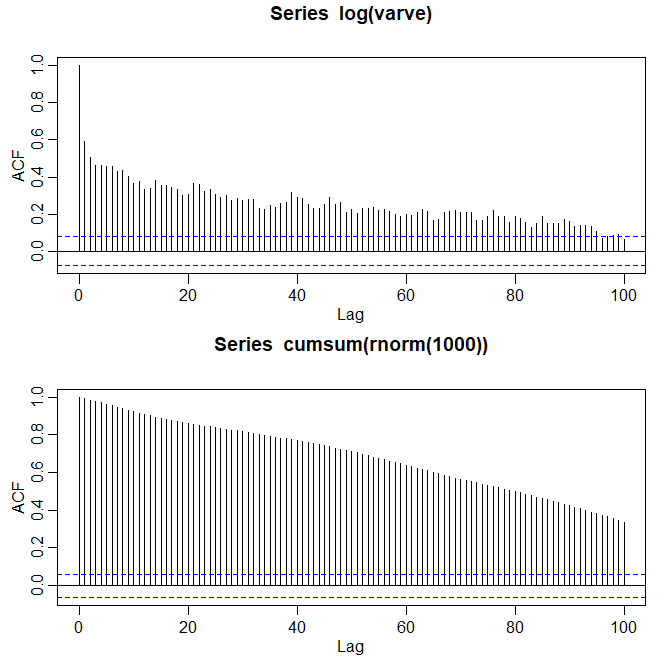
Figura V.1: Acima, gráfico da função de auocorrelação amostral do logaritmo da série de variações glaciais (varve). Abaixo mostramos a função de auocorrelação amostral de uma caminhada aleatória para comparar.
Análise de Séries Temporais
Apresentamos aqui um material que pode ser considerado especial ou avançado no domínio do tempo. O Capítulo VI é dedicado a um dos tópicos de domínio de tempo mais úteis e interessantes, modelos de espaço de estados. Consequentemente, não abordamos agora modelos de espaço de estado ou tópicos relacionados, dos quais existem muitos. O conteúdo aqui é de tópicos independentes que podem ser lidos em qualquer ordem. A maioria das seções depende de um conhecimento básico dos modelos ARMA, previsão e estimação, que é o material abordado no Capítulo III. Algumas seções, por exemplo, a seção sobre modelos de memória longa, requerem algum conhecimento de análise espectral e tópicos relacionados abordados no Capítulo IV. Além da memória longa, discutimos o teste de raiz unitária, modelos GARCH, modelos de limiar, funções de regressão com atraso ou de transferência e tópicos selecionados em modelos ARMAX multivariados.
O processo \(ARMA(p,q)\) convencional é freqüentemente chamado de processo de memória curta porque os coeficientes na representação \begin{equation} X_t \, = \, \sum_{j=0}^\infty \psi_j W_{t-j}, \end{equation} obtidos resolvendo \begin{equation} \phi(z)\psi(z) \, = \, \theta(z), \end{equation} são dominados por decaimento exponencial. Conforme apontado na Seção III.2 e na Seção III.3, este resultado implica que o ACF do processo de memória curta satisfaz \(\rho(h)\to 0\) exponencialmente rápido quando \(h\to \infty\). Quando o ACF amostral de uma série temporal decai lentamente, os conselhos dados no Capítulo III tem sido a diferenciação da série até parecer estacionária. Seguindo esse conselho com a série de variações glaciais apresentada pela primeira vez no Exemplo III.33, a primeira diferença dos logaritmos dos dados é representada como uma média móvel de primeira ordem. No Exemplo III.41, uma análise mais aprofundada dos resíduos leva ao ajuste de um modelo \(ARIMA(1,1,1)\), \begin{equation} \nabla X_t \, = \, \phi \nabla X_{t-1}+W_t+\theta W_{t-1}, \end{equation} onde entendemos \(X_t\) é a série transformada por logaritmo. Em particular, as estimativas dos parâmetros e os erros padrão, foram \(\widehat{\phi} = 0.23_{(0.05)}\), \(\widehat{\theta} = -0.89_{(0.03)}\) e \(\widehat{\sigma}_{_W}^2 = 0.23\).
O uso da primeira diferença \(\nabla X_t=(1-B)X_t\), no entanto, às vezes pode ser uma modificação muito severa no sentido de que o modelo não-estacionário pode representar uma superdiferença do processo original. Séries temporais de memória longa ou persistente foram consideradas em Hosking (1981) e Granger and Joyeux (1980) como compromissos intermediários entre os modelos do tipo \(ARMA\) de memória curta e os processos não estacionários totalmente integrados na classe Box–Jenkins. A maneira mais fácil de gerar uma série de memória longa é pensar em usar o operador de diferença \((1-B)^d\) para valores fracionários de \(d\), por exemplo, \(0 < d < 0.5\), para que uma série básica de memória longa seja gerada como \begin{equation} (1-B)^d X_t \, = \, W_t, \end{equation} onde \(W_t\) ainda indica ruído branco com variância \(\sigma_{_W}^2\). A série fracionariamente diferenciada acima, para \(|d| < 0.5\), é freqüentemente chamada de ruído fracionário, exceto quando \(d\) é zero. Agora, \(d\) se torna um parâmetro a ser estimado juntamente com \(\sigma_{_W}^2\). Diferenciar o processo original, como na abordagem de Box-Jenkins, pode ser considerado simplesmente atribuindo um valor de \(d = 1\). Essa idéia foi estendida à classe de componentes fracionados integrados ARMA ou ARFIMA, em que \(-0.5 < d < 0.5\); quando \(d\) é negativo, o termo antipersistente é usado. Processos de memória longa ocorrem na hidrologia (ver Hurst, 1951, e McLeod and Hipel, 1978) e em séries ambientais, como os vários dados que analisamos anteriormente, para citar alguns exemplos. Os dados de séries temporais de memória longa tendem a exibir autocorrelações amostrais que não são necessariamente grandes, como no caso de \(d = 1\), mas persistem por um longo tempo. A figura abaixo mostra o ACF amostral, para um retardo ou lag de 100, da série de variações transformada por logaritmo, que exibe o comportamento clássico de memória longa:
Figura V.1: Acima, gráfico da função de auocorrelação amostral do logaritmo da série de variações glaciais (varve). Abaixo mostramos a função de auocorrelação amostral de uma caminhada aleatória para comparar.
Esta figura pode ser contrastada com o ACF da série PIB original mostrada na figura do Exemplo III.39, que também é persistente e decai linearmente, mas os valores do ACF são grandes.
Para investigar suas propriedades, podemos usar a expansão binomial \((d>-1)\), e escrever \begin{equation} W_t \, = \, (1-B)^d X_t \, = \, \displaystyle \sum_{j=0}^\infty \pi_j B^j X_t \, = \, \sum_{j=0}^\infty \pi_j X_{t-j}, \end{equation} onde \begin{equation} \pi_j \, = \, \frac{\Gamma(j-d)}{\Gamma(j+1)\Gamma(-d)}, \end{equation} com \(\Gamma(x+1)=x\Gamma(x)\) sendo a função gama. Similarmente \((d< 1)\), podemos escrever \begin{equation} X_t \, = \, (1-B)^{-d} W_t \, = \, \displaystyle \sum_{j=0}^\infty \psi_j B^j W_t \, = \, \sum_{j=0}^\infty \psi_j W_{t-j}, \end{equation} onde \begin{equation} \psi_j \, = \, \frac{\Gamma(j+d)}{\Gamma(j+1)\Gamma(d)}\cdot \end{equation}
Quando \(|d|< 0.5\) os processos \(W_t\) e \(X_t\) anteriores são processos estacionários bem definidos, veja Brockwell and Davis, 1991, para detalhes. No caso de diferenciação fracionária, no entanto, os coeficientes satisfazem \(\sum_j \pi_j^2 < \infty\) e \(\sum_j \psi_j^2 <\infty\), em oposição à soma absoluta dos coeficientes nos processos ARMA.
Após algumas manipulações não triviais, pode-se mostrar que o ACF de \(X_t\) é \begin{equation} \rho(h) \, = \, \frac{\Gamma(h+d)\Gamma(1-d)}{\Gamma(h-d+1)\Gamma(d)} \approx h^{2d-1}, \end{equation} para \(h\) grande. A partir disso, vemos que para \(0< d < 0.5\) \begin{equation} \sum_{h=-\infty}^\infty |\rho(h)| \, = \, \infty, \end{equation} e, portanto, o termo memória longa.
Para examinar uma série como a série de variações para um possível padrão de memória longa, é conveniente procurar maneiras de estimar \(d\). Observandoa a expressão dos \(\pi_j\) acima, podemos derivar as recursões \begin{equation} \pi_{j+1}(d) \, = \, \frac{(j-d)\pi_j(d)}{j+1}, \end{equation} para \(j = 0,1,\cdots\), com \(\pi_0(d)=1\). Maximizar a verossimilhança conjunta dos erros sob normalidade, digamos, \(W_t(d)\), envolverá a minimização da soma dos erros ao quadrado \begin{equation} Q(d) \, = \, \displaystyle \sum_t W_t^2(d)\cdot \end{equation}
O método de Gauss-Newton usual, descrito na Seção III.5, leva à expansão: \begin{equation} W_t(d) \, = \, W_t(d_0) + W_t'(d_0)(d-d_0), \end{equation} onde \begin{equation} W_t'(d_0) \, = \, \displaystyle \left.\dfrac{\partial W_t}{\partial d} \right|_{d=d_0} \end{equation} e \(d_0\) é uma estimativa inicial ou palpite no valor de \(d\). A configuração da regressão usual leva a \begin{equation} d \, = \, d_0 - \dfrac{\displaystyle \sum_t W_t'(d_0)W_t(d_0)}{\displaystyle \sum_t W_t'(d_0)^2}\cdot \end{equation}
As derivadas são computadas recursivamente pela diferenciação de \(\pi_{j+1}(d)\) sucessivamente em relação a \(d\): \begin{equation} \pi_{j+1}'(d) \, = \, \dfrac{(j-d)\pi_j'(d)-\pi_j(d)}{j+1}, \end{equation} onde \(\pi_0'(d)=0\). Os erros são calculados a partir de uma aproximação a \(W_t=(1-B)^d X_t\), a saber \begin{equation} W_t(d) \, = \, \displaystyle\sum_{j=0}^t \pi_j(d)X_{j-t}\cdot \end{equation}
É aconselhável omitir vários termos iniciais do cálculo e iniciar a somas \(\sum_t W_t'(d_0)W_t(d_0)\) e \(\sum_t W_t'(d_0)^2\) em algum valor razoavelmente grande de \(t\) para ter uma aproximação razoável.
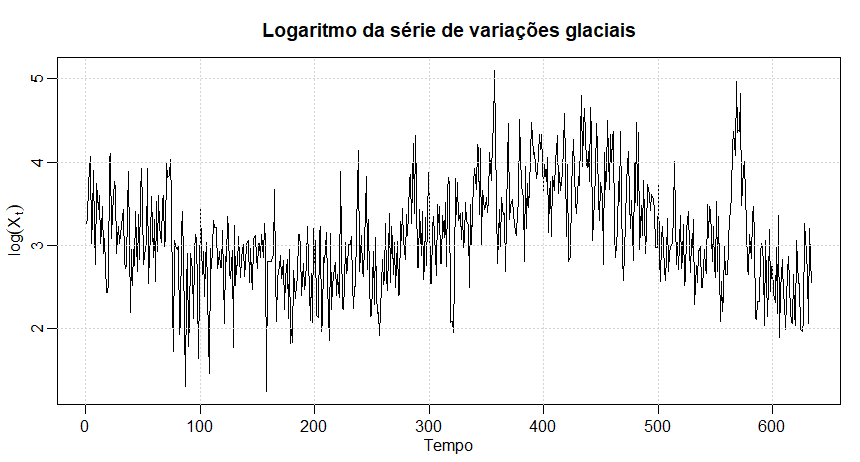
Consideramos analisar a série de variações glaciais discutida em vários exemplos e apresentada pela primeira vez no Exemplo II.7. A figura naquele exemplo mostra as séries originais e transformadas em logaritmo, que denotamos por \(X_t\). No Exemplo III.41, observamos que \(X_t\) poderia ser modelado como um processo \(ARIMA(1,1,1)\). Ajustamos o modelo diferenciado fracionariamente à série ajustada pela média, \(X_t - \overline{X}\). A aplicação do procedimento iterativo de Gauss-Newton descrito anteriormente, iniciando com \(d =0.1\) e omitindo os primeiros 30 pontos no cálculo, leva a um valor final de \(d =0.384\), o que implica o conjunto de coeficientes \(\pi_j (0.384)\), como dado na figura abaixo com \(\pi_0 (0.384) = 1\).
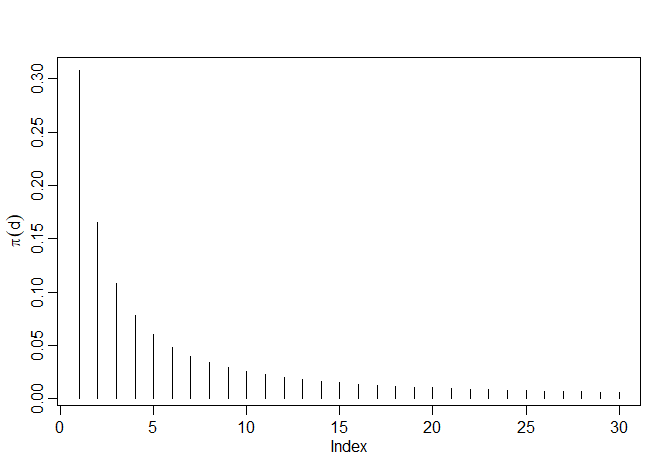
Figura V.2: Coeficientes \(\pi_j (0.384)\), \(j = 1,2,\cdots,30\) na representação \(\pi_{j+1}(d)\).
O R usa um procedimento de máxima verossimilhança truncada que foi discutido em Haslett and Raftery (1989), que é um pouco mais elaborado do que simplesmente zerar os valores iniciais. O valor padrão de truncamento no R é \(M = 100\). No caso padrão, a estimativa é \(\widehat{d}=0.37\) com aproximadamente o mesmo erro padrão questionável. O erro padrão é, supostamente, obtido do Hessiano, conforme descrito no Exemplo III.30. Um erro padrão mais crível é dado no Exemplo V.2.
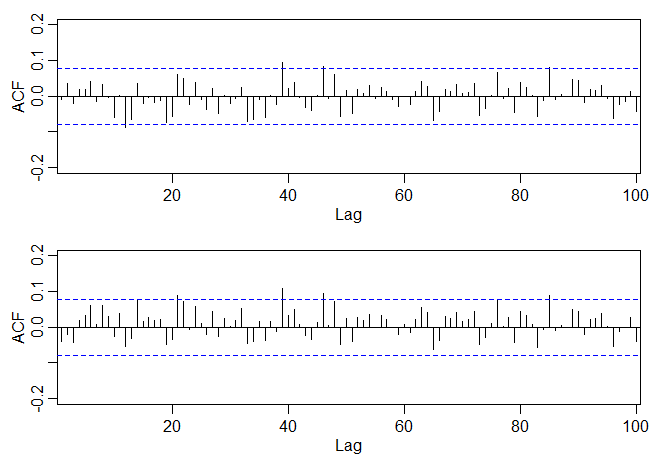
Figura V.3: Mostramos acima a função de autocorrelação amostral (ACF) dos resíduos do modelo \(ARIMA(1,1,1)\) ajustado à série de variações glaciais (varve) e abaixo, mostramos o ACF dos resíduos do ajuste do modelo de memória longa, \((1-B)^d X_t = W_t\), com \(d =0.384\).
A previsão de processos de memória longa é semelhante à previsão dos modelos \(ARIMA\). Ou seja, \(W_t=(1-B)^d X_t\) e \(\pi_{j+1}'(d) = \big((j-d)\pi_j'(d)-\pi_j(d)\big)/(j+1)\) podem ser usados para obter as previsões truncadas \begin{equation} \widetilde{X}^n_{n+m} \, = \, -\displaystyle \sum_{j=1}^n \pi_j(\widehat{d})\widetilde{X}^n_{n+m-j}, \end{equation} para \(m=1,2,\cdots\). Os limites de erro podem ser aproximados usando \begin{equation} P^n_{n+m} \, = \, \widehat{\sigma}^2_{_W} \Big( \displaystyle\sum_{j=0}^{m-1} \psi_j^2(\widehat{d})\Big) \end{equation} onde \begin{equation} \psi_j(\widehat{d}) \, = \, \dfrac{(j+\widehat{d})\psi_j(\widehat{d})}{j+1}, \end{equation} com \(\psi_0(\widehat{d})=1\).
Nenhum componente óbvio do tipo ARMA de memória curta pode ser visto na função de autocorrelação dos resíduos da série de variações glaciais fracionada e diferenciada mostrada na figura do Exemplo V.1. É natural, no entanto, que existam casos em que componentes substanciais do tipo memória curta também estarão presentes nos dados que exibem memória longa. Portanto, é natural definir o processo \(ARFIMA(p,d,q)\) geral, \(-0.5< d< 0.5\) como \begin{equation} \phi(B)\nabla^d (X_t-\mu) \, = \, \theta(B)W_t, \end{equation} onde \(\phi(B)\) e \(\theta(B)\) como dados na Parte III. Escrevendo o modelo na forma \begin{equation} \phi(B)\pi_d (B) (X_t-\mu) \, = \, \theta(B)W_t \end{equation} deixa claro como calculamos os parâmetros para o modelo mais geral.
Previsões para o processo \(ARFIMA(p,d,q)\) podem ser feitas com facilidade, notando que possamos igualar coeficientes em \begin{equation} \phi(z)\psi(z) \, = \, (1-z)^{-d}\theta(z) \end{equation} e \begin{equation} \theta(z)\pi(z) \, = \, (1-z)^d\phi(z) \end{equation} para obter as representações \begin{equation} X_t \, = \, \mu+\sum_{j=0}^\infty \phi_j W_{t-j} \qquad \mbox{e} \qquad W_t \, = \, \sum_{j=0}^\infty \pi_j (X_{t-j}-\mu)\cdot \end{equation} Podemos então proceder e obter \(\widetilde{X}^n_{n+m}\) e \(\widetilde{P}^n_{n+m}\).
