma_{_W}^2) \, = \, \frac{1}{\displaystyle \big(2\pi \sigma_{_W}^2\big)^\frac{n}{2}} \frac{1}{\sqrt{r_1(\beta)r_2(\beta)\cdots r_n(\beta)}}\exp\left(-\frac{S(\beta)}{2\sigma_{_W}^2}\right), \end{equation} onde \begin{equation} S(\beta) \, = \, \sum_{t=1}~n \frac{\big( X_t-X_t^{t-1}(\beta)\big)^2}{r_t(\beta)}\cdot \end{equation}
Ambos, \(X_t^{t-1}\) e \(r_t\) são funções somente de \(\beta\) e tornamos esse fato explícito na função de verossimilhança dos dados anterior. Dados valores para \(\beta\) e \(\sigma_{_W}^2\), a verossimilhança pode ser avaliada usando as técnicas da Seção III.4. Como no exemplo do \(AR(1)\), temos \begin{equation} \widehat{\sigma}_W^2 \, = \, \frac{1}{n}S(\widehat{\beta}), \end{equation} onde \(\widehat{\beta}\) é o valor de \(\beta\) que minimiza a verossimilhança concentrada ou perfilada \begin{equation} \ell(\beta) \, = \, \log\left(\frac{S(\beta)}{n}\right)+\frac{1}{n}\sum_{t=1}^n \log\big(r_t(\beta) \big)\cdot \end{equation}
Para o modelo \(AR(1)\) discutido anteriormente, lembre-se que \begin{equation} X_1^0 = \mu \qquad \mbox{ e } \qquad X_t^{t-1} = \mu+\phi(X_{t-1}-\mu), \end{equation} para \(t = 2,\cdots,n\cdot\). Também, usando o fato de que \phi_{1,1} = \phi\) e \(\phi_{h,h} = 0\) para \(h> 1\), temos \begin{equation} r_1 = \sum_{j=0}^\infty \phi^{2j} \, = \, \frac{1}{1-\phi^2}, \qquad r_2 \, = \, \frac{1-\phi^2}{1-\phi^2} \, = \, 1 \end{equation} e, em geral, \(r_t = 1\) para \(t = 2,\cdots,n\).
Os mínimos quadrados incondicionais seriam realizados minimizando \(S(\beta)\) em relação a \(\beta\). A estimativa de mínimos quadrados condicionais envolveria a minimização da mesmo expressão em relação a \(\beta\), mas onde, para aliviar a carga computacional, as previsões e seus erros são obtidos pelo condicionamento nos valores iniciais dos dados. Em geral, as rotinas de otimização numérica são usadas para obter as estimativas reais e seus erros padrão.
Exemplo III.30. Os algoritmos de Newton–Raphson e de escore.
Duas rotinas comuns de otimização numérica para realizar a estimação de máxima verossimilhança são Newton–Raphson e escore. Vamos dar um breve relato das ideias matemáticas aqui. A implementação real desses algoritmos é muito mais complicada do que nossa discussão pode implicar. Para detalhes, o leitor é encaminhado para, por exemplo, Press et al. (1993).
Seja \(\ell(\beta)\) a função de critério dos \(k\) parâmetros \(\beta=(\beta_1,\cdots,\beta_k)\) que queremos minimizar em relação a \(\beta\). Por exemplo, considere alguma das funções de verossimilhança dadas acima. Suponha que \(\ell(\widehat{\beta})\) é o extremo que estamos interessados em encontrar e \(\widehat{\beta}\) é encontrado resolvendo \(\partial\ell(\beta)/\partial\beta_j=0\), para \(j=1,\cdots,k\).
Seja \(\ell^{(1)}(\beta)\) o vetor \(k\times 1\) de derivadas parciais \begin{equation} \ell^{(1)}(\beta) \, = \, \left( \frac{\partial\beta}{\partial\beta_1},\cdots,\frac{\partial\beta}{\partial\beta_k}\right)^\top \cdot \end{equation}
Observe que, \(\ell^{(1)}(\widehat{\beta}) = 0\), o vetor \(k\times 1\) de zeros. Seja \(\ell^{(2)}(\beta)\) a matriz \(k\times k\) das derivadas parciais de segundo ordem \begin{equation} \ell^{(2)}(\beta) \, = \, \left( -\frac{\partial \ell^2(\beta)}{\partial\beta_i \partial\beta_j}\right)_{i,j=1}^k, \end{equation} e assuma que \(\ell^{(2)}(\beta)\) não seja singular. Seja \(\beta_{(0)}\) um estimador inicial suficientemente bom de \(\beta\). Então, usando a expansão de Taylor, temos a seguinte aproximação: \begin{equation} 0 \, = \, \ell^{(1)}(\widehat{\beta}) \, \approx \, \ell^{(1)}(\beta_{(0)}) \, - \, \ell^{(2)}(\beta_{(0)})\big( \widehat{\beta}-\beta_{(0)}\big)\cdot \end{equation}
Configurando o lado direito igual a zero e resolvendo por \(\widehat{\beta}\), chame a solução de \(\beta_{(1)}\), obtemos \begin{equation} \beta_{(1)} \, = \, \beta_{(0)} \, + \, \Big(\ell^{(2)}\big( \beta_{(0)}\big) \Big)^{-1}\ell^{(1)}\big( \beta_{(0)}\big)\cdot \end{equation} O algoritmo de Newton–Raphson procede iterando esse resultado, substituindo \(\beta_{(0)}\) por \(\beta_{(1)}\) para obter \(\beta_{(2)}\), e assim por diante, até a convergência. Sob um conjunto de condições apropriadas, a sequência de estimadores, \(\beta_{(1)},\beta_{(2)},\cdots\) converge para \(\widehat{\beta}\), a estimativa de máxima verossimilhança de \(\beta\).
Para a estimação por máxima verossimilhança, a função de critério usada é \(\ell(\beta)\) dada acima; \(\ell^{(1)}(\beta)\) é chamado vetor escore e \(\ell^{(2)}(\beta)\) é chamado de hessiano. No método de escore, substituímos \(\ell^{(2)}(\beta)\) por \(\mbox{E}\big(\ell^{(2)}(\beta)\big)\), a matriz de informação. Sob condições apropriadas, o inverso da matriz de informação é a matriz de variâncias e covariâncias assintótica do estimador \(\widehat{\beta}\). Isso às vezes é aproximado pelo inverso do hessiano em \(\widehat{\beta}\). Se as derivadas são difíceis de obter é possível usar estimação de quase máxima verossimilhança, onde técnicas numéricas são usadas para aproximar as derivadas.
Exemplo III.31. Estimação por máxima verossimilhança para a série de Recrutamento.
Até agora, ajustamos um modelo \(AR(2)\) à série Recrutamento usando mínimos quadrados ordinários (Exemplo III.18) e usando os estimadores de Yule-Walker (Exemplo III.28). A seguir, uma sessão R usada para ajustar um modelo \(AR(2)\) via estimação de máxima verossimilhança à série de Recrutamento; estes resultados podem ser comparados com os resultados do Exemplo 3.18 e do Exemplo III.28.
Discutimos agora os mínimos quadrados para os modelos \(ARMA(p,q)\) via Gauss–Newton. Para detalhes gerais e completos do procedimento de Gauss-Newton, o leitor é referido ao livro de Fuller (1996). Como antes, escreva \(\beta=(\phi_1,\cdots,\phi_p,\theta_1,\cdots,\theta_q)^\top\) e para facilitar a discussão, vamos colocar \(\mu=0\). Escrevemos o modelo em termos de erros \begin{equation} W_t \, = \, X_t - \sum_{j=1}^p \phi_j \, X_{t=j}-\sum_{k=1}^q \theta_k \, W_{t-k}(\beta), \end{equation} enfatizando a dependência dos erros nos parâmetros.
Para os mínimos quadrados condicionais, aproximamos a soma dos quadrados residual pelo condicionamento em \(X_1,\cdots,X_p\), se \(p>0\) e \(W_p=W_{p-1}=W_{p-2}=\cdots+W_{1-q}=0\) se \(q>0\), neste caso, dado \(\beta\) podemos avaliar a expressão acima para \(t=p+1,p+2,\cdots,n\). Usando este argumento de condicionamento, a soma do erro dos quadrados condicional é \begin{equation} S_c(\beta) \, = \, \sum_{t=p+1}^n W_t^2(\beta)\cdot \end{equation} Minimizar \(S_c(\beta)\) com respeito a \(\beta\) produz as estimativas de mínimos quadrados condicionais. Se \(q = 0\), o problema é a regressão linear e nenhuma técnica iterativa é necessária para minimizar o \(S_c(\phi_1,\cdots,\phi_p)\). Se \(q> 0\), o problema se torna regressão não-linear e teremos que confiar na otimização numérica.
Quando \(n\) é grande, o condicionamento em alguns valores iniciais terá pouca influência nas estimativas finais dos parâmetros. No caso de amostras pequenas a moderadas, pode-se desejar confiar em mínimos quadrados incondicionais. O problema dos mínimos quadrados incondicionais é escolher minimizar a soma incondicional de quadrados, que genericamente denotamos por \(S(\beta)\) nesta seção. A soma incondicional de quadrados pode ser escrita de várias maneiras e uma forma útil no caso de modelos \(ARMA(p,q)\) são derivados em Box et al. (1994). Eles mostraram que a soma incondicional de quadrados pode ser escrita como \begin{equation} S(\beta) \, = \, \sum_{t=-\infty}^n \widetilde{W}_t^2(\beta), \end{equation} onde \(\widetilde{W}_t^2(\beta)=\mbox{E}(W_t|X_1,\cdots,X_n)\). Quando \(t\leq 0\), o \(\widetilde{W}_t^2(\beta)\) é obtido por backcasting ou previsão reversa. Como uma questão prática, nos aproximamos do \(S(\beta)\) começando a soma em \(t=-M+1\), onde \(M\) é escolhido grande o suficiente para garantir \(\displaystyle \sum_{t=-\infty}^{-M} \widetilde{W}_t^2(\beta)\approx 0\). No caso da estimação de mínimos quadrados incondicionais, uma técnica de otimização numérica é necessária mesmo quando \(q = 0\).
Para empregar Gauss-Newton, vamos escolher \(\beta_{(0)}=(\phi_1^{(0)},\cdots,\phi_p^{(0)},\theta_1^{(0)},\cdots,\theta_q^{(0)})^\top\) como uma estimativa inicial de \(\beta\). Por exemplo, poderíamos obter \(\beta_{(0)}\) pelo método dos momentos. A primeira ordem da expansão de Taylor de \(W_t(\beta)\) é \begin{equation} W_t(\beta) \, \approx \, W_t(\beta_{(0)}) - \big(\beta-\beta_{(0)}\big)^\top z_t\big(\beta_{(0)}\big), \end{equation} onse \begin{equation} z_t^\top\big(\beta_{(0)}\big) \, = \, \left. \left( -\frac{\partial W_t(\beta)}{\partial\beta_1},\cdots,-\frac{\partial W_t(\beta)}{\partial \beta_{p+q}}\right) \right|_{\beta=\beta_{(0)}}, \qquad t=1,\cdots,n\cdot \end{equation}
A aproximação linear de \(S_c(\beta)\) é \begin{equation} Q(\beta) \, = \, \sum_{t=p+1}^n \big( W_t(\beta_{(0)}) - \big(\beta-\beta_{(0)}\big)^\top z_t\big(\beta_{(0)}\big) \Big)^2 \end{equation} e esta é a quantidade que vamos minimizar. Para quadrados mínimos incondicionais aproximados iniciaríamos a soma em \(t=-M+1\), para um grande valor de \(M\) e trabalharíamos com os valores para trás.
Usando os resultados dos mínimos quadrados ordinários (Seção II.1), sabemos \begin{equation} \big(\widehat{\beta-\beta_{(0)}}\big) \, = \, \displaystyle\left(\frac{1}{n} \sum_{t=p+1}^n z_t\big(\beta_{(0)}\big) z_t^\top\big(\beta_{(0)}\big)\right)^{-1} \left(\frac{1}{n} \sum_{t=p+1}^n z_t\big(\beta_{(0)}\big) W_t\big(\beta_{(0)}\big)\right), \end{equation} minimiza \(Q(\beta)\). Da expressão acima escrevemos a estimativa de um passo de Gauss-Newton como \begin{equation} \beta_{(1)} \, = \, \beta_{(0)}+∆\big( \beta_{(0)}\big), \end{equation} sendo que \(∆\big( \beta_{(0)}\big)\) denota o lado direito de \(\big(\widehat{\beta-\beta_{(0)}}\big)\). A estimativa de Gauss-Newton é realizada substituindo \(\beta_{(0)}\) por \(\beta_{(1)}\). Este processo é repetido calculando, na iteração \(j = 2,3,\cdots\), \begin{equation} \beta_{(j)} \, = \, \beta_{(j-1)}+∆\big( \beta_{(j-1)}\big), \end{equation} até a convergência.
Exemplo III.32. Gauss-Newton para um modelo \(MA(1)\).
Considere o processo \(MA(1)\) invertível \(X_t=W_t+\theta W_{t-1}\). Escrevamos os erros truncados como \begin{equation} W_t(\theta) \, = \, X_t-\theta W_{t-1}(\theta), \qquad t=1,\cdots,n, \end{equation} onde condicionamos \(W_0(\theta)=0\). Tomando derivados e mudando o sinal, \begin{equation} -\frac{\partial W_t(\theta)}{\partial \theta} \, = \, W_{t-1}(\theta)+\theta \frac{\partial W_{t-1}(\theta)}{\partial \theta}, \qquad t=1,\cdots,n, \end{equation} onde \(\partial W_0(\theta)/\partial\theta=0\). Também podemos escrever a expressão acima como \begin{equation} z_t(\theta) \, = \, W_{t-1}(\theta)-\theta z_{t-1}(\theta), \qquad t=1,\cdots,n, \end{equation} sendo que \(z_t(\theta)=-\partial W_t(\theta)/\partial\theta\) e \(z_0(\theta)=0\).
Seja \(\theta_{(0)}\) ser uma estimativa inicial de \(\theta\), por exemplo, a estimativa dada no Exemplo III.29. Então, o procedimento de Gauss-Newton para mínimos quadrados condicionais é dado por \begin{equation} \theta_{(j+1)} \, = \, \theta_{(j)}+\frac{\displaystyle \sum_{t=1}^n z_t\big(\theta_{(j)}\big)W_t\big(\theta_{(j)}\big)} {\displaystyle \sum_{t=1}^n z_t^2\big(\theta_{(j)}\big)}, \qquad j=0,1,2,\cdots, \end{equation} sendo que os valores acima são calculados recursivamente. Os cálculos são interrompidos quando \(|\theta_{(j+1)}-\theta_{(j)}|\) ou \(|Q\big(\theta_{(j+1)}\big)-Q\big(\theta_{(j)}\big)|\) são menores que alguns valores predefinidos.
Exemplo III.33. Ajuste da série Variedades Glaciais Paleoclimáticas.
Considere a série de variedades glaciais de Massachusetts em \(n = 634\) anos, conforme analisado no Exemplo II.7, onde foi argumentado que um modelo de médias móveis de primeira ordem poderia se encaixar nas séries logaritmicamente transformadas e diferenciadas, digamos, \begin{equation} \nabla \log(X_t) \, = \, \log(X_t)-\log(X_{t-1}) \, = \, \displaystyle\log\Big( \frac{X_t}{X_{t-1}}\Big), \end{equation} que pode ser interpretado como sendo aproximadamente a variação percentual na espessura.
O ACF e PACF amostrais, mostrados na figura abaixo, confirmam a tendência de \(\nabla \log(X_t)\) de se comportar como um processo de médias móveis de primeira ordem, pois o ACF tem apenas um pico significativo no lag um e o PACF diminui exponencialmente. Usando a Tabela III.1, esse comportamento amostral se encaixa muito bem com o \(MA(1)\).
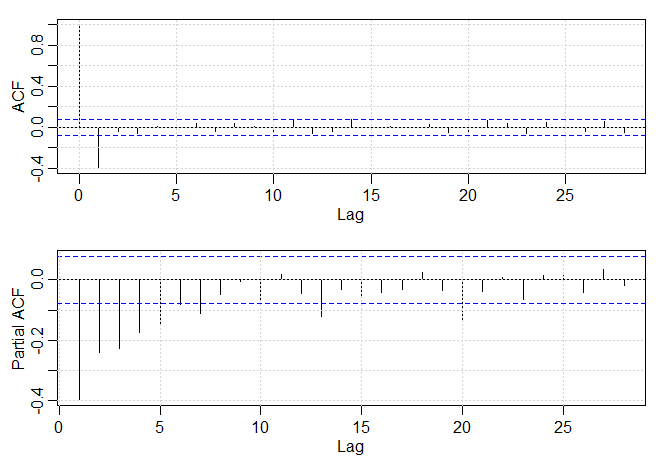 |
|---|
Como \(\widehat{\rho}(1)=-0.397\), nossa estimativa inicial é \(\theta_{(0)}=-0.495\). Os resultados de onze iterações do procedimento de Gauss-Newton, começando com \(\theta_{(0)}\), são mostrados abaixo. A estimativa final é \(\widehat{\theta}=\theta_{(11)}=-0.773\); valores intermediários e o valor correspondente da soma de quadrados condicional \(S_c(\theta)\), também são exibidos.
