A extensão das técnicas clássicas de reconhecimento de padrões a séries temporais experimentais é um problema de grande interesse prático.
Uma série de observações indexadas no tempo geralmente produz um padrão que pode formar uma base para a discriminação entre diferentes
classes de eventos. Como exemplo, considere a Figura VII.2, que mostra gravações regionais (100-2000 km) de vários terremotos típicos Escandinavos e explosões
de mineração medidos por estações na Escandinávia. Uma lista dos eventos é apresentada em Kakizawa et al. (1998). O problema da discriminação
entre explosões de mineração e terremotos é um representante razoável para o problema de discriminação entre explosões de mineração
e terremotos. Esse último problema é de fundamental importância para o monitoramento de um tratado abrangente de proibição de testes. Os problemas de
classificação de séries temporais não se restringem a aplicações geofísicas, mas ocorrem sob muitas e variadas circunstâncias em
outros campos. Tradicionalmente, a detecção de um sinal incorporado em uma série de ruídos é analisada na literatura de engenharia por técnicas
estatísticas de reconhecimento de padrões, consulte o Exercício VII.10 e o Exercício VII.11.
As abordagens históricas para o problema da discriminação entre diferentes classes de séries temporais podem ser divididas em duas categorias distintas. A
abordagem de otimização, como encontrada na literatura de engenharia e estatística, faz suposições Gaussianas específicas sobre as funções
de densidade dos grupos separados e, em seguida, desenvolve soluções que satisfazem critérios de erros mínimos bem definidos. Normalmente, no caso de séries
temporais, podemos assumir que a diferença entre classes é expressa através de diferenças nas funções de média e covariância teóricas
e usar métodos de verossimilhança para desenvolver uma função de classificação ideal. Uma segunda classe de técnicas, que pode ser
descrita como uma abordagem de extração de recursos, prossegue-se de maneira mais heurística, observando quantidades que tendem a ser bons discriminadores visuais
para populações bem separadas e que têm alguma base na teoria ou intuição física. Menos atenção é dada à busca de
funções que sejam aproximações de alguns conceitos bem definidos de critérios de otimização.
Como no caso da regressão, existem abordagens no domínio do tempo e no domínio da frequência à discriminação. Para séries univariadas
relativamente curtas, pode ser preferível uma abordagem no domínio do tempo que siga a análise discriminante multivariada convencional, conforme descrito em textos
multivariados convencionais, como Anderson (1984) ou Johnson and Wichern (1992). Podemos até caracterizar diferenças segundo as funções de autocovariância
geradas por diferentes modelos ARMA ou de espaço de estados. Para séries temporais multivariadas mais longas que possam ser consideradas estacionárias após
a subtração da média comum, a abordagem do domínio da frequência será mais fácil computacionalmente porque o vetor \(n\times p\) dimensional
no domínio do tempo, representado aqui como \(X=(X_1^\top,X_2^\top,\cdots,X_n^\top)^\top\), com \(X_t=(X_{t,1},\cdots,X_{t,p})^\top\) será reduzido para separar os cálculos
feitos nas transformadas discretas de Fourier (DFT's) \(p\)-dimensionais. Isso acontece devido à independência aproximada das transformadas discretas de Fourier, \(X(\omega_k)\),
\(0\leq \omega_k\leq 1\), uma propriedade que usamos frequentemente anteriormente.
Por fim, as propriedades de agrupamento de medidas como informações sobre discriminção e estatísticas baseadas na verossimilhança podem ser usadas
para desenvolver medidas de disparidade para agrupar séries temporais multivariadas. Nesta seção, definimos uma medida de disparidade entre duas séries temporais
multivariadas pelas matrizes espectrais dos dois processos e, em seguida, aplicamos técnicas hierárquicas de agrupamento e particionamento para identificar agrupamentos naturais
nas populações bivariadas de terremotos e explosões.
O problema geral de discriminação
O problema geral de classificação de uma série temporal vetorial ocorre da seguinte maneira. Observamos uma série temporal \(X\) conhecida por pertencer
a uma das \(g\) populações, denotadas por \(\Pi_1,\Pi_2,\cdots,\Pi_g\). O problema geral é atribuir ou classificar essa observação em um dos \(g\) grupos da
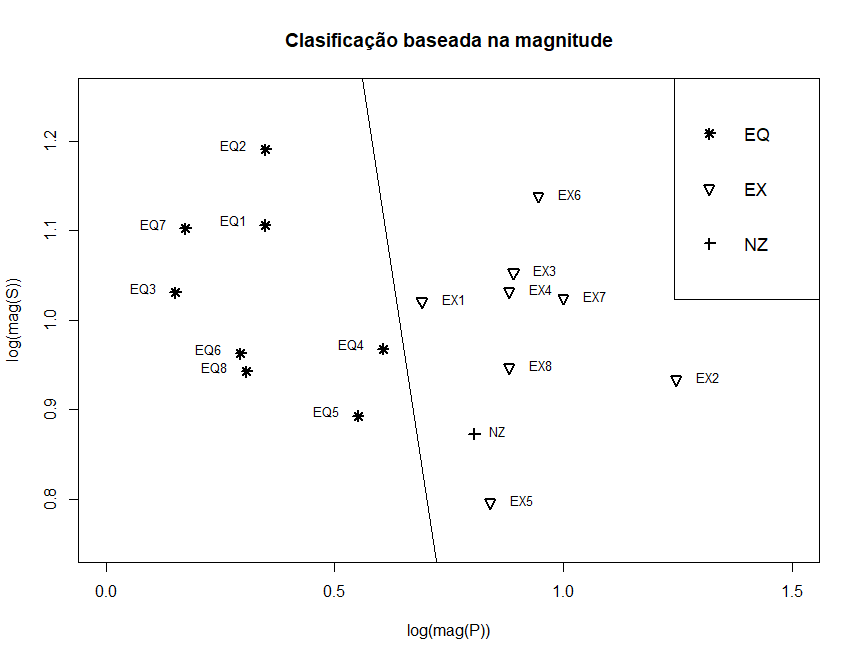
melhor maneira possível. Um exemplo pode ser as \(g=2\) populações de terremotos e explosões mostradas na Figura VII.2. Gostaríamos de classificar
o evento desconhecido, mostrado como NZ nos dois painéis inferiores, como pertencente às populações de terremotos \(\Pi_1\) ou explosão \(\Pi_2\).
Para resolver esse problema, precisamos de um critério de otimização que leve a uma estatística \(T(X)\) que possa ser usada para atribuir o evento da
NZ às populações de terremotos ou explosões. Para medir o sucesso da classificação, precisamos avaliar os erros que podem ser esperados
no futuro em relação ao número de terremotos classificados como explosões (alarmes falsos) e o número de explosões classificadas como
terremotos (sinais perdidos).