Tratamentos abrangentes de modelos de séries temporais de memória longa são dados nos textos de Beran (1994), Palma (2007) e Robinson (2003) e deve-se notar que várias outras técnicas para estimar os parâmetros, especialmente o parâmetro de memória longa, pode ser desenvolvido no domínio da frequência. Nesse caso, podemos pensar nas equações como geradas por uma série autoregressiva de ordem infinita com coeficientes \(\pi_j\) dados anteriormente. Usando a mesma abordagem de antes, obtemos \begin{array}{rcl} f_X(\omega) & = & \displaystyle \dfrac{\sigma^2_{_W}}{\displaystyle \left| \sum_{k=1}^\infty \pi_k e^{-2\pi \, i \, k\omega}\right|^2} \\ & = & \displaystyle \sigma_{_W}^2 \left|1-e^{-2\pi \, i \, \omega} \right|^{-2d} \, = \, \big( 4\mbox{sen}^2(\pi\omega)\big)^{-d}\sigma^2_{_W}, \end{array} como representações equivalentes do espectro de um processo de memória longa. O longo espectro de memória se aproxima do infinito quando a frequência \(\omega\to 0\).
O principal motivo para definir a aproximação de Whittle à log-verossimilhança é propor seu uso para estimar o parâmetro \(d\) no caso de memória longa como uma alternativa ao método do domínio do tempo mencionado anteriormente. A abordagem no domínio do tempo é útil devido à sua simplicidade e erros padrão facilmente calculáveis. Pode-se também usar uma abordagem de verossimilhança exata, desenvolvendo uma forma de inovação da verossimilhança, como em Brockwell and Davis (1991).
Para a abordagem aproximada usando a verossimilhança de Whittle, consideramos usar a abordagem de Fox and Taqqu (1986) os quais mostraram que maximizar a log-verossimilhança de Whittle leva a um estimador consistente com a distribuição normal assintótica usual que seria obtida pelo tratamento da verossimilhança de Whittle como uma log-verossimilhança convencional (ver também Dahlhaus, 1989; Robinson, 1995; Hurvich et al., 1998). Infelizmente, as ordenadas do periodograma não são assintoticamente independentes (Hurvich and Beltrao, 1993), embora uma quase verossimilhança na forma da aproximação Whittle funcione bem e tenha boas propriedades assintóticas.
Para ver como isso funcionaria no caso de memória puramente longa, escrevamos o espectro de memória longa como \begin{equation} f_X(\omega_k; d,\sigma^2_{_W}) \, = \, \sigma^2_{_W} g_k^{-d}, \end{equation} onde \begin{equation} g_k \, = \, 4\mbox{sen}^2(\pi\omega_k)\cdot \end{equation}
Então, diferenciando a log-verossimilhança, digamos \begin{equation} \ln \big(L(X;d,\sigma^2_{_W})\big) \, \approx \, -m\ln (\sigma^2_{_W})+d \sum_{k=1}^m \ln (g_k) -\dfrac{1}{\sigma^2_{_W}}\sum_{k=1}^m g^d_k I(\omega_k) \end{equation} em \(m = n/2-1\) frequências e resolvendo por \(\sigma^2_{_W}\) produz \begin{equation} \sigma^2_{_W}(d) \, = \, \dfrac{1}{m}\sum_{k=1}^m g^d_k I(\omega_k) \end{equation} como o estimador aproximado do máximo da verossimilhança para o parâmetro de variância. Para estimar \(d\), podemos usar uma pesquisa em grade da log-verossimilhança perfilada \begin{equation} \ln \big( L(X;d)\big) \approx -m\ln\big(\sigma^2_{_W}(d)\big) +d\sum_{k=1}^m \ln(g_k)-m, \end{equation} no intervalo \((0;0.5)\), seguido de um procedimento de Newton–Raphson para convergência.
No Exemplo V.1, ajustamos um modelo de memória longa aos dados da variável de variações glaciais através de métodos no domínio do tempo. Ajustar o mesmo modelo usando métodos no domínio da frequência e a aproximação Whittle acima fornece \(\widehat{d}=0.380\), com um erro padrão estimado de \(0.028\). O método anterior no domínio do tempo deu \(\widehat{d}=0.384\) com \(M = 30\) e \(\widehat{d}=0.370\) com \(M = 100\). Ambas as estimativas obtidas através de métodos no domínio do tempo apresentaram um erro padrão de cerca de \(4.6\times 10^{-6}\), o que parece implausível. A estimativa da variância de erro neste caso é de \(\widehat{\sigma}_{_W}^2=0.2293\). No Exemplo V.1, poderíamos ter usado var(res.fd) como uma estimativa; nesse caso, obtemos \(0.2298097\).
O código R para executar esta análise é:Também se pode considerar ajustar um modelo autoregressivo a esses dados usando um procedimento semelhante ao usado no Exemplo IV.18. Seguindo essa abordagem, obteve-se um modelo auto-regressivo com \(p = 8\) e \(\widehat{\phi}_{1:8}=\{0.34, 0.11, 0.04, 0.09, 0.08, 0.08, 0.02, 0.09\}\), com \(\widehat{\sigma}_{_W}^2=0.23\) como a variância do erro. Os dois log-espectros são plotados na figura abaixo para \(\omega> 0\) e observamos que o espectro de memória longa acabará se tornando infinito, enquanto o espectro \(AR(8)\) é finito em \(\omega=0\).
O código R usado para esta parte do exemplo, assumindo que os valores anteriores foram mantidos, é: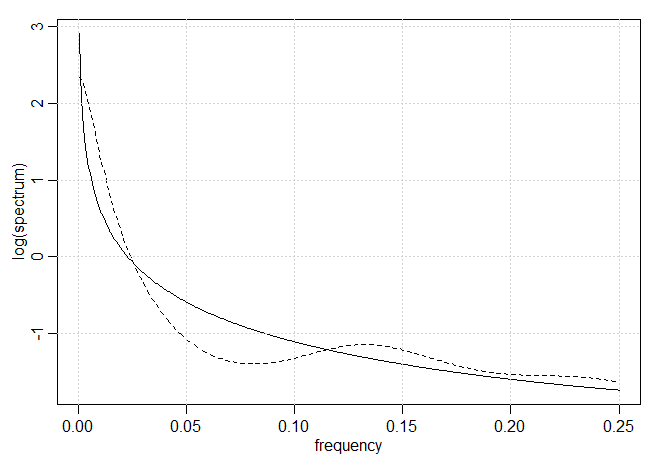
Figura V.4: Estimadores espectrais de memória longa \(d =0.380\), linha sólida, e estimadores auto-regressivos \(AR(8)\), linha tracejada, para a série varve, série das variações glaciais paleoclimáticas.
Frequentemente, as séries temporais não têm uma memória puramente longa. Uma situação comum tem o componente de memória longa multiplicado por um componente de memória curta, levando a uma versão alternativa da forma \begin{equation} f_X(\omega; d,\theta) \, = \, g_k^{-d} f_0(\omega_k;\theta), \end{equation} onde \(f_0(\omega_k;\theta)\) pode ser o espectro de um processo autorregressivo de médias móveis com vetor de parâmetros \(\theta\)) ou pode não ser especificado. Se o espectro tiver uma forma paramétrica, a verossimilhança de Whittle poderá ser usada. Entretanto, existe uma quantidade substancial de literatura semiparamétrica que desenvolve os estimadores quando o espectro subjacente \(f_0(\omega;\theta)\) é desconhecido. Uma classe de estimadores semi-paramétricos gaussianos simplesmente usa a mesma verossimilhança de Whittle avaliada em uma sub-banda de baixas frequências, digamos \(m'=\sqrt{n}\). Há alguma latitude na seleção de uma banda relativamente livre de interferências de baixa frequência devido ao componente de memória curta. Se o espectro é altamente parametrizado, pode-se estimar usando a log-verossimilhança de Whittle e estimar em conjunto os parâmetros \(d\) e \(\theta\) usando o método de Newton-Raphson. Se estivermos interessados em um estimador não paramétrico, usando o estimador espectral suavizado convencional para o periodograma, ajustado para o componente de memória longa, digamos que \(g_k^d I(\omega_k)\) pode ser uma abordagem possível.
Geweke and Porter-Hudak (1983) desenvolveram um método aproximado para estimar \(d\) com base em um modelo de regressão. Observe que podemos escrever uma equação simples para o logaritmo do espectro como \begin{equation} \ln \big(f_X(\omega_k;d) \big) \, = \, \ln \big(f_0(\omega_k;\theta) \big)-d \ln \Big( 4\mbox{sen}^2(\pi\omega_k)\Big), \end{equation} com as frequências \(\omega_k = k/n\) restritas a uma faixa \(k = 1,2,\cdots,m\) perto da frequência zero com \(m =\sqrt{n}\) como o valor recomendado. A relação acima sugere o uso de um modelo de regressão linear simples da forma, \begin{equation} \ln \big( I(\omega_k)\big) \, = \, \beta_0 -d \ln\Big(4\mbox{sen}^2(\pi\omega_k) \Big)+\epsilon_k, \end{equation} para o periodograma para estimar os parâmetros \(\sigma^2_{_W}\) e \(d\). Nesse caso, executa-se mínimos quadrados usando \(\ln \big( I(\omega_k)\big)\) como variável dependente e \(\ln\Big(4\mbox{sen}^2(\pi\omega_k) \Big)\) como variável independente para \(k = 1,2,\cdots,m\). A estimativa da inclinação resultante é então usada como uma estimativa de \(-d\). Para uma boa discussão de vários métodos alternativos para selecionar \(m\), veja Hurvich and Deo (1999).
O pacote R fracdiff também fornece esse método através do comando fdGPH(); consulte o arquivo de ajuda para obter mais informações. Aqui está um exemplo rápido usando os dados lvarve registrados:Conforme discutido na seção anterior, o uso da primeira diferença \(\nabla X_t =(1-B)X_t\) pode ser uma modificação muito severa, no sentido de que o modelo não-estacionário pode representar uma superdiferença do processo original. Por exemplo, considere um processo causal de \(AR(1)\), assumimos ao longo desta seção que o ruído é gaussiano, \begin{equation} X_t \, = \, \phi X_{t-1}+W_t\cdot \end{equation}
A aplicação de \((1-B)\) em ambos os lados mostra que a diferença, \(\nabla X_t = \phi\nabla X_{t-1}+\nabla W_t\) ou \begin{equation} Y_t \, = \, \phi Y_{t-1}+W_t-W_{t-1}, \end{equation} onde \(Y_t=\nabla X_t\), introduz problemas estranhos de correlação e invertibilidade. Significa que, enquanto \(X_t\) é um processo causal \(AR(1)\), trabalhar com o processo diferenciado \(Y_t\) será problemático porque é um \(ARMA(1,1)\) não invertível.
O teste da raiz unitária fornece uma maneira de testar se \(X_t = \phi X_{t-1}+W_t\) é uma caminhada aleatória, o caso nulo, em oposição a um processo causal, a alternativa. Ou seja, fornece um procedimento para testar \begin{equation} H_0 \, : \, \phi\, = \, 1 \qquad \mbox{contra} \qquad H_1 \, : \, |\phi|< 1\cdot \end{equation} Uma estatística de teste óbvia seria considerar \(\widehat{\phi}-1\), adequadamente normalizado, na esperança de desenvolver uma estatística de teste assintoticamente normal, onde \(\widehat{\phi}\) é um dos estimadores ideais discutidos na Parte III. Infelizmente, a teoria da Seção III.5 não funciona no caso nulo porque o processo não é estacionário. Além disso, como visto no Exemplo III.36, a estimativa próxima ao limite da estacionariedade produz distribuições amostrais altamente distorcidas e isso é uma boa indicação de que o problema será atípico.
Para examinar o comportamento de \(\widehat{\phi}-1\) sob a hipótese nula de que \(\phi= 1\) ou mais precisamente, que o modelo é um passeio aleatório, \(\displaystyle X_t = \sum_{j=1}^t W_j\) ou \(X_t = X_{t-1}+W_t\) com \(X_0 = 0\), considere o estimador de mínimos quadrados de \(\phi\). Observando que \(\mu_X = 0\), o estimador de mínimos quadrados pode ser escrito como \begin{equation} \widehat{\phi} \, = \, \frac{\displaystyle \sum_{t=1}^n X_t X_{t-1}}{\displaystyle \sum_{t=1}^n X_{t-1}^2} \, = \, 1+ \frac{\displaystyle \frac{1}{n}\sum_{t=1}^n W_t X_{t-1}}{\displaystyle \frac{1}{n}\sum_{t=1}^n X_{t-1}^2}, \end{equation} onde escrevemos \(X_t=X_{t-1}+W_t\) no numerador: lembre-se de que \(X_0 = 0\) e na configuração de mínimos quadrados, estamos regredindo \(X_t\) em \(X_{t-1}\) para \(t = 1,,\cdots,n\). Portanto, sob \(H_0\) verdadeira, temos que \begin{equation} \widehat{\phi} -1 \, = \, \frac{\displaystyle \frac{1}{n\sigma_{_W}^2}\sum_{t=1}^n W_t X_{t-1}}{\displaystyle \frac{1}{n\sigma_{_W}^2}\sum_{t=1}^n X_{t-1}^2}\cdot \end{equation}
Considere o numerador da expressão acima de \(\widehat{\phi}\). Observe primeiro que elevando ao quadrado os dos dois lados da \(X_t=X_{t-1}+W_t\), obtemos \(X_t^2=X_{t-1}^2+2X_{t-1}W_t+W_t^2\), de modo que \begin{equation} X_{t-1}W_t \, = \, \frac{1}{2}\big( X_t^2-X_{t-1}^2-W_t^2\big), \end{equation} e somando \begin{equation} \frac{1}{n\sigma_{_W}^2}\sum_{t=1}^n X_{t-1}W_t \, = \, \displaystyle \frac{1}{2}\left( \frac{X_n^2}{n\sigma_{_W}^2}-\frac{\sum_{t=1}^n W_t^2}{n\sigma_{_W}^2}\right)\cdot \end{equation} Porque \(\displaystyle X_n=\sum_{t=1}^n W_t\), temos \(X_n\sim N(0,n\sigma_{_W}^2)\), de maneira que \begin{equation} \frac{1}{n\sigma_{_W}^2} X_n \sim \chi^2_1, \end{equation} tem distribuição qui-quadrado com um grau de liberdade. Além disso, porque \(W_t\) é ruído branco gaussiano \begin{equation} \frac{1}{n}\sum_{t=1}^n W_t^2 \overset{P}{\longrightarrow} \sigma_{_W}^2 \qquad \mbox{ou} \qquad \frac{1}{n\sigma_{_W}^2}\sum_{t=1}^n W_t^2 \overset{P}{\longrightarrow} 1\cdot \end{equation} Consequentemente, quando \(n\to\infty\) \begin{equation} \frac{1}{n\sigma_{_W}^2}\sum_{t=1}^n X_{t-1} W_t \overset{D}{\longrightarrow} \displaystyle \frac{1}{2}\big( \chi^2_1-1\big)\cdot \end{equation}
A seguir, focaremos no denominador da expressão acima de \(\widehat{\phi}\). Primeiro, apresentamos o movimento browniano padrão.
Um processo estocástico de tempo contínuo \(\{W(t) \, : \, t\geq 0\}\) é chamado de movimento Browniano padrão se satisfizer as seguintes condições:
Além de (i) - (iii) acima, supõe-se que quase todos os caminhos amostrais de \(W(t)\) sejam contínuos em \(t\). O resultado para o denominador usa o Teorema do Limite Central Funcional, que pode ser encontrado em Billlingsley (1999, § 2.8). Em particular, se \(\xi_1,\cdots,\xi_n\) é uma sequência de variáveis aleatórias independentes idênticamente distribuídas com média 0 e variância 1; então, para \(0\leq t\leq 1\), o processo contínuo no tempo \begin{equation} S_n(t) \, = \, \frac{1}{\sqrt{n}}\sum_{j=1}^{[[nt]]} \xi_j \overset{D}{\longrightarrow} W(t), \end{equation} quando \(n\to\infty\), onde \([[\cdot]]\) é a maior função inteira e \(W(t)\) é o movimento Browniano padrão em \([0,1]\). A intuição aqui é, para \(k=[[nt]]\) e fixado \(t\), o Torema do Limite Central implica que \begin{equation} \sqrt{t}\frac{1}{\sqrt{k}}\sum_{j=1}^k \xi_j \sim N(0,t), \qquad \mbox{quando} \qquad n\to\infty\cdot \end{equation}
Observe que o sob a hipótese nula \(X_s=W_1+\cdots+W_s\sim N(0,s\sigma_{_W}^2)\) e, pelo resultado acima, temos que \begin{equation} \frac{X_s}{\sigma_{_W} \sqrt{n}} \overset{D}{\longrightarrow} W(s)\cdot \end{equation} Deste fato, podemos mostrar que, quando \(n\to\infty\), \begin{equation} \frac{1}{n}\sum_{t=1}^n \left( \frac{X_{t-1}}{\sigma_{_W} \sqrt{n}}\right)^2 \, \overset{D}{\longrightarrow} \, \displaystyle \int_0^1 W^2(t)\mbox{d}t\cdot \end{equation}
Obtemos então que, quando \(n\to\infty\), \begin{equation} n(\widehat{\phi} -1) \, = \, \frac{\displaystyle \frac{1}{n\sigma_{_W}^2}\sum_{t=1}^n W_t X_{t-1}}{\displaystyle \frac{1}{n^2\sigma_{_W}^2}\sum_{t=1}^n X_{t-1}^2} \, \overset{D}{\longrightarrow} \, \frac{\displaystyle \frac{1}{2}\big( \chi_1^2 -1\big)}{\displaystyle \int_0^1 W^2(t)\mbox{d}t}\cdot \end{equation}
A estatística \(n(\widehat{\phi}-1)\) é conhecida como raiz unitária ou estatística Dickey-Fuller (DF), veja Fuller, 1976 ou 1996, embora a estatística real do teste DF seja normalizada de forma um pouco diferente. Derivações relacionadas foram discutidas em Rao (1978; Correction 1980) e em Evans & Savin (1981). Como a distribuição da estatística de teste não tem uma forma fechada, os quantis da distribuição devem ser calculados por aproximação numérica ou por simulação. O pacote R tseries fornecem este teste junto com testes mais gerais que mencionamos brevemente.
Para um modelo mais geral, notamos que o teste DF foi estabelecido observando que se \(X_t=\phi X_{t-1}+W_t\), então \(\nabla X_t=(\phi-1)X_{t-1}+W_t=\gamma X_{t-1}+W_t\) e poderiamos testar \(H_):\gamma=0\) regredindo \(\nabla X_t\) em \(X_{t-1}\). Formando assim uma estatística de Wald e derivar sua distribuição limite, a derivação anterior baseada no movimento browniano é devida a Phillips (1987).
