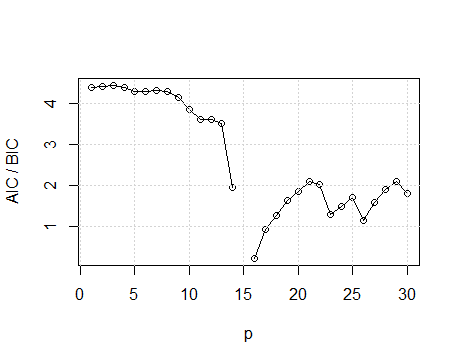
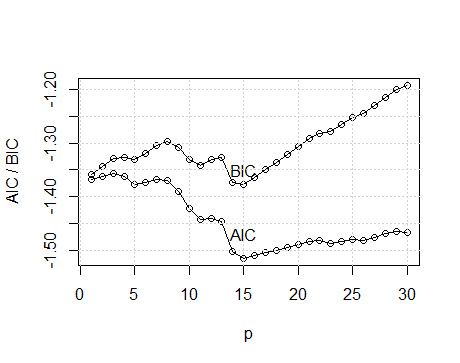
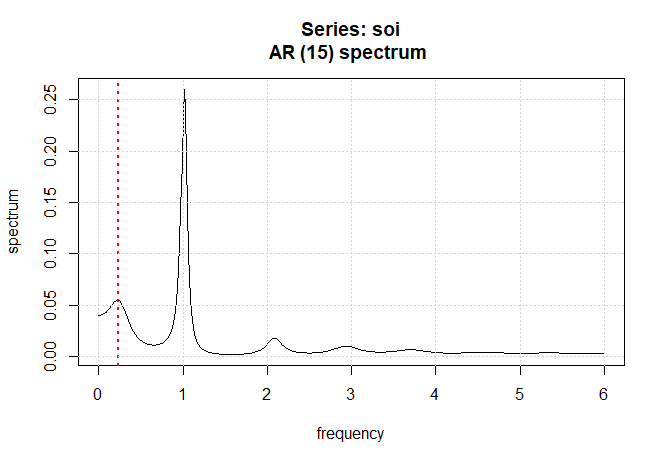
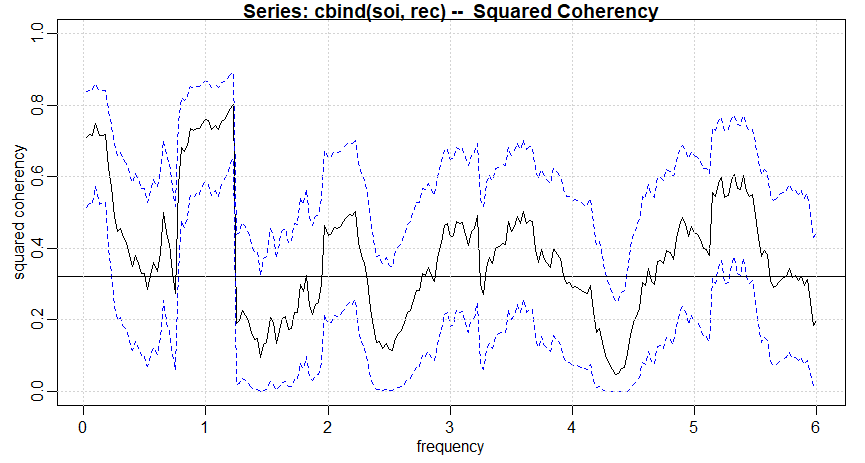
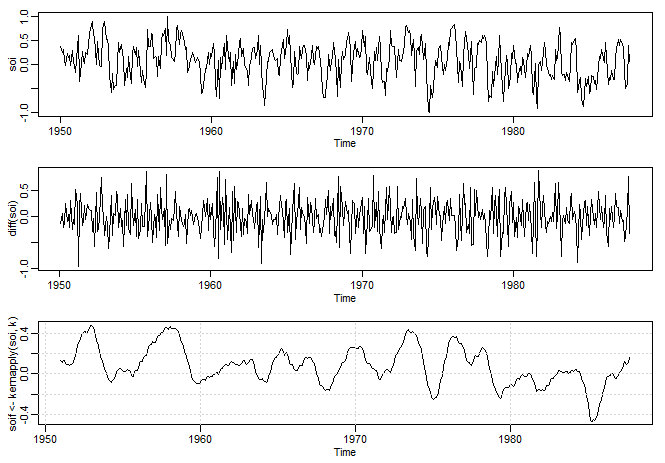
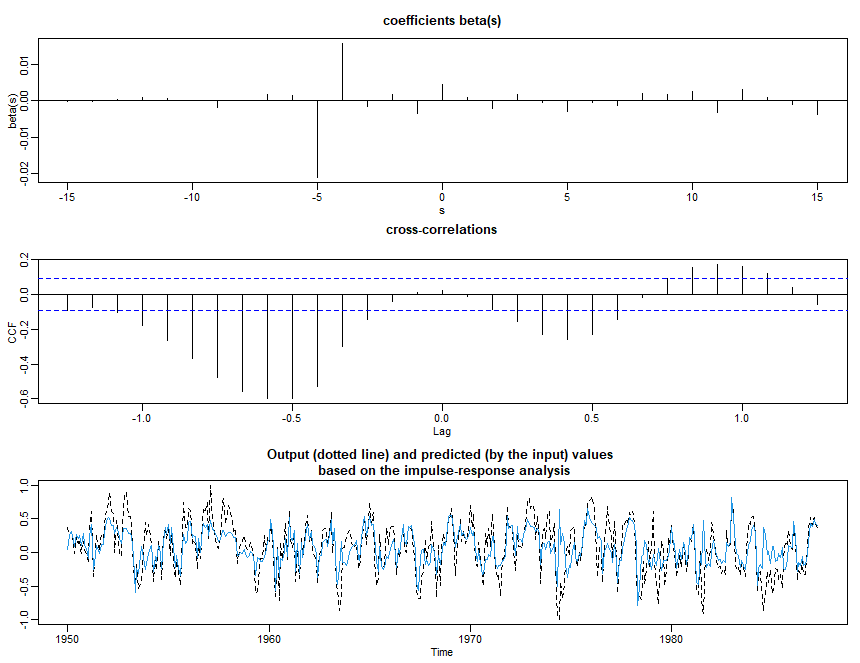
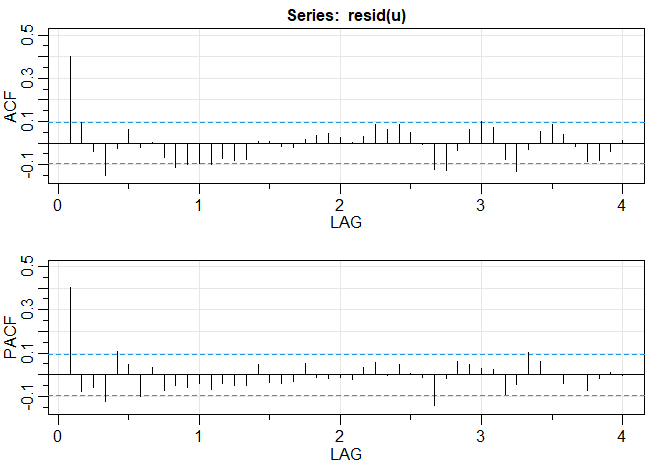
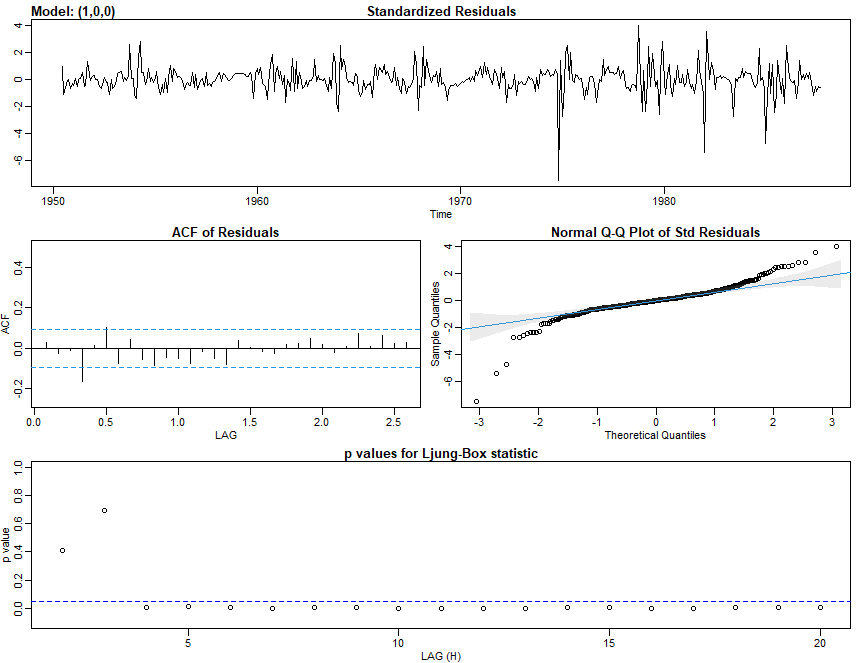
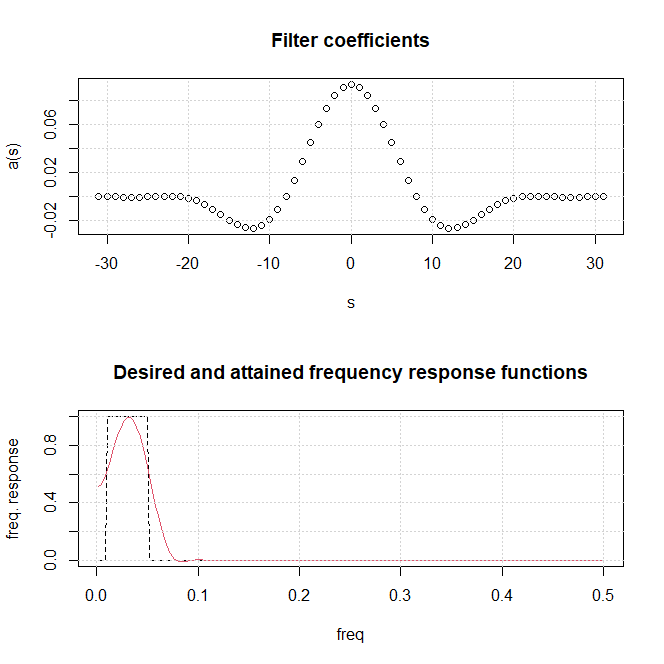
Vamos nos concentrar na abordagem do domínio da frequência para análise de séries temporais. Argumentamos que o
conceito de regularidade de uma série pode ser melhor expresso em termos de variações periódicas do fenômeno
subjacente que produziu a série. Muitos dos exemplos na Seção I.1 são séries temporais que são orientadas
por componentes periódicos. Por exemplo, a gravação da fala no Exemplo I.3 contém uma mistura complicada de frequências
relacionadas à abertura e ao fechamento da glote. O SOI mensal exibido no Exemplo I.5 contém duas periodicidades, um componente
periódico sazonal de 12 meses e um componente El Niño de cerca de três a sete anos. De interesse fundamental é o
período de retorno do fenômeno El Niño, que pode ter efeitos profundos no clima local.
Uma parte importante da análise de dados no domínio da frequência, bem como no domínio do tempo, é a investigação
e exploração das propriedades do filtro linear invariante no tempo. Essa transformação linear especial é usada
de forma semelhante à regressão linear na estatística convencional e usamos muitos dos mesmos termos no contexto de séries
temporais.
Também introduzimos a coerência como uma ferramenta para relacionar o comportamento periódico comum de duas séries. A
coerência é uma medida baseada na frequência da correlação entre duas séries em uma dada frequência,
e mostramos posteriormente que ela mede o desempenho do melhor filtro linear relacionado às duas séries.
Muitas escalas de frequência coexistem, dependendo da natureza do problema. Por exemplo, no conjunto de dados da Johnson & Johnson no
Exemplo I.1, a frequência predominante de oscilação é de um ciclo por ano, 4 trimestres, ou \(\omega =0.25\) ciclos
por observação. A frequência predominante nas séries de SOI e populações de peixes no Exemplo I.5 é
também um ciclo por ano, mas isso corresponde a 1 ciclo a cada 12 meses ou \(\omega=1/12=0.083\) ciclos por observação. Ao longo do
texto, medimos a frequência \(\omega\) em ciclos por ponto de tempo, em vez da alternativa \(\lambda=2\pi\omega\) isso daria radianos por
ponto. De interesse descritivo é o período de uma série temporal, definida como o número de pontos em um ciclo, ou
seja, \(1/\omega\). Assim, o período predominante da série de Johnson & Johnson é \(1/0.25\) ou 4 trimestres por ciclo,
enquanto o predominante período da série SOI é de 12 meses por ciclo.
Já encontramos a noção de periodicidade em numerosos exemplos nos Capítulos I, II e III.
A noção geral de periodicidade pode ser tornada mais precisa introduzindo alguma terminologia. Para definir a taxa na qual uma série
oscila, primeiro definimos um ciclo como um período completo de uma função seno ou cosseno definida ao longo de um intervalo de tempo
unitário. Como no Exemplo I.12, consideramos o processo periódico
\begin{equation}
X_t \, = \, A\cos\big( 2\pi\omega t+\phi\big),
\end{equation}
para \(t=0,\pm 1,\pm 2, \cdots\) onde \(\omega\) é um índice de frequência, definido em ciclos por unidade de tempo com \(A\)
determinando a altura ou amplitude da função e \(\phi\), chamada fase, determinando o ponto inicial da função cosseno.
Podemos introduzir variação aleatória nesta série temporal permitindo a amplitude e fase para variar aleatoriamente.
Como discutido no Exemplo II.10, para fins de análise de dados, é mais fácil usar a identidade trigonométrica
\(\cos(\alpha\pm \beta)=\cos(\alpha)\cos(\beta)\mp \sin(\alpha)\sin(\beta)\) e escrever a expressão acima como
\begin{equation}
X_t \, = \, U_1 \cos\big( 2\pi\omega t\big)+U_2\sin\big(2\pi\omega t\big),
\end{equation}
onde \(U_1=A\cos(\phi)\) e \(U_2=-A\sin(\phi)\) são frequentemente considerados como variáveis aleatórias normalmente distribuídas.
Neste caso, a amplitude é \(A=\sqrt{U_1^2+U_2^2}\) e a fase é \(\phi=\tan^{-1}\big(-U_2/U_1\big)\).
A partir desses fatos podemos mostrar que se, e somente se, \(A\) e \(\phi\) são variáveis aleatórias independentes, onde
\(A^2\) é qui-quadrado com 2 graus de liberdade e \(\phi\) uniformemente distribuído em \((-\pi,\pi)\), então \(U_1\)
e \(U_2\) são variáveis aleatórias normais padronizadas.
Se assumirmos que \(U_1\) e \(U_2\) são variáveis aleatórias não correlacionadas com média 0 e variância
\(\sigma^2\), então \(X_t\) é estacionária com média \(\mbox{E}(X_t)=0\) e, escrevendo \(c_t = \cos\big(2\pi\omega t\big)\) e
\(s_t = \sin\big(2\pi\omega t\big)\), a função de autocovariância assume a forma
\begin{equation}
\begin{array}{rcl}
\gamma_{_X}(h) \, = \, \mbox{Cov}(X_{t+h},X_t) & = & \mbox{Cov}\big(U_1c_{t+h}+U_2s_{t+h}, U_1c_t+U_2s_t \big) \\
& = & \mbox{Cov}\big(U_1c_{t+h}, U_1c_t\big) \, + \, \mbox{Cov}\big(U_1c_{t+h},U_2s_t \big) \\
& & \qquad \qquad + \, \mbox{Cov}\big(U_2s_{t+h}, U_1c_t\big) \, + \, \mbox{Cov}\big(U_2s_{t+h},U_2s_t \big) \\
& = & \sigma^2 c_{t+h}c_t \, + \, 0 \, + \, 0 \, + \, \sigma^2s_{t+h}s_t \, = \, \sigma^2\cos(2\pi\omega h),
\end{array}
\end{equation}
utilizando a relação \(\cos(\alpha\pm \beta)\) mencionada acima e notando que \(\mbox{Cov}\big(U_1,U_2\big)=0\). Então, vemos que
\begin{equation}
\mbox{Var}(X_t)=\gamma_{_X}(0)=\sigma^2\cdot
\end{equation}
Assim, se observarmos \(U_1 = a\) e \(U_2 = b\), uma estimativa de \(\sigma^2\) é a variância amostral dessas duas observações,
que neste caso é simplesmente
\begin{equation}
S^2 = \frac{a^2+b^2}{2-1} \, = \, a^2 + b^2\cdot
\end{equation}
O processo aleatório \(X_t \, = \, U_1 \cos\big( 2\pi\omega t\big)+U_2\sin\big(2\pi\omega t\big),\) é função da sua
frequência \(\omega\). Para \(\omega = 1\), a série faz um ciclo por unidade de tempo; para \(\omega=0.50\), a série faz um
ciclo a cada duas unidades de tempo; para \(\omega =0.25\), a cada quatro unidades e assim por diante. Em geral, para dados que ocorrem em pontos
de tempo discretos, precisaremos de pelo menos dois pontos para determinar um ciclo, então a maior frequência de interesse é
0.5 ciclos por ponto. Essa frequência é chamada de frequência de dobra e define a frequência mais alta que pode ser vista
na amostragem discreta. Frequências mais altas amostradas dessa maneira aparecerão em frequências mais baixas, chamadas aliases.
Um exemplo é o modo como uma câmera faz a amostragem de uma roda giratória em um automóvel em movimento em um filme, no
qual a roda parece estar girando a uma taxa diferente, e às vezes para trás, o efeito da roda do vagão. Por exemplo, a maioria
dos filmes são gravados a 24 quadros por segundo ou 24 Hertz. Se a câmera estiver filmando uma roda que esteja girando a 24 Hertz, a
roda parecerá ficar parada.
Considere uma generalização de \(X_t \, = \, U_1 \cos\big( 2\pi\omega t\big)+U_2\sin\big(2\pi\omega t\big),\) que permite misturas
de séries periódicas com múltiplas frequências e amplitudes,
\begin{equation}
X_t \, = \, \sum_{k=1}^q \Big(U_{k1} \cos\big( 2\pi\omega_k t\big)+U_{k2}\sin\big(2\pi\omega_k t\big)\Big),
\end{equation}
onde \(U_{k1}\) e \(U_{k2}\), para \(k=1,2,\cdots,q\) são variáveis aleatórias de média zero não correlacionadas
com variâncias \(\sigma^2_k\) e as \(\omega_k\) são frequências distintas. Observe que \(X_t\) acima exibe o processo como
uma soma de componentes não correlacionados, com variância \(\sigma^2_k\) para frequência \(\omega_k\).
Pode-se mostrar que a função de autocovariância do processo é
\begin{equation}
\gamma_{_X}(h)=\sum_{k=1}^q \sigma^2_k \cos\big( 2\pi\omega h\big),
\end{equation}
e notamos que a função de autocovariância é a soma de componentes periódicos com pesos proporcionais às
variâncias \(\sigma^2_k\). Portanto, \(X_t\) é um processo estacionário com média zero com variância
\begin{equation}
\gamma_{_X}(0) \, = \, \mbox{Var}(X_t) \, = \, \sum_{k=1}^q \sigma^2_k,
\end{equation}
exibindo a variância global como uma soma de variâncias de cada uma das partes componentes.
Como no caso simples, se observarmos \(U_{k1} = a_k\) e \(U_{k2} = b_k\) para \(k = 1,\cdots,q\), então uma estimativa do \(k\)-ésimo
componente de variância \(\sigma_k^2\) de \(\mbox{Var}(X_t)\), seria a variância amostral \(S^2_k = a^2_k + b^2_k\). Além disso,
uma estimativa da variância total de \(X_t\), a saber, \(\widehat{\gamma}_{_X}(0)\) seria a soma dos desvios amostrais,
\begin{equation}
\widehat{\gamma}_{_X} \, = \, \widehat{\mbox{Var}}(X_t) \, = \, \sum_{k=1}^q \big( a_k^2+b_k^2\big)\cdot
\end{equation}
Agarre-se a esta ideia porque vamos usá-la no Exemplo IV.2.
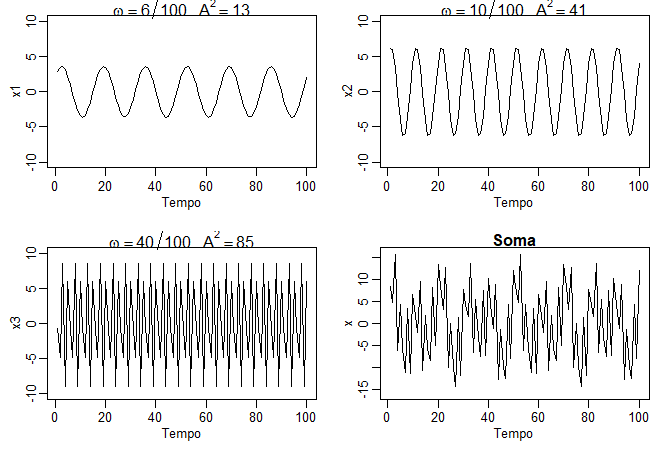
Exemplo IV.1. Uma série periódica.
A figura abaixo mostra um exemplo da mistura com \(q = 3\) construído da seguinte maneira. Primeiro, para \(t = 1,\cdots, 100\), geramos
três séries
\begin{equation}
\begin{array}{rcl}
X_{t1} & = & 2\cos\big( 2\pi t 6/100\big)+3\sin\big( 2\pi t 6/100\big) \\
X_{t2} & = & 4\cos\big( 2\pi t 10/100\big)+5\sin\big( 2\pi t 10/100\big) \\
X_{t3} & = & 6\cos\big( 2\pi t 40/100\big)+7\sin\big( 2\pi t 40/100\big) \\
\end{array}
\end{equation}
Essas três séries são exibidas na figura, juntamente com as frequências correspondentes e as amplitudes quadradas.
Por exemplo, a amplitude quadrada de \(X_{t1}\) é \(A^2 = 2^2 + 3^2 = 13\). Assim, os valores máximo e mínimo que \(X_{t1}\)
atingirá são \(\pm \sqrt{13} = \pm 3.61\).
Finalmente, construímos
\begin{equation}
X_t=X_{t1}+X_{t2}+X_{t3},
\end{equation}
e esta série também é exibida na figura. Observamos que \(X_t\) parece comportar-se como algumas das séries periódicas
que vimos antes. A sistemática de seleção dos componentes de frequência essencial em uma série temporal, incluindo
suas contribuições relativas, constitui um dos principais objetivos da análise espectral.
Figura IV.1: Componentes periódicos e sua soma conforme descrito neste exemplo.
Para mostrar os dados digite os seguintes comandos:
O modelo de séries periódicas com múltiplas frequências e amplitudes, juntamente com a função de
autocovariância correspondente são construções populacionais. Embora, para obtermos \(\widehat{\gamma}_{_X}\), tenhamos
sugerido como estimaríamos os componentes de variância, agora discutimos os aspectos práticos de como, dadas as observações ou
realizações de uma séria \(x_1,x_2,\cdots,x_n\), estimar realmente os componentes de variância \(\sigma^2_k\).
Exemplo IV.2. Estimação e periodograma.
Para qualquer amostra de série temporal \(x_1,x_2,\cdots,x_n\), onde \(n\) é ímpar, podemos escrever, exatamente
\begin{equation}
X_t=a_0+\sum_{j=1}^{(n-1)/2} \Big( a_j \cos\big( 2\pi t \, j/n\big)+b_j\sin\big( 2\pi t \, j/n\big)\Big),
\end{equation}
para \(t = 1,\cdots,n\) e coeficientes adequadamente escolhidos.
Se \(n\) é par, a representação acima pode ser modificada somando \(n/2-1\) e adicionando um componente adicional dado
por um \(a_{n/2}\cos\big( 2\pi t \, \frac{1}{2}\big) \, = \, a_{n/2}(-1)^t\). O ponto crucial aqui é que esta representação
é exata para qualquer amostra. Portanto, a série periódica com múltiplas frequências e amplitudes, pode ser
pensada como uma aproximação para a expressão acima, a ideia é que muitos dos coeficientes a serem adequadamente
escolhidos podem ser próximos de zero.
Usando os resultados de regressão, os coeficientes \(a_j\) e \(b_j\) são da forma \(\sum_{t=1}^n x_t z_{tj}/\sum_{t=1}^n z_{tj}^2\),
onde \(z_{tj}\) é um outro \(\cos\big( 2\pi t \, j/n\big)\) ou \(\sin\big( 2\pi t \, j/n\big)\). Pode-se demonstrar que \(\sum_{t=1}^n z_{tj}^2=n/2\),
quando \(j/n\neq 0,1/2\) então os coeficientes de regressão podem ser escritos como \(a_0=\overline{x}\),
\begin{equation}
a_j=\frac{2}{n}\sum_{t=1}^n x_t \cos\big( 2\pi t \, j/n\big) \qquad \mbox{e} \qquad b_j=\frac{2}{n}\sum_{t=1}^n x_t \sin\big( 2\pi t \, j/n\big)\cdot
\end{equation}
Em seguida, definimos o periodograma escalonado como sendo
\begin{equation}
P(j/n)=a_j^2+b_j^2,
\end{equation}
e é de interesse porque indica quais componentes de frequência são grandes em magnitude e quais componentes são
pequenos.
O periodograma escalado é simplesmente a variância amostral em cada componente de frequência e, consequentemente, é
uma estimativa de \(\sigma^2_j\) correspondente à sinusoide que oscila a uma frequência de \(\omega_j = j/n\). Essas
frequências específicas são chamadas de frequências de Fourier ou frequências fundamentais. Grandes valores
de \(P(j/n)\) indicam quais frequências \(\omega_j = j/n\) são predominantes na série, enquanto valores pequenos de \(P(j/n)\)
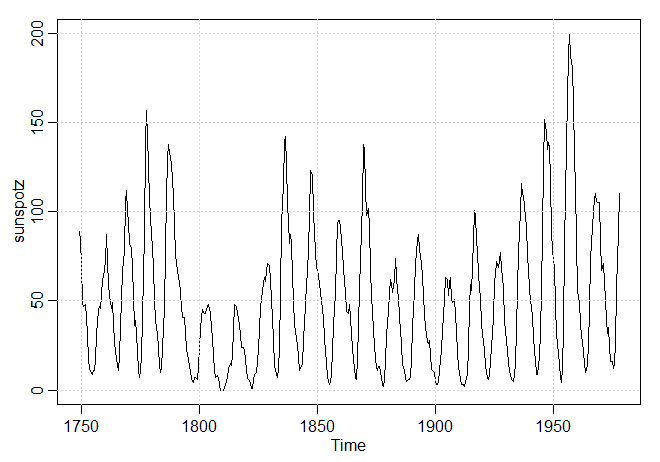
podem estar associados a ruído. O periodograma foi introduzido em Schuster (1898) e usado em Schuster (1906) para estudar as periodicidades
na série das manchas solares, mostrado na figura do Exercício IV.9.
Felizmente, não é necessário executar uma grande regressão para obter os valores de \(a_j\) e \(b_j\), porque eles
podem ser calculados rapidamente se \(n\) for um inteiro altamente composto. Embora vamos discuti-lo em mais detalhes na Seção IV.3,
a transformada discreta de Fourier (DFT) é uma média ponderada de valor complexo dos dados fornecidos, dada por
\begin{equation}
\begin{array}{rcl}
d(j/n) & = & \displaystyle \frac{1}{n}\sum_{t=1}^n x_t \exp\big( -2\pi \, it \, j/n\big) \\
& = & \displaystyle \frac{1}{n}\left(\sum_{t=1}^n x_t \cos\big( 2\pi \, t \, j/n\big)-i\sum_{t=1}^n x_t \sin\big( 2\pi \, t \, j/n\big) \right)
\end{array}
\end{equation}
para \(j = 0,1,\cdots,n-1\), onde as frequências \(j/n\) são as frequências de Fourier ou frequências fundamentais.
Para encontrarmos a expressão acima utilizamos a fórmula de Euler \(e^{i\alpha}=\cos(\alpha)+i\sin(\alpha)\), da qual, por consequência
temos que \(\cos(\alpha)=(e^{i\alpha}+e^{-i\alpha})/2\) e \(\sin(\alpha)=(e^{i\alpha}-e^{-i\alpha})/2\). Também \(1/i=-i\), isto porque \(-i\times i=1\).
Se \(z=a+ib\) é um número complexo, então \(|z|^2=Z z^*=(a+ib)(a-ib)=a^2+b^2\), sendo que \(z^*\) denota o conjugado complexo.
Devido a um grande número de redundâncias no cálculo, \(d(j/n)\) pode ser calculado rapidamente usando a transformada
rápida de Fourier (FFT). Observe que
\begin{equation}
|d(j/n)|^2=\displaystyle \frac{1}{n}\left(\sum_{t=1}^n x_t \cos\big( 2\pi \, t \, j/n\big)\right)^2+\frac{1}{n}\left(\sum_{t=1}^n x_t \sin\big( 2\pi \, t \, j/n\big) \right)^2
\end{equation}
e é essa quantidade chamada de periodograma.
Podemos calcular o periodograma escalonado, utilizando o periodograma como
\begin{equation}
P(j/n)=\displaystyle \frac{4}{n}|d(j/n)|^2\cdot
\end{equation}
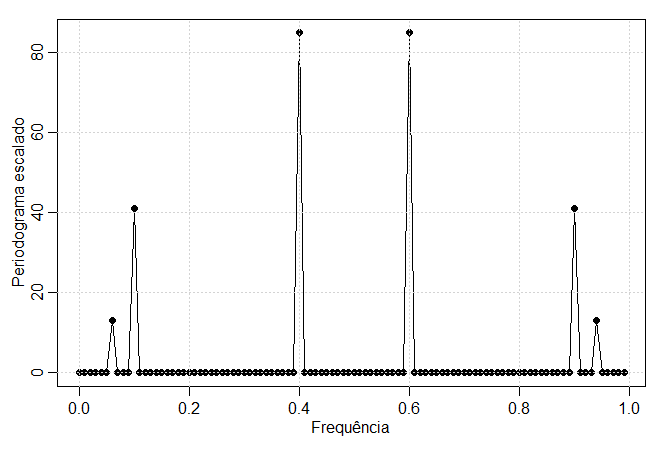
O periodograma escalado dos dados \(x_t\), simulado no Exemplo IV.1 é mostrado na figura abaixo e identifica claramente os três
componentes \(x_{t1}\), \(x_{t2}\) e \(x_{t3}\) de \(x_t\). Observe que
\begin{equation}
P(j/n)=P(1-j/n), \qquad j=0,1,\cdots,n-1,
\end{equation}
então há um efeito de espelhamento na frequência de dobramento de 1/2; consequentemente, o periodograma normalmente não
é mostrado para frequências mais altas que a frequência de dobramento. Além disso, note que as alturas do periodograma
escalado mostrado na figura são
\begin{equation}
P(6/100)=P(94/100)=13, \qquad P(10/100)=P(90/100)=41, \qquad P(40/100)=P(60/100)=85,
\end{equation}
e \(P(j/n)=0\), caso contrário. Estes são exatamente os valores das amplitudes quadradas dos componentes gerados no Exemplo IV.1.
Figura IV.2: O períodograma escalonado dos dados gerados no Exemplo IV.1.
Assumindo que os dados simulados, \(x\), foram retidos do exemplo anterior, o código R para reproduzir a figura acima é:
Pacotes diferentes escalam a FFT de maneira diferente, por isso é uma boa idéia consultar a documentação. O R
calcula-o sem o fator \(n^{-1/2}\) e com um fator adicional de \(e^{2\pi i\omega j}\) que pode ser ignorado porque estaremos interessados
no módulo ao quadrado.
Se considerarmos os dados \(x_t\) no Exemplo IV.1 como uma cor (forma de onda) composta de cores primárias \(x_{t1}\), \(x_{t2}\),
\(x_{t3}\) em várias intensidades ou amplitudes, então podemos considerar o periodograma como um prisma que decompõe a
cor \(x_t\) em suas cores primárias ou espectro. Daí o termo análise espectral. A seguir, um exemplo usando dados reais.
Exemplo IV.3. Magnitude da Estrela.