O problema pode ser formulado assumindo que a série observada \(X\) tem uma função de densidade \(p_i(x)\) quando a série observada eacute; da população
\(\Pi_i\) para \(i = 1,\cdots,g\). Em seguida, particione o espaço abrangido pelo processo \(n\times p\)-dimensional \(x\) em \(g\) regiões mutuamente exclusivas
\(R_1, R_2, \cdots, R_g\) tal que, se \(x\) cair em \(R_i\), atribuímos \(x\) à população \(\Pi_i\). À probabilidade de classificação incorreta
é definida como a probabilidade de classificar a observação na população \(\Pi_j\) quando ela pertence a \(\Pi_i\), para \(j\neq i\) e seria dada pela
expressão
\begin{equation}
P(j \, | \, i ) \, = \, \displaystyle \int_{R_{_j}} p_i(x) \mbox{d}x\cdot.
\end{equation}
A probabilidade do erro total depende também das probabilidades a priori, por exemplo, \(\pi_1, \pi_2,\cdots,\pi_g\) de \(x\) pertencer a um dos \(g\) grupos. Por exemplo,
a probabilidade de uma observação \(x\) se originar de \(\Pi_i\) e depois ser classificada em \(\Pi_j\) é obviamente \(\pi_i P(j\, | \, i)\) e a probabilidade
total de erro se torna
\begin{equation}
P_\epsilon \, = \, \sum_{i=1}^g \pi_i \sum_{j\neq i} P(j \, | \, i)\cdot
\end{equation}
Embora os custos não tenham sido incorporados na expressão acima, é possível fazê-lo multiplicando \(P( j\, | \, i)\) por \(C(j \, | \, i)\), o
custo de atribuir uma série da população \(\Pi_i\) a \(\Pi_j\).
O erro geral \(P_\epsilon\) é minimizado classificando \(x\) em \(\Pi_i\) se
\begin{equation}
\dfrac{p_{_i}(x)}{p_{_j}(x)} > \dfrac{\pi_j}{\pi_i},
\end{equation}
para todos os \(j\neq i\) (ver, por exemplo, Anderson, 1984). Uma quantidade de interesse, da perspectiva Bayesiana, é a probabilidade a posteriori de uma observação
pertencer à população \(\Pi_i\), condicionada à observação de \(x\), digamos
\begin{equation}
P(\Pi_i \, | \, x) \, = \, \dfrac{\pi_i p_i(x)}{\displaystyle \sum_j \pi_j p_j(x)}\cdot
\end{equation}
O procedimento que classifica \(x\) na população \(\Pi_i\) para a qual a probabilidade a posteriori é maior é equivalente ao critério implícito anterior. As
probabilidades a posteriori dão uma idéia intuitiva plausível das chances relativas de pertencer a cada uma das populações.
Muitas situaçães ocorrem, como na classificação de terremotos e explosões, nas quais existem apenas \(g = 2\) populações de interesse. Para
duas populações, o Lema de Neyman – Pearson implica, na ausência de probabilidades a priori, classificar uma observação em \(\Pi_1\) quando
\begin{equation}
\dfrac{p_1(x)}{p_2(x)}> K,
\end{equation}
minimiza cada uma das probabilidades de erro para um valor fixo do outro. A regra éé idêntica à regra de Bayes do erro geral \(P_\epsilon\), o qual é
minimizado classificando \(x\) em \(\Pi_i\) quando \({p_{_i}(x)}/{p_{_j}(x)} > {\pi_j}/{\pi_i}\), para todos os \(j\neq i\). A regra acima é idêntica à regra
de Bayes quando \(K = \pi_2/\pi_1\).
A teoria apresentada acima assume uma forma simples quando o vetor \(x\) tem uma distribuição normal \(p\)-variáda com vetores de média \(\mu_j\) e matrizes
de covariância \(\Sigma_j\) sob \(\Pi_j\) para \(j = 1,2,\cdots,g\). Nesse caso, basta usar
\begin{equation}
p_{_j}(x) \, = \, (2\pi)^{-p/2} |\Sigma_j|^{-1/2}\exp\left\{ -\dfrac{1}{2}\big( x-\mu_j\big)^\top \Sigma_j^{-1}\big(x-\mu_j\big)\right\}\cdot
\end{equation}
As funções de classificação são expressas convenientemente por quantidades proporcionais aos logaritmos das densidades, por exemplo,
\begin{equation}
g_{_j}(x) \, = \, -\dfrac{1}{2}\ln\big( |\Sigma_j|\big)-\dfrac{1}{2}x^\top \Sigma_j^{-1}x+\mu_j^\top \Sigma_j^{-1} x
-\dfrac{1}{2}\mu_j^\top\Sigma_j^{-1}\mu_j+\ln\big(\pi_j\big)\cdot
\end{equation}
Nas expressões que envolvem a log-verossimilhança, geralmente ignoraremos os termos que envolvem a constante \(-2\ln(2\pi)\). Nesse caso, podemos atribuir uma observação
\(x\) à população \(\Pi_i\) sempre que
\begin{equation}
g_{_i}(x) > g_{_j}(x)
\end{equation}
para \(i\neq j\), \(i=1,2,\cdots,g\) e a probabilidade a posteriori tem a forma
\begin{equation}
p(\Pi_i \, | \, x) \, = \, \dfrac{\exp\big( g_{_i}(x)\big)}{\displaystyle \sum_j\exp\big( g_{_j}(x)\big)}\cdot
\end{equation}
Uma situação comum que ocorre nas aplicações envolve a classificação para grupos \(g = 2\), sob a premissa de normalidade multivariada e
matrizes de covariância iguais; ou seja, \(\Sigma_1=\Sigma_2 =\Sigma\). Então, o critério de atribuição de uma observação \(x\) à
população \(\Pi_i\) pode ser expresso em termos da função discriminante linear como
\begin{equation}
d_{_l}(x) \, = \, g_1(x)-g_2(x) \, = \, (\mu_1-\mu_2)^\top \Sigma^{-1}x -\dfrac{1}{2}(\mu_1-\mu_2)^\top \Sigma^{-1}(\mu_1+\mu_2)+\ln(\pi_1/\pi_2),
\end{equation}
onde classificamos em \(\Pi_1\) ou \(\Pi_2\) de acordo com \(d_{_l}(x)\geq 0\) ou \(d_{_l}(x) < 0\). A função discriminante linear é claramente uma combinação
de variáveis normais e, para o caso \(\pi_1 = \pi_2 =0.5\), terá média \(D^2/2\) sob \(\Pi_1\) e média \(-D^2/2\) sob \(\Pi_2\), com variâncias dadas por
\(D^2\) nas duas hipóteses, em que
\begin{equation}
D^2 \, = \, (\mu_1-\mu_2)^\top \Sigma^{-1}(\mu_1-\mu_2)
\end{equation}
é a distância de Mahalanobis entre os vetores médios \(\mu_1\) e \(\mu_2\). Nesse caso, as duas probabilidades de classificação incorreta são
\begin{equation}
P(1 \, | \, 2) \, = \, P(2 \, | \, 1) \, = \, \Phi(-D/2),
\end{equation}
e o desempenho está diretamente relacionado à distância de Mahalanobis.