O teste foi estendido para acomodar modelos \(AR(p)\), \(X_t=\displaystyle \sum_{j=1}^p \phi_j X_{t-j}+W_t\), como segue. Subtraindo \(X_{t-1}\) de ambos os lados, se obtém \begin{equation} \nabla X_t \, = \, \gamma X_{t-1} +\sum_{j=1}^{p-1} \psi_j \nabla X_{t-j} +W_t, \end{equation} onde \(\displaystyle \gamma = \sum_{j=1}^p \phi_j-1\) e \(\displaystyle \psi_j=-\sum_{i=j}^p \phi_i\), pata \(j=2,\cdots,p\).
Para uma verificação rápida da expressão acima, quando \(p = 2\), observe que \begin{equation} X_t \, = \, (\phi_1+\phi_2)X_{t-1} - \phi_2(X_{t-1}-X_{t-2})+W_t, \end{equation} subtraindo \(X_{t-1}\) de ambos os lados. Para testar a hipótese de que o processo tem uma raiz unitária em 1, ou seja, o \(AR\) polinomial \(\phi(z)=0\) quando \(z = 1\), podemos testar \(H_0: \gamma = 0\) estimando \(\gamma\) na regressão de \(\nabla X_t\) em \(X_{t-1},\nabla X_{t-1},\cdots,\nabla X_{t-p+1}\) e formando um teste de Wald baseado em \begin{equation} t_{_\gamma} \, = \, \frac{\widehat{\gamma}}{\sqrt{\mbox{Var}(\widehat{\gamma})}}\cdot \end{equation} Este teste leva ao chamado teste aumentado de Dickey-Fuller (ADF). Enquanto os cálculos para obter a distribuição nula assintótica mudam, as idéias básicas e o maquinário permanecem os mesmos que no caso simples. A escolha de \(p\) é crucial e discutiremos algumas sugestões no exemplo. Para modelos \(ARMA(p,q)\), o teste ADF pode ser usado assumindo que \(p\) é grande o suficiente para capturar a estrutura de correlação essencial. Outra alternativa é o teste de Phillips-Perron (PP), que difere dos testes do ADF principalmente no modo como eles lidam com a correlação serial e a heteroscedasticidade nos erros.
Pode-se estender o modelo para incluir uma tendência constante ou mesmo não-estocástica. Por exemplo, considere o modelo \begin{equation} X_t \, = \, \beta_0+\beta_1 t+\phi X_{t-1}+W_t\cdot \end{equation} Se assumirmos \(\beta_1 = 0\), então, sob a hipótese nula, \(\phi= 1\), o processo é um passeio aleatório com tendência constante \(\beta_0\). Sob a hipótese alternativa, o processo é um \(AR(1)\) causal, com média \(\mu_X = \beta_0(1-\phi)\). Se não podemos assumir \(\beta_1 = 0\), então o interesse aqui é testar a hipótese nula que \((\beta_1,\phi)=(0,1)\), simultaneamente, versus a alternativa que \(\beta_1\neq 0\) e \(|\phi|< 1\). Neste caso, a hipótese nula é que o processo é um passeio aleatório com tendência, versus a hipótese alternativa de que o processo é de tendência estacionária, como pode ser considerado para a série de preços de frango no Exemplo II.1.
Neste exemplo, usamos o pacote R tseries para testar a hipótese nula de que o logaritmo da série de variações glaciais tem uma raiz unitária, versus a hipótese alternativa de que o processo é estacionário. Testamos a hipótese nula usando os testes DF, ADF e PP disponíveis. Observe que, em cada caso, a equação de regressão geral incorpora uma tendência constante e linear. No teste ADF, o número padrão de componentes \(AR\) incluídos no modelo, digamos \(k\), é \([[(n-1)^\frac{1}{3}]]\), que corresponde ao limite superior sugerido na taxa na qual o número de lags, \(k\), deve ser feito para crescer com o tamanho da amostra para a configuração geral \(ARMA(p,q)\). Para o teste PP, o valor padrão de \(k\) é \([[0.04n^\frac{1}{4}]]\).
Em cada teste, rejeitamos a hipótese nula de que a série de variações glaciais registrada possui uma raiz unitária. A conclusão desses testes suporta a conclusão da seção anterior de que o logaritmo da série é de memória longa ao invés de integrada.
Vários problemas, como a precificação de opções em finanças, motivaram o estudo da volatilidade ou variabilidade de uma série temporal. Os modelos ARMA foram usados para modelar a média condicional de um processo quando a variância condicional era constante. Usando um \(AR(1)\) como exemplo, assumimos \begin{equation} \mbox{E}(X_t \, | \, X_{t-1},X_{t-2},\cdots) \, = \, \phi X_{t-1} \qquad \mbox{Var}(X_t \, | \, X_{t-1},X_{t-2},\cdots) \, = \, \sigma_{_W}^2\cdot \end{equation}
Em muitos problemas, no entanto, a suposição de uma variância condicional constante será violada. Modelos como o auto-regressivo condicionalmente heterocedástico ou o modelo ARCH, introduzidos pela primeira vez por Engle (1982), foram desenvolvidos para modelar mudanças na volatilidade. Esses modelos foram posteriormente estendidos aos modelos ARCH ou GARCH generalizados por Bollerslev (1986).
Nesses problemas, estamos preocupados em modelar a taxa de retorno ou crescimento de uma série. Por exemplo, se \(X_t\) é o valor de um ativo no momento \(t\), então o retorno ou ganho relativo, \(r_t\), do ativo no momento \(t\) é \begin{equation} r_t \, = \, \frac{X_t-X_{t-1}}{X_{t-1}}\cdot \end{equation} A definição acima implica que \(X_t = (1-r_t)X_{t-1}\). Assim, com base na discussão na Seção III.7, se o retorno representar uma pequena porcentagem, em magnitude, de mudança percentual então \begin{equation} \nabla \log(X_t)\approx r_t\cdot \end{equation}
Qualquer valor, \(\nabla \log(X_t)\) ou \((X_t-X_{t-1})/X_{t-1}\), será chamado de retorno e será indicado por \(r_t\). Lembre-se que, se \(r_t = (X_t-X_{t-1}/X_{t-1}\) for uma pequena porcentagem, então \(\log(1 + r_t)\approx r_t\). É mais fácil programar \(\nabla \log(X_t)\), portanto, isso geralmente é usado em vez de calcular \(r_t\) diretamente. Embora seja um nome impróprio, \(\nabla \log(X_t)\) é frequentemente chamado de log-retorno; mas os retornos não estão sendo registrados. Uma alternativa ao modelo GARCH é o modelo de volatilidade estocástica; discutiremos esses modelos no Capítulo VI porque eles são modelos de espaço de estados.
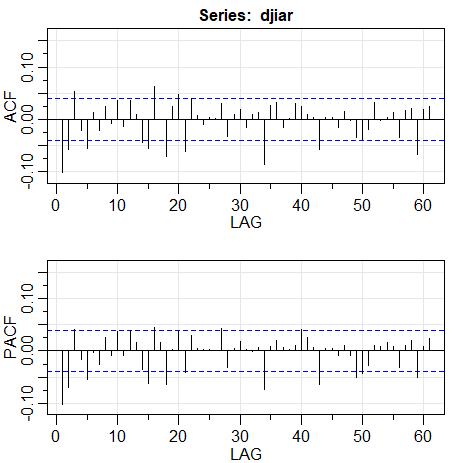
Normalmente, para séries financeiras, o retorno \(r_t\), não tem uma variância condicional constante e períodos altamente voláteis tendem a ser agrupados. Em outras palavras, há uma forte dependência de explosões súbitas de variabilidade em um retorno sobre o passado da própria série. Por exemplo, a figura do Exemplo I.4 mostra os retornos diários do Dow Jones Industrial Average (DJIA) de 20 de abril de 2006 a 20 de abril de 2016. Nesse caso, como é típico, o retorno \(r_t\) é razoavelmente estável, exceto para rajadas de curto prazo de alta volatilidade.
O modelo ARCH mais simples o \(ARCH(1)\), modela o retorno como \begin{equation} r_t \, = \, \sigma_t \epsilon_t \qquad \mbox{e} \qquad \sigma_t^2 \, = \, \alpha_0 +\alpha_1 r_{t-1}^2, \end{equation} onde \(\epsilon_t\) é o ruído branco gaussiano padrão, \(\epsilon_t \sim N(0,1)\) independentes. A suposição de normalidade pode ser relaxada. Vamos discutir isso mais tarde. Assim como nos modelos ARMA, devemos impor algumas restrições aos parâmetros do modelo para obter propriedades desejáveis. Uma restrição óbvia é que \(\alpha_0,\alpha_1\geq 0\), porque \(\sigma_t^2\) é a variância.
Como veremos, os modelos \(ARCH(1)\) retornam como um processo de ruído branco com variância condicional não constante e essa variância condicional depende do retorno anterior. Primeiro, observe que a distribuição condicional de \(r_t\) dado \(r_{t-1}\) é gaussiana: \begin{equation} r_t \,| \, r_{t-1} \, \sim \, N\big( 0,\alpha_0+\alpha_1 r_{t-1}^2\big)\cdot \end{equation}
Além disso, é possível escrever o modelo \(ARCH(1)\) como um modelo \(AR(1)\) não-Gaussiano no quadrado dos retornos \(r_t^2\). Para isso, reescrevemos \begin{equation} r_t^2 \, = \, \sigma_t^2 \epsilon_t^2 \qquad \mbox{e} \qquad \alpha_0+\alpha_1 r_{t-1}^2 \, = \, \sigma_t^2, \end{equation} e subtraindo as duas equações obtemos \begin{equation} r_t^2 \, - \, (\alpha_0+\alpha_1 r_{t-1}^2) \, = \, \sigma_t^2 \epsilon_t^2 -\sigma_t^2\cdot \end{equation} Agora, escreva esta equação como \begin{equation} r_t^2 \, = \, \alpha_0+\alpha_1 r_{t-1}^2+\nu_t, \end{equation} onde \(\nu_t=\sigma_t^2(\epsilon_t^2-1)\). Devido a \(\epsilon_t^2\) ser o quadrado de uma variável aleatória \(N(0,1)\), \(\epsilon_t^2-1\) é uma variável aleatória \(\chi_1^2\) deslocada, para ter média zero.
Para explorar as propriedades do mosdelo ARCH, definimos \(\mathcal{R}_s = \{r_s, r_{s-1},\cdots \}\). Então, usando que \(r_t | r_{t-1} \sim N\big( 0,\alpha_0+\alpha_1 r_{t-1}^2\big)\), vemos imediatamente que \(r_t\) tem média zero: \begin{equation} \mbox{E}(r_t) \, = \, \mbox{E}\big(\mbox{E}(r_t \, | \, \mathcal{R}_{t-1})\big) \, = \, \mbox{E}\big(\mbox{E}(r_t \, | \, r_{t-1})\big) \, = \, 0\cdot \end{equation} Porque \(\mbox{E}\big(\mbox{E}(r_t|\mathcal{R}_{t-1})\big) = 0\), o processo \(r_t\) é dito ser uma diferençça martingal.
Por ser \(r_t\) uma diferença martingal, também é uma sequência não correlacionada. Por exemplo, com \(h> 0\), \begin{array}{rcl} \mbox{Cov}(r_{t+h}, r_t) & = & \mbox{E}(r_t \, r_{t+h}) \, = \, \mbox{E}\big(\mbox{E}(r_t \, r_{t+h}|\mathcal{R}_{t+h-1})\big) \\ & = & \mbox{E}\big(r_t \, \mbox{E}(r_{t+h} \, | \, \mathcal{R}_{t+h-1})\big) \, = \, 0\cdot \end{array} A última linha acima segue porque \(r_t\) pertence ao conjunto de informações \(R_{t+h-1}\) para \(h> 0\) e \(\mbox{E}(r_{t+h} | \mathcal{R}_{t+h-1})=0\).
Um argumento similar estabelecerá o fato de que o processo de erro \(\nu_t\) é também uma diferença martingal e, consequentemente, uma sequência não correlacionada. Se a variância de \(\nu_t\) é finita e constante em relação ao tempo e \(0\leq \alpha_1 < 1\), então com base no Teorema III.1, \(r_t^2 = \alpha_0+\alpha_1 r_{t-1}^2+\nu_t\) especifica um processo causal \(AR(1)\) para \(r^2_t\). Portanto, \(\mbox{E}(r^2_t)\) e \(\mbox{Var}(r^2_t)\) devem ser constantes em relação ao tempo \(t\). Isso implica que \begin{equation} \mbox{E}(r_t^2) \, = \, \mbox{Var}(r_t) \, = \, \frac{\alpha_0}{1-\alpha_1} \end{equation} e, depois de algumas manipulações, \begin{equation} \mbox{E}(r_t^4) \, = \, \frac{3\alpha_0^2}{(1-\alpha_1)^2}\frac{1-\alpha_1^2}{1-3\alpha_1^2}, \end{equation} desde que \(3\alpha_1^2 < 1\). Obsere que \begin{equation} \mbox{Var}(r_t^2) \, = \, \mbox{E}(r_t^4) \, - \, \big(\mbox{E}(r_t^2)\big)^2, \end{equation} que existe apenas se \(0< \alpha_1 < 1/\sqrt{3}\approx 0.58\). Além disso, estes resultados implicam que a curtose, \(\kappa\) de \(r_t\) é \begin{equation} \kappa \, = \, \frac{\mbox{E}(r_t^4)}{\big(\mbox{E}(r_t^2)\big)^2} \, = \, 3\frac{1-\alpha_1^2}{1-3\alpha_1^2}, \end{equation} que nunca é menor que 3, a curtose da distribuição normal. Assim, a distribuição marginal dos retornos \(r_t\), é leptocúrtica ou tem “caudas grossas”. Resumindo, se \(0\leq \alpha_1 <, 1\), o processo \(r_t\) em si é ruído branco e sua distribuição incondicional é distribuída simetricamente em torno de zero; essa distribuição é leptocúrtica. Se, além disso, \(3\alpha_1^2 < 1\), o quadrado do processo, \(r^2_t\), segue um modelo causal \(AR(1)\) com ACF dado por \(\rho_{_{r_t^2}}(h)=\alpha_1^h\geq 0\), para todo \(h>0\). Se \(3\alpha_1^2 \geq 1\), mas \(\alpha_1 < 1\), pode-se mostrar que \(r^2_t\) é estritamente estacionário com variância infinita (ver Douc, et al., 2014).
A estimação dos parâmetros \(\alpha_0\) e \(\alpha_1\) do modelo \(ARCH(1)\) é tipicamente realizada por máxima verossimilhança condicional. A verossimilhança condicional dos dados \(r_2,\cdots,r_n\) dado \(r_1\), é dada por \begin{equation} L(\alpha_0,\alpha_1|r_1) \, = \, \prod_{t=2}^n f_{\alpha_0,\alpha_1}(r_t|r_{t-1}), \end{equation} onde a densidade \(f_{\alpha_0,\alpha_1}(r_t|r_{t-1})\) é a densidade normal \(N\big( 0,\alpha_0+\alpha_1 r_{t-1}^2\big)\). Portanto, a função critério a ser minimizada, \(\ell(\alpha_0,\alpha_1)=- \ln\big(L(\alpha_0,\alpha_1|r_1)\big)\) é dada por \begin{equation} \ell(\alpha_0,\alpha_1) \, = \, \displaystyle \frac{1}{2}\sum_{t=2}^n \ln \big( \alpha_0+\alpha_1 r_{t-1}^2\big) \, + \, \frac{1}{2}\sum_{t=2}^n \left( \frac{r_t^2}{\alpha_0 +\alpha_1 r_{t-1}^2}\right)\cdot \end{equation}
A estimação é realizada por métodos numéricos, conforme descrito na Seção III.5. Nesse caso, expressões analíticas para o vetor gradiente, \(\ell^{(1)}(\alpha_0,\alpha_1)\) e matriz Hessiana, \(\ell^{(2)}(\alpha_0,\alpha_1)\), como descrita sa Saçã III.30, podem ser obtidos por cálculos diretos. Por exemplo, o vetor gradiente \(2\times 1\), \(\ell^{(1)}(\alpha_0,\alpha_1)\), é dado por \begin{equation} \begin{pmatrix} \displaystyle \partial \ell ∕ \partial\alpha_0 \\ \displaystyle \partial \ell ∕ \partial\alpha_1 \end{pmatrix} \, = \, \sum_{t=2}^n \begin{pmatrix} 1 \\ r_{t-1}^2 \end{pmatrix} \times \frac{\displaystyle \alpha_0+\alpha_1 r_{t-1}^2-r_t^2} {\displaystyle \big( \alpha_0+\alpha_1 r_{t-1}^2\big)^2}\cdot \end{equation}
O cálculo da matriz Hessiana é deixado como um exercício. A verossimilhança do modelo ARCH tende a ser plana, a menos que \(n\) seja muito grande. Uma discussão sobre esse problema pode ser encontrada em Shephard (1996).
Também é possível combinar uma regressão ou um modelo ARMA para a média com um modelo ARCH para os erros. Por exemplo, uma regressão com o modelo de erros \(ARCH(1)\) teria as observações \(X_t\) como função linear dos regressores \(p\), \(z_p = (z_{t1},\cdots,z_{tp})^\top\) e o ruído \(Y_t\) \(ARCH(1)\), digamos, \begin{equation} X_t \, = \, \beta^\top z_t + Y_t, \end{equation} onde \(Y_t\) satisfaz \(r_t = \sigma_t\epsilon_t\) e \(\sigma_t^2 = \alpha_0 +\alpha_1 r_{t-1}^2\) mas, neste caso, não é observado. Da mesma forma, por exemplo, um modelo \(AR(1)\) para os dados \(X_t\) exibindo erros \(ARCH(1)\) seria \begin{equation} X_t \, = \, \phi_0 +\phi_1 X_{t-1}+Y_t\cdot \end{equation} Esses tipos de modelos foram explorados por Weiss (1984).
No Exemplo III.39, ajustamos um modelo \(MA(2)\) e um modelo \(AR(1)\) à série do PIB dos EUA e concluímos que os resíduos de ambos os ajustes parecíam se comportar como um processo de ruído branco. No Exemplo III.43, concluímos que o \(AR(1)\) é provavelmente o melhor modelo nesse caso. Foi sugerido que a série do PIB dos EUA tem erros ARCH e, neste exemplo, investigaremos essa reivindicação. Se o termo de ruído do PIB for ARCH, os quadrados dos resíduos do ajuste devem se comportar como um processo \(AR(1)\) não gaussiano. A figura abaixo à direita mostra o ACF e o PACF dos resíduos quadrados, parece que pode haver alguma dependência, embora pequena, nos resíduos. A figura foi gerada em R da seguinte maneira.
