Nesta seção, apresentamos os tópicos relacionados à análise de componentes principais e análise fatorial para séries temporais no
domínio espectral. Os tópicos de componentes principais e análise canônica no domínio da frequência são rigorosamente apresentados
em Brillinger (1981) e muitos dos detalhes relativos a esses conceitos podem ser encontrados lá.
As técnicas apresentadas aqui estão relacionadas entre si, pois se concentram na extração de informações pertinentes de matrizes
espectrais. Esta informação é importante porque lidar diretamente com uma matriz espectral de alta dimensão \(f(\omega)\) em si é um pouco complicado
porque é uma função no conjunto de matrizes Hermitianas complexas, definidas não negativas.
Podemos ver essas técnicas como ferramentas fáceis de entender e parcimoniosas para explorar o comportamento de séries temporais com valores
vetoriais no domínio da frequência com perda mínima de informação. Como nosso foco está em matrizes espectrais, assumimos por
conveniência que as séries temporais de interesse têm médias zero; as técnicas são facilmente ajustadas no caso de médias
diferentes de zero.
Nesta seção e nas subseqüentes, será conveniente trabalhar ocasionalmente com séries temporais de valor complexo. Uma série temporal
\(p\times 1\) de valor complexo pode ser representada como \(X_t = X_{1t}- iX_{2t}\); onde \(X_{1t}\) é a parte real e \(X_{2t}\) é a parte imaginária de
\(X_t\).
O processo \(X_t\) é dito estacionário se \(\mbox{E}(X_t)\) e \(\mbox{E}(X_{t+h}X_t^*)\) existem e são independentes do tempo \(t\). A função
de autocovariância,
\begin{equation}
\Gamma_{_{XX}}(h) \, = \, \mbox{E}(X_{t+h}X_t^*)-\mbox{E}(X_{t+h})\mbox{E}(X_t^*),
\end{equation}
de \(X_t\) satisfaz condições semelhantes às do caso com valor real. Escrevendo
\begin{equation}
\Gamma_{_{XX}}(h) \, = \, \{\gamma_{ij}(h)\}, \qquad i,j =1,2,\cdots,p,
\end{equation}
temos
(i) \(\gamma_{ii}(0)\geq 0\) é real,
(ii) \(|\gamma_{ij}(h)|^2\leq \gamma_{ii}(0)\gamma_{jj}(0)\), para todos os interios \(h\) e
(iii) \(\Gamma_{_{XX}}(h)\) é uma função definida não negetiva.
A teoria espectral de séries temporais vetoriais complexas é análoga ao caso real. Por exemplo, se
\begin{equation}
\sum_h ||\Gamma_{_{XX}}(h) ||<\infty
\end{equation}
a matriz de densidade espectral da série temporal complexa \(X_t\) é dada por
\begin{equation}
f_{_{XX}}(\omega) \, = \, \sum_{h=-\infty}^\infty \Gamma_{_{XX}}(h)\exp\big(-2\pi \, i \, h\omega \big)\cdot
\end{equation}
Análise de componentes principais
A análise clássica de componentes principais (PCA) se preocupa em explicar a estrutura de variâncias-covariâncias entre as \(p\)
variáveis \(X=(X_1,\cdots,X_p)^\top\), por meio de algumas combinações lineares dos componentes de \(X\). Suponha que desejamos
encontrar uma combinação linear
\begin{equation}
Y \, = \, c^\top X \, = \, c_1X_1+\cdots+c_p X_p
\end{equation}
dos componentes de \(X\) de modo que \(\mbox{Var}(Y)\) seja o maior possível. Como \(\mbox{Var}(Y)\) pode ser aumentado simplesmente multiplicando
por uma constante \(c\) é comum restringir \(c\) para ter comprimento unitário; ou seja, \(c^\top c = 1\).
Observando que \(\mbox{Var}(Y)=c^\top \Sigma_{_{XX}}c\), onde \(\Sigma_{_{XX}}\) é a matriz \(p\times p\) de variâncias-covariâncias
de \(X\), outra maneira de declarar o problema é encontrar \(c\) tal que
\begin{equation}
\max_{c\neq 0} \dfrac{c^\top \Sigma_{_{XX}}c}{c^\top c}\cdot
\end{equation}
Denote os pares de autovalores e autovetores de \(\Sigma_{_{XX}}\) por \(\{(\lambda_1,e_1),\cdots,(\lambda_p,e_p)\}\), onde \(\lambda_1\geq \lambda_2\geq \cdots\geq \lambda_p\geq 0\)
e os autovetores são de comprimento unitário. A solução para o máximo acima é escolher \(c = e_1\), caso em que
a combinação linear \(Y_1 = e_1^\top X\) tem variância máxima, \(\mbox{Var}(Y_1) = \lambda_1\). Em outras palavras,
\begin{equation}
\max_{c\neq 0} \dfrac{c^\top \Sigma_{_{XX}}c}{c^\top c} \, = \, \dfrac{e_1^\top \Sigma_{_{XX}}e_1}{e_1^\top e_1} \, = \, \lambda_1\cdot
\end{equation}
A combinação linear \(Y_1 = e_1^\top X\) é chamada de primeira componente principal. Como os autovalores de \(\Sigma_{_{XX}}\) não são necessariamente
únicos, a primeira componente principal não é necessariamente única.
O segundo componente principal é definido como a combinação linear \(Y_2 = c^\top X\) que maximiza \(\mbox{Var}(Y_2)\) sujeito a
\(c^\top c = 1\) e tal que \(\mbox{Cov}(Y_1,Y_2) = 0\). A solução é escolher \(c = e_2\), caso em que \(\mbox{Var}(Y_2) = \lambda_2\).
Em geral, o \(k\)-ésimo componente principal, para \(k = 1,2,\cdots,p\), é a combinação linear \(Y_k = c^\top X\) que maximiza
\(\mbox{Var}(Y_k)\) sujeito a \(c^\top c = 1\) e tal que \(\mbox{Cov}(Y_k,Y_j) = 0\), para \(j = 1,2,\cdots,k-1\). A solução em cada
situação é escolher \(c = e_k\), caso em que \(\mbox{Var}(Y_k) = \lambda_k\).
Uma medida da importâcia de uma componente principal é avaliar a proporção da variância total atribuída a esse
componente principal. A variância total de \(X\) é definida como a soma das variâncias das componentes individuais; ou seja,
\begin{equation}
\mbox{Var}(X_1) +\cdots + \mbox{Var}(X_p) \, = \, \sigma_{_{11}} +\cdots +\sigma_{_{pp}},
\end{equation}
onde \(\sigma_{_{jj}}\) é o \(j\)-ésimo elemento da diagonal de \(\Sigma_{_{XX}}\).
A soma acima também é denotada como \(\mbox{tr}\big(\Sigma_{_{XX}}\big)\) ou o traço de \(\Sigma_{_{XX}}\). Como
\begin{equation}
\mbox{tr}\big(\Sigma_{_{XX}}\big) \, = \, \lambda_1 +\cdots +\lambda_p,
\end{equation}
a proporção da variância total atribuída a \(k\)-ésima componente principal é dada simplesmente por
\begin{equation}
\dfrac{\mbox{Var}(Y_k)}{\mbox{tr}\big(\Sigma_{_{XX}}\big)} \, = \, \dfrac{\lambda_k}{\sum_{j=1}^p \lambda_j}\cdot
\end{equation}
Dada uma amostra aleatória \(x_1,\cdots,x_n\), as componentes principais amostrais são definidos como acima, mas com \(\Sigma_{_{XX}}\)
substituído pela matriz de variâncias-covariâncias amostral
\begin{equation}
S_{_{XX}} \, = \, \dfrac{1}{n-1}\sum_{i=1}^n \big(x_i-\overline{x} \big)\big(x_i-\overline{x} \big)^\top\cdot
\end{equation}
Mais detalhes podem ser encontrados na introdução à análise clássica de componentes principais em Johnson and Wichern (1992).
Para o caso de séries temporais, suponha que temos processo vetorial \(p\times 1\) estacionário \(X_t\) de média zero e matriz de densidade
espectral \(p\times p\) dada por \(f_{_{XX}}(\omega)\). Lembre-se de que \(f_{_{XX}}(\omega)\) é uma matriz Hermitiana de valor complexo, definida não
negativa. Usando a analogia dos componentes principais clássicos, suponha que, para um valor fixo de \(\omega\), queremos encontrar um processo univariado
de valor complexo \(Y_t(\omega) = c^*(\omega)X_t\), onde \(c(\omega)\) é complexo, de modo que a densidade espectral de \(Y_t(\omega)\) é maximizada
na frequência \(\omega\) e \(c(\omega)\) é de comprimento unitário, \(c(\omega)^*c(\omega) = 1\).