Para o caso em que as matrizes de covariâncias não sejam iguais, a função discriminante assume uma forma diferente, com a diferença \(g_1(x)-g_2(x)\)
na forma
\begin{equation}
d_{_q}(x) \, = \, -\dfrac{1}{2}\ln\left( \dfrac{|\Sigma_1|}{|\Sigma_2|}\right)-\dfrac{1}{2}x^\top \big( \Sigma_1^{-1}-\Sigma_2^{-1}\big)x + \big( \mu_1^\top\Sigma_1^{-1}-\mu_2^\top\Sigma_2^{-1}\big)x+\ln\left( \dfrac{\pi_1}{\pi_2}\right),
\end{equation}
para \(g = 2\) grupos. Essa função discriminante difere do caso de covariância iguais no termo linear e em um termo quadrático não linear envolvendo
as diferentes matrizes de covariância. A distribuição teórica não é tratável para o caso quadrático, portanto, nenhuma expressão
conveniente está disponível para as probabilidades de erro da função discriminante quadrática.
Uma dificuldade em aplicar a teoria acima a dados reais é que os vetores médios \(\mu_j\) e as matrizes de covariância \(\Sigma_j\) raramente são conhecidos.
Alguns problemas de engenharia, como a detecção de um sinal no ruído branco, assumem que os vetores médios e os parâmetros de covariância são
conhecidos exatamente e isso pode levar a uma solução óótima, consulte os Exercícios VII.14 e VII.15. Na situação multivariada clássica,
é possível coletar uma amostra de \(N_i\) vetores de treinamento do grupo \(\Pi_i\), por exemplo, \(x_{i,j}\), para \(j = 1,\cdots,N_i\) e usá-los para estimar os
vetores médios e as matrizes de covariância para cada um dos grupos \(i = 1,2,\cdots,g\); ou seja, basta escolher \(\overline{x}_i\) e
\begin{equation}
S_i \, = \, \dfrac{1}{N_i-1}\sum_{j=1}^{N_i} \big(x_{i,j}-\overline{x}_i \big)\big( x_{i,j}-\overline{x}_i\big)^\top
\end{equation}
como estimadores para \(\mu_i\) e \(\Sigma_i\), respectivamente. No caso em que as matrizes de covariância sejam consideradas iguais, basta usar o estimador agrupado
\begin{equation}
S \, = \, \dfrac{1}{\displaystyle \sum_i N_i-g}\sum_i (N_i-1)S_i\cdot
\end{equation}
Para o caso de uma função discriminante linear, podemos usar
\begin{equation}
\widehat{g}_i(x) \, = \, \overline{x}_i^\top S^{-1} x -\dfrac{1}{2}\overline{x}_i^\top S^{-1}\overline{x}_i+\log\big(\pi_i\big),
\end{equation}
como um estimador simples para \(g_i(x)\). Para amostras grandes, \(\overline{x}_i\) e \(S\) convergem para \(\mu_i\) e \(\Sigma\) em probabilidade, de modo que \(\widehat{g}_i(x)\)
converte em distribuição para \(g_i(x)\) nesse caso. O procedimento funciona razoavelmente bem para o caso em que cada \(N_i\); \(i = 1,\cdots,g\) são grandes, em
relação ao comprimento da série \(n\), um caso relativamente raro na análise de séries temporais. Por esse motivo, recorreremos ao uso de aproximações
espectrais para o caso em que os dados são fornecidos como séries temporais longas.
O desempenho das funções discriminantes amostrais podem ser avaliadas de várias maneiras diferentes. Se os parâmetros populacionais forem conhecidos, a distância
de Mahalanobis e as probabilidades de classificação incorreta poderão ser avaliadas diretamente. Se os parâmetros forem estimados, a distância estimada
de Mahalanobis \(\widehat{D}^2\) pode ser substituída pelo valor teórico em amostras muito grandes. Outra abordagem é calcular as taxas de erro aparentes usando
o resultado da aplicação do procedimento de classificação às amostras de treinamento. Se \(n_{i,j}\) denota o número de observações
da população \(\Pi_j\) classificadas em \(\Pi_i\), as taxas de erro amostral podem ser estimadas pela razão
\begin{equation}
\widehat{P}(i \, | \, j) \, = \, \dfrac{n_{i,j}}{\displaystyle \sum_i n_{i,j}},
\end{equation}
para \(i\neq j\). Se as amostras de treinamento não forem grandes, esse procedimento pode ser tendencioso e uma opção de reamostragem, como validação
cruzada ou o bootstrap, pode ser empregada.
Uma versão simples da validação cruzada é o procedimento jackknife proposto por Lachenbruch and Mickey (1968), que sustenta a observação a ser
classificada, derivando a função de classificação das demais observações. A repetição deste procedimento para cada um dos
membros da amostra de treinamento e o cálculo da taxa de erro amostral acima para as amostras de validação levam a melhores estimadores das taxas de erro.
Podemos dar um exemplo simples de aplicação dos procedimentos acima aos logaritmos das amplitudes dos componentes \(P\) e \(S\) separados dos traços originais
de terremotos e explosões. Os logaritmos (base 10) das amplitudes máximas pico a pico dos componentes \(P\) e \(S\), denotados por \(\log_{10}(P)\) e \(\log_{10}(S)\),
podem ser considerados vetores de característica bidimensionais, por exemplo, \(x = (x_1, x_2)^\top = \big(\log_{10}(P),\log_{10}(S)\big)^\top\), de uma população
normal bivariada com médias e covariâncias diferentes.
Figura VII.12: Classificação de terremotos e explosões com base na análise discriminante linear usando a
magnitude.
Os dados originais, de Kakizawa et al. (1998), são mostrados na Figura VII.12. A figura inclui o evento Novaya Zemlya (NZ) de origem desconhecida. A tendência dos
terremotos de terem valores mais altos para \(\log_{10}(S)\), em relação ao \(\log_{10}(P)\), foi notada por muitos e o uso do logaritmo da razão, ou seja,
\(\log_{10}(P)-\log_{10}(S)\) em algumas referências, por exemplo, Lay (1997) é um indicador tácito de que uma função linear dos dois parâmetros
será um discriminante útil.
As médias amostrais foram \(\overline{x}_1=(0.3477384,1.0244672)\) e \(\overline{x}_2=(0.9222803,0.9930151)\) e as matrizes de covarância amostrais foram
\begin{equation}
S_1 \, = \, \begin{pmatrix} 0.025907196 & -0.007064702 \\ -0.007064702 & 0.010202513 \end{pmatrix} \qquad \mbox{e} \qquad
S_2 \, = \, \begin{pmatrix} 0.025197761 & -0.000760573 \\ -0.000760573 & 0.010342222 \end{pmatrix}
\end{equation}
com a matriz de covariância agrupada dada por
\begin{equation}
S \, = \, \begin{pmatrix} 0.025552479 & -0.003912638 \\ -0.003912638 & 0.010272368 \end{pmatrix}\cdot
\end{equation}
Embora as matrizes de covariância não sejam iguais, tentamos a função discriminante linear de qualquer maneira que produz, com probabilidades a priori iguais
\(\pi_1 = \pi_2 = 0.5\), as funções discriminantes amostrais são
\begin{equation}
\widehat{g}_1(x) \, = \, 29.68321 x_1 + 106.1547 x_2 - 59.53698
\end{equation}
e
\begin{equation}
\widehat{g}_2(x) \, = \, 51.95275 x_1 + 112.8352 x_2 - 80.5039
\end{equation}
com a função discriminante linear estimada
\begin{equation}
\widehat{g}_2(x) \, = \, -23.3795 x_1 -5.843191 x_2 + 20.74047 \cdot
\end{equation}
As probabilidades a posteriori jackknife de ser um terremoto para o grupo de terremotos variavam de 0.621 a 1.000, enquanto as probabilidades de explosão para o grupo de
explosão variavam de 0.717 a 1.000. O evento desconhecido, NZ, foi classificado como explosão, com probabilidade a posteriori 0.960.