A estimativa final da variância do erro é \(\widehat{\sigma}_{_W}^2=148.980/(n-2)=148.980/632=0.236\) com 632 graus de liberdade, um é perdido na diferenciação. O valor da soma de quadradasdas derivadas na convergência é \(\sum_{t=1}^n z_t^2(\theta_{(11)})=368.741\) e, consequentemente, o erro padrão estimado de \(\widehat{\theta}\) é \(\sqrt{0.236/368.741}=0.025\), isto leva-nos a um valor \(t\) de \(-0.773/0.025 = -30.92\) com 632 graus de liberdade.
O código a seguir foi usado neste exemplo.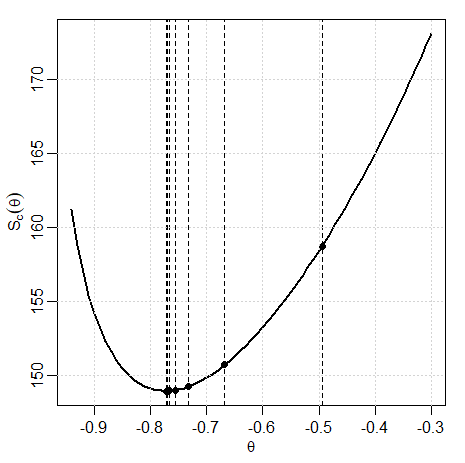 |
|---|
A figura acima mostra a soma de quadrados condicional \(S_c(\theta)\) como função de \(\theta\), assim como indica os valores em cada passo do algoritmo de Gauss-Newton. Observe que o procedimento de Gauss-Newton dá passos largos em direção ao mínimo inicialmente e, em seguida, executa etapas muito pequenas à medida que se aproxima do valor de minimização. Quando há apenas um parâmetro, como neste caso, seria fácil avaliar o \(S_c(\theta)\) em uma grade de pontos e, em seguida, escolher o valor apropriado de \(\theta\) da pesquisa da grade. Seria difícil, no entanto, realizar buscas em grade quando há muitos parâmetros.
No caso geral dos modelos causais e invertíveis \(ARMA(p,q)\), a estimação por máxima verossimilhança, a estimação por mínimos quadrados condicionais e incondicionais e a estimação de Yule-Walker no caso de modelos AR levam a estimadores ótimos. A prova desse resultado geral pode ser encontrada em vários textos sobre análise de séries temporais teóricos, por exemplo, Brockwell and Davis (1991) ou Hannan (1970). Vamos denotar os parâmetros do modelo ARMA por \(\beta=(\phi_1,\cdots,\phi_p,\theta_1,\cdots,\theta_q)^\top\).
Sob condições apropriadas, para processos ARMA causais e invertíveis, os estimadores de máxima verossimilhança, mínimos quadrados incondicionais e mínimos quadrados condicionais, cada um iniciado pelo método de momentos, todos fornecem estimadores ótimos de \(\sigma_{_W}^2\) e \(\beta\), no sentido de que \(\widehat{\sigma}_{_W}^2\) é consistente e a distribuição assintótica de \(\widehat{\beta}\) é a melhor distribuição normal assintótica. Em particular, quando \(n\to\infty\) \begin{equation} \sqrt{n}\big( \widehat{\beta}-\beta\big) \, \overset{D}{\longrightarrow} \, N\big(0,\sigma_{_W}^2 \Gamma_{p,q}^{-1} \big)\cdot \end{equation}
A matriz de variâncias e covariâncias assintótica do estimador \(\widehat{\beta}\) é o inverso da matriz de informação. Em particular, a matriz \(\Gamma_{p,q}\) de dimensão \((p+q)\times (p+q)\), tem a forma \begin{equation} \Gamma_{p,q} \, = \, \begin{pmatrix} \Gamma_{\phi,\phi} & \Gamma_{\phi,\theta} \\ \Gamma_{\theta,\phi} & \Gamma_{\theta,\theta} \end{pmatrix}\cdot \end{equation}
O elemento \((i,j)\) da matriz \(\Gamma_{\phi,\phi}\), para \(i,j=1,\cdots,p\), é \(\gamma_{_X}(i-j)\) para o processo \(AR(p)\), \(\phi(B)X_t = W_t\). Similarmente, o elemento \((i,j)\) da matriz \(\Gamma_{\theta,\theta}\), para \(i,j=1,\cdots,q\), é igual a \(\gamma_{_Y}(i-j)\) para o processo \(AR(q)\), \(\theta(B)Y_t=W_t\). A matriz \(p\times p\), \(\Gamma_{\phi,\theta}=\{\gamma_{_{XY}}(i-j) \, : \, i=1,\cdots,p; \, j=1,\dots,q\}\), isto é, o elemento \((i,j)\) desta matriz é a covariância cruzada entre os dois processos dados por \(\phi(B)X_t=W_t\) e \(\theta(B)Y_t=W_t\). Finalmente, \(\Gamma_{\theta,\phi}=\Gamma_{\phi,\theta}^\top\) é uma matriz de dimensão \(q\times p\).
Exemplo III.34. Algumas distribuições assintóticas específicas.
A seguir estão alguns casos específicos do Teorema III.10.
- \(AR(1)\): \(\gamma_{_X}(0) = \displaystyle\frac{\sigma_{_W}^2}{1-\phi^2}\), assim \(\sigma_{_W}^2 \Gamma_{1,0}^{-1} = 1-\phi^2\). Então, quando \(n\to\infty\), \begin{equation} \widehat{\phi} \, \sim \, N\Big(\phi,\frac{1-\phi^2}{n}\Big)\cdot \end{equation}
- \(AR(2)\): Pode-se verificar que \begin{equation} \gamma_{_X}(0) \, = \, \left( \frac{1-\phi_2}{1+\phi_2}\right)\frac{\sigma_{_W}^2}{(1-\phi_2)^2-\phi_1^2}, \end{equation} e que \(\gamma_{_X}(1)=\phi_1\gamma_{_X}(0)+\phi_2\gamma_{_X}(1)\). A partir desses fatos, podemos calcular \(\Gamma_{2,0}^{-1}\). Em particular, temos \begin{equation} \begin{pmatrix} \widehat{\phi}_1 \\ \widehat{\phi}_2 \end{pmatrix} \, \sim \, N\left( \begin{pmatrix} \phi_1 \\ \phi_2 \end{pmatrix}, \displaystyle\frac{1}{n}\begin{pmatrix} 1-\phi_2^2 & -\phi_1(1+\phi_2) \\ -\phi_1(1+\phi_2) & 1-\phi_2^2 \end{pmatrix}\right), \end{equation} quando \(n\to\infty\).
- \(MA(1)\): Neste caso escrevemos \(\theta(B)Y_t=W_t\) ou \(Y_t+\theta Y_{t-1}=W_t\). Então, análogo ao caso \(AR(1)\) temos que, \(\gamma_{_Y}(0)=\displaystyle\frac{\sigma_{_W}^2}{1-\theta^2}\), deste modo \(\sigma_{_W}^2 \Gamma_{1,0}^{-1} = 1-\theta^2\). Portanto, \begin{equation} \widehat{\theta} \, \sim \, N\Big(\theta,\frac{1-\theta^2}{n}\Big), \end{equation} quando \(n\to\infty\).
- \(MA(2)\): Escrevendo \(Y_t+\theta_1 Y_{t-1}+\theta_2 Y_{t-2}=W_t\), então, análogo ao caso \(AR(2)\), temos \begin{equation} \begin{pmatrix} \widehat{\theta}_1 \\ \widehat{\theta}_2 \end{pmatrix} \, \sim \, N\left( \begin{pmatrix} \theta_1 \\ \theta_2 \end{pmatrix}, \displaystyle\frac{1}{n}\begin{pmatrix} 1-\theta_2^2 & -\theta_1(1+\theta_2) \\ -\theta_1(1+\theta_2) & 1-\theta_2^2 \end{pmatrix}\right), \end{equation} quando \(n\to\infty\).
- \(ARMA(1,1)\): Para calcular \(\Gamma_{\phi,\theta}\), devemos encontrar \(\gamma_{_{XY}}(0)\), onde \(X_t-\phi X_{t-1}=W_t\) e \(Y_t+\theta Y_{t-1}=W_t\). Temos então \begin{equation} \gamma_{_{XY}}(0) \, = \, \mbox{Cov}(X_t,Y_t) \, = \, \mbox{Cov}(\phi X_{t-1}+W_t,-\theta Y_{t-1}+W_t) \, = \, -\phi\theta \gamma_{_{XY}}(0)+\sigma_{_W}^2\cdot \end{equation} Resolvendo, encontramos \(\gamma_{_{XY}}(0)=\displaystyle \frac{\sigma_{_W}^2}{1+\phi\theta}\). Então \begin{equation} \begin{pmatrix} \widehat{\phi} \\ \widehat{\theta} \end{pmatrix} \, \sim \, N\left( \begin{pmatrix} \phi \\ \theta \end{pmatrix}, \frac{1}{n}\begin{pmatrix} \displaystyle\frac{1}{\displaystyle 1-\phi^2} & \frac{1}{\displaystyle 1+\phi\theta} \\ \displaystyle\frac{1}{1+\phi\theta} & \displaystyle\frac{1}{1-\theta^2} \end{pmatrix}^{-1}\right), \end{equation} quando \(n\to\infty\).
Exemplo III.35. Overfitting.
O comportamento assintótico dos estimadores de parâmetros nos dá uma visão adicional sobre o problema de adaptar os modelos ARMA aos dados. Por exemplo, suponha que uma série temporal segue um processo \(AR(1)\) e decidimos ajustar um \(AR(2)\) aos dados. Algum problema ocorre ao fazer isso? Em termos mais gerais, por que não simplesmente ajustar modelos de AR de ordem maior para garantir que capturemos a dinâmica do processo? Afinal, se o processo for realmente um \(AR(1)\) os outros parâmetros autoregressivos não serão significativos.
A resposta é que, se formos demais, obteremos estimativas dos parâmetros menos eficientes ou, de outra maneira, menos precisas. Por exemplo,se ajustarmos um modelo \(AR(1)\) a um processo \(AR(1)\), para grande \(n\), \begin{equation} \mbox{Var}\big(\widehat{\phi}_1\big) \, \approx \, \frac{1}{n}(1-\phi_1^2)\cdot \end{equation} Mas, se ajustarmos um \(AR(2)\) ao processo \(AR(1)\), para \(n\) grande, \begin{equation} \mbox{Var}\big(\widehat{\phi}_1\big) \, \approx \, \frac{1}{n}(1-\phi_2^2)=\frac{1}{n}, \end{equation} porque \(\phi_2=0\). Assim, a variância de \(\phi_1\) foi inflada, tornando o estimador menos preciso.
Queremos mencionar, no entanto, que o overfitting pode ser usado como uma ferramenta de diagnóstico. Por exemplo, se ajustarmos um modelo \(AR(2)\) aos dados e estivermos satisfeitos com esse modelo, adicionar mais um parâmetro e ajustar um \(AR(3)\) deve levar aproximadamente ao mesmo modelo que no ajuste \(AR(2)\). Discutiremos os diagnósticos do modelo em mais detalhes na Seção III.7.
O leitor pode querer saber, por exemplo, por que as distribuições assintóticas de \(\widehat{\phi}\) de um \(AR(1)\) e \(\widehat{\theta}\) de um \(MA(1)\) são da mesma forma. É possível explicar este resultado inesperado usando heuristicamente a intuição da regressão linear. Ou seja, para o modelo de regressão normal apresentado na Seção II.1, sem termo de intercepto \(X_t=\beta z_t+W_t\), sabemos que \(\widehat{\beta}\) é normalmente distribuído com mádia \(\beta\) e \begin{equation} \mbox{Var}\Big( \sqrt{n}\big( \widehat{\beta}-\beta\big)\Big) \, = \, \frac{n\sigma_{_W}^2}{\displaystyle \sum_{t=1}^n z_t^2} \, = \, \frac{\sigma_{_W}^2}{\displaystyle \frac{1}{n}\sum_{t=1}^n z_t^2}\cdot \end{equation}
Para o modelo causal \(AR(1)\) dado por \(X_t=\phi X_{t-1}+W_t\), a intuição da regressão nos diz para esperar que, para \(n\) grande, \(\sqrt{n}\big( \widehat{\phi}-\phi\big)\) é aproximadamente normal com média zero e com variância dada por \begin{equation} \frac{\sigma_{_W}^2}{\displaystyle \frac{1}{n}\sum_{t=2}^n X_{t-1}^2}\cdot \end{equation} Agora, \(\frac{1}{n}\sum_{t=2}^n X_{t-1}^2\) é a variância amostral de \(X_t\), lembremos que a média de \(X_t\) é zero, assim quando \(n\) se torna grande, esperamos que ele se aproxime a \(\mbox{Var}(X_t)=\gamma(0)=\displaystyle\frac{\sigma_{_W}^2}{1-\phi^2}\). Assim, a variância de \(\sqrt{n}\big( \widehat{\phi}-\phi\big)\), em amostras grandes, é \begin{equation} \frac{\sigma_{_W}^2}{\gamma_{_X}(0)} \, = \, \sigma_{_W}^2\left( \frac{1-\phi^2}{\sigma_{_W}^2}\right) \, = \, 1-\phi^2, \end{equation} isto é, o resultado no Exemplo III.34 para o caso \(AR(1)\) procede.
No caso de um \(MA(1)\), podemos usar a discussão do Exemplo III.32 para escrever um modelo de regressão aproximado para o \(MA(1)\). Ou seja, considere a aproximação no Exemplo III.32, como o modelo de regressão \begin{equation} z_t(\widehat{\theta}) \, = \, -\theta z_{t-1}(\widehat{\theta})+W_{t-1}, \end{equation} onde agora, \(z_{t-1}(\widehat{\theta})\) como definido no Exemplo III.32, desempenha o papel do regressor. Continuando com a analogia, esperaríamos a distribuição assintótica de \(\sqrt{n}\big( \widehat{\theta}-\theta\big)\) ser normal, com média zero e variáncia aproximada \begin{equation} \frac{\sigma_{_W}^2}{\displaystyle \frac{1}{n}\sum_{t=2}^n z_{t-1}^2(\widehat{\theta})}\cdot \end{equation}
Como no caso \(AR(1)\), \(\frac{1}{n}\sum_{t=2}^n z_{t-1}^2(\widehat{\theta})\) é a variância amostral de \(z_t(\widehat{\theta})\) então, para \(n\) grande, deve ser que \(\mbox{Var}\big(z_t(\theta)\big)=\gamma_{_Z}(0)\). Mas, note que \(z_t(\theta)\), pode ser aproximado como um processo \(AR(1)\) com parâmetro \(-\theta\). Deste modo \begin{equation} \frac{\sigma_{_W}^2}{\gamma_{_Z}(0)} \, = \sigma_{_W}^2\left(\frac{1-(-\theta)^2}{\sigma_{_W}^2}\right) \, = \, 1-\theta^2\cdot \end{equation} Finalmente, as distribuições assintóticas dos estimadores dos parâmetros AR e os estimadores dos parâmetros MA são da mesma forma, porque no caso MA, os regressores são os processos diferenciais \(z_t(\theta)\) que têm estrutura AR e é essa estrutura que determina a variância assintótica dos estimadores. Para um relato rigoroso dessa abordagem para o caso geral, ver Fuller (1996).
No Exemplo III.33, o erro padrão estimado de \(\widehat{\theta}\) é 0.025. Nesse exemplo, usamos resultados de regressão para estimar o erro padrão como a raiz quadrada de \begin{equation} \frac{\widehat{\sigma}_W^2}{n}\left(\frac{1}{n}\sum_{t=1}^n z_t^2\big(\widehat{\theta}\big) \right)^{-1} \, = \, \frac{\widehat{\sigma}_W^2}{\displaystyle \sum_{t=1}^n z_t^2\big(\widehat{\theta}\big)}, \end{equation} onde \(n=632\), \(\widehat{\sigma}_W^2=0.236\), \(\sum_{t=1}^n z_t^2\big(\widehat{\theta}\big)=368.74\) e \(\widehat{\theta}=-0.773\). Utilizando o resultado acerca do comportamento da distribuição assintótica específicas para os modelos \(MA(1)\) no Exemplo III.34, poderíamos também ter calculado esse valor usando a aproximação assintótica, como a raiz quadrada de \(\big(1-(-0.773)^2\big)/632\), que também é 0.025.
Se \(n\) é pequeno ou se os parâmetros estão próximos dos limites, as aproximações assintóticas podem ser bastante fracas. O bootstrap pode ser útil neste caso; para um amplo tratamento do bootstrap, ver Efron and Tibshirani (1994). Discutimos o caso de um modelo \(AR(1)\) aqui e deixamos a discussão geral para o Capítulo VI. Por enquanto, damos um exemplo simples do bootstrap para um processo \(AR(1)\).
Exemplo III.36. Bootstrapping um \(AR(1)\).