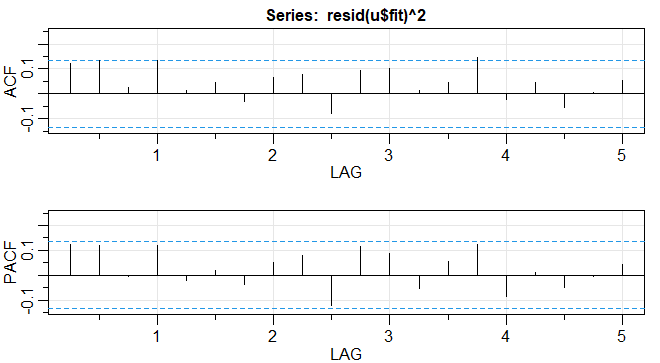
Figura V.5: Funções de autocorrelação e autocorrelação parcial amostrais dos quadrados dos resíduos do ajuste \(AR(1)\) no PNB dos EUA.
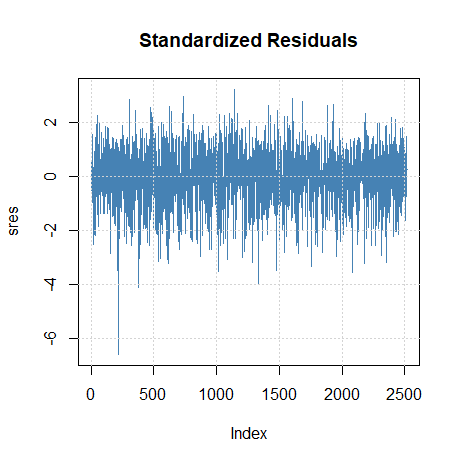
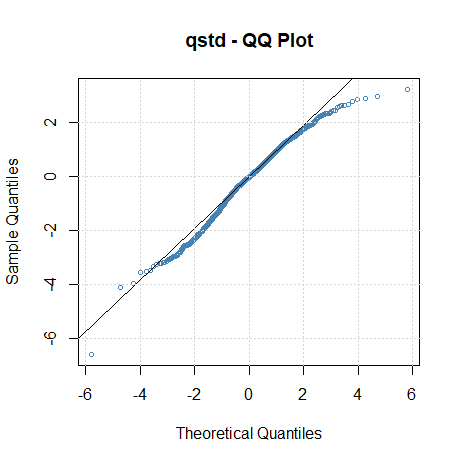
Usamos o pacote R do fGarch para ajustar um modelo \(AR(1)-ARCH(1)\) aos retornos do PIB dos EUA com os seguintes resultados. Notamos que o modelo \(GARCH(1,0)\) especifica um \(ARCH(1)\) no código abaixo.
Observe que os \(p\)-valores no parágrafo das estimativas são bilaterais, portanto devem ser reduzidos pela metade ao considerar os parâmetros do modelo ARCH. Neste exemplo, obtemos \(\widehat{\phi}_0 =0.005\), chamado \(\mu\) na saída, e \(\widehat{\phi}_1 =0.367\), chamado \(ar1\) para as estimativas de parâmetro \(AR(1)\). No Exemplo III.39, os valores foram: 0.005 e 0.347, respectivamente. As estimativas dos parâmetros \(ARCH(1)\) são \(\alpha_0 = 0\), chamado ômega, e para a constante \(\alpha_1 =0.194\), que é significativo com um \(p\)-valor de cerca de \(0.0418/2=0.02\). Existem vários testes realizados nos resíduos \([R]\) ou nos resíduos ao quadrado \([R^2]\). Por exemplo, a estatística Jarque – Bera testa os resíduos do ajuste para normalidade com base na assimetria e a curtose observadas e parece que os resíduos têm alguma assimetria e curtose não normais. A estatística Shapiro-Wilk testa os resíduos do ajuste para normalidade com base nas estatísticas de ordem empíricas. Os outros testes, principalmente baseados na estatística \(Q\), são usados nos resíduos e seus quadrados.
O modelo \(ARCH(1)\) pode ser estendido ao modelo geral \(ARCH(p)\) da seguinte maneira óbvia, retemos \(r_t=\sigma_t \epsilon_t\) mas estendemos \begin{equation} \sigma_t^2 \, = \, \alpha_0 +\alpha_1 r_{t-1}^2+\cdots+\alpha_p r_{t-p}^2\cdot \end{equation} A estimação para o modelo \(ARCH(p)\) também segue de maneira similar a partir da discussão da estimação para o modelo do \(ARCH(1)\). Ou seja, a verossimilhança condicional dos dados \(r_{p+1},\cdots,r_n\) dados \(r_{1},\cdots,r_p\), é dada por \begin{equation} L(\alpha \, | \, r_1,\cdots,r_n) \, = \, \displaystyle \prod_{t=p+1}^n f_\alpha(r_t \, | \, r_{t-1},\cdots,r_{t-m}), \end{equation} onde \(\alpha=(\alpha_0,\alpha_1,\cdots,\alpha_p)\) e sob a suposição de normalidade, as densidades condicionais \(f_\alpha(\cdot|\cdot)\) são, para \(t>p\), dadas por \begin{equation} r_t \, | \, r_{t-1},\cdots,r_{t-p} \, \sim \, N\big( 0,\alpha_0 +\alpha_1 r_{t-1}^2+\cdots+\alpha_p r_{t-p}^2\big)\cdot \end{equation}
Outra extensão do ARCH é o modelo ARCH generalizado ou GARCH, desenvolvido por Bollerslev (1986). Por exemplo, um modelo \(GARCH(1,1)\) mantém \(r_t=\sigma_t\epsilon_t\) mas se estende da seguinte maneira: \begin{equation} \sigma_t^2 \, = \, \alpha_0+\alpha_1 r_{t-1}^2+\beta_1 \sigma_{t-1}^2\cdot \end{equation} Sob a condição de \(\alpha_1 + \beta_1 < 1\), usando manipulações semelhantes às anteriores, o modelo \(GARCH(1,1)\) admite um modelo \(ARMA(1,1)\) não gaussiano para o processo quadrado \begin{equation} r_t^2 \, = \, \alpha_0 +(\alpha_0+\beta_1)r_{t-1}^2 +\nu -\beta_1 v_{t-1}, \end{equation} onde \(v_t=\sigma_t^2(\epsilon_t^2-1)\). A representação acima segue escrevendo \begin{array}{rcl} r_t^2-\sigma_t^2 & = & \sigma_t^2 (\epsilon_t^2-1) \\ \beta_1 (r_{t-1}^2-\sigma_{t-1}^2) & = & \beta_1\sigma_{t-1}^2(\epsilon_{t-1}^2-1), \end{array} subtraindo a segunda equação da primeira e usando o fato de que, \(\sigma_t^2-\beta_1 \sigma_{t-1}^2=\alpha_0+\alpha_1 r_{t-1}^2\), no lado esquerdo do resultado. O modelo \(GARCH(p,q)\) retém \(\sigma_t^2 = \alpha_0+\alpha_1 r_{t-1}^2+\beta_1 \sigma_{t-1}^2\) e se estende até \begin{equation} \sigma_t^2 \, = \, \alpha_0+\sum_{j=1}^p \alpha_j r_{t-j}^2 +\sum_{j=1}^q \beta_j \sigma_{t=j}^2\cdot \end{equation}
Estimação por máxima verossimilhan\ça condicional dos parâmetros do modelo \(GARCH(m,r)\) é semelhante ao caso \(ARCH(m)\), em que a verossimilhança condicional é produto de densidade \(N(0,\sigma_t^2)\) com \(\sigma^2_t\) dadas acima e onde o condicionamento está nas primeiras \(\max(m,r)\) observações, com \(\sigma^2_1 = \cdots=\sigma^2_r = 0\). Uma vez obtidas as estimativas dos parâmetros, o modelo pode ser usado para obter previsões um pouco à frente da volatilidade, digamos \(\sigma^2_{t+1}\), dadas por \begin{equation} \widehat{\sigma}^2_{t+1} \, = \, \widehat{\alpha}_0+\sum_{j=1}^p \widehat{\alpha}_j r^2_{t+1-j}+\sum_{j=1}^q \widehat{\beta}_j\widehat{\sigma}^2_{t+1-j}\cdot \end{equation}
Exploramos esses conceitos no exemplo a seguir.
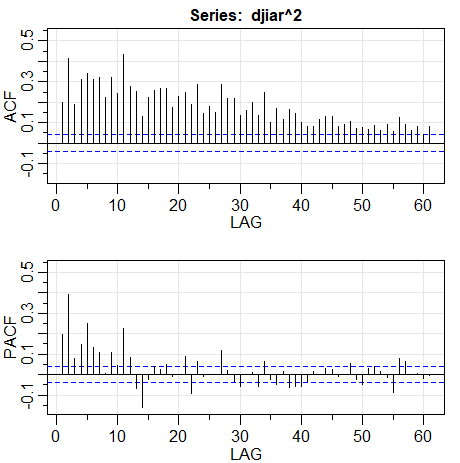
Como mencionado anteriormente, os retornos diários do DJIA mostrados na figura do Exemplo I.4 exibem recursos clássicos do modelo GARCH. Além disso, existe alguma autocorrelação de baixo nível na própria série e, para incluir esse comportamento, usamos o pacote R fGarch para ajustar um modelo \(AR(1)-GARCH(1,1)\) à série:
 |  |
|---|
Funções de autocorrelação ACF e autocorrelação parcial PACF da série \(\nabla \log(r_t)\), sendo \(r_t\) retornos diários do valor de fechamento da Bolsa de Valores de Nova York (DJIA) a esquerda e as mesmas funções de \(\nabla \log(r_t^2)\).
A seguir o ajuste do modelo \(AR(1)-GARCH(1,1)\):
 |  |
|---|---|
 |  |
Para explorar as previsões de volatilidade GARCH, calculamos e graficamos parte dos dados em torno das crises financeiras de 2008, juntamente com as previsões um passo à frente da volatilidade correspondente, \(\widehat{\sigma}_t\) como uma linha sólida na figura abaixo.
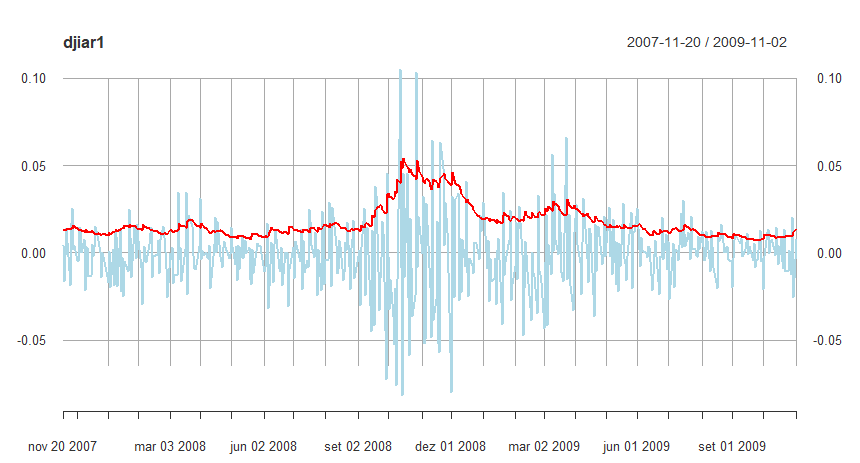
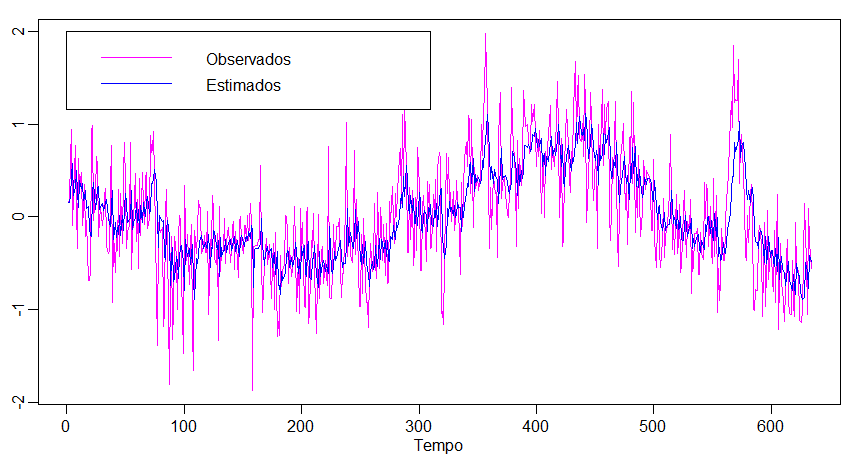
Figura V.6 Previsões \(GARCH\) um passo à frente da volatilidade \(\widehat{\sigma}_t\) do DJIA, sobreposta em parte dos dados, incluindo a crise financeira de 2008.
Outro modelo que mencionamos brevemente é o modelo ARCH de potência assimétrica. O modelo mantém \(r_t=\sigma_t \epsilon_t\), mas a variância condicional é modelada como \begin{equation} \sigma_t^\delta \, = \, \alpha_0 + \sum_{j=1}^p \alpha_j\big(|r_{t-j}|-\gamma_j r_{t-j} \big)^\delta + \sum_{j=1}^q \beta_j \sigma_{t-j}^\delta\cdot \end{equation} Observe que o modelo é GARCH quando \(\delta= 2\) e \(\gamma_j = 0\), para \(j\in\{1,\cdots,p\}\). Os parâmetros \(\gamma_j\), tais que \(|\gamma_j|\leq 1\) são os parâmetros de alavancagem, que são uma medida de assimetria e \(\delta>0\) é o parâmetro para o termo de potência. Um valor positivo ou negativo de \(\gamma_j\) significa que choques positivos ou negativos passados têm um impacto mais profundo na volatilidade condicional atual do que choques negativos ou positivos passados. Esse modelo combina a flexibilidade de um expoente variável com o coeficiente de assimetria para levar em consideração o efeito de alavancagem. Além disso, para garantir que \(\sigma_t> 0\), assumimos que \(\alpha_0> 0\), \(\alpha_j\geq 0\) com pelo menos um \(\alpha_j> 0\) e \(\beta_j\geq 0\).
Continuamos a análise dos retornos do DJIA no exemplo a seguir.
O pacote R fGarch foi usado para ajustar um modelo \(AR-APARCH\) aos retornos do DJIA discutidos no Exemplo V.5. Como no exemplo anterior, incluímos um \(AR(1)\) no modelo para contabilizar a média condicional. Nesse caso, podemos pensar no modelo como \(r_t = \mu_t + Y_t\), onde \(\mu_t\) é um \(AR(1)\) e \(Y_t\) é um ruído \(APARCH\) com variância condicional modelada como acima com erros \(t-Student\). A volatilidade prevista é, obviamente, diferente dos valores mostrados na figura do Exemplo V.5, mas parece semelhante quando representada graficamente.
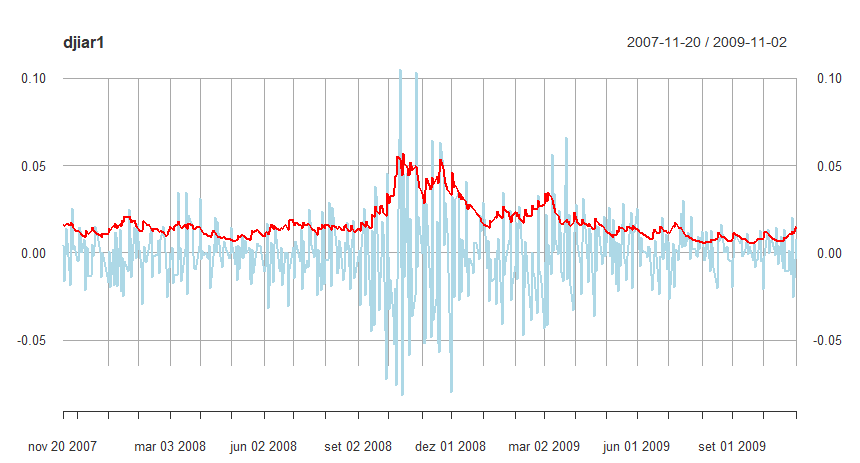 |
|---|
Na maioria das aplicações, a distribuição do ruído \(\epsilon_t\), raramente é normal. O pacote R fGarch permite que várias distribuições sejam ajustadas aos dados; consulte o arquivo de ajuda para obter informações. Algumas desvantagens do GARCH e modelos relacionados são as seguintes. (i) O modelo GARCH assume que retornos positivos e negativos têm o mesmo efeito porque a volatilidade depende de retornos quadrados; os modelos assimétricos ajudam a aliviar esse problema. (ii) Esses modelos geralmente são restritivos devido às restrições rígidas nos parâmetros do modelo, por exemplo, para um \(ARCH(1)\), \(0\leq \alpha_1^2< \frac{1}{3}\). (iii) A verossimilhança é plana, a menos que \(n\) seja muito grande. (iv) Os modelos tendem a predizer a volatilidade porque respondem lentamente a grandes retornos isolados.
Várias extensõs ao modelo original foram propostas para superar algumas das deficiências que acabamos de mencionar. Por exemplo, já discutimos o fato de que o fGarch permite dinâmica de retorno assimétrica. No caso de persistência na volatilidade, o modelo GARCH integrado ou IGARCH pode ser usado. Lembre-se, mostramos que o modelo \(GARCH(1,1)\) pode ser escrito como \begin{equation} r_t^2 \, = \, \alpha_0 +(\alpha_1+\beta_1)r_{t-1}^2+\nu_t-\beta_1 \nu_{t-1}, \end{equation} e \(r_t^2\) é estacionário se \(\alpha_1+\beta_1< 1\). No modelo IGARCH fazemos \(\alpha_1+\beta_1=1\), nesse caso, o modelo \(IGARCH(1,1)\) é \begin{equation} r_t \, = \, \sigma_t\epsilon_t \qquad \mbox{e} \qquad \sigma_t^2 \, = \, \alpha_0+(1-\beta_1)r_{t-1}^2+\beta_1\sigma_{t-1}^2\cdot \end{equation} Existem muitas extensões diferentes no modelo ARCH básico que foram desenvolvidas para lidar com as várias situações observadas na prática. Os leitores interessados podem encontrar as discussões gerais em Engle et al. (1994) e Shephard (1996) valem a pena ler as referidas referências. Além disso, Gouriéroux (1997) faz uma apresentação detalhada do ARCH e modelos relacionados com aplicações financeiras e contém uma extensa bibliografia. Dois excelentes textos sobre análise financeira de séries temporais são Chan (2002) e Tsay (2002).