A abordagem de extração de recursos geralmente funciona bem para discriminar entre classes de séries univariadas ou multivariadas quando existe um vetor de baixa
dimensão simples que parece capturar a essência das diferenças entre as classes. Ainda parece sensato, no entanto, desenvolver métodos ótimos de
classificação que explorem as diferenças entre as médias multivariadas e as matrizes de covariância no caso de séries temporais. Tais métodos
podem basear-se na aproximação de Whittle à log-verossimilhança fornecida na Seção VII.2. Nesse caso, assume-se que os DFTs vetoriais, digamos,
\(X(\omega_k)\), sejam aproximadamente normais, com médias \(M_j(\omega_k)\) e matrizes espectrais \(f_j(\omega_k)\) para a população \(\Pi_j\) nas frequências
\(\omega_k=k/n\), para \(k = 0,1,\cdots,[n/2]\) e são aproximadamente não correlacionados em diferentes frequências, digamos, \(\omega_k\) e \(\omega_l\), para \(k\neq l\).
Em seguida, escrevendo as densidades normais complexas como na Seção VII.2 leva ao critério,
\begin{array}{rcl}
g_{_j}(X) & = & \displaystyle \ln\big(\pi_j\big) \, - \, \sum_{0<\omega_k<1/2} \left( \ln\big(|f_j(\omega_k)|\big) + X^*(\omega_k)f_j^{-1}(\omega_k)X(\omega_k) \right.\\
& & \qquad \qquad \qquad \left. -2M_j^*(\omega_k)f_j^{-1}(\omega_k)X(\omega_k)+M_j^*(\omega_k)f_j^{-1}(\omega_k)M_j(\omega_k)\right),
\end{array}
onde a soma ultrapassa as frequências para as quais \(|f_j(\omega_k)\neq 0|\). A periodicidade da matriz de densidade espectral e da transformada dsicreta de Fourier permitem
adicionar mais de \(0 < k <1/2\). A regra de classificação é como anteriormente mencionado.
No caso de séries temporais, é mais provável que a análise discriminante envolva assumir que as matrizes de covariâncias são diferentes e
as médias são iguais. Por exemplo, os testes, mostrados na Figura VII.11, implicam que, para os terremotos e explosões, as diferenças primárias estão
nas matrizes espectrais bivariadas e as médias são essencialmente as mesmas. Para este caso, será conveniente escrever a aproximação de Whittle para
o logaritmo da verossimilhança na forma
\begin{equation}
\ln\big( p_j(X)\big) \, = \, \sum_{0<\omega_k<1/2} \left( -\ln\big(|f_j(\omega_k)|\big) - X^*(\omega_k)f_j^{-1}(\omega_k)X(\omega_k)\right),
\end{equation}
onde omitimos as probabilidades a priori da equação. O detector quadrático, neste caso, pode ser escrito na forma
\begin{equation}
\ln\big( p_j(X)\big) \, = \, \sum_{0<\omega_k<1/2} \left( -\ln\big(|f_j(\omega_k)|\big) - \mbox{tr}\Big(I(\omega_k)f_j^{-1}(\omega_k)\Big)\right),
\end{equation}
onde
\begin{equation}
I(\omega_k) \, = \, X(\omega_k)X^*(\omega_k)
\end{equation}
denota a matriz do periodograma. Para probabilidades a priori iguais, podemos atribuir uma observação \(x\) na população \(\Pi_i\) sempre que
\begin{equation}
\ln\big( p_j(x)\big) > \ln \big( p_j(x)\big),
\end{equation}
para \(j\neq i, j=1,2,\cdots,g\).
Numerosos autores consideraram várias versões de análise discriminante no domínio da frequência. Por exemplo, Shumway and Unger (1974),
Alagón (1989), Dargahi-Noubary and Laycock (1981), Taniguchi et al. (1994) e Shumway (1982).
Medidas de discrepância
Antes de prosseguir com os exemplos de análise discriminante e de agrupamento será útil considerar a relação com a informação
de discriminação de Kullback-Leibler (K-L). Usando a aproximação espectral e observando que a matriz do periodograma tem esperança aproximada
\begin{equation}
\mbox{E}_j\big( I(\omega_k)\big) \, = \, f_j(\omega_k)
\end{equation}
assumindo que os dados vêm da população \(\Pi_j\) e aproximando a razão das densidades por
\begin{equation}
\ln\left( \dfrac{p_1(X)}{p_2(X)}\right) \, = \, \sum_{0<\omega_k<1/2} \left( -\ln\left(\dfrac{|f_1(\omega_k)|}{|f_2(\omega_k)|} \right) -
\mbox{tr}\left( \big(f_2^{-1}(\omega_k)-f_1^{ -1}(\omega_k)\big)I(\omega_k)\right)\right),
\end{equation}
podemos escrever as informações aproximadas de discriminação como
\begin{equation}
I(f_1;f_2) \, = \, \dfrac{1}{n}\mbox{E}_1\left(\ln\left( \dfrac{p_1(X)}{p_2(X)}\right) \right) \, = \,
\dfrac{1}{n}\sum_{0<\omega_k<1/2} \left( \mbox{tr}\left( f_1(\omega_k)f_2^{ -1}(\omega_k)\right)-
\ln\left(\dfrac{|f_1(\omega_k)|}{|f_2(\omega_k)|} \right) -p\right)\cdot
\end{equation}
A aproximação pode ser cuidadosamente justificada observando a série temporal normal multivariada \(x = (x_1^\top,x_2^\top,\cdots,x_n^\top)\) com médias
zero e matrizes \(np\times np\) de covariâncias estacionárias \(\Gamma_1\) e \(\Gamma_2\) tendo \(p\), \(n\times n\) blocos, com elementos da forma
\(\gamma_{ij}^{(t)}(s-t)\), \(s,t = 1,\cdots,n\), \(i,j = 1,\cdots,p\) para a população \(\Pi_\ell\), \(\ell=1,2\). A informação de discriminação,
nessas condições, torna-se
\begin{equation}
I(1;2:x) \, = \, \dfrac{1}{n}\mbox{E}_1\left(\ln\left( \dfrac{p_1(X)}{p_2(X)}\right) \right) \, = \,
\dfrac{1}{n} \left( \mbox{tr}\left( \Gamma_1\Gamma_2^{-1}\right)-\ln\left(\dfrac{|\Gamma_1|}{|\Gamma_2|}\right) -np\right)\cdot
\end{equation}
O limite resultante é
\begin{equation}
\lim_{n\to\infty} I(1;2:x) \, = \, \dfrac{1}{2} \int_{-1/2}^{1/2} \left( \mbox{tr}\left( f_1(\omega)f_2^{-1}(\omega)\right)-\ln\left(\dfrac{|f_1(\omega)|}{|f_2(\omega)|}\right) -p\right)\mbox{d}\omega,
\end{equation}
o qual foi mostrado, em diversas formas, por Pinsker (1964), Hannan (1970) e Kazakos and Papantoni-Kazakos (1980).