Consideramos um modelo \(AR(1)\) com um coeficiente de regressão próximo ao limite de causalidade e um processo de erro que é simétrico, mas não normal. Especificamente, considere o modelo causal \begin{equation} X_t \, = \, \mu +\phi(X_{t-1}-\mu)+W_t, \end{equation} onde \(\mu=50\), \(\phi=0.95\) e \(W_t\) são variáveis aleatórias independentes com distribuição exponencial dupla ou Laplace, cm média zero e parâmetro de escala \(\beta=2\). A função de densidade de \(W_t\) é dada por \begin{equation} f(w) \, = \, \frac{1}{2\beta}\exp\Big( -\frac{|w|}{\beta}\Big), \qquad -\infty < w <\infty\cdot \end{equation}
Neste exemplo, \(\mbox{E}(W_t)=0\) e \(\mbox{Var}(W_t) = 2\beta^2 = 8\). A figura abaixo mostra \(n = 100\) observações simuladas deste processo. Essa percepção particular é interessante; os dados parecem que foram gerados a partir de um processo não-estacionário com três níveis médios diferentes. De fato, os dados foram gerados a partir de um modelo causal bem comportado, embora não normal. Para mostrar as vantagens do bootstrap, agiremos como se não soubéssemos a distribuição real dos erros. Os dados da figura foram gerados da seguinte forma.
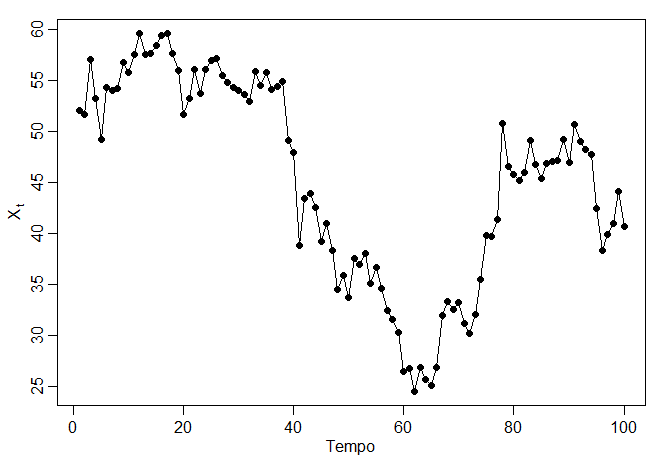 |
|---|
Usando esses dados, obtivemos as estimativas de Yule-Walker \(\widehat{\mu}=45.25\), \(\widehat{\phi}=0.96\) e \(\widehat{\sigma}_W^2=7.88\), como segue:
Para avaliar a distribuição em amostras finitas de \(\widehat{\phi}\) quando \(n = 100\), simulamos 1000 realizações deste processo \(AR(1)\) e estimamos os parâmetros via Yule-Walker. A densidade amostral finita da estimativa de Yule-Walker, baseada nas 1000 simulações repetidas é mostrada na figura abaixo. Com base na Proposição III.10, diríamos que \(\widehat{\phi}\) é aproximadamente normal com média \(\phi\), que supostamente não sabemos, e a variância \((1-\phi^2)/100\), que seria aproximada por \((1-0.96^2)/100=0.03^2\); essa distribuição é sobreposta na figura abaixo. Claramente, a distribuição amostral não está próxima da normalidade para este tamanho de amostra.
O código R para executar a simulação é o seguinte. Usamos os resultados no final do exemplo:
A simulação anterior exigia conhecimento total do modelo, dos valores dos parâmetros e da distribuição do ruído. É claro que, em uma situação de amostragem, não teríamos as informações necessárias para fazer a simulação anterior e, consequentemente, não conseguiríamos gerar uma figura como a abaixo. O bootstrap, no entanto, nos dá uma maneira de atacar o problema.
Para simplificar a discussão e a notação, condicionamos \(X_1\) ao longo do exemplo. Nesse caso, os preditores de um passo à frente têm uma forma simples, \begin{equation} X_t^{t-1} \, = \, \mu+\phi(X_{t-1}-\mu), \qquad t=2,\cdots,100\cdot \end{equation} Consequentemente, as inovações, \(\epsilon_t = X_t-X_t^{t-1}\), são dadas por \begin{equation} \epsilon_t \, = \, (X_t-\mu)-\phi(X_{t-1}-\mu), \qquad t=2,\cdots,100, \end{equation} cada um com erro \(P_t^{t-1}=\mbox{E}(\epsilon_t^2)=\mbox{E}(W_t^2)=\sigma_{_W}^2\) para \(t=2,cdots,100\). Podemos usar a expressão anterior para escrever o modelo em termos de inovações, \begin{equation} X_t \, = \, X_t^{t-1}+\epsilon_t \, = \, \mu+\phi(X_{t-1}-\mu)+\epsilon_t, \qquad t=2,\cdots,100\cdot \end{equation}
Para realizar a simulação bootstrap, substituímos os parâmetros com suas estimativas na expressão acima, ou seja, \(\widehat{\mu}=45.25\) e \(\widehat{\phi}=0.96\), e denotamos as inovações amostrais resultantes como \(\{\widehat{\epsilon}_2,\cdots,\widehat{\epsilon}_{100}\}\). Para obter uma amostra bootstrap, primeiro faça uma amostragem aleatória, com substituição, \(n = 99\) valores do conjunto de inovações amostrais; chame os valores amostrados \(\{\widehat{\epsilon}_2^*,\cdots,\widehat{\epsilon}_{100}^*\}\). Agora, gere um conjunto de dados inicializado sequencialmente, definindo \begin{equation} X_t^* \, = \, 45.25+0.96(X_{t-1}^*-45.25)+\epsilon_t^*, \qquad t=2,\cdots,100, \end{equation} com \(X_!^*\) fixo como \(X_1\). Em seguida, estime os parâmetros como se os dados fossem \(X_t^*\). Chame estas estimativas \(\widehat{\mu}(1)\), \(\widehat{\phi}(1)\) e \(\sigma_{_W}^2(1)\). Repita este processo um número grande \(B\), de vezes, gerando uma coleção de estimativas de parâmetros bootstrap, \(\{\widehat{\mu}(b),\widehat{\phi}(b),\sigma_{_W}^2(b) \, : \, b=1,\cdots,B\}\). Podemos, então, aproximar a distribuição em amostras finitas de um estimador a partir dos valores dos parâmetros bootstrap. Por exemplo, podemos aproximar a distribuição de \(\widehat{\phi}-\phi\) pela distribuição empírica de \(\widehat{\phi}(b)-\widehat{\phi}\), para \(b = 1,\cdots,B\).
A figura abaixo mostra o histograma da amostra bootstrap de 500 estimativas bootstrap dos dados mostrados na figura acima. Note que a distribuição bootstrap de \(\widehat{\phi}\) é próxima da distribuição de \(\widehat{\phi}\) mostrada na figura abaixo. O código a seguir foi usado para executar o bootstrap.
 |
|---|
III.6 Modelos integrados para dados não estacionários
No Capítulo I e no Capítulo II vimos que se \(X_t\) é um passeio aleatório, \(X_t = X_{t-1}+W_t\), então por diferenciação de \(X_t\), achamos que \(\nabla X_t = W_t\) é estacionário. Em muitas situações, séries temporais podem ser consideradas como sendo compostas por dois componentes, um componente de tendência não estacionário e um componente estacionário de média zero. Por exemplo, na Seção II.1, consideramos o modelo \begin{equation} X_t \, = \, \mu_t+Y_t, \end{equation} onde \(\mu_t=\beta_0+\beta_1 t\) e \(Y_t\) é estacionário. Diferenciar esse processo levará a um processo estacionário: \begin{equation} \nabla X_t \, = \, X_t-X_{t-1} \, = \, \beta_1+Y_t -Y_{t-1} \, = \, \beta_1+\nabla Y_t\cdot \end{equation} Outro modelo que leva à primeira diferenciação é o caso em que \(\mu_t\) no modelo \(X_t = \mu_t+Y_t\) é estocástico e varia lentamente de acordo com um passeio aleatório. Isto é, \begin{equation} \mu_t \, = \, \mu_{t-1}+V_t \end{equation} sendo \(V_t\) estacionário. Neste caso, \begin{equation} \nabla X_t \, = \, V_t+\nabla Y_t, \end{equation} é estacionário. Se \(\mu_t\) no modelo acima é um polinômio de \(k\)-ésima ordem, \(\displaystyle \mu_t = \sum_{j=0}^k \beta_j t^j\), então a série diferenciada \(\nabla^k X_t\) é estacionária. Os modelos de tendência estocástica também podem levar a uma diferenciação de ordem superior. Por exemplo, suponha \begin{equation} \mu_t \, = \, \mu_{t-1}+V_t \qquad \mbox{e} \qquad V_t \, = \, V_{t-1}+\epsilon_t, \end{equation} onde \(\epsilon_t\) é estacionária. Então, \(\nabla X_t=V_t+\nabla Y_t\) não é estacionária, mas \begin{equation} \nabla^2 X_t \, = \, \epsilon_t+\nabla^2 Y_t, \end{equation} é estacionária.
O modelo ARMA integrado ou ARIMA é uma ampliação da classe de modelos ARMA para incluir a diferenciação.
O processo \(X_t\) é dito ser \(ARIMA(p,d,q)\) se \begin{equation} \nabla^d X_t \, = \, (1-B)^d X_t, \end{equation} é \(ARMA(p,q)\). Em geral, vamos escrever o modelo como \begin{equation} \phi(B)(1-B)^d X_t \, = \, \theta(B) W_t\cdot \end{equation} Se \(\mbox{E}\big( \nabla^d X_t\big)=\mu\), escrevemos o modelo como \begin{equation} \phi(B)(1-B)^d X_t \, = \, \delta +\theta(B) W_t, \end{equation} onde \(\delta = \mu(1-\phi_1-\cdots-\phi_p)\).
Por causa da não-estacionariedade, deve-se ter cuidado ao derivar previsões. Por uma questão de completude, discutimos brevemente essa questão aqui, mas enfatizamos o fato de que os aspectos teóricos e computacionais do problema são mais bem tratados por meio de modelos de espaço de estados. Discutimos os detalhes teóricos no Capítulo VI. Para obter informações sobre o aspectos computacionais baseados em espaço de estados em R, veja os arquivos de ajuda ARIMA,
Deve ficar claro que, como \(Y_t = \nabla^d X_t\) é ARMA, podemos usar os métodos da Seção III.4 para obter previsões de \(Y_t\), que, por sua vez, levam a previsões para \(X_t\). Por exemplo, se \(d = 1\), dadas as previsões \(Y_{n+m}^n\) para \(m = 1,2,\cdots,\), temos \(Y_{n+m}^n=X_{n+m}^n-X_{n+m-1}^n\), de modo que \begin{equation} X_{n+m}^n \, = \, Y_{n+m}^n+X_{n+m-1}^n, \end{equation} com condição inicial \(X_{n+1}^n=Y_{n+1}^n+X_{n}\), notando que \(X_n^n = X_n\).
É um pouco mais difícil obter os erros de previsão \(P^n_{n+m}\), mas para grandes \(n\), a aproximação usada na Seção III.4, funciona bem. Ou seja, o erro de previsão do quadrado médio pode ser aproximado por \begin{equation} P_{n+m}^n \, = \, \sigma_{_W}^2\sum_{j=0}^{m-1} {\psi_j^*}^2, \end{equation} sendo \({\psi_j^*}^2\) o coeficiente de \(z^j\) em \begin{equation} \psi^*(z) \, = \, \frac{\theta(z)}{\phi(z)(1-z)^d}\cdot \end{equation}
Para entender melhor os modelos integrados, examinamos as propriedades de alguns casos simples. O Exercício III.29 abrange o caso \(ARIMA(1,1,0)\).
Exemplo III.37. Passeio aleatório com tendência.
Para fixar ideias, começamos considerando o passeio aleatório com modelo de tendência apresentado primeiro no Exemplo I.11, ou seja, \begin{equation} X_t \, = \, \delta +X_{t-1}+W_t, \end{equation} para \(t=1,2,\cdots\) e \(X_0=0\). Tecnicamente, o modelo não é ARIMA, mas podemos incluí-lo trivialmente como um modelo \(ARIMA(0,1,0)\). Dados \(X_1,\cdots,X_n\), a previsão de um passo à frente é dada por \begin{equation} X_{n+1}^n \, = \, \mbox{E}(X_{n=1} \, | \, X_n,\cdots,X_1) \, = \, \mbox{E}(\delta+X_n+W_{n+1} \, | \, X_n,\cdots,X_1) \, = \, \delta+X_n\cdot \end{equation} A previsão de dois passos é dada por \(X_{n+2}^n=\delta+X_{n+1}^n=2\delta +X_n\) e, consequentemente, a previsão de \(m\)-passos à frente, para \(m=1,2,\cdots\) é \begin{equation} X_{n+m}^n \, = \, m\delta +X_n\cdot \end{equation}
Para obter os erros de previsão, é conveniente lembrar que \(\displaystyle X_n=n\delta+\sum_{j=1}^n W_j\), nesse caso, podemos escrever \begin{equation} X_{n+m} \, = \, (n+m)\delta + \sum_{j=1}^{n+m} W_j \, = \, m\delta +X_n +\sum_{j=n+1}^{n+m} X_j\cdot \end{equation} A partir disso, segue-se que o erro de predição de \(m\) passos à frente é dado por \begin{equation} P_{n+m}^n \, = \, \mbox{E}\big( X_{n+m}-X_{n+m}^n\big)^2 \, = \, \mbox{E}\left( \sum_{j=n+1}^{n+m} W_j\right)^2 \, = \, m\sigma_{_W}^2\cdot \end{equation}
Assim, ao contrário do caso estacionário (ver Exemplo III.23), à medida que o horizonte de previsão cresce, os erros de previsão, aumentam sem limite e as previsões seguem uma linha reta com declive que emana de \(X_n\). Notamos que \begin{equation} P_{n+m}^n \, = \, \sigma_{_W}^2\sum_{j=0}^{m-1} {\psi_j^*}^2 \end{equation} é exato neste caso porque \(\displaystyle\psi^*(z)=\frac{1}{1-z}=\sum_{j=0}^\infty z^j\), para \(|z|< 1\), de modo que \(\psi_j^*=1\) para todo \(j\).
Os valores \(W_t\) são gaussianos, portanto, a estimação é direta porque os dados diferenciados \(Y_t = \nabla X_t\), são variáveis normais independentes e identicamente distribuídas com média \(\delta\) e variância \(\sigma_{_W}^2\). Consequentemente, as estimativas ótimas de \(\delta\) e \(\sigma_{_W}^2\) são a média e variância amostrais de \(Y_t\), respectivamente.
Exemplo III.38. \(IMA(1,1)\) e EWMA.
O modelo \(ARIMA(0,1,1)\) ou \(IMA(1,1)\) é de interesse porque muitas séries temporais econômicas podem ser modeladas com sucesso dessa maneira. Além disso, o modelo leva a um método de previsão frequentemente usado e abusado, chamado de médias móveis exponencialmente ponderadas ou EWMA (Exponentially Weighted Moving Averages). Vamos escrever o modelo como \begin{equation} X_t \, = \, X_{t-1}+W_t -\lambda W_{t-1}, \end{equation} com \(|\lambda|< 1\), para \(t=1,2,\cdots\) e \(X_0=0\), porque este modelo é mais fácil de se trabalhar aqui e leva à representação padrão para EWMA. Poderíamos ter incluído um termo de tendência como foi feito no exemplo anterior, mas por uma questão de simplicidade, deixamos fora da discussão. Escrevendo \begin{equation} Y_t \, = \, W_t-\lambda W_{t-1}, \end{equation} podemos escrever \(X_t=X_{t-1}+Y_t\). Devido a que \(|\lambda|< 1\), \(Y_t\) tem uma representação invertível, \begin{equation} Y_t \, = \, \sum_{j=1}^\infty \lambda^j Y_{t-j}+W_t \end{equation} e substituindo \(Y_t=X_t-X_{t-1}\), podemos escrever \begin{equation} X_t \, = \, \sum_{j=1}^\infty (1-\lambda)\lambda^j X_{t-j}+W_t, \end{equation} como uma aproximação para \(t\) grande, coloque \(X_t = 0\) para \(t\leq 0\). A verificação da expressão acima é deixada para o leitor no Exercício III.28. Usando a aproximação acima, temos que o preditor aproximado de um passo à frente, usando a notação da Seção III.4, é \begin{equation} \begin{array}{rcl} \widetilde{X}_{n+1} & = & \displaystyle \sum_{j=1}^\infty (1-\lambda)\lambda^j X_{n+1-j} \\ & = & (1-\lambda)X_n \, + \, \lambda \sum_{j=1}^\infty (1-\lambda)\lambda^{j-1} X_{n-j} \, = \, (1-\lambda)X_n + \lambda \widetilde{X}_n\cdot \end{array} \end{equation}
Do resultado anterior vemos que a nova previsão é uma combinação linear da previsão antiga e da nova observação. Com base nesse resultado e no fato de que apenas observamos \(X_1,\cdots,X_n\) e consequentemente \(Y_1,\cdots,Y_n\), porque \(Y_t = X_t - X_{t-1}\) com \(X_0 = 0\), as previsões truncadas são \begin{equation} \widetilde{X}_{n+1}^n \, = \, (1-\lambda) X_n+\lambda \widetilde{X}_n^{n-1}, \qquad n\geq 1, \end{equation} com \(\widetilde{X}_1^0 = X_1\) como valor inicial.