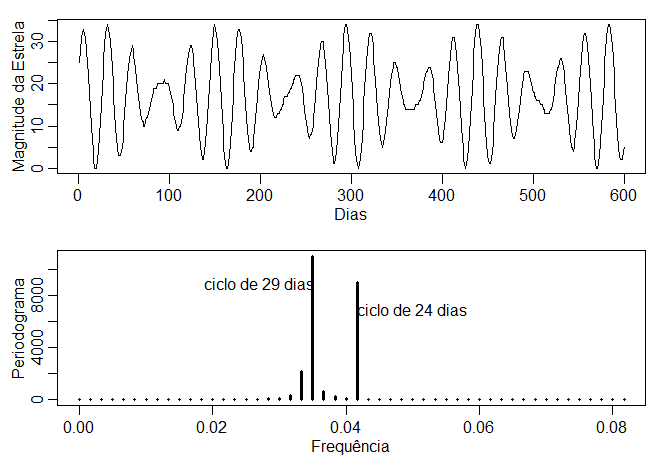
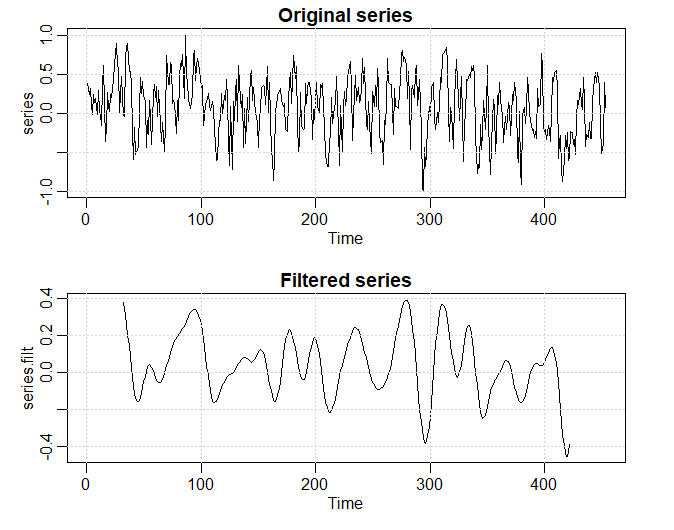
Os dados na segunda figura embaixo são a magnitude de uma estrela tirada à meia-noite por 600 dias consecutivos. Os dados são retirados
do texto clássico: The Calculus of Observations, a Treatise on Numerical Mathematics, por E.T. Whittaker e G. Robinson (1923, Blackie & Son, Ltd.).
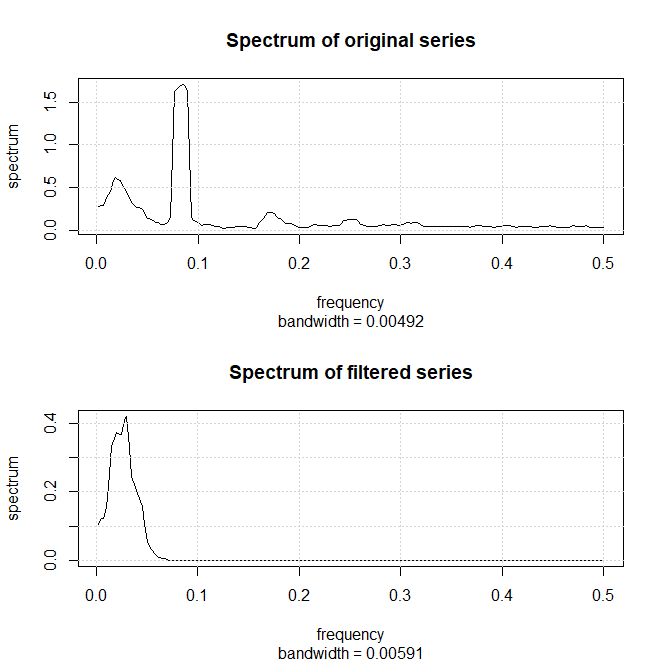
O periodograma para frequências inferiores a 0.08 também é exibido na figura; as ordenadas do periodograma para frequências
superiores a 0.08 são essencialmente zero. Observe que o ciclo de \(29 \approx 1/0.035\) dias e o ciclo de \(24 \approx 1/0.041\) dias são
os componentes periódicos mais proeminentes dos dados.
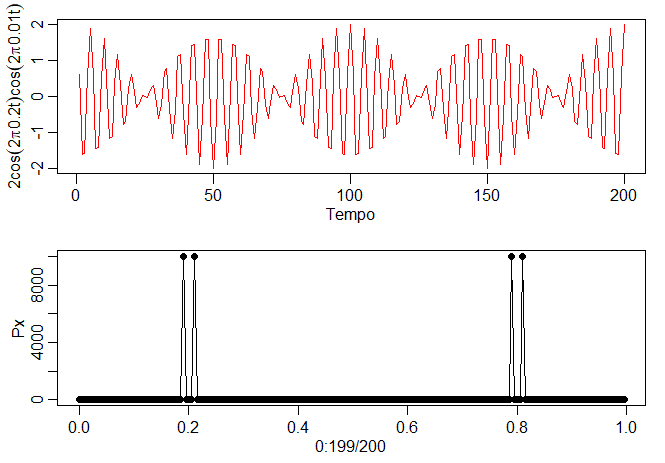
Podemos interpretar esse resultado conforme estamos observando um sinal modulado em amplitude. Por exemplo, suponha que estamos observando sinal-mais-ruído,
\(X_t = s_t + V_t\), onde \(s_t = \cos(2\pi\omega \, t)\cos(2\pi\delta \, t)\) e \(\delta\) é muito pequeno. Neste caso, o processo irá oscilar
na frequência \(\omega\), mas a amplitude será modulada por \(\cos(2\pi\delta \, t)\). Como \(2\cos(\alpha)\cos(\delta) = \cos(\alpha+\delta) + \cos(\alpha-\delta)\),
o periodograma dos dados gerados como \(X_t\) terá dois picos próximos um do outro em. Observe isso na figura a seguir:
> t = 1:200
> plot.ts(x <- 2*cos(2*pi*.2*t)*cos(2*pi*.01*t), type="n", xlab="Tempo",
ylab=expression(2*cos(2*pi*0.2*t)*cos(2*pi*.01*t)))
> lines(cos(2*pi*.19*t)+cos(2*pi*.21*t), col=2) # the same
> Px = Mod(fft(x))^2; plot(0:199/200, Px, type='o', pch=19) # periodograma
Figura IV.3: Magnitudes de estrelas e parte do periodograma correspondente.
Nesta seção, definimos a ferramenta do domínio de frequência fundamental, a densidade espectral. Além disso, discutimos
as representações espectrais para processos estacionários. Assim como a decomposição de Wold (Teorema B.5)
justifica teoricamente o uso de regressão para analisar séries temporais, os teoremas de representação espectral
fornecem as justificativas teóricas para a decomposição de séries temporais estacionárias em componentes
periódicos que aparecem em proporção às suas variâncias subjacentes. Este material é aprimorado pelos
resultados apresentados no Apêndice C.
Exemplo IV.4. Um processo estacionário periódico.
Considere um processo aleatório estacionário periódico, com uma frequência fixa \(\omega_0\),
\begin{equation}
X_t=U_1\cos\big(2\pi\omega_0 \, t \big)+U_2\sin\big(2\pi\omega_0 \, t \big),
\end{equation}
onde \(U_1\) e \(U_2\) são variáveis aleatórias de média zero não correlacionadas com igual variância
\(\sigma^2\). O número de períodos necessários para a série acima para completar um ciclo é exatamente \(1/\omega_0\)
e o processo faz exatamente \(\omega_0\) ciclos por ponto para \(t = 0,\pm 1,\pm 2,\cdots\). Temos então que
\begin{equation}
\begin{array}{rcl}
\gamma(h) & = & \sigma^2\cos\big( 2\pi\omega_0 \, h\big) \, = \, \displaystyle \frac{\sigma^2}{2}\exp\big( -2\pi \, i\omega_0 \, h\big) +
\frac{\sigma^2}{2}\exp\big( 2\pi \, i\omega_0 \, h\big) \\
& = & \displaystyle \int_{-1/2}^{1/2} \exp\big( 2\pi \, i\omega_0 \, h\big)\mbox{d}F(\omega),
\end{array}
\end{equation}
usando a integração de Riemann-Stieltjes (ver Seção C.4.1), onde \(F(\omega)\) é a função definida
por
\begin{equation}
F(\omega) \, = \, \left\{\begin{array}{ccc} 0, & \mbox{ caso } & \omega<-\omega_0 \\
\displaystyle \frac{\sigma^2}{2}, & \mbox{ caso } & -\omega_0\leq \omega < \omega_0 \\
\sigma^2, & \mbox{ caso } & \omega\geq \omega_0\end{array}\right.\cdot
\end{equation}
A função \(F(\omega)\) se comporta como uma função de distribuição para uma variável aleatória
discreta, exceto que \(F(\infty) = \sigma^2 = \mbox{Var}(X_t)\) em vez de um. De fato, \(F(\omega)\) é uma função de distribuição,
não de probabilidades, mas sim de variâncias, com \(F(\infty)\) sendo a variância total do processo \(X_t\). Portanto, denominamos
\(F(\omega)\) a função de distribuição espectral. Este exemplo será continuado no Exemplo IV.9.
Uma representação como a fornecida no Exemplo IV.4 sempre existe para um processo estacionário. Para detalhes, veja o
Teorema C.1 e sua prova. A integração de Riemann-Stieltjes é descrita na Seção C.4.1.
Teorema IV.1. Representação Espectral de uma Função de Autocovariância.
Se \(\{X_t\}\) é um processo estacionário com autocovariância \(\gamma(h)=\mbox{Cov}(X_{t+h},X_t)\), então existe
uma função única monotonicamente crescente \(F(\omega)\), chamada de função de distribuição
espectral, com \(F(-\infty)=F(-1/2)=0\) e \(F(\infty)=F(1/2)=\gamma(0)\), de tal modo que
\begin{equation}
\gamma(h) \, = \, \displaystyle \int_{-\frac{1}{2}}^{\frac{1}{2}} \exp\big(2\pi \, i \omega \, h \big) \mbox{d}F(\omega)\cdot
\end{equation}
Demonstração Ver Teorema C.1 ▉
Uma situação importante que usamos repetidamente é o caso quando a função de autocovariância é
absolutamente sumável, em cujo caso a função de distribuição espectral é absolutamente contínua
com \(\mbox{d}F(\omega)=f(\omega)\mbox{d}\omega\) e a representação no Teorema IV.1 se torna a motivação
para a propriedade dada abaixo.
Teorema IV.2. A Densidade Espectral.
Se a função de autocovariância \(\gamma(h)\), de um processo estacionário satisfaz
\begin{equation}
\sum_{h=-\infty}^\infty |\gamma(h)| \, < \, \infty,
\end{equation}
então tem a representação
\begin{equation}
\gamma(h) \, = \, \displaystyle \int_{-\frac{1}{2}}^{\frac{1}{2}} \exp\big( 2\pi \, i \omega \, t\big)f(\omega)\mbox{d}\omega,
\qquad h=0,\pm 1,\pm 2,\cdots,
\end{equation}
como a transformação inversa da densidade espectral,
\begin{equation}
f(\omega)=\sum_{h=-\infty}^\infty \gamma(h)\exp\big( -2\pi \, i \omega \, t\big), \qquad -1/2\leq \omega\leq 1/2\cdot
\end{equation}
Demonstração Ver Teorema C.1 ▉
Essa densidade espectral é o análogo da função de densidade; o fato de \(\gamma(h)\) ser definido não negativo
garante que \(f(\omega)\geq 0\), para todo \(\omega\). Segue imediatamente do Teorema IV.2 que \(f(\omega)=f(-\omega)\), verificando
que a densidade espectral é uma função par.
Por causa da uniformidade, tipicamente traçamos apenas \(f(\omega)\) para \(0\leq \omega\leq 1/2\). Mais ainda, escolhendo \(h=0\) na expressão acima, produz
\begin{equation}
\gamma(0) \, = \, \mbox{Var}(X_t) \, = \, \displaystyle \int_{-\frac{1}{2}}^{\frac{1}{2}} f(\omega)\mbox{d}\omega,
\end{equation}
que expressa a variância total como densidade espectral integrada em todas as frequências. Mostramos mais adiante que um filtro
linear pode isolar a variância em certos intervalos de frequência ou bandas.
Agora deve ficar claro que as funções de autocovariância e distribuição espectral contêm as mesmas
informações. Essa informação, no entanto, é expressa de maneiras diferentes. A função de
autocovariância expressa informações em termos de atrasos, enquanto a distribuição espectral expressa as
mesmas informações em termos de ciclos. Alguns problemas são mais fáceis de trabalhar quando consideramos as
informações defasadas e nós tenderíamos a lidar com esses problemas no domínio do tempo. No entanto, outros
problemas são mais fáceis de trabalhar quando consideramos informações periódicas e nós tenderíamos
a lidar com esses problemas no domínio espectral.
Observamos que a função de autocovariância \(\gamma(h)\) e a densidade espectral \(f(\omega)\) são pares de transformada
de Fourier. Em particular, isto significa que se \(f(\omega)\) e \(g(\omega)\) são duas densidades espectrais para as quais
\begin{equation}
\gamma_{_f}(h) \, = \, \displaystyle \int_{-\frac{1}{2}}^{\frac{1}{2}} f(\omega)\exp\big(2\pi \, i\omega \, h \big)\mbox{d}\omega \, = \,
\int_{-\frac{1}{2}}^{\frac{1}{2}} g(\omega)\exp\big(2\pi \, i\omega \, h \big)\mbox{d}\omega \, = \, \gamma_{_g}(h),
\end{equation}
para \(h=0,\pm 1,\pm 2,\cdots\), então
\begin{equation}
f(\omega) \, = \, g(\omega)\cdot
\end{equation}
Finalmente, a condição de soma absoluta \(\sum_{h=-\infty}^\infty |\gamma(h)| < \infty\), no Teorema IV.2, não é satisfeita
pela função \(\gamma_{_X}(h)=\sum_{k=1}^q \sigma^2_k \cos\big( 2\pi\omega h\big)\), no exemplo que usamos para introduzir a idéia
de uma representação espectral. A condição, no entanto, é satisfeita para os modelos \(ARMA\).
É esclarecedor examinar a densidade espectral da série que examinamos em discussões anteriores.
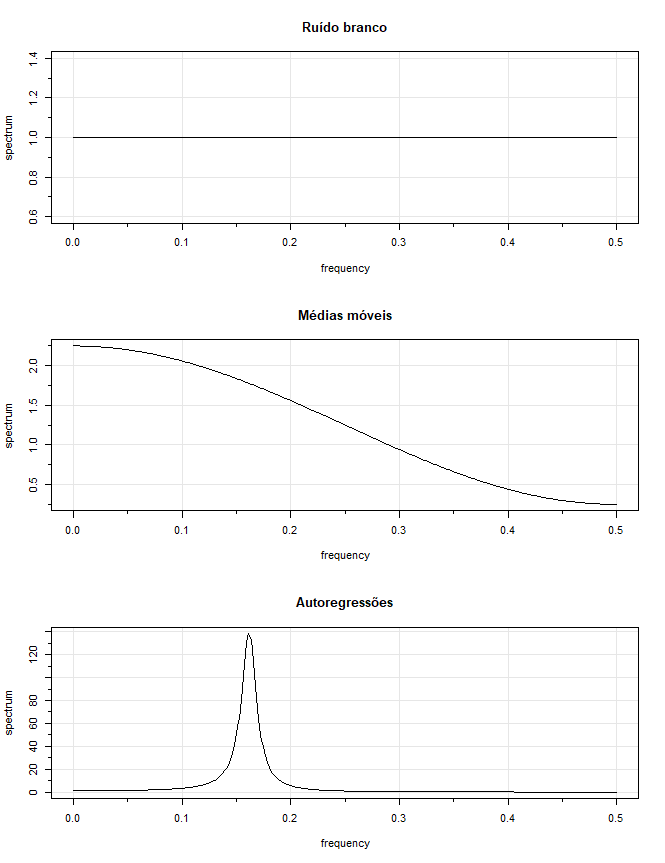
Exemplo IV.5. Série de ruído branco.
Como um exemplo simples, considere o espectro do poder teórico de uma sequência de variáveis aleatórias não
correlacionadas \(W_t\), com variância \(\sigma^2_{_W}\). Um conjunto simulado de dados é exibido na figura no Exemplo I.8.
Porque a função de autocovariância foi computada no Exemplo I.16 como \(\gamma_{_W}(h) = \sigma^2_{_W}\) para \(h = 0\) e zero,
caso contrário, segue que
\begin{equation}
f_{_W}(\omega)=\sigma^2_{_W},
\end{equation}
para \(-1/2\leq \omega\leq 1/2\). Portanto, o processo contém poder igual em todas as frequências. Esta propriedade é vista
na realização, que parece conter todas as frequências diferentes em uma mistura aproximadamente igual. De fato, o nome
ruído branco vem da analogia à luz branca, que contém todas as frequências no espectro de cores no mesmo nível
de intensidade. O topo da figura do Exemplo IV.7 mostra um gráfico do espectro de ruído branco para \(\sigma^2_{_W} = 1\). O código
R para reproduzir a figura é dado no final do Exemplo IV.7.
Como o processo linear é uma ferramenta essencial, vale a pena investigar o espectro de tal processo. Em geral, um filtro linear usa um
conjunto de coeficientes especificados, digamos \(a_j\), quando \(j = 0,\pm 1,\pm 2,\cdots\) para transformar uma série de entrada, \(X_t\),
produzindo uma série de saída, \(Y_t\), da forma
\begin{equation}
Y_t \, = \, \sum_{j=-\infty}^\infty a_j X_{t-j}, \qquad \sum_{j=-\infty}^\infty |a_j|< \infty\cdot
\end{equation}
A forma acima também é chamada de convolução em alguns contextos estatísticos. Os coeficientes são chamados
coletivamente de função de resposta ao impulso e a transformada de Fourier
\begin{equation}
A(\omega) \, = \, \sum_{j=-\infty}^\infty a_j e^{-2\pi \, i \, \omega j},
\end{equation}
é chamada função de resposta de frequência. Se, na expressão de \(Y_t\) acima, \(X_t\) tiver densidade espectral
\(f_{_X}(\omega)\), temos o seguinte resultado.
Teorema IV.3. Espectro de saída de uma série estacionária filtrada.
Para o processo em \(\displaystyle Y_t = \sum_{j=-\infty}^\infty a_j X_{t-j}\), quando \(\displaystyle \sum_{j=-\infty}^\infty |a_j|< \infty\),
se \(X_t\) tem espectro \(f_{_X}(\omega)\), então o espectro da saída filtrada \(Y_t\), digamos \(f_{_Y}(\omega)\), está
relacionado com o espectro da entrada \(X_t\) por
\begin{equation}
f_{_Y}(\omega) \, = \, |A(\omega)|^2 f_{_X}(\omega),
\end{equation}
onde a função de resposta de frequência \(A(\omega)\) é definida como \(\displaystyle A(\omega) = \sum_{j=-\infty}^\infty a_j e^{-2\pi \, i \, \omega j},\).
Demonstração
Consideremos a saída filtrada dada por
\begin{equation}
Y_t \, = \, \displaystyle \sum_{j=-\infty}^\infty a_j X_{t-j},
\end{equation}
sendo que \(\displaystyle \sum_{j=-\infty}^\infty |a_j|< \infty\cdot\).
O resultado vale explorando a exclusividade da transformada de Fourier ▉
O uso do Teorema IV.3 é explorado na Seção IV.7. Se \(X_t\) é um processo \(ARMA\), sua densidade espectral pode
ser obtida explicitamente usando o fato de que é um processo linear, isto é, \(X_t = \sum_{j=0}^\infty \psi_j W_{t-j}\), onde \(\sum_{j=0}^\infty |\psi_j|< \infty\).
Teorema IV.4. A densidade espectral do \(ARMA\).
Se \(X_t\) é \(ARMA(p,q)\), \(\phi(B)X_t = \theta(B)W_t\), sua densidade espectral é dada por
\begin{equation}
f_{_X}(\omega) \, = \, \sigma^2_{_W}\frac{\displaystyle \big|\theta(e^{-2\pi \, i \, \omega})\big|^2}{\displaystyle \big|\phi(e^{-2\pi \, i \, \omega})\big|^2},
\end{equation}
onde \(\displaystyle \phi(z) = 1-\sum_{k=1}^p \phi_k z^k\) e \(\displaystyle \theta(z)=1+\sum_{k=1}^q \theta_k z^k\).
Demonstração
Consequência direta do Teorema IV.3, usando os fatos adicionais de que a densidade espectral do ruído branco é \(f_{_W}(\omega)=\sigma^2_{_W}\)
e, pelo Teorema III.1, \(\psi(z)=\theta(z)/\phi(z)\) ▉
Exemplo IV.6. Série de médias móveis.
Como exemplo de uma série que não possui uma mistura igual de frequências, consideramos um modelo de médias móveis.
Especificamente, considere o modelo \(MA(1)\) dado por
\begin{equation}
X_t \, = \, W_t + 0.5 W_{t-1}\cdot
\end{equation}
Uma realização amostral é mostrada no topo da figura do Exemplo III.5 e notamos que a série tem menos frequências
mais altas ou mais rápidas. A densidade espectral irá verificar esta observação.
A função de autocovariância foi exibida no Exemplo III.5 e para este exemplo em particular, temos
\begin{equation}
\gamma(h) \, = \, \left\{ \begin{array}{ccl} (1+0.5^2)\sigma^2_{_W} \, = \, 1.25\sigma^2_{_W} & \mbox{quando} & h=0 \\
0.5\sigma^2_{_W} & \mbox{quando} & h \pm 1 \\ 0 & \mbox{quando} & h>1 \end{array} \right. \cdot
\end{equation}
Substituindo isto diretamente na definição da densidade espectral, temos
\begin{equation}
f(\omega) \, = \, \displaystyle \sum_{h=-\infty}^\infty \gamma(h) e^{-2\pi \, i \, \omega h} \, = \,
\sigma^2_{_W}\Big( 1.25+0.5\big(e^{-2\pi \, i \, \omega}+e^{2\pi\omega} \big)\Big) \, = \, \sigma^2_{_W}\big( 1.25+\cos(2\pi \, \omega) \big)\cdot
\end{equation}
Podemos também calcular a densidade espectral usando o Teorema IV.4, que afirma que para uma \(MA\),
\begin{equation}
f(\omega) \, = \, \sigma^2_{_W} \big|\theta e^{-2\pi \, i \, \omega} \big|^2\cdot
\end{equation}
Devido a que \(\theta(z)=1+0.5z\), temos
\begin{array}{rcl}
\big|\theta \big(e^{-2\pi \, i \, \omega} \big)\big|^2 & = & \big|1+0.5 e^{-2\pi \, i \, \omega} \big|^2 \, = \,
\big(1+0.5 e^{-2\pi \, i \, \omega} \big) \big(1+0.5 e^{2\pi \, i \, \omega} \big)\\
& = & 1.25 +0.5\big(e^{-2\pi \, i \, \omega} +e^{2\pi\omega}\big)
\end{array}
o que leva a um acordo com o encontrado acima.
Mostrando o espectro para \(\sigma^2_{_W} = 1\), como no meio da figura do Exemplo IV.7, mostra que as frequências mais baixas ou mais lentas
têm maior potência do que as frequências mais altas ou mais rápidas.
Exemplo IV.7. Uma série autorregressiva de segunda ordem.
Consideramos agora o espectro de uma série \(AR(2)\) da forma
\begin{equation}
X_t -\phi_1 X_{t-1} -\phi_2 X_{t-2}\, = \, W_t,
\end{equation}
para o caso especial \(\phi_1 = 1\) e \(\phi_2 = -0.9\). A figura do Exemplo I.10 mostra uma realização amostral de tal processo
para \(\sigma_{_W} = 1\). Notamos que os dados exibem um forte componente periódico que faz um ciclo a cada seis pontos.
Para usar o Teorema IV.4, observe que \(\theta(z)=1\), \(\phi(z)=1-z+0.9z^2\) e
\begin{equation}
\begin{array}{rcl}
\big|\theta \big(e^{-2\pi \, i \, \omega} \big)\big|^2 & = & \\
& = & 2.81-1.9\big( e^{2\pi \, i \, \omega}+e^{-2\pi \, i \, \omega}\big)+0.9\big( e^{4\pi \, i \, \omega}+e^{-4\pi \, i \, \omega}\big) \\
& = & 2.81-3.8 \cos(2\pi\omega)+1.8\cos(4\pi\omega),
\end{array}
\end{equation}
Então, a densidade espectral de \(X_t\) é
\begin{equation}
f_{_X}(\omega) \, = \, \frac{\sigma^2_{_W}}{2.81-3.8 \cos(2\pi\omega)+1.8\cos(4\pi\omega)}\cdot
\end{equation}
Definindo \(\sigma^2_{_W} = 1\), a parte inferior da figura abaixo exibe \(f_{_X}(\omega)\) e mostra um forte componente de potência em torno de \(\omega=0.16\)
ciclos por ponto ou um período entre seis e sete ciclos por ponto e pouquíssima potência em outras frequências. Nesse caso, modificar
a série de ruído branco aplicando o operador \(AR\) de segunda ordem concentrou a potência ou a variação da série resultante
em uma faixa de frequência muito estreita.
A densidade espectral também pode ser obtida sem ter que usar o Teorema IV.4; isso porque
\begin{equation*}
W_t \, = \, X_t-X_{t-1}+0.9X_{t-2},
\end{equation*}
neste exemplo, do qual temos
\begin{equation*}
\begin{array}{rcl}
\gamma_{_W}(h) & = & \mbox{Cov}(W_{t+h},W_t) \\
& = & \mbox{Cov}(X_{t+h}-X_{t+h-1}+0.9 X_{t+h-2} \, , \, X_t-X_{t-1}+0.9 X_{t-2}) \\
& = & 2.81\gamma_{_X}(h)-1.9\big(\gamma_{_X}(h+1)+\gamma_{_X}(h-1) \big)+0.9\big( \gamma_{_X}(h+2)+\gamma_{_X}(h-2)\big) \cdot
\end{array}
\end{equation*}
Agora, substituindo a representação espectral por \(\gamma_{_X}(h)\) na equação acima produz
\begin{equation*}
\begin{array}{rcl}
\gamma_{_W}(h) & = & \displaystyle \int_{-\frac{1}{2}}^\frac{1}{2}
\Big(2.81-1.9\big(e^{2\pi \, i \, \omega}+e^{-2\pi \, i \, \omega}\big)+0.9\big(e^{4\pi \, i \, \omega}+e^{-4\pi \, i \, \omega}\big)\Big)e^{2\pi \, i \, \omega h}f_{_X}(\omega)\mbox{d}\omega \\
& = & \displaystyle {-\frac{1}{2}}^\frac{1}{2}
\Big(2.81-3.8\cos(2\pi \omega)+1.8 \cos(4\pi\omega) \Big)e^{2\pi \, i \, \omega h}f_{_X}(\omega)\mbox{d}\omega\cdot
\end{array}
\end{equation*}
Se o espectro do processo de ruído branco \(W_t\), for \(g_{_W}(\omega)\), a unicidade da transformada de Fourier nos permite identificar
\begin{equation*}
g_{_W}(\omega) \, = \, \Big(2.81-3.8\cos(2\pi \omega)+1.8 \cos(4\pi\omega) \Big)f_{_X}(\omega)\cdot
\end{equation*}
Mas, como já vimos, \(g_{_W}(\omega)=\sigma^2_{_W}\), do qual deduzimos que
\begin{equation*}
f_{_X}(\omega) \, = \, \frac{\sigma^2_{_W}}{2.81-3.8\cos(2\pi \omega)+1.8 \cos(4\pi\omega)},
\end{equation*}
é o espectro da série autoregressiva.
Figura IV.4: Espectros teóricos do ruído branco (superior), médias móveis de
primeira ordem (meio) e processo autorregressivo de segunda ordem (inferior).
O código R para reproduzir a figura utiliza arma.spec em astsa:
Exemplo IV.8. Toda explosão tem uma causa (continuação).
No Exemplo III.4, discutimos o fato de que os modelos explosivos têm contrapartes causais. Nesse exemplo, também indicamos que era
mais fácil mostrar esse resultado em geral no domínio espectral. Neste exemplo, damos os detalhes para um modelo \(AR(1)\), mas as
técnicas usadas aqui indicarão como generalizar o resultado.
Como no Exemplo III.4, supomos que \(X_t=2X_{t-1}+W_t\), onde \(W_t\sim N(0,\sigma^2_{_W})\) independentes. Então, a densidade espectral
de \(X_t\) é
\begin{equation}
f_{_X}(\omega) \, = \, \sigma^2_{_W} \big| 1-e^{-2\pi \, i \, \omega}\big|^{-2}\cdot
\end{equation}
Mas,
\begin{equation}
\begin{array}{rcl}
\big| 1-e^{-2\pi \, i \, \omega}\big| & = & \displaystyle \big| 1-e^{2\pi \, i \, \omega}\big| \\
& = & \displaystyle \big|\big(2e^{2\pi \, i \, \omega}\big)\big(\frac{1}{2}e^{-2\pi \, i \, \omega} -1\big)\big| \\
& = & \displaystyle 2\big|1-\frac{1}{2}e^{-2\pi \, i \, \omega} \big|\cdot
\end{array}
\end{equation}
Assim, podemos escrever
\begin{equation}
f_{_X}(\omega) \, = \, \frac{1}{4}\sigma^2_{_W} \big| 1-\frac{1}{2}e^{-2\pi \, i \, \omega}\big|^{-2},
\end{equation}
o que implica que \(X_t=\frac{1}{2}X_{t-1}+V_t\), com \(V_t\sim N\big(0,\frac{1}{4}\sigma^2_{_W}\big)\) é uma forma equivalente do modelo.
Terminamos esta seção mencionando outra representação espectral que lida diretamente com o processo. Em termos
não técnicos, o resultado sugere que
\begin{equation}
X_t \, = \, \sum_{k=1}^q \Big(U_{k1} \cos\big( 2\pi\omega_k t\big)+U_{k2}\sin\big(2\pi\omega_k t\big)\Big),
\end{equation}
é aproximadamente verdadeiro para qualquer série temporal estacionária e isso fornece uma justificativa teórica
adicional para a decomposição de séries temporais em componentes harmônicos.
Exemplo IV.9. Um processo estacionário periódico (continuação).
No Exemplo IV.4, consideramos o processo periódico estacionário com uma frequência fixa \(\omega_0\), dado como
\begin{equation}
X_t \, = \, U_1\cos\big(2\pi\omega_0 \, t \big)+U_2\sin\big(2\pi\omega_0 \, t \big)\cdot
\end{equation}
Podemos escrever isso como
\begin{equation}
X_t \, = \, \displaystyle \frac{1}{2}\big(U_1+ iU_2\big)e^{-2\pi \, i \,\omega_0 t}+\frac{1}{2}\big(U_1- iU_2\big)e^{2\pi \, i \,\omega_0 t},
\end{equation}
onde nos lembramos que \(U_1\) e \(U_2\) são variáveis aleatórias não correlacionadas, com média zero,
cada uma com variância \(\sigma^2\).
Chamemos \(Z=\frac{1}{2}(U_1+i U_2)\), então \(Z^*=\frac{1}{2}(U_1-i U_2)\), onde \(*\) denota o complexo conjugado. Neste caso,
\(\mbox{Z}=\frac{1}{2}\big(\mbox{E}(U_1)+i \mbox{E}(U_2)\big)=0\) e, similarmente, \(\mbox{E}(Z^*)=0\). Para variáveis aleatórias
complexas com média zero, digamos \(X\) e \(Y\), \(\mbox{Cov}(X,Y)=\mbox{E}(XY^*)\). Portanto
\begin{equation}
\begin{array}{rcl}
\mbox{Var}(Z) & = & \mbox{E}(|Z|^2) \, = \, \mbox{E}(ZZ^*) \, = \, \displaystyle \frac{1}{4}\mbox{E}\big( (U_1+i U_2)(U_1-i U_2)\big) \\
& = & \displaystyle \frac{1}{4}\big(\mbox{E}(U_1^2)+\mbox{E}(U_2^2) \big) \, = \, \frac{\sigma^2}{2}\cdot
\end{array}
\end{equation}
Similarmente \(\displaystyle \mbox{Var}(Z^*)=\frac{\sigma^2}{2}\).