Por fim, discutimos brevemente modelos de volatilidade estocástica; um tratamento detalhado desses modelos é apresentado no Capítulo VI. O componente de volatilidade, \(\sigma^2_t\), no GARCH e os modelos relacionados são condicionalmente não estocásticos. Por exemplo, no modelo \(ARCH(1)\), sempre que o retorno anterior for avaliado em, digamos \(c\), isto é, \(r_{t-1}=c\), deve ser o caso \(\sigma^2_t =\alpha_0 + \alpha_1 c^2\). Essa suposição parece um pouco irrealista. O modelo de volatilidade estocástica adiciona um componente estocástico à volatilidade da seguinte maneira. No modelo GARCH, um retorno, digamos, \(r_t\), é \begin{equation} r_t=\sigma_t \epsilon_t, \qquad \mbox{o qual implica que} \qquad \log(r_t^2) \, = \, \log(\sigma^2_t)+\log(\epsilon_t^2)\cdot \end{equation} Assim, as observações \(\log(r^2_t)\) são geradas por dois componentes, a volatilidade não observada, \(\log(\sigma^2_t)\) e o ruído não observado, \(\log(\epsilon_t^2)\).
Enquanto, por exemplo, o \(GARCH(1,1)\) modela a volatilidade sem erro, \(\sigma^2_{t + 1} = \alpha_0+ \alpha_1 r_t^2 + \beta_1\sigma^2_t\), o modelo básico de volatilidade estocástica assume que a variável latente registrada é um processo autoregressivo, \begin{equation} \log(\sigma^2_{t+1}) \, = \, \phi_0+\phi_1 \log(\sigma^2_t)+W_t, \end{equation} em que \(W_t\sim N(0,\sigma_{_W}^2)\) independentes. A introdução do termo ruído torna o processo de volatilidade latente estocástico. As duas expressões acima juntas compõem o modelo de volatilidade estocástica. Dadas \(n\) observações, o objetivo é estimar os parâmetros \(\phi_0\), \(\phi_1\) e \(\sigma^2_{_W}\) e prever a volatilidade futura. Os detalhes são fornecidos na Seção VI.11.
Na Seção III.4, discutimos o fato de que, para uma série temporal estacionária, a melhor predição linear para a frente no tempo é igual à melhor predição linear para trás no tempo.
Este resultado decorreu do fato de que a matriz de variâncias-covariâncias de \(X_{1:n} = \{X_1,X_2,\cdots,X_n\}\), digamos, \(\Gamma = \{\gamma(i-j)\}_{ij,=1}^n\), é a mesma do que a matriz de variâncias-covariâncias de \(X_{n:1} = \{X_n,X_{n-1},X_{n-2},\cdots,X_1\}\). Além disso, se o processo for gaussiano, as distribuições de \(X_{1:n}\) e \(X_{n:1}\) são idênticas. Nesse caso, um gráfico de tempo de \(X_{1:n}\), ou seja, um grádico dos dados traçados para frente no tempo, deve ser semelhante a um gráfico de tempo de \(X_{n:1}\), ou seja, um gráfico dos dados traçados para trás no tempo.
Existem, no entanto, muitas séries que não se enquadram nesta categoria. Por exemplo, a Figura V.7 mostra o gráfico das mortes mensais por pneumonia e influenza para cada 10.000 habitantes nos EUA por 11 anos, de 1968 a 1978. Normalmente, o número de mortes tende a aumentar ↑ mais rápido do que diminuir ↘, especialmente durante epidemias. Assim, se os dados fossem plotados para trás no tempo, essa série tenderia a aumentar mais lentamente do que diminui.
Além disso, se as mortes mensais por pneumonia e influenza seguirem um processo linear de gaussiano, não esperaríamos ver tantos surtos de mudanças positivas e negativas que ocorrem periodicamente nesta série. Além disso, embora o número de mortes seja normalmente maior durante os meses de inverno, os dados não são perfeitamente sazonais, ou seja, embora o pico da série muitas vezes ocorra em janeiro, nos demais anos o pico ocorre em fevereiro ou março, portanto, os modelos ARMA sazonais não captariam esse comportamento.
Existem muitas abordagens para modelar séries não lineares que podem ser usadas (ver Priestley, 1988); aqui, nos concentramos na classe de modelos de limiar TARMA, apresentada em Tong (1983, 1990). A ideia básica desses modelos é ajustar modelos ARMA lineares locais, e seu apelo é que podemos usar a intuição de ajustar modelos ARMA lineares globais. Por exemplo, um modelo de limiar de \(k\)-regimes SETARMA tem a forma \begin{equation*} X_t \, = \, \left\{ \begin{array}{rcl} \displaystyle \phi_0^{(1)}+\sum_{i=1}^{p_1} \phi_i^{(1)}X_{t-i}+W_t^{(1)}+\sum_{j=1}^{q_1} \theta_j^{(1)} W_{t-j}^{(1)}, & \mbox{caso} & X_{t-d}\leq r_1, \\ \displaystyle \phi_0^{(2)}+\sum_{i=1}^{p_2} \phi_i^{(2)}X_{t-i}+W_t^{(2)}+\sum_{j=1}^{q_2} \theta_j^{(2)} W_{t-j}^{(2)}, & \mbox{caso} & r_1< X_{t-d}\leq r_2, \\ \vdots & & \vdots \\ \displaystyle \phi_0^{(k)}+\sum_{i=1}^{p_k} \phi_i^{(k)}X_{t-i}+W_t^{(k)}+\sum_{j=1}^{q_k} \theta_j^{(k)} W_{t-j}^{(k)}, & \mbox{caso} & r_{k-1}< X_{t-d}, \\ \end{array} \right. \end{equation*} onde \(W_t^{(j)}\sim N(0,\sigma_{_j}^2)\) independentes indeticamente distribuídos, para \(j = 1,\cdots,k\), o inteiro positivo \(d\) é um atraso ou delay específico e \( -∞ < r_1 < \cdots < r_{k-1} < ∞ \) consitui uma partição dos números reais.
Esses modelos permitem mudanças nos coeficientes ARMA ao longo do tempo e essas mudanças são determinadas pela comparação de valores anteriores, retrocedidos por um intervalo de tempo igual a \(d\), a valores de limite fixos. Cada modelo ARMA diferente é conhecido como um regime. Na definição acima, os valores \((p_j, q_j)\) da ordem dos modelos ARMA podem diferir em cada regime, embora em muitas aplicações, eles sejam iguais. Estacionaridade e a invertibilidade são preocupações óbvias ao ajustar modelos de série temporal. Para os modelos de séries temporais de limiar, como modelos TAR, TMA e TARMA, no entanto, as condições de estacionaridade e invertibilidade na literatura são menos conhecidas em geral e freqüentemente são modelos restritos de ordem um.
O modelo pode ser generalizado para incluir a possibilidade de que os regimes dependam de uma coleção de valores passados do processo ou de que os regimes dependam de uma variável exógena, como casos presa-predador. Por exemplo, o Lince Canadense (Canadian lynx) foi exaustivamente estudado, consulte o conjunto de dados R lynx, e a série é normalmente usada para demonstrar o ajuste de modelos de limiar.
A presa do Lince varia de pequenos roedores a veados, com a Lebre sendo sua presa predominantemente favorita. Na verdade, em certas áreas, o Lince está tão intimamente ligado à Lebre que sua população aumenta e diminui conforme muda a população da Lebre, embora outras fontes de alimento possam ser abundantes. Nesse caso, parece razoável substituir \(X_{t-d}\) por \(Y_{t-d}\), onde \(Y_t\) é o tamanho da população de Lebre.
A popularidade dos modelos TAR se deve ao fato de serem relativamente simples de especificar, estimar e interpretar, em comparação com muitos outros modelos de série temporais não lineares. Além disso, apesar de sua aparente simplicidade, a classe de modelos TAR pode reproduzir muitos fenômenos não lineares. No exemplo a seguir, usamos esse métodos para ajustar um modelo de limiar para a série mensal de mortes por pneumonia e influenza mencionadas anteriormente.
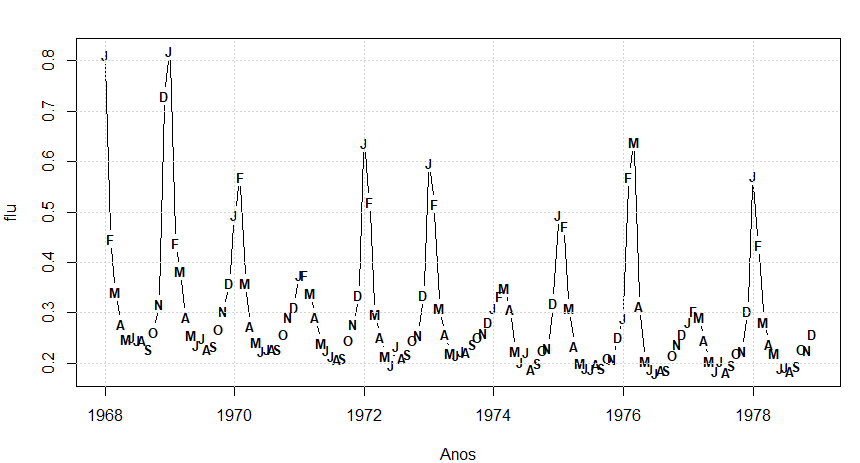
Figura V.7: Mortes mensais por pneumonia e influenza nos EUA por 10.000.
Como discutido anteriormente, o exame da Figura V.7 nos leva a acreditar que a série temporal de mortes mensais por pneumonia e influenza, digamos \(flu_t\), não é linear. Também é evidente na Figura V.7 que há uma ligeira tendência negativa nos dados. Descobrimos que a maneira mais conveniente de ajustar um modelo de limiar a esses dados, enquanto removemos a tendência, é trabalhar com as primeiras diferenças. Os dados diferenciados, digamos \begin{equation*} X_t \, = \, flu_t \, - \, flut_{t-1} \end{equation*} são exibidos na Figura V.9 como pontos (+) representando as observações.
A não linearidade dos dados é mais pronunciada no gráfico das primeiras diferenças \(X_t\). Claramente, \(X_t\) sobe lentamente por alguns meses e, então, em algum momento no inverno, tem a possibilidade de pular para um grande número quando \(X_t\) exceder cerca de \(0.05\). Se o processo der um grande salto, ocorrerá uma diminuição significativa subsequente em \(X_t\).
Outro gráfico revelador é o gráfico de defasagem de \(X_t\) versus \(X_{t-1}\) mostrado na Figura V.8, que sugere a possibilidade de dois regimes lineares baseados se \(X_{t-1}\) excede ou não 0.05.
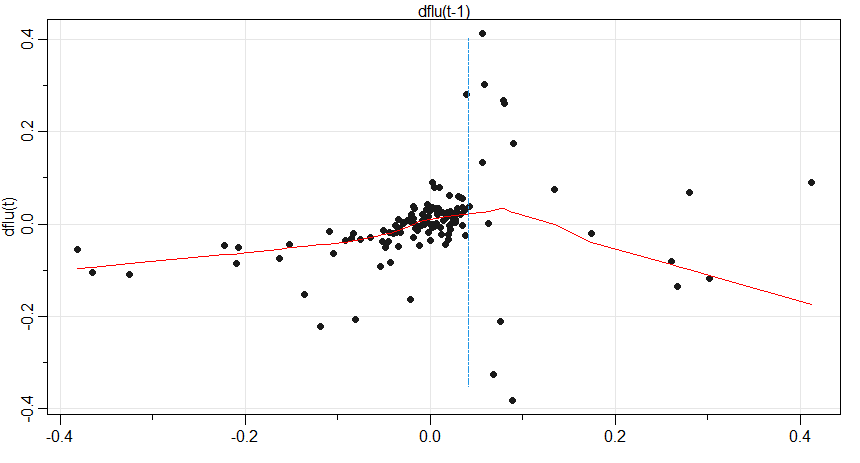
Figura V.8: Gráfico de dispersão de \(dflu_t = flu_t - flu_{t-1}\) versus \(dflu_{t-1}\) com um ajuste lowess sobreposto (linha). Uma linha tracejada vertical indica \(dflu_{t-1} = 0.05\).
Como uma análise inicial, ajustamos o seguinte modelo de limiar \begin{array}{rcl} X_t & = & \displaystyle \alpha^{(1)} \, + \, \sum_{j=1}^p \phi_j^{(1)} X_{t-j} \, + \, W_t^{(1)}, \qquad X_{t-1}< 0.05; \\ X_t & = & \displaystyle \alpha^{(2)} \, + \, \sum_{j=1}^p \phi_j^{(2)} X_{t-j} \, + \, W_t^{(2)}, \qquad X_{t-1}\geq 0.05, \end{array} com \(p = 6\), assumindo que seria maior do que o necessário. O modelo acima é fácil de ajustar usando duas execuçães de regressão linear, uma quando \(X_t <0.05\) e a outra quando \(X_t\geq 0.05\). Os detalhes são fornecidos no código R no final deste exemplo.
Usando o modelo final, as previsões com um mês de antecedência podem ser feitas e são mostradas na Figura 5.9 como uma linha. O modelo se sai extremamente bem em prever uma epidemia de gripe; o pico em 1976, no entanto, foi perdido por este modelo. Quando ajustamos um modelo com um limiar menor de: 04, as epidemias de gripe foram um tanto subestimadas, mas a epidemia de gripe no oitavo ano foi prevista um mês antes. Escolhemos o modelo com um limite de: 05 porque o diagnóstico residual não mostrou nenhum desvio óbvio da suposição do modelo (exceto para um outlier em 1976); o modelo com um limite de 0,04 ainda tinha alguma correlação restante nos resíduos e havia mais de um outlier. Finalmente, a previsão para além de um mês de antecedência para este modelo é complicada, mas existem algumas técnicas aproximadas (ver Tong, 1983).
Os seguintes comandos podem ser usados para realizar esta análise no R.
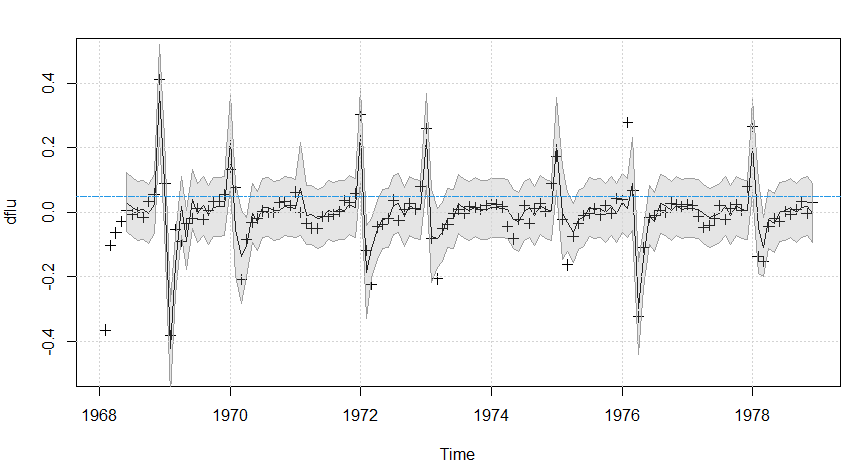
Figura V.9: Primeiras diferenças do número de mortes mensais por pneumonia e influenza nos EUA (+); previsões com um mês de antecedência (linha contínua) com \(\pm 2\) os limites de erro de previsão. A linha horizontal é o limiar.
Finalmente, notamos que existe um pacote R denominado tsDyn que pode ser usado para ajustar esses modelos; presumimos que o dflu já existe.
O limite encontrado aqui é 0.036, que inclui algumas observações a mais do que usando 0.04, mas sofre das mesmas desvantagens observadas anteriormente.
Na Seção IV.8, consideramos a regressão defasada em uma abordagem no domínio da frequência com base na coerência. Por exemplo, considere as séries de SOI e Recrutamento que foram analisadas no Exemplo IV.24; as séries são exibidas na Figura I.5. Nesse exemplo, o interesse estava em prever a série de Recrutamento como a saída, digamos \(Y_t\), a partir do SOI como entrada, digamos \(X_t\). Consideramos o modelo de regressão defasado como \begin{equation*} Y_t \, = \, \sum_{j=0}^\infty \alpha_j X_{t-j} \, + \, \eta_t \, = \, \alpha(B)X_t \, + \, \eta_t, \end{equation*} onde \(\sum_j |\alpha_j|<\infty\). Assumimos que o processo de entrada \(X_t\) e o processo de ruído \(\eta_t\) acima são estacionários e mutuamente independentes. Os coeficientes \(\alpha_0,\alpha_1,\cdots\) descrevem os pesos atribuídos aos valores anteriores de \(X_t\) usados na previsão de \(Y_t\) e usamos a notação \begin{equation*} \alpha(B) \, = \, \sum_{j=0}^\infty \alpha_j B^j\cdot \end{equation*}
Na formulação de Box and Jenkins (1970), atribuímos modelos \(ARIMA(p,d,q)\) e \(ARIMA(p_\eta,d_\eta,q_\eta)\), às séries \(X_t\) e \(\eta_t\), respectivamente. Na Seção IV.8, assumimos que o ruído \(\eta_t\), era ruído branco. Os componentes em notação de retrocesso, para o caso simple \(ARMA(p,q)\) modelando da entrada e no ruído, teria a representação \begin{equation*} \phi(B)X_t \, = \, \theta(B)W_t \qquad \mbox{e} \qquad \phi_\eta(B)\eta_t \, = \, \theta_\eta(B)Z_t, \end{equation*} onde \(W_t\) e \(Z_t\) são processos de ruído branco independentes com variâncias \(\sigma_{_W}^2\) e \(\sigma_{_Z}^2\), respectivamente.
Box and Jenkins (1970) propuseram que padrões sistemáticos frequentemente observados nos coeficientes \(\alpha_j\); para \(j = 1,2,\cdots\), muitas vezes pode ser expressos como uma proporção de polinômios envolvendo um pequeno número de coeficientes, juntamente com um atraso especificado \(d\), então \begin{equation*} \alpha(B) \, = \, \dfrac{\delta(B)B^d}{\omega(B)}, \end{equation*} onde \begin{equation*} \omega(B) \, = \, 1-\omega_1 B -\omega_2 B^2 - \cdots - \omega_r B^r \end{equation*} e \begin{equation*} \delta(B) \, = \, \delta_0+\delta_1 B + \cdots + \delta_s B^s \end{equation*} são os operadores indicados; nesta seção, achamos conveniente representar o operador inverso, digamos \(\omega(B)^{-1}\), como \(1/\omega(B)\).