A versão discreta de \(I(f_1;f_2)\) é apenas a aproximação da integral da forma limite. A medida K-L de disparidade não
é uma distância verdadeira, mas pode ser mostrado que \(I(1;2)\geq 0\), com igualdade se, e somente se, \(f_1(\omega) = f_2(\omega)\) quase em
todos os lugares. Este resultado o torna potencialmente adequado como uma medida de disparidade entre as duas densidades.
É claro que existe uma conexão entre o número da informação de discriminação, que é apenas a esperança do
critério de verossimilhança e a própria verossimilhança. Por exemplo, podemos medir a disparidade entre a amostra e o processo definido
pelo espectro teórico \(f_j(\omega_k)\) correspondente à população \(\Pi_j\) no sentido de Kullback (1958), como \(I(\widehat{f};f_j)\), onde
\begin{equation}
\widehat{f}(\omega_k) \, = \, \sum_{\ell=-m}^m h_\ell I(\omega_k+\ell/n),
\end{equation}
denota a matriz espectral suavizada com pesos \(\{h_\ell\}\).
O critério da razão de verossimilhanças pode ser pensado como medindo a disparidade entre o periodograma e o espectro teórico para
cada uma das populações. Para tornar as informações de discriminação finitas, substituímos o periodograma
implícito do logaritmo da verossimilhança pelo espectro amostral. Nesse caso, o procedimento de classificação pode ser considerado
como encontrando a população mais próxima, no sentido de minimizar a disparidade entre a amostra e as matrizes espectrais teóricas.
A classificação, neste caso, prossegue simplesmente escolhendo a população \(\Pi_j\) que minimiza \(I(\widehat{f};f_j)\), ou seja,
atribuindo \(x\) à população \(\Pi_i\) sempre que
\begin{equation}
I(\widehat{f};f_i) < I(\widehat{f};f_j),
\end{equation}
para \(j\neq i\), \(j=1,2,\cdots,g\).
Kakizawa et al. (1998) propuseram o uso da medida de informação de Chernoff (CH) (Chernoff, 1952, Renyi, 1961), definida como
\begin{equation}
B_\alpha(1;2) \, = \, -\ln\left( \mbox{E}_2\left( \dfrac{p_2(x)}{p_1(x)}\right)^\alpha\right),
\end{equation}
onde a medida é indexada por um parâmetro de regularização \(\alpha\), para \(0 <\alpha <1\). Quando \(\alpha=0.5\), a medida de
Chernoff é a divergência simétrica proposta por Bhattacharya (1943). Para o caso multivariado,
\begin{equation}
B_\alpha(1;2: x) \, = \, -\ln\left( \mbox{E}_2\left( \dfrac{p_2(x)}{p_1(x)}\right)^\alpha\right)\cdot
\end{equation}
A aproximação espectral em amostras grandes para a medida de informação de Chernoff é análoga àquela
para a informação de discriminação,
\begin{equation}
B_\alpha(f_1;f_2) \, = \, \dfrac{1}{n}\sum_{0<\omega_k<1/2} \left( \ln\left( \dfrac{|\alpha f_1(\omega_k)+(1-\alpha)f_2(\omega_k)|}{|f_2(\omega_k)|}\right)-
\alpha \ln\left(\dfrac{|f_1(\omega_k)|}{|f_2(\omega_k)|}\right)\right) \cdot
\end{equation}
A medida de Chernoff, quando dividida por \(\alpha(1-\alpha)\), se comporta como a informação de discriminação no limite
no sentido de que converge para \(I(1;2 : x)\) para \(\alpha\to 0\) e para \(I(2;1 : x)\) para \(\alpha\to 1\). Portanto, próximo aos limites
do parâmetro, tende a se comportar como informação de discriminação e para outros valores representa um compromisso
entre as duas medidas de informação. A regra de classificação para a medida de Chernoff se reduz a atribuir \(x\) à
população \(\Pi_i\) sempre que
\begin{equation}
B_\alpha(\widehat{f};f_i) \, < \, B_\alpha(\widehat{f};f_j),
\end{equation}
para \(j\neq i\), \(j=1,2,\cdots,g\).
Embora as regras de classificação acima sejam bem definidas se as matrizes espectrais do grupo forem conhecidas, este não será
o caso em geral. Se houver \(g\) amostras de treinamento, \(x_{ij}\), \(j = 1,\cdots,N_i\), \(i = 1,\cdots,g\), com as \(N_i\) observações
vetoriais disponíveis em cada grupo, o estimador natural para a matriz espectral do grupo \(i\) é apenas a matriz espectral média
\(\widehat{f}_i(\omega_k)\), ou seja, com \(\widehat{f}_{ij}(\omega_k)\) denotando a matriz espectral estimada da série \(j\) da \(i\)-ésima
população,
\begin{equation}
\widehat{f}_i(\omega_k) \, = \, \dfrac{1}{N_i}\sum_{j=1}^{N_i} \widehat{f}_{ij}(\omega_k)\cdot
\end{equation}
Uma segunda consideração é a escolha do parâmetro de regularização para o critério de Chernoff. Para o
caso de \(g=2\) grupos, deve ser escolhido maximizar a disparidade entre os dois espectros do grupo. Kakizawa et al. (1998) simplesmente mostram
\(B_\alpha(f_1;f_2)\) como uma função de \(\alpha\), usando os espectros de grupo estimados \(\widehat{f}_i(\omega_k)\) definidos acima;
escolhendo o valor que dá a disparidade máxima entre os dois grupos.
Exemplo VII.11. Análise discriminante em dados sísmicos.
As abordagens mais simples para discriminar entre os grupos de terremoto e explosão foram baseadas nas amplitudes relativas das fases P e S, como na Figura VII.5,
ou nos componentes de potência relativa em várias bandas de frequência. Um esforço considerável foi despendido no uso de várias
razões espectrais envolvendo as fases bivariadas P e S como características de discriminação. Kakizawa et al. (1998) mencionam uma série
de medidas que têm sido usadas na literatura sismológica como recursos. Esses recursos incluem relações de potência para as duas fases
e relações de componentes de potência em bandas de alta e baixa frequência. O uso de tais características do espectro sugere que um
procedimento ótimo baseado na discriminação entre as matrizes espectrais de dois processos estacionários seria razoável. O fato de
que a hipótese de que as matrizes espectrais eram iguais, testada no Exemplo VII.9, também foi amplamente rejeitada sugere o uso de uma função
discriminante baseada em diferenças espectrais. Lembre-se de que a taxa de amostragem é de 40 pontos por segundo, levando a uma frequência de
dobramento de 20 Hz.