Além disso, desde que \(Z^{**}=Z\),
\begin{equation}
\mbox{Cov}(Z,Z^*) \, = \, \mbox{E}(ZZ^{**}) \, = \, \displaystyle \frac{1}{4}\mbox{E}\big( (U_1+i U_2)(U_1-i U_2)\big) \, = \,
\frac{1}{4}\big(\mbox{E}(U_1^2)-\mbox{E}(U_2^2) \big) \, = \, 0\cdot
\end{equation}
Portanto, (4.13) pode ser escrito como
\begin{equation}
X_t \, = \, Z e^{-2\pi \, \, i \omega_0 t}+Z^* e^{2\pi \, \, i \omega_0 t} \, = \, \displaystyle \int_{-\frac{1}{2}}^\frac{1}{2}
e^{2\pi \, \, i \omega t}\mbox{d}Z(\omega),
\end{equation}
onde \(Z(\omega)\) é um processo aleatório de valor complexo que faz saltos não correlacionados em \(-\omega_0\) e
\(\omega_0\) com média-zero e variância \(\sigma^2/2\). A integração estocástica é discutida em
mais detalhes na Seção C.4.2.
Teorema IV.5. Representação espectral de um processo estacionário.
Se \(X_t\) é um processo estacionário de média zero, com distribuição espectral \(F(\omega)\) como dado na
Proposição IV.1, então existe um processo estocástico de valor complexo \(Z(\omega)\), no intervalo \(\omega \in [-1/2,1/2]\),
com incrementos estacionários não-correlacionados não-sobrepostos, tal que \(X_t\) pode ser escrito como a integral
estocástica (ver Seção C.4.2)
\begin{equation}
X_t \, = \, \int_{-\frac{1}{2}}^\frac{1}{2} e^{2\pi \, i \, \omega t}\mbox{d}Z(\omega),
\end{equation}
onde, para \(-1/2\leq \omega\leq 1/2\),
\begin{equation}
\mbox{Var}\big(Z(\omega_2)-Z(\omega_1)\big) \, = \, F(\omega_2)-F(\omega_1)\cdot
\end{equation}
Demonstração Ver Teorema C.2 ▉
IV.3 Periodograma e transformada discreta de Fourier
Agora estamos pronto para unir o periodograma, que é o conceito amostral apresentado na Seção IV.1, com a densidade espectral,
que é o conceito populacional da Seção IV.2.
Definição IV.1 Transformada discreta de Fourier.
Dada a amostra \(X_1,\cdots,X_n\) definimos a Transformada Discreta de Fourier (DFT) como sendo
\begin{equation}
d(\omega_j) \, = \, \frac{1}{n}\sum_{t=1}^n X_t e^{-2\pi \, i \, \omega_j t},
\end{equation}
para \(j=0,1,\cdots,n-1\), onde as frequências \(\omega_j=j/n\), são chamadas de frequências fundamentais ou frequências de Fourier.
Se \(n\) é um inteiro altamente composto, isto é, tem muitos fatores o DFT pode ser calculado pela transformada rápida de
Fourier (FFT) introduzida em Cooley and Tukey (1965). Além disso, diferentes pacotes escalonam a FFT de maneira diferente, por isso é
uma boa ideia consultar a documentação. R calcula o DFT definida acima sem o fator \(\frac{1}{n}\), mas com um fator adicional de
\(e^{2\pi \, i \, \omega_j}\) que pode ser ignorado porque estaremos interessados no quadrado do módulo da DFT. Às vezes, é
útil explorar o resultado da inversão para DFTs, o que mostra que a transformação linear é de um para um.
Para o DFT inverso temos,
\begin{equation}
X_t \, = \, \frac{1}{n}\sum_{t=1}^{n-1} d(\omega_j) e^{2\pi \, i \, \omega_j t},
\end{equation}
para \(t=1,\cdots,n\). O exemplo a seguir mostra como calcular o DFT e seu inverso em R para o conjunto de dados \(\{1,2,3,4\}\); note que R
escreve um número complexo \(z = a + ib\) como a+bi.
Agora definimos o periodograma como o quadrado do módulo da DFT.
Definição IV.2 Periodograma.
Dada a amostra \(X_1,\cdots,X_n\) definimos o periodograma como sendo
\begin{equation}
I(\omega_j) \, = \, \big| d(\omega_j)\big|^2,
\end{equation}
para \(j=0,1,2,\cdots,n-1\).
Note que \(I(0)=n\overline{X}^2\), sendo \(\overline{X}\) é a média amostral. Também
\begin{equation}
\sum_{t=1}^n e^{-2\pi \, i \, tj/n} \, = \, 0, \qquad \mbox{para} \qquad j\neq 0,
\end{equation}
ist porque \(\sum_{t=1}^n z^t = z\frac{1-z^n}{1-z}\), para \(z\neq 1\), neste caso \(z^n = e^{-2\pi \, i \, j}=1\). Podemos então escrever a DFT como
\begin{equation}
d(\omega_j) \, = \, \frac{1}{n}\sum_{t=1}^n (X_t-\overline{X})e^{-2\pi \, i \, \omega_j t},
\end{equation}
para \(j\neq 0\)
Portanto,
\begin{equation}
\begin{array}{rcl}
I(\omega_j) & = & \big| d(\omega_j)\big|^2 \, = \, \displaystyle \frac{1}{n}\sum_{t=1}^n\sum_{s=1}^n (X_t-\overline{X})(X_s-\overline{X})e^{-2\pi \, i \, \omega_j (t-s)} \\
& = & \displaystyle \frac{1}{n}\sum_{h=-(n-1)}^{n-1}\sum_{t=1}^{n-|h|} (X_{t+|h|}-\overline{X})(X_t-\overline{X})e^{-2\pi \, i \, \omega_j h} \\
& = & \displaystyle \sum_{h=-(n-1)}^{n-1} \widehat{\gamma}(h) e^{-2\pi \, i \, \omega_j h},
\end{array}
\end{equation}
para \(j\neq 0\), onde colocamos \(h=t-s\), com \(\widehat{\gamma}(h)\) como dado na Definição I.14. Note que a expressão acima
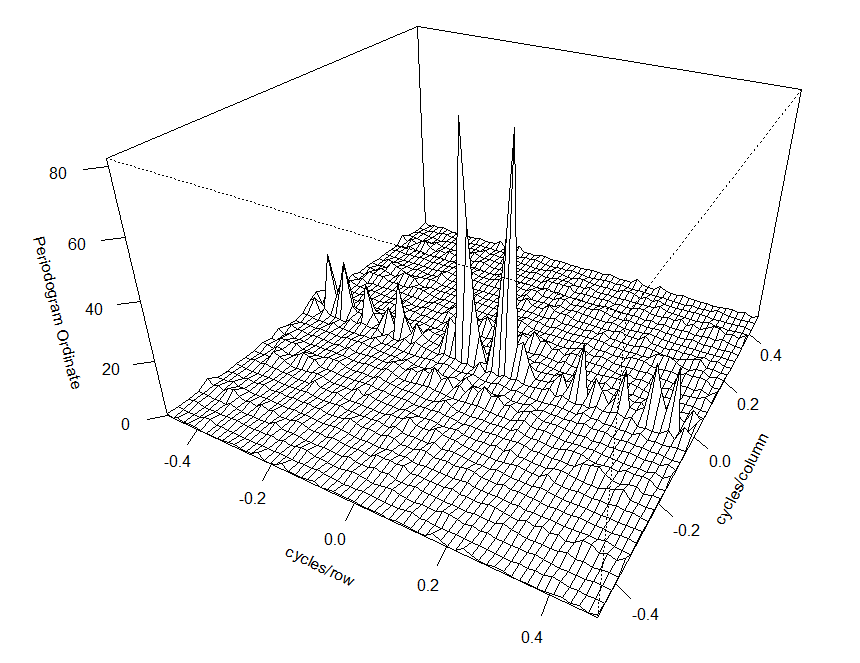
pode ser usado para obter \(\widehat{\gamma}(h)\) tomando o DFT inverso de \(I(\omega_j)\). Esta abordagem foi usada no Exemplo I.31 para obter um ACF bidimensional.
Em vista da expressão acima, o periodograma, \(I(\omega_j)\) é a versão amostral de \(f(\omega_j)\), a densidade espectral. Ou seja, podemos pensar
no periodograma como a densidade espectral amostral de \(X_t\).
Inicialmente, a expressão acima parece ser uma maneira óbvia de estimar uma densidade espectral, ou seja, basta colocar um chapéu
em \(\gamma(h)\) e somar até onde o tamanho da amostra permitir. No entanto, após uma análise mais aprofundada, verifica-se que
este não é um bom estimador, porque usa algumas estimativas ruins de \(\gamma(h)\). Por exemplo, há apenas um par de observações,
\((X_1,X_n)\) para estimar \(\gamma(n-1)\) e apenas dois pares \((X_1,X_{n-1})\) e \((X_1,X_n)\) que podem ser usados para estimar \(\gamma(n-1)\),
e assim por diante. Discutiremos esse problema ainda mais à medida que progredirmos, mas uma melhoria óbvia seria algo como
\begin{equation}
\widehat{f}(\omega) \, = \, \sum_{|h|\leq m} \widehat{\gamma}(h)e^{-2\pi \, i \, \omega h},
\end{equation}
onde \(m\) é muito menor que \(n\).
às vezes é útil trabalhar com as partes real e imaginária da DFT individualmente. Para este fim, definimos as seguintes transformações.
Definição IV.3 Transformações coseno e seno.
Dada a amostra \(X_1,\cdots,X_n\) definimos a transformação coseno
\begin{equation}
d_c(\omega_j) \, = \, \frac{1}{n}\sum_{t=1}^n X_t \cos(2\pi\omega_j t),
\end{equation}
e a transformação seno
\begin{equation}
d_s(\omega_j) \, = \, \frac{1}{n}\sum_{t=1}^n X_t \sin(2\pi\omega_j t),
\end{equation}
onde \(\omega_j=j/n\) para \(j=0,1,\cdots,n-1\).
Notemos que \(d(\omega_j)=d_c(\omega_j)-i d_s(\omega_j)\) e, portanto
\begin{equation}
I(\omega_j)=d_c^2(\omega_j)+d_s^2(\omega_j)\cdot
\end{equation}
Também discutimos o fato de que a análise espectral pode ser pensada como uma análise de variância. O próximo
exemplo examina essa noção.
Exemplo IV.10. ANOVA espectral.
Seja \(X_1,\cdots,X_n\) uma amostra de tamanho \(n\), onde para facilidade, \(n\) é ímpar. Então, lembrando o Exemplo IV.2,
\begin{equation}
X_t \, = \, a_0 +\sum_{j=1}^m \big( a_j\cos(2\pi \omega_j t)+b_j\sin(2\pi\omega_j t)\big),
\end{equation}
onde \(m=(n-1)/2\), é exato para \(t = 1,\cdots,n\). Em particular, usando fórmulas de regressão múltipla, temos
\(a_0=\overline{X}\),
\begin{equation}
\begin{array}{rcl}
a_j & = & \displaystyle \frac{2}{n}\sum_{t=1}^n X_t \cos(2\pi \omega_j t) \, = \, \frac{2}{\sqrt{n}} d_c(\omega_j),
b_j & = & \displaystyle \frac{2}{n}\sum_{t=1}^n X_t \sin(2\pi \omega_j t) \, = \, \frac{2}{\sqrt{n}} d_s(\omega_j)\cdot
\end{array}
\end{equation}
Portanto, podemos escrever
\begin{equation}
(X_t-\overline{X}) \, = \, \frac{2}{n}\sum_{j=1}^m \big( d_c(\omega_j)\cos(2\pi \omega_j t) + d_s(\omega_j)\sin(2\pi \omega_j t) \big),
\end{equation}
para \(t = 1,\cdots,n\). Tomando o quadrado em ambos os lados e somando obtemos
\begin{equation}
\sum_{t=1}~n (X_t-\overline{X})^2 \, = \, \displaystyle 2\sum_{j=1}^m \big( d_c^2(\omega_j)+d_s^2(\omega_j)\big) \, = \, 2\sum_{j=1}^m I(\omega_j),
\end{equation}
usando os resultados do Exercício IV.1.
Assim, particionamos a soma dos quadrados em componentes harmônicos representados pela
freqüência \(\omega_j\) com o periodograma, \(I(\omega_j)\), sendo a regressão quadrada média. Isso leva à tabela ANOVA
para \(n\) ímpar:
O seguinte é um exemplo R para ajudar a explicar este conceito. Consideramos \(n = 5\) observações dadas por \(x_1 = 1\),
\(x_2 = 2\), \(x_3 = 3\), \(x_4 = 2\) e \(x_5 = 1\). Observe que os dados completam um ciclo, mas não em uma rota sinusoidal. Assim,
devemos esperar que o componente \(\omega_1 = 1/5\) seja relativamente grande, mas não exaustivo, e que o componente \(\omega_2 = 2/5\)
seja pequeno.
> x = c(1, 2, 3, 2, 1)
> c1 = cos(2*pi*1:5*1/5); s1 = sin(2*pi*1:5*1/5)
> c2 = cos(2*pi*1:5*2/5); s2 = sin(2*pi*1:5*2/5)
> omega1 = cbind(c1, s1); omega2 = cbind(c2, s2)
> anova(lm(x~omega1+omega2)) # ANOVA Table
Analysis of Variance Table
Response: x
Df Sum Sq Mean Sq F value Pr(>F)
omega1 2 2.74164 1.37082
omega2 2 0.05836 0.02918
Residuals 0 0.00000
> Mod(fft(x))^2/5 # o periodograma
[1] 16.20000000 1.37082039 0.02917961 0.02917961 1.37082039
# I(0) I(1/5) I(2/5) I(3/5) I(4/5)
Observe que \(I(0)=n\overline{x}^2=5\times 1.8^2=16.2\). Além disso, a soma dos quadrados associados aos resíduos (SSE) é zero, indicando um ajuste exato.
Exemplo IV.11. Análise espectral como Análise de Componentes Principais.
Também é possível pensar em análise espectral como uma Análise de Componentes Principais. Na Seção C.5, mostramos que
a densidade espectral pode ser considerada como os autovalores aproximados da matriz de covariância de um processo estacionário. Se \(X=(X_1,\cdots,X_n)\)
são \(n\) valores de uma série temporal de média zero \(X_t\) com densidade espectral \(f_{_X}(\omega)\), então
\begin{equation}
\mbox{Cov}(X) \, = \, \Gamma_n \, = \, \begin{pmatrix} \gamma(0) & \gamma(1) & \cdots & \gamma(n-1) \\
\gamma(1) & \gamma(0) & \cdots & \gamma(n-2) \\ \vdots & \vdots & \ddots & \vdots \\ \gamma(n-1) & \gamma(n-2) & \cdots & \gamma(0) \end{pmatrix}\cdot
\end{equation}
Para \(n\) suficientemente grande, os autovalores de \(\Gamma_n\) são
\begin{equation}
A_j \approx f(\omega_j) \, = \, \sum_{h=-\infty}^\infty \gamma(h)e^{-2\pi \, i \, hj/n},
\end{equation}
com autovetores aproximados
\begin{equation}
g^*_j \, = \, \displaystyle \frac{1}{\sqrt{n}} \Big( e^{-2\pi \, i \, 0j/n}, e^{-2\pi \, i \, 1j/n}, \cdots, e^{-2\pi \, i \, (n-1)j/n}\Big),
\end{equation}
para \(j=0,1,\cdots,n-1\). Considerando \(G\) ser a matriz complexa com colunas \(g_j\), então o vetor complexo \(Y = G^* X\) tem elementos
que são as DFTs,
\begin{equation}
y_j \, = \, \displaystyle \frac{1}{\sqrt{n}} \sum_{t=1}^n X_t e^{-2\pi \, i \, tj/n},
\end{equation}
para \(j=0,1,\cdots,n-1\). Neste caso, os elementos de \(Y\) são variáveis aleatórias complexas assintoticamente não
correlacionadas, com média zero e variância \(f(\omega_j)\). Além disso, \(X\) pode ser recuperado como \(X = GY\), de modo que
\begin{equation}
X_t \, = \, \displaystyle \frac{1}{\sqrt{n}} \sum_{j=0}^{n-1} Y_j e^{2\pi \, i \, tj/n}\cdot
\end{equation}
Agora estamos prontos para apresentar algumas propriedades em amostras grandes do periodograma. Primeiro, seja \(\mu\) a média de um processo
estacionário \(X_t\) com função de autocovariância absolutamente convergente \(\gamma(h)\) e densidade espectral \(f(\omega)\).
Podemos escrever
\begin{equation}
I(\omega_j) \, = \, \sum_{h=-(n-1)}^{n-1}\sum_{t=1}^{n-|h|} \big( X_{t+|h|}-\mu\big)\big( X_{t}-\mu\big)e^{-2\pi \, i \, \omega)j h}
\end{equation}
onde \(\omega_j\) é uma frequência fundamental diferente de zero. Tomando esperança acima obtemos
\begin{equation}
\mbox{E}\big( I(\omega_j)\big) \, = \, \sum_{h=-(n-1)}^{n-1}\sum_{t=1}^{n-|h|} \left(\frac{n-|h|}{n} \right)\gamma(h)e^{-2\pi \, i \, \omega)j h}\cdot
\end{equation}
Para qualquer dado \(\omega\neq 0\), escolha uma sequência de frequências fundamentais \(\omega_{j:n}\to\infty\), isto significa que \(\omega_{j:n}=j_n/n\), onde \(\{j_n\}\) é uma
seqëência de inteiros escolhidos de modo que \(j_n/n\) é a frequência de Fourier mais próxima de \(\omega\); consequentemente \(|j_n/n-\omega|\leq \frac{1}{2n}\). Disto,
segue que, c/quando \(n\to\infty\)
\begin{equation}
\mbox{E}\big( I(\omega_j)\big) \, \to\, f(\omega) \, = \, \sum_{h=-\infty}^{\infty}\sum_{h=-\infty}^{\infty} \gamma(h)e^{-2\pi \, i \, h\omega}\cdot
\end{equation}
Da Definição IV.2, temos \(I(0)=n\overline{X}^2\), então o resultado análogo deste anterior para o caso \(\omega=0\) é
\begin{equation}
\mbox{E}\big( I(0)\big) -n\mu^2 \, = \, n\mbox{Var}\big( \overline{X}\big) \, \to \, f(0), \qquad \mbox{quando} \; n\to\infty\cdot
\end{equation}
Em outras palavras, sob a soma absoluta de \(\gamma(h)\), a densidade espectral é a média de longo prazo do periodograma.
Propriedades assintóticas adicionais podem ser estabelecidas sob a condição de que a função de autocovariância satisfaça
\begin{equation}
\theta \, = \, \sum_{h=-\infty}^\infty |h| |\gamma(h)| \, < \infty\cdot
\end{equation}
Primeiro, notamos que cálculos diretos levam a
\begin{equation}
\begin{array}{rcl}
\mbox{Cov}\big( d_c(\omega_j) \, , \, d_c(\omega_k)\big) & = & \displaystyle \frac{1}{n}\sum_{s=1}^n\sum_{t=1}^n \gamma(s-t)\cos(2\pi\omega_j s)\cos(2\pi\omega_k t), \\
\mbox{Cov}\big( d_c(\omega_j) \, , \, d_s(\omega_k)\big) & = & \displaystyle \frac{1}{n}\sum_{s=1}^n\sum_{t=1}^n \gamma(s-t)\cos(2\pi\omega_j s)\sin(2\pi\omega_k t), \\
\mbox{Cov}\big( d_s(\omega_j) \, , \, d_s(\omega_k)\big) & = & \displaystyle \frac{1}{n}\sum_{s=1}^n\sum_{t=1}^n \gamma(s-t)\sin(2\pi\omega_j s)\sin(2\pi\omega_k t), \\
\end{array}
\end{equation}
onde as variâncias são obtidas configurando \(\omega_j=\omega_k\) nos termos acima. No Apêndice C, Seção C.2, mostramos que os termos os termos
acima possuem propriedades interessantes sob a suposição de que \(\theta < 0\) é válida. Em particular, para \(\omega_j,\omega_k\neq 0\) ou \(1/2\),
\begin{equation}
\begin{array}{rcl}
\mbox{Cov}\big( d_c(\omega_j) \, , \, d_c(\omega_k)\big) & = & \mbox{Cov}\big( d_s(\omega_j) \, , \, d_s(\omega_k)\big) \, = \,
\displaystyle \left\{ \begin{array}{ccl} \frac{1}{2}f(\omega_j)+\epsilon_n & & \omega_j=\omega_k \\
\epsilon_n & & \omega_j\neq \omega_k \end{array}\right., \\
\end{array}
\end{equation}
e
\begin{equation}
\mbox{Cov}\big( d_c(\omega_j) \, , \, d_s(\omega_k)\big) \, = \, \epsilon_n,
\end{equation}
onde o termo de erro \(\epsilon_n\) nas aproximações podem ser limitados,
\begin{equation}
|\epsilon_n| \leq \frac{\theta}{n},
\end{equation}
e \(\theta\) dado como anteriormente. Se \(\omega_j=\omega_k=0\) ou \(1/2\), o multiplicador 1/2 desaparece; observe que \(d_s(0)=d_s(1/2)=0\), então
\(\mbox{Cov}\big( d_s(\omega_j) , d_s(\omega_k)\big)\) dado acima não se aplica nestes casos.
Exemplo IV.12. Covariância das transformações seno e cosseno.
Para a série de médias móveis de três pontos do Exemplo I.9 e \(n = 256\) observações, a matriz de covariância
teórica do vetor \(D=\big( d_c(\omega_{26}),d_s(\omega_{26}),d_c(\omega_{27}),d_s(\omega_{27})\big)^\top\) é
\begin{equation}
\mbox{Cov}(D) \, = \, \left(\begin{array}{rr|rr} 0.3752 & -0.0009 & -0.0022 & -0.0010 \\
-0.0009 & 0.3777 & -0.0009 & 0.0003 \\ \hline -0.0022 & -0.0009 & 0.3667 & -0.0010 \\
-0.0010 & 0.0003 & -0.0010 & 0.3692 \end{array}\right)\cdot
\end{equation}
Os elementos diagonais podem ser comparados com metade dos valores espectrais teóricos de \(\frac{1}{2}f(\omega_{26})=0.3774\) para o espectro na
frequência \(\omega_{26}=26/256\) e de \(\frac{1}{2}f(\omega_{27}) =0.3689\) para o espectro em \(\omega_{27} = 27/256\). Assim, as transformações
de cosseno e seno produzem variáveis quase não correlacionadas com variâncias aproximadamente iguais a metade do espectro teórico.
Para este caso particular, o limite uniforme é determinado de \(\theta= 8/9\), rendendo \(|\epsilon_{256}|\leq 0.0035\) para o limite no erro de
aproximação.
Se \(X_t\) forem independentes identicamente distribuídas com média zero e variância \(\sigma^2\) e utilizando o Teorema do Limite Central,
obtemos que
\begin{equation}
d_c(\omega_{j:n})\sim N(0,\sigma^2/2) \qquad \mbox{e} \qquad d_s(\omega_{j:n})\sim N(0,\sigma^2/2),
\end{equation}
aproximadamente, de forma conjunta e independente, e independente de \(d_c(\omega_{k:n})\) e \(d_s(\omega_{k:n})\) desde que \(\omega_{j:n}\to \omega_1\) e
\(\omega_{k:n}\to \omega_2\) sendo que \(0< \omega \neq \omega_2< 1/2\). Lembremos que se \(\{Y_j\}\) forem variáveis aleatórias independentes
identicamente distribuídas de médai zero e variância \(\sigma^2\) e \(\{a_j\}\) uma sequência de constantes para os quais
\(\displaystyle \frac{1}{\max_{1\leq j\leq n} a_j^2}\sum_{j=1}^n a_j^2\to \infty\) quando \(n\to\infty\), então
\begin{equation}
\sum_{j=1}^n a_j Y_j \sim N\big( 0,\sum_{j=1}^n a_j^2\big),
\end{equation}
assintoticamente, veja a Definição A.5.
Notamos que neste caso \(f_{_X}(\omega)=\sigma^2\). Em vista do resultado anterior, segue-se imediatamente que, quando \(n\to\infty\)
\begin{equation}
\frac{2}{\sigma^2}I(\omega_{j:n}) \overset{D}{\longrightarrow} \chi_2^2 \qquad \mbox{e} \qquad \frac{2}{\sigma^2}I(\omega_{k:n}) \overset{P}{\longrightarrow} \chi_2^2,
\end{equation}
com \(I(\omega_{j:n})\) e \(I(\omega_{k:n})\) sendo assintoticamente independentes, onde \(\chi_v^2\) denota uma variável aleatória
qui-quadrado com \(\nu\) graus de liberdade. Se o processo também for gaussiano, as declarações acima serão verdadeiras
para qualquer tamanho de amostra.
Usando a teoria do limite central da Seção C.2, é razoavelmente fácil estender os resultados do caso independentes igualmente
distribuídas para o caso de um processo linear.
Teorema IV.6. Distribuição das ordenadas do periodograma.
Seja
\begin{equation}
X_t \, = \, \displaystyle \sum_{j=-\infty}^\infty \psi_j W_{t-j},
\end{equation}
sendo que \(\displaystyle \sum_{j=-\infty}^\infty |\psi_j|< \infty\) e \(W_t\) variáveis aleatórias independentes e igualmente distribuídos de média zero e variância \(\sigma^2_{_W}\) satisfazendo que
\(\theta = \displaystyle \sum_{h=-\infty}^\infty |h| |\gamma(h)| \, < \infty\). Então, para qualquer coleção de \(m\) distintas frequências \(\omega_{j}\in (0,1/2)\), com
\(\omega_{j:n}\to\omega_j\)
\begin{equation}
2\frac{I(\omega_{j:n})}{f(\omega_j)} \overset{D}{\longrightarrow} \chi_2^2,
\end{equation}
independentes e igualmente distribuídas desde que \(f(\omega_j)>0\), para \(j=1,\cdots,m\).
Demonstração Este resultado é indicado mais precisamente no Teorema C.7 ▉
Outras abordagens para a normalidade em amostras grandes das ordenadas do periodograma são em termos de cumulantes, como em Brillinger (1981)
ou em termos de condições de mistura, como em Rosenblatt (1956a). Aqui, adotamos a abordagem usada por Hannan (1970), Fuller (1996) e
Brockwell e Davis (1991).
O resultado assintótico no Teorema IV.6 pode ser usado para derivar um intervalo de confiança aproximado para o
espectro da maneira usual. Seja \(\chi^2_\nu\) denotando a cauda de probabilidade \(\alpha\) mais baixa para a distribuição qui-quadrado
com \(\nu\) graus de liberdade; isso é,
\begin{equation}
P\big( \chi_\nu^2\leq \chi_nu^2(\alpha)\big) \, = \, \alpha\cdot
\end{equation}
Então, um intervalo de confiança aproximado de \(100\times (1-\alpha)%\) para a função de densidade espectral seria
da forma
\begin{equation}
\frac{2I(\omega_{j:n})}{\displaystyle \chi_2^2(1-\alpha/2)}\leq f(\omega)\leq \frac{2I(\omega_{j:n})}{\displaystyle \chi_2^2(\alpha/2)}\cdot
\end{equation}
Muitas vezes, as tendências estão presentes e devem ser eliminadas antes do cálculo do periodograma. As tendências introduzem
componentes de frequência extremamente baixa no periodograma que tendem a obscurecer a aparência em frequências mais altas. Por esta
razão, é usualmente convencional centralizar os dados antes de uma análise espectral usando dados ajustados à média da
forma \(X_t-\overline{X}\) para eliminar o componente zero ou \(d-c\) ou usar dados retificados da forma \(X_t-\widehat{\beta}_1-\widehat{\beta}_2 t\) para
eliminar o termo que será considerado meio ciclo pela análise espectral. Observe que as regressões polinomiais de ordem mais alta
em \(t\) ou suavização não paramétrica (filtragem linear) podem ser usadas nos casos em que a tendência é
não-linear.
Como indicado anteriormente, muitas vezes é conveniente calcular os DFTs e, portanto, o periodograma, usando o algoritmo da transformação
rápida de Fourier (FFT). A FFT utiliza um número de redundâncias no cálculo da DFT quando \(n\) é altamente composto; isto
é, um inteiro com muitos fatores de \(2, 3\) ou \(5\), sendo o melhor caso quando \(n = 2^p\) é um fator de 2. Detalhes podem ser encontrados
em Cooley e Tukey (1965). Para acomodar essa propriedade, podemos preencher os dados centralizados ou retificados de comprimento \(n\) até o próximo
composto altamente inteiro \(n'\) adicionando zeros, ou seja, definindo \(X_{n+1}^c=X_{n+2}^c=\cdots=X_{n'}^c=0\), onde \(X_t^c\) denota os dados centralizados.
Isto significa que as ordenadas da frequência fundamental serão \(\omega_j=l/n'\) em vez de \(j/n\). Ilustramos considerando o periodograma das
séries de IOS e Recrutamento mostradas na figura do Exemplo I.5. Lembre-se de que são séries mensais e \(n = 453\) meses. Para encontrar
\(n'\) em R, use o comando nextn(453) para ver que \(n' = 480\) será usado nas análises espectrais por padrão.
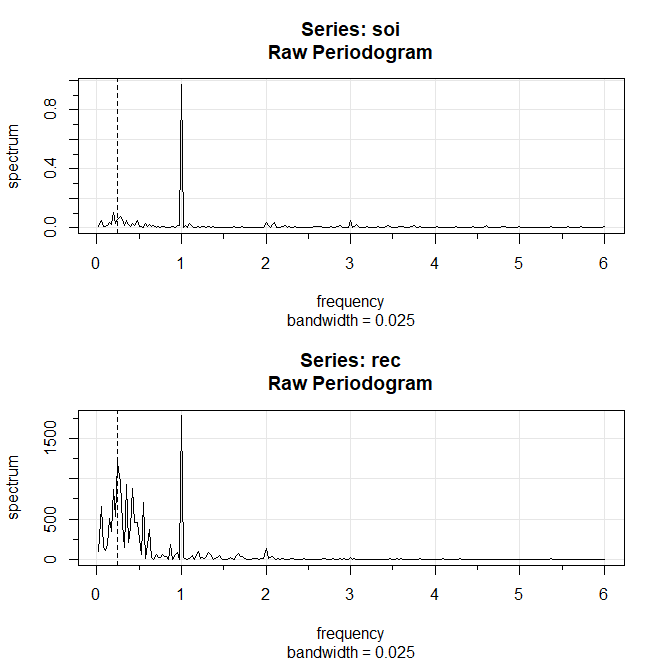
Exemplo IV.13. Periodograma da série SOI e Recrutamento.
A figura abaixo mostra os periodogramas de cada série, onde o eixo da frequência é rotulado em múltiplos de \(∆ = 1/12\).
Como indicado anteriormente, os dados centralizados foram preenchidos com uma série de comprimento de 480. Notamos um pico de banda estreita no
óbvio ciclo anual (12 meses) \(\omega = 1∆ = 1/12\). Além disso, há uma potência considerável em uma banda
larga nas frequências mais baixas, centradas no ciclo de quatro anos (48 meses) \(\omega = \frac{1}{4}∆ = 1/48\) representando um possível
efeito El Niño. Essa atividade de banda larga sugere que o possível ciclo El Niño é irregular, mas tende a ser em torno de quatro
anos em média. Continuaremos abordando esse problema à medida que avançamos para análises mais sofisticadas.
Observando que \(\chi^2_2(0.025)=0.05\) e \(\chi^2_2(0.975)=7.38\), podemos obter intervalos de confiança aproximados de 95% para as frequências
de interesse. Por exemplo, o periodograma da série SOI é \(I_{SOI}(1/12)=0.97\) no ciclo anual. Um intervalo de confiança aproximado
de 95% para o espectro \(f_{SOI}(1/12)\) é então
\begin{equation}
\left( \displaystyle 2\frac{0.97}{7.38}, \, 2\frac{0.97}{0.05}\right) \, = \, (0.26, \, 38.4),
\end{equation}
que é muito grande para ser de muito uso. Notamos, entretanto, que o valor mais baixo de 0.26 é maior do que qualquer outro periodograma
ordenado, então é seguro dizer que este valor é significativo. Por outro lado, um intervalo de confiança de 95% para o
espectro no ciclo de quatro anos, \(f_{SOI}(1/48)\) é
\begin{equation}
\left( \displaystyle 2\frac{0.05}{7.38}, \, 2\frac{0.05}{0.05}\right) \, = \, (0.01, \, 2.12),
\end{equation}
que novamente é extremamente amplo e com o qual somos incapazes de estabelecer significância do pico.