O erro quadrático médio da previsão pode ser aproximado usando observando que \begin{equation} \psi^*(z) \, = \, \frac{1-\lambda z}{1-z} \, = \, \displaystyle 1+(1-\lambda)\sum_{j=1}^\infty z^j, \end{equation} para \(|z|< 1\). Consequentemente, para \(n\) grande, leva a \begin{equation} P_{n+m}^n \approx \sigma_{_W}^2 \big(1+(m-1)(1-\lambda)^2 \big)\cdot \end{equation}
No EWMA, o parâmetro \(1-\lambda\) é freqüentemente chamado de parâmetro de suavização e é restrito a ser entre zero e um. Valores maiores levam a previsões mais suaves.
Este método de previsão é popular porque é fácil de usar, precisamos apenas reter o valor da previsão anterior e a observação atual para prever o próximo período de tempo. Infelizmente, como sugerido anteriormente, o método é frequentemente abusado porque alguns analistas não verificam se as observações seguem um processo \(IMA(1,1)\) e muitas vezes arbitrariamente escolher valores de \(\lambda\). A seguir, mostramos como gerar 100 observações de um modelo \(IMA(1,1)\) com \(\lambda=-\theta=0.8\) e depois calcular e exibir o EWMA ajustado sobreposto aos dados. Isso é feito usando o comando Holt-Winters em R, veja o arquivo de ajuda ?HoltWinters para detalhes:
 |
|---|
III.7 Diagnóstico de resíduos para modelos ARIMA
Existem algumas etapas básicas para ajustar modelos ARIMA a dados de séries temporais. Essas etapas envolvem:
- plotando os dados,
- possivelmente transformando os dados,
- identificar as ordens de dependência do modelo,
- estimação dos parâmetros,
- diagnósticos e
- escolha do modelo.
Por exemplo, vimos vários exemplos em que os dados se comportam como \(X_t=(1+p_t)X_{t-1}\), onde \(p_t\) é uma pequena alteração percentual do período \(t-1\) para \(t\), que pode ser negativo. Se \(p_t\) é um processo relativamente estável, então \(\nabla \log(X_t)\approx p_t\) será relativamente estável. Frequentemente,\(\nabla \log(X_t)\) é chamado retorno ou taxa de crescimento. Essa ideia geral foi usada no Exemplo III.33 e vamos usá-la novamente no Exemplo III.39.
Depois de transformar adequadamente os dados, o próximo passo é identificar os valores preliminares da ordem autoregressiva \(p\), a ordem de diferenciação \(d\) e a ordem de médias móveis \(q\). Um gráfico de tempo dos dados geralmente sugere se alguma diferenciação seja necessária. Se a diferenciação for solicitada, fazendo a diferença dos dados uma vez \(d = 1\), e inspecione o gráfico de tempo de \(\nabla X_t\). Se a diferenciação adicional for necessária, tente novamente a diferenciação e inspecione um gráfico de tempo de \(\nabla^2 X_t\). Tenha cuidado para não superdiferenciar porque isso pode introduzir dependência onde não existe. Por exemplo, \(\nabla X_t = W_t\) é serialmente não correlacionada, mas \(\nabla X_t = W_t - W_{t-1}\) é \(MA(1)\).
Além dos gráficos de tempo, o ACF amostral pode ajudar a indicar se a diferenciação é necessária. Como o polinômio \(\phi(z)(1-z)^d\) tem uma raiz unitária, o ACF amostral \(\widehat{\rho}(h)\), não decairá a zero rápido quando \(h\) aumenta. Assim, um decaimento lento em \(\widehat{\rho}(h)\) é uma indicação de que a diferenciação pode ser necessária.
Quando os valores preliminares de \(d\) foram estabelecidos, o próximo passo é olhar para o ACF e o PACF amostrais de \(\nabla^d X_t\) para quaisquer valores de \(d\) que tenham sido escolhidos. Usando a Tabela III.1 como guia, os valores preliminares de \(p\) e \(q\) são escolhidos. Observe que não é possível que tanto o ACF quanto o PACF sejam cortados. Como estamos lidando com estimativas, nem sempre ficará claro se o ACF ou o PACF amostral está diminuindo ou cortando. Além disso, dois modelos aparentemente diferentes podem ser muito semelhantes. Com isso em mente, não devemos nos preocupar em ser tão precisos neste estágio do ajuste do modelo. Neste ponto, alguns valores preliminares de \(p\), \(d\) e \(q\) devem estar à mão, e podemos começar a estimar os parâmetros.
Exemplo III.39. Análise de dados do PIB.
Neste exemplo, consideramos a análise do PIB trimestral dos EUA do primeiro trimestre de 1947 ao terceiro trimestre de 2002, \(n = 223\) observações. Os dados são o Produto Interno Bruto real dos EUA em bilhões de dólares de 1996 encadeados e foram ajustados sazonalmente. Os dados foram obtidos do Federal Reserve Bank of St. Louis. A figura abaixo mostra um gráfico dos dados, digamos, \(Y_t\). Como a tendência forte tende a obscurecer outros efeitos é difícil ver qualquer outra variabilidade nos dados, exceto por grandes quedas periódicas na economia.
 |
|---|
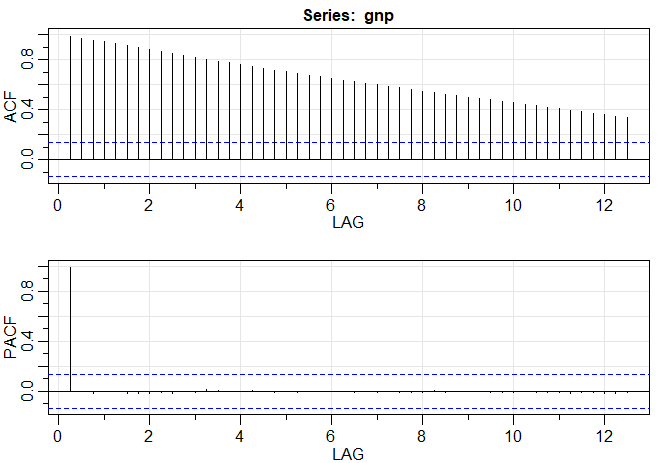 |
|---|
Quando são apresentados relatórios do PIB e indicadores econômicos similares, geralmente é na taxa de crescimento ou variação percentual e não nos valores reais ou ajustados que presta-se interesse. A taxa de crescimento, digamos, \(X_t = \nabla \log(Y_t)\) é plotada na figura embaixo e parece ser um processo estável.
 |
|---|
A funções ACF e PACF amostrais da taxa de crescimento trimestral estão representadas na figura abaixo. Inspecionando as ACF e PACFa mostrais, podemos sentir que o ACF está cortando no lag ou atraso 2 e o PACF está diminuindo. Isto sugeriria que a taxa de crescimento do PIB segue um processo \(MA(2)\) ou que o logartimo do PIB segue um modelo \(ARIMA(0,1,2)\). Em vez de focar em um modelo, também sugeriremos que parece que o ACF está diminuindo e o PACF está cortando na defasagem 1. Isso sugere um modelo \(AR(1)\) para a taxa de crescimento ou \(ARIMA(1,1,0)\) para logartimo do PIB. Como uma análise preliminar, vamos encaixar ambos os modelos.
 |
|---|
Usando a estimação por máxima verossimilhança para ajustar o modelo \(MA(2)\) para a taxa de crescimento \(X_t\), o modelo estimado é \begin{equation} \widehat{X}_t \, = \, 0.008_{(0.001)}+0.303_{(0.065)}\widehat{W}_{t-1}+0.204_{(0.064)}\widehat{W}_{t-2}+\widehat{W}_t, \end{equation} onde \(\widehat{\sigma}_{_W}=0.0094\) com 219 graus de liberdade. Os valores entre parênteses correspondem aos erros padrão estimados. Todos os coeficientes de regressão são significativos, incluindo a constante.
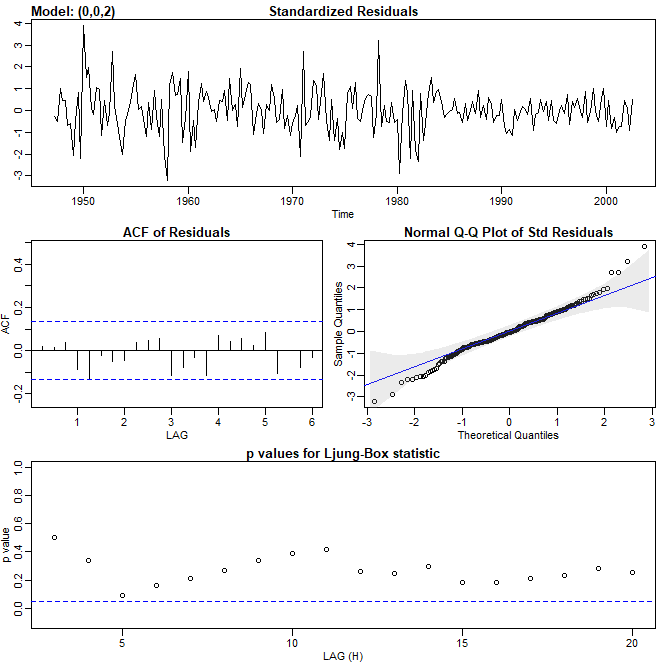 |
|---|
Fazemos uma nota especial disso porque, como padrão, alguns pacotes computacionais não ajustam uma constante em um modelo diferenciado. Ou seja, esses pacotes assumem, por padrão, que não há desvio. Neste exemplo, não incluir uma constante leva a conclusões erradas sobre a natureza da economia dos EUA. A não inclusão de uma constante assume que a taxa de crescimento média trimestral é zero, enquanto a taxa de crescimento trimestral média do PIB dos EUA é de cerca de 1%, o que pode ser visto facilmente na figura da taxa de crescimento. Deixamos para o leitor investigar o que acontece quando a constante não é incluída.
O modelo \(AR(1)\) estimado é \begin{equation} \widehat{X}_t \, = \, 0.008_{(0.001)}(1-0.347)+0.347_{(0.063)}\widehat{X}_{t-1}+\widehat{W}_t, \end{equation} onde \(\widehat{\sigma}_{_W}=0.0095\) com 220 graus de liberdade, observe que a constante na expressão acima é 0.008(1-0.347)=0.005.
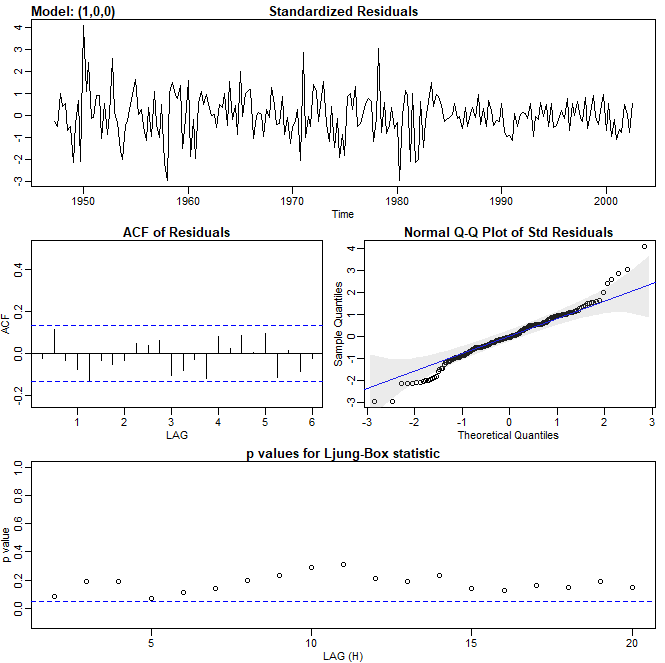 |
|---|
Discutiremos os diagnósticos a seguir, mas assumindo que ambos os modelos se encaixam bem, como vamos reconciliar as diferenças aparentes dos modelos estimados. De fato, os modelos ajustados são quase os mesmos. Para mostrar isso, considere um modelo \(AR(1)\) sem um termo constante; isto é, \begin{equation} X_t \, = \, 0.35 X_{t-1}+W_t, \end{equation} e escrevê-lo em sua forma causal \begin{equation} X_t \, = \, \sum_{j=0}^\infty \psi_j W_{t-j}, \end{equation} onde lembramos que \(\psi_j=0.35^j\). Portanto, \(\psi_0=0\), \(\psi_1=0.350\), \(\psi_2=0.123\), \(\psi_3=0.043\), \(\psi_4=0.015\), \(\psi_5=0.005\), \(\psi_6=0.002\), \(\psi_7=0.001\), \(\psi_8=0\) e assim por diante. Portanto, \begin{equation} X_t \approx 0.35 W_{t-1}+0.12 W_{t-2}+W_t, \end{equation} que é semelhante ao modelo \(MA(2)\).
O próximo passo no ajuste do modelo é o diagnóstico. Esta investigação inclui a análise dos resíduos, bem como comparações de modelos. Mais uma vez, o primeiro passo envolve um gráfico de tempo das inovações ou resíduos \(X_t-\widehat{X}_t^{t-1}\) ou das inovações padronizadas \begin{equation} \epsilon_t \, = \, \displaystyle \frac{X_t-\widehat{X}_t^{t-1}}{\sqrt{\widehat{P}_t^{t-1}}}, \end{equation} onde \(\widehat{X}_t^{t-1}\) é a previsão de \(X_t\) com um passo à frente com base no modelo ajustado e \(\widehat{P}_t^{t-1}\) é a variância estimada do erro de um passo à frente. Se o modelo se encaixa bem, os resíduos padronizados devem se comportar como uma sequência independente e identicamente distribuída com média zero e variância um. O gráfico de tempo deve ser inspecionado para quaisquer desvios óbvios desta suposição. A menos que a série temporal seja gaussiana, não é suficiente que os resíduos sejam não correlacionados. Por exemplo, é possível, no caso não gaussiano, ter um processo não correlacionado para o qual os valores contíguos no tempo sejam altamente dependentes. Como exemplo, mencionamos a família de modelos GARCH que serão discutidos no Capítulo V.
A investigação da normalidade marginal pode ser realizada visualmente, observando-se um histograma dos resíduos. Além disso, um gráfico de probabilidade normal ou um gráfico Q-Q pode ajudar a identificar desvios da normalidade. Veja Johnson e Wichern (1992) para detalhes deste teste, bem como testes adicionais para normalidade multivariada.
Existem vários testes de aleatoriedade, por exemplo, o teste de execução, que pode ser aplicado aos resíduos. Poderíamos também inspecionar as autocorrelações amostrais dos resíduos, digamos, \(\widehat{\rho}_\epsilon(h)\), para quaisquer padrões ou valores grandes. Lembre-se de que, para uma sequência de ruído branco, as autocorrelações amostrais são aproximadamente independentes e normalmente distribuídas com média zero e variância \(1/n\). Portanto, uma boa verificação na estrutura de correlação dos resíduos é traçar \(\widehat{\rho}_\epsilon(h)\) versus versus \(h\) juntamente com os limites de erro de \(\pm 2/\sqrt{n}\). Os resíduos de um ajuste de modelo, no entanto, não terão exatamente as propriedades de uma sequência de ruído branco e a variância de \(\widehat{\rho}_\epsilon(h)\) pode ser muito menor que \(1/n\). Detalhes podem ser encontrados em Box e Pierce (1970) e McLeod (1978). Esta parte dos diagnósticos pode ser vista como uma inspeção visual de \(\widehat{\rho}_\epsilon(h)\) com a principal preocupação sendo a detecção de desvios óbvios da suposição de independência.
Além de mostrar o \(\widehat{\rho}_\epsilon(h)\), podemos realizar um teste geral que leva em consideração as magnitudes de \(\widehat{\rho}_\epsilon(h)\) como um grupo. Por exemplo, pode ser o caso de, individualmente, cada \(\widehat{\rho}_\epsilon(h)\) ser pequeno em magnitude, digamos, cada um é ligeiramente menor que \(2/\sqrt{n}\) em magnitude, mas, coletivamente, os valores são grandes. A estatística \(Q\) de Ljung-Box-Pierce dada por \begin{equation} Q \, = \, n(n+2)\sum_{h=1}^H \frac{\widehat{\rho}_\epsilon(h)}{n-h}, \end{equation} pode ser usada para realizar tal teste. O valor \(H\) na expressão acima é escolhido arbitrariamente, tipicamente, \(H = 20\). Sob a hipótese nula de adequação do modelo, assintoticamente, \(Q\sim \chi_{H-p-q}^2\). Assim, rejeitaríamos a hipótese nula no nível \(\alpha\) se o valor de \(Q\) exceder o valor do quantil \(1-\alpha\) da distribuição \(\chi_{H-p-q}^2\). Detalhes podem ser encontrados em Box e Pierce (1970), Ljung e Box (1978) e Davies et al. (1977). A ideia básica é que se \(W_t\) é ruído branco, então por Proposição I.2, \(n\widehat{\rho}_W^2(h)\) para \(h = 1,\cdots,H\), são variáveis aleatórias assintoticamente independentes com distribuição \(\chi_1^2\). Isso significa que \begin{equation} n\sum_{h=1}^H \widehat{\rho}_W^2(h), \end{equation} é aproximadamente uma variável aleatória com distribuição \(\chi_H^2\). Como o teste envolve o ACF dos resíduos de um ajuste de modelo, há uma perda de \(p + q\) graus de liberdade; os outros valores na expressão da estatística \(Q\) são usados para ajustar a estatística para melhor corresponder à distribuição qui-quadrada assintoticamente.