Determinar um modelo parcimonioso envolvendo uma forma simples para \(\alpha(B)\) e estimar todos os parâmetros no modelo acima são as principais tarefas na metodologia da função de transferência. Devido ao grande número de parâmetros, é necessário desenvolver uma metodologia sequencial.
Suponha que nos concentremos primeiro em encontrar o modelo ARIMA para a entrada \(X_t\) e aplicando esse operador a ambos os lados na primeira equação nesta seção, obtendo o novo modelo \begin{equation*} \widetilde{Y}_t \, = \, \dfrac{\phi(B)}{\theta(B)}Y_t \, = \, \alpha(B)\dfrac{\phi(B)}{\theta(B)}X_t \, + \, \dfrac{\phi(B)}{\theta(B)}\eta_t \, = \, \alpha(B)W_t \, \widetilde{\eta}_t, \end{equation*} onde \(W_t\) e o ruído transformado \(\widetilde{\eta}_t\) são independentes.
A série \(W_t\) é uma versão pré-branqueada da série de entrada e sua correlação cruzada com a série de saída transformada \(\widetilde{Y}_t\) será \begin{equation*} \gamma_{_{\widetilde{Y},W}}(h) \, = \, \mbox{E}(\widetilde{Y}_{t+h}W_t) \, = \, \mbox{E}\left( \sum_{j=0}^\infty \alpha_j W_{t+h-j}W_t\right) \, = \, \sigma_{_W}^2 \alpha_h, \end{equation*} porque a função de autocovariância do ruído branco será zero, exceto quando \(j = h\) acima. Portanto, ao calcular a correlação cruzada entre a série de entrada pré-branqueada e a série de saída transformada, deve-se obter uma estimativa grosseira do comportamento de \(\alpha(B)\).
Damos um exemplo simples do procedimento sugerido para o SOI e a série de Recrutamento. A Figura V.10 mostra as funções ACF e PACF amostrais do SOI destendido e fica claro, a partir do PACF, que uma série autoregressiva com \(p = 1\) fará um trabalho razoável.
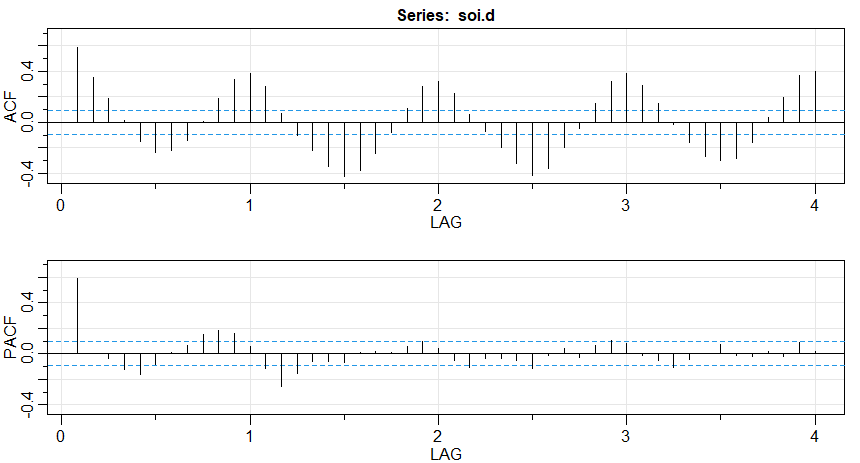
Figura V.10: Funções ACF e PACF da série SOI destendida.
Ajustando a série obtemos \(\widehat{\phi} = 0.588\) com \(\widehat{\sigma}_{_W}^2 = 0.092\), e aplicamos o operador \(1-0.588 B\) ambos, \(X_t\) e \(Y_t\) e calculamos a função de correlação cruzada, que é mostrada na Figura V.11.
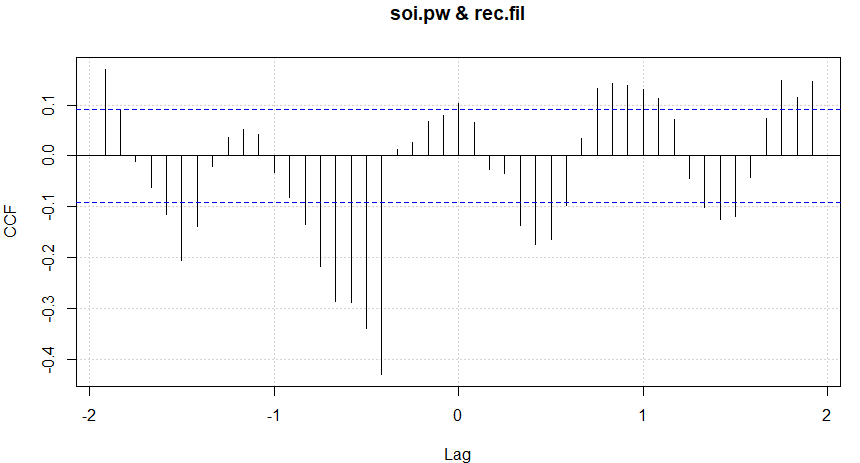
Figura V.11: CCF amostral da série SOI pré-branqueada, destendida e da série de recrutamento transformada de forma semelhante; atrasos negativos indicam que o SOI lidera o recrutamento.
Observando a mudança aparente de \(d = 5\) meses e a diminuição daí em diante, parece plausível levantar a hipótese de um modelo da forma \begin{equation*} \alpha(B) \, = \, \delta_0 B^5 (1+\omega_1 B+\omega_2 B^2+ \cdots ) \, = \, \dfrac{\delta_0 B^5}{1-\omega_1 B} \end{equation*} para a função de transferência. Nesse caso, esperaríamos que \(\omega_1\) fosse negativo.
No código acima soi.pw representa a série SOI destendida pré-branqueada e rec.fil representa a série de Recrutamento filtrada.
Em alguns casos, podemos postular a forma dos componentes separados \(\delta(B)\) e \(\omega(B)\), então podemos escrever a equação \begin{equation*} Y_t \, = \, \dfrac{\delta(B)B^d}{\omega(B)} X_t \, + \, \eta_t \end{equation*} como \begin{equation*} \omega(B)Y_t \, = \, \delta(B)B^d X_t \, + \, \omega(B)\eta_t, \end{equation*} ou em forma de modelo de regressão \begin{equation*} Y_t \, = \, \sum_{k=1}^r \omega_k Y_{t-k} \, + \, \sum_{k=0}^s \delta_k X_{t-d+k} \, + \, U_t, \end{equation*} onde \(U_t = \omega(B)\eta_t\).
Assim que tivermos \(Y_t\), será fácil ajustar o modelo se esquecermos \(\eta_t\) e permitirmos que \(U_t\) tenha qualquer comportamento ARMA. Ilustramos essa técnica no exemplo a seguir.
Ilustramos o procedimento para ajustar um modelo de regressão defasado da forma sugerida no Exemplo V.8 para a série SOI destendida \(X_t\) e a série de Recrutamento \(Y_t\).
Os resultados relatados aqui são praticamente os mesmos que os resultados obtidos a partir da abordagem no domínio da frequência usada no Exemplo IV.24.
Com base no Exemplo V.8, determinamos que \begin{equation*} Y_t \, = \, \alpha + \omega_1 Y_{t-1} +\delta_0 X_{t-5} + U_t \end{equation*} é um modelo razoável.
Neste ponto, simplesmente rodamos a regressão permitindo erros autocorrelacionados com base nas técnicas discutidas na Seção III.8. Com base nessas técnicas, o modelo ajustado é o mesmo obtido no Exemplo IV.24, a saber, \begin{equation*} Y_t \, = \, 12.3323 + 0.8005 Y_{t-1}-21.0307 X_{t-5} +U_t \qquad \mbox{e} \qquad U_t \, = \, 0.4487 U_{t-1}+W_t, \end{equation*} onde \(W_t\) é um ruído branco com \(\widehat{\sigma}_{_W}^2=49.93\).
Figura V.12a: CCF amostral da série SOI pré-branqueada, destendida e da série de recrutamento transformada de forma semelhante; atrasos negativos indicam que o SOI lidera o recrutamento.
A Figura 5.12a mostra as funções ACF e PACF amostrais do ruído \(U_t\) estimado, mostrando que um \(AR(1)\) é apropriado. Além disso, a Figura V.12c exibe a série de Recrutamento e as previsões de um passo à frente com base no modelo final.
Figura V.12b: CCF amostral da série SOI pré-branqueada, destendida e da série de recrutamento transformada de forma semelhante; atrasos negativos indicam que o SOI lidera o recrutamento.
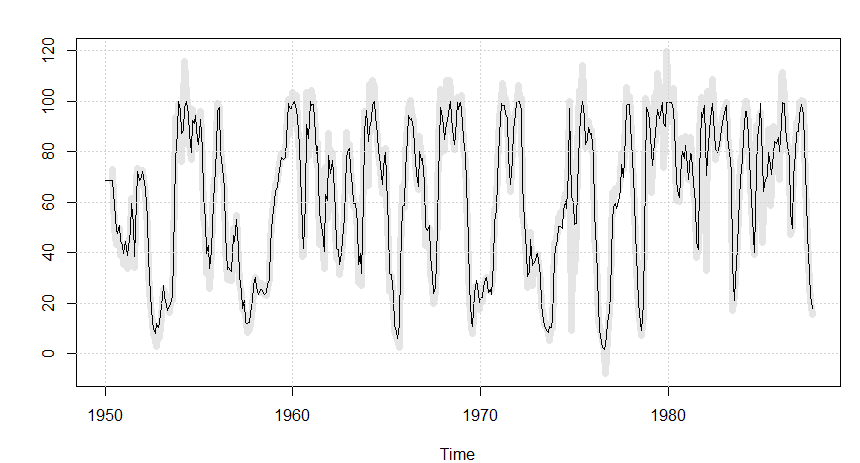
Figura V.12c: A série de recrutamento (linha) e as previsões de um passo à frente (amostra cinza) com base no modelo de função de transferência final.
Para completar, concluímos a discussão do método mais complicado de Box-Jenkins para ajustar modelos de função de transferência. Observamos, entretanto, que o método não tem otimização geral reconhecível e geralmente não é melhor ou pior do que o método discutido anteriormente.
A forma de \(Y_t\) sugere fazer uma regressão nas versões defasadas de ambas as séries de entrada e saída para obter \(\widehat{\beta}\), a estimativa do vetor de regressão \((r + s + 1)\times 1\) \begin{equation*} \beta \, = \, (\omega_1,\cdots,\omega_r,\delta_0,\delta_1,\cdots,\delta_s)^\top \cdot \end{equation*} Os resíduos da regressão, digamos, \begin{equation*} \widehat{U}_t \, = \, Y_t - \widehat{\beta}^\top Z_t, \end{equation*} onde \begin{equation*} Z_t \, = \, (Y_{t-1},\cdots,Y_{t-r},X_{t-d},\cdots,X_{t-d-s})^\top \end{equation*} denota o vetor usual de variáveis independentes, poderia ser usado para aproximar o melhor modelo ARMA para o processo de ruído \(\eta_t\), porque podemos calcular um estimador para esse processo usando \(\widehat{U}_t\) e \(\widehat{\omega}(B)\) e aplicando o operador de média móvel para obter \(\widehat{\eta}_t\). Ajustando um modelo \(ARMA(p_\eta,q_\eta)\) para este ruído estimado então completa a especificação. O anterior sugere o seguinte procedimento sequencial para ajustar o modelo da função de transferência aos dados.
O procedimento acima é bastante razoável mas, como mencionado anteriormente, não é ideal em nenhum sentido. A estimação simultânea de mínimos quadrados, com base em \(X_t\) e \(Y_t\) observados, pode ser realizada observando que o modelo de função de transferência pode ser escrito como \begin{equation*} Y_t \, = \, \dfrac{\delta(B)B^d}{\omega(B)} X_t \, + \, \dfrac{\theta_\eta(B)}{\phi_\eta(B)}Z_t, \end{equation*} que pode ser colocado na forma \begin{equation*} \omega(B)\phi_\eta(B)Y_t \, = \, \phi_\eta(B)\delta(B)B^d X_t \, + \, \omega(B)\theta_\eta(B)Z_t \end{equation*} e é claro que podemos usar mínimos quadrados para minimizar \(\sum_t Z_t^2\), como nas seç&aotilde;es anteriores.
No Exemplo V.9, simplesmente permitimos que \begin{equation*} U_t\dfrac{\theta_\eta(B)}{\phi_\eta(B)}Z_t \end{equation*} acima tivesse qualquer estrutura ARMA. Finalmente, mencionamos que também podemos expressar a função de transferência na forma de espaço de estados como um modelo ARMAX; consulte a Seção V.6 a seguir e a Seção VI.6.1.
Para compreender os modelos de séries temporais multivariadas e suas capacidades, apresentamos primeiro uma introdução às técnicas de regressão de séries temporais multivariadas. Como todos os processos são vetores, suspendemos o uso de negrito para vetores. Uma extensão útil do modelo básico de regressão univariada apresentado na Seção II.1 é o caso em que temos mais de uma série de resultados, isto é, análise de regressão multivariada.
Suponha, em vez de uma única variável resposta \(Y_t\), que existe uma coleção de \(k\) variáveis resposta \(Y_{t1}, Y_{t2},\cdots,Y_{tk}\) as quais estão relacionados às entradas como \begin{equation*} Y_{ti} \, = \, \beta_{i1}Z_{t1} + \beta_{i2} Z_{t2}+\cdots + \beta_{ir}Z_{tr}+W_{ti} \end{equation*} para cada uma das \(i = 1,2,\cdots,k\) variáveis de saída.
Assumimos que as variáveis \(W_{ti}\) são correlacionadas sobre o identificador de variável \(i\), mas ainda são independentes ao longo do tempo. Formalmente, assumimos \(\mbox{Cov}(W_{si},W_{tj}) = \sigma_{ij}\) para \(s = t\) e é zero caso contrário. Então, escrevendo a expressão acima em notação matricial, com \(Y_t = (Y_{t1},Y_{t2},\cdots,Y_{tk})^\top \) sendo o vetor de respostas ou saías e \(B = \{\beta_{ij}\}\), \(i=1,\cdots,k\) e \(j=1,\cdots,r\) sendo uma matriz \(k\times r\) contendo os coeficientes de regressão, leva à forma de aparência simples \begin{equation*} Y_t \, = \, BZ_t \, + \, W_t\cdot \end{equation*}
Aqui, o processo \(k\times 1\) vetorial \(W_t\) é assumido como uma coleção de vetores independentes com matriz de covariâncias comum \(\mbox{E}(W_t W_t^\top)=\Sigma_{_W}\), a matriz \(k\times k\) contendo as covariâncias \(\sigma_{ij}\). Sob a suposição de normalidade, o estimador de máxima verossimilhança para a matriz de regressão é \begin{equation*} \widehat{B} \, = \, \left(\sum_{t=1}^n y_tz_t^\top \right)\left(\sum_{t=1}^n z_tz_t^\top \right)^{-1}\cdot \end{equation*}
A matriz de covariâncias do erro \(\Sigma_{_W}\) é estimada por \begin{equation*} \widehat{\Sigma}_{_W} \, = \, \dfrac{1}{n-r}\sum_{t=1}^n (y_t-\widehat{B}z_t)(y_t-\widehat{B}z_t)^\top\cdot \end{equation*}
A incerteza nos estimadores pode ser avaliada a partir de \begin{equation*} se\big( \widehat{\beta}_{ij}\big) \, = \, \sqrt{c_{ii}\widehat{\sigma}_{jj}}, \end{equation*} para \(i=1,\cdots,r\) e \(j=1,\cdots,k\), onde se denota o erro padrão estimado \(\widehat{\sigma}_{jj}\), o \(j\)-ésimo elemento da diagonal de \(\widehat{\Sigma}_{_W}\) e \(c_{ii}\) é o \(i\)-ásimo elemento da diagonal de \((\sum_{t=1}^n z_tz_t^\top)^{-1}\).
Além disso, o Critéio de Informação e Akaike muda para \begin{equation*} AIC \, = \, \ln\Big(|\widehat{\Sigma}_{_W}|\Big) \, + \, \dfrac{2}{n}\left(kr+\dfrac{k(k+1)}{2}\right) \end{equation*} e o \(BIC\) substitui o segundo termo da expressão acima por \(K\ln(n)/n\) onde \(K = kr + k(k + 1)/2\). Bedrick and Tsai (1994) forneceram uma expressão para o AIC corrigido no caso multivariado como \begin{equation*} AICc \, = \, \ln\Big(|\widehat{\Sigma}_{_W}|\Big) \, + \, \dfrac{k(r+n)}{n-k-r-1}\cdot \end{equation*}
Muitos conjuntos de dados envolvem mais de uma série temporal e muitas vezes estamos interessados nas possíveis dinâmicas relacionadas a todas as séries. Nesta situação, estamos interessados em modelar e prever \(k\times 1\) séries temporais com valor vetorial \(X_t=(X_{t1},\cdots,X_{tk})^\top\), \(t=0,\pm 1, \pm 2,\cdots\).
Infelizmente, estender modelos ARMA univariados para o caso multivariado não é tão simples. O modelo multivariado autorregressivo, entretanto, é uma extensão direta do modelo AR univariado.
Para o modelo autoregressivo vetorial de primeira ordem \(VAR(1)\), temos \begin{equation*} X_t \, = \, \alpha +\Phi X_{t-1}+W_t, \end{equation*} onde \(\Phi\) é uma matriz \(k\times k\) de transição que expressa a dependência de \(X_t\) em \(X_{t-1}\). O processo de ruído branco vetorial \(W_t\) é considerado normal multivariado com média zero e matriz de covariâncias \begin{equation*} \mbox{E}\big(W_t W_t^\top \big) \, = \, \Sigma_{_W}\cdot \end{equation*}
O vetor \(\alpha=(\alpha_1,\alpha_2,\cdots,\alpha_k)^\top\) aparece como a constante na configuração da regressão. Se \(\mbox{E}(X_t)=\mu\), então \(\alpha=(\mbox{I}-\Phi)\mu\).