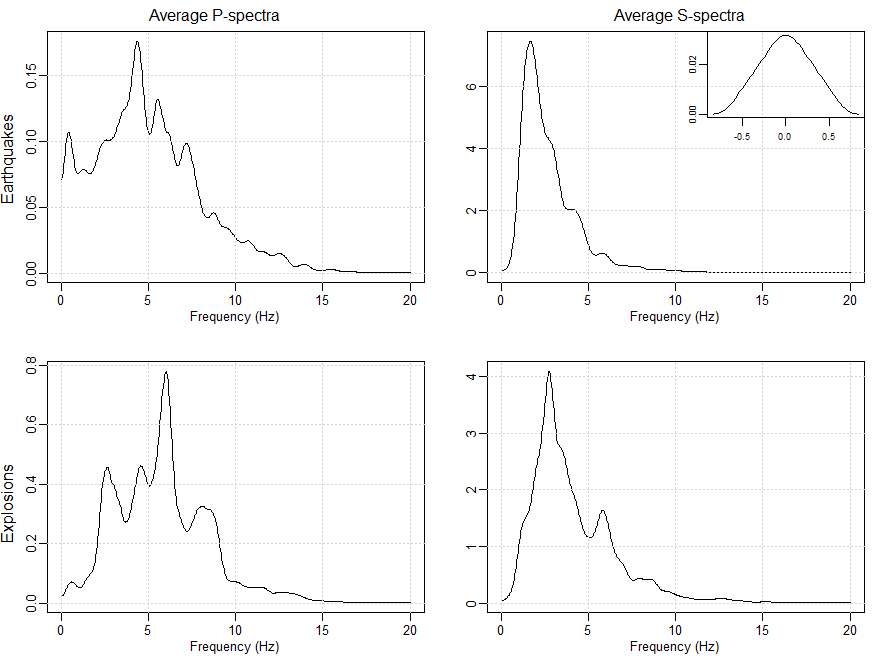
A Figura VII.13 exibe os elementos diagonais das matrizes espectrais médias para cada grupo. O valor máximo da disparidade de Chernoff estimada
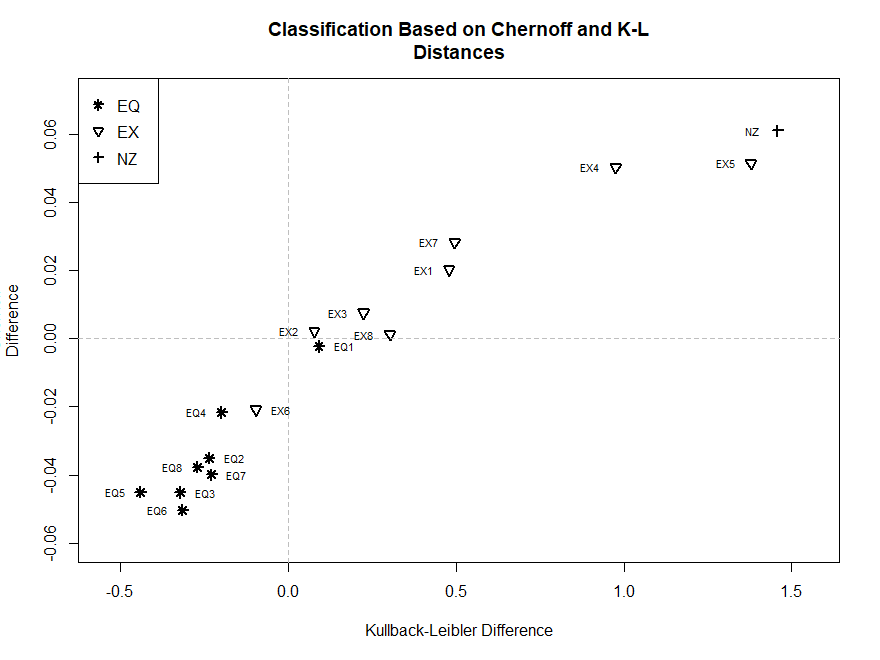
\(B_\alpha(\widehat{f}_1;\widehat{f}_2)\) ocorre para \(\alpha=0.4\), e usamos esse valor no critério discriminante. A Figura VII.14 mostra os resultados
do uso das diferenças de Chernoff junto com as diferenças de Kullback-Leibler para classificação. As diferenças são
as medidas para terremotos menos as explosões, portanto, os valores negativos das diferenças indicam terremotos e os valores positivos indicam
explosões. Portanto, os pontos no primeiro quadrante da Figura VII.14 são classificados como uma explosão e os pontos no terceiro quadrante
são classificados como terremotos. Notamos que a Explosão 6 (EX6) foi erroneamente classificada como um terremoto. Além disso, o Terremoto 1 (EQ1),
que cai no quarto quadrante, tem uma classificação incerta, a distância de Chernoff o classifica como um terremoto, entretanto, a diferença
Kullback-Leibler o classifica como uma explosão.
Figura VII.13: Espectros médios P e S das séries de terremotos e explosões. A inserção no canto superior
direito mostra o kernel de alisamento usado; a largura de banda resultante é de cerca de 0.75 Hz.
O evento NZ de origem desconhecida também foi classificado usando essas medidas de distância e, como no Exemplo VII.10, é classificado
como uma explosão. Os russos afirmaram que não ocorreram explosões de minas ou testes nucleares na área em questão, de modo
que o evento permanece um tanto misterioso. O fato de ter sido relativamente removido geograficamente do conjunto de teste também pode ter introduzido
algumas incertezas no procedimento.
Figura VII.14: Classificação (por quadrante) de terremotos e explosões usando as
diferenças de Chernoff e Kullback-Leibler.