Exemplo III.40. Diagnósticos para o exemplo da taxa de crescimento do PIB.
Vamos nos concentrar no ajuste \(MA(2)\) do Exemplo III.39; a análise dos resíduos do modelo \(AR(1)\) é semelhante. A figura mostra um gráfico dos resíduos padronizados, o ACF dos resíduos, um boxplot dos resíduos padronizados e os p-valores associados à estatística-\(Q\) nas defasagens \(H = 3\) até \(H = 20\), com \(H-2\) graus de liberdade.
|
|---|
A inspeção do gráfico de tempo dos resíduos padronizados na figura acima não mostra padrões óbvios. Observe que pode haver outliers, com alguns valores excedendo 3 desvios padrão em magnitude. O ACF dos resíduos padronizados não mostra nenhum desvio aparente das premissas do modelo e a estatística \(Q\) nunca é significativa nas defasagens mostradas. O gráfico Q-Q normal dos resíduos mostra que a suposição de normalidade é razoável, com exceção dos possíveis outliers.
O modelo parece se encaixar bem. Os diagnósticos mostrados na figura acima são um subproduto do comando sarima do exemplo anterior, Exemplo III.39. O script tsdiag está disponível no R para executar diagnósticos para um objeto ARIMA, no entanto, o script possui erros e não é recomendável usá-lo.
Exemplo III.41. Diagnósticos para o exemplo das Variedades Glaciais Paleoclimáticas.
No Exemplo III.33, ajustamos um modelo \(ARIMA(0,1,1)\) aos logaritmos dos dados das variedades glaciais Paleoclimáticasvariante e parece haver uma pequena quantidade de autocorrelação nos resíduos e os testes-\(Q\) são todos significativos; veja a figura abaixo.
 |
|---|
Para retificar este problema, ajustamos um \(ARIMA(1,1,1)\) aos dados das variedades glaciais registradas e obteve as estimativas \begin{equation} \widehat{\phi}=0.23_{(0.05)}, \qquad \widehat{\theta}=-0.89_{(0.03)}, \qquad \widehat{\sigma}_W^2 =0.23\cdot \end{equation} Portanto, o termo AR é significativo. Os p-valores da estatística \(Q\) para este modelo também são exibidos na figura abaixo e parece que esse modelo se ajusta bem aos dados.
 |
|---|
Como dito anteriormente, os diagnósticos são subprodutos das execuções individuais do sarima. Notamos que não ajustamos uma constante em nenhum modelo porque não há desvio aparente na série. Este fato pode ser verificado observando que a constante não é significativa quando o comando no.constant = TRUE é removido no código:
No Exemplo III.39, temos dois modelos concorrentes, um \(AR(1)\) e um \(MA(2)\) sobre a taxa de crescimento do PIB, que parecem se encaixar bem nos dados. Além disso, podemos também considerar que um \(AR(2)\) ou um \(MA(3)\) podem ser melhores para a previsão. Talvez combinar os dois modelos, isto é, ajustar um \(ARMA(1,2)\) na taxa de crescimento do PIB, seria o melhor. Como mencionado anteriormente, temos que nos preocupar com o overfitting do modelo; isso porque nem sempre é o caso que mais é melhor. O overfitting leva a estimadores menos precisos e a adição de mais parâmetros pode adequar melhor os dados, mas também pode levar a previsões ruins. Esse resultado é ilustrado no exemplo a seguir.
Exemplo III.42. Um problema com overfitting.
A figura mostra a população dos EUA por censo oficial a cada dez anos, de 1910 a 1990, como pontos. Se usarmos essas nove observações para prever a população futura, podemos usar um polinômio de oito graus para que o ajuste às nove observações seja perfeito. O modelo neste caso é \begin{equation} X_t \, = \, \beta_0+\beta_1 t +\beta_2 t^2+ \cdots+\beta_8 t^8+W_t\cdot \end{equation} A linha ajustada, que é plotada na figura, passa pelas nove observações. O modelo prevê que a população dos Estados Unidos crescerá pouco no ano 2000 e irá diminiuir fortemente sendo em 2020 a população similar à população de 1960 enquanto a população projetada para 2020 deve ser 333.546.000.
 |
|---|
O código R para gerar os resultados da figura acima são os seguintes:
A etapa final do ajuste do modelo é a escolha do modelo ou a seleção do modelo. Ou seja, devemos decidir qual modelo iremos reter para previsão. As técnicas mais populares, AIC, AICc e BIC, foram descritas na Seção II.1 no contexto de modelos de regressão.
Exemplo III.43. Escolha do modelo para a série do PIB dos EUA.
Retornando à análise dos dados do PIB dos EUA apresentados no Exemplo III.39 e no Exemplo III.40, lembremos que dois modelos, um \(AR(1)\) e um \(MA(2)\), se ajustam bem à taxa de crescimento do PIB. Para escolher o modelo final, comparamos o AIC, o AICc e o BIC para ambos os modelos. Esses valores são um subproduto das execuções do comando sarima exibidas no final do Exemplo III.39 mas, por conveniência, exibimos novamente aqui lembrando que os dados da taxa de crescimento estão no objeto gnpgr:
O AIC e o AICc preferem o ajuste \(MA(2)\), enquanto o BIC prefere o modelo \(AR(1)\) mais simples. Geralmente, o BIC selecionará um modelo de ordem menor que o AIC ou AICc. Em ambos os casos, não é irracional manter o \(AR(1)\) porque os modelos autorregressivos puros são mais fáceis de trabalhar.
III.8 Regressão com erros autocorrelacionados
Na Seção II.1, cobrimos o modelo de regressão clássico com erros não correlacionados \(W_t\). Nesta seção, discutimos as modificações que podem ser consideradas quando os erros são correlacionados. Ou seja, considere o modelo de regressão \begin{equation} Y_t \, = \, \sum_{j=1}^r \beta_j \, z_{t,j}+X_t, \end{equation} onde \(X_t\) é um processo com alguma função de covariância \(\gamma_{_X}(s,t)\). Em mínimos quadrados ordinários, a suposição é que \(X_t\) é ruído branco gaussiano, em que \(\gamma_{_X}(s,t)=0\) para \(s\neq t\) e \(\gamma_{_X}(t,t)=\sigma^2\), independente de \(t\). Se este não for o caso, então os mínimos quadrados ponderados devem ser usados.
Escrevendo o modelo em notação vetorial, \(Y=Z\beta\), onde \(Y=(Y_1,\cdots,Y_n)^\top\) e \(X=(X_1,\cdots,X_n)^\top\) são vetores \(n\times 1\), \(\beta=(\beta_1,\cdots,\beta_r)^\top\) é \(r\times 1\) e \(Z=(Z_1|Z_2|\cdots|z_n)^\top\) é uma matriz \(n\times r\) matriz composta das variáveis de entrada. Seja \(\Gamma=\{\gamma_{_X}(s,t)\}\), então \begin{equation} \Gamma^{-1/2}Y \, = \, \Gamma^{-1/2}Z\beta \, + \, \Gamma^{-1/2}X, \end{equation} para que possamos escrever o modelo como \begin{equation} Y^* \, = \, Z^* \beta+\delta, \end{equation} onde \(Y^* = \Gamma^{-1/2}Y\), \(Z^* =\Gamma^{-1/2}Z\) e \(\delta=\Gamma^{-1/2}X\). Consequentemente, a matriz de covariância de \(\delta\) é a identidade e o modelo está na forma de modelo linear clássico. Segue-se que a estimativa ponderada de \(\beta\) é \begin{equation} \widehat{\beta}_W \, = \, \big( {Z^*}^\top Z^*\big)^{-1} {Z^*}^\top Y^* \, = \, (Z^\top \Gamma^{-1}Z)^{-1} Z^\top \Gamma^{-1}Y \end{equation} e a matriz de variâncias e covariâncias do estimador é \begin{equation} \mbox{Var}(\widehat{\beta}_W) \, = \, (Z^\top \Gamma^{-1}Z)^{-1}\cdot \end{equation} Se \(X_t\) é ruído branco, então \(\Gamma=\sigma \mbox{I}\) e estes resultados reduzem-se aos resultados usuais de mínimos quadrados.
No caso de séries temporais, muitas vezes é possível assumir uma estrutura de covariância estacionária para o processo de erro \(X_t\) que corresponde a um processo linear e tentar encontrar uma representação ARMA para \(X_t\). Por exemplo, se tivermos um erro \(AR(p)\) puro, \begin{equation} \phi(B) X_t \, = \, W_t, \end{equation} e \(\phi(B)=1-\phi_1 B-\cdots-\phi_p B^p\) é a transformação linear que, quando aplicada ao processo de erro, produz o ruído branco \(W_t\). Multiplicando a equação de regressão através da transformação \(\phi(B)\), produz \begin{equation} \underbrace{\phi(B) Y_t}_{Y_t^*} \, = \, \displaystyle \sum_{j=1}^r \beta_j \, \underbrace{\phi(B)z_{t,j}}_{z_{t,j}^*} \, + \, \underbrace{\phi(B) X_t}_{W_t} \end{equation} e estamos de volta ao modelo de regressão linear onde as observações foram transformadas de modo que \(Y_t^* = \phi(B)Y_t\) seja a variável dependente, \(z_{t,j}^* =\phi(B)z_{t,j}\) para \(j = 1,\cdots,r\), são as variáveis independentes, mas os \(\beta\) são os mesmos que no modelo original. Por exemplo, se \(p = 1\), então \(Y_t^* = Y_t-\phi Y_{t-1}\) e \(z_{t,j}^*=z_{t,j}-\phi Z_{t-1,j}\).
No caso de AR, podemos configurar o problema dos quadrados mínimos para minimizar a soma dos quadrados dos erros \begin{equation} S(\phi,\beta) \, ´= \, \sum_{t=1}^n W_t^2 \, = \, \displaystyle \sum_{t=1}^n \left( \phi(B)Y_t \, - \, \sum_{j=1}^r \beta_j \phi(B)Z_{t,j}\right)^2, \end{equation} com relação a todos os parâmetros \(\phi=(\phi_1,\cdots,\phi_p)\) e \(\beta=(\beta_1,\cdots,\beta_r)\). Naturalmente, a otimização é realizada usando métodos numéricos.
Se o processo de erro é \(ARMA(p,q)\), ou seja, \(\phi(B)X_t = \theta(B)W_t\), então na discussão acima, transformamos por \(\pi(B)X_t=W_t\), onde \(\pi(B)=\theta(B)^{-1}\phi(B)\). Neste caso, a soma dos quadrados dos erros também depende de \(\theta=(\theta_1,\cdots,\theta_q)\): \begin{equation} S(\phi,\theta,\beta) \, ´= \, \sum_{t=1}^n W_t^2 \, = \, \displaystyle \sum_{t=1}^n \left( \pi(B)Y_t \, - \, \sum_{j=1}^r \beta_j \pi(B)Z_{t,j}\right)^2, \end{equation}
Neste ponto, o principal problema é que normalmente não conhecemos o comportamento do ruído \(X_t\) antes da análise. Uma maneira fácil de resolver esse problema foi apresentada pela primeira vez em Cochrane e Orcutt (1949) e com o advento da computação barata é modernizado abaixo:
- (i) Primeiro, execute uma regressão ordinária de \(Y_t\) em \(z_{t,1},\cdots,z_{tr}\) agindo como se os erros não fossem correlacionados. Guarde os resíduos, \begin{equation} \widehat{X}_t \, = \, Y_t -\sum_{j=1}^r \widehat{\beta}_j z_{t,j}\cdot \end{equation}
- (ii) Identifique modelo ARMA para os resíduos \(\widehat{X}_t\).
- (iii) Executar os mínimos quadrados ponderados ou MLE no modelo de regressão com erros autocorrelacionados usando o modelo especificado na etapa (ii).
- (iv) Inspecione os resíduos \(\widehat{W}_t\), verificando são um ruído branco e ajuste o modelo, se necessário.
Consideramos as análises apresentadas no Exemplo II.2, relacionando a temperatura média ajustada \(T_t\) e os níveis de partículas \(P_t\) com a mortalidade cardiovascular \(M_t\). Consideramos o modelo de regressão \begin{equation} M_t \, = \, \beta_1+\beta_2 t +\beta_3 T_t +\beta_4 T_t^2+\beta_5 P_t+X_t, \end{equation} onde, por enquanto, assumimos que \(X_t\) é ruído branco. O ACF e o PACF amostrais dos resíduos do ajuste de mínimos quadrados ordinários são mostrados na figura abaixo e os resultados sugerem um modelo \(AR(2)\) para os resíduos.
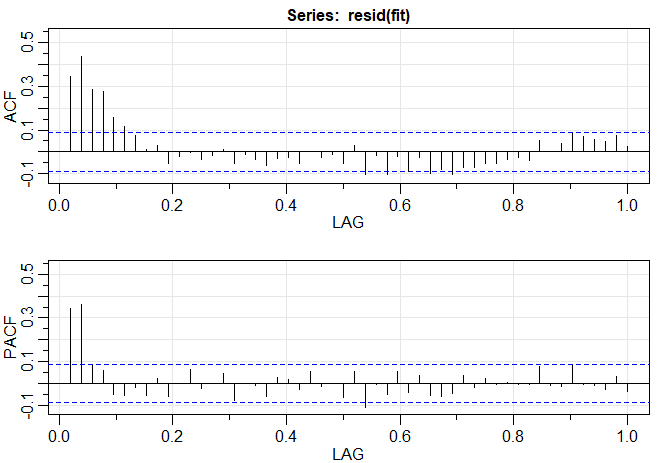 |
|---|
Nossa próxima etapa é ajustar o modelo de erro correlacionado mostrado acima, mas onde \(X_t\) é \(AR(2)\), \begin{equation} X_t \, = \, \phi_1 X_{t-1}+\phi_2 X_{t-2}+W_t, \end{equation} e \(W_t\) é um ruído branco. O modelo pode ser ajustado usando a função sarima da seguinte forma:
 |
|---|
A saída de análise dos resíduos do sarima não mostra nenhum problema óbvio de afastamento dos resíduos de um ruído branco.
No Exemplo II.29 ajustamos o modelo \begin{equation} R_t \, = \, \beta_0+\beta_1 S_{t-6}+\beta_2 D_{t-6}+\beta_3 D_{t-6} S_{t-6}+W_t, \end{equation} onde \(R_t\) é o Recrutamento, \(S_t\) é SOI e \(D_t\) é uma variável fictícia que é 0 se \(S_t <0\) e 1 caso contrário. No entanto, a análise dos resíduos indica que os resíduos não são ruído branco. O ACF e o PACF amostrais dos resíduos indicam que um modelo \(AR(2)\) pode ser apropriado, o que é semelhante aos resultados do Exemplo III.44.
 | 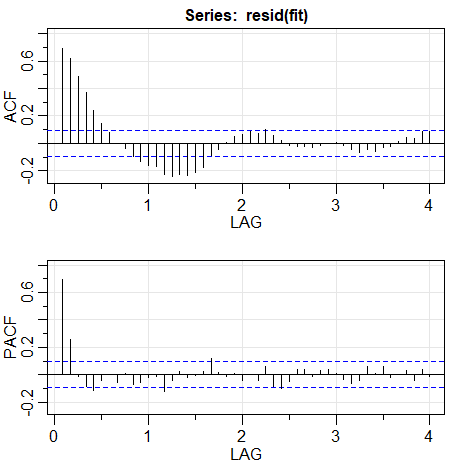 |
|---|
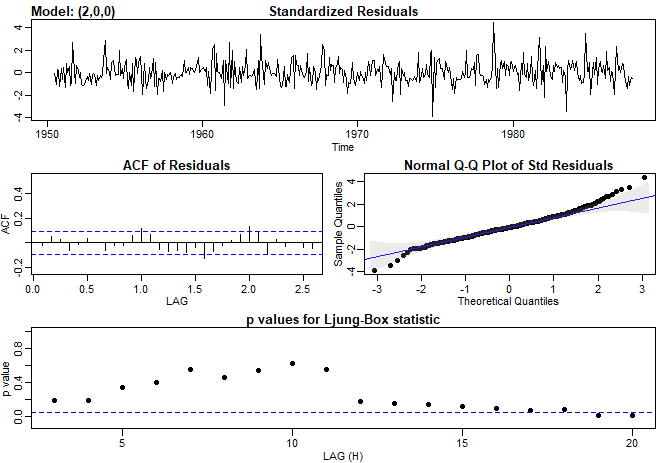 |
|---|
III.9 Modelos ARIMA sazonais multiplicativos
Nesta seção, introduzimos várias modificações feitas no modelo ARIMA para considerar o comportamento sazonal e não-estacionário. Muitas vezes, a dependência do passado tende a ocorrer mais fortemente em múltiplos de alguns lag \(s\) sazonais subjacentes. Por exemplo, com dados econômicos mensais, há um forte componente anual ocorrendo em lags que são múltiplos de \(s = 12\), devido às fortes conexões de todas as atividades ao ano civil. Os dados obtidos trimestralmente exibirão o período anual repetitivo em \(s = 4\) trimestres. Fenômenos naturais como a temperatura também têm componentes fortes correspondentes às estações do ano. Assim, a variabilidade natural de muitos processos físicos, biológicos e econômicos tende a combinar com as flutuações sazonais. Por causa disso, é apropriado introduzir polinômios autorregressivos de médias móveis que se identifiquem com as defasagens sazonais. O modelo resultante de médias móveis autorregressivo puro resultante, digamos, \(ARMA(P,Q)\), então assume a forma \begin{equation} \Phi_{_P}(B^s)X_t \, = \, \Theta_{_Q}(B^s)W_t, \end{equation} onde os operadores \begin{equation} \Phi_{_P} \, = \, 1-\Phi_1B^s - \Phi_2 B^{2s}-\cdots -\Phi_{_P}B^{Ps} \end{equation} e \begin{equation} \Theta_{_Q} \, = \, 1+\Theta_1B^s + \Theta_2 B^{2s}+\cdots +\Theta_{_Q}B^{Qs}, \end{equation} são o operador autoregressivo sazonal e o operador de médias móveis sazonal das ordens \(P\) e \(Q\), respectivamente, com o período sazonal \(s\).