Figura IV.5: Periodograma das séries SOI e Recrutamento, \(n = 453\) e \(n' = 480\), onde o eixo da frequência é rotulado em múltiplos
de \(∆= 1/12\). Observe os picos comuns em \(\omega = 1∆ = 1/12\) ou um ciclo por ano (12 meses) e alguns valores maiores próximos
\(\omega = \frac{1}{4}∆ = 1/48\) ou um ciclo a cada quatro anos (48 meses).
Mostramos agora os comandos R que podem ser usados para reproduzir a figura acima. Para calcular e representar graficamente o periodograma, usamos o comando
mvspec disponível em astsa. Notamos que o valor de \(∆\) é o recíproco do valor frequency
para os dados de um objeto de série temporal. Se os dados não são um objeto de série temporal, frequency é
definida como 1. Além disso, definimos log = "no" porque o periodograma é plotado na escala \(\log_{10}\) por padrão. A figura
acima exibe uma largura de banda ou bandwidth. Vamos discutir a largura de banda na próxima seção, então ignore
isso por enquanto.
O exemplo anterior deixou claro que o periodograma como um estimador é suscetível a grandes incertezas e precisamos encontrar uma maneira de
reduzir a variância. Não surpreendentemente, este resultado segue se considerar no Teorema IV.6 o fato de que, para qualquer \(n\), o periodograma
é baseado em apenas duas observações. Lembre-se de que a esperança e a variância da distribuição \(\chi^2(\nu)\)
são \(\nu\) e \(\nu^2\), respectivamente. Assim, usando o resultado do Teorema IV.6, temos \(I(\omega)\sim \frac{1}{2}f(\omega)\chi^2(2)\), implicando que
\begin{equation}
\mbox{E}\big( I(\omega)\big)\approx f(\omega) \qquad \mbox{e} \qquad \mbox{Var}\big( I(\omega)\big)\approx f(\omega)^2\cdot
\end{equation}
Consequentemente, \(\mbox{Var}\big(I(\omega)\big)\nrightarrow 0\) quando \(n\to\infty\) e, portanto, o periodograma não é um estimador consistente da densidade espectral. A solução para este dilema pode ser resolvida suavizando o periodograma.
IV.4 Estimação espectral não paramétrica
Para continuar a discussão que terminou a seção anterior, introduzimos uma banda de frequência \(\mathcal{B}\) de \(L≪ n\)
frequências fundamentais contíguas, centradas em torno da frequência \(\omega_j=j/n\), que é escolhido perto de uma frequência
de interesse \(\omega\). Para frequências da forma \(\omega^*=\omega_j+k/n\), seja
\begin{equation}
\mathcal{B} \, = \, \left\{ \omega^* \, : \, \omega_j-\frac{m}{n}\leq \omega^* \leq \omega_j+\frac{m}{n}\right\},
\end{equation}
onde
\begin{equation}
L \, = \, 2m+1
\end{equation}
é um número ímpar, escolhido de tal forma que os valores espectrais no intervalo \(\mathcal{B}\),
\begin{equation}
f(\omega_j+k/n), \qquad k=-m,\cdots,0,\cdots,m
\end{equation}
são aproximadamente iguais a \(f(\omega)\). Essa estrutura pode ser realizada para tamanhos de amostra grandes, conforme mostrado formalmente
na Seção C.2. Os valores do espectro nesta faixa devem ser relativamente constantes para que os espectros suavizados definidos abaixo
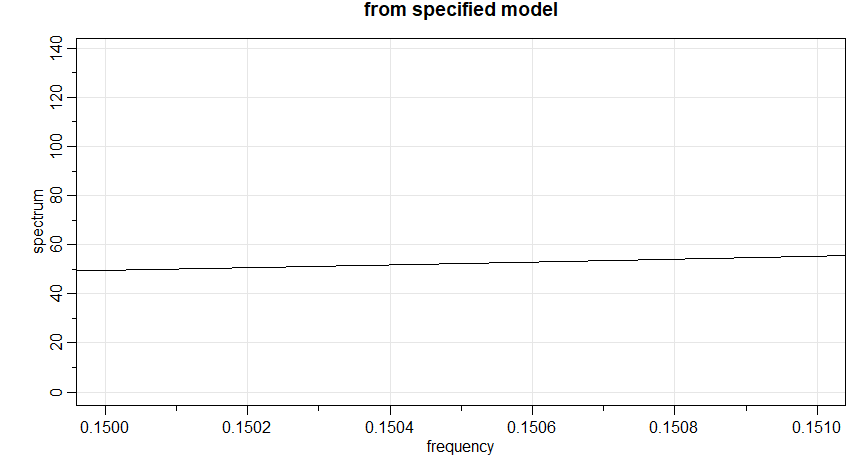
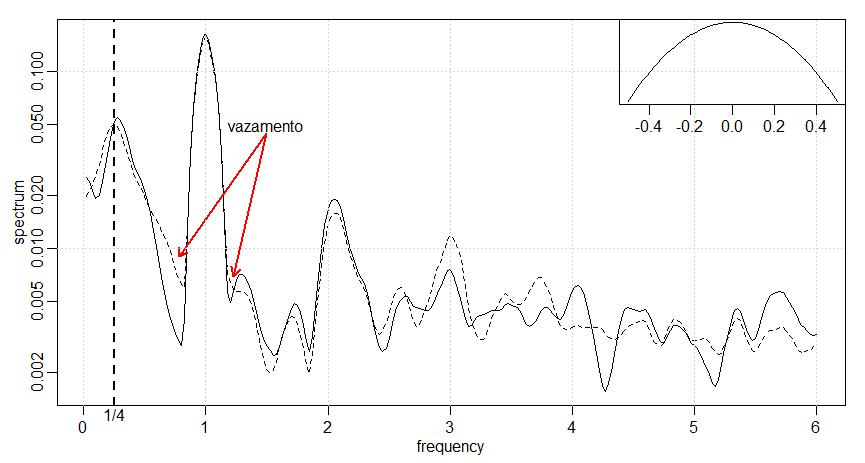
serem bons estimadores. Por exemplo, para ver uma pequena seção do espectro \(AR(2)\), próximo ao pico, mostrado na figura do Exemplo
IV.13, use
Figura IV.6: Uma pequena seção, perto do pico, do espectro do modelo \(AR(2)\) mostrado na figura do Exemplo IV.13.
Definimos agora o periodograma médio ou suavizado como a média dos valores do periodograma, digamos,
\begin{equation}
\overline{f}(\omega) \, = \, \frac{1}{L}\sum_{k=-m}^m I(\omega_j+k/n),
\end{equation}
sobre a banda \(\mathcal{B}\). Sob a suposição de que a densidade espectral é razoavelmente constante na banda \(\mathcal{B}\),
e em vista da conclusão do Teorema IV.6 podemos mostrar que sob condições apropriadas, para \(n\) grande, o
periodograma tem distribuição aproximadamente como variáveis aleatórias independentes \(f(\omega)\chi_2^2/2\), para
\(0< \omega < 1/2\), contanto que mantenhamos \(L\) relativamente pequeno em relação a \(n\). Este resultado é discutido
formalmente na Seção C.2. Assim, sob essas condiçõs, \(L\overline{f}(\omega)\) é a soma de aproximadamente \(L\)
variáveis aleatórias independentes \(f(\omega)\chi_2^2/2\). Daqui resulta que, para \(n\) grande
\begin{equation}
2\frac{L\overline{f}(\omega)}{f(\omega)}\sim \chi^2_{2L}\cdot
\end{equation}
As condições à quais fazemos referência acima, que são suficientes, são que \(X_t\) seja um processo linear,
como descrito na Proposição IV.6, com \(\sum_j \sqrt{|j|}|\psi_j| < \infty\) e que \(W_t\) tenha quarto momento finito.
Neste cenário, onde suavizamos o periodograma pela média simples, parece razoável chamar a largura do intervalo de
frequência definido por \(\mathcal{B}\),
\begin{equation}
B=\frac{L}{n},
\end{equation}
a largura de banda ou bandwidth. Existem muitas definições de largura de banda e uma excelente discussão pode ser encontrada
em Percival and Walden (1993, §6.7). O valor de largura de banda usado em R para spec.pgram é baseado em Grenander
(1951). A ideia básica é que a largura de banda pode estar relacionada ao desvio padrão da distribuição de
ponderação. Para a distribuição uniforme na faixa de frequência \(-m/n\) a \(m/n\), o desvio padrão
é \(L/n\sqrt{12}\), usando uma correção de continuidade. Consequentemente, no caso de \(\overline{f}(\omega)\), o R irá
reportar uma largura de banda de \(L/n\sqrt{12}\), o que equivale a dividir nossa definição por \(\sqrt{12}\). Note que no caso
extremo \(L = n\), teríamos \(B = 1\) indicando que tudo foi usado na estimação. Nesse caso, o R relataria uma largura de
banda de \(1/\sqrt{12}\approx 0.29\), o que parece perder o ponto.
O conceito de largura de banda, no entanto, torna-se mais complicado com a introdução de estimadores espectrais que suavizam com pesos
desiguais. Note que a expressão acima implica que os graus de liberdade podem ser expressos como
\begin{equation}
2L \, = \, 2Bn,
\end{equation}
ou o dobro do tempo de largura de banda do produto.
O resultado \(\displaystyle 2\frac{L\overline{f}(\omega)}{f(\omega)}\sim \chi^2_{2L}\) pode ser rearranjado para obter uma aproximação do
intervalo de confiança com \(100(1-\alpha)%\) probabilidade de cobertura, da forma
\begin{equation}
\frac{2L\overline{f}(\omega)}{\chi^2_{2L}(1-\alpha/2)} \leq f(\omega)\leq \frac{2L\overline{f}(\omega)}{\chi^2_{2L}(\alpha/2)},
\end{equation}
para o verdadeiro espectro \(f(\omega)\).
Muitas vezes, o impacto visual de um gráfico de densidade espectral será melhorado ao traçar o logaritmo do espectro
em vez do espectro propriamente, a transformação logarítmica é a transformação estabilizadora
da variância nesta situação. Esse fenômeno pode ocorrer quando as regiões do espectro existem com picos de interesse
muito menores do que alguns dos principais componentes de potência. Tomando logaritmos no intervalos de confiança acima,
obtemos um intervalo para o logaritmo do espectro dado por
\begin{equation}
\left\{ \log\big( \overline{f}(\omega)\big)-a_{_L} \, , \, \log\big( \overline{f}(\omega)\big)+b_{_L}\right\},
\end{equation}
onde
\begin{equation}
a_{_L} \, = \, -\log(2L)+\log\big(\chi^2_{2L}(1-\alpha/2) \big) \qquad \mbox{e} \qquad b_{_L} \, = \, \log(2L)-\log\big(\chi^2_{2L}(\alpha/2) \big)
\end{equation}
não dependem de \(\omega\).
Se forem acrescentados zeros antes de calcular os estimadores espectrais precisamos ajustar os graus de liberdade, porque não se obtém mais
informações por preenchimento, e uma aproximação é substituir \(2L\) por \(2Ln/n'\). Assim, definimos os graus de liberdade
ajustados como
\begin{equation}
df \, = \, \frac{2Ln}{n'}\cdot
\end{equation}
Assim, os intervalos de confiança são
\begin{equation}
\frac{df\overline{f}(\omega)}{\chi^2_{df}(1-\alpha/2)} \leq f(\omega)\leq \frac{df\overline{f}(\omega)}{\chi^2_{df}(\alpha/2)}\cdot
\end{equation}
Várias suposições são feitas no cálculo dos intervalos de confiança aproximados acima, que podem não
se manter na prática. Nesses casos, pode ser razoável empregar técnicas de reamostragem, como um dos bootstraps paramétricos
propostos por Hurvich and Zeger (1987) ou um bootstrap não paramétrico proposto por Paparoditis and Politis (1999). Para desenvolver
as distribuições bootstrap, assumimos que as transformadas discretas de Fourier contíguas em uma banda de frequências vieram
todas de uma série temporal com espectro idêntico \(f(\omega)\). Isso, na verdade, é exatamente a mesma suposição
feita ao derivar a teoria de grandes amostras. Podemos, então, simplesmente re-amostrar as \(L\) transformadas diiscretas de Fourier na banda,
com a substituição, calculando uma estimativa espectral de cada amostra de bootstrap. A distribuição amostral dos
estimadores bootstrap aproxima a distribuição do estimador espectral não paramétrico. Para mais detalhes, incluindo as
propriedades teóricas de tais estimadores, ver Paparoditis and Politis (1999).
Antes de prosseguir, consideramos o cálculo dos periodogramas médios para as séries SOI e Recrutamento.
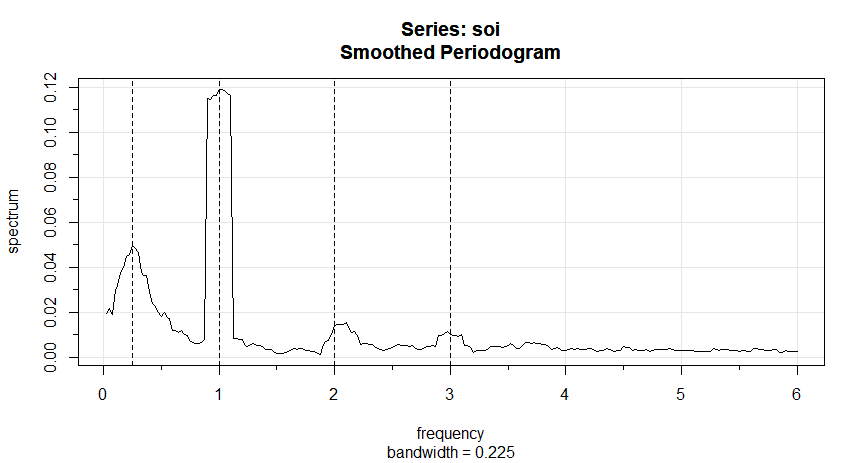
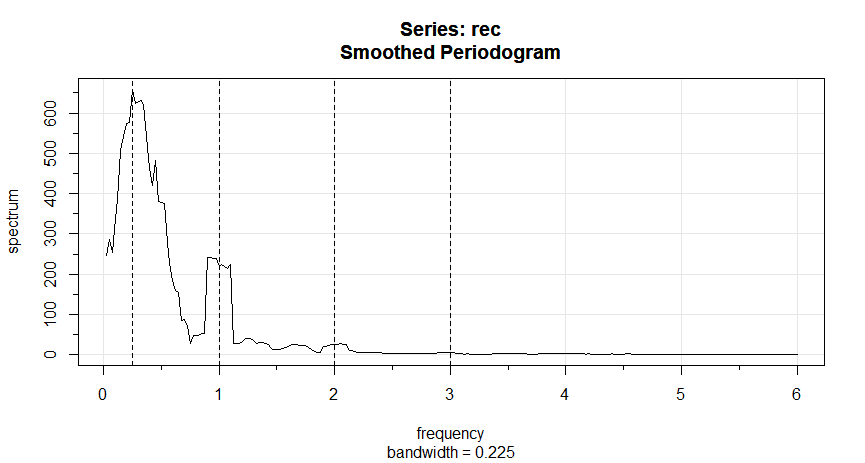
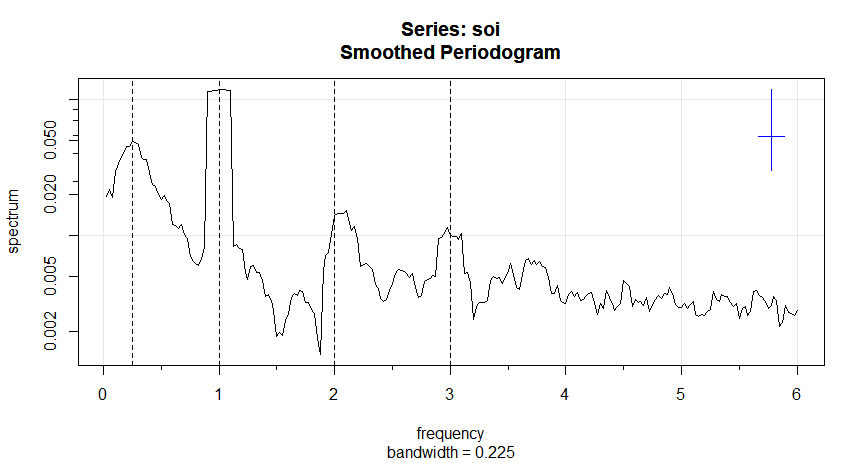
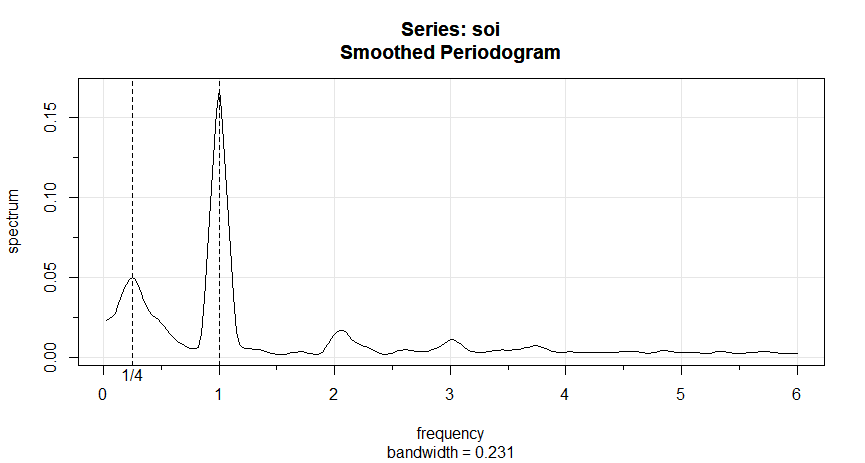
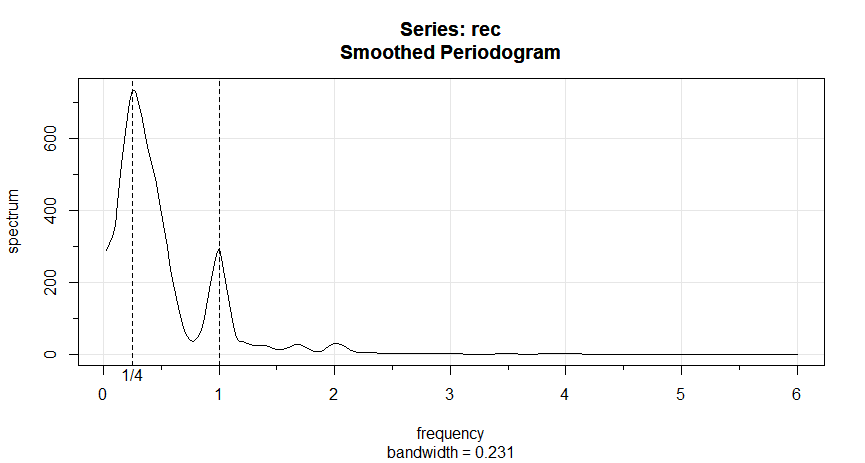
Exemplo IV.14. Periodograma médio para SOI e Recrutamento.
Geralmente, é uma boa idéia tentar várias larguras de banda que parecem ser compatíveis com a forma geral geral do
espectro, conforme sugerido pelo periodograma. Discutiremos esse problema com mais detalhes após o exemplo. Os periodogramas das séries
SOI e Recrutamento, previamente calculados no gráfico do Exemplo IV.13, sugerem que a potência na frequência mais baixa do
El Niño precisa de suavização para identificar o período geral predominante. A tentativa de valores de \(L\) leva
à escolha \(L = 9\) como um valor razoável, e o resultado é exibido na figura abaixo.
Figura IV.7: Periodograma médio da série SOI e Recrutamento \(n = 453\), \(n' = 480\), \(L = 9\),
\(df = 17\), mostrando picos comuns no período de quatro anos, \(\omega=\frac{1}{4}\Delta = 1/48\) ciclos/mês, o
período anual, \(\omega = 1\Delta = 1/12\) ciclos/mês e alguns de seus harmônicos \(\omega = k\Delta\) para \(k = 2,3\).
Os espectros suavizados mostrados fornecem um meio-termo razoável entre a versão ruidosa, mostrada na Figura IV.5 e um espectro mais
suavizado, que pode perder alguns dos picos. Um efeito indesejável da média pode ser observado no ciclo anual \(\omega = 1\Delta\), onde os
picos de banda estreita que apareceram nos periodogramas na Figura IV.5 foram achatados e espalhados para frequências proacute;ximas. Também notamos
e marcamos o aparecimento de harmônicos do ciclo anual, isto é, frequências da forma \(\omega= k\Delta\) para \(k = 1,2,\cdots\). Os
harmônicos normalmente ocorrem quando um componente não sinusoidal periódico está presente; veja o Exemplo IV.15.
A Figura IV.7 pode ser reproduzida em R usando os seguintes comandos:
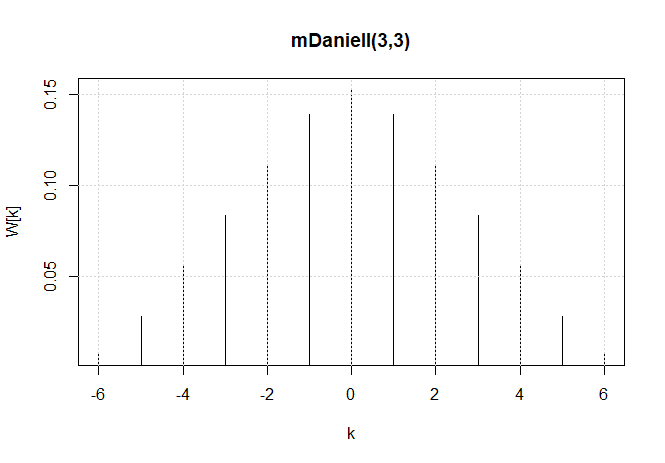
Para calcular periodogramas médios, use o kernel de Daniell e especifique \(m\), onde \(L = 2m + 1\) logo, \(L = 9\) e \(m = 4\) neste exemplo).
Explicaremos o conceito de kernel posteriormente nesta seção, especificamente antes do Exemplo IV.16.
A largura de banda exibida \(0.225\) é ajustada para o fato de que a escala de frequência do gráfico é em termos de ciclos por ano
em vez de ciclos por mês. Usando que \(B=L/n\), a largura de banda em termos de meses é \(9/480 =0.01875\); o valor exibido é
simplesmente convertido em anos: \(0.01875\times 12 =0.225\).
Os graus de liberdade ajustados são \(df = 2(9)(453)/480 \approx 17\). Podemos usar este valor para os intervalos de confiança de 95%,
com \(\chi^2_{df}(0.025) = 7.56\) e \(\chi^2_{df}(0.975) = 30.17\). Substituindo na expressão do intervalo de confiança fornece os
intervalos na Tabela IV.1 para as duas bandas de frequência identificadas como tendo a potência máxima.
Para examinar as duas possibilidades de potência de pico, podemos olhar para os intervalos de confiança de 95% e ver se os limites
inferiores são substancialmente maiores do que os níveis espectrais de linha de base adjacentes.
Por exemplo, a frequência do El Niño de 48 meses tem limites inferiores que excedem os valores que o espectro teria se houvesse simplesmente
uma função espectral subjacente suave sem os picos. A distribuição relativa de potência nas frequências é
diferente, com o SOI tendo menos potência na frequência mais baixa, em relação aos períodos sazonais e a série
Recrutamento tendo mais potência na frequência mais baixa ou El Niño.
As entradas na Tabela IV.1 para SOI e REC podem ser obtidas no R da seguinte forma:
Tabela IV.1. Intervalos de confiança para os espectros das séries SOI e Recrutamento.
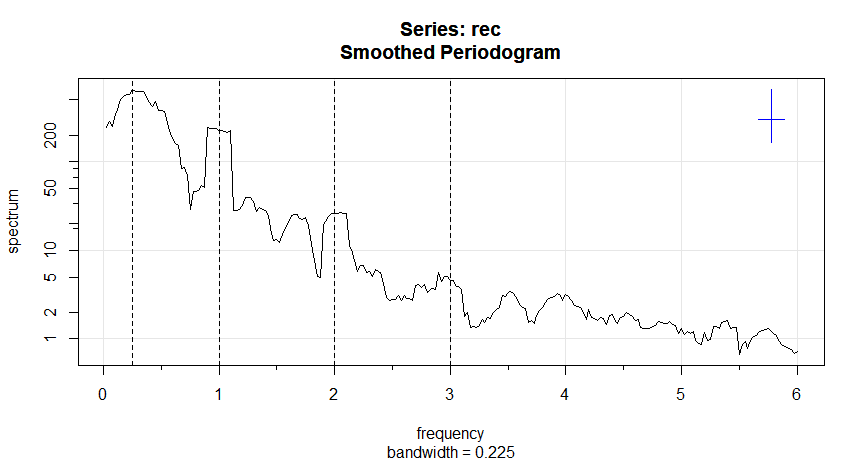
Finalmente, a Figura IV.8 mostra os periodogramas médios na Figura IV.7 plotados em uma escala \(\log_{10}\). Isto pode ser obtido colocando a instrução log = "y".
Observe que o gráfico padrão também mostra um intervalo de confiança genérico. Notamos que exibir as estimativas em uma escala logarítmica tende a enfatizar os componentes harmônicos.
Figura IV.8: Figura IV.7 com as ordenadas do periodograma médio plotadas em uma escala \(\log_{10}\). A tela no canto superior
direito representa um intervalo de confiança genérico de 95%, onde o a marca de escala do meio é a largura da largura de banda.
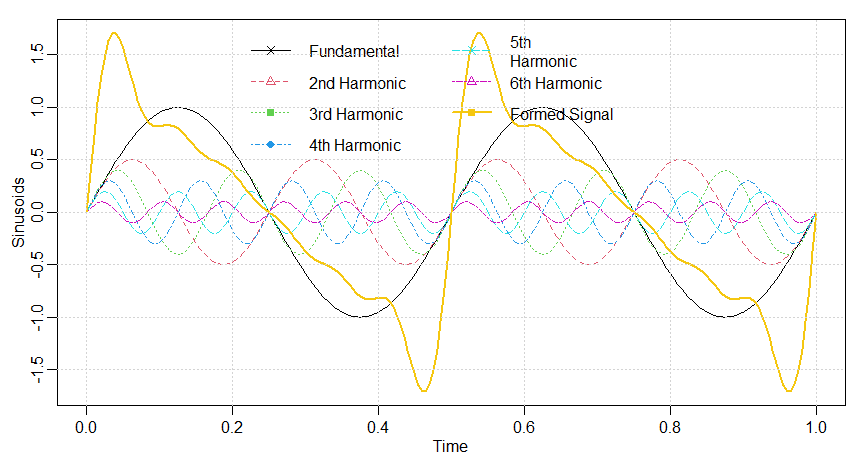
No exemplo anterior, vimos que os espectros dos sinais anuais exibiam picos menores nos harmônicos; ou seja, o espectro do sinal teve um grande pico
em \(\omega = 1\Delta = 1/12\) ciclos/mês o ciclo de um ano e picos menores em seus harmônicos \(\omega = k\Delta\) para \(k = 2,3,\cdots\), dois, três
e assim por diante, ciclos por ano. Geralmente, esse será o caso porque a maioria dos sinais não são sinusóides perfeitos ou perfeitamente
cíclicos. Nesse caso, os harmônicos são necessários para capturar o comportamento não senoidal do sinal. Como exemplo,
considere o sinal formado na Figura IV.9 a partir de uma sinusóide, fundamental, oscilando em dois ciclos por unidade de tempo junto com o segundo ao
sexto harmônico em amplitudes decrescentes. Em particular, o sinal foi formado como
\begin{equation*}
X_t \, = \, \sin(2\pi \, 2t)+0.5\sin(2\pi \, 4t)+0.4\sin(2\pi \, 6t)+0.3\sin(2\pi \, 8t)+0.2\sin(2\pi \, 10t)+0.1\sin(2\pi \, 12t),
\end{equation*}
para \(0\leq t\leq 1\). Observe que o sinal não é sinusoidal na aparência e aumenta rapidamente, em seguida, diminui lentamente.
Figura IV.9: Um sinal (linha sólida espessa) formado por uma senoide fundamental (linha sólida fina)
oscilando a dois ciclos por unidade de tempo e seus harmônicos conforme especificado acima.
O Exemplo IV.14 aponta a necessidade de se ter algum procedimento relativamente sistemático para decidir se os picos são significativos. A questão de
decidir se um único pico é significativo geralmente repousa em estabelecer o que poderíamos pensar como um nível de linha de base para o
espectro, definido vagamente como a forma que se esperaria ver se nenhum pico espectral estivesse presente. Geralmente, esse perfil pode ser adivinhado observando-se a
forma geral do espectro que inclui os picos; normalmente, um tipo de nível de linha de base será aparente, com os picos parecendo emergir desse nível de
linha de base. Se o limite de confiança inferior para o valor espectral ainda for maior do que o nível da linha de base em algum nível predeterminado de
significância, podemos reivindicar esse valor de frequência como um pico estatisticamente significativo. Para ser consistente com nossa indiferença declarada
aos limites superiores, podemos usar um intervalo de confiança unilateral.
Um aspecto importante da interpretação da importância dos intervalos de confiança e testes envolvendo espectros é que tipicamente, mais
de uma frequência será de interesse; de modo que estaremos potencialmente interessados em declarações simultâneas sobre toda uma
coleção de frequências. Por exemplo, seria injusto reivindicar na Tabela IV.1 as duas frequências de interesse como sendo estatisticamente
significativas e todos os outros candidatos potenciais como não significativos no nível geral de \(\alpha=0.05\). Nesse caso, seguimos a abordagem
estatística usual, observando que se \(K\) afirmações \(S_1,S_2,\cdots,S_k\) são feitas em nível de significância \(\alpha\), ou seja,
\(P(\{S_k\}) = 1 -\alpha\), então a probabilidade geral de todas as afirmações serem verdadeiras satisfaz a desigualdade de Bonferroni
\begin{equation*}
P(\{\mbox{todos os } S_k \mbox{ verdadeiros}\}) \, \geq 1-Ka\cdot
\end{equation*}
Por esta razão, é desejável definir o nível de significância para testar cada frequência em \(K\) se houver \(K\) frequências
potenciais de interesse. Se, a priori, potencialmente \(K = 10\) frequências forem de interesse, definir \(\alpha=0.01\) daria um nível de significância
geral do limite de \(0.10\).
O uso dos intervalos de confiança e a necessidade de suavização requerem que tomemos uma decisão sobre a largura de banda \(\mathcal{B}\) na qual
o espectro será essencialmente constante. Usar uma banda muito ampla tenderá a suavizar os picos válidos nos dados quando a suposição de
variância constante não for atendida ao longo da banda. Usar uma banda muito estreita levará a intervalos de confiança tão amplos que os
picos não serão mais estatisticamente significativos. Assim, notamos que há um conflito aqui entre propriedades de variância ou estabilidade de
largura de banda, que pode ser melhorada aumentando ou diminuindo \(\mathcal{B}\). Uma abordagem comum é tentar várias larguras de banda diferentes e olhar
qualitativamente nos estimadores espectrais para cada caso.
Para tratar do problema de resolução da largura de banda, deve ser evidente que o achatamento dos picos na Figura IV.7 e na Figura IV.8 foi devido ao fato de
que a média simples foi usada no cálculo de \(\overline{f}(\omega)\). Não há nenhuma razão particular
para usar a média simples e podemos melhorar o estimador empregando uma média ponderada, digamos
\begin{equation*}
\widehat{f}(\omega) \, = \, \sum_{k=-m}^m h_k I(\omega_j+k/n),
\end{equation*}
onde os pesos \(h_k> 0\) satisfazem \(\displaystyle \sum_{k=-m}^m h_k=1\).