O código R para este exemplo é o seguinte:
> library(astsa)
> P = 1:1024; S = P+1024; p.dim = 2; n =1024
> eq = as.ts(eqexp[, 1:8])
> ex = as.ts(eqexp[, 9:16])
> nz = as.ts(eqexp[, 17])
> f.eq <- array(dim=c(8, 2, 2, 512)) -> f.ex
> f.NZ = array(dim=c(2, 2, 512))
> # below calculates determinant for 2x2 Hermitian matrix
> det.c <- function(mat){return(Re(mat[1,1]*mat[2,2]-mat[1,2]*mat[2,1]))}
> L = c(15,13,5) # for smoothing
> for (i in 1:8){ # compute spectral matrices
f.eq[i,,,] = mvspec(cbind(eq[P,i], eq[S,i]), spans=L, taper=.5)$fxx
f.ex[i,,,] = mvspec(cbind(ex[P,i], ex[S,i]), spans=L, taper=.5)$fxx}
> u = mvspec(cbind(nz[P], nz[S]), spans=L, taper=.5)
> f.NZ = u$fxx
> bndwidth = u$bandwidth*sqrt(12)*40 # about .75 Hz
> fhat.eq = apply(f.eq, 2:4, mean) # average spectra
> fhat.ex = apply(f.ex, 2:4, mean)
> # plot the average spectra
> par(mfrow=c(2,2), mar=c(3,3,2,1), mgp = c(1.6,.6,0))
> Fr = 40*(1:512)/n
> plot(Fr,Re(fhat.eq[1,1,]),type="l",xlab="Frequency (Hz)",ylab="")
> grid()
> plot(Fr,Re(fhat.eq[2,2,]),type="l",xlab="Frequency (Hz)",ylab="")
> grid()
> plot(Fr,Re(fhat.ex[1,1,]),type="l",xlab="Frequency (Hz)",ylab="")
> grid()
> plot(Fr,Re(fhat.ex[2,2,]),type="l",xlab="Frequency (Hz)",ylab="")
> grid()
> mtext("Average P-spectra", side=3, line=-1.5, adj=.2, outer=TRUE)
> mtext("Earthquakes", side=2, line=-1, adj=.8, outer=TRUE)
> mtext("Average S-spectra", side=3, line=-1.5, adj=.82, outer=TRUE)
> mtext("Explosions", side=2, line=-1, adj=.2, outer=TRUE)
> par(fig = c(.75, 1, .75, 1), new = TRUE)
> ker = kernel("modified.daniell", L)$coef; ker = c(rev(ker),ker[-1])
> plot((-33:33)/40, ker, type="l", ylab="", xlab="", cex.axis=.7, yaxp=c(0,.04,2))
> # Choose alpha
> Balpha = rep(0,19)
> for (i in 1:19){ alf=i/20
for (k in 1:256) {
Balpha[i]= Balpha[i] + Re(log(det.c(alf*fhat.ex[,,k] +
(1-alf)*fhat.eq[,,k])/det.c(fhat.eq[,,k])) -
alf*log(det.c(fhat.ex[,,k])/det.c(fhat.eq[,,k])))} }
> alf = which.max(Balpha)/20 # alpha = .4
> # Calculate Information Criteria
> rep(0,17) -> KLDiff -> BDiff -> KLeq -> KLex -> Beq -> Bex
> for (i in 1:17){
if (i <= 8) f0 = f.eq[i,,,]
if (i > 8 & i <= 16) f0 = f.ex[i-8,,,]
if (i == 17) f0 = f.NZ
for (k in 1:256) { # only use freqs out to .25
tr = Re(sum(diag(solve(fhat.eq[,,k],f0[,,k]))))
KLeq[i] = KLeq[i] + tr + log(det.c(fhat.eq[,,k])) - log(det.c(f0[,,k]))
Beq[i] = Beq[i] +
Re(log(det.c(alf*f0[,,k]+(1-alf)*fhat.eq[,,k])/det.c(fhat.eq[,,k]))
- alf*log(det.c(f0[,,k])/det.c(fhat.eq[,,k])))
tr = Re(sum(diag(solve(fhat.ex[,,k],f0[,,k]))))
KLex[i] = KLex[i] + tr + log(det.c(fhat.ex[,,k])) - log(det.c(f0[,,k]))
Bex[i] = Bex[i] +
Re(log(det.c(alf*f0[,,k]+(1-alf)*fhat.ex[,,k])/det.c(fhat.ex[,,k]))
- alf*log(det.c(f0[,,k])/det.c(fhat.ex[,,k]))) }
KLDiff[i] = (KLeq[i] - KLex[i])/n
BDiff[i] = (Beq[i] - Bex[i])/(2*n) }
> x.b = max(KLDiff)+.1; x.a = min(KLDiff)-.1
> y.b = max(BDiff)+.01; y.a = min(BDiff)-.01
> plot(KLDiff[9:16], BDiff[9:16], type="p", xlim=c(x.a,x.b), ylim=c(y.a,y.b),
cex=1.1,lwd=2, xlab="Kullback-Leibler Difference",ylab="Chernoff
Difference", main="Classification Based on Chernoff and K-L Distances", pch=6)
> points(KLDiff[1:8], BDiff[1:8], pch=8, cex=1.1, lwd=2)
> points(KLDiff[17], BDiff[17], pch=3, cex=1.1, lwd=2)
> legend("topleft", legend=c("EQ", "EX", "NZ"), pch=c(8,6,3), pt.lwd=2)
> abline(h=0, v=0, lty=2, col="gray")
> text(KLDiff[-c(1,2,3,7,14)]-.075, BDiff[-c(1,2,3,7,14)],
label=names(eqexp[-c(1,2,3,7,14)]), cex=.7)
> text(KLDiff[c(1,2,3,7,14)]+.075, BDiff[c(1,2,3,7,14)],
label=names(eqexp[c(1,2,3,7,14)]), cex=.7)
Análise de cluster
Para fins de agrupamento, pode ser mais útil considerar uma medida de disparidade simétrica e apresentamos a medida J-Divergência
\begin{equation}
J(f_1;f_2) \, = \, I(f_1;f_2)+I(f_2;f_1)
\end{equation}
e o número de Chernoff simétrico
\begin{equation}
JB_\alpha(f_1;f_2) \, = \, B_\alpha(f_1;f_2)+B_\alpha(f_2;f_1)
\end{equation}
para esse propósito.
Neste caso, definimos a disparidade entre a matriz espectral amostral de um único vetor \(x\), e a população \(\Pi_j\) como
\begin{equation}
J(\widehat{f};f_j) \, = \, I(\widehat{f};f_j)+I(f_j;\widehat{f})
\end{equation}
e
\begin{equation}
JB_\alpha(\widehat{f};f_j) \, = \, B_\alpha(\widehat{f};f_j)+B_\alpha(f_j;\widehat{f}),
\end{equation}
respectivamente e use-as como quase distâncias entre o vetor e a população \(\Pi_j\).
As medidas de disparidade podem ser usadas para agrupar séries temporais multivariadas. As medidas simétricas de disparidade, conforme
definidas acima, garantem que a disparidade entre \(f_i\) e \(f_j\) seja igual à disparidade entre \(f_j\) e \(f_i\). Portanto, consideraremos
as formas simétricas mostradas acima como quase distâncias com o propósito de definir uma matriz de distância para entrada
em um dos procedimentos de agrupamento padrão (ver Johnson and Wichern, 1992). Em geral, podemos considerar métodos de agrupamento
hierárquico ou particionado usando a matriz de quase distância como entrada.
Para fins de ilustração, podemos usar a divergência simétrica \(J(\widehat{f};f_j)\), que implica que a quase-distância
entre as séries amostrais com matrizes espectrais estimadas \(\widehat{f}_i\) e \(\widehat{f}_j\) seria \(J(\widehat{f}_i;\widehat{f}_j)\); ou seja,
\begin{equation}
J(\widehat{f}_i;\widehat{f}_j) \, = \, \dfrac{1}{n}\sum_{0<\omega_k<1/2} \left( \mbox{tr}\left(\widehat{f}_i(\omega_k)\widehat{f}_j^{-1}(\omega_k)\right) +
\mbox{tr}\left(\widehat{f}_j(\omega_k)\widehat{f}_i^{-1}(\omega_k)\right)-2p\right)
\end{equation}
para \(i\neq j\). Também podemos usar a forma comparável para a divergência de Chernoff, mas podemos não querer fazer uma
suposição para o parâmetro de regularização \(\alpha\).