Analogamente às propriedades dos modelos de ARMA não sazonais, o \(ARMA(P,Q)_s\) puro e sazonal é causal apenas quando as raízes de \(\Phi_{_P}(z^s)\) se situam fora do círculo unitário, e é invertível somente quando as raízes de \(\Theta_{_Q}(z^s)\) estão fora do círculo unitário.
Uma série autorregressiva sazonal de primeira ordem que pode ser executada ao longo de meses pode ser escrita como \begin{equation} (1-\Phi B^{12})X_t \, = \, W_t \end{equation} ou \begin{equation} X_t \, = \, \Phi X_{t-12}+W_t\cdot \end{equation}
Este modelo exibe a série \(X_t\) em termos de atrasos passados no múltiplo do período sazonal anual \(s = 12\) meses. Fica claro, a partir da forma acima, que a estimação e previsão para tal processo envolve apenas modificações diretas do caso de defasagem unitária já tratado. Em particular, a condição causal requer \(|\Phi|<1\).
Simulamos 3 anos de dados do modelo com \(\Phi =0.9\), e exibimos o ACF teórico e o PACF do modelo. Veja a figura. |
|---|
Dados gerados a partir de um \(AR(1)\) sazonal, \(s = 12\) e o ACF verdadeiro e PACF do modelo \(X_t =0.9 X_{t-12}+W_t\).
Para o modelo de MA sazonal de primeira ordem, \(s = 12\), \(X_t = W_t + \Theta W_{t-12}\) podemos verificar que \begin{equation} \gamma(0) \, = \, (1+\Theta^2)\sigma^2, \qquad \gamma(\pm 12) \, = \, \Theta \sigma^2 \qquad \mbox{e} \qquad \gamma(h) \, = \, 0, \; \quad \mbox{caso contrário}\cdot \end{equation} Assim, a única correlação não nula, além do desfasamento zero, é \begin{equation} \rho(\pm 12) \, = \, \dfrac{\Theta}{1+\Theta^2}\cdot \end{equation}
Para o modelo de AR sazonal de primeira ordem, \(s = 12\), usando as técnicas do \(AR(1)\) não sazonal, temos \begin{equation} \gamma(0) \, = \, \dfrac{\sigma^2}{1-\Phi^2}, \qquad \gamma(\pm 12k) \, = \, \dfrac{\sigma^2\Phi^k}{1-\Phi^2}, \; k=1,2,\cdots \qquad \mbox{e} \qquad \gamma(h) \, = \, 0, \; \quad \mbox{caso contrário}\cdot \end{equation} Neste caso, as únicas correlações não nulas são \(\rho(\pm 12k)=\Phi^k\), \(k=0,1,2,\cdots\).
Estes resultados podem ser verificados usando o resultado geral que \(\gamma(h)=\Phi_{_\gamma}(h-12)\), para \(h\geq 1\). Por exemplo, quando \(h = 1\), \(\gamma(1) = \Phi_{_\gamma}(11)\), mas quando \(h = 11\), temos \(\gamma(11) = \Phi_{_\gamma}(1)\), o que implica que \(\gamma(1) = \gamma(11)= 0\). Além desses resultados, o PACF tem as extensões análogas de modelos não sazonais a sazonais. Esses resultados são demonstrados na figura acima.
Como critério inicial de diagnóstico, podemos usar as propriedades das séries autorregressivas sazonais e de médias móveis sazonais listadas na Tabela abaixo.
| \(AR(P)_s\) | \(MA(Q)_s\) | \(ARMA(P,Q)_s\) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| \(ACF^*\) | Cauda em retardos \(k s\) | Corta depois | Cauda em retardos | ||||||
| \(k=1,2,\cdots\) | lag \(Q_s\) | lags \(k s\) | |||||||
| \(PACF^*\) | Corta depois | Cauda em retardos \(k s\) | Cauda em retardos | ||||||
| lag \(P s\) | \(k=1,2,\cdots\) | lags \(k s\) |
*Os valores em atrasos não sazonais \(h\neq ks\), para \(k=1,2,\cdots\), são zero.
Como critério inicial de diagnóstico, podemos usar as propriedades das séries autorregressivas sazonais e de médias móveis sazonais listadas na Tabela III.3. Essas propriedades podem ser consideradas como generalizações das propriedades para modelos não sazonais que foram apresentadas na Tabela III.1.
Em geral, podemos combinar os operadores sazonais e não sazonais em um modelo de média móvel autorregressivo sazonal multiplicativo, denotado por \(ARMA(p,q)\times (P,Q)_s\) e escrever \begin{equation} \Phi_{_P}(B^s)\phi(B)X_t \, = \, \Theta_{_Q}(B^s)\theta(B)W_t, \end{equation} como o modelo geral. Embora as propriedades de diagnóstico na Tabela III.3 não sejam estritamente verdadeiras para o modelo global misto, o comportamento do ACF e do PACF tende a mostrar padrões aproximados da forma indicada. De fato, para modelos mistos, tendemos a ver uma mistura dos fatos listados na Tabela III.1 e na Tabela III.3. Na adaptação de tais modelos, a focalização nos componentes de média regressiva e média móvel sazonal geralmente leva a resultados mais satisfatórios.
Considere o modelo \(ARMA(0,1)\times (1,0)_{12}\) \begin{equation} X_t \, = \, \Phi X_{t-12}+W_t+\theta W_{t-1}, \end{equation} onde \(|\Phi|< 1\) e \(|\theta|< 1\). Então, devido à que \(X_{t-12}\), \(W_t\) e \(W_{t-1}\) são não correlacionados e \(X_t\) é estacionário, \(\gamma(0)=\Phi^2 \gamma(0)+\sigma_{_W}^2+\theta^2 \sigma_{_W}^2\) ou \begin{equation} \gamma(0)=\dfrac{1+\theta^2}{1-\Phi^2}\sigma_{_W}^2\cdot \end{equation} Além disso, multiplicando o modelo por \(X_{t-h}\), \(h>0\) e tomando esperança, temos \(\gamma(1)=\Phi_{_\gamma}(11)+\theta\sigma_{_W}^2\) e \(\gamma(h)=\Phi_{_\gamma}(h-12)\), para \(h\geq 2\). Assim, o ACF para este modelo é \begin{equation} \begin{array}{rcl} \rho(12 h) & = & \Phi^h, \qquad h=1,2,\cdots \\ \rho(12 h-1) & = & \rho(12 h +1) \, = \, \displaystyle \frac{\theta}{1+\theta^2}\Phi^h, \qquad h=0,1,2,\cdots, \\ \rho(h) & = & 0, \qquad \mbox{caso contrário} \end{array} \end{equation}
O ACF e o PACF para este modelo, com \(\Phi=0.8\) e \(\theta=-0.5\), são mostrados na figura. Esse tipo de relação de correlação, embora idealizado aqui, é tipicamente visto com dados sazonais.
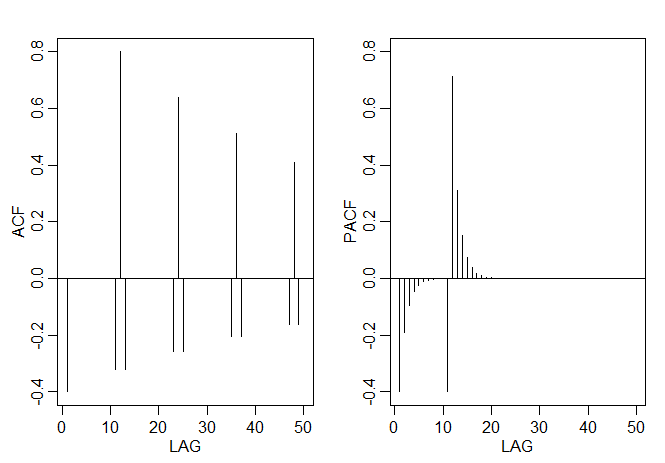 |
|---|
A persistência sazonal ocorre quando o processo é quase periódico na temporada. Por exemplo, com temperaturas médias mensais ao longo dos anos, cada janeiro seria aproximadamente o mesmo, cada fevereiro seria aproximadamente o mesmo e assim por diante. Nesse caso, podemos pensar na temperatura média mensal \(X_t\) como sendo modelada como \begin{equation} X_t \, = \, S_t + W_t, \end{equation} onde \(S_t\) é um componente sazonal que varia um pouco de um ano para o outro, de acordo com um passeio aleatório, \begin{equation} S_t \, = \, S_{t-12}+V_t\cdot \end{equation}
Neste modelo, \(W_t\) e \(V_t\) são processos de ruído branco não correlacionados. A tendência dos dados para seguir este tipo de modelo será exibida em uma amostra de ACF que é grande e decai muito lentamente nas defasagens \(h = 12k\), para \(k = 1,2,\cdots\). Se subtrairmos o efeito de anos sucessivos um do outro, descobriremos que \begin{equation} (1-B^{12})X_t \, = \, X_t - X_{t-12} \, = \, V_t+W_t-W_{t-12}\cdot \end{equation}
Este modelo é um \(MA(1)_{12}\) estacionário e o seu ACF terá um pico apenas na defasagem 12. Em geral, a diferenciação sazonal pode ser indicada quando o ACF decai lentamente em múltiplos de algumas estações, mas é insignificante entre os períodos. Então, uma diferença sazonal da ordem \(D\) é definida como \begin{equation} \nabla_s^D X_t \, = \, (1-B^s)^D X_t, \end{equation} onde \(D=1,2,\cdots\) assume valores inteiros positivos. Normalmente, \(D = 1\) é suficiente para obter estacionariedade sazonal. Incorporar essas ideias em um modelo geral leva à seguinte definição.
A modelo multiplicativo sazonal autoregressivo integrado de médias móveis ou modelo SARIMA é dado por \begin{equation} \Phi_{_P}(B^s)\phi(B)\nabla_s^D\nabla^d X_t \, = \, \delta+\Theta_{_Q}(B^s)\theta(B)W_t, \end{equation} onde \(W_t\) é o processo habitual de ruído branco gaussiano. O modelo geral é denotado como \(ARIMA(p,d,q)\times (P,D,Q)_s\). As componentes autorregressiva e de médias móveis são representadas pelos polinômios \(\phi(B)\) e \(\theta(B)\) de ordem \(p\) e \(q\), respectivamente, e as componentes autorregressiva e de médias móveis sazonal por \(\Phi_{_P}(B^s)\) e \(\Theta_{_Q}(B^s\) de ordem \(P\) e \(Q\) assim como as componentes das diferenças ordinárias e sazonal por \(\nabla^d=(1-B)^d\) e \(\nabla^D_s=(1-B^s)^D\).
Considere o modelo a seguir, que geralmente fornece uma representação razoável para séries temporais sazonais e não-estacionárias. Exibimos as equações do modelo, denotadas por \(ARIMA(0,1,1)\times (0,1,1)_{12}\) na notação acima, onde as flutuações sazonais ocorrem a cada 12 meses. Então, com \(\delta=0\), o modelo na Definição III.12 torna-se \begin{equation} \nabla_{12}\nabla X_t \, = \, \Theta(B^{12})\theta(B)W_t, \end{equation} ou \begin{equation} (1-B^{12})(1-B)X_t \, = \, (1+\Theta B^{12})(1+\theta B)W_t\cdot \end{equation}
Expandir ambos os lados da expressão acime leva à representação \begin{equation} (1-B-B^{12}+B^{13})X_t \, = \, (1+\theta B+\Theta B^{12}+\Theta\theta B^{13})W_t, \end{equation} ou na forma de equações de diferença \begin{equation} X_t \, = \, X_{t-1}+X_{t-12}-X_{t-13}+W_t+\theta W_{t-1}+\Theta W_{t-12}+\Theta\theta W_{`t-13}\cdot \end{equation}
Note que a natureza multiplicativa do modelo implica que o coeficiente de \(W_{t-13}\) é o produto dos coeficientes de \(W_{t-1}\) e \(W_{t-12}\), em vez de um parâmetro livre. A suposição do modelo multiplicativo parece funcionar bem com muitos conjuntos de dados de séries temporais sazonais, reduzindo o número de parâmetros que devem ser estimados.
Selecionar o modelo apropriado para um dado conjunto de dados de todos aqueles representados pela expressão geral na Definição III.12 é uma tarefa difícil e geralmente pensamos primeiro em termos de encontrar operadores de diferenças que produzam uma série aproximadamente estacionária e então em termos de encontrar um conjunto autorregressivo de médias móveis simples ou ARMA sazonal multiplicativo para se ajustar à série residual resultante. As operações de diferenciação são aplicadas primeiro e, em seguida, os resíduos são construídos a partir de uma série de comprimentos reduzidos. Em seguida, o ACF e o PACF desses resíduos são avaliados. Os picos que aparecem nessas funções podem ser eliminados com o ajuste de um componente autorregressivo ou de médias móveis de acordo com as propriedades gerais apresentadas na Tabela III.1 e na Tabela III.3. Ao considerar se o modelo é satisfatório, as técnicas de diagnóstico discutidas na Seção III.7 ainda se aplicam.
Consideramos o conjunto de dados R AirPassengers, que são os totais mensais de passageiros de linhas aéreas internacionais entre 1949 a 1960, retirados do livro de Box & Jenkins (1970). Vários gráficos dos dados e dados transformados são mostrados nas figuras a seguir e foram obtidos da forma apresentada.
 |
|---|
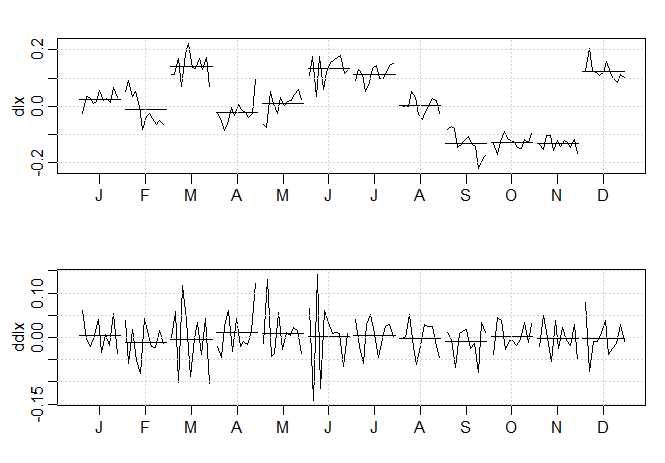 |
|---|
Observe que \(x\) é a série original, que mostra tendência mais variação crescente. O logaritmo dos dados estão registrados em \(lx\) e a transformação estabiliza a variação. O logaritmo dos dados são então diferenciados para remover a tendência e são armazenados em \(dlx\). É claro que ainda há persistência nas estações, ou seja, \(dlx_t \approx dlx_{t-12}\), de modo que uma diferença de décima segunda ordem seja aplicada e armazenada em \(ddlx\). Os dados transformados parecem estar estacionários e agora estamos prontos para estimar o modelo.
As funções ACF e PACF amostrais de \(ddlx\), ou seja, de \(\nabla_{12}\nabla \log(x_t)\) são mostradas na figura a seguir. O código R é: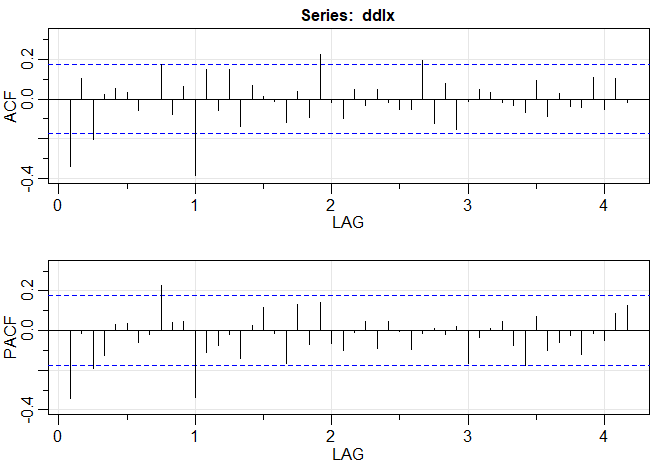 |
|---|
Componente sazonal: parece que nas estações do ano o ACF está cortando um atraso ou lag de \(1s\), \(s = 12\), enquanto o PACF está diminuindo nos intervalos \(1s, 2s, 3s, 4s,\cdots\). Estes resultados implicam um modelo \(SMA(1)\), \(P = 0\), \(Q = 1\), na estação \(s = 12\).