Porque, na frequência \(\omega\), a densidade espectral de \(Y_t(\omega)\) é \(f_{_Y}(\omega) = c(\omega)^*f_{_{XX}}(\omega)c(\omega)\), o problema
pode ser reformulado como: encontrar o vetor complexo \(c(\omega)\) de modo que
\begin{equation}
\max_{c(\omega)\neq 0} \dfrac{c(\omega)^*f_{_{XX}}(\omega)c(\omega)}{c(\omega)^*c(\omega)}\cdot
\end{equation}
Sejam \(\{(\lambda_1(\omega),e_1(\omega)),\cdots,(\lambda_p(\omega),e_p(\omega))\}\) os pares de autovalor–autovetor de \(f_{_{XX}}(\omega)\) onde
os autovetores têm comprimento unitário e os auvalores satisfazem que \(\lambda_1(\omega)\geq \lambda_2(\omega)\geq \cdots \geq \lambda_p(\omega)\geq 0\).
Notamos que os autovalores de uma matriz Hermitiana são reais. A solução para a maximização anterior é escolher
\(c(\omega) = e_1(\omega)\); nesse caso, a combinação linear desejada é \(Y_t(\omega) = e_1(\omega)^*X_t\). Para esta escolha,
\begin{equation}
\max_{c(\omega)\neq 0} \dfrac{c(\omega)^*f_{_{XX}}(\omega)c(\omega)}{c(\omega)^*c(\omega)} \, = \,
\dfrac{e_1(\omega)^*f_{_{X}}(\omega)e_1(\omega)}{e_1(\omega)^*e_1(\omega)} \, = \, \lambda_1(\omega)\cdot
\end{equation}
Este processo pode ser repetido para qualquer frequência! \(\omega\) e o processo de valor complexo \(Y_{t1}(\omega)=e_1^*(\omega)X_t\) é chamado
de primeira componente principal na frequência \(\omega\). A \(k\)-ésima componente principal na frequência \(\omega\), para \(k = 1,,\cdots,p\)
é a série temporal de valores complexos \(Y_{tk}(\omega) = e_k^*(\omega)X_t\), em analogia ao caso clássico. Neste caso, a densidade
espectral de \(Y_{tk}(\omega)\) na frequência \(\omega\) é \(f_{_{Y_k}}(\omega) = e_k(\omega)^*f_{_{XX}}(\omega)e_k(\omega) = \lambda_k(\omega)\).
O desenvolvimento anterior de componentes principais do domínio espectral está relacionado à metodologia do envelope espectral discutida
pela primeira vez em Stoffer et al. (1993). Apresentaremos o envelope espectral na próxima seção, onde motivamos o uso de componentes
principais conforme apresentado acima. Outra maneira de motivar o uso de componentes principais no domínio da frequência foi apresentada em
Brillinger (1981). Embora essa técnica leve à mesma análise, a motivação pode ser mais satisfatória para o leitor
neste ponto. Neste caso, supomos que temos um processo estacionário, \(p\)-dimensional, com valor vetorial \(X_t\) e só somos capazes de manter
um processo univariado \(Y_t\) de modo que, quando necessário, podemos reconstruir o processo com valor vetorial \(X_t\), de acordo com um critério
de otimalidade.
Especificamente, supomos que queremos aproximar uma série temporal vetorial \(X_t\) com valor médio de zero, estacionária, com matriz espectral
\(f_{_{XX}}(\omega)\), por um processo univariado \(Y_t\) definido por
\begin{equation}
Y_t \, = \, \sum_{j=-\infty}^\infty c_{t-j}^* X_j,
\end{equation}
onde \(\{c_j\}\) é um filtro vetorial \(p\times 1\), de maneira que \(\{c_j\}\) seja absolutamente convergente, ou seja,
\begin{equation}
\sum_{j=-\infty}^\infty |c_j|<\infty\cdot
\end{equation}
A aproximação é realizada para a reconstrução de \(X_t\) de \(Y_t\), digamos,
\begin{equation}
\widehat{X}_t \, = \, \sum_{j=-\infty}^\infty b_{t-j} Y_j,
\end{equation}
onde \(\{b_j\}\) é um filtro vetorial \(p\times 1\) absolutamente convergente, de modo que o erro de aproximação quadrático
médio
\begin{equation}
\mbox{E}\Big(\big(X_t-\widehat{X}_t\big)^* \big(X_t-\widehat{X}_t\big) \Big)
\end{equation}
é minimizado.
Sejam \(\{b(\omega)\}\) e \(\{c(\omega)\}\) as transformadas de \(\{b_j\}\) e \(\{c_j\}\), respectivamente. Por exemplo,
\begin{equation}
c(\omega) \, = \, \sum_{j=-\infty}^\infty c_j \exp\big(-2\pi \, i \, j\omega \big)
\end{equation}
e, consequentemente
\begin{equation}
c_j \, = \, \int_{-1/2}^{1/2} c(\omega)\exp(2\pi \, i\, j\omega)\mbox{d}\omega\cdot
\end{equation}
Brillinger (1981) mostrou que a solução para o problema é escolher \(c(\omega)\) satisfazendo
\begin{equation}
\max_{c(\omega)\neq 0} \dfrac{c(\omega)^*f_{_{XX}}(\omega)c(\omega)}{c(\omega)^*c(\omega)}
\end{equation}
e definir \(b(\omega) = \overline{c(\omega)}\). Este é justamente o problema anterior, com a solução dada por
\begin{equation}
\max_{c(\omega)\neq 0} \dfrac{c(\omega)^*f_{_{XX}}(\omega)c(\omega)}{c(\omega)^*c(\omega)} \, = \,
\dfrac{e_1(\omega)^*f_{_{X}}(\omega)e_1(\omega)}{e_1(\omega)^*e_1(\omega)} \, = \, \lambda_1(\omega)\cdot
\end{equation}
Ou seja, escolhemos \(c(\omega)=e_1(\omega)\) e \(b(\omega) = \overline{e_1(\omega)}\); os valores do filtro podem ser obtidos por meio da fórmula
de inversão de \(c_j\) acima. Usando esses resultados, podemos formar a primeira série de componentes principais, digamos \(Y_{t1}\).
Essa técnica pode ser estendida solicitando outra série, digamos, \(Y_{t2}\), para aproximar \(X_t\) em relação ao erro
quadrático médio mínimo, mas onde a coerência entre \(Y_{t2}\) e \(Y_{t1}\) seja zero. Nesse caso, escolhemos \(c(\omega) = e_2(\omega)\).
Continuando assim, podemos obter a primeira \(q\leq p\) série de componentes principais, digamos, \(Y_t = (Y_{t1}\cdots,Y_{tq})^\top\), com densidade
espectral
\begin{equation}
f_q(\omega) = \mbox{diag}\{\lambda_1(\omega),\cdots,\lambda_q(\omega)\}\cdot
\end{equation}
A série \(Y_{tk}\) é a \(k\)-ésima série de componentes principais.