Em particular, parece razoável que a resolução do estimador melhore se usarmos pesos que diminuem à medida que a distância do peso central \(h_0\)
aumenta; voltaremos a essa ideia em breve. Para obter o periodograma médio \(\overline{f}(\omega)\), defina \(h_k = L^{-1}\), para todo \(k\), onde \(L = 2m + 1\). A
teoria assintótica estabelecida para \(\overline{f}(\omega)\) ainda é válida para \(\widetilde{f}(\omega)\) desde que os pesos satisfaçam a condição
adicional de que se \(m\to\infty\) quando \(n\to\infty\) mas \(m/n\to 0\), então
\begin{equation*}
\sum_{k=-m}^m h_k^2 \to 0\cdot
\end{equation*}
(ii) \(\displaystyle \dfrac{1}{\sum_{k=-m}^m h_k^2} \mbox{Cov}\Big( \widehat{f}(\omega),\widehat{f}(\lambda)\Big) \, \to \, \left\{
\begin{array}{ccc} f^2(\omega), & \mbox{ quando } & \omega=\lambda\neq 0,1/2 \\ 0, & \mbox{ quando } & \omega\neq \lambda \\
2f^2(\omega), & \mbox{ quando } & \omega=\lambda=0 \mbox{ ou } 1/2\end{array}\right. \).
Já vimos esses resultados no caso de \(\overline{f}(\omega)\), onde os pesos são constantes, \(h_k = L^{-1}\), caso em que \(\sum_{k=-m}^m h_k^2 = L^{-1}\).
As propriedades de distribuição de \(\widehat{f}(\omega)\) são mais difíceis agora porque este estimador é uma combinação linear
ponderada de variáveis aleatórias \(\chi^2\) assintoticamente independentes.
Uma aproximação que parece funcionar bem é substituir \(L\) por \(\displaystyle \left(\sum_{k=-m}^m h_k^2\right)^{-1}\). Ou seja, defina
\begin{equation*}
L_h \, = \, \left(\sum_{k=-m}^m h_k^2\right)^{-1}
\end{equation*}
e use a seguinte aproximação: se \(\widehat{f}\sim c\chi^2_\nu\), onde \(c\) é uma constante, então
\begin{equation*}
\mbox{E}\big(\widehat{f}\big)\approx c\nu \qquad \mbox{e} \qquad \mbox{Var}\big(\widehat{f} \big)\approx f^2 \sum_k h_k^2 \approx c^2 2\nu\cdot
\end{equation*}
Resolvendo, \(c\approx f \sum_k h_k^2/2=f/2L_h\) e \(\displaystyle \nu=2\big(\sum_k h_k^2\big)^{-1}=2L_h\).
Significa que
\begin{equation*}
\dfrac{2L_h \widehat{f}(\omega)}{f(\omega)} \approx \chi^2_{2L_h}\cdot
\end{equation*}
Em analogia a resultados anteriores, definiremos a largura de banda neste caso como
\begin{equation*}
B \, = \, \dfrac{L_h}{n}\cdot
\end{equation*}
Utilizando a aproximação anterior, obtemos um intervalo de confiança aproximado de \(100(1-\alpha)\)% da forma
\begin{equation*}
\dfrac{2L_h \widehat{f}(\omega)}{\chi^2_{2L_h}(1-\alpha/2)} \leq f(\omega) \leq \dfrac{2L_h \widehat{f}(\omega)}{\chi^2_{2L_h}(\alpha/2)}
\end{equation*}
para o espectro verdadeiro \(f(\omega)\). Se os dados forem preenchidos com \(n'\), então substitua \(2L_h\) acima por \(df = 2L_h n/n'\).
Uma maneira fácil de gerar os pesos em R é pelo uso repetido do kernel Daniell. Por exemplo, com \(m = 1\) e \(L = 2m + 1 = 3\), o kernel
Daniell tem pesos \(\{h_k\}=\big\{ \frac{1}{3},\frac{1}{3},\frac{1}{3}\big\}\); aplicando este kernel a uma sequência de números \(\{u_t\}\), produz
\begin{equation*}
\widehat{u}_t \, = \, \frac{1}{3}u_{t-1}+\frac{1}{3}u_t+\frac{1}{3}u_{t+1}\cdot
\end{equation*}
Podemos aplicar o mesmo kernel novamente ao \(\widehat{u}_t\),
\begin{equation*}
\widehat{\widehat{u}}_t \, = \, \frac{1}{3}\widehat{u}_{t-1}+\frac{1}{3}\widehat{u}_t+\frac{1}{3}\widehat{u}_{t+1},
\end{equation*}
que simplifica para
\begin{equation*}
\widehat{\widehat{u}}_t \, = \, \frac{1}{9}{u}_{t-2}+\frac{2}{9}{u}_{t-1}+\frac{3}{9}{u}_{t}+\frac{2}{9}{u}_{t+1}+\frac{1}{9}{u}_{t+2}\cdot
\end{equation*}
O kernel Daniell modificado coloca meio peso nos pontos finais, então com \(m = 1\) os pesos são \(\{h_k\}=\big\{\frac{1}{4},\frac{2}{4},\frac{1}{4}\big\}\) e
\begin{equation*}
\widehat{u}_t \, = \, \frac{1}{4}u_{t-1}+\frac{2}{4}u_t+\frac{1}{4}u_{t+1}\cdot
\end{equation*}
Aplicando o mesmo kernel novamente para \(\widehat{u}_t\) rende
\begin{equation*}
\widehat{\widehat{u}}_t \, = \, \frac{1}{16}{u}_{t-2}+\frac{4}{16}{u}_{t-1}+\frac{6}{16}{u}_{t}+\frac{4}{16}{u}_{t+1}+\frac{1}{16}{u}_{t+2}\cdot
\end{equation*}
Esses coeficientes podem ser obtidos em R emitindo o comando kernel. Por exemplo,
> kernel("modified.daniell", c(1,1))
produziria os coeficientes do último exemplo. Outros kernels que estão atualmente disponíveis no R são o kernel Dirichlet e o kernel Fejér,
que discutiremos em breve.
É interessante notar que esses pesos do kernel formam uma distribuição de probabilidade. Se \(X\) e \(Y\) são uniformes
discretos independentes nos inteiros \(\{-1,0,1\}\), cada com probabilidade \(\frac{1}{3}\), então a convolução \(X + Y\) é discreta
nos inteiros \(\{-2,-1,0,1,2\}\) com as probabilidades correspondentes \(\{\frac{1}{9},\frac{2}{9},\frac{3}{9},\frac{2}{9},\frac{1}{9}\}\).
Exemplo IV.16. Periodograma suavizado para SOI e Recrutamento.
Neste exemplo, estimamos os espectros das séries SOI e Recrutamento usando a estimativa do periodograma suavizado em \(\widehat{f}(\omega)\). Usamos um kernel Daniell
modificado duas vezes, com \(m = 3\) nas duas vezes. Isso resulta em \(\displaystyle L_h = 1/\sum_{k=-m}^m h_k^2 = 9.232\), que é próximo ao valor de \(L = 9\) usado no
Exemplo IV.14.
Nesse caso, a largura de banda é \(B = 9.232/480 =0.019\) e os graus de liberdade modificados são \(df = 2L_h 453/480 = 17.43\).
Os pesos \(h_k\), podem ser obtidos e representados graficamente em R da seguinte forma:
As estimativas espectrais resultantes podem ser vistas na Figura IV.10 e notamos que as estimativas são mais atraentes do que as da Figura IV.7.
A Figura IV.10 foi gerada em R como segue; também mostramos como obter a largura de banda associada e os graus de liberdade.
Figura IV.10: Estimativas espectrais suavizadas (afiladas) das séries SOI e Recrutamento; consulte o
Exemplo IV.16 para obter detalhes.
Observe que uma redução gradual foi aplicada no processo de estima¸ão; discutiremos a redução gradual na próxima parte.
A reemissão dos comandos mvspec com log="no" removido resultará em uma figura semelhante à Figura IV.8.
Finalmente, mencionamos que o kernel de Daniell modificado é usado por padrão e uma maneira mais fácil de obter soi.smo é
emitir o comando:
Observe que spans é um vetor de inteiros ímpares, dados em termos de \(L = 2m + 1\) em vez de \(m\).
Tem havido muitas tentativas de lidar com o problema de alisar o periodograma de maneira automática; uma referência anterior é Wahba (1980). Fica evidente a partir do
Exemplo IV.16 que a largura de banda de suavização para o comportamento do El Niño de banda larga (perto do ciclo de 4 anos), deve ser muito maior do que a largura
de banda para o ciclo anual (o ciclo de 1 ano). Consequentemente, talvez seja melhor realizar a suavização adaptativa automática para estimar o espectro. Referimos os
leitores interessados a Fan and Kreutzberger (1998) e as inúmeras referências contidas nele.
Redução gradual (Tapering)
Agora estamos prontos para introduzir o conceito de redução gradual (tapering); uma discussão mais detalhada pode ser encontrada em Bloomfield (2000). Suponha que \(X_t\) seja
um processo estacionário de méia zero com densidade espectral \(f_{_X}(\omega)\). Se substituírmos a série original pela série reduzida
\begin{equation*}
Y_t \, = \, h_t X_t,
\end{equation*}
para \(t=1,2,\cdots,n\), usando a Transformada Discreta de Fourier (DFT) modificada
\begin{equation*}
d_{_Y}(\omega_j) \, = \, \dfrac{1}{n}\sum_{t=1}^n h_t X_t e^{-2\pi \, i \omega_j t}
\end{equation*}
e fazendo \(I_{_Y}(\omega_j=|d_{_Y}(\omega_j)|^2\), obtemos que
\begin{equation*}
\mbox{E}(I_{_Y}(\omega_j)) \, = \, \int_{-\frac{1}{2}}^\frac{1}{2} W_n(\omega_j-\omega)f_{_X}(\omega)\mbox{d}\omega,
\end{equation*}
onde
\begin{equation*}
W_n(\omega) \, = \, |H_n(\omega)|^2
\end{equation*}
e
\begin{equation*}
H_n(\omega) \, = \, \frac{1}{\sqrt{n}}\sum_{t=1}^n h_t e^{-2\pi \, i \omega t}\cdot
\end{equation*}
O valor \(W_n(\omega)\) é denominado janela espectral porque ele determina qual parte da densidade espectral \(f_{_X}(\omega)\) está sendo vista pelo estimador
\(I_{_Y}(\omega_j)\) em média. No caso em que \(h_t = 1\) para todo \(t\), \(I_{_Y}(\omega_j) = I_{_X}(\omega_j)\) é simplesmente o periodograma dos dados e
a janela é
\begin{equation*}
W_n(\omega) \, = \, \dfrac{\sin^2(n\pi\omega)}{n\sin^2(\pi\omega)},
\end{equation*}
com \(W_n(0)=n\), que é conhecido como kernel de Fejér ou kernel Bartlett modificado.
Se considerarmos o periodograma médio
\begin{equation*}
\overline{f}_{_X}(\omega) \, = \, \dfrac{1}{L}\sum_{k=-m}^m I_{_X}(\omega_j+k/n),
\end{equation*}
a janela \(W_n(\omega)\), em \(\mbox{E}(I_{_Y}(\omega))\), assumirá a forma
\begin{equation*}
W_n(\omega) \, = \, \frac{1}{nL}\sum_{k=-m}^m \dfrac{\sin^2\big(n\pi(\omega+k/n) \big)}{\sin^2\big( \pi(\omega+k/n)\big)}\cdot
\end{equation*}
Os cones geralmente têm uma forma que realça o centro dos dados em relação às extremidades, como um sino cosseno da forma
\begin{equation*}
h_t \, = \, 0.5\left( 1+\cos\left( \frac{2\pi(t-\overline{t})}{n}\right)\right),
\end{equation*}
onde \(\overline{t} = (n + 1)/2\), preferido por Blackman and Tukey (1959). A forma desse cone é mostrada na inserção da Figura IV.12.
Na Figura IV.11, traçamos as formas de duas janelas \(W_n(\omega)\), para \(n = 480\) e \(L = 9\), quando
(i) \(h_t= 1\), caso em que \(W_n(\omega) = \displaystyle \frac{1}{nL}\sum_{k=-m}^m \dfrac{\sin^2\big(n\pi(\omega+k/n) \big)}{\sin^2\big( \pi(\omega+k/n)\big)}\) se aplica, e
(ii) \(h_t\) é o afilamento do cosseno em \(h_t = \displaystyle 0.5\left( 1+\cos\left( \frac{2\pi(t-\overline{t})}{n}\right)\right)\).
Em ambos os casos, a largura de banda prevista deve ser \(B = 9/480 = 0.01875\) ciclos por ponto, o que corresponde à “largura” das janelas mostradas na Figura IV.11.
Ambas as janelas produzem um espectro médio integrado sobre esta banda, mas a janela afunilada nos painéis superiores mostra ondulações consideráveis
sobre a banda e fora da banda.
As ondulações fora da banda são chamadas de lóbulos laterais e tendem a introduzir frequências de fora do intervalo que podem contaminar a estimativa
espectral desejada dentro da banda. Por exemplo, uma grande faixa dinâmica para os valores no espectro introduz espectros em intervalos de frequência contíguos várias ordens de
magnitude maiores do que o valor no intervalo de interesse. Esse efeito às vezes é chamado de vazamento. A Figura IV.11 enfatiza a supressão dos lóbulos laterais no kernel de
Fejér quando uma conicidade cosseno é usada.
Figura IV.11: Janela Fejér média (linha superior) e a janela cosseno cônica correspondente (linha inferior) para \(L = 9\); \(n = 480\). As
marcas de tiques extras no eixo horizontal dos gráficos à esquerda exibem a largura de banda prevista, \(B = 9/480 = 0.01875\).
Exemplo IV.17. O efeito da redução gradual da série SOI.
As estimativas no Exemplo IV.16 foram obtidas diminuindo os 10% superior e inferior dos dados. Neste exemplo, examinamos o efeito do tapering na estimativa do espectro da
série SOI, os resultados para a série de Recrutamento são semelhantes. A Figura IV.12 mostra duas estimativas espectrais mostradas em uma escala logarítmica. A linha tracejada
na Figura IV.12 mostra a estimativa sem qualquer redução. A linha sólida mostra o resultado com afilamento total. Observe que o espectro cônico faz um trabalho melhor em separar
o ciclo anual \(\omega = 1\) e o ciclo El Niño \(\omega = 1/4\).
A seguinte sessão R foi usada para gerar a Figura IV.12. Observamos que, por padrão, o mvspec não faz a redução gradual. Para a
gerarmos a redução gradual completa, usamos o argumento taper = 0.5 na instrução mvspec para diminuir 50% de cada
extremidade dos dados; qualquer valor entre 0 e 0.5 é aceitável.
Figura IV.12: Estimativas espectrais suavizadas do SOI sem afilamento (linha tracejada) e com afilamento total (linha contínua); veja o Exemplo IV.17.
A inserção mostra uma conicidade completa em sino, com eixo horizontal \((t-\overline{t})/n\), para \(t = 1,\cdots,n\).
Encerramos esta seção com uma breve discussão sobre os estimadores da janela de latência. Primeiro, considere o periodograma \(I(\omega_j)\), que foi
mostrado acima como sendo
\begin{equation*}
I(\omega_j) \, = \, \sum_{|h|< n} \widehat{\gamma}(h)e^{-2\pi \, i\omega_j h}\cdot
\end{equation*}
A equação acima sugere estimadores da forma
\begin{equation*}
\widetilde{f}(\omega) \, = \, \sum_{|h|\leq r} w(h/r)\widehat{\gamma}(h) e^{-2\pi \, i \omega h}
\end{equation*}
onde \(w(\cdot)\) é uma função de peso, chamada janela de latência, que satisfaz
(i) \(w(0)=1\).
(b) \(|w(x)|\leq 1\) e \(w(x)=0\) para \(|x|>1\).
(iii) \(w(x)=w(-x)\).
Observe que se \(w(x) = 1\) para \(|x|< 1\) e \(r = n\), então \(\widetilde{f}(\omega_j) = I(\omega_j)\), o periodograma. Este resultado indica que o problema
com o periodograma como um estimador da densidade espectral é que ele dá muito peso aos valores de \(\widehat{\gamma}(h)\) quando \(h\) é grande e, portanto,
não é confiável, por exemplo, há apenas um par de observações usados para estimar \(\widehat{\gamma}(n-1)\), e assim por diante. A
janela de suavização é definida sendo
\begin{equation*}
W(\omega) \, = \, \sum_{h=-r}^r w(h/r)e^{-2\pi \, i\omega h},
\end{equation*}
e determina qual parte do periodograma será usado para formar a estimativa de \(f(\omega)\).
A teoria assintótica para \(\widehat{f}(\omega)\) é válida para \(\widetilde{f}(\omega)\) nas mesmas condições e desde que \(r\to\infty\) quando
\(n\to\infty\) mas com \(r/n\to 0\). Ou seja,
\begin{equation*}
\mbox{E}\big( \widetilde{f}(\omega)\big) \, \to \, f(\omega),
\end{equation*}
e
\begin{equation*}
\frac{n}{r}\mbox{Cov}\big(\widetilde{f}(\omega),\widetilde{f}(\lambda) \big) \to f^2(\omega)\int_{-1}^1 w^2(x)\mbox{d}x, \qquad \omega=\lambda\neq 0,1/2\cdot
\end{equation*}
Acima substitua \(f^2(\omega)\) por \(0\) se \(\omega\neq \lambda\) e por \(2f^2(\omega)\) se \(\omega=\lambda=0\) ou \(1/2\).
Muitos autores desenvolveram várias janelas e Brillinger (2001) e Brockwell and Davis (1991) são boas fontes de informações detalhadas sobre este tópico.
IV.5 Estimação espectral paramétrica
Os métodos da seção anterior levam ao que é geralmente referido como estimadores espectrais não paramétricos
porque nenhuma suposição é feita sobre os parâmetros de forma da densidade espectral. No Teorema IV.4,
exibimos o espectro de um processo \(ARMA\) e podemos considerar basear um estimador espectral nesta função, substituindo as estimativas
dos parâmetros de um \(ARMA(p,q)\) ajustado nos dados na fórmula para a densidade espectral \(f_{_X}(\omega)\) dada no Teorema IV.4.
Esse estimador é chamado de estimador paramétrico espectral. Por conveniência, um estimador espectral paramétrico é
obtido ajustando um modelo \(AR(p)\) aos dados, onde a ordem \(p\) é determinada por um dos critérios de seleção, como \(AIC\),
\(AICc\) e \(BIC\), definidos anteriormente. Estimadores espectrais paramétricos autoregressivos muitas vezes têm resolução
superior em problemas quando vários picos espectrais estreitos e próximos estão presentes e são preferidos por engenheiros
para uma ampla variedade de problemas (ver Kay, 1988). O desenvolvimento de estimadores espectrais autorregressivos foram resumidos por Parzen (1983).
Sejam \(\widehat{\phi}_1,\widehat{\phi}_2,\cdots,\widehat{\phi}_p\) e \(\widehat{\sigma}_{_W}^2\) os estimadores do modelo \(AR(p)\) ajustado à \(X_t\),
então segundo o Teorema IV.4, uma estimativa espectral paramétrica de \(f_{_X}(\omega)\) é obtida substituindo essas
estimativas na expressão do teorema mencionado, ou seja,
\begin{equation*}
\widehat{f}_{_X}(\omega) \, = \, \dfrac{\widehat{\sigma}_{_W}^2}{\big|\widehat{\phi}(e^{-2\pi i\omega})\big|^2},
\end{equation*}
onde
\begin{equation*}
\widehat{\phi}(z) \, = \, 1-\widehat{\phi}_1 z-\widehat{\phi}_2 z^2-\cdots - \widehat{\phi}_p z^p\cdot
\end{equation*}
A distribuição assintótica do estimador espectral autoregressivo foi obtida por Berk (1974) nas condições \(p\to \infty\),
\(p^3/n \to 0\) quando \(p,n \to\infty\), que pode ser muito grave para a maioria das aplica¸ões. Os resultados limites implicam em um
intervalo de confiança da forma
\begin{equation*}
\dfrac{\widehat{f}_{_X}(\omega)}{\big(1+Cz_{\alpha/2}\big)} \, \leq \, f_{_X}(\omega) \, \leq \, \dfrac{\widehat{f}_{_X}(\omega)}{\big(1-Cz_{\alpha/2}\big)},
\end{equation*}
onde \(C \, = \, \sqrt{2p/n}\) e \(z_{\alpha/2}\) é o quantil \(\alpha/2\) superior da distribuição normal padrão.
Se a distribuição amostral deve ser verificada, sugerimos a aplicação do estimador bootstrap para obter a distribuição
amostral de \(\widehat{f}_{_X}(\omega)\) usando um procedimento semelhante ao usado para \(p = 1\) no Exemplo III.36. Uma alternativa para séries autoregressivas
de ordem superior é colocar o modelo \(AR(p)\) na forma de espaço de estado e usar o procedimento de bootstrap discutido na Seção VI.7.
Um fato interessante sobre os espectros racionais da forma descritos no Teorema IV.4 é que qualquer densidade espectral pode ser aproximada,
arbitrariamente próxima, pelo espectro de um processo \(AR\).
Teorema IV.7. Aproximação espectral de um processo \(AR\).
Seja \(g(\omega)\) a densidade espectral de um processo estacionário. Então, dado \(\epsilon > 0\), há uma série temporal com a
representação
\begin{equation}
X_t \, = \, \sum_{k=1}^p \phi_k X_{t-k} \, + \, W_t,
\end{equation}
onde \(W_t\) é um ruído branco com variância \(\sigma_{_W}^2\), tal que,
\begin{equation}
\big| f_{_X}(\omega)-g(\omega)\big| < \epsilon \qquad \forall \; \omega\in [-1/2, 1/2]\cdot
\end{equation}
Além disso, \(p\) é finito e as raízes de \(\displaystyle \phi(z) \, = \, \sum_{k=1}^p \phi_k z^k\) estão fora do círculo unitário.
Demonstração
Se \(g(\omega)=0\), então \(p=0\) e \(\sigma_{_W}=0\). Quando \(g(\omega)>0\) sobre alguns \(\omega\in \big(-\frac{1}{2},\frac{1}{2}\big)\), seja
\(\epsilon>0\) e definamos
\begin{equation}
d(\omega) \, = \, \left\{ \begin{array}{ccl} g^{-1}(\omega) & \mbox{ caso } & g(\omega)>\epsilon/2, \\
2/\epsilon & \mbox{ caso } & g(\omega)\leq \epsilon/2, \end{array}\right.
\end{equation}
de modo que \(d^{-1}(\omega)=\max\{g(\omega),\epsilon/2 \}\). Definamos \(G=\max_\omega \{g(\omega)\}\) e seja \(0<\delta <\epsilon \big(G(2G+\epsilon)\big)^{-1}\).
Definamos a soma \(\displaystyle S_n\big(d(\omega) \big) =\sum_{|j|\leq n} <d,e_j> e_j(\omega)\) onde \(e_j(\omega)=e^{2\pi \, i \, j\omega}\) e
\(\displaystyle <d,e_j>=\int_{-\frac{1}{2}}^\frac{1}{2} d(\omega)e^{-2\pi \, i \, j\omega}\mbox{d}\omega\). Agora definimos a soma Cesaro
\begin{equation}
C_m(\omega) \, = \, \frac{1}{m}\sum_{n=0}^{m-1} S_n\big(d(\omega) \big),
\end{equation}
que é uma média cumulativa de \(S_n(\cdot)\). Nesse caso \(\displaystyle C_m(\omega)=\sum_{|j|\leq m} c_j e^{-2\pi \, i \, j\omega}\) onde
\(c_j=\big( 1-\frac{|j|}{m}\big)<d,e_j>\). A soma Cesaro converge uniformemente em \(\big( -\frac{1}{2},\frac{1}{2}\big)\) para \(d\in L^2\),
consequentemente, existe um \(p\) finito tal que
\begin{equation}
\left|\sum_{|j|\leq p} c_j e^{-2\pi \, i \, j\omega}-d(\omega) \right| < \delta \qquad \mbox{ para todo } \qquad \omega\in \Big( -\frac{1}{2},\frac{1}{2}\Big)\cdot
\end{equation}
Observe que \(C_p(\omega)\) é uma densidade espectral. Na verdade, é a densidade espectral de um processo \(MA(p)\) com \(\gamma(h) = c_h\)
para \(|h|\leq p\) e \(\gamma(h) = 0\) para \(|h|> p\); pode-se verificar que \(\gamma(h)\) definido desta forma é definido não negativo. Portanto,
é um processo \(MA(p)\) invertível, digamos
\begin{equation}
Y_t \, = \, U_t+\alpha_1 U_{t-1}+\cdots +\alpha_p U_{t-p},
\end{equation}
onde \(U_t\sim N_n(0,\sigma_{_U}^2)\) e \(\alpha(z)\) tem raízes fora do círculo unitário. Por isso,
\begin{equation}
C_p(\omega) \, = \, \sum_{|j|\leq p} c_j e^{-2\pi \, i \, j\omega} \, = \, \sigma_{_U}^2|\alpha(e^{-2\pi \, i \, \omega})|^2
\end{equation}
e
\begin{equation}
\left| \sigma_{_U}^2|\alpha(e^{-2\pi \, i \, \omega})|^2-d(\omega)\right| \, < \, \delta \, < \epsilon \big(G(2G+\epsilon)\big)^{-1} \, = \, \epsilon^*\cdot
\end{equation}
Definamos agora \(f_{_X}(\omega) =\big( \sigma_{_U}^2|\alpha(e^{-2\pi \, i \, \omega})|^2\big)^{-1}\). Mostraremos que \(|f_{_X}(\omega)-g(\omega)|<\epsilon\), caso
em que o resultado segue com \(\alpha_1,\cdots,\alpha_p\) sendo estes os coeficientes \(AR(p)\) exigidos e \(\sigma_{_W}^2 = \sigma_{_U}^{-2}\) sendo a
variância do ruído. Considere que
\begin{equation}
|f_{_X}(\omega)-g(\omega)| \, \leq \, |f_{_X}(\omega)-d^{-1}(\omega)|+|d^{-1}(\omega)-g(\omega)| \, < \, |f_{_X}(\omega)-d^{-1}(\omega)|+\epsilon/2\cdot
\end{equation}
Também
\begin{array}{rdl}
|f_{_X}(\omega)-d^{-1}(\omega)| & = & \left| \sigma_{_W}^2|\alpha(e^{-2\pi \, i \, \omega})|^{-2}-d^{-1}(\omega)\right| \\
& = & \left| \sigma_{_W}^{-2}|\alpha(e^{-2\pi \, i \, \omega})|^2-d(\omega)\right|\times \left| \sigma_{_W}^2|\alpha(e^{-2\pi \, i \, \omega})|^{-2}-d^{-1}(\omega)\right|\\
& < & \delta \sigma_{_W}^2|\alpha(e^{-2\pi \, i \, \omega})|^{-2}G\cdot
\end{array}
Mas
\begin{equation}
\epsilon^*-d(\omega) \, < \, \sigma_{_W}^{-2}|\alpha(e^{-2\pi \, i \, \omega})|^2 \, < \, \epsilon^*+d(\omega),
\end{equation}
de maneira que
\begin{equation*}
\sigma_{_W}^{2}|\alpha(e^{-2\pi \, i \, \omega})|^{-2} \, < \, \dfrac{1}{\epsilon^*-d(\omega)} \, < \, \dfrac{1}{\epsilon^*-G^{-1}} \, = \,
\dfrac{1}{\epsilon \big(G(2G+\epsilon)\big)^{-1}-G^{-1}} \, = \, G+\epsilon/2\cdot
\end{equation*}
Agora temos que
\begin{equation}
|f_{_X}(\omega)-d^{-1}(\omega)| \, < \, \epsilon \big(G(2G+\epsilon)\big)^{-1} G+\epsilon/2 G \, = \, \epsilon/2\cdot
\end{equation}
Finalmente,
\begin{equation}
|f_{_X}(\omega)-g(\omega)| \, < \, \epsilon/2+\epsilon/2 \, = \, \epsilon,
\end{equation}
como era para ser mostrado ▉
Uma desvantagem desta propriedade é que ela não nos diz quão grande \(p\) deve ser antes que a aproximação seja razoável;
em algumas situações, \(p\) pode ser extremamente grande. Este teorema permance válido para processos \(MA\) e \(ARMA\). Mostramos a
técnica no exemplo a seguir.
Exemplo IV.18. Estimador espectral autoregressivo para SOI.
Considere a obtenção de resultados comparáveis aos estimadores não paramétricos mostrados na Figura IV.7 para a série SOI.
Ajustando modelos \(AR(p)\) de ordem sucessivamente mais alta para \(p = 1, 2, \cdots,30\) resulta em um \(BIC\) mínimo e um \(AIC\) mínimo em
\(p = 15\), conforme mostrado na Figura IV.13.
Podemos ver na Figura IV.13 que o BIC é muito preciso sobre o modelo que escolhe; ou seja, o BIC mínimo é muito distinto. Por outro lado,
não está claro o que vai acontecer com a AIC; ou seja, o mínimo não é tão claro e há alguma preocupação
de que o AIC comece a diminuir após \(p = 30\). O AICc mínimo seleciona o modelo \(p = 15\), mas sofre da mesma incerteza que o AIC.
Figura IV.13: Critérios de seleção de modelos AIC e BIC em função da ordem \(p\) para
modelos autorregressivos ajustados à série SOI.
No R, o comando spec.ar pode ser usado para ajustar o melhor modelo via \(AIC\) e mostrar o espectro resultante. Uma maneira
rápida de obter os valores \(AIC\) é executar o comando ar da seguinte maneira:
O espectro é mostrado na Figura IV.14, e notamos os fortes picos próximos aos ciclos de quatro e um ano, como nas estimativas não paramétricas obtidas
na Seção IV.4. Além disso, as harmônicas do período anual são evidentes no espectro estimado.
Figura IV.14: Estimador espectral autoregressivo para a série SOI usando o modelo \(AR(15)\) selecionado
por AIC, AICc e BIC.
Finalmente, deve ser mencionado que qualquer espectro paramétrico \(f(\omega;\theta)\), dependendo do vetor de parâmetros pode ser estimado através
da verossimilhaça de Whittle (Whittle, 1961), usando as propriedades aproximadas da transformada discreta de Fourier derivadas no Apêndice C.
Temos que as transformadas discretas de Fourier \(d(\omega_j)\), são aproximadamente complexas normalmente distribuídas com média zero e variância
\(f(\omega_j;\theta)\) e são aproximadamente independentes para \(\omega_j\neq \omega_k\). Isso implica que a log-verossimilhança aproximada pode
ser escrita na forma
\begin{equation}
\ln\big( L(x;\theta)\big) \, \approx \, -\sum_{0<\omega_j<1/2} \left( \ln\big(f_{_X}(\omega_j;\theta) \big)+\dfrac{|d(\omega_j)|^2}{f_{_X}(\omega_j;\theta)}\right),
\end{equation}
onde a soma às vezes é expandida para incluir as frequências \(\omega_j = 0,1/2\). Se a forma com as duas frequências adicionais for usada, o
multiplicador da soma será a unidade, exceto para os pontos puramente reais em \(\omega_j = 0,1/2\) para o qual o multiplicador é 1/2.
Para uma discussão sobre a aplicação da aproximação de Whittle ao problema de estimar parâmetros em um espectro ARMA, consulte
Anderson (1978). A verossimilhança de Whittle é especialmente útil para ajustar modelos de memória longa que serão discutidos no Capíítulo V.
IV.6 Múltiplas séries e cross-espectra
A noção de analisar flutuações de frequência usando idéias estatísticas clássicas se estende ao caso
em que existem várias séries estacionárias conjuntamente, por exemplo, \(X_t\) e \(Y_t\).
Nesse caso, podemos introduzir a ideia de uma correlação indexada por frequência, chamada de coerência. Os resultados na
Seção C.2 implicam que a função de covariância
\begin{equation*}
\gamma_{_{XY}}(h) \, = \, \mbox{E}\big( (X_{t+h}-\mu_{_X})(Y_t-\mu_{_Y})\big)
\end{equation*}
tem a representação
\begin{equation*}
\gamma_{_{XY}}(h) \, = \, \int_{-\frac{1}{2}}^\frac{1}{2} f_{_{XY}}(\omega)e^{2\pi \, i \, \omega h}\mbox{d}\omega \qquad h=0,\pm 1,\pm 2, \cdots,
\end{equation*}
onde o espectro cruzado é definido como a transformada de Fourier
\begin{equation*}
f_{_{XY}}(\omega) \, = \, \sum_{h=-\infty}^\infty \gamma_{_{XY}}(h)e^{-2\pi \, i \, \omega h}, \qquad -1/2\leq \omega\leq 1/2,
\end{equation*}
assumindo que a função de covariância cruzada é absolutamente somatável, como foi o caso da autocovariância.