Observe a semelhança entre o modelo \(VAR\) e o modelo de regressão linear multivariado anteriormente apresentado, nesta mesma seção. As fórmulas de regressão continuam e podemos, ao observar \(x_1,\cdots,x_n\), configurar o modelo \(VAR(1)\) com \(y_t = x_t\), \(B = (\alpha,\Phi)\) e \(z_t = (1,x_{t-1}^\top)^\top\). Então, a estimativa de máxima verossimilhança condicional para a matriz de covariâncias é dada por \begin{equation*} \widehat{\Sigma}_{_W} \, = \, \dfrac{1}{n-1}\sum_{t=2}^n (x_t-\widehat{\alpha}-\widehat{\Phi}x_{t-1})(x_t-\widehat{\alpha}-\widehat{\Phi}x_{t-1})^\top\cdot \end{equation*}
A forma especial assumida para a componente constante \(\alpha\), do modelo vetorial \(AR\) pode ser generalizada para incluir um vetor \(r\times 1\) fixo de entradas \(U_t\). Ou seja, poderíamos ter proposto o modelo vetorial \(ARX\), \begin{equation*} X_t \, = \, \Gamma U_t \, + \, \sum_{j=1}^P \Phi_j X_{t-j} \, + \, W_t, \end{equation*} onde \(\Gamma\) é a matriz \(p\times r\) de parâmetros.
O X em ARX refere-se ao processo vetorial exógeno que denotamos aqui por \(U_t\). A introdução de variáveis exógenas através de substituir \(\alpha\) por \(\Gamma U_t\) não apresenta nenhum problema especial em fazer inferências e frequentemente deixaremos o \(X\) de lado por ser supérfluo.
Por exemplo, para a série tridimensional composta de mortalidade cardiovascular \(X_{t1}\), temperatura \(X_{t2}\) e níveis de partículas \(X_{t3}\), introduzida no Exemplo II.2, definamos \(X_t = (X_{t1}, X_{t2}, X_{t3})\) como um vetor de dimensão \(k = 3\). Podemos imaginar relações dinâmicas entre as três séries definidas como a relação de primeira ordem, \begin{equation*} X_{t1} \, = \, \alpha_1 +\beta_1 t +\phi_{11} X_{t-1,1} + \phi_{12}X_{t-1,2} + \phi_{13} X_{t-1,3} +W_{t1}, \end{equation*} que expressa o valor atual da mortalidade como uma combinação linear de tendência e seu valor passado imediato e os valores anteriores de temperatura e níveis de partículas. Similarmente, \begin{equation*} X_{t2} \, = \, \alpha_2 +\beta_2 t +\phi_{21} X_{t-1,1} + \phi_{22}X_{t-1,2} + \phi_{23} X_{t-1,3} +W_{t2} \end{equation*} e \begin{equation*} X_{t3} \, = \, \alpha_3 +\beta_3 t +\phi_{31} X_{t-1,1} + \phi_{32}X_{t-1,2} + \phi_{33} X_{t-1,3} +W_{t3}, \end{equation*} expressam a dependência da temperatura e dos níveis de partículas nas outras séries. Claro, existem métodos para a identificação preliminar desses modelos e discutiremos esses métodos em breve.
O modelo ARX acima é \begin{equation*} X_t \, = \, \Gamma U_t + \Phi X_{t-1} + W_t, \end{equation*} onde \(\Gamma = (\alpha | \beta)\) é \(3\times 2\) e \(U_t = (1,t)^\top\) é \(2\times 1\).
Ao longo de grande parte desta se¸ão, usaremos o pacote R vars para ajustar modelos AR vetoriais por meio de mínimos quadrados.
Para este caso particular, obtemos \(\widehat{\alpha} \, = \, (73.23, 67.59, 67.46)^\top\), \(\widehat{\beta} \, = \, (-0.014, -0.007, -0.005)^\top\), \begin{equation*} \widehat{\Phi} \, = \, \begin{pmatrix} 0.46_{(0.04)} & -0.36_{(0.03)} & 0.10_{(0.02)} \\ -0.24_{(0.04)} & 0.49_{(0.04)} & -0.13_{(0.02)} \\ -0.12_{(0.08)} & -0.48_{(0.07)} & 0.58_{(0.04)} \end{pmatrix} \qquad \mbox{e} \qquad \widehat{\Sigma} \, = \, \begin{pmatrix} 31.17 & 5.98 & 16.65 \\ 5.98 & 40.96 & 42.32 \\ 16.65 & 52.32 & 144.26 \end{pmatrix}, \end{equation*} onde os erros padrão são dados entre parênteses.
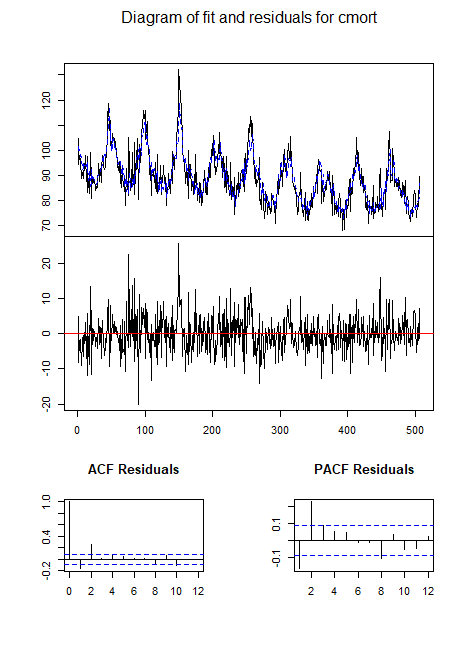 | 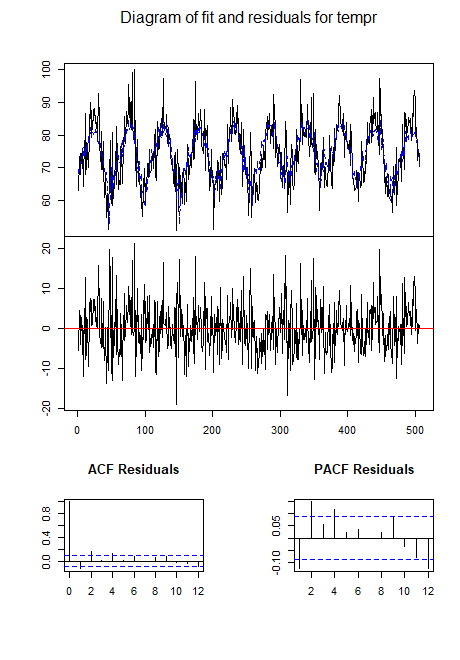 |
|---|
Para o vetor \(X_{t1},X_{t2},X_{t3}) = (M_t,T_t,P_t)\), com \(M_t\), \(T_t\) e \(P_t\) denotando mortalidade, temperatura e nível de particulado, respectivamente, obtemos a equação de predição para mortalidade, \begin{equation*} \widehat{M}_t \, = \, 73.23 -0.014 t + 0.46 M_{t-1} -0.36 T_{t-1}+0.10 P_{t-1}\cdot \end{equation*} Comparando a mortalidade observada e prevista com este modelo leva a um \(R^2\) de cerca de 0.69.
Pode-se estender o processo \(VAR(1)\) para ordens superiores, \(VAR(p)\). Para fazer isso, escrevemos o vetor de regressores como \begin{equation*} Z_t \, = \, (1, X_{t-1}^\top, X_{t-2}^\top,,\cdots,X_{t-p}^\top)^\top \end{equation*} e a matriz de regressão como \(B = (\alpha,\Phi_1,\Phi_2,\cdots,\Phi_p)\). Então, este modelo de regressão pode ser escrito como \begin{equation*} X_t \, = \, \alpha + \sum_{j=1}^p \Phi_j X_{t-j}+W_t, \end{equation*} para \(t=p+1,\cdots,n\).
A matriz \(k\times k\) de somas de produtos do erro torna-se \begin{equation*} SSE \, = \, \sum_{t=p+1}^n (x_t-Bz_t)(x_t-Bz_t)^\top, \end{equation*} de modo que o estimativa de máxima verossimilhança condicional para a matriz de covariâncias de erro \(\Sigma_{_W}\) é \begin{equation*} \widehat{\Sigma}_{_W} \, = \, \dfrac{SSE}{n-p}, \end{equation*} como no caso da regressão multivariada, exceto que agora apenas existem \(n-p\) resíduos.
Para o caso multivariado, descobrimos que o critério de Schwarz assume a forma \begin{equation*} BIC \, = \, \ln\Big(|\widehat{\Sigma}_{_W}|\Big) \, + \, \dfrac{k^2p}{n}\ln(n), \end{equation*} fornece classificações mais razoáveis do que o \(AIC\) ou \(AICc\), a versão corrigida. O resultado é consistente com os relatados nas simulações de Lütkepohl (1985).
Usamos o pacote R vars primeiro para selecionar um modelo \(VAR(p)\) e depois ajustar o modelo. Os critérios de seleção usados no pacote são \(AIC\), Hannan-Quinn (HQ; Hannan and Quinn, 1979), \(BIC\) (SC) e Erro de Previsão Final (FPE). O procedimento de Hannan-Quinn é semelhante ao \(BIC\), mas com \(\ln(n)\) substituído por \(2\ln\big(\ln(n)\big)\) no termo de penalização. O FPE encontra o modelo que minimiza o erro de predição um passo à frente do quadrado médio aproximado (ver Akaike, 1969 para detalhes); raramente é usado.
Observe que o \(BIC\) escolhe o modelo de ordem \(p = 2\) enquanto \(AIC\) e FPE selecionam um modelo de ordem \(p = 9\) e Hannan-Quinn seleciona um modelo de ordem \(p = 5\).
Ajustando o modelo selecionado pelo \(BIC\), obtemos \(\widehat{\alpha}=(56.10,49.88,59.58)\), \(\widehat{\beta}=(-0.011,-0.005,-0.008)\), \begin{array}{c} \widehat{\Phi}_1 \, = \, \begin{pmatrix} 0.30_{(0.04)} & -0.20_{(0.04)} & 0.04_{(0.02)} \\ -0.11_{(0.05)} & 0.26_{(0.05)} & -0.05_{(0.03)} \\ 0.08_{(0.09)} & -0.39_{(0.09)} & 0.39_{(0.05)} \end{pmatrix}, \\ \widehat{\Phi}_2 \, = \, \begin{pmatrix} 0.28_{(0.04)} & -0.08_{(0.03)} & 0.07_{(0.03)} \\ -0.04_{(0.05)} & 0.36_{(0.05)} & -0.10_{(0.03)} \\ -0.33_{(0.09)} & 0.05_{(0.09)} & 0.38_{(0.05)} \end{pmatrix}, \end{array} sendo que os erros padrão são fornecidos entre parênteses. A estimative de \(\Sigma_{_W}\) é \begin{equation*} \widehat{\Sigma}_{_W} \, = \, \begin{pmatrix} 28.03 & 7.08 & 16.33 \\ 7.08 & 37.63 & 40.88 \\ 16.33 & 40.88 & 123.45 \end{pmatrix}\cdot \end{equation*}
Para ajustar o modelo usando o pacote vars, use o seguinte:
Usando a notação do exemplo anterior, o modelo de predição para mortalidade cardiovascular é estimado como \begin{equation*} \widehat{M}_t \, = \, 56-0.11t +0.3 M_{t-1}-0.2 T_{t-1} +0.04 P_{t-1} +0.28 M_{t-2} -0.08 T_{t-2} +0.07 P_{t-2}\cdot \end{equation*}
Para examinar os resíduos, podemos representar graficamente as correlações cruzadas dos resíduos e examinar a versão multivariada do teste Q da seguinte forma:
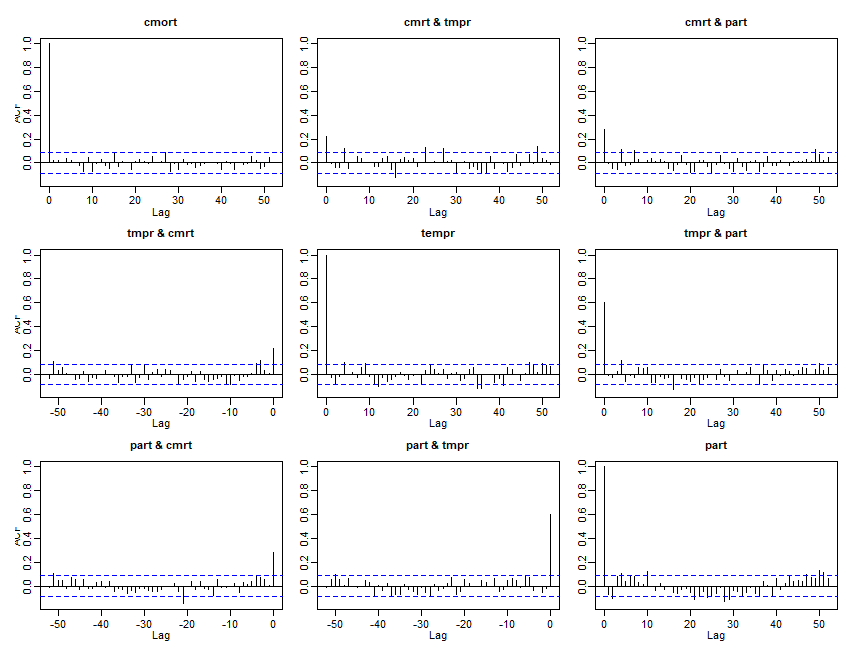
Figura V.13: Na diagonal, funções de autocorrelação (ACFs) e fora das diagonais, funções de correlação cruzada para os resíduos do \(VAR(2)\) tridimensional, ajustado ao conjunto de dados de poluição, clima e mortalidade em LA. Fora da diagonal, a série com o segundo nome é aquela que lidera.
A matriz de correlação cruzada é mostrada na Figura V.13. A figura mostra os ACFs das séries de resíduos individuais ao longo da diagonal. Por exemplo, o primeiro gráfico diagonal é o ACF de \(M_t -\widehat{M}_t\) e assim por diante. As diagonais externas exibem os CCFs entre pares de séries de resíduos. Se o título do graacute;fico fora da diagonal for \(x \, \& \, y\), então \(y\) lidera o gráfico; isto é, na diagonal superior, o gráfico mostra \(\mbox{Corr}\big(x(t+Lag), y(t)\big)\), enquanto na diagonal inferior, se o título for \(x \, \& \, y\), você obtém um gráfico de \(\mbox{Corr}\big(x( t + Lag), y(t)\big)\) sim, é a mesma coisa, mas as defasagens são negativas na diagonal inferior. O gráfico está rotulado de forma estranha, basta lembrar que a segunda série com nome é a que lidera.
Na Figura V.13, notamos que a maioria das correlações nas séries de resíduos são desprezíveis, no entanto, a correlação de ordem zero da mortalidade com os resíduos de temperatura é de cerca de 0.22 e a mortalidade com resíduos de particulados é de cerca de 0.28, tipo
A estatística do teste Q é dada por \begin{equation*} Q \, = \, n^2\sum_{h=1}^H \dfrac{1}{n-h} \mbox{tr}\left( \widehat{\Gamma}_{_W}(h){\widehat{\Gamma}_{_W}(0)}^{-1}\widehat{\Gamma}_{_W}(h){\widehat{\Gamma}_{_W}(0)}^{-1} \right), \end{equation*} onde \begin{equation*} \widehat{\Gamma}_{_W}(h) \, = \, \dfrac{1}{n}\sum_{t=1}^{n-h} \widehat{W}_{t+h} \widehat{W}_t^\top, \end{equation*} e \(\widehat{W}_{t}\) é o processo residual. Sob a hipóteses nula de que \(W_t\) é ruído branco, a estatístia Q tem distribuição assintótica \(\chi^2\) com \(k^2(H-p)\) graus de liberdade.
Finalmente, a previsão segue de uma maneira direta do caso univariado. Usando o pacote R vars, use o comando predict e o comando fanchart, que produz um bom gráfico:
Figura V.14: As previsões de um \(VAR(2)\) ajustado aos dados de mortalidade - poluição em LA.
Obviamente, a estimação via Yule-Walker, mínimos quadrados incondicionais e MLE seguem diretamente das contrapartes univariadas. Para modelos \(VAR(p)\) puros, a estrutura de autocovariância leva à versão multivariada das equações de Yule-Walker: \begin{array}{c} \Gamma(h) \, = \, \displaystyle \sum_{j=1}^P \Phi_j \Gamma(h-j), \qquad h=1,2,\cdots, \\ \Gamma(0) \, = \, \displaystyle \sum_{j=1}^P \Phi_j \Gamma(-j)+\Sigma_{_W}, \end{array} onde \(\Gamma(h)=\mbox{Cov}(X_{t+h},X_t)\) é uma matriz \(k\times k\) e \(\Gamma(-h)=\Gamma(h)^\top\).
A estimativa da matriz de autocovariância é semelhante ao caso univariado, ou seja, com \(\overline{x}=\frac{1}{n}\sum_{t=1}^n x_t\) como estimativa de \(\mu=\mbox{E}(X_t)\), \begin{equation*} \widehat{\Gamma}(h) \, = \, \dfrac{1}{n}\sum_{t=1}^{n-h} (x_{t+h}-\overline{x})(x_{t+h}-\overline{x})^\top, \qquad h=0,1,2,\cdots,n-1, \end{equation*} e \(\widehat{\Gamma}(-h)=\widehat{\Gamma}(h)^\top\).
Se \(\widehat{\gamma}_{i,j}(h)\) denota o elemento na \(i\)-ésima linha e \(j\)-ésima coluna de \(\widehat{\Gamma}(h)\), as funções de correlação cruzada (CCF), conforme discutido na Seção I.3, são estimadas por \begin{equation*} \widehat{\rho}_{i,j}(h) \, = \, \dfrac{\widehat{\gamma}_{i,j}(h)}{\sqrt{\widehat{\gamma}_{i,i}(0)\widehat{\gamma}_{j,j}(0)}}, \qquad h=0,1,2,\cdots,n-1\cdot \end{equation*} Quando \(i = j\) na expressão acima, obtemos a função de autocorrelação estimada (ACF) das séries individuais.
Embora a estimação por mínimos quadrados tenha sido usada no Exemplo V.10 e no Exemplo V.11, poderíamos também ter usado a estimação de Yule-Walker, estimação por máxima verossimilhança condicional ou incondicional. Como no caso univariado, os estimadores de Yule-Walker, os estimadores de máxima verossimilhança e os estimadores de mínimos quadrados são assintoticamente equivalentes.