Componente não sazonal: inspecionando a amostra ACF e PACF nos desfasamentos inferiores, parece que ambos estão diminuindo. Isso sugere um modelo \(ARMA(1,1)\) dentro das estações \(p=q=1\).
Assim, primeiro tentamos um modelo \(ARIMA(1,1,1)\times (0,1,1)_{12}\) no logaritmo dos dados.No entanto, o parâmetro AR não é significativo, então devemos tentar eliminar um parâmetro da parte dentro das estações. Neste caso, tentamos ambos os modelos \(ARIMA(0,1,1)\times (0,1,1)_{12}\) e \(ARIMA(1,1,0)\times (0,1,1)_{12}\).
Todos os critérios de informação preferem o modelo \(ARIMA(0,1,1)\times (0,1,1)_{12}\), que é o modelo ajustado no objeto modelo1. Os diagnósticos dos resíduos são mostrados na figura abaixo e, com exceção de um ou dois outliers, o modelo parece se encaixar bem.
Análise dos resíduos do modelo \(ARIMA(0,1,1)\times (0,1,1)_{12}\) aplicado ao conjunto de dados de passageiros aéreos registados.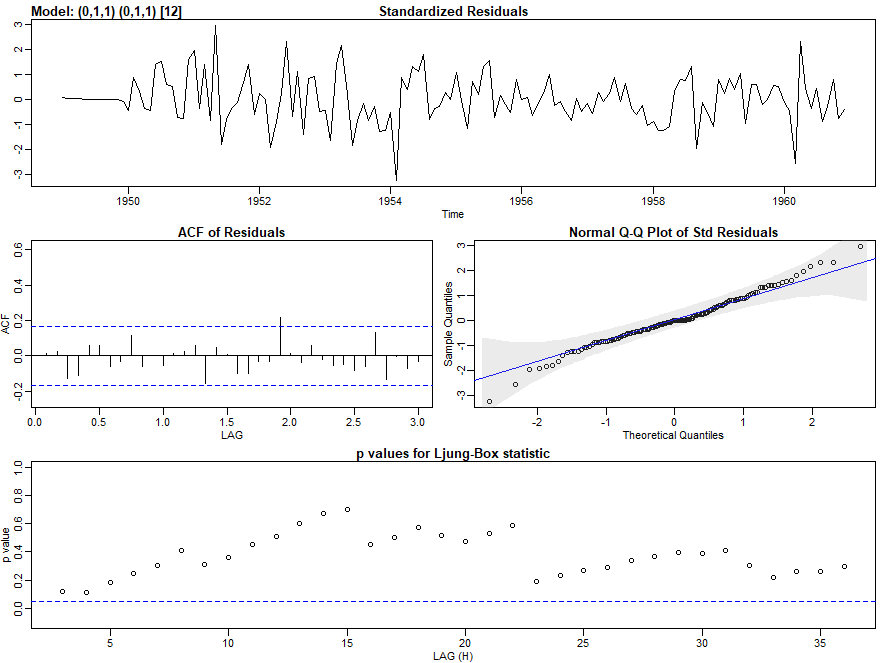 |
|---|
Finalmente, projetamos os dados registrados em doze meses e os resultados são mostrados na figura abaixo.
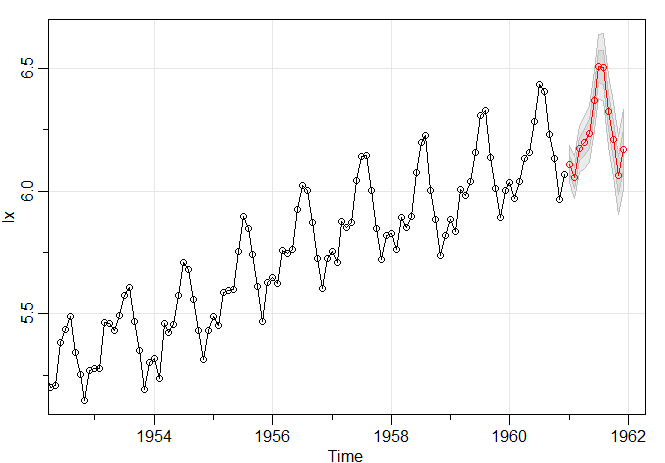 |
|---|
III.10 Exercícios
- Para um modelo \(MA(1)\), \(X_t = W_t + \theta W_{t-1}\), mostrar que \(|\rho_{_X}(1)|\leq 1/2\) para qualquer número \(\theta\). Para quais valores de \(\theta\), \(\rho_{_X}(1)\) não atinge seu máximo e mínimo?
- Sejam \(\{W_t \, : \, t=0,1,\cdots\}\) um processo de ruído branco com variância \(\sigma_{_W}^2\) e seja \(|\phi|< 1\) uma
constante. Considere o processo \(X_0=W_0\) e
\begin{equation}
X_t \, = \, \phi X_{t-1}+W_t, \qquad t=1,2,\cdots\cdot
\end{equation}
Podemos usar este método para simular um processo \(AR(1)\) a partir do ruído branco simulado.
- (a) Mostre que \(X_t=\sum_{j=0}^t \phi^j W_{t-j}\) para qualquer \(t=1,2,\cdots\).
- (b) Encontre \(\mbox{E}(X_t)\).
- (c) Mostre que, para \(t=0,1,\cdots\) \begin{equation} \mbox{Var}(X_t) \, = \, \dfrac{\sigma_{_W}^2}{1-\phi^2}\big( 1-\phi^{2(t+1)}\big)\cdot \end{equation}
- (d) Mostre que, para \(h\geq 0\), \(\mbox{Cov}(X_{t+h},X_t)=\phi^h\mbox{Var}(X_t)\).
- (e) É \(X_t\) estacionário?
- (f) Argumente que, quando \(t\to\infty\), o processo se torna estacionário, então, em certo sentido, \(X_t\) é assintoticamente estacionário.
- (g) Comente como poderiamos usar esses resultados para simular \(n\) observações de um modelo estacionário Gaussiano \(AR(1)\) a partir de valores de independentes identicamente distribuídos \(N(0,1)\) simulados.
- (h) Agora suponha que \(X_0=W_0\sqrt{1-\phi^2}\). Este é um processo estacionário?
- Verifique os cálculos feitos no Exemplo III.4 da seguinte forma:
- (a) Seja \(X_t=\phi X_{t-1}+W_t\), onde \(|\phi|>1\) e \(W_t\sim N(0,\sigma_{_W}^2)\) independentes. Mostre que \(\mbox{E}(X_t)=0\) e \(\gamma_{_X}(h)=\sigma_{_W}^2 \phi^{-2}\phi^{-h}/(1-\phi^{-2})\), para \(h\geq 0\).
- (b) Seja \(Y_t=\phi^{-1}Y_{t-1}+V_t\) onde \(V_t\sim N(0,\sigma_{_W}^2\phi^{-2})\) e \(\phi\) e \(\sigma_{_W}\) são como na parte (a). Verifique se a função de média e de autocovariância de \(Y_t\) são as mesmas de \(X_t\).
- Identifique os seguintes modelos como modelos \(ARMA(p,q)\), atente para a redundância de parâmetros e determine se eles
são causais e ou invertíveis:
- (a) \(X_t=0.80 X_{t-1}-0.15 X_{t-2}+W_t-0.30 W_{t-1}\).
- (b) \(X_t=X_{t-1}-0.50 X_{t-2}+W_t-W_{t-1}\).
- Mostre que um modelo \(AR(2)\) é causal se, e somente se, as condições mostrados no Exemplo III.9 forem válidas, ou seja, mostre que um modelo \(AR(2)\) é causal se, e somente se, \(\phi_1+\phi_2< 1\), \(\phi_2-\phi_1< 1\) e \(|\phi_2|< 1\).
- Para o modelo \(AR(2)\) dado por \(X_t = -0.9 X_{t-2}+W_t\), encontre as raízes do polinômio autoregressivo e, em seguida, trace o ACF, \(\rho(h)\).
- Para as séries \(AR(2)\) mostradas abaixo, use os resultados do Exemplo III.10 para determinar um conjunto de equações em
diferença que podem ser usadas para encontrar o ACF \(\rho(h)\), \(h = 0,1,\cdots\); resolva para encontrar as constantes no ACF usando as
condições iniciais. Em seguida, plote os valores do ACF para o lag ou atraso 10, use o ARMAacf como uma verificação
das suas respostas.
- (a) \(X_t+1.60 X_{t-1}+0.64 X_{t-2} \, = \, W_t\)
- (b) \(X_t-0.40 X_{t-1}-0.45 X_{t-2} \, = \, W_t\)
- (c) \(X_t-1.20 X_{t-1}+0.85 X_{t-2} \, = \, W_t\)
- Verifique os cálculos para a função de autocorrelação de um processo \(ARMA(1,1)\) dado no Exemplo III.14. Compare a forma com o ACF para o \(ARMA(1,0)\) e o \(ARMA(0,1)\). Plote os ACFs das três séries no mesmo gráfico para \(\phi=0.6\) e \(\theta =0.9\) e comente as capacidades de diagnóstico do ACF neste caso.
- Gere \(n = 100\) observações de cada um dos três modelos discutidos no Exercício III.8. Calcule o ACF amostral para cada modelo e compare-a com os valores teóricos. Calcule o PACF amostral para cada uma das séries geradas e compare as ACF e PACF amostrais com os resultados gerais apresentados na Tabela III.1.
- Seja \(X_t\) um processo que represente a série de mortalidade cardiovascular cmort discutida no Exemplo II.2.
- (a) Ajuste um modelo \(AR(2)\) à \(X_t\) usando regressão linear como no Exemplo III.18.
- (b) Assumindo que o modelo ajustado em (a) seja o modelo verdadeiro, encontre as previsões ao longo de um horizonte de quatro semanas, \(X_{n+m}^n\) para \(m=1,2,3,4\) e os intervalos de previsão de 95% correspondentes.
- Considere a série \(MA(1)\)
\begin{equation}
X_t \, = W_t+\theta W_{t-1},
\end{equation}
onde \(W_t\) é um ruído branco com variáncia \(\sigma_{_W}^2\).
- (a) Encontre o mínimo do erro quadrático médio da previsão de um passo à frente com base no passado infinito e determine o erro quadrático médio dessa previsão.
- (b) Seja \(\widetilde{X}_{n+1}^n\) a previsão truncada de um passo à frente como dada na Proposição III.7. Mostre que \begin{equation} \mbox{E}\Big(\big(X_{n+1}- \widetilde{X}_{n+1}^n\big)^2 \Big) \, = \, \sigma^2\big(1+\theta^{2+2n}\big)\cdot \end{equation} Compare o resultado com (a) e indique o quão bem a aproximação finita funciona neste caso.
- No contexto da equação \(\Gamma_n \phi_n \, = \, \gamma_n\), mostre que \(\gamma(0)>0\) e \(\gamma(h)\to 0\), quando \(h\to\infty\), então \(\Gamma_n\) é definida positiva.
- Suponha que \(X_t\) seja estacionário com média zero e lembre a Definição III.9 do PACF. Isto é,
\begin{equation}
\epsilon_t \, = \, X_t-\displaystyle \sum_{i=1}^{h-1} a_i X_{t-i} \qquad \mbox{e} \qquad
\delta_{t-h} \, = \, X_{t-h}-\sum_{j=1}^{h-1} b_j X_{t-j},
\end{equation}
sejam os dois resíduos onde \(\{a_1,\cdots,a_{h-1}\}\) e \(\{b_1,\cdots,b_{h-1}\}\) foram escolhidos para minimizar os erros
quadráticos médios
\begin{equation}
\mbox{E}\big(\epsilon_t^2\big) \qquad \mbox{e} \qquad \mbox{E}\big(\delta_{t-h}^2\big)\cdot
\end{equation}
O PACF no atraso ou lag \(h\) foi definido como a correlação cruzada entre \(\epsilon_t\) e \(\delta_{t-h}\), ou seja,
\begin{equation}
\phi_{h,h} \, = \, \frac{\displaystyle \mbox{E}(\epsilon_t\delta_{t-h})}{\displaystyle\sqrt{\mbox{E}\big(\epsilon_t^2\big)\mbox{E}\big(\delta_{t-h}^2\big)}}\cdot
\end{equation}
Seja \(R_h\) uma matriz \(h\times h\) com elementos \(\rho(i-j)\) para \(i,j=1,\cdots,h\) e seja \(\rho_h=\big(\rho(1),\rho(2),\cdots,\rho(h)\big)^\top\) o vetor
de atrasos ou lag autocorrelacionados \(\rho(h)=\mbox{Corr}(X_{t+h},X_t)\). Seja \(\widetilde{\rho}_h=\big(\rho(h),\rho(h-1),\cdots,\rho(1)\big)^\top\) o
vetor reverso. Mais ainda, seja \(X_t^h\) o melhor preditor linear de \(X_t\) dados \(\{X_{t-1},\cdots,X_{t-h}\}\):
\begin{equation}
X_t^h \, = \, \alpha_{h,1}X_{t-1}+\cdots+\alpha_{h,h}X_{t-h},
\end{equation}
como descrito no Teorema III.3. Prove que
\begin{equation}
\phi_{h,h} \, = \, \frac{\displaystyle \rho(h)-\widetilde{\rho}_{h-1}^\top R_{h-1}^{-1}\rho_h}{\displaystyle 1-\widetilde{\rho}_{h-1}^\top R_{h-1}^{-1}\widetilde{\rho}_{h-1}} \, = \, \alpha_{h,h}\cdot
\end{equation}
Em particular, este resultado prova o Teorema III.4.
Sugestão: divida o sistema equações de predição \(\Gamma_n \phi_n = \gamma_n\) por \(\gamma(0)\) e escreva a equação matricial na forma particionada como \begin{equation} \begin{pmatrix} R_{h-1} & \widetilde{\rho}_{h-1} \\ \widetilde{\rho}_{h-1}^\top & \rho(0) \end{pmatrix} \begin{pmatrix} \alpha_1 \\ \alpha_{h,h} \end{pmatrix} \, = \, \begin{pmatrix} \rho_{h-1} \\ \rho(h) \end{pmatrix}, \end{equation} onde o vetor \(h\times 1\) de coeficientes \(\alpha=\big(\alpha_{h,1},\cdots,\alpha_{h,h} \big)^\top\) é paticionado como \((\alpha_1^\top,\alpha_{h,h})^\top\). - Suponha que desejamos encontrar uma função de predição \(g(x)\) que minimize
\begin{equation}
MSE \, = \, \mbox{E}\Big(\big(Y-g(x)\big)^2 \Big),
\end{equation}
onde \(X\) e \(Y\) são variáveis aleatórias com função densidade conjunta \(f(x,y)\).
- (a) Mostre que o MSE é minimizado pela escolha \(g(x)=\mbox{E}(Y|X)\).
Sugestão: \(\displaystyle \mbox{E}\Big(\mbox{E}\Big(\big( Y-g(X)\big)^2 \, | \, X \Big)\Big)\). - (b) Aplique o resultado acima ao modelo \(Y=X^2+z\), onde \(X\) e \(z\) são variáveis aleatórias independentes com média zero e variância um. Mostre que \(MSE=1\).
- (c) Suponha que restringimos nossas escolhas para a função \(g(x)\) para funções lineares da forma \begin{equation} g(X) \, = \, a + bX, \end{equation} e determine \(a\) e \(b\) que minimizem \(MSE\). Mostre que \(a=1\), \(b=\mbox{E}(XY)⁄ \mbox{E}(X^2)\) e \(MSE=3\). O que você interpreta isso quer dizer?
- (a) Mostre que o MSE é minimizado pela escolha \(g(x)=\mbox{E}(Y|X)\).
- Para um modelo \(AR(1)\), determine a forma geral da previsão \(m\) passos à frente \(X_{t+m}^t\) e mostre que \begin{equation} \mbox{E}\Big( \big(X_{t+m}-X_{t+m}^t\big)^2\Big) \, = \, \sigma_{_W}^2\frac{1-\phi^{2m}}{1-\phi^2}\cdot \end{equation}
- Considere o modelo \(ARMA(1,1)\) discutido no Exemplo III.8, isto é, \(X_t = 0.9 X_{t-1}+0.5 W_{t-1}+W_t\). Mostre que a previsão truncada definido como \begin{equation} \widetilde{X}_{n+m}^n \, = \, -\sum_{j=1}^{m-1} \pi_j\widetilde{X}_{n+m-j}^n-\sum_{j=m}^{n+m-1} \pi_j X_{n+m-j}, \end{equation} que também é calculado recursivamente, \(m = 1,2,\cdots\) é equivalente à previsão truncada usando a fórmula recursiva mostrada na Proposição III.7.