O espectro cruzado é geralmente uma função de valor complexo e muitas vezes é escrito como
\begin{equation*}
f_{_{XY}}(\omega) \, = \, c_{_{XY}}(\omega)-iq_{_{XY}}(\omega),
\end{equation*}
onde
\begin{equation*}
c_{_{XY}}(\omega) \, = \, \sum_{h=-\infty}^\infty \gamma_{_{XY}}(h)\cos\big( 2\pi\omega h\big)
\end{equation*}
e
\begin{equation*}
q_{_{XY}}(\omega) \, = \, \sum_{h=-\infty}^\infty \gamma_{_{XY}}(h)\sin\big(2\pi\omega h \big)
\end{equation*}
são chamados como o cospectro e o quadspectrum, respectivamente.
Por causa da relação \(\gamma_{_{YX}}(h) = \gamma_{_{XY}}(-h)\), segue-se, substituindo em
\begin{equation*}
f_{_{XY}}(\omega) \, = \, \sum_{h=-\infty}^\infty \gamma_{_{XY}}(h)e^{-2\pi \, i \, \omega h}, \qquad -1/2\leq \omega\leq 1/2,
\end{equation*}
e reorganizando, que
\begin{equation*}
f_{_{YX}}(\omega) \, = \, f_{_{XY}}^*(\omega),
\end{equation*}
com \(*\) denotando conjugação. Este resultado, por sua vez, implica que o cospectro e o quadspectrum satisfazem
\begin{equation*}
c_{_{YX}}(\omega) \, = \, c_{_{XY}}(\omega)
\end{equation*}
e
\begin{equation*}
q_{_{YX}}(\omega) \, = \, -q_{_{XY}}(\omega)\cdot
\end{equation*}
Um exemplo importante da aplicação do espectro cruzado é o problema de prever uma série de saída \(Y_t\) de alguma série
de entrada \(X_t\) por meio de uma relação de filtro linear, como a média móvel de três pontos considerada abaixo.
Uma medida da força de tal relação é a função de coerência ao quadrado, definida como
\begin{equation*}
\rho^2_{_{YX}}(\omega) \, = \, \dfrac{|f_{_{YX}}(\omega)|^2}{f_{_{XX}}(\omega)f_{_{YY}}(\omega)},
\end{equation*}
onde \(f_{_{XX}}(\omega)\) e \(f_{_{YY}}(\omega)\) são os espectros individuais das séries \(X_t\) e \(Y_t\), respectivamente.
Embora consideremos uma forma mais geral disso que se aplica a várias entradas posteriormente, é instrutivo exibir o caso de entrada única
para enfatizar a analogia com a correlação quadrática convencional, que assume a forma
\begin{equation*}
\rho^2_{_{YX}} \, = \, \dfrac{\sigma_{_{YX}}^2}{\sigma_{_{XX}}^2\sigma_{_{YY}}^2},
\end{equation*}
para variáveis aleatórias com variâncias \(\sigma_{_X}^2\) e \(\sigma_{_{Y}}^2\) e covariância \(\sigma_{_{YX}} = \sigma_{_{XY}}\).
Isso motiva a interpretação da coerência quadrada e a correlação quadrada entre duas séries temporais na frequência \(\omega\).
Exemplo IV.19. Média móvel de três pontos.
Como um exemplo simples, calculamos o espectro cruzado entre \(X_t\) e a média móvel de três pontos \(Y_t=\frac{1}{3}(X_{t-1}+X_t+X_{t+1})\), onde \(X_t\)
é um processo de entrada estacionário com densidade espectral \(f_{_{XX}}(\omega)\). Primeiro,
\begin{array}{rcl}
\gamma_{_{XY}}(h) \, = \, \mbox{Cov}\big( X_{t+h},Y_t\big) & = & \displaystyle \frac{1}{3}\mbox{Cov}\big(X_{t+h} \, , \, X_{t-1}+X_t+X_{t+1} \big) \\
& = & \displaystyle \frac{1}{3}\Big( \gamma_{_{XY}}(h+1)+\gamma_{_{XY}}(h)+\gamma_{_{XY}}(h+1) \Big) \\
& = & \displaystyle \frac{1}{3}\int_{-\frac{1}{2}}^\frac{1}{2} \left( e^{2\pi \, i \, \omega}+1+e^{-2\pi \, i \, \omega}\right)e^{2\pi \, i \, \omega h} f_{_{XX}}(\omega)\mbox{d}\omega \\
& = & \displaystyle \frac{1}{3}\int_{-\frac{1}{2}}^\frac{1}{2} \left( 1+2\cos(2\pi\omega)\right)f_{_{XX}}(\omega) e^{2\pi \, i \, \omega h} \mbox{d}\omega,
\end{array}
onde usamos a representação do Teorema IV.2. Usando a singularidade da transformada de Fourier, argumentamos a partir da representação espectral que
\begin{equation*}
f_{_{XY}}(\omega) \, = \, \frac{1}{3}\left( 1+2\cos(2\pi\omega)\right)f_{_{XX}}(\omega),
\end{equation*}
de modo que o espectro cruzado é real neste caso. Usando o Teorema IV.3, a densidade espectral de \(Y_t\) é
\begin{equation*}
f_{_{YY}}(\omega) \, = \, \frac{1}{9}\left| e^{2\pi \, i \, \omega}+1+e^{-2\pi \, i \, \omega}\right|^2 f_{_{XX}}(\omega) \, = \, \frac{1}{9}\left|1+2\cos\big( 2\pi\omega\big) \right|^2 f_{_{XX}}(\omega)\cdot
\end{equation*}
Substituindo adequadamente temos,
\begin{equation*}
\rho^2_{_{YX}} \, = \, \dfrac{\left|\frac{1}{3}\Big(1+2\cos\big( 2\pi\omega\big)\Big) f_{_{XX}}(\omega) \right|^2 }{f_{_{XX}}(\omega)\frac{1}{9}\Big(1+2\cos\big( 2\pi\omega\big)\Big)^2 f_{_{XX}}(\omega)} \, = \, 1;
\end{equation*}
isto é, a coerência quadrada entre \(X_t\) e \(Y_t\) é a unidade em todas as frequências.
Esta é uma característica herdada por filtros lineares mais gerais. No entanto, se algum ruído for adicionado à média móvel de três pontos, a coerência não
será unidade; esses tipos de modelos serão considerados em detalhes posteriormente.
Teorema IV.8. Representação espectral de um processo estacionário vetorial
Seja \(X_t=(X_{t1},X_{t2},\cdots,X_{tp})^\top\) um processo \(p\times 1\) estacionário com matriz de autocovariâncias
\begin{equation*}
\Gamma(h) \, = \, \mbox{E}\big((X_{t+h}-\mu)(X_t-\mu)^\top \big) \, = \, \{\gamma_{_{jk}}(h)\},
\end{equation*}
satisfazendo
\begin{equation*}
\sum_{k=-\infty}^\infty |\gamma_{_{jk}}(h)|<\infty,
\end{equation*}
para todos \(j,k=1,\cdots,p\). Então, \(\Gamma(h)\) tem a representação
\begin{equation*}
\Gamma(h) \, = \, \int_{-\frac{1}{2}}^\frac{1}{2} e^{2\pi \, i \, \omega h} f(\omega)\mbox{d}\omega, \qquad h=0,\pm 1,\pm 2, \cdots,
\end{equation*}
como a transformação inversa da matriz de densidade espectral
\begin{equation*}
f(\omega) \, = \, \{f_{_{jk}}(\omega)\},
\end{equation*}
para \(j,k=1,\cdots,p\). A matrix \(f(\omega)\) tem a representação
\begin{equation*}
f(\omega) \, = \, \sum_{h=-\infty}^\infty \Gamma(h) e^{-2\pi \, i \, \omega h}, \qquad -1/2\leq \omega \leq 1/2\cdot
\end{equation*}
A matriz espectral \(f(\omega)\) é Hermitiana, \(f(\omega) = f^*(\omega)\), onde \(*\) significa transposto conjugado.
Demonstração.
Ver Seção C. ▉
Exemplo IV.20. Matriz espectral de um processo bivariado.
Considere um processo bivariado conjuntamente estacionário \((X_t,Y_t)\). Organizamos as autocovariâncias na matriz
\begin{equation*}
\Gamma(h) \, = \, \begin{pmatrix} \gamma_{_{XX}}(h) & \gamma_{_{XY}}(h) \\ \gamma_{_{YX}}(h) & \gamma_{_{YY}}(h) \end{pmatrix}\cdot
\end{equation*}
A matriz espectral seria dada por
\begin{equation*}
f(\omega) \, = \, \begin{pmatrix} f_{_{XX}}(h) & f_{_{XY}}(h) \\ f_{_{YX}}(h) & f_{_{YY}}(h) \end{pmatrix},
\end{equation*}
onde as transformadas de Fourier no Teorema IV.8 relacionam a autocovariância e as matrizes espectrais.
A extensão da estimativa espectral para séries de vetores é bastante clara. Para a série vetorial \(X_t=(X_{t1},X_{t2},\cdots,X_{tp})^\top\)
podemos usar o vetor de DFTs \(d(\omega_j)=(d_1(\omega_j),d_2(\omega_j),\cdots,d_p(\omega_j))^\top\) e estimar a matriz espectral por
\begin{equation*}
\overline{f}(\omega) \, = \, \dfrac{1}{L}\sum_{k=-\infty}^\infty I(\omega_j+k/n),
\end{equation*}
onde agora
\begin{equation*}
I(\omega_j) \, = \, d(\omega_j)d^*(\omega_j)
\end{equation*}
é uma matriz complexa \(p\times p\).
A série pode ser reduzida antes que o DFT \(\overline{f}(\omega)\) e podemos usar a estimativa ponderada,
\begin{equation*}
\widehat{f}(\omega) \, = \, \sum_{k=-\infty}^\infty h_k I(\omega_j+k/n),
\end{equation*}
onde \(\{h_k\}\) são pesos conforme definido pela função de coerência quadrada. A estimativa da coerência quadrada
entre duas séies, \(Y_t\) e \(X_t\) é
\begin{equation*}
\widehat{\rho}^2_{_{YX}}(\omega) \, = \, \dfrac{|\widehat{f}_{_{YX}}(\omega)|^2}{\widehat{f}_{_{XX}}(\omega)\widehat{f}_{_{YY}}(\omega)}\cdot
\end{equation*}
Se as estimativas espectrais acima forem obtidas usando pesos iguais, escreveremos \(\overline{\rho}_{_{YX}}(\omega)\) para a estimativa.
Sob condições gerais, se \({\rho}^2_{_{YX}}(\omega)>0\) então
\begin{equation*}
|\widehat{\rho}_{_{YX}}(\omega)| \, \sim \, N\Big(|{\rho}_{_{YX}}(\omega)| \, , \, \big(1-{\rho}^2_{_{YX}}(\omega) \big)^2/2L_h \Big),
\end{equation*}
onde \(L_h = \big(\sum_{k=-m}^m h_k^2 \big)^{-1}\); os detalhes desse resultado podem ser encontrados em Brockwell and Davis (1991). Podemos usar o resultado
acima para obter intervalos de confiança aproximados para a coerência quadrada \({\rho}^2_{_{YX}}(\omega)\).
Também podemos testar a haip&ocute;tese nula de que \({\rho}^2_{_{YX}}(\omega)=0\) se usarmos \(\overline{\rho}^2_{_{YX}}(\omega)\) para a estimativa
com \(L> 1\), caso \(L=1\) então \(\overline{\rho}^2_{_{YX}}(\omega)=1\); ou seja,
\begin{equation*}
\overline{\rho}^2_{_{YX}}(\omega) \, = \, \dfrac{|\overline{f}_{_{YX}}(\omega)|^2}{\overline{f}_{_{XX}}(\omega)\overline{f}_{_{YY}}(\omega)}\cdot
\end{equation*}
Neste caso, sob a hipótese nula, a estatística
\begin{equation*}
F \, = \, \dfrac{\overline{\rho}^2_{_{YX}}(\omega)}{1-\overline{\rho}^2_{_{YX}}(\omega)}(L-1)
\end{equation*}
tem distribuição \(F\) aproximada com \(2\) e \(2L-2\) graus de liberdade.
Quando a série foi estendida ao comprimento \(n'\), substituímos \(2L-2\) por \(df-2\), onde \(df=2Ln/n'\). Resolver \(F\) acima para um determinado
nível de significância leva a
\begin{equation*}
C_\alpha \, = \, \dfrac{F_{2,2L-2}(\alpha)}{L-1+F_{2,2L-2}(\alpha)},
\end{equation*}
como o valor aproximado que deve ser excedido para que a coerência quadrada original seja capaz de rejeitar \({\rho}^2_{_{YX}}(\omega)=0\) em uma
frequência especificada a priori.
Exemplo IV.21. Coerência entre SOI e Recrutamento.
Figura IV.15: Coerência quadrática entre as séries SOI e Recrutamento; \(L = 19\), \(n = 453\);
\(n' = 480\) e \(\alpha=0.001\). A linha horizontal é \(C_{0.001}\).
A Figura IV.15 mostra a coerência quadrática entre as séries SOI e Recrutamento em uma banda mais ampla do que a usada para o espectro.
Nesse caso, ao nível de significância \(\alpha=0.001\), usamos \(L = 19\), \(df = 2(19)(453/480)\approx 36\) e \(F_{2,df-2}(0.001)\approx 8.53\).
Portanto, podemos rejeitar a hipótese de nenhuma coerência para valores de \(\overline{\rho}^2_{_{YX}}(\omega)\) que exceda \(C_{0.001} = 0.32\).
Enfatizamos que este método é bruto porque, além do fato da estatística \(F\) ser aproximada, estamos examinando a coerência
quadrada em todas as frequências com a desigualdade de Bonferroni em mente. A Figura IV.15 também exibe bandas de confiança como parte
da rotina de gráfico do R. Enfatizamos que essas bandas são válidas apenas para \(\omega\) onde \(\overline{\rho}^2_{_{YX}}(\omega)>0\) .
Nesse caso, as duas séries são obviamente fortemente coerentes na frequência sazonal anual. As séries também são fortemente
coerentes em frequências mais baixas que podem ser atribuídas ao ciclo El Niño, que afirmamos ter um período de 3 a 7 anos. O pico na
coerência, entretanto, ocorre próximo ao ciclo de 9 anos. Outras frequências também são coerentes, embora a coerência
forte seja menos impressionante porque o espectro de potência subjacente nessas frequências mais altas é bastante pequeno. Finalmente, notamos
que a coerência é persistente nas frequências harmônicas sazonais.
IV.7 Filtros lineares
Alguns dos exemplos das seções anteriores sugeriram a possibilidade de que a distribuição de poder ou variação em uma série
temporal pode ser modificada por meio de uma transformação linear. Nesta seção, exploramos essa noção ainda mais, mostrando como os
filtros lineares podem ser usados para extrair sinais de uma série temporal. Esses filtros modificam as características espectrais de uma série temporal
de maneira previsível e o desenvolvimento sistemático de métodos para aproveitar as propriedades especiais dos filtros lineares é um tópico
importante na análise de série temporal.
Recordando que o Teorema IV.3 afirmou se
\begin{equation*}
Y_t \, = \, \sum_{j=-\infty}^\infty a_j X_{t-j}, \qquad \sum_{j=-\infty}^\infty |a_j| < \infty,
\end{equation*}
e \(X_t\) tem espectro \(f_{_{XX}}(\omega)\), então \(Y_t\) tem espectro
\begin{equation*}
f_{_{YY}}(\omega) \, = \, \big| A_{_{YX}}(\omega)\big|^2 f_{_{XX}}(\omega),
\end{equation*}
onde
\begin{equation*}
A_{_{YX}}(\omega) \, = \, \sum_{j=-\infty}^\infty a_j e^{-2\pi \, i \omega j}
\end{equation*}
é a função de resposta em frequência. Este resultado mostra que o efeito de filtragem pode ser caracterizado como uma multiplicação de
frequência por frequência pela magnitude quadrada da função da resposta em frequência.
Exemplo IV.22. Filtros de primeira diferença e média móvel.
Ilustramos o efeito da filtragem com dois exemplos comuns, o primeiro filtro de diferença
\begin{equation*}
Y_t \, = \, \nabla X_t \, = \, X_t \, - \, X_{t-1}
\end{equation*}
e o filtro de média móvel simétrica anual,
\begin{equation*}
Y_t \, = \, \dfrac{1}{24}\big(X_{t-6}+X_{t+6}\big) \, + \, \dfrac{1}{12}\sum_{r=-5}^5 X_{t-r},
\end{equation*}
que é um kernel Daniell modificado com \(m = 6\).
Os resultados da filtragem da série SOI usando os dois filtros são mostrados nos painéis do meio e inferior da Figura IV.16. Observe que o efeito da
diferenciação é tornar a série mais áspera porque tende a reter as frequências mais altas ou mais rápidas. A média
móvel centralizada suaviza a série porque retém as frequências mais baixas e tende a atenuar as frequências mais altas. Em geral, a
diferenciação é um exemplo de filtro alto porque retém ou passa as frequências mais altas, enquanto a média móvel
é um filtro baixo porque passa as frequências mais baixas ou mais lentas.
Figura IV.16: Série SOI (topo) comparada com o SOI diferenciado (meio) e uma média móvel de 12 meses centralizada (parte inferior).
> library(astsa)
> par(mfrow=c(3,1), mar=c(3,3,1,1), mgp=c(1.6,.6,0))
> plot(soi) # gráfico dos dados
> plot(diff(soi)) # mostrando a primeira diferença
> k = kernel("modified.daniell", 6) # calculando os pesos dos filtros
> plot(soif <- kernapply(soi, k)) # mostrando o filtro de 12 meses
> grid()
Observe que os períodos mais lentos são realçados na média móvel simétrica e as frequências sazonais ou anuais são
atenuadas. A série filtrada faz cerca de 9 ciclos na duração dos dados, cerca de um ciclo a cada 52 meses, e o filtro das médias móveis tende
a aumentar ou extrair o sinal do El Niño. Além disso, ao filtrar os dados com um filtro baixo temos uma melhor noção do efeito do El Niño e de sua irregularidade.
Agora, feita a filtragem, é essencial determinar a maneira exata como os filtros alteram o espectro de entrada. Usando que \(A(\omega)=\sum_{j=-\infty}^\infty a_j e^{-2 \pi \, i \, \omega i}\)
e o resultado da Teorema IV.3 para este propósito. O primeiro filtro de diferença pode ser escrito como
\begin{equation*}
Y_t \, = \, \sum_{j=-\infty}^\infty A_j X_{t-j} \qquad \mbox{ com } \qquad \sum_{j=-\infty}^\infty |a_j|<\infty,
\end{equation*}
considerando \(a_0 = 1\), \(a_1 = -1\) e \(a_r = 0\) caso contrário. Isso implica que
\begin{equation*}
A_{_{YX}}(\omega) \, = \, 1-e^{-2\pi \, i \, \omega},
\end{equation*}
e a resposta de frequência quadrada torna-se
\begin{equation*}
|A_{_{YX}}(\omega) |^2 \, = \, \big(1-e^{-2\pi \, i \, \omega} \big)\big(1-e^{2\pi \, i \, \omega} \big) \, = \, 2\big(1-\cos(2\pi\omega) \big)\cdot
\end{equation*}
Figura IV.17: Funções de resposta de frequência ao quadrado da primeira diferença (topo) e filtros de média móvel de doze meses (parte inferior).
O painel superior da Figura IV.17 mostra que o primeiro filtro de diferença atenuará as frequências mais baixas e aumentará as frequências
mais altas porque o multiplicador do espectro \(|A_{_{YX}}(\omega) |^2\) é grande para as frequências mais altas e pequeno para as frequências mais baixas. Geralmente,
o aumento lento desse tipo de filtro não o recomenda particularmente como um procedimento para reter apenas as altas frequências.
Para a média móvel centrada de 12 meses, podemos tomar \(a_{-6}=a_6=1/24\), \(a_k=1/12\) para \(-5\leq k\leq 5\) e \(a_k=0\) caso contrário. Substituindo
e reconhecendo o termos cosseno dá
\begin{equation*}
A_{_{YX}}(\omega) \, = \, \dfrac{1}{12}\left( 1+\cos\big( 12\pi\omega\big)+2\sum_{k=1}^5 \cos\big( 2\pi\omega \, k\big)\right)\cdot
\end{equation*}
Traçando o quadrado da resposta de frequência desta função como na parte inferior da Figura IV.17 mostra que podemos esperar que este filtro corte
a maior parte do conteúdo de frequência acima de 0.05 ciclos por ponto e quase todo o conteúdo de frequência acima de \(1/12\approx 0.083\). Em particular,
isso reduz os componentes anuais com períodos de 12 meses e aumenta a frequência do El Niño, que é um pouco menor. O filtro não é
completamente eficiente na atenuação de altas frequências; algumas contribuições de potência são deixadas em frequências mais
altas, conforme mostrado na função \(|A_{_{YX}}(\omega)|^2\).
Os dois filtros discutidos no exemplo anterior eram diferentes porque a função de resposta em frequência da primeira diferença era de valor complexo, enquanto
a resposta em frequência da média móvel era puramente real. Uma derivação direta mostra que, quando \(X_t\) e \(Y_t\) estão relacionados pela
relação de filtro linear, o espectro cruzado satisfaz
\begin{equation*}
f_{_{YX}}(\omega) \, = \, A_{_{YX}}(\omega)f_{_{XX}}(\omega),
\end{equation*}
então a resposta em frequência é da forma
\begin{equation*}
A_{_{YX}}(\omega) \, = \, \dfrac{f_{_{YX}}(\omega)}{f_{_{XX}}(\omega)} \, = \, \dfrac{c_{_{YX}}(\omega)}{f_{_{XX}}(\omega)} -i\dfrac{q_{_{YX}}(\omega)}{f_{_{XX}}(\omega)},
\end{equation*}
onde usamos que \(f_{_{XY}}(\omega)=c_{_{XY}}(\omega)-iq_{_{XY}}(\omega)\) para obter a último relação. Então, podemos escrever \(A_{_{YX}}(\omega)\)
em coordenadas polares como
\begin{equation*}
A_{_{YX}}(\omega) \, = \, |A_{_{YX}}(\omega) |\exp\big( -i \phi_{_{YX}}(\omega)\big),
\end{equation*}
onde a amplitude e a fase do filtro são definidas por
\begin{equation*}
|A_{_{YX}}(\omega)| \, = \, \dfrac{\sqrt{c^2_{_{YX}}(\omega)+q^2_{_{YX}}(\omega)}}{f_{_{XX}}(\omega)}
\end{equation*}
e
\begin{equation*}
\phi_{_{YX}}(\omega) \, = \, \tan^{-1}\left(-\dfrac{q_{_{YX}}(\omega)}{c_{_{YX}}(\omega)} \right)\cdot
\end{equation*}
Uma interpretação simples da fase de um filtro linear é que ele exibe atrasos de tempo em função da frequência, da mesma forma que o
espectro representa a variância em função da frequência. Uma visão adicional pode ser obtida considerando o filtro de atraso simples
\begin{equation*}
Y_t \, = \, A X_{t-D},
\end{equation*}
onde a série é substituída por uma versão amplificada pela multiplicação por \(A\) e atrasada por \(D\) pontos.
Para este caso,
\begin{equation*}
f_{_{YX}}(\omega) \, = \, A e^{-2\pi \, i \omega D} f_{_{XX}}(\omega),
\end{equation*}
a amplitude é \(|A|\) e a fase é
\begin{equation*}
\phi_{_{YX}}(\omega) \, = \, -2\pi \omega D,
\end{equation*}
ou apenas uma função linear da frequência \(\omega\). Para este caso, a aplicação de um atraso de tempo simples causa atrasos de fase
que dependem da frequência do componente periódico que está sendo atrasado. A interpretação é ainda mais aprimorada pela
configuração
\begin{equation*}
X_t \, = \, \cos\big( 2\pi\omega t\big),
\end{equation*}
caso no qual
\begin{equation*}
Y_t \, = \, A\cos\big( 2\pi \, \omega t -2\pi\, \omega D\big)\cdot
\end{equation*}
Assim, a série de saída \(Y_t\), tem o mesmo período que a série de entrada \(X_t\), mas a amplitude da saída aumentou por um
fator de \(|A|\) e a fase foi alterada por um fator de \(-2\pi \omega D\).
Exemplo IV.23. Filtros de diferença e médias móveis.
Consideramos o cálculo da amplitude e da fase dos dois filtros discutidos no Exemplo IV.22. O caso da média móvel é fácil porque
\(A_{_{YX}}(\omega)\) é puramente real. Portanto, a amplitude é apenas \(|A_{_{YX}}(\omega)|\) e a fase é \(\phi_{_{YX}}(\omega) = 0\). Em geral,
os filtros simétricos \(a_j = a_{-j}\) têm fase zero.
A primeira diferença, entretanto, muda isso, como poderíamos esperar do exemplo acima envolvendo o filtro de atraso de tempo. Nesse caso, a amplitude
ao quadrado é dada por
\begin{equation*}
|A_{_{YX}}(\omega)|^2 \, = \, \big(1-e^{-2\pi \, i \, \omega} \big)\big(1-e^{2\pi \, i \,\omega} \big) \, = \, 2|1-\cos\big( 2\pi\omega\big)|\cdot
\end{equation*}
Para calcular a fase, escrevemos
\begin{array}{rcl}
A_{_{YX}}(\omega) & = & 1-e^{-2\pi \, i \, \omega} \, = \, e^{-\pi \, i \, \omega}\Big(e^{i\pi \omega}-e^{-i\pi \omega} \Big) \\[0.8em]
& = & 2ie^{-i\pi\omega}\sin(\pi\omega) \, = \, 2\sin^2(\pi\omega)+2i \cos(\pi\omega)\sin(\pi\omega)\\[0.8em]
& = & \dfrac{c_{_{YX}}(\omega)}{f_{_{XX}}(\omega)}-i\dfrac{q_{_{YX}}(\omega)}{f_{_{XX}}(\omega)},
\end{array}
então
\begin{equation*}
\phi_{_{YX}}(\omega) \, = \, \tan^{-1}\left( -\dfrac{q_{_{YX}}(\omega)}{c_{_{YX}}(\omega)}\right) \, = \, \tan^{-1}\dfrac{\cos(\pi\omega)}{\sin(\pi\omega)}\cdot
\end{equation*}
Notar que
\begin{equation*}
\cos(\pi\omega) \, = \, \sin(-\pi\omega +\pi/2)
\end{equation*}
e que
\begin{equation*}
\sin(\pi\omega) \, = \, \cos(-\pi\omega +\pi/2),
\end{equation*}
e
\begin{equation*}
\phi_{_{YX}}(\omega) \, = \, -\pi\omega+\pi/2,
\end{equation*}
e a fase é novamente uma função linear da frequência.
A tendência acima das frequências de chegarem em momentos diferentes na versão filtrada da série permanece como uma das duas características
irritantes dos filtros de tipo de diferença. A outra fraqueza é o aumento suave na função de resposta de frequência. Se as baixas frequências
não são realmente importantes e as altas frequências devem ser preservadas, gostaríamos de ter uma resposta um pouco mais nítida do que é óbvio
na Figura IV.17. Da mesma forma, se as frequências baixas são importantes e as frequências altas não, os filtros de médias móveis também não
são muito eficientes em passar as frequências baixas e atenuar as frequências altas. A melhoria é possível projetando filtros melhores e mais longos, mas
não discutiremos isso aqui.
Ocasionalmente, usaremos resultados para séries multivariadas \(X_t = (X_{t1},\cdots,X_{tp})\) que são comparáveis à propriedade simples mostrada no
Teorema IV.3. Considere o filtro matricial
\begin{equation*}
Y_t \, = \, \sum_{j=-\infty}^\infty A_j X_{t-j},
\end{equation*}
onde \(\{A_j\}\) denota uma sequência de matrizes \(q\times p\) tais que \(\sum_{j=-\infty}^\infty ||A_j|| <\infty \) e \(||\cdot||\) denota qualquer norma de matriz,
\(X_t = (X_{t1}\cdots,X_{tp})^\top\) é um processo vetorial estacionário \(p\times 1\) com vetor médio \(\mu_{_X}\), função \(p\times p\) de matriz de
covariâncias \(\Gamma_{_{XX}}(h)\), matriz espectral \(f_{_{XX}}(\omega)\) e \(Y_t\) é o processo de saída \(q\times 1\). Então, podemos
obter a seguinte propriedade.
Teorema IV.9. Matriz espectral de saída da série de vetores filtrados.
A matriz espectral da saída filtrada \(Y_t\) em
\begin{equation*}
Y_t \, = \, \sum_{j=-\infty}^\infty A_j X_{t-j},
\end{equation*}
está relacionada ao espectro da entrada \(X_t\) por
\begin{equation}
f_{_{YY}}(\omega) \, = \, \mathcal{A}(\omega)f_{_{XX}}(\omega)\mathcal{A}^*,
\end{equation}
onde a função de resposta de frequência matricial \(\mathcal{A}(\omega)\) é definida por
\begin{equation}
\mathcal{A} \, = \, \sum_{j=-\infty}^\infty A_j \exp\big(-2\pi \, i \, \omega j \big)\cdot
\end{equation}
Demonstração Ver Seção C.6 ▉
IV.8 Modelos de regressão defasada
Uma das possibilidades intrigantes oferecidas pela análise de coerência da relação entre as séries de SOI e Recrutamento
discutidas no Exemplo IV.21 seria estender a regressão clássica à análise de modelos de regressão defasados da forma
\begin{equation}
Y_t \, = \, \sum_{r=\infty}^\infty \beta_r X_{t-r}+V_t,
\end{equation}
onde \(V_t\) é um processo de ruído estacionário, \(X_t\) é a série de entrada observada e \(Y_t\) é a série
de saída observada. Estamos interessados em estimar os coeficientes de filtro \(\beta_r\) relacionando os valores defasados adjacentes de \(X_t\) à
série de saída \(Y_t\).
No caso das séries SOI e Recrutamento, podemos identificar a série de condução do El Niño, SOI, como a entrada, \(X_t\) e
\(Y_t\), a série de Recrutamento, como a saída. Em geral, haverá mais de uma série de entradas possíveis e podemos imaginar
um vetor \(q\times 1\) de séries de condução. Essa situação de entrada multivariada é abordada no Capítulo VII.
O modelo acima é útil sob vários cenários diferentes, correspondendo a diferentes suposições que podem ser feitas
sobre os componentes.
Assumimos que as entradas e saídas têm médias zero e são conjuntamente estacionárias, de dimensão \(2\times 1\), com o
processo vetorial \((X_t,Y_t)^\top\) tendo uma matriz espectral da forma
\begin{equation}
f(\omega) \, = \, \begin{pmatrix} f_{_{X,X}}(\omega) & f_{_{X,Y}}(\omega) \\ f_{_{Y,X}}(\omega) & f_{_{Y,Y}}(\omega) \end{pmatrix}\cdot
\end{equation}
Aqui, \(f_{_{X,Y}}(\omega)\) é o espectro cruzado relacionando a entrada \(X_t\) com a saída \(Y_t\), e \(f_{_{X,X}}(\omega)\) e
\(f_{_{Y,Y}}(\omega)\) são os espectros das séries de entrada e saída, respectivamente. Geralmente, observamos duas séries,
consideradas como entrada e saída e procuramos por funções de regressão para relacionar as entradas às saídas.
Presumimos que todas as funções de autocovariância satisfazem as condições de soma absoluta.