Para o agrupamento hierárquico, começamos agrupando os dois elementos da população que minimizam a medida de disparidade
\(J(\widehat{f}_i;\widehat{f}_j)\). Então, esses dois itens formam um cluster e podemos calcular distâncias entre itens não agrupados
como antes. A distância entre itens não agrupados e um agrupamento atual é definida aqui como a média das distâncias
aos elementos no agrupamento. Novamente, combinamos objetos que estão mais próximos. Também podemos calcular a distância
entre os itens não agrupados e os itens agrupados como a distância mais próxima, em vez da média. Quando uma série
está em um cluster, ela permanece lá. Em cada estágio, temos um número fixo de clusters, dependendo do estágio de
fusão.
Alternativamente, podemos pensar no agrupamento como uma partição da amostra em um número pré-especificado de grupos.
MacQueen (1967) propôs isso usando agrupamento de k-médias, usando a distância de Mahalonobis entre uma observação
e os vetores de média do grupo. Em cada estágio, uma redesignação de uma observação em seu grupo de
afinidade mais próximo é possível. Para ver como este procedimento se aplica ao contexto atual, considere uma partição
preliminar em um número fixo de grupos e defina a disparidade entre a matriz espectral da observação, digamos, \(\widehat{f}\)
e a matriz espectral média do grupo, digamos, \(\widehat{f}_i\), como \(J(\widehat{f};\widehat{f}_i)\), onde a matriz espectral do grupo pode
ser estimada por
\begin{equation}
\widehat{f}_i(\omega_k) \, = \, \dfrac{1}{N_i}\sum_{j=1}^{N_i} \widehat{f}_{ij}(\omega_k)\cdot
\end{equation}
Em qualquer passagem, uma única série é reatribuída ao grupo para o qual sua disparidade é minimizada. O procedimento
de reatribuição é repetido até que todas as observações fiquem em seus grupos atuais. Obviamente, o número
de grupos deve ser especificado para cada repetição do algoritmo de particionamento e uma partição inicial deve ser escolhida.
Essa atribuição pode ser aleatória ou escolhida a partir de um agrupamento hierárquico preliminar, conforme descrito acima.
Exemplo VII.12. Análise de cluster em dados sísmicos.
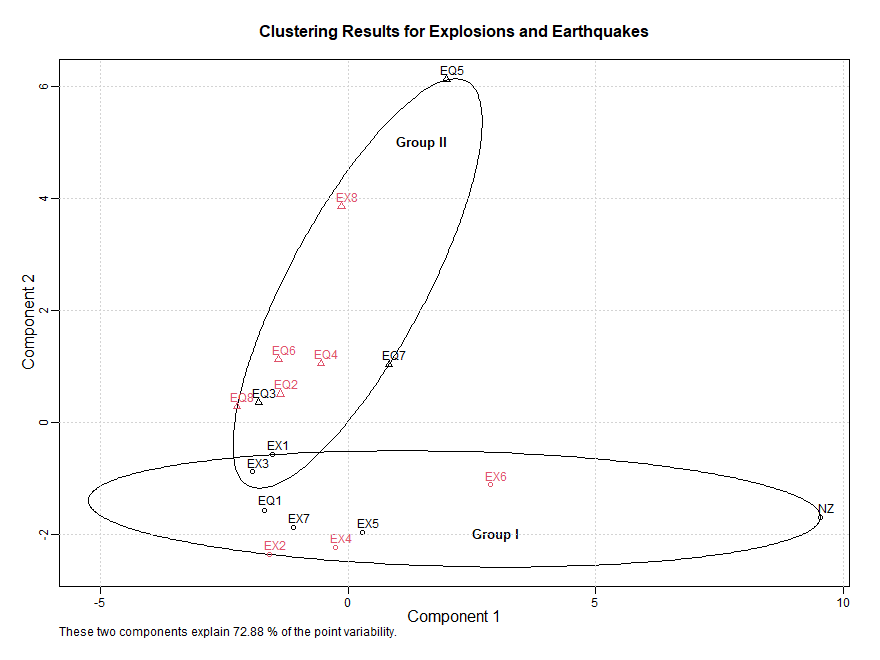
É instrutivo tentar um procedimento de agrupamento na população de terremotos e explosões conhecidos. A Figura VII.15 mostra
os resultados da aplicação do algoritmo de agrupamento Partitioning Around Medoids (PAM), que é essencialmente uma robustez do
procedimento k-means (ver Kaufman and Rousseeuw, 1990), sob a suposição de que dois grupos são apropriados. A partição
de dois grupos tende a produzir uma parti¸ão final que concorda intimamente com a configuração conhecida com o terremoto 1 (EQ1)
e a explosão 8 (EX8) sendo classificados incorretamente; como nos exemplos anteriores, o evento NZ é classificado como uma explosão.
Figura VII.15: Resultados de agrupamento para a série de terremotos e explosões com base na
divergência simétrica usando uma versão robusta de agrupamento k-means com dois grupos. Os círculos indicam a
classificação do Grupo I, os triângulos indicam a classificação do Grupo II.
O código R para este exemplo usa o pacote cluster e o script mvspec, no pacote astsa, para estimar matrizes espectrais.
O problema de detecção de um sinal no ruído pode ser considerado usando o modelo
\begin{equation}
X_t \, = \, S_t+W_t, \qquad t=1,\cdots,n,
\end{equation}
para \(p_1(x)\) quando um sinal está presente e o modelo
\begin{equation}
X_t \, = \, W_t, \qquad t=1,\cdots,n,
\end{equation}
para \(p_2(x)\) quando nenhum sinal está presente. Sob normalidade multivariada, podemos especializar
ainda mais assumindo que o vetor \(W = (W_1,\cdots,W_n)^\top\) tem distribuição normal multivariada com
média 0 e matriz de covariâncias \(\Sigma=\sigma^2_{_W}\mbox{I}_n\), correspondendo a ruído branco.
Assumindo o vetor de sinal \(S = (S_1,\cdots,S_n)^\top\) é fixo e conhecido, mostrar que a função
discriminante \(d_{_l}(x) = g_1(x)-g_2(x)\) torna-se o filtro casado
\begin{equation}
\dfrac{1}{\sigma^2_{_W}}\sum_{t=1}^n S_tX_t -\dfrac{1}{2}\left(\dfrac{S}{N}\right)+\ln\left(\dfrac{\pi_1}{\pi_2}\right),
\end{equation}
onde
\begin{equation}
\left(\dfrac{S}{N}\right) \, = \, \dfrac{\sum_{t=1}^n S_t^2}{\sigma^2_{_W}},
\end{equation}
denota a relação sinal-ruído. Forneça o critério de decisão se as probabilidades anteriores
forem assumidas como as mesmas. Expresse as probabilidades de alarme falso e sinal perdido em termos da função de
distribuição normal e a relação sinal-ruído.
Assuma o mesmo sinal aditivo mais representações de ruído como no problema anterior, exceto, o sinal é agora um processo aleatório
com uma média zero e matriz de covariâncias \(\sigma^2_s \mbox{I}\). Derive a versão comparável de \(d_q(x)\) como um detector quadrático
e caracterize seu desempenho em ambas as hipóteses em termos de múltiplos constantes da distribuição qui-quadrado.