- Verifique que para \(k\geq 1\) \begin{equation} \mbox{E}\Big(\big(X_{n+m}-\widetilde{X}_{n+m} \big)\big(X_{n+m+k}-\widetilde{X}_{n+m+k} \big) \Big) \, = \, \sigma_{_W}^2\sum_{j=0}^{m-1}\psi_j\psi_{j+k}\cdot \end{equation} Significa que, para um tamanho de amostra fixo, os erros de previsão do modelo ARMA estão correlacionados.
- Ajustar um modelo \(AR(2)\) para a série de mortalidade cardiovascular cmort discutida no Exemplo II.2. usando regressão linear e usando Yule-Walker.
- (a) Compare as estimativas dos parâmetros obtidos pelos dois métodos.
- (b) Compare os erros padrão estimados das estimativas dos coeficientes obtidos por regressão linear com suas aproximações assintóticas correspondentes, como dado no Teorema III.10.
- Suponha que \(X_1,\cdots,X_n\) são observações de um processo \(AR(1)\) com \(\mu= 0\).
- (a) Mostrar os backcasts ou previsão reversa podem ser escritos como \(X_t^n = \phi^{1-t} X_1\), para \(t\leq 1\).
- (b) Por sua vez, mostre que, para \(t\leq 1\), os erros da previsão reversa são \begin{equation} \widetilde{W}_t(\phi) \, = \, X_t^n -\phi X_{t-1}^n \, = \, \phi^{1-t}(1-\phi^2)X_1\cdot \end{equation}
- (c) Use o resultado de (b) para mostrar \(\displaystyle \sum_{t=-\infty}^1 \widetilde{W}_t(\phi)^2=(1-\phi^2)X_1^2\).
- (d) Use o resultado de (c) para verificar se a soma de quadrados incondicional, \(S(\phi)\), pode ser escrita como \(\sum_{t=-\infty}^1 \widetilde{W}_t(\phi)^2\).
- (e) Encontre \(X_t^{t-1}\) e \(r_t\) para \(1\leq t\leq n\) e mostre que \begin{equation} S(\phi) \, = \, \sum_{t=1}^n \frac{1}{r_t}\big( X_t-X_t^{t-1}\big)^2\cdot \end{equation}
- Repita o seguinte exercício numérico três vezes. Gere \(n = 500\) observações do modelo ARMA dado por \begin{equation} X_t \, = \, 0.9 X_{t-1}+W_t-0.9 W_{t-1}, \end{equation} com \(W_t\sim N(0,1)\) independentes. Plote os dados simulados, calcule o ACF e o PACF amostrais dos dados simulados e ajuste um modelo \(ARMA(1,1)\) aos dados. O que aconteceu e como você explica os resultados?
- Gere 10 realizações de comprimento \(n = 200\) cada de um processo \(ARMA(1,1)\) com \(\phi=0.9\), \(\theta=0.5\) e \(\sigma^2 = 1\). Encontre os MLEs dos três parâmetros em cada caso e compare os estimadores com os valores verdadeiros.
- Gere \(n = 50\) observações de um modelo Gaussian \(AR(1)\) com \(\phi=0.99\) e \(\sigma_{_W}^2 = 1\). Usando uma técnica de estimação de sua escolha, compare a distribuição assintótica aproximada de sua estimativa, a que você usaria para inferência, com os resultados de um experimento de Bootstrap, use \(B = 200\).
- Usando o Exemplo III.32 como seu guia, desenvolva o procedimento de Gauss-Newton para estimar o parâmetro autoregressivo \(\phi\), a partir do
modelo \(AR(1)\), \(X_t = \phi X_{t-1}+W_t\), dados \(X_1,\cdots,X_n\). Este procedimento produz o estimador incondicional ou condicional?
Dica: Escreva o modelo como \(W_t = X_t -\phi X_{t-1}\); sua solução deve funcionar como um procedimento não-recursivo. - Considere a série estacionária gerada por
\begin{equation}
X_t \, = \, \alpha+\phi X_{t-1}+W_t+\theta W_{t-1},
\end{equation}
onde \(\mbox{E}(X_t)=\mu\), \(|\theta|< 1\), \(|\phi|< 1\) e \(W_t\) são variáveis aleatórias independentes com média zero e
variância \(\sigma^2_W\).
- (a) Determine a média como uma função do modelo acima. Encontre a autocovariância e o ACF do processo \(X_t\) e mostre que o processo é fracamente estacionário. O processo é estritamente estacionário?
- (b) Prove que a distribuição limite quando \(n\to\infty\) da média da amostral, \begin{equation} \overline{X} \, = \, \frac{1}{n}\sum_{t=1}^n X_t, \end{equation} é normal e encontre sua média e variância em termos de \(\alpha\), \(\phi\), \(\theta\) e \(\sigma_{_W}^2\).
- Um problema de interesse na análise de séries temporais geofísicas envolve um modelo simples para dados observados
contendo um sinal e uma versão refletida do sinal com fator de amplificação desconhecido \(a\) e atraso de tempo desconhecido \(\delta\).
Por exemplo, a profundidade de um terremoto é proporcional ao tempo de atraso \(\delta\) para a onda \(P\) e sua forma refletida \(pP\)
em um registro sísmico. Suponha que o sinal, digamos \(s_t\), seja ruído branco Gaussiano com variância \(\sigma_s^2\)
e considere o modelo gerador
\begin{equation}
X_t \, = \, s_t+ a s_{t-\delta}\cdot
\end{equation}
- (a) Prove que o processo \(X_t\) é estacionário. Se \(|a|< 1\), mostre que \begin{equation} s_t \, = \, \sum_{j=0}^\infty (-a)^j X_{t-\delta j} \end{equation} é a média quadrada convergente a uma representação para o sinal \(s_t\), para \(t=1,\pm 1,\pm 2,\cdots\).
- (b) Se o atraso de tempo \(\delta\) for assumido como sendo conhecido, sugira um método computacional aproximado para estimar os parâmetros \(a\) e \(\sigma^2_s\) usando a máxima verossimilhança e o método de Gauss-Newton.
- (c) Se o atraso de tempo \(\delta\) for assumido como sendo desconhecido, especifiqu como poderíamos estimar os parâmetros incluindo \(\delta\). Gere \(n=500\) pontos da série com \(a=0.9\), \(\sigma_{_W}^2=1\) e \(\delta=5\). Estime o atraso de tempo inteiro \(\delta\) pesquisando sobre \(\delta=3,4,\cdots,7\).
- Previsão com parâmetros estimados: Seja \(X_1,X_2,\cdots,X_n\) uma amostra de tamanho \(n\) de um processo
causal \(AR(1)\), \(X_t = \phi X_{t-1}+W_t\). Seja \(\widehat{\phi}\) o estimador Yule-Walker de \(\phi\).
- (a) Mostre que \(\widehat{\phi}-\phi=O_P(n^{-1/2})\). Veja o Apêndice A para a definição de \(O_P(\cdot)\).
- (b) Seja \(X_{n+1}^n\) a previsão de um passo à frente de \(X_{n+1}\) dados \(X_1,\cdots,X_n\), baseado no parâmetro conhecido \(\phi\) e seja \(\widehat{X}_{n+1}^n\) a previsão de um passo à frente quando o parâmetro for substituído por \(\widehat{\phi}\). Mostrar que \(X_{n+1}^n-\widehat{X}_{n+1}^n=O_P(n^{-1/2})\)
- Suponha \begin{equation} Y_t \, = \, \beta_0+\beta_1 t+\cdots+\beta_q t^q+X_t, \qquad \beta_q\neq 0, \end{equation} onde \(X_t\) é estacionário. Primeiro, mostre que \(\nabla^k X_t\) é estacionário para qualquer \(k = 1,2,\cdots\) e então mostre que \(\nabla^k Y_t\) não é estacionário para \(k< q\), mas é estacionário para \(k\geq q\).
- Verifique se o modelo \(IMA(1,1)\), \(X_t=X_{t-1}+W_t-\lambda W_{t-1}\) com \(|\lambda|< 1\) para \(t=1,2,\cdots\) e \(X_0=0\), como apresentado do Exemplo III.38, pode ser invertido e escrito como \begin{equation} X_t \, = \, \sum_{j=1}^\infty (1-\lambda)\lambda^{j-1} X_{t-j} +W_t\cdot \end{equation}
- Para um modelo \(ARIMA(1,1,0)\) com tendência
\begin{equation}
(1-\phi B)(1-B)X_t=\delta+W_t,
\end{equation}
seja \(Y_t=(1-B)X_t=\nabla X_t\).
- (a) Observando que \(Y_t\) é \(AR(1)\), mostre que, para \(j\geq 1\), \begin{equation} Y_{n+j}^n \, = \, \delta\big(1+\phi+\cdots+\phi^{j-1} \big)+\phi^j Y_n\cdot \end{equation}
- (b) Use a parte (a) para mostrar que, para \(m=1,2,\cdots\), \begin{equation} X_{n+m}^n \, = \, X_n +\frac{\delta}{1-\phi}\left( m-\frac{\phi(1-\phi^m)}{1-\phi}\right)+(X_n-Z_{n-1})\frac{\phi(1-\phi^m)}{1-\phi}\cdot \end{equation} Dica: De (a), \begin{equation} X_{n+j}^n-X_{n+j-1}^n \, = \, \delta\frac{1-\phi^j}{1-\phi}+\phi^j(X_n-X_{n-1})\cdot \end{equation} Agora somamos ambos os lados ao longo de \(j\) de 1 para \(m\).
- (c) Use que \(P_{n+m}^n =\sigma_{_W}^2\sum_{j=0}^{m-1} {\psi_j^*}^2\), onde \({\psi_j^*}\) são os coeficientes de \(z^j\) em \(\psi^*(z)=\theta(z)/\phi(z)(1-z)^d\), para encontrar \(P_{n+m}^n\) mostrando primeiro que \(\psi_0^*=1\), \(\psi_1^*=(1+\phi)\) e \(\psi_j^*-(1+\phi)\psi_{j-1}^*+\phi\psi_{j-2}^*=0\) quando \(j\geq 2\), neste caso \(\psi_j^*=(1-\phi^{j+1})/(1-\phi)\), para \(j\geq 1\).
- Para o logaritmo dos dados das variedades glaciais paleoclimáticas, chamemos \(X_t\), apresentados no Exemplo III.33, use as primeiras 100 observações e calcule o EWMA, \(\widetilde{X}^t_{t+1}\), dado no Exemplo III.38 para \(t = 1,\cdots,100\), usando \(\lambda=0.25,0.50\) e \(\lambda=0.75\) e grafique os EWMA's e os dados sobrepostos uns aos outros. Comente os resultados.
- No Exemplo III.40, apresentamos os diagnósticos para o \(MA(2)\) ajustado à série de taxas de crescimento do PIB. Usando esse exemplo como guia, conclua o diagnóstico para o ajuste do \(AR(1)\).
- Os preços do petróleo bruto em dólares por barril são guardados em oil. Ajuste um modelo \(ARIMA(p,d,q)\) para a taxa de crescimento realizando todos os diagnósticos necessários. Comente.
- Ajuste um modelo \(ARIMA(p,d,q)\) para os dados da temperatura global em globtemp realizando todos os diagnósticos necessários. Depois de decidir sobre um modelo apropriado, faça uma previsão com limites de confiança para os próximos 10 anos. Comente.
- Ajuste um modelo \(ARIMA(p,d,q)\) para a série de dióxido de enxofre so2, realizando todos os diagnósticos necessários. Depois de decidir sobre um modelo apropriado, faça uma previsão dos dados para o futuro com quatro períodos de tempo à frente, cerca de um mês, e calcule os intervalos de previsão de 95% para cada uma das quatro previsões. Comente. O dióxido de enxofre é um dos poluentes monitorados no estudo de mortalidade descrito no Exemplo II.2.
- Consideremos que \(S_t\) representa os dados de vendas mensais em sales, \(n = 150\) e seja \(L_t\) o principal indicador em
lead.
- (a) Ajustar um modelo ARIMA para \(S_t\), os dados de vendas mensais. Discuta seu modelo passo-a-passo, apresentando seu (A) exame inicial dos dados, (B) transformações, se necessário, (C) identificação inicial das ordens de dependência e grau de diferenciação, (D) estimativas dos parâmetros, (E) diagnósticos dos resíduos e escolha do modelo.
- (b) Use os gráficos CCF e lag entre \(\nabla S_t\) e \(\nabla L_t\) para argumentar que uma regressão de \(\nabla S_t\) em \(\nabla L_t\) é razoável. Observe que, em lag2.plot(), a primeira série nomeada é aquela que fica defasada.
- (c) Ajuste o modelo de regressão \(\nabla S_t = \beta_0 + \beta_1\nabla L_{t-3} + X_t\), onde \(X_t\) é um processo ARMA. Explique como você decidiu o seu modelo para \(X_t\). Discuta seus resultados. Veja o Exemplo III.45 para ajudar na codificação deste problema.
- Um dos notáveis desenvolvimentos tecnológicos na indústria de computadores tem sido a capacidade de armazenar informações
densamente em um disco rígido. Além disso, o custo de armazenamento diminuiu constantemente, causando problemas de excesso de dados, em vez
de big datas. O conjunto de dados para esta tarefa é o cpg, que consiste no preço mediano anual de varejo por GB de discos rígidos,
digamos \(C_t\), de uma amostra de fabricantes de 1980 a 2008.
- (a) Mostre gráficamente \(C_t\) e descreva o que você vê.
- (b) Argumente que a curva \(C_t\) versus \(t\) se comporta como \(C_t\approx \alpha e^{\beta t}\) ajustando uma regressão linear de \(\log(C_t)\) em \(t\) e então plotando a linha ajustada para compará-la aos dados registrados. Comente.
- (c) Inspecione os resíduos do ajuste de regressão linear e comente.
- (d) Ajuste a regressão novamente, mas agora usando o fato de que os erros são autocorrelacionados. Comente.
- Refaça o Exercício 2 da Seção II.1, sem assumir que o termo de erro é ruído branco.
- Considere o modelo ARIMA
\begin{equation}
X_t \, = \, W_t +\Theta W_{t-2}\cdot
\end{equation}
- (a) Identifique o modelo usando a notação \(ARIMA(p,d,q)\times (P,D,Q)_s\).
- (b) Mostre que a série é invertível para \(|\Theta|< 1\) e encontre os coeficientes na representação \begin{equation} W_t \, = \, \sum_{k=0}^\infty \pi_k X_{t-k}\cdot \end{equation}
- (c) Desenvolva equações para a previsão \(m\) passos à frente \(\widetilde{X}_{n+m}\) e sua variância baseada no passado infinito \(X_n,X_{n-1},\cdots\).
- Trace o ACF do sazonal do modelo \(ARIMA(0,1)\times (1,0)_{12}\) com \(\Phi=0.8\) e \(\theta=0.5\).
- Ajuste um modelo sazonal ARIMA de sua escolha aos dados de preço de frango em chicken. Use o modelo estimado para prever os próximos 12 meses.
- Ajuste um modelo sazonal ARIMA de sua escolha para os dados de desemprego em unemp. Use o modelo estimado para prever os próximos 12 meses.
- Ajuste um modelo sazonal ARIMA de sua escolha para os dados de desemprego em UnempRate. Use o modelo estimado para prever os próximos 12 meses.
- Ajuste um modelo sazonal ARIMA de sua escolha para a série de nascidos vivos dos EUA birth. Use o modelo estimado para prever os próximos 12 meses.
- Ajustar um modelo sazonal ARIMA apropriado à série de lucros Johnson & Johnson jj transformada em logaritmo do Exemplo I.1. Use o modelo estimado para prever os próximos 4 trimestres.
- Suponha que \(\displaystyle X_t=\sum_{j=1}^p \phi_j X_{t-j}+W_t\) onde \(\phi_p\neq 0\) e \(W_t\) é um ruído branco de tal modo que \(W_t\) não está correlacionado com \(\{X_k \, : \, k< t\}\). Use o Teorema da Projeção, Teorema B.1, para mostrar que, para \(n> p\), o melhor preditor linear de \(X_{n+1}\) em \(\overline{\mbox{sp}}\{X_k \, : \, k\leq n\}\) é \begin{equation} \widehat{X}_{n+1} \, = \, \sum_{j=1}^p \phi_j X_{n+1-j}\cdot \end{equation}
- Considere a série \(X_t=W_t-W_{t-1}\), onde \(W_t\) é um processo de ruído branco com média zero e variância
\(\sigma_{_W}^2\). Suponha que consideremos o problema de prever \(X_{n+1}\) baseado em apenas \(X_1,\cdots,X_n\). Use o Teorema da Projeção
para responder às perguntas abaixo.
- (a) Mostrar que o melhor preditor linear é \(\displaystyle X_{n+1}^n = -\frac{1}{n+1}\sum_{k=1}^n k X_k\).
- (b) Prove que o erro quadrático médio é \(\displaystyle \mbox{E}\big( X_{n+1}-X_{n+1}^n\big)^2=\frac{n+2}{n+1}\sigma_{_W}^2\).