Então, minimizando o erro quadrático médio
\begin{equation}
MSE \, = \, \mbox{E}\left( Y_t - \sum_{r=\infty}^\infty \beta_r X_{t-r}\right)^2,
\end{equation}
leva às condições usuais de ortogonalidade
\begin{equation}
\mbox{E}\left( \Big(Y_t - \sum_{r=\infty}^\infty \beta_r X_{t-r}\Big)X_{t-s}\right) \, = \, 0
\end{equation}
para todos os \(s = 0,\pm 1,\pm 2,\cdots\). Tomando as esperanças dentro leva às equações normais
\begin{equation}
\sum_{r=-\infty}^\infty \beta_r \gamma_{_{X,X}}(s-r) \, = \, \gamma_{_{Y,X}}(s),
\end{equation}
para \(s = 0,\pm 1,\pm 2,\cdots\). Estas equações podem ser resolvidas, com algum esforço, se as funções de covariância
forem conhecidas exatamente. Se os dados \((X_t,Y_t)\) para \(t = 1,\cdots,n\) estão disponíveis, podemos usar uma aproximação finita
das equações acima com \(\widehat{\gamma}_{_{X,X}}(h)\) e \(\widehat{\gamma}_{_{Y,X}}(h)\) substituídos nas equações normais acima.
Se os vetores de regressão forem essencialmente nulos para \(|s|\geq M/2\) e \(M < n\), o sistema de equações normais seria de total
alcance e a solução envolveria inverter uma matriz \((M-1)\times (M-1)\).
Uma solução aproximada de domínio de frequência é mais fácil neste caso por dois motivos. Primeiro, os cálculos
dependem de espectros e espectros cruzados que podem ser estimados a partir de dados amostrais usando as técnicas da Seção IV.5. Além
disso, nenhuma matriz terá que ser invertida, embora a razão do domínio da frequência tenha que ser calculada para cada frequência.
Para desenvolver a solução do domínio da frequência, substitua a representação na Proposição IV.8 de \(\Gamma(h)\)
pelas equações normais. O lado esquerdo das equações normais pode então ser escrito na forma
\begin{equation}
\int_{-\frac{1}{2}}^{\frac{1}{2}}\sum_{r=-\infty}^\infty \beta_r e^{2\pi \, i \, \omega(s-r)}f_{_{X,X}}(\omega)\mbox{d}\omega \, = \,
\displaystyle \int_{-\frac{1}{2}}^{\frac{1}{2}}e^{2\pi \, i \, \omega s}B(\omega)f_{_{X,X}}(\omega)\mbox{d}\omega,
\end{equation}
onde
\begin{equation}
B(\omega) \, = \, \sum_{r=-\infty}^\infty \beta_r e^{2\pi \, i \, \omega r}
\end{equation}
é a transformada de Fourier dos coeficientes de regressão \(\beta_t\). Agora, como \(\gamma_{_{Y,X}}(s)\) é a transformada inversa do espectro cruzado
\(f_{_{Y,X}}(\omega)\), podemos escrever o sistema de equações no domínio da frequência, usando a unicidade da transformada de Fourier, como
\begin{equation}
B(\omega)f_{_{X,X}}(\omega) \, = \, f_{_{Y,X}}(\omega),
\end{equation}
que então se tornam os análogos das equações normais usuais.
Então, podemos escrever
\begin{equation}
\widehat{B}(\omega_k) \, = \, \frac{\widehat{f}_{_{Y,X}}(\omega_k)}{\widehat{f}_{_{X,X}}(\omega_k)},
\end{equation}
como estimador da transformada de Fourier dos coeficientes de regressão, avaliados em algum subconjunto de frequências fundamentais \(\omega_k=k/M\) com \(M≪ n\).
Geralmente, assumimos suavidade de \(B(\cdot)\) sobre intervalos da forma \(\{\omega_k+\ell \, : \, \ell =-m,\cdots,0,\cdots,m\}\), com \(L=2m+1\). A transformada inversa da
função \(\widehat{B}(\omega)\) nos daria \(\widehat{\beta}_t\) e observamos que a aproximação discreta pode ser tomada como
\begin{equation}
\widehat{\beta}_t \, = \, \frac{1}{M}\sum_{k=0}^{M-1} \widehat{B}(\omega_k)e^{2\pi \, i \, \omega_k t},
\end{equation}
para \(t=0,\pm 1,\pm 2,\cdots,\pm (M/2-1)\). Se tivéssemos que usar a expressão acima para definir \(\widehat{\beta}_t\) para \(|t|\geq M/2\),
acabaríamos com uma sequência de coeficientes que é periódica com um período de \(M\). Na prática, definimos
\(\widehat{\beta}_t=0\) para \(|t|\geq M/2\).
Exemplo IV.24. Regressão retardada para SOI e Recrutamento.
A alta coerência entre as séries SOI e Recrutamento observada no Exemplo IV.21 sugere uma relação de regressão defasada
ou retardada entre as duas séries. Uma direção natural para a implicação nesta situação está
implícita porque sentimos que a temperatura da superfície do mar ou SOI deve ser a entrada e a série de Recrutamento deve ser a
saída. Com isto em mente, seja \(X_t\) a série SOI e \(Y_t\) a série Recrutamento.
Embora pensemos naturalmente no SOI como a entrada e o Recrutamento como a saída, duas configurações de entrada-saída são
de interesse. Com o SOI como entrada, o modelo é
\begin{equation}
Y_t \, = \, \sum_{r=-\infty}^\infty a_r X_{t-r}+W_t,
\end{equation}
considerando que um modelo que inverte os dois papéis seria
\begin{equation}
X_t \, = \, \sum_{r=-\infty}^\infty b_r Y_{t-r}+V_t,
\end{equation}
onde \(W_t\) e \(V_t\) são processos de ruído branco. Embora não exista uma explicação ambiental plausível
para o segundo desses dois modelos, a exibição de ambas as possibilidades ajuda a estabelecer um modelo de função
de transferência parcimoniosa, mas não será mostrado.
Baseado no script LagReg no pacote astsa, a função de regressão estimada ou resposta ao impulso
para SOI, com \(M = 32\) e \(L = 15\) é:
> library(astsa)
> par(mfrow=c(1,1), mar=c(3,3,3,1), mgp=c(1.6,.6,0))
> resultado = LagReg(soi, rec, L=15, M=32, threshold=6)
INPUT: soi OUTPUT: rec L = 15 M = 32
The coefficients beta(0), beta(1), beta(2) ... beta(M/2-1) are
3.463141 2.088613 2.688139 -0.3515829 0.3717705 -18.47931 -12.2633 -8.539368 -6.984553 -4.978238 -4.526358 -4.223713
-3.239262 -1.372815 1.489903 3.744727
The coefficients beta(0), beta(-1), beta(-2) ... beta(-M/2+1) are
3.463141 2.835444 1.628129 2.726815 0.6330645 -1.256092 -0.05458373 1.722774 4.925481 5.440352 6.877381 5.141606
4.479202 3.796848 4.004762 3.184184
The positive lags, at which the coefficients are large
in absolute value, and the coefficients themselves, are:
lag s beta(s)
[1,] 5 -18.479306
[2,] 6 -12.263296
[3,] 7 -8.539368
[4,] 8 -6.984553
The prediction equation is
rec(t) = alpha + sum_s[ beta(s)*soi(t-s) ], where alpha = 65.96584
MSE = 414.0847
Observe o pico negativo em um atraso de cinco pontos na figura acima. A queda após o desfasamento cinco parece ser aproximadamente exponencial
e um possível modelo é
\begin{equation}
Y_t \, = \, 65.96584-18.479306 X_{t-5}-12.263296 X_{t-6}-8.539368 X_{t-7}-6.984553 X_{t-8}+W_t\cdot
\end{equation}
Se examinarmos a relação inversa, ou seja, um modelo de regressão com a série Recrutamento \(Y_t\) como entrada obtemos
um modelo muito mais simples:
> par(mfrow=c(1,1), mar=c(3,3,3,1), mgp=c(1.6,.6,0))
> resultado1 = LagReg(rec, soi, L=15, M=32, inverse=TRUE, threshold=.01)
INPUT: rec OUTPUT: soi L = 15 M = 32
The coefficients beta(0), beta(1), beta(2) ... beta(M/2-1) are
0.004461216 0.001061309 -0.002206203 0.001890203 -0.0005578082 -0.003021943 -0.0004643641 -0.00137669 0.002186134
0.001726505 0.002637365 -0.003106259 0.003181714 0.001085057 -0.001040998 -0.003780144
The coefficients beta(0), beta(-1), beta(-2) ... beta(-M/2+1) are
0.004461216 -0.003535525 0.001851014 -0.001654371 0.01593167 -0.02120013 0.001450279 0.001901667 0.000181094
-0.001796688 0.0001158145 0.0006828962 0.00107619 0.0005235587 -0.000145583 -0.0001296385
The negative lags, at which the coefficients are large
in absolute value, and the coefficients themselves, are:
lag s beta(s)
[1,] 4 0.01593167
[2,] 5 -0.02120013
The prediction equation is
soi(t) = alpha + sum_s[ beta(s)*rec(t+s) ], where alpha = 0.4080661
MSE = 0.07023683
dependendo de apenas dois coeficientes, ou seja,
\begin{equation}
X_t \, = \, 0.4080661+0.01593167 Y_{t+4}-0.02120013 Y_{t+5}+V_t\cdot
\end{equation}
Multiplicando ambos os lados por \(50B^5\) e rearranjando, temos
\begin{equation}
(1-0.8 B)Y_t \, = \, 20.5 -50B^5 X_t+\epsilon_t\cdot
\end{equation}
Finalmente, verificamos se o ruído \(\epsilon_t\) é branco. Além disso, neste ponto, simplifica a questão se
voltarmos a executar a regressão com erros autocorrelacionados e reestimar os coeficientes. O modelo é chamado de modelo \(ARMAX\), o \(X\)
significa exógeno; consulte a Seção V.6 e a Seção VI.6.1:
> sarima(fish[,1], 1, 0, 0, xreg=fish[,2:3]) # modelo ARMAX
initial value 2.047606
iter 2 value 1.958908
iter 3 value 1.957404
iter 4 value 1.952420
iter 5 value 1.952201
iter 6 value 1.951913
iter 7 value 1.951750
iter 8 value 1.951726
iter 9 value 1.951724
iter 10 value 1.951724
iter 10 value 1.951724
final value 1.951724
converged
initial value 1.951922
iter 2 value 1.951921
iter 3 value 1.951915
iter 4 value 1.951915
iter 5 value 1.951914
iter 5 value 1.951914
iter 5 value 1.951914
final value 1.951914
converged
$fit
Call:
stats::arima(x = xdata, order = c(p, d, q), seasonal = list(order = c(P, D,
Q), period = S), xreg = xreg, transform.pars = trans, fixed = fixed, optim.control = list(trace = trc,
REPORT = 1, reltol = tol))
Coefficients:
ar1 intercept RL1 SL5
0.4489 14.6838 0.7902 -20.9988
s.e. 0.0495 1.5605 0.0229 1.0812
sigma^2 estimated as 49.57: log likelihood = -1510.14, aic = 3030.28
$degrees_of_freedom
[1] 444
$ttable
Estimate SE t.value p.value
ar1 0.4489 0.0495 9.0591 0
intercept 14.6838 1.5605 9.4098 0
RL1 0.7902 0.0229 34.4532 0
SL5 -20.9988 1.0812 -19.4218 0
$AIC
[1] 6.764027
$AICc
[1] 6.764229
$BIC
[1] 6.80984
Nosso modelo ajustado final e parcimonioso é com arredondamento é
\begin{equation}
Y_t \, = \, 14.6838 +0.7902 Y_{t-1}-20.9988 X_{t-5}+\epsilon_t, \qquad \epsilon_t=0.4489 \epsilon_{t-1}+W_t,
\end{equation}
onde \(W_t\) é ruído branco com \(\widehat{\sigma}^2_{_W}=49.57\). Este exemplo também é examinado no Capítulo V e os valores
ajustados para o modelo final podem ser visualizados na figura no Exemplo V.9.
O exemplo mostra que podemos obter um estimador limpo para as funções de transferência relacionando as duas séries se a
coerência \(\widehat{\rho}^2_{_{x,y}}\) é grande. A razão é que podemos escrever o erro quadrático médio
como
\begin{equation}
MSE \, = \, \mbox{E}\left( \Big(Y_t -\sum_{r=-\infty}^\infty \beta_r X_{t-r} \Big)Y_y\right) \, = \, \gamma_{_{Y,Y}}(0)-\sum_{r=-\infty}^\infty \beta_r \gamma_{_{X,Y}}(-r),
\end{equation}
usando o resultado sobre a ortogonalidade dos dados e o termo de erro no Teorema da Projeção. Então, substituindo as representações
espectrais das funções de autocovariância e de covariância cruzada e identificando a transformada de Fourier no resultado
\begin{equation*}
B(\omega) \, = \, \sum_{r=-\infty}^\infty \beta_r e^{2\pi \, i \, \omega r},
\end{equation*}
leva a
\begin{equation}
MSE \, = \, \int_{-\frac{1}{2}}^\frac{1}{2} \left( f_{_{Y,Y}}(\omega)-B(\omega)f_{_{X,Y}}(\omega)\right)\mbox{d}(\omega) \, = \,
\int_{-\frac{1}{2}}^\frac{1}{2} f_{_{Y,Y}}(\omega)\left( 1-\rho_{_{Y,X}}^2(\omega)\right)\mbox{d}(\omega),
\end{equation}
onde \(\rho_{_{Y,X}}^2(\omega)\) é apenas a coerência quadrada. A semelhança do \(MSE\) dado acima com o erro quadrático médio
usual resulta da previsão de \(y\) de \(x\). Nesse caso, teríamos
\begin{equation}
\mbox{E}\big( Y-\beta X\big)^2 \, = \, \sigma_{_Y}^2 \big(1-\rho^2_{_{X,Y}}\big),
\end{equation}
para variáveis aleatórias com distribuição conjunta \(X\) e \(Y\) com m&eacdias;dias zero, variâncias \(\sigma^2_{_X}\) e
\(\sigma^2_{_Y}\) e covariância \(\sigma_{_{X,Y}} = \rho_{_{X,Y}}\sigma_{_X}\sigma_{_Y}\). Como o erro quadrático médio satisfaz \(MSE\geq 0\)
com \(f_{_{Y,Y}}(\omega)\) uma função não-negativa, segue-se que a coerência satisfaz
\begin{equation}
0\leq \rho^2_{_{X,Y}}\leq 1,
\end{equation}
para todo \(\omega\). Assim, a coerência múltipla fornece uma medida da associação ou correlação entre as
séries de entrada e saída em função da frequência.
A questão de verificar se a distribuição \(F\) será válida quando os valores da coerência amostral forem
substituídos por valores teóricos ainda permanece. Novamente, a forma da estatística \(F\) é exatamente análoga
ao teste \(t\) usual para nenhuma correlação em um contexto de regressão. Daremos um argumento que leva a essa conclusão
mais tarde usando os resultados da Seção C.3.
Outra questão que não foi resolvida nesta seção é a extensão para o caso de múltiplas entradas
\(X_{t_1},X_{t_2},\cdots,X_{t_q}\). Frequentemente, há mais do que apenas uma única série de entrada que pode possivelmente formar um
preditor defasado da série de saída \(Y_t\). Um exemplo é a série de mortalidade cardiovascular que dependia possivelmente de várias
séries de poluição e temperatura. Discutimos essa extensão particular como parte das técnicas de séries temporais
multivariadas consideradas no Capítulo VII.
IV.9 Extração de sinal e filtragem ótima
Um modelo intimamente relacionado à regressão pode ser desenvolvido assumindo novamente que
\begin{equation}
Y_t \, = \, \sum_{r=\infty}^\infty \beta_r X_{t-r}+V_t,
\end{equation}
mas onde os \(\beta\)s são conhecidos e \(X_t\) é algum sinal aleatório desconhecido que não está correlacionado com
o processo de ruído \(V_t\). Neste caso, observamos apenas \(Y_t\) e estamos interessados em um estimador para o sinal \(X_t\) da forma
No domínio da frequência é conveniente fazer as suposições adicionais de que as séries \(X_t\) e \(V_t\) são
ambas séries estacionárias de média zero com espectros \(f_{_{X,X}}(\omega)\) e \(f_{_{V,V}}(\omega)\), frequentemente referidos como
o espectro de sinal e o espectro de ruído, respectivamente. O caso especial \(\beta_t = \delta_t\), em que \(\delta_t\) é o delta de Kronecker,
é de interesse porque o modelo assumido para \(Y_t\) acima se reduz ao modelo simples de sinal mais ruído
\begin{equation}
Y_t \, = \, X_t + V_t
\end{equation}
nesse caso. Em geral, buscamos o conjunto de coeficientes de filtro que minimizam o erro quadrático médio de estimativa,
\begin{equation}
MSE \, = \, \mbox{E}\left( X_t - \sum_{r=\infty}^\infty \beta_r Y_{t-r}\right)^2\cdot
\end{equation}
Lembremos que a delta de Kronecker, nomeado em homenagem a Leopold Kronecker, é uma função de duas variáveis, geralmente apenas
inteiros não negativos. A função é 1 se as variáveis forem iguais e 0 caso contrário, definida como:
\begin{equation}
\displaystyle \delta_{ij} = \begin{cases} 0 & {\text{ se }} i \neq j, \\ 1 & {\text{ se }} i = j. \end{cases}
\end{equation}
Este problema foi originalmente resolvido por Kolmogorov (1941) e por Wiener (1949), que derivou o resultado em 1941 e o publicou em relatórios
confidenciais durante a Segunda Guerra Mundial.
Podemos aplicar o princípio da ortogonalidade para escrever
\begin{equation}
\mbox{E}\left( \Big(X_t - \sum_{r=\infty}^\infty a_r Y_{t-r}\Big)Y_{t-s}\right) \, = \, 0
\end{equation}
para todos os \(s = 0,\pm 1,\pm 2,\cdots\), o que leva a
\begin{equation}
\sum_{r=-\infty}^\infty a_r \gamma_{_{Y,Y}}(s-r) \, = \, \gamma_{_{X,Y}}(s),
\end{equation}
a ser resolvido para os coeficientes do filtro. Substituindo as representações espectrais para as funções de autocovariância
acima e identificar as densidades espectrais através da exclusividade da transformada de Fourier produz
\begin{equation}
A(\omega)f_{_{Y,Y}}(\omega) \, = \, f_{_{X,Y}}(\omega),
\end{equation}
onde \(A(\omega)\) e o filtro ótimo \(a_t\) são pares de transformada de Fourier para \(B(\omega)\) e \(\beta_t\). Agora, uma consequência
especial do modelo é que
\begin{equation}
f_{_{X,Y}}(\omega) \, = \, B^*(\omega)f_{_{X,X}}(\omega)
\end{equation}
e
\begin{equation}
f_{_{Y,Y}}(\omega) \, = \, |B(\omega)|^2f_{_{X,X}}(\omega)+f_{_{V,V}}(\omega),
\end{equation}
implicando que o filtro ideal seria a transformada de Fourier de
\begin{equation}
A(\omega) \, = \, \dfrac{B^*(\omega)}{|B(\omega)|^2+\dfrac{f_{_{V,V}}(\omega)}{f_{_{X,Y}}(\omega)}},
\end{equation}
onde o segundo termo no denominador é apenas o inverso da relação sinal-ruído, digamos
\begin{equation}
SNR(\omega) \, = \, \dfrac{f_{_{V,V}}(\omega)}{f_{_{X,Y}}(\omega)}\cdot
\end{equation}
O resultado mostra que os filtros ideais podem ser calculados para este modelo se os espectros de sinal e ruído forem conhecidos ou se pudermos assumir o
conhecimento da relação sinal-ruído \(SNR(\omega)\) em função da frequência. No Capítulo VII, mostramos alguns
métodos para estimar esses dois parâmetros em conjunto com os modelos de análise de variância de efeitos aleatórios, mas assumimos
aqui que é possível especificar a razão sinal-ruído a priori.
Se a relação sinal-ruído for conhecida, o filtro ideal pode ser calculado pela transformada inversa da função \(A(\omega)\). É
mais provável que a transformada inversa seja intratável e uma aproximação de filtro finito como a usada na seção anterior
possa ser aplicada aos dados. Neste caso, teremos
\begin{equation}
a_t^M \, = \, \dfrac{1}{M}\sum_{k=0}^{M-1} A(\omega_k)e^{2\pi \, i \, \omega_k t},
\end{equation}
como a função de filtro estimada. Freqüentemente, a forma da resposta de frequência especificada terá algumas transições
bastante nítidas entre regiões onde a relação sinal-ruído é alta e regiões onde há pouco sinal.
Nestes casos, a forma da função de resposta em frequência terá ondulações que podem introduzir frequências em diferentes
amplitudes. Uma solução estética para este problema é introduzir a redução gradual como foi feito com a estimação
espectral não paramétrica.
Usamos abaixo o filtro cônico \(\widetilde{a}_t = h_ta_t\) onde \(h_t\) é o cosseno dado por
\begin{equation}
h_t \, = \, \displaystyle 0.5\left( 1+\cos\left( \frac{2\pi(t-\overline{t})}{n}\right)\right)\cdot
\end{equation}
A resposta de frequência quadrada do filtro resultante será \(|\widetilde{A}(\omega)|^2\), onde
\begin{equation}
\widetilde{A}(\omega) \, = \, \sum_{t=-\infty}^\infty a_t h_t e^{-2\pi \, i \, \omega t}\cdot
\end{equation}
Os resultados são ilustrados no exemplo a seguir que extrai o componente El Niño da série de temperaturas da superfície do mar.
Exemplo IV.25. Estimando o sinal do El Niño por meio de filtros óptimos.
A Figura IV.7 mostra o espectro da série SOI e notamos que essencialmente dois componentes têm energia: a frequência do El Niño de cerca de 0.02
ciclos por mêês, o ciclo de quatro anos, e uma frequência anual de cerca de 0.08 ciclos por mês, ciclo anual. Assumimos, para este exemplo,
que desejamos preservar a frequência inferior como sinal e eliminar as frequências de ordem superior e, em particular, o ciclo anual. Neste caso, assumimos
o modelo simples de sinal mais ruído
\begin{equation}
Y_t \, = \, X-t + V_t,
\end{equation}
de modo que não há função convolvente \(\beta_t\).
Além disso, a relação sinal-ruído é considerada alta para cerca de 0.06 ciclos por mês e zero depois disso. A resposta de
frequência ótima foi assumida como unitária a 0.05 ciclos por ponto e, em seguida, decai linearmente até zero em várias etapas.
A Figura IV.19 à esquerda mostra os coeficientes conforme especificados por \(a_t^M\) com \(M = 64\), bem como a função de resposta em
frequência dada por \(\widetilde{A}(\omega)\), dos coeficientes cosseno cônicos; lembre-se da Figura IV.11, onde demonstramos a necessidade da
redução gradual para evitar ondulações severas na janela. A função de resposta construída é comparada
com a janela ideal na Figura IV.19.
Figura IV.19. Esquerda: coeficientes do filtro (parte superior) e funções de resposta de frequência (parte inferior) para filtros SOI projetados.
Direita: espectros da séria original e da série filtrada.
A Figura IV.20 mostra o índice SOI original e filtrado e vemos um sinal extraído suave que transmite a essência do sinal El Niño subjacente.
A resposta de frequência do filtro projetado pode ser comparada com aquela da média móvel simétrica de 12 meses aplicada à mesma
série no Exemplo IV.22. A série filtrada, mostrada na Figura IV.16, mostra uma boa quantidade de vibração de frequência mais alta
na versão suavizada, que foi introduzida pelas frequências mais altas que vazam na resposta de frequência quadrada, como na Figura IV.17.
Figura IV.20. Série SOI original (parte superior) em comparação com a versão filtrada mostrando o sinal
estimado de temperatura do El Niño (parte inferior).
O projeto de filtros finitos com uma resposta de frequência especificada requer alguma experimentação com várias funções de
resposta de frequência alvo e apenas tocamos na metodologia aqui. O filtro projetado aqui, às vezes chamado de filtro passa-baixa, reduz as frequências
altas e mantém ou passa as frequências baixas. Como alternativa, poderíamos projetar um filtro passa-alta para manter as altas frequências
se for onde o sinal está localizado. Um exemplo de um filtro passa-alta simples é a primeira difereça com uma resposta de frequência que
é mostrada na Figura IV.17. Também podemos projetar filtros passa-banda que mantêm as frequências em bandas especificadas. Por exemplo, filtros
de ajuste sazonal são freqüentemente usados em economia para rejeitar frequências sazonais, enquanto mantêm frequências altas, frequências
mais baixas e tendência (ver, por exemplo, Grether and Nerlove, 1970).
Os filtros que discutimos aqui são todos filtros simétricos de dois lados, porque as funções de resposta de frequência projetadas eram
puramente reais. Alternativamente, podemos projetar filtros recursivos para produzir uma resposta desejada. Um exemplo de filtro recursivo é aquele que substitui
a entrada \(X_t\) pela saída filtrada
\begin{equation}
Y_t \, = \, \sum_{k=1}^p \phi_k Y_{t-k}+X_t-\sum_{k=1}^q \theta_k X_{t-k}\cdot
\end{equation}
Observe a semelhança entre a expressão acima e o modelo \(ARMA(p,q)\), em que o componente de ruído branco é substituído pela entrada.
Transpor os termos envolvendo \(Y_t\) e usando o resultado do filtro linear básico no Teorema IV.3 leva a
\begin{equation}
f_{_Y}(\omega) \, = \, \dfrac{|\theta(e^{-2\pi \, i \, \omega})|^2}{|\phi(e^{-2\pi \, i \, \omega})|^2} f_{_X}(\omega),
\end{equation}
onde
\begin{equation}
\theta(e^{-2\pi \, i \, \omega}) \, = \, 1-\sum_{k=1}^p \phi_k e^{-2\pi \, i \, k \, \omega}
\end{equation}
e
\begin{equation}
\theta(e^{-2\pi \, i \, \omega}) \, = \, 1-\sum_{k=1}^q \theta_k e^{-2\pi \, i \, k \,\omega}\cdot
\end{equation}
Filtros recursivos, como os fornecidos por \(f_{_Y}(\omega)\), distorcem as fases das frequências de chegada e não consideramos o problema de projetar tais
filtros em detalhes.
IV.10 Análise espectral de séries multidimensionais
Uma séries multidimensional da forma \(X_s\), onde \(s = (s_1, s_2,\dots,s_r)^\top\) é um vetor \(r\)-dimensional de coordenadas espaciais
ou uma combinação de coordenadas de espaço e tempo, foi introduzida na Seção I.6. O exemplo dado ali, mostrado na Figura
I.18, foi uma coleção de medições de temperatura em um campo retangular. Estes dados formaram um processo bidimensional,
indexado por linhas e colunas no espaço. Nessa seção, a função de autocovariância multidimensional de uma série
estacionária \(r\)-dimensional foi dada como \(\gamma_{_X}(h) = \mbox{E}\big( X_{s+h}X_s\big)\), onde o vetor de atraso multidimensional é
\(h = (h_1,h_2,\cdots,h_r)^\top\).
O espectro multidimensional é dado como a transformada de Fourier da autocovariância,
\begin{equation}
f_{_X}(\omega) \, = \, \underset{h}{\sum \cdots \sum} \gamma_{_X}(h)e^{-2\pi \, i \, \omega^\top h}\cdot
\end{equation}
Novamente, o resultado inverso
\begin{equation}
\gamma_{_X}(h) \, = \, \int_{-\frac{1}{2}}^\frac{1}{2}\cdots \int_{-\frac{1}{2}}^\frac{1}{2} f_{_X}(\omega)e^{2\pi \, i \, \omega^\top h}\mbox{d}\omega
\end{equation}
se mantém, onde a integral acima é calculada no intervalo multidimensional do vetor \(\omega\). Temos como interpretação intuitiva
a taxa de ciclagem \(\omega_i\) por distância percorrida \(s_i\) na \(i\)-ésima direção.
Processos bidimensionais ocorrem frequentemente em aplicações práticas e as representações acima se reduzem a
\begin{equation}
f_{_X}(\omega_1,\omega_2) \, = \, \sum_{h=-\infty}^\infty \sum_{h=-\infty}^\infty \gamma_{_X}(h_1,h_2)e^{-2\pi \, i \, (\omega_1 h_1+\omega_2 h_2)}
\end{equation}
e
\begin{equation}
\gamma_{_X}(h_1,h_2) \, = \, \int_{-\frac{1}{2}}^\frac{1}{2} \int_{-\frac{1}{2}}^\frac{1}{2} f_{_X}(\omega_1,\omega_2)e^{2\pi \, i \, (\omega_1 h_1+\omega_2 h_2)}
\mbox{d}\omega_1\mbox{d}\omega_2
\end{equation}
no caso \(r = 2\). A noção de filtragem linear generalizada para o caso bidimensional, definindo a função de resposta ao impulso
\(a_{s_1,s_2}\) e a saída do filtro espacial como
\begin{equation}
Y_{s_1,s_2} \, = \, \sum_{u_1}\sum_{u_2} a_{u_1,u_2}X_{s_1-u_1,s_2-u_2}\cdot
\end{equation}
O espectro da saída deste filtro pode ser derivado como
\begin{equation}
f_{_Y}(\omega_1,\omega_2) \, = \, |A(\omega_1,\omega_2)|^2 f_{_X}(\omega_1,\omega_2)
\end{equation}
onde
\begin{equation}
A(\omega_1,\omega_2) \, = \, \sum_{u_1}\sum_{u_2} a_{u_1,u_2}e^{-2\pi \, i \, (\omega_1 u_1+\omega_2 u_2)}\cdot
\end{equation}
Esses resultados são análogos aos do caso unidimensional, descritos pelo Teorema IV.3.
O Transformada Discreta de Fourier multidimensional também é uma generalização direta da expressão univariada. No caso
bidimensional com dados em uma grade retangular \(\{X_{s_1,s_2} \, : \, s_1=1,\cdots,n_1 \, , \, s_2=1,\cdots,n_2\}\), vamos escrever, para \(-1/2\leq \omega_1, \omega_2\leq 1/2\),
\begin{equation}
d(\omega_1,\omega_2) \, = \, \dfrac{1}{\sqrt{n_1 n_2}}\sum_{s_1=1}^{n_1}\sum_{s_2=1}^{n_2} X_{s_1,s_2}e^{-2\pi \, i \, (\omega_1 s_1+\omega_2 s_2)}
\end{equation}
como a Transformada Discreta de Fourier bidimensional, onde as frequências \(\omega_1,\omega_2\) são avaliados em múltiplos de
\((1/n_1,1/n_2)\) na escala de frequência espacial. O espectro bidimensional pode ser estimado pelo espectro amostral suavizado
\begin{equation}
\overline{f}_{_{X}}(\omega_1,\omega_2) \, = \, \dfrac{1}{L_1 L_2}\sum_{\ell_1 \ell_2} \left| d\big( \omega_1+\ell_1/n_1,\omega_2+\ell_2/n_2 \big)\right|^2,
\end{equation}
onde a soma é obtida ao longo da grade \(\{-m_j\leq \ell_j \leq m_j \, : \, j = 1,2\}\) onde \(L_1 = 2m_1 +1\) e \(L_2 = 2m_2 + 1\). A estatística
\begin{equation}
\dfrac{2L_1L_2 \overline{f}_{_{X}}(\omega_1,\omega_2)}{{f}_{_{X}}(\omega_1,\omega_2)} \, \sim \, \chi_{2L_1L_2}^2
\end{equation}
pode ser usado para definir intervalos de confiança ou fazer testes aproximados contra um espectro fixo assumido \({f}_{_{0}}(\omega_1,\omega_2)\).
Exemplo IV.26. Temperaturas na superfície do solo.
Como exemplo, considere o periodograma da série bidimensional de temperaturas mostrada na Figura I.18 e analisada por Bazza et al. (1988). Lembramos que
as coordenadas espaciais neste caso serão \((s_1,s_2)\), que definem as coordenadas espaciais linhas e colunas para que as frequências nas duas
direções sejam expressas em ciclos por linha e ciclos por coluna. A Figura IV.21 mostra o periodograma da série bidimensional de temperatura
e notamos a crista de fortes picos espectrais correndo sobre linhas com uma frequência de coluna zero. Um componente periódico óbvio aparece
nas frequências de 0.0625 e -0.0625 ciclos por linha, o que corresponde a 16 linhas ou cerca de 272 pés. Em uma investigação mais
aprofundada dos padrões de irrigação anteriores neste campo, os níveis de tratamento de sal variaram periodicamente nas colunas.
Figura IV.21. Periodograma bidimensional do perfil da temperatura do solo mostrando pico em 0.0625 ciclos/linha. O período
é de 16 linhas e isso corresponde a \(16\times 17\)pés = 272 pés.