Para exibir a distribuição assintótica dos estimadores dos parâmetros de autorregressão, escrevemos \begin{equation*} \phi \, = \, \mbox{vec}(\Phi_1,\cdots,\Phi_P), \end{equation*} onde o operador \(\mbox{vec}\) empilha as colunas de uma matriz em um vetor. Por exemplo, para um modelo bivariado \(AR(2)\), \begin{equation*} \phi \, = \, \mbox{vec}(\Phi_1,\phi_2) \, = \, (\Phi_{1_{11}},\Phi_{1_{21}},\Phi_{1_{12}},\Phi_{1_{22}},\Phi_{2_{11}},\Phi_{2_{21}},\Phi_{2_{12}},\Phi_{2_{22}})^\top, \end{equation*} onde \(\Phi_{l_{ij}}\) é o \(ij\)-ésimo elemento de \(\Phi_l\), \(l=1,2,\cdots\).
Denotemos por \(\widehat{\phi}\) o vetor de estimadores dos parâmetros obtidos via Yule – Walker, mínimos quadrados ou máxima verossimilhança para um modelo \(AR(p)\) \(k\)-dimensional. Então, \begin{equation*} \sqrt{n}\big(\widehat{\phi}-\phi\big) \, \sim \, \displaystyle AN\big(0,\Sigma_{_W}⊗ \Gamma_{PP}^{-1}\big), \end{equation*} onde \(\Gamma_{PP}=\{\Gamma(i-j)\}_{i,j=1}^P\) é uma matriz \(kp\times kp\) e \(\Sigma_{_W}⊗ \Gamma_{PP}^{-1}=\{\sigma_{ij}\Gamma_{PP}^{-1}\}_{i,l=1}^k\) é uma matriz \(k^2p\times k^2p\) com \(\sigma_{i,j}\) denotando o \(ij\)-ésimo elemento de \(\Sigma_{_W}\).
A matriz de variâncias-covariâncias do estimador \(\widehat{\phi}\) é aproximada substituindo \(\Sigma_{_W}\) por \(\widehat{\Sigma}_{_W}\), e substituindo \(\Gamma(h)\) por \(\widehat{\Gamma}(h)\) em \(\Gamma_{PP}\). A raiz quadrada dos elementos diagonais de \(\Sigma_{_W}⊗ \Gamma_{PP}^{-1}\) dividida por \(\sqrt{n}\) fornece os erros padrão individuais.
Para o exemplo de dados de mortalidade, os erros padrão estimados para o ajuste \(VAR(2)\) estão listados no Exemplo V.11; embora esses erros padrão tenham sido obtidos de uma execução de regressão, eles também poderiam ter sido calculados usando o Teorema V.1.
A série temporal vetorial \(X_t\) de dimensão \(k\times 1\), para \(t = 0,\pm 1,\pm 2,\cdots\) &reaute; dita ser \(VARMA(p,q)\) se \(X_t\) for estacionária e \begin{equation*} X_t \, = \, \alpha+\Phi_1X_{t-1}+\cdots+\Phi_p X_{t-p}+W_t+\Theta_1 W_{t-1}+\cdots+\Theta_q W_{t-q}, \end{equation*} com \(\Phi_p\neq 0\), \(\Theta_q\neq 0\) e \(\Sigma_{_W}> 0\), ou seja, \(\Sigma_{_W}\) é definida positivo.
As matrizes de coeficientes \(\Phi_j\), \(j = 1,\cdots,p\) e \(\Theta_j\), \(j = 1,\cdots,q\) são, é claro, matrizes \(k\times k\). Se \(X_t\) tiver média \(\mu\), então \(\alpha=(\mbox{I}-\Phi_1-\cdots-\Phi_p)\mu\). Como no caso univariado, teremos que colocar uma série de condições no modelo ARMA multivariado para garantir que o modelo seja único e tenha propriedades desejáveis, como causalidade. Essas condições serão discutidas em breve.
Como no modelo VAR, a forma especial assumida para o componente constante pode ser generalizada para incluir um vetor de entradas \(r\times 1\) fixo, \(U_t\). Ou seja, poderíamos ter proposto o modelo vetorial ARMAX, \begin{equation*} X_t \, = \, \Gamma U_t \, + \, \sum_{j=1}^p \Phi_j X_{t-j} \, + \ \sum_{j=1}^q \Theta_j W_{t-j} \, + \, W_t, \end{equation*} onde \(\Gamma\) é uma matriz \(p\times r\) de parâmetros.
Embora estender modelos AR univariados ou MA puros para o caso vetorial seja bastante fácil, estender modelos ARMA univariados para o caso multivariado não é uma questão simples. Nossa discussão será breve, mas os leitores interessados podem obter mais detalhes em Lütkepohl (1993), Reinsel (1997) e Tiao and Tsay (1989).
No caso multivariado, o operador autoregressivo assume a forma \begin{equation*} \Phi(B) \, = \, \mbox{I}-\Phi_1 B-\cdots-\Phi_p B^p, \end{equation*} e o operador de médias móveis é \begin{equation*} \Theta(B) \, = \, \mbox{I}+\Theta_1 B + \cdots +\Theta_q B^q\cdot \end{equation*}
O modelo \(VARMA(p,q)\) de média zero é então escrito de forma concisa como \begin{equation*} \Phi(B)X_t \, = \, \Theta(B)W_t\cdot \end{equation*}
O modelo é considerado causal se as raízes de \(|\Phi(z)|\), onde \(|\cdot|\) denota o determinante, estão fora do círculo unitário \(|z|> 1\); isto é \(|\Phi(z)|\neq 0\) para qualquer valor \(z\) tal que \(|z|\leq 1\). Neste caso, podemos escrever \begin{equation*} X_t \, = \, \Psi(B)W_t, \end{equation*} onde \(\displaystyle \Psi=\sum_{j=0}^\infty \Psi_j B^j\), \(\Psi_0=\mbox{I}\) e \(\displaystyle \sum_{j=0}^\infty ||\Psi_j ||<\infty \).
O modelo é considerado invertível se as raízes de \(|\Theta(z)|\) estiverem fora do círculo unitário. Então, podemos escrever \begin{equation*} W_t \, = \, \Pi (B)X_t, \end{equation*} onde \(\displaystyle \Pi(B)=\sum_{j=0}^\infty \Pi_j B^j\), \(\Pi_0=\mbox{I}\) e \(\displaystyle \sum_{j=0}^\infty ||\Pi_j||<\infty\).
Analogamente ao caso univariado, podemos determinar as matrizes \(\Psi_j\) resolvendo \(\Psi(z) = \Phi(z)^{-1}\Theta(z)\), \(|z|\leq 1\) e as matrizes \(\Pi_j\) resolvendo \(\Pi(z) = \Theta(z)^{-1}\Phi(z)\), \(|z|\leq 1\).
Para um modelo causal, podemos escrever \(X_t = \Psi(B)W_t\) de forma que a estrutura geral de autocovariância de um modelo \(ARMA(p,q)\) seja, para \(h\geq 0\), \begin{equation*} \Gamma(h) \, = \, \mbox{Cov}(X_{t+h},X_t) \, = \, \sum_{j=0}^\infty \Psi_{j+h}\Sigma_{_W}\Psi_j^\top, \end{equation*} e \(\Gamma(-h)=\Gamma(h)^\top\). Para processos \(MA(q)\) puros, a expressão acima torna-se \begin{equation*} \Gamma(h) \, = \, \sum_{j=0}^{q-h} \Theta_{j+h}\Sigma_{_W}\Theta_j^\top, \end{equation*} onde \(\Theta_0=\mbox{I}\). Claro que, \(\Gamma(h)=0\) para \(h>q\).
Como no caso univariado, precisaremos de condições para a unicidade do modelo. Essas condições são semelhantes à condição no caso univariado em que os polinômios autoregressivos e de médias móveis não têm fatores comuns. Para explorar os problemas de unicidade que encontramos com modelos ARMA multivariados, considere um processo \(AR(1)\) bivariado, \(X_t = (X_{t,1},X_{t,2})^\top\), dado por \begin{array}{rcl} X_{t,1} & = & \phi X_{t-1,2}+W_{t,1},\\ X_{t,2} & = & W_{t,2}, \end{array} onde \(W_{t,1}\) e \(W_{t,2}\) são processos de ru&iaute;do branco independentes e \(|\phi|<1\). Ambos os processos, \(X_{t,1}\) e \(X_{t,2}\) são causais e invertíveis. Além disso, os processos são estacionários conjuntamente porque \begin{equation*} \mbox{Cov}(X_{t+h,1},X_{t,2}) \, = \, \phi\mbox{Cov}(X_{t+h-1,2},X_{t,2}) \, = \, \phi \gamma_{2,2}(h-1) \, = \, \phi\sigma_{_{W_2}}^2\delta_1^h, \end{equation*} que não depende de \(t\). Observe, \(\delta_1^h = 1\) quando \(h = 1\), caso contr´rio, \(\delta_1^h=0\).
Em notação matricial, podemos escrever este modelo como \begin{equation*} X_t \, = \, \Phi X_{t-1}+W_t, \qquad \mbox{onde} \qquad \Phi=\begin{pmatrix} 0 & \phi \\ 0 & 0 \end{pmatrix}\cdot \end{equation*} Podemos escrever a expressã anterior em notação de operador como \begin{equation*} \Phi(B)X_t \, = \, W_t, \qquad \mbox{onde} \qquad \Phi(z)=\begin{pmatrix} 1 & -\phi z \\ 0 & 1 \end{pmatrix}\cdot \end{equation*} Além disso, este modelo pode ser escrito como um modelo \(ARMA(1,1)\) bivariado \begin{equation*} X_t \, = \, \Phi X_{t-1}+\Theta W_{t-1}+W_t, \end{equation*} onde \begin{equation*} \Phi_1=\begin{pmatrix} 0 & \phi+\theta \\ 0 & 0 \end{pmatrix} \qquad \mbox{e} \qquad \Theta_1=\begin{pmatrix} 0 & -\theta \\ 0 & 0 \end{pmatrix}, \end{equation*} e \(\theta\) arbitrário.
Para verificar isto, podemos escrever o modelo \(ARMA(1,1)\) como \begin{equation*} \Phi_1(B)X_t \, = \, \Theta_1(B)W_t \end{equation*} ou \begin{equation*} \Theta_1(B)^{-1}\Phi_1(B)X_t \, = \, W_t, \end{equation*} onde \begin{equation*} \Phi_1(z)=\begin{pmatrix} 1 & -(\phi+\theta)z \\ 0 & 1 \end{pmatrix} \qquad \mbox{e} \qquad \Theta_1(z)=\begin{pmatrix} 1 & -\theta z \\ 0 & 1 \end{pmatrix}\cdot \end{equation*} Então \begin{equation*} \Theta_1(z)^{-1}\Phi_1(z) \, = \, \begin{pmatrix} 1 & \theta z \\ 0 & 1 \end{pmatrix}\begin{pmatrix} 1 & -(\phi+\theta)z \\ 0 & 1 \end{pmatrix} \, = \, \begin{pmatrix} 1 & -\phi z \\ 0 & 1 \end{pmatrix} \, = \, \Phi(z), \end{equation*} onde \(\Phi(z)\) é o polinômio associado ao modelo bivariado \(AR(1)\). Por ser \(\theta\) arbitrário, os parâmetros do modelo \(ARMA(1,1)\) não são identificáveis. Não existe nenhum problema, entretanto, no ajuste do modelo \(AR(1)\) dado anteriormente.
O problema na discussão anterior foi causado pelo fato de que tanto \(\Theta(B)\) quanto \(\Theta(B)^{-1}\) são finitos; esse operador de matriz é chamado de unimodular. Se \(U(B)\) for unimodular, \(|U(z)|\) será constante. Também é possível que dois modelos \(ARMA(p,q)\) multivariados aparentemente diferentes, digamos \begin{equation*} \Phi (B)X_t \, = \, \Theta (B)W_t \qquad \mbox{e} \qquad \Phi_*(B)X_t \, = \, \Theta_*(B)W_t, \end{equation*} sejam relacionados por meio de um operador unimodular, \(U(B)\) como \begin{equation*} \Phi_*(B) \, = \, U(B)\Phi(B) \qquad \mbox{e} \qquad \Theta_*(B) \, = \, U(B)\Theta(B), \end{equation*} de forma que as ordens de \(\Phi(B)\) e \(\Theta(B)\) sejam iguais às ordens de \(\Phi_*(B)\) e \(\Theta_*(B)\), respectivamente. Por exemplo, considere os modelos bivariados \(ARMA(1,1)\) dados por \begin{equation*} \Phi X_t = \begin{pmatrix} 1 & -\phi B \\ 0 & 1 \end{pmatrix} X_t \, = \, \begin{pmatrix} 1 & \theta B \\ 0 & 1 \end{pmatrix}W_t \, = \, \Theta W_t \end{equation*} e \begin{equation*} \Phi_*(B) X_t = \begin{pmatrix} 1 & (\alpha-\phi) B \\ 0 & 1 \end{pmatrix} X_t \, = \, \begin{pmatrix} 1 & (\alpha+\theta) B \\ 0 & 1 \end{pmatrix}W_t \, = \, \Theta_*(B) W_t, \end{equation*} onde
Este resultado implica que os dois modelos possuem a mesma função de autocovariância \(\Gamma(h)\). Dois desses modelos \(ARMA(p,q)\) são considerados equivalentes observacionalmente.
Como mencionado anteriormente, além de exigir causalidade e invertibilidade, precisaremos de algumas suposições adicionais no caso multivariado para garantir que o modelo seja único. Para garantir a identificabilidade dos parâmetros do modelo multivariado \(ARMA(p,q)\), precisamos das seguintes duas condições adicionais:
Uma sugestão para evitar a maioria dos problemas mencionados é ajustar apenas modelos vetoriais \(AR(p)\) em situações multivariadas. Embora essa sugestão possa ser razoável para muitas situações, essa filosofia não está de acordo com a lei da parcimônia porque podemos ter que ajustar um grande número de parâmetros para descrever a dinâmica de um processo.
As inferências assintóticas para o caso geral de modelos ARMA vetoriais são mais complicadas do que os modelos AR puros; detalhes podem ser encontrados em Reinsel (1997) ou Lütkepohl (1993), por exemplo. Também observamos que a estimação para modelos VARMA podem ser reformuladas no problema de estimação para modelos de espaço de estados que será discutido no Capítulo VI.
Vale a pena mencionar um algoritmo simples para ajustar modelos vetoriais ARMA devido a Spliid (1983); porque usa repetidamente as equações de regressão multivariadas.
Considere um modelo \(ARMA(p,q)\) geral para uma série temporal com uma média diferente de zero \begin{equation*} X_t \, = \, \alpha+\Phi_1 X_{t-1}+\cdots+\Phi_p X_{t-p}+W_t+\Theta_1 X_{t-1}+\cdots+\Theta_q W_{t-q}\cdot \end{equation*} Se \(\mu=\mbox{E}(X_t)\), então \(\alpha=(\mbox{I}-\Phi_1-\cdots-\Phi_p)\mu\).
Se \(W_{t-1},\cdots,W_{t-q}\) foram observados, poderíamos reorganizar a equação acima como um modelo de regressão multivariado \begin{equation*} X_t \, = \, \mathcal{B}Z_t + W_t, \end{equation*} com \begin{equation*} Z_t \, = \, \big(1,X_{t-1}^\top,\cdots,X_{t-p}^\top,W_{t-1}^\top,\cdots,W_{t-q}^\top \big)^\top \end{equation*} e \begin{equation*} \mathcal{B} \, = \, \big( \alpha,\Phi_1,\cdots,\Phi_p,\Theta_1,\cdots,\Theta_q\big), \end{equation*} para \(t=p+1,\cdots,n\).
Dado um estimador inicial \(\mathcal{B}_0\) de \(\mathcal{B}\), podemos reconstruir \(\{W_{t-1},\cdots,W_{t-q}\}\) fazendo \begin{equation*} W_{t-j} \, = \, X_{t-j}-\mathcal{B}_0Z_{t-j}, \qquad t=p+1,\cdots,n, \quad j=1,\cdots,q, \end{equation*} onde, se \(q>p\), colocamos \(W_{t-j}=0\) para \(t-j\leq 0\).
Os novos valores de \(\{W_{t-1},\cdots,W_{t-q}\}\) são então colocados nos regressores \(Z_t\) e uma nova estimativa, digamos \(\mathcal{B}_1\), é obtida. O valor inicial, \(\mathcal{B}_0\), pode ser calculado ajustando uma autorregressão pura de ordem \(p\) ou superior e tomando \(\Theta_1 = \cdots = \Theta_q = 0\). O procedimento é então iterado até que as estimativas dos parâmetros se estabilizam.
O algoritmo freqüentemente converge, mas não para os estimadores de máxima verossimilhança. A experiência sugere que os estimadores podem estar razoavelmente próximos dos estimadores de máxima verossimilhança. O algoritmo pode ser considerado uma maneira rápida e fácil de ajustar um modelo VARMA inicial como ponto de partida para usar a estimação de máxima verossimilhança, que é melhor feita por meio de modelos de espaço de estado abordados no Capítulo VI.
Usamos o pacote R marima para ajustar o modelo \(ARMA(2;1)\) vetorial ao conjunto de dados de mortalidade-poluição. Notamos que a mortalidade é destendida antes da análise. As previsões de mortalidade um passo à frente são mostradas na Figura V.15.
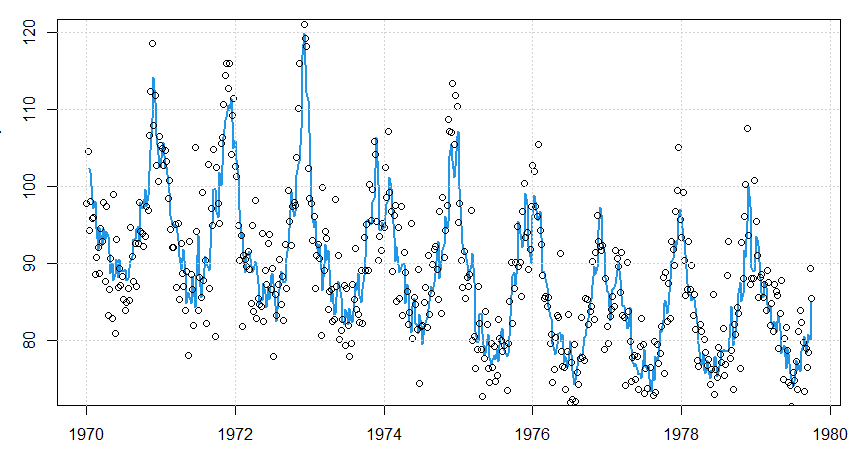
Figura V.15: As previsões de um \(VAR(2)\) ajustado aos dados de mortalidade - poluição em LA.