Como no caso clássico, dadas as observações \(x_1,x_2,\cdots,x_n\), a partir do processo \(x_t\), podemos formar uma estimativa
\(\widehat{f}_{_{XX}}(\omega)\) de \(f_{_{XX}}(\omega)\) e definir a série de componentes principais amostrais substituindo \(f_{_{XX}}(\omega)\) por
\(\widehat{f}_{_{XX}}(\omega)\) na discussão anterior. Detalhes precisos relativos ao comportamento assintótico, quando \(n\to\infty\) da
série de componentes principais e seus espectros podem ser encontrados em Brillinger (1981). Para dar uma ideia básica do que podemos esperar,
nos concentramos na primeira série de componentes principais e no estimador espectral obtido pela suavização da matriz do periodograma,
\(I_n(\omega_j)\); isto é
\begin{equation}
\widehat{f}_{_{XX}}(\omega_j) \, = \, \sum_{\ell=-m}^m h_\ell I_n(\omega_j + \ell/n),
\end{equation}
onde \(L=-2m-1\) é ímpar e os pesos são escolhidos de forma que \(h_\ell = h_{-\ell}\) sejam positivos e \(\sum_\ell h_\ell = 1\). Sob
as condições para as quais \(\widehat{f}_{_{XX}}(\omega_j)\) é um estimador bem-comportado de \(f_{_{XX}}(\omega_j)\) e para o qual
o maior autovalor de \(f_{_{XX}}(\omega_j)\) é único,
\begin{equation}
\left\{ \eta_n\dfrac{\widehat{\lambda}_1(\omega_j)-\lambda_1(\omega_j)}{\lambda_1(\omega_j)} \, ; \, \eta_n\Big(\widehat{e}_1(\omega_j)-e_1(\omega_j)\Big) \, : \, j=1,\cdots,J\right\}
\end{equation}
convergem conjuntamente em distribuição, quando \(n\to\infty\), à distribuições normais de média zero independentes,
a primeira das quais é normal padrão. Na expressão acima, \(\eta_n^{-2} = \sum_{\ell=-m}^m h_\ell^2\), observando que devemos ter \(L\to\infty\) e \(\eta_n\to\infty\), mas \(L/n\to 0\) quando
\(n\to\infty\).
A matriz de variâncias-covariâncias assintótica de \(\widehat{e}_1(\omega)\), digamos, \(\Sigma_{\widehat{e}_1}(\omega)\), é dada por
\begin{equation}
\Sigma_{\widehat{e}_1}(\omega) \, = \, \dfrac{\lambda_1(\omega)}{\eta_n^2}\sum_{\ell=2}^p \dfrac{\lambda_\ell(\omega)}{\lambda_1(\omega)-\lambda_\ell(\omega)}e_\ell(\omega)e_\ell^*(\omega)\cdot
\end{equation}
A distribuição de \(\widehat{e}_1(\omega)\) depende das outras raízes latentes e vetores de \(f_{_X}(\omega)\). Escrevendo
\begin{equation}
\widehat{e}_1(\omega) \, = \, (\widehat{e}_{11}(\omega),\widehat{e}_{12}(\omega),\cdots,\widehat{e}_{1p}(\omega))^\top,
\end{equation}
podemos usar este resultado para formar regiões de confiança para os componentes de \(\widehat{e}_1(\omega)\) aproximando a distribuição de
\begin{equation}
2\dfrac{|\widehat{e}_{1,j}(\omega)-e_{1,j}(\omega)|^2}{s_j^2(\omega)},
\end{equation}
para \(j = 1,\cdots,p\), por uma distribuição \(\chi^2\) com dois graus de liberdade. Acima \(s_j^2(\omega)\) é o \(j\)-ésimo elemento da
diagonal de \(\widehat{\Sigma}_{e_1}(\omega)\), a estimativa de \(\Sigma_{{e}_1}(\omega)\). Podemos usar a expressão acima para verificar se o valor de zero
está na região de confiança comparando \(2|\widehat{e}_{1,j}(\omega)|^2/s_j^2(\omega)\) com \(\chi^2_2(1-\alpha)\), o corte da cauda superior da distribuição \(\chi^2_2\).
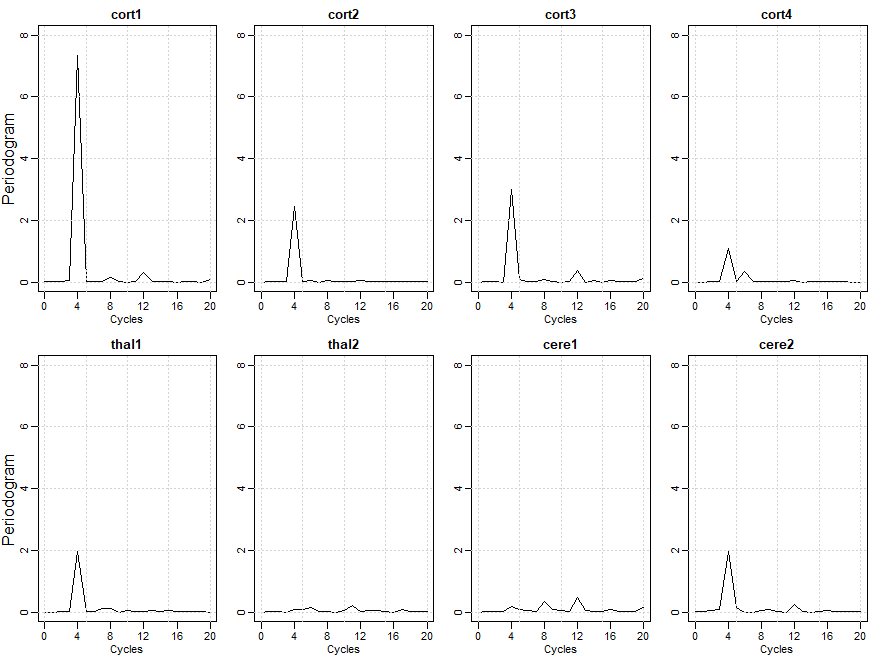
Exemplo VII.13. Análise de componentes principais dos dados de fMRI.
Lembremos do Exemplo I.6, onde a série temporal vetorial \(X_t = (X_{t1},\cdots,X_{t8})^\top\), \(t = 1,\cdots,128\), representa medidas consecutivas
de intensidade de sinal dependente do nível médio de oxigenação do sangue (BOLD), que mede áreas de ativação no
cérebro. Os sujeitos receberam uma escovação indolor na mão e outros um estímulo que foi aplicado por 32 segundos e depois
interrompido por 32 segundos; assim, o período do sinal é de 64 segundos, a taxa de amostragem foi uma observação a cada dois
segundos por 256 segundos. As séries \(X_{tk}\) para \(k = 1,2,3,4\), representam locais no córtex, as séries \(X_{t5}\) e \(X_{t6}\)
representam locais no tálamo e \(X_{t7}\) e \(X_{t8}\) representam locais no cerebelo.
Como fica evidente na Figura I.6, diferentes áreas do cérebro estão respondendo de maneira diferente e uma análise de componentes
principais pode ajudar a indicar quais locais estão respondendo com a maior potência espectral e quais locais não contribuem para a
potência espectral no período do sinal de estímulo. Nesta análise, vamos nos concentrar principalmente no periacute;odo de sinal de
64 segundos, que se traduz em quatro ciclos em 256 segundos ou \(\omega = 4/128\) ciclos por ponto de tempo.
Figura VII.16: Os periodogramas individuais de \(X_{tk}\), para \(k = 1,\cdots,8\).
A Figura VII.16 mostra periodogramas individuais das séries \(X_{tk}\) para \(k = 1,\cdots,8\). Como ficou evidente na Figura I.6, uma forte resposta
ao estímulo da escova ocorreu em áreas do córtex. Para estimar a densidade espectral de \(X_t\), usamos \(\widehat{f}_{_{XX}}(\omega)\) acima
com \(L = 5\) e \(\{h_0 = 3/9, h_{\pm 1} = 2/9, h_{\pm 2} = 1/9\}\); este é um kernel Daniell com \(m = 1\) passado duas vezes.
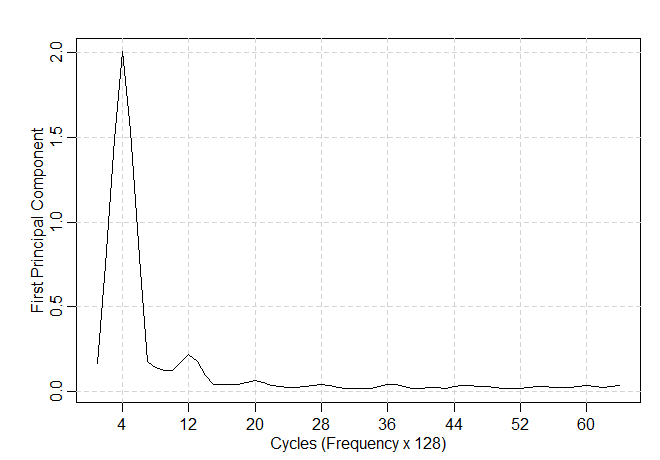
Chamando o espectro estimado de \(\widehat{f}_{_{XX}}(j/128)\), para \(j = 0,1,\cdots,64\); podemos obter o espectro estimado da primeira série de
componentes principais \(Y_{t1}\) calculando o maior autovalor \(\widehat{\lambda}_1(j/128)\), de \(\widehat{f}_{_{XX}}(j/128)\) para cada \(j = 0,1,\cdots,64\). O
resultado \(\widehat{\lambda}_1(j/128)\) é mostrado na Figura VII.17.
Figura VII.17: Envelope espectral amostral suavizado do gene BNRF1 do vírus Epstein-Barr: (a) primeiros
1000 bp, (b) segundos 1000 bp, (c) terceiro 1000 bp e (d) últimos 954 bp.
Como esperado, há um grande pico na frequência de estímulo \(4/128\), em que \(\widehat{\lambda}_1(4/128) = 2\). A potência total
na frequência de estímulo é \(\mbox{tr}\big(\widehat{f}_{_{XX}}(4/128)\big) = 2.05\), então a proporção da potência
na frequência 4/128 atribuída à primeira série de componentes principais é de cerca de 2/2.05 ou cerca de 98%. Como a
primeira componente principal explica quase toda a potência total na frequência do estímulo, não há necessidade de explorar
as outras séries de componentes principais nessa frequência.
Local
1
2
3
4
5
6
7
8
\(|\widehat{e}_1(4/128)|\)
0.64
0.36
0.36
0.22
0.32
0.05*
0.13
0.39
Tabela VII.5. Magnitudes do vetor de componentes principais na frequência de estímulo
*Zero está em uma região de confiança de aproximadamente 99% para este componente.
A primeira série de componentes principais estimada na frequência 4/128 é dada por
\begin{equation}
\widehat{Y}_{t1}(4/128) = \widehat{e}_1^*(4/128)X_t
\end{equation}
e os componentes de \(\widehat{e}_1^*(4/128)\) podem dar uma visão sobre quais locais do cérebro estão respondendo ao estímulo da escova.
A Tabela VII.5 mostra as magnitudes de \(\widehat{e}_1^*(4/128)\). Além disso, um intervalo de confiança de aproximadamente 99% foi obtido
para cada componente usando a distribuição aproximada de \(2|\widehat{e}_{1,j}(4/128)-e_{1,j}(4/128)|^2/s_j^2(4/128)\).
Como esperado, a análise indica que o local 6 não está contribuindo para o poder nesta frequência, mas surpreendentemente, a análise
sugere que o local 5 (cerebelo 1) está respondendo ao estímulo.
O código R para este exemplo é o seguinte:
A análise fatorial clássica é semelhante à análise clássica de componentes principais. Suponha que \(X\) seja um vetor
aleatório \(p\times 1\) de média zero com matriz de variâncias-covariâncias \(\Sigma_{_{XX}}\). O modelo de fatorial propõe
que \(X\) seja dependente de alguns fatores comuns não observados, \(Z_1,\cdots,Z_q\), mais erro. Nesse modelo, espera-se que \(q\) seja muito menor
que \(p\).
O modelo de fatorial é dado por
\begin{equation}
X \, = \, \mathcal{B}Z +\epsilon,
\end{equation}
onde \(\mathcal{B}\) é uma matriz \(p\times p\) de cargas fatoriais \(Z = (Z_1,\cdots,Z_q)^\top\), as quais são vetores \(q\times 1\) aleatórios
de fatores tais que \(\mbox{E}(Z) = 0\) e \(\mbox{E}(ZZ^\top) = I_q\), a matriz de identidade \(q\times q\). O vetor \(p\times 1\) de erro \(\epsilon\) não
observado é considerado independente dos fatores, com média zero e matriz diagonal de variâncias-covariâncias
\begin{equation}
D \, = \, \mbox{diag}\{\delta_1^2,\cdots,\delta_p^2\}\cdot
\end{equation}
Observe, o modelo fatorial difere do modelo de regressão multivariado na Seção V.6 porque os fatores \(Z\), não são observados.
De forma equivalente, o modelo fatoral acima, pode ser escrito em termos da estrutura de covariância de \(X\),
\begin{equation}
\Sigma_{_{XX}} \, = \, \mathcal{B}\mathcal{B}^\top + D,
\end{equation}
ou seja, a matriz de variâncias-covariâncias de \(X\) é a soma de uma matriz simétrica, definida não negativa e posto
\(q\leq p\) e uma matriz diagonal definida não negativa. Se \(q = p\), então \(\Sigma_{_{XX}}\) pode ser reproduzido exatamente como
\(\mathcal{B}\mathcal{B}^\top\), usando o fato de que \(\Sigma_{_{XX}} = \lambda_1 e_1 e_1^\top + \cdots + \lambda_p e_p e_p^\top\), onde \((\lambda_i,e_i)\)
são os pares autovalor – autovetor de \(\Sigma_{_{XX}}\). No entanto, conforme indicado anteriormente, esperamos que \(q\) seja muito menor que \(p\).
Infelizmente, a maioria das matrizes de covariâncias não pode ser fatorada da forma acima quando \(q\) é muito menor que \(p\).
Para motivar a análise fatorial, suponha que os componentes de \(X\) possam ser agrupados em grupos significativos. Dentro de cada grupo, os componentes
são altamente correlacionados, mas a correlação entre variáveis que não estão no mesmo grupo é pequena.
Um grupo é supostamente formado por um único construto, representado como um fator não observável, responsável pelas
altas correlações dentro de um grupo. Por exemplo, uma pessoa competindo em um decatlo realiza \(p = 10\) eventos atléticos e podemos
representar o resultado do decatlo como um vetor de pontuação \(10\times 1\). Os eventos em um decatlo envolvem corrida, salto ou arremesso e
é concebível que o vetor \(10\times 1\) de pontuações possa ser fatorado em \(q = 4\) fatores, (1) força do braço,
(2) força da perna, (3) velocidade de corrida e (4) resistência de corrida. O modelo fatorial especifica que \(\mbox{Cov}(X,Z) = \mathcal{B}\)
ou \(\mbox{Cov}(X_i,Z_j) = b_{ij}\) onde \(b_{ij}\) é o \(ij\)-ésimo componente da matriz de carregamento fatorial \(\mathcal{B}\), para
\(i = 1,\cdots,p\) e \(j = 1,\cdots,q\). Assim, os elementos de \(\mathcal{B}\) são usados para identificar a quais fatores hipotéticos os
componentes de \(X\) pertencem ou sobre os quais se carregam.
Neste ponto, alguma ambigüidade ainda está associada ao modelo fatorial. Seja \(Q\) uma matriz \(q\times q\) ortogonal; isto é
\begin{equation}
Q^\top Q \, = \, QQ^\top \, = \, I_q\cdot
\end{equation}
Seja \(\mathcal{B}_*=\mathcal{B}Q\) e \(Z_*=Q^\top Z\) de maneira que o modelo fatorial pode ser escrito como
\begin{equation}
X \, = \, \mathcal{B}Z +\epsilon \, = \, \mathcal{B} QQ^\top Z+\epsilon \, = \, \mathcal{B}_* Z_*+\epsilon\cdot
\end{equation}
O modelo em termos de \(\mathcal{B}_*\) e \(Z_*\) atende a todos os requisitos do modelo fatorial, por exemplo,
\begin{equation}
\mbox{Cov}(Z_*) \, = \, Q^\top \mbox{Cov}(Z)Q \, = \, QQ^\top \, = \, I_q,
\end{equation}
portanto
\begin{equation}
\Sigma_{_{XX}} \, = \, \mathcal{B}_* \mbox{Cov}(Z_*)\mathcal{B}_*^\top + D \, = \, \mathcal{B} Q Q^\top \mathcal{B}^\top + D
\, = \, \mathcal{B}\mathcal{B}^\top + D\cdot
\end{equation}
Portanto, com base nas observações em \(x\), não podemos distinguir entre os carregamentos \(\mathcal{B}\) e os carregamentos rotacionados
\(\mathcal{B}_* = \mathcal{B}Q\). Tipicamente, \(Q\) é escolhido de forma que a matriz \(\mathcal{B}\) seja fácil de interpretar e
é a base do que é chamado de rotação fatorial.
Dada uma amostra \(x_1,\cdots,x_n\), vários métodos são usados para estimar os parâmetros do modelo fatorial e
discutiremos dois deles aqui. O primeiro método é o método de componentes principais.
Seja \(S_{_{XX}}\) a matriz de variâncias-covariâncias amostral e seja \((\widehat{\lambda}_i,\widehat{e}_i)\) os pares autovalor – autovetor
de \(S_{_{XX}}\). A matriz \(p\times q\) de cargas fatoriais estimadas é encontrada definindo
\begin{equation}
\widehat{\mathcal{B}} \, = \, \left(\left. \widehat{\lambda}_1^{1/2}\widehat{e}_1\right| \left. \widehat{\lambda}_2^{1/2}\widehat{e}_2\right|
\quad \cdots \quad \left| \widehat{\lambda}_q^{1/2}\widehat{e}_q\right. \right)\cdot
\end{equation}
O argumento aqui é que se \(q\) fatores existirem, então
\begin{equation}
S_{_{XX}} \, \approx \, \widehat{\lambda}_1\widehat{e}_1\widehat{e}_1^\top + \cdots + \widehat{\lambda}_q\widehat{e}_q\widehat{e}_q^\top \, = \,
\widehat{\mathcal{B}}\widehat{\mathcal{B}}^\top,
\end{equation}
porque os autovalores restantes, \(\widehat{\lambda}_{q+1},\cdots,\widehat{\lambda}_p\), serão insignificantes. A matriz diagonal estimada
das variâncias dos erros é então obtida definindo \(\widehat{D} = \mbox{diag}\{\widehat{\delta}_1^2,\cdots,\widehat{\delta}_p^2\}\);
onde \(\widehat{\delta}_j^2\) é o \(j\)-ésimo elemento da diagonal de \(S_{_{XX}}-\widehat{\mathcal{B}}\widehat{\mathcal{B}}^\top\).
O segundo método, que pode fornecer respostas consideravelmente diferentes do método de componentes principais é a máxima
verossimilhança. Supondo ainda que no modelo fatorial \(Z\) e \(\epsilon\) sejam normais multivariados, o logaritmo da verossimilhança
de \(\mathcal{B}\) e \(D\), ignorando uma constante é
\begin{equation}
-2\ln\big( L(\mathcal{B},D)\big) \, = \, n\ln\big(|\Sigma_{_{XX}}| \big) +\sum_{j=1}^n X_j^\top \Sigma_{_{XX}}^{-1}X_j\cdot
\end{equation}
A verossimilhança depende de \(\mathcal{B}\) e \(D\) por meio da relação \(\Sigma_{_{XX}} \, = \, \mathcal{B}\mathcal{B}^\top + D\).
Como discutido acima, a verossimilhança não é bem definida porque \(\mathcal{B}\) pode ser rotacionado. Restringir
\(\mathcal{B}D^{-1}\mathcal{B}^\top\) para ser uma matriz diagonal é uma condição de unicidade computacionalmente conveniente.
A maximização real da verossimilhança é realizada usando métodos numéricos.
Um método óbvio de realizar a máxima verossimilhança para o modelo fatorial Gaussiano é o algoritmo EM. Por exemplo,
suponha que o vetor de fatores \(Z\) seja conhecido. Então, o modelo fatorial é simplesmente o modelo de regressão multivariada
dado na Seção V.6, ou seja, escrevendo \(X^\top=(x_1,x_2,\cdots,x_n)\) e \(Z^\top=(z_1,z_2,\cdots,z_n)\) e observando que \(X\) é
uma matriz \(n\times p\) e \(Z\) é uma matriz \(n\times q\). Então, o estimador de máxima verossimilhança de \(\mathcal{B}\)
é
\begin{equation}
\widehat{\mathcal{B}} \, = \, X^\top Z(Z^\top Z)^{-1} \, = \, C_{_{XZ}}C_{_{ZZ}}^{-1},
\end{equation}
onde
\begin{equation}
C_{_{XZ}} \, = \, \dfrac{1}{n}\sum_{j=1}^n x_j z_j^\top \qquad \mbox{ e } \qquad C_{_{ZZ}} \, = \, \dfrac{1}{n}\sum_{j=1}^n z_j z_j^\top,
\end{equation}
e o estimador de máxima verossimilhança de \(D\) é
\begin{equation}
\widehat{D} \, = \, \mbox{diag}\left\{ \frac{1}{n}\sum_{j=1}^n \big( x_j-\widehat{\mathcal{B}} z_j\big)\big( x_j-\widehat{\mathcal{B}} z_j\big)^\top\right\};
\end{equation}
ou seja, apenas os elementos diagonais do lado direito da expressão acima são usados. A quantidade entre parênteses acima se reduz para
\begin{equation}
C_{_{XX}} - C_{_{XZ}}C_{_{ZZ}}^{-1}C_{_{XZ}}^\top,
\end{equation}
onde \(C_{_{XX}}=\frac{1}{n}\sum_{j=1}^n x_j x_j^\top\).
Com base na derivação do algoritmo EM para o modelo de espaço de estados, concluímos que, para empregar o algoritmo EM aqui,
dadas as estimativas dos parâmetros atuais, em \(C_{_{XZ}}\), substituímos \(x_j z_j^\top\) por \(x_j \widetilde{z}_j^\top\), onde
\begin{equation}
\widetilde{z}_j \, = \, \mbox{E}(Z_j \, | \, x_j)
\end{equation}
e em \(C_{_{ZZ}}\), substituímos \(z_j z_j^\top\) por \(P_{_Z}+\widetilde{z}_j \widetilde{z}_j^\top\), onde
\begin{equation}
P_{_Z} \, = \, \mbox{Var}(Z_j \, | \, x_j)\cdot
\end{equation}
Usando o fato de que o vetor \((x_j^\top,z_j^\top)^\top\) de dimensão \((p+q)\times 1\) é normal multivariado com média zero e matriz de variâncias-covariâncias
dada por
\begin{pmatrix}
\mathcal{B}\mathcal{B}^\top + D & \mathcal{B} \\ \mathcal{B}^\top & I_q
\end{pmatrix}
temos
\begin{equation}
\widetilde{z}_j \, = \, \mbox{E}(Z_j \, | \, x_j) \, = \, \mathcal{B}^\top (\mathcal{B}^\top\mathcal{B}+D)^{-1} x_j
\end{equation}
e
\begin{equation}
P_{_Z} \, = \, \mbox{Var}(Z_j \, | \, x_j) \, = \, I_q -\mathcal{B}^\top (\mathcal{B}^\top\mathcal{B}+D)^{-1}\mathcal{B}\cdot
\end{equation}
Para séries temporais, suponha que \(X_t\) seja um processo \(p\times 1\) estacionário com matriz \(p\times p\) espectral \(f_{_{XX}}(\omega)\). Análogo ao modelo clássico,
podemos postular que em uma dada frequência de interesse \(\omega\), a matriz espectral de \(X_t\) satisfaz
\begin{equation}
f_{_{XX}}(\omega) \, = \, \mathcal{B}(\omega)\mathcal{B}^*(\omega)+D(\omega),
\end{equation}
onde \(\mathcal{B}(\omega)\) é uma matriz complexa de posto \(\mbox{posto}\big(\mathcal{B}(\omega)\big)=q\leq p\) e \(\mathcal{D}(\omega)\) é
uma matriz real diagonal, definida não negativa. Tipicamente, esperamos que \(q\) seja muito menor que \(p\).
Como exemplo de um modelo que dá origem à relação anterior, seja \(x_t = (x_{t1},\cdots,x_{tp})^\top\) e suponha
\begin{equation}
x_{tj} \, = \, c_j s_{t-\tau_j}+\epsilon_{tj}, \qquad j=1,\cdots,p,
\end{equation}
onde \(c_j\geq 0\) são amplitudes individuais e \(s_t\) é um sinal (fator) comum não observado com densidade espectral \(f_{_{ss}}(\omega)\).
Os valores \(\tau_j\) são as mudanças de fase individuais. Suponha que \(s_t\) seja independente de \(\epsilon_t = (\epsilon_{t1}\cdots,\epsilon_{tp})^\top\)
e a matriz espectral de \(\epsilon_t\), \(D_{_{\epsilon\epsilon}}(\omega)\) seja diagonal.
A transformada discreta de Fourier de \(x_{tj}\) é dada por
\begin{equation}
X_j(\omega) \, = \, \dfrac{1}{\sqrt{n}}\sum_{t=1}^n x_{tj} \exp\big( -2\pi \, i \, t\omega\big)
\end{equation}
e, em termos do modelo \(x_{tj} = c_j s_{t-\tau_j}+\epsilon_{tj}\), para \(j=1,\cdots,p\),
\begin{equation}
X_j(\omega) \, = \, a_j(\omega)X_s(\omega)+X_{{\epsilon_j}}(\omega),
\end{equation}
onde \(a_j(\omega)=c_j\exp\big(-2\pi \, i\, \tau_j \omega \big)\) e \(X_s(\omega)\) e \(X_{{\epsilon_j}}(\omega) \) são as respectivas transformadas
discretas de Fourier do sinal \(s_t\) e do ruído \(\epsilon_{tj}\).
Empilhando os elementos individuais de \(X_j(\omega) = a_j(\omega)X_s(\omega)+X_{{\epsilon_j}}(\omega)\), obtemos uma versão complexa do modelo fatorial
clássico com um fator,
\begin{equation}
\begin{pmatrix} X_1(\omega) \\ \vdots \\ X_p(\omega) \end{pmatrix} \, = \, \begin{pmatrix} a_1(\omega) \\ \vdots \\ a_p(\omega) \end{pmatrix}X_s(\omega)+
\begin{pmatrix} X_{\epsilon_1}(\omega) \\ \vdots \\ X_{\epsilon_p}(\omega) \end{pmatrix},
\end{equation}
ou mais sucintamente,
\begin{equation}
X(\omega) \, = \, a(\omega)X_s(\omega)+X_\epsilon(\omega)\cdot
\end{equation}
Da relação acima, podemos identificar os componentes espectrais do modelo; isso é,
\begin{equation}
f_{_{XX}}(\omega) \, = \, b(\omega)b^*(\omega)+D_{\epsilon\epsilon}(\omega),
\end{equation}
onde onde \(b(\omega)\) é um vetor \(p\times 1\) de valor complexo e
\begin{equation}
b(\omega)b(\omega)^* \, = \, a(\omega)f_{_{ss}}(\omega)a(\omega)^*\cdot
\end{equation}
O modelo \(f_{_{XX}}(\omega) = b(\omega)b^*(\omega)+D_{\epsilon\epsilon}(\omega)\) pode ser considerado o modelo fatorial de um fator para séries temporais.
Este modelo pode ser estendido para mais de um fator adicionando outros sinais independentes no modelo original \(x_{tj} = c_j s_{t-\tau_j}+\epsilon_{tj}\), para \(j=1,\cdots,p\).
Mais detalhes sobre este e modelos relacionados podem ser encontrados em Stoffer (1999).
Exemplo VII.14. Análise fatorial simple dos dados de fMRI.
Os dados de fMRI analisados no Exemplo VII.13 são bem adequados para uma análise fatorial de um único fator usando o modelo
\(x_{tj} = c_j s_{t-\tau_j}+\epsilon_{tj}\), para \(j=1,\cdots,p\) ou, de forma equivalente, o modelo fatorial de um único fator de valor complexo
\(X(\omega) = a(\omega)X_s(\omega)+X_\epsilon(\omega)\). Em termos de \(x_{tj} = c_j s_{t-\tau_j}+\epsilon_{tj}\), para \(j=1,\cdots,p\), podemos pensar no
sinal \(s_t\) como representando o sinal de estímulo da escova. Como antes, a frequência de interesse é \(\omega = 4/128\), que corresponde
a um período de 32 pontos no tempo ou 64 segundos.
Uma maneira simples de estimar os componentes \(b(\omega)\) e \(D_{\epsilon\epsilon}(\omega)\), conforme especificado em
\begin{equation}
f_{_{XX}}(\omega) \, = \, b(\omega)b^*(\omega)+D_{\epsilon\epsilon}(\omega)
\end{equation}
é usar o método dos componentes principais.
Seja \(\widehat{f}_{_{XX}}(\omega)\) a estimativa da densidade espectral de \(X_t = (x_{t1},\cdots,x_{t8})^\top\) obtida no Exemplo VII.13. Então, de forma análoga a
\begin{equation}
\widehat{\mathcal{B}} \, = \, \left(\left. \widehat{\lambda}_1^{1/2}\widehat{e}_1\right| \left. \widehat{\lambda}_2^{1/2}\widehat{e}_2\right|
\quad \cdots \quad \left| \widehat{\lambda}_q^{1/2}\widehat{e}_q\right. \right)
\end{equation}
e
\begin{equation}
S_{_{XX}} \, \approx \, \widehat{\lambda}_1\widehat{e}_1\widehat{e}_1^\top + \cdots + \widehat{\lambda}_q\widehat{e}_q\widehat{e}_q^\top \, = \,
\widehat{\mathcal{B}}\widehat{\mathcal{B}}^\top,
\end{equation}
definimos
\begin{equation}
\widehat{b}(\omega) \, = \, \sqrt{\widehat{\lambda_1}(\omega)}\widehat{e}_1(\omega),
\end{equation}
onde
Os elementos diagonais de \(\widehat{D}_{\epsilon\epsilon}(\omega)\) são obtidos a partir dos elementos diagonais de \(\widehat{f}_{_{XX}}(\omega)-\widehat{b}(\omega) \widehat{b}(\omega)^*\).
A adequação do modelo pode ser avaliada verificando se os elementos da matriz residual
\begin{equation}
\widehat{f}_{_{XX}}(\omega)-\left(\widehat{b}(\omega) \widehat{b}(\omega)^*+\widehat{D}_{\epsilon\epsilon}(\omega) \right),
\end{equation}
são desprezíveis em magnitude.
Concentrando-se na frequência do estímulo \(\widehat{\lambda}_1(4/128) = 2\):
(a) As magnitudes de \(\widehat{e}_1(4/128)\) foram exibidas na Tabela VII.5, indicando a carga de todos os locais no fator de estímulo, exceto o local 6 e o local 7 podem ser
considerados limítrofes
(b) Os elementos diagonais de \(\widehat{f}_{_{XX}}(\omega)-\widehat{b}(\omega) \widehat{b}(\omega)^*\) são
\begin{equation}
\widehat{D}_{\epsilon\epsilon}(4/128) \, = \, 0.001\times \mbox{diag}\{1.36, 2.04, 6.22, 11.30, 0.73, 12.26, 6.93, 5.88\}\cdot
\end{equation}
Diversos autores consideraram a análise fatorial no domínio espectral, por exemplo Priestley et al. (1974); Priestley and Subba Rao (1975);
Geweke (1977) e Geweke and Singleton (1981), para mencionar alguns.
Uma extensão óbvia do modelo simples \(x_{tj} = c_j s_{t-\tau_j}+\epsilon_{tj}\), é o modelo fatorial
\begin{equation}
X_t \, = \, \sum_{j=-\infty}^\infty \Lambda_j s_{t-j}+\epsilon_{t},
\end{equation}
onde \(\{\Lambda_j\}\) é um filtro \(p\times q\) de valor real, \(s_t\) é um sinal estacionário de dimensão \(q\times 1\), não observado,
com componentes independentes e \(\epsilon_t\) é ruído branco.
Assumimos que os processos de sinal e ruído são independentes, \(s_t\) tem dimensão \(q\times q\), matriz espectral diagonal
\begin{equation}
f_{_{ss}}(\omega) \, = \, \mbox{diag}\{f_{_{s1}}(\omega),\cdots,f_{_{sq}}(\omega)\}
\end{equation}
real e \(\epsilon_t\) tem uma matriz espectral real, diagonal, \(p\times p\) dada por
\begin{equation}
D_{_{\epsilon\epsilon}}(\omega) \, = \, \mbox{diag}\{ f_{_{\epsilon 1}}(\omega),\cdots,f_{_{\epsilon q}}(\omega)\}\cdot
\end{equation}
Se, além disso, \(\sum|| \Lambda_j||<\infty\), a matriz espectral de \(X_t\) pode ser escrita como
\begin{equation}
f_{_{XX}}(\omega) \, = \, \Lambda(\omega)f_{_{ss}}(\omega)\Lambda^*(\omega) + D_{_{\epsilon\epsilon}}(\omega) \, = \,
\mathcal{B}(\omega)\mathcal{B}^*(\omega)+D_{_{\epsilon\epsilon}}(\omega),
\end{equation}
onde
\begin{equation}
\Lambda(\omega) \, = \, \sum_{t=-\infty}^\infty \Lambda_t\exp\big( -2\pi \,i \, t\omega\big)
\end{equation}
e \(\mathcal{B}(\omega)=\Lambda(\omega)f_{_{ss}}^{1/2}(\omega)\).
Assim, por \(f_{_{XX}}(\omega) = \mathcal{B}(\omega)\mathcal{B}^*(\omega)+D_{_{\epsilon\epsilon}}(\omega)\), o modelo \(X_t = \sum_{j=-\infty}^\infty \Lambda_j s_{t-j}+\epsilon_{t}\)
é visto que satisfaz o requisito básico do modelo de análise fatorial de domínio espectral; isto é, a matriz de densidade
espectral \(p\times p\) do processo de interesse \(f_{_{XX}}(\omega)\), é a soma de uma matriz de posto \(q\leq p\), \(\mathcal{B}(\omega)\mathcal{B}^*(\omega)\) e
uma matriz diagonal real, \(D_{_{\epsilon\epsilon}}(\omega)\). Para efeitos de identificabilidade, definimos \(f_{_{ss}}(\omega) = I_q\) para todo \(\omega\);
nesse caso, \(\mathcal{B}(\omega) = \Lambda(\omega)\). Como no caso clássico, o modelo é especificado apenas até as rotações; para
obter detalhes, consulte Bloomfield and Davis (1994).
A estimação dos parâmetros do modelo \(f_{_{XX}}(\omega) = \mathcal{B}(\omega)\mathcal{B}^*(\omega)+D_{_{\epsilon\epsilon}}(\omega)\), pode ser realizada
usando o método de componentes principais. Seja \(\widehat{f}_{_{XX}}(\omega)\) uma estimativa de \(f_{_{XX}}(\omega)\) e sejam
\begin{equation}
\big(\widehat{\lambda}_1(\omega),\widehat{e}_1(\omega) \big), \big(\widehat{\lambda}_2(\omega),\widehat{e}_2(\omega) \big), \; \cdots \; ,\big(\widehat{\lambda}_p(\omega),\widehat{e}_p(\omega) \big)
\end{equation}
os pares autovalor–autovetor, na ordem usual, de \(\widehat{f}_{_{XX}}(\omega)\). Então, como no caso clássico, a matriz \(p\times q\) \(\mathcal{B}\) é estimada por
\begin{equation}
\widehat{\mathcal{B}}(\omega) \, = \, \left( \left. \widehat{\lambda}_1^{1/2}(\omega)\widehat{e}_1(\omega) \, \right| \,
\left. \widehat{\lambda}_2^{1/2}(\omega)\widehat{e}_2(\omega) \, \right| \quad \cdots \quad
\left| \widehat{\lambda}_q^{1/2}(\omega)\widehat{e}_q(\omega) \right. \right)\cdot
\end{equation}
A matriz de densidade espectral diagonal estimada de erros é então obtida ajustando
\begin{equation}
\widehat{D}_{_{\epsilon\epsilon}}(\omega) \, = \, \mbox{diag}\{ \widehat{f}_{_{\epsilon 1}}(\omega),\cdots,\widehat{f}_{_{\epsilon q}}(\omega)\}
\end{equation}
onde \(\widehat{f}_{_{\epsilon j}}(\omega)\) é o \(j\)-ésimo elemento da diagonal de \(\widehat{f}_{_{XX}}(\omega)-\widehat{\mathcal{B}}(\omega)\widehat{\mathcal{B}}^*(\omega)\).
Alternativamente, podemos estimar os parâmetros por métodos de verossimilhança aproximada. Como em \(X(\omega) = a(\omega)X_s(\omega)+X_\epsilon(\omega)\),
seja \(X(\omega_j)\) a transformada discreta de Fourier dos dados \(x_1,\cdots,x_n\) na frequência \(\omega_j = j/n\). Da mesma forma, sejam \(Xs(\omega_j)\) e
\(X_\epsilon(\omega_j)\) as tranformadas discretas de Fourier dos processos de sinal e ruído, respectivamente. Então, sob certas condições
(ver Pawitan and Shumway, 1989), para \(\ell= 0,\pm 1, \pm 2,\cdots,\pm m\),
\begin{equation}
X(\omega_j+\ell/n) \, = \, \Lambda(\omega_j)X_s(\omega_j+\ell/n)+X_\epsilon(\omega_j+\ell/n)+o_{as}(n^{-\alpha})
\end{equation}
onde \(\Lambda(\omega_j)\) foi dado anteriormente e \(o_{as}(n^{-\alpha})\to 0\) quase certamente para algum \(0\leq \alpha <1/2\) quando \(n\to\infty\). Na expressão acima,
os \(X(\omega_j+\ell/n)\) são as transformadas discretas de Fourier dos dados nas \(L\) frequências ímpares \(\{\omega_j+\ell/n \, : \, \ell= 0,\pm 1,\cdots,\pm m\}\)
em torno da frequência central de interesse \(\omega_j= j/n\).
Sob condições apropriadas, quando \(n\to\infty\), a sequência \(\{X(\omega_j+\ell/n) \, : \, \ell= 0,\pm 1,\cdots,\pm m\}\) é formada de vetores aleatórios
Gaussianos complexos independentes com matriz de variâncias-covariâncias \(f_{_{XX}}(\omega_j)\).
A verossimilhança aproximada é dada por
\begin{equation}
\left|-2\ln\Big(L\big(\mathcal{B}(\omega_j), D_{_{\epsilon\epsilon_j}}(\omega)\big)\Big)\right| \, = \, n\ln\big(|f_{_{XX}}(\omega_j)|\big)+
\sum_{\ell=-m}^m X^*(\omega_j+\ell/n)f_{_{XX}}^{-1}(\omega_j)X(\omega_j+\ell/n),
\end{equation}
com a restrição \(f_{_{XX}}(\omega_j)=\mathcal{B}(\omega_j)\mathcal{B}^*(\omega_j)+D_{_{\epsilon\epsilon}}(\omega_j)\). Como no caso clássico, podemos usar vários
métodos numéricos para maximizar a verossimilhança em todas as frequências \(\omega_j\), de interesse. Por exemplo, o algoritmo EM discutido para
o caso clásico, pode ser estendido para este caso.
Assumindo \(f_{_{ss}}(\omega)=I_q\), a estimativa de \(\mathcal{B}(\omega_j)\) é também a estimativa de \(\Lambda(\omega_j)\). Chamando esta estimativa de
\(\widehat{\Lambda}(\omega_j)\), o filtro no domínio do tempo pode ser estimado por
\begin{equation}
\widehat{\Lambda}_t^M \, = \, \dfrac{1}{M}\sum_{j=0}^{M-1} \widehat{\Lambda}(\omega_j)\exp\big( -2\pi \, i \, jt/n\big),
\end{equation}
para alguns \(0 < M \leq n\), que é a versão discreta e finita da fórmula de inversão dada por
\begin{equation}
\Lambda_t \, = \, \int_{-1/2}^{1/2} \Lambda(\omega)\exp\big( -2\pi \, i \, \omega t\big)\mbox{d}\omega\cdot
\end{equation}
Observe que usamos essa aproximação anteriormente no Capítulo IV, para estimar a resposta em tempo de uma função de resposta
em frequência definida em um número finito de frequências.
Exemplo VII.15. Gastos do governo, investimento privado e desemprego.
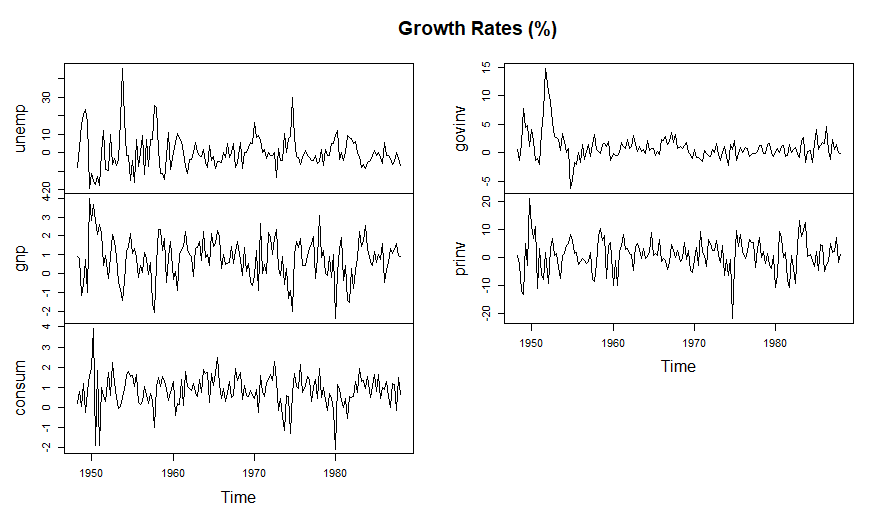
A Figura VII.18 mostra a taxa de crescimento trimestral ajustada sazonalmente (como porcentagens) de cinco séries macroeconôicas: desemprego (unemp),
PIB (gnp), consumo (consum), investimento governamental (govinv) e investimento privado (prinv) nos Estados Unidos
entre 1948 e 1988, \(n = 160\) valores. Esses dados são analisados no domínio do tempo por Young and Pedregal (1998), que investigavam como os gastos do governo e o investimento de capital privado
influenciavam a taxa de desemprego.
Figura VII.18: A taxa de crescimento trimestral ajustada sazonalmente (como porcentagens) de cinco séries macroeconômicas: desemprego,
PIB, consumo, investimento público e investimento privado nos Estados Unidos entre 1948 e 1988, \(n = 160\) valores.
A estimativa espectral foi realizada nos valores da taxa de crescimento sem tendência, padronizada e afilada; consulte o código R no final deste exemplo para obter detalhes.
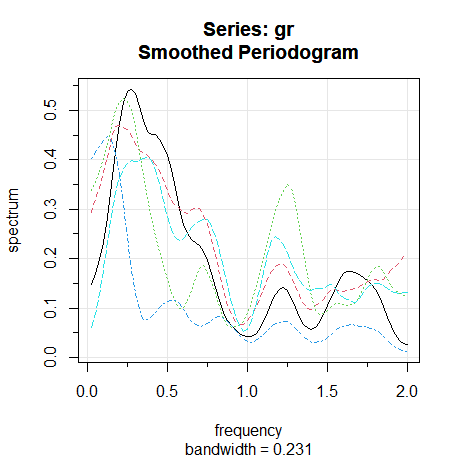
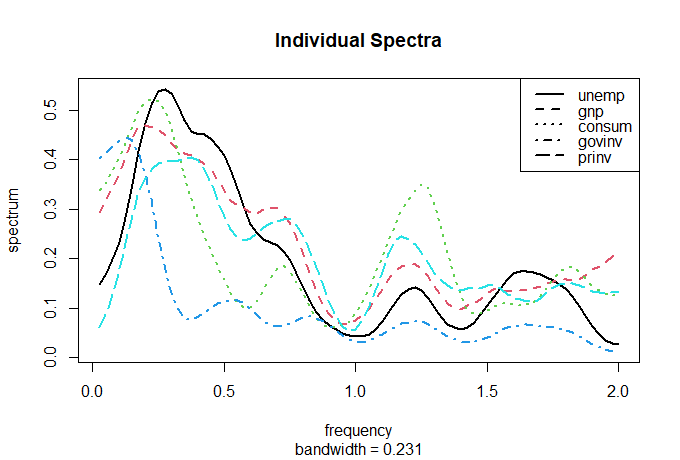
A Figura VII.19 (abaixo) mostra os espectros estimados individuais de cada série. Concentramo-nos em três frequências interessantes. Em primeiro lugar, notamos
a falta de potência espectral perto do ciclo anual \(\omega = 1\) ou um ciclo a cada quatro trimestres; indicando que os dados foram ajustados sazonalmente.
Além disso, devido ao ajuste sazonal, alguma potência espectral aparece perto da frequência sazonal; esta é uma distorção aparentemente
causada pelo método de ajuste sazonal dos dados. Em seguida, notamos o poder espectral próximo \(\omega =0.25\), ou um ciclo a cada quatro anos, no desemprego,
PIB, consumo e, em menor grau, no investimento privado. Finalmente, o poder espectral parece próximo \(\omega = 0.125\), ou um ciclo a cada oito anos em investimento
governamental e talvez em menor grau em desemprego, PIB e consumo.
Figura VII.19: Os espectros estimados individuais (em escala de 1000) de cada série são mostrados na Figura 7.18 em termos do número de ciclos em 160 trimestres.
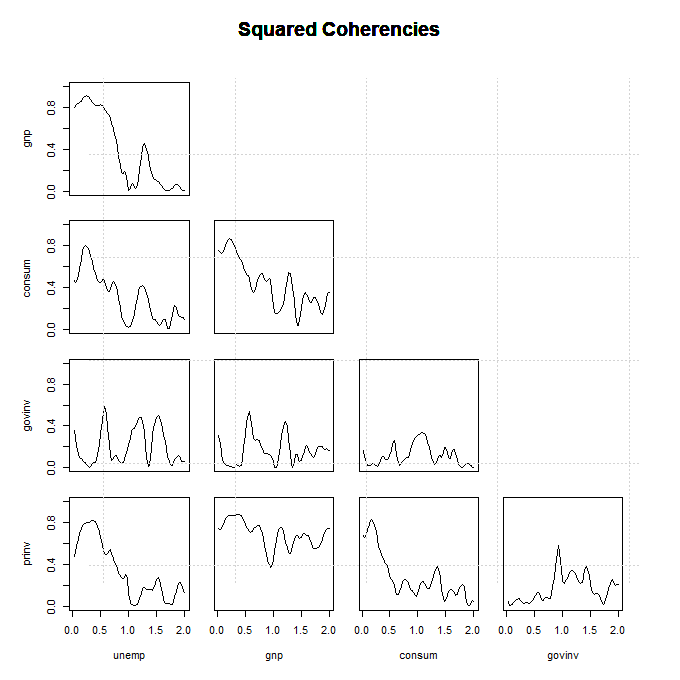
A Figura VII.20 mostra as coerências entre as várias séries. Nas frequências de interesse, \(\omega =0.125\) e \(\omega=0.25\), aos pares, PIB, Desemprego, Consumo
e Investimento Privado (exceto Desemprego e Investimento Privado) são coerentes. O investimento governamental não é coerente ou é minimamente coerente com as
outras séries.
Figura VII.20: As coerências quadradas entre as várias séries exibidas na Figura VII.18.
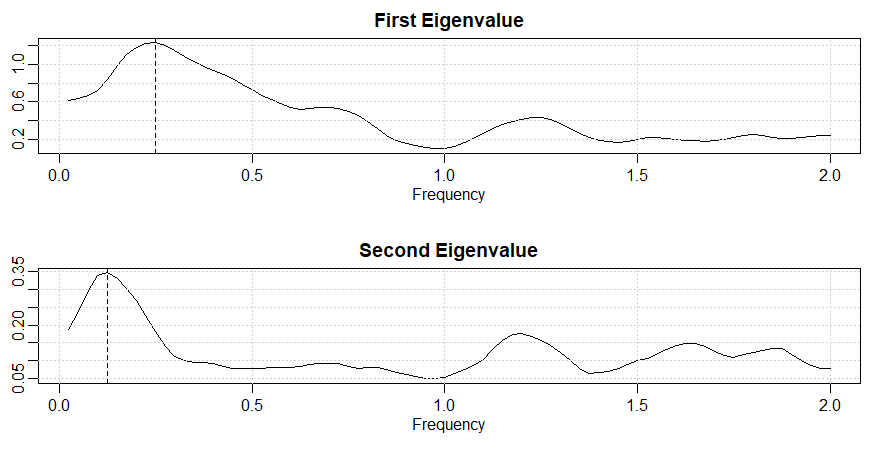
A Figura VII7.21 mostra \(\widehat{\lambda}_1(\omega)\) e o segundo \(\widehat{\lambda}_2(\omega)\), o primeiro e o segundo valores próprios da matriz espectral estimada
\(\widehat{f}_{_{XX}}(\omega)\). Esses valores próprios sugerem que o primeiro fator é identificado pela frequência de um ciclo a cada quatro anos, enquanto
o segundo fator é identificado pela frequência de um ciclo a cada oito anos. O módulo dos autovetores correspondentes nas frequências de interesse,
\(\widehat{e}_1(10/160)\) e \(\widehat{e}_2(5/160)\); são mostrados na Tabela VII.6. Esses valores confirmam a carga de Desemprego, PIB, Consumo e Investimento Privado
no primeiro fator e cargas de Investimento do Governo no segundo fator. O restante dos detalhes envolvendo a análise fatorial de esses dados são deixados como
um exercício.
Figura VII.21: O primeiro \(\widehat{\lambda}_1(\omega)\) e o segundo \(\widehat{\lambda}_