Outra aplicação da análise espectral bidimensional é no campo agrícola foi dada em McBratney and Webster (1981), que a
usou para detectar padrões de cristas e sulcos no campo. A necessidade de amostras regulares e igualmente espaçadas em grades bastante grandes
tende a limitar o entusiasmo pela análise espectral bidimensional estrita. Uma exceção é quando um sinal de propagação
de uma dada velocidade e azimute está presente, de forma que a previsão do espectro do número de onda em função da velocidade
e do azimute se torna viável (ver Shumway et al., 1999).
IV.11 Exercícios
Verifique se para qualquer número inteiro positivo \(n\) e \(j, k = 0,1,\cdots,[n/2]\), onde \([\cdot]\) denota a função maior inteiro:
Repita as simulações e análises nos Exemplos IV.1 e IV.2 com as seguintes alterações:
(a) Mude o tamanho da amostra para \(n = 128\), gere e mostre gráficamente na mesma série do Exemplo IV.1:
\begin{array}{rcl}
X_{t1} & = & 2\cos(2\pi \, 0.06t)+3\sin(2\pi \, 0.06t), \\
X_{t2} & = & 4\cos(2\pi \, 0.10t)+5\sin(2\pi \, 0.10t), \\
X_{t3} & = & 6\cos(2\pi \, 0.40t)+7\sin(2\pi \, 0.40t), \\
X_{t} & = & X_{t1}+X_{t2}+X_{t3}\cdot
\end{array}
Qual é a principal diferença entre essas séries e as séries geradas no Exemplo IV.1?
Dica: a resposta é fundamental. Mas não é aceito como resposta que a série é mais longa.
(b) Como no Exemplo IV.2, calcule e mostre gráficamente o periodograma da série \(X_t\), gerado em (a) e comente.
(c) Repita as análises de (a) e (b), mas com \(n = 100\), como no Exemplo IV.1, e adicionando ruído a \(X_t\); isso é
\begin{equation*}
X_t \, = \, X_{t1}+X_{t2}+X_{t3}+W_t,
\end{equation*}
onde \(W_t\sim N(0,25)\) independentes identicamente disrtibuídas. Ou seja, você deve simular e mostrar os dados e então
traçar o periodograma de \(X_t\) e comentar.
Considere o processo periódico
\begin{equation}
X_t \, = \, A\cos\big( 2\pi\omega t+\phi\big),
\end{equation}
para \(t=0,\pm 1,\pm 2, \cdots\), o qual pode-se escrever como
\begin{equation}
X_t \, = \, U_1 \cos\big( 2\pi\omega t\big)+U_2\sin\big(2\pi\omega t\big),
\end{equation}
onde \(U_1=A\cos(\phi)\) e \(U_2=-A\sin(\phi)\). Sejam \(Z_1 = U_1\) e \(Z_2 = -U_2\) variáveis normais padrão independentes. Considere
as coordenadas polares do ponto \((Z_1,Z_2)\), isto é,
\begin{equation*}
A^2 \, = \, Z_1^2+Z_2^2 \qquad \mbox{e} \qquad \phi \, = \, \tan^{-1}(Z_2/Z_1)\cdot
\end{equation*}
(a) Encontre a densidade conjunta de \((A^2,\phi)\). Conclua que \(A^2\) e \(\phi\) são independentes, sendo que
\(A^2\sim \chi^2(2)\) e \(\phi\sim U(-\pi,\pi)\).
(b) Indo no sentido inverso, das coordenadas polares às coordenadas retangulares. Suponha assumimos que \(A^2\) e \(\phi\) sejam
variáveis aleatórias independentes, onde \(A^2\sim \chi^2(2)\) e \(\phi\sim U(-\pi,\pi)\). Com \(Z_1 = A\cos(\phi)\) e
\(Z_2 = A\sin(\phi)\), onde \(A\) é a raiz quadrada positiva de \(A^2\), mostre que \(Z_1\) e \(Z_2\) são variáveis
aleatórias normais padrão independentes.
Considere o processo periódico
\begin{equation}
X_t \, = \, \sum_{k=1}^q \Big(U_{k1} \cos\big( 2\pi\omega_k t\big)+U_{k2}\sin\big(2\pi\omega_k t\big)\Big),
\end{equation}
onde \(U_{k1}\) e \(U_{k2}\), para \(k=1,2,\cdots,q\) são variáveis aleatórias de média zero não correlacionadas
com variâncias \(\sigma^2_k\). Prove que a função de autocovariância do processo é
\begin{equation}
\gamma_{_X}(h)=\sum_{k=1}^q \sigma^2_k \cos\big( 2\pi\omega h\big)\cdot
\end{equation}
Uma série temporal foi gerada desenhando primeiro a série de ruído branco \(W_t\) de uma distribuição normal com
média zero e variância um. A série observada \(X_t\) foi gerada a partir de
\begin{equation*}
X_t \, = \, W_t-\theta W_{t-1}, \qquad t=0,\pm 1,\pm 2, \cdots,
\end{equation*}
onde \(\theta\) é o parâmetro.
(a) Derive as esperanças e as funções de autocovariância para as séries \(X_t\) e \(W_t\). As
séries \(X_t\) e \(W_t\) são estacionárias? Dê suas razões.
(b) Forneça uma fórmula para o espectro de potência de \(W_t\), expresso em termos de \(\theta\) e \(\omega\).
Um modelo autoregressivo de primeira ordem é gerado a partir da série de ruído branco \(W_t\) usando as equações geradoras
\begin{equation*}
X_t \, = \, \phi X_{t-1}+W_t,
\end{equation*}
onde \(\phi\), para \(|\phi|<1\) é o parâmetro e \(W_t\) são variáveis aletórias independentes de média zero e
variância \(\sigma_{_W}^2\).
(a) Mostre que o espectro de potência de \(X_t\) é dado por
\begin{equation*}
f_{_X}(\omega) \, = \, \dfrac{\sigma_{_W}^2}{1+\phi^2-2\phi \cos(2\pi \omega)}\cdot
\end{equation*}
(b) Verifique se a função de autocovariância do processo é
\begin{equation*}
\gamma_{_X}(h) \, = \, \dfrac{\sigma_{_W}^2 \phi^{|h|}}{1-\phi^2},
\end{equation*}
\(h=0,\pm 1,\pm 2, \cdots\), mostrando que a transformada inversa de \(\gamma_{_X}(h)\) é o espectro derivado no item (a).
Nas aplicações, frequentemente observaremos séries contendo um sinal que foi atrasado por algum tempo \(D\) desconhecido, ou seja,
\begin{equation*}
X_t \, = \, S_t + A S_{t-D} + \eta_t,
\end{equation*}
onde \(S_t\) e \(\eta_t\) são estacionários e independentes com médias zero e densidades espectrais \(f_{_S}(\omega)\) e \(f_{_\eta}(\omega)\),
respectivamente. Observe que o sinal atrasado é multiplicado por alguma constante desconhecida \(A\). Mostre que
\begin{equation*}
f_{_X}(\omega) \, = \, \Big(1+A^2+2A\cos(2\pi \, \omega D ) \Big)f_{_S}(\omega)+f_{_\eta}(\omega)\cdot
\end{equation*}
Suponha que \(X_t\) e \(Y_t\) sejam séries temporais de média zero estacionárias com \(X_t\) independente de \(Y_s\), para todos os
\(s\) e \(t\). Considere a série dos produtos
\begin{equation*}
Z_t \, = \, X_t\times Y_t\cdot
\end{equation*}
Prove que a densidade espectral de \(Z_t\) pode ser escrita como
\begin{equation*}
f_{_Z}(\omega) \, = \, \int_{-\frac{1}{2}}^{\frac{1}{2}} f_{_X}(\omega-\nu)f_{_Y}(\nu) \mbox{d}\nu\cdot
\end{equation*}
A Figura IV.22 mostra o número de manchas solares suavizadas bi-ano (média móvel de 12 meses) de junho de 1749 a dezembro de 1978 com \(n = 459\)
pontos que foram obtidos duas vezes por ano; os dados estão contidos em sunspotz. Com o Exemplo IV.13 como guia, execute uma análise
de periodograma identificando os períodos predominantes e obtendo intervalos de confiança para os períodos identificados. Interprete suas descobertas.
Figura IV.22: Números suavizados de manchas solares, média móvel de 12 meses, (sunspotz) amostradas duas vezes por ano.
Os níveis de concentração de sal que se sabe ocorreram ao longo das linhas, correspondendo aos níveis de temperatura
média para os dados científicos do solo considerados na Figura I.18 e na Figura I.19, estão em salt e saltemp.
Trace as séries e, em seguida, identifique as frequências dominantes realizando análises espectrais separadas nas duas séries. Inclua intervalos
de confiança para as frequências dominantes e interprete suas descobertas.
Considere a série observada \(X_t\) ser composta de um sinal periódico e ruído, podendo ser escrita como
\begin{equation*}
X_t \, = \, \beta_1 \cos(2\pi \, \omega_k t)+\beta_2 \sin(2\pi \, \omega_k t)+W_t,
\end{equation*}
onde \(W_t\) é um processo de ruído branco com variância \(\sigma_{_W}^2\). Suponha que consideremos estimar \(\beta_1\), \(\beta_2\) e \(\sigma_{_W}^2\)
por mínimos quadrados ou equivalentemente, por máxima verossimilhança se \(W_t\) for assumido como Gaussiano.
(a) Prove, para \(\omega_k\) fixo, o erro quadrático mínimo é atingido por
\begin{equation*}
\begin{pmatrix} \widehat{\beta}_1 \\ \widehat{\beta}_2 \end{pmatrix} \, = \, \dfrac{2}{\sqrt{n}}\begin{pmatrix} d_c(\omega_k) \\ d_s(\omega_k) \end{pmatrix},
\end{equation*}
onde as transformadas cosseno e seno na Definição IV.3 aparecem no lado direito.
(b) Prove que a soma dos quadrados dos erros pode ser escrita como
\begin{equation*}
SSE \, = \, \sum_{t=1}^n x_t^2 -2I_X(\omega_k),
\end{equation*}
de modo que o valor de \(\omega_k\) que minimiza o erro quadrático é o mesmo que o valor que maximiza o estimador do periodograma
\(I(\omega_j) = \big| d(\omega_j)\big|^2\).
(c) Sob a suposição Gaussiana e com \(\omega_k\) fixo, mostre que o teste \(F\) de nenhuma regressão leva
a uma estatística \(F\) que é uma função monótona de \(I_X(\omega_k)\).
Prove a propriedade de convolução da tranformada discreta de Fourier, ou seja
\begin{equation*}
\sum_{s=1}^n a_s X_{t-s} \, = \, \sum_{k=0}^{n-1} d_A(\omega_k)d_X(\omega_k)\exp( 2\pi \, \omega_k t),
\end{equation*}
para \(t = 1,2,\cdots,n\), onde \(d_A(\omega_k)\) e \(d_X(\omega_k)\) são as transformadas discretas de Fourier de \(a_t\) e \(X_t\), respectivamente e
assumimos que \(X_t = X_{t + n}\) é periódica.
Analise os dados do preço do frango (chicken) usando um procedimento de estimação espectral não paramétrica.
Além do ciclo anual óbvio descoberto no Exemplo II.5, que outros ciclos interessantes são revelados?
Repita o Problema IV.3.1 usando um procedimento de estimação espectral não paramétrica. Além de discutir suas descobertas
em detalhes, comente sobre sua escolha de uma estimação espectral com relação a suavização e redução.
Repita o Problema IV.3.2 usando um procedimento de estimação espectral não paramétrica. Além de discutir suas descobertas
em detalhes, comente sobre sua escolha de uma estimação espectral com relação a suavização e redução.
Análise Cepstral. O comportamento periódico de uma série temporal induzida por ecos também pode ser observado
no espectro da série; este fato pode ser visto a partir dos resultados declarados no Exercício IV.2.3. Usando a notação desse problema,
suponha que observamos
\begin{equation}
X_t \, = \, S_t + A S_{t-D} + \eta_t,
\end{equation}
o que implica que os espectros satisfazem
\begin{equation}
f_{_X}(\omega) \, = \, \Big(1 + A^2 + 2A\cos\big(2\pi \omega D\big)\Big)f_{_S}(\omega) + f_{\eta}(\omega)\cdot
\end{equation}
Se o ruído for insignificante, ou seja, se \(f_{\eta}(\omega)\approx 0\), então \(\log\big(f_{_X}(\omega)\big)\) é aproximadamente a soma
de um componente periódico,
\begin{equation}
\log\Big(1 + A^2 + 2A\cos\big(2\pi \omega D\big)\Big)
\end{equation}
e
\begin{equation}
\log\big(f_{_S}(\omega)\big)\cdot
\end{equation}
Bogart et al. (1962) propuseram tatar o espectro do logaritmo sem tendência como uma pseudo série temporal e calcular seu espectro ou cepstrum, que deve
mostrar um pico em uma quefrência correspondente a \(1/D\). O cepstrum pode ser plotado como uma função da quefrência, a partir do qual
o atraso \(D\) pode ser estimado.
Para a série de fala apresentada no Exemplo I.3, estime o período de pico usando a análise cepstral como segue. Os dados estão na
spreech.
(a) Calcule e exiba o log-periodograma dos dados. O periodograma é periódico, conforme previsto?
(b) Realize uma análise cepstral ou espectral no periodograma registrado sem tendência e use os resultados para estimar o atraso \(D\).
Como sua resposta se compara à análise do Exemplo I.27, que foi baseado na ACF?
Utilize o Teorema IV.2 para demonstrar que
\begin{equation}
\mbox{E}(I_{_Y}(\omega_j)) \, = \, \int_{-\frac{1}{2}}^\frac{1}{2} W_n(\omega_j-\omega)f_{_X}(\omega)\mbox{d}\omega\cdot
\end{equation}
Demonstre que
\begin{equation*}
W_n(\omega) \, = \, \dfrac{\sin^2(n\pi\omega)}{n\sin^2(\pi\omega)},
\end{equation*}
com \(W_n(0)=n\), que é conhecido como kernel de Fejér ou kernel Bartlett modificado. Prove também que
\begin{equation*}
W_n(\omega) \, = \, \frac{1}{nL}\sum_{k=-m}^m \dfrac{\sin^2\big(n\pi(\omega+k/n) \big)}{\sin^2\big( \pi(\omega+k/n)\big)}\cdot
\end{equation*}
Considere as duas séries temporais
\begin{equation}
X_t \, = \, W_t - W_{t-1},
\end{equation}
e
\begin{equation}
Y_t \, = \, \frac{1}{2}\big( W_t+W_{t-1}\big),
\end{equation}
formadas a partir da série de ruído branco \(W_t\) com variância \(\sigma^2_{_W} = 1\).
(a) São \(X_t\) e \(Y_t\) conjuntamente estacionárias? Lembre-se de que a função de covariância cruzada
também deve ser uma função apenas da defasagem \(h\) e não pode depender do tempo.
(b) Calcule os espectros \(f_{_Y}(\omega)\) e \(f_{_X}(\omega)\) e comente sobre a diferença entre os dois resultados.
(c) Suponha que o estimador espectral amostral \(\overline{f}_{_Y}(0.10)\) seja calculado usando \(L = 3\). Encontre \(a\) e \(b\) tais que
\begin{equation}
P\left(a\leq \overline{f}_{_Y}(0.10)\leq b \right) \, = \, 0.90\cdot
\end{equation}
Esta expressão fornece dois pontos que conterão 90% dos valores espectrais da amostra. Coloque 5% da
área em cada cauda.
Os dados no arquivo climhyd contém 454 meses de valores medidos para as variáveis climáticas: temperatura do ar (Temp),
ponto de orvalho (DewPt), cobertura de nuvens (CldCvr), velocidade do vento (WndSpd), precipitação (Precip) e influxo (Inflow), no Lago Shasta;
os dados são exibidos na Figura VII.3. Gostaríamos de examinar as possíveis relações entre os fatores climáticos
e o influxo para o Lago Shasta.
(a) Ajuste um modelo \(ARIMA(0,0,0)\times (0,1,1)_{12}\) para (i) a precipitação transformada \(P_t = \sqrt{\mbox{Precip}}\) e
(ii) influxo transformado \(I_t = \ln(\mbox{Inflow})\).
(b) Calcule as coerências quadradas entre todas as variáveis meteorológicas e o influxo transformado e argumente que o determinante
mais forte da série de influxo é a precipitação (transformada). Dica: se \(x\) contiver várias séries
temporais, a maneira mais fácil de exibir todas as coerências quadradas é graficar as coerências suprimindo os intervalos de
confiança, por exemplo,
\begin{equation}
\mbox{mvspec(x, spans=c(7,7), taper=.5, plot.type="coh", ci=-1)}\cdot
\end{equation}
(c) Ajuste um modelo de regressão defasada da forma
\begin{equation}
I_t = \beta_0+\sum_{j=0}^\infty \beta_j P_{t-j}+\omega_t,
\end{equation}
usando limiarização e depois comentar a capacidade preditiva da precipitação para o influxo.
Freqüentemente, as periodicidades nas séries de manchas solares são investigadas ajustando-se um espectro autorregressivo de ordem suficientemente
alta. A periodicidade principal costuma ser em torno de 11 anos. Ajuste um estimador espectral autoregressivo aos dados de manchas solares usando um método de
seleção de modelos de sua escolha. Compare o resultado com um estimador espectral não paramétrico convencional encontrado no Exercício 1,
Seção IV.3.
Analise os dados do preço do frango (chicken) usando um procedimento de estimação espectral paramétrica. Compare
os resultados com os do Exercício 1, Seção IV.4.
Ajuste um estimador espectral autorregressivo à série de recrutamento e compare-o com os resultados do Exemplo IV.16.
Suponha que uma série temporal amostrada com \(n = 256\) pontos esteja disponível seguindo o modelo autorregressivo de primeira ordem. Além
disso, suponha que o espectro amostral calculado com \(L = 3\) produza o valor estimado \(\overline{f}_{_X}(1/8) = 2.25\). Este valor amostral é consistente
com \(\sigma_{_W}^2 = 1\) e \(\phi =0.5\)? Repita usando \(L = 11\) se apenas obtivermos o mesmo valor da amostra.
Suponha que desejamos testar a hipótese de ruído sozinho \(H_0 \, : \, X_t = \eta_t\) contra a hipótese de sinal mais ruído
\(H_1 \, : \, X_t = S_t + \eta_t\), onde \(S_t\) e \(\eta_t\) são processos estacionários de média zero não correlacionados com espectros
\(f_{_S}(\omega)\) e \(f_{_\eta}(\omega)\). Suponha que você queira o teste em uma banda de \(L = 2m + 1\) frequências da forma \(\omega_{j:n} + k/n\);
para \(k = 0,\pm 1,\pm 2,\cdots,\pm m\) perto de alguma frequência fixa \(\omega\). Suponha que os espectros de sinal e ruído sejam aproximadamente
constantes ao longo do intervalo.
(a) Prove que a estatística de teste baseada na verossimilhança aproximada para testar \(H_0\) contra \(H_1\) é proporcional a
\begin{equation}
T \, = \, \sum_k |d_X(w_{j:n}+k/n)|^2\left( \dfrac{1}{f_{_\eta}(\omega)} -\dfrac{1}{f_{_S}(\omega)+f_{_\eta}(\omega)}\right)\cdot
\end{equation}
(b) Encontre as distribuições aproximadas de \(T\) sob \(H_0\) e \(H_1\).
(c) Defina as probabilidades de falso alarme e detecção de sinal como \(P_F = P(T> K \, | \, H_0)\) e \(P_d = P(T> k \, | \, H_1)\), respectivamente.
Expresse essas probabilidades em termos da razão sinal-ruído \(f_{_S}(\omega)/f_{_\eta}(\omega)\) e integrais qui-quadradas apropriadas.
Analise a coerência entre os dados de temperatura e sal discutidos no Exercício 2 da Seção IV.3. Discuta suas descobertas.
Considere dois processos:
\begin{equation*}
X_t \, = \, W_t \qquad \mbox{ e } \qquad Y_t \, = \, \phi X_{t-D}+\nu_t,
\end{equation*}
onde \(W_t\) e \(\nu_t\) são processos de ruído branco independentes com variância comum \(\sigma^2\), \(\phi\) é uma constante e
\(D\) é um atraso inteiro fixo.
(a) Calcule a coerência entre \(X_t\) e \(Y_t\).
(b) Simule \(n = 1024\) observações normais de \(X_t\) e \(Y_t\) para \(\phi =0.9\), \(\sigma^2 = 1\) e \(D = 0\). Em seguida,
estime e mostre a coerência entre as séries simuladas para os seguintes valores de \(L\) e comente:
(i) \(L=1\), (ii) \(L=3\), (iii) \(L=41\) e (iv) \(L=101\).
Considere o processo
\begin{equation*}
X_t \, = \, W_t \qquad \mbox{ e } \qquad Y_t \, = \, \phi X_{t-D}+V_t
\end{equation*}
onde \(W_t\) e \(V_t\) são processos de ruído branco independentes com variância comum \(\sigma^2\), \(\phi\) é uma
constante e \(D\) é um atraso inteiro fixo.
(a) Calcule a fase entre \(X_t\) e \(Y_t\).
(b) Simule \(n=1024\) observações de \(X_t\) e \(Y_t\) para \(\phi=0.9\), \(\sigma^2=1\) e \(D=1\). Em seguida,
estime e mostre a fase entre as séries simuladas para os seguintes valores de \(L\) e comente:
(i) \(L=1\), (ii) \(L=3\), (iii) \(L=41\) e (iv) \(L=101\).
Considere os registros da série temporal bivariada contendo a produção mensal dos EUA (prodn) conforme
medido pelo Índice de Produção do Federal Reserve Board e a série mensal de desemprego (unemp).
(a) Calcule o espectro e o espectro do logaritm para cada série e identifique picos estatisticamente significativos. Explique
o que pode estar gerando os picos. Calcule a coerência e explique o que significa quando uma alta coerência é
observada em uma determinada frequência.
(b) Qual seria o efeito da aplicação do filtro
\begin{equation*}
U_t \, = \, X_t - X_{t-1} \qquad \mbox{seguido de} \qquad V_t \, = \, U_t-U_{t-12}
\end{equation*}
para a série dada acima? Trace as respostas de frequência previstas do filtro de diferença simples e da
diferença sazonal da primeira diferença.
(c) Aplique os filtros sucessivamente a uma das duas séries e mostre a saída. Examine a saída depois de fazer
uma primeira diferença e comente se a estacionariedade é uma suposição razoável. Por que ou por
que não? Trace depois de tirar a diferença sazonal da primeira diferença. O que pode ser notado sobre a saída
que é consistente com o que voê previu a partir da resposta de frequência? Verifique calculando o espectro da
saída após a filtragem.
Determine o espectro de potência teórico da série formada combinando a série de ruído branco \(W_t\) para formar
\begin{equation*}
Y_t \, = \, W_{t-2}+4 W_{t-1}+6 W_t + 4 W_{t+1} + W_{t+2}\cdot
\end{equation*}
Determine quais frequências estão presentes traçando o espectro de potência.
Seja \(X_t=\cos\big( 2\pi\omega t\big)\) e considere a saída
\begin{equation*}
Y_t \, = \, \sum_{k=-\infty}^\infty a_k X_{t-k},
\end{equation*}
onde \(\sum_k |a_k|<\infty\). Prove que
\begin{equation*}
Y_t \, = \, |A(\omega)|\cos\big( 2\pi \omega t+\phi(\omega)\big),
\end{equation*}
onde \(|A(\omega)|\) e \(\phi(\omega)\) são a amplitude e a fase do filtro, respectivamente. Interprete o resultado em termos da relação
entre a série de entrada \(X_t\) e a série de saída \(Y_t\).
Suponha que \(X_t\) seja uma série estacionária e aplicamos duas operações de filtragem em sucessão, digamos,
\begin{equation*}
Y_t \, = \, \sum_r a_r X_{t-r} \qquad \mbox{ depois } \qquad Z_t \, = \, \sum_s b_s Y_{t-s}\cdot
\end{equation*}
(a) Mostre que o espectro da saída é
\begin{equation*}
f_{_Z}(\omega) \, = \, |A(\omega)|^2 |B(\omega)|^2 f_{_X}(\omega),
\end{equation*}
onde \(A(\omega)\) e \(B(\omega)\) são as transformadas de Fourier das sequências de filtro \(a_t\) e \(b_t\), respectivamente.
(b) Qual seria o efeito da aplicação do filtro
\begin{equation*}
U_t \, = \, X_t-X_{t-1}, \qquad \mbox{seguido de} \qquad V_t \, = \, U_t-U_{t-12},
\end{equation*}
para uma série temporal?
(c) Trace as respostas de frequência previstas do filtro de diferença simples e da diferença sazonal da primeira
diferença. Filtros como esses são chamados de filtros de ajuste sazonal em economia porque tendem a atenuar frequências
em múltiplos dos períodos mensais. O filtro de diferença tende a atenuar tendências de baixa frequência.
Suponha que recebamos uma série de média zero estacionária \(X_t\) com espectro \(f_{_X}(\omega)\) e, em seguida,
construamos a série derivada
\begin{equation*}
Y_t \, = \, aY_{t-1}+X_t, \qquad t=\pm 1,\pm 2,\cdots \cdot
\end{equation*}
(a) Mostre como o espectro \(f_{_Y}(\omega)\) teórico está relacionado com \(f_{_X}(\omega)\).
(b) Trace a função que multiplica \(f_{_X}(\omega)\) na parte (a) para \(a =0.1\) e para \(a =0.8\). Este filtro
é denominado filtro recursivo.
Considere o problema de aproximar a saída do filtro
\begin{equation*}
Y_t \, = \, \sum_{k=-\infty}^\infty a_k X_{t-k}, \qquad \sum_{-\infty}^\infty |a_k|<\infty,
\end{equation*}
por
\begin{equation*}
Y_t^M \, = \, \sum_{|k| < M/2} a_k^M X_{t-k},
\end{equation*}
para \(t=M/2-1,M/2,\cdots,n-M/2\), onde \(X_t\) está disponível para \(t=1,\cdots,n\) e
\begin{equation*}
a_t^M \, = \, \dfrac{1}{M}\sum_{k=0}^{M-1} A(\omega_k)\exp\big(2\pi \, i\omega_k t \big),
\end{equation*}
com \(\omega_k=k/M\). Prove que
\begin{equation*}
\mbox{E}\big( (Y_t-Y_t^M)^2 \big) \, \leq \, 4\gamma_{_X}(0)\left( \sum_{|k| > M/2} |a_k|\right)^2\cdot
\end{equation*}
Prove que a coerência quadrada \(\rho_{_{Y,X}}^2(\omega)=1\), para todo \(\omega\), quando
\begin{equation*}
Y_t \, = \, \sum_{r=-\infty}^{\infty} a_r X_{t-r},
\end{equation*}
isto é, quando \(X_t\) e \(Y_t\) podem ser relacionados exatamente por um filtro linear.
O conjunto de dados climhyd contém 454 meses de valores medidos para seis variáveis climáticas:
(i) Temp: temperatura do ar,
(ii) DewPt: ponto de orvalho,
(iii) CldCvr: cobertura de nuvens,
(iv) WndSpd: velocidade do vento,
(v) Precip: precipitação,
(vi) Influxo: influxo,
no Lago Shasta na Califórnia; os dados são exibidos na Figura VII.3.
Gostaríamos de examinar as possíveis relações entre os fatores climáticos e entre os fatores climáticos
e o influxo para o Lago Shasta.
(a) Primeiro transforme as séries de influxo e precipitação da seguinte forma: \(I_t = \log(i_t)\), onde \(i_t\)
é o influxo e \(P_t =\sqrt{p_t}\), onde \(p_t\) é a precipitação. Em seguida, calcule as coerências quadradas
entre todas as variáveis climáticas e o influxo transformado e argumente que o determinante mais forte da série de
influxo é a precipitação (transformada).
Dica: se \(x\) contiver várias séries temporais, a maneira mais fácil de exibir todas as coerências
quadradas é plotar as coerências suprimindo os intervalos de confiança, por exemplo,
(b) Ajustar um modelo de regressão defasada da forma
\begin{equation*}
I_t \, = \, \beta_0 + \sum_{j=0}^\infty \beta_j P_{t-j}+W_t,
\end{equation*}
usando limiares e, em seguida, comente sobre a capacidade preditiva da precipitação para o influxo.
Considere o modelo de sinal mais ruído
\begin{equation*}
Y_t \, = \, \sum_{r=-\infty}^\infty \beta_r X_{t-r} + V_t,
\end{equation*}
onde as séies de sinal e ruído, \(X_t\) e \(V_t\) são estacionárias com espectros \(f_{_X}(\omega)\) e \(f_{_V}(\omega)\), respectivamente.
Assumindo que \(X_t\) e \(V_t\) sejam independentes um do outro para todo \(t\), verifique que
\begin{equation}
f_{_{X,Y}}(\omega) \, = \, B^*(\omega)f_{_{X,X}}(\omega)
\end{equation}
e
\begin{equation}
f_{_{Y,Y}}(\omega) \, = \, |B(\omega)|^2f_{_{X,X}}(\omega)+f_{_{V,V}}(\omega)\cdot
\end{equation}
Considere o modelo
\begin{equation*}
Y_t \, = \, X_{t}+V_t,
\end{equation*}
onde
\begin{equation}
X_t \, = \, \phi X_{t-1}+W_t,
\end{equation}
tal que \(V_t\) é ruído branco gaussiano e independente de \(X_t\) com \(\mbox{Var}(V_t) = \sigma^2_{_V}\) e \(W_t\) é ruíído branco
gaussiano e independente de \(V_t\), com \(\mbox{Var}(W_t) = \sigma^2_{_W}\) e \(|\phi|<1\) e \(\mbox{E}(X_0)=0\). Prove que o espectro da série
observada \(Y_t\) é
\begin{equation}
f_{_Y}(\omega) \, = \, \sigma^2 \dfrac{|1-\theta e^{-2\pi \, i \, \omega}|^2}{|1-\phi e^{-2\pi \, i \, \omega}|^2},
\end{equation}
onde
\begin{equation}
\theta \, = \, \dfrac{c\pm \sqrt{c^2-4}}{2}, \qquad \sigma^2 \, = \, \dfrac{\sigma^2_{_V}\phi}{\theta}
\end{equation}
e
\begin{equation}
c \, = \, \dfrac{\sigma^2_{_W}+\sigma^2_{_V}(1+\phi^2)}{\sigma^2_{_V}\phi}\cdot
\end{equation}
Considere o mesmo modelo do problema anterior.
(a) Prove o estimador suavizado ideal da forma
\begin{equation}
\widehat{X}_t \, = \, \sum_{s=-\infty}^\infty a_s Y_{t-s}
\end{equation}
tem
\begin{equation}
a_s \, = \, \dfrac{\sigma^2_{_W}\theta^{|s|}}{\sigma^2(1-\theta^2)}\cdot
\end{equation}
(b) Mostre que o erro quadrético médio é dado por
\begin{equation*}
\mbox{E}\Big( \big(X_t-\widehat{X}_t\big)^2\Big) \, = \, \dfrac{\sigma^2_{_W}\sigma^2_{_V}}{\sigma^2(1-\theta^2)}\cdot
\end{equation*}
(c) Compare o erro quadrático médio do estimador na parte (b) com aquele do estimador finito ótimo da forma
\begin{equation}
\widehat{X}_t \, = \, a_1 Y_{t-1}+a_2 Y_{t-2},
\end{equation}
quando \(\sigma^2_{_V}=0.053\), \(\sigma^2_{_W}=0.172\) e \(\phi_1=0.9\).
Considere o filtro linear bidimensional \(\displaystyle Y_{s_1,s_2} = \sum_{u_1}\sum_{u_2} a_{u_1,u_2}X_{s_1-u_1,s_2-u_2}\).
(a) Expresse a função de autocovariância bidimensional \(\gamma_{_Y}(h_1,h_2)\), em termos de uma soma infinita
envolvendo a função de autocovariância de \(X_s\) e os coeficientes do filtro \(a_{s_1,s_2}\).
(b) Use a expressão derivada em (a), combinada com as expressões de \(\gamma_{_X}(h_1,h_2)\) e \(A(\omega_1,\omega_2)\) para derivar
o espectro da saída filtrado \(f_{_Y}(\omega_1,\omega_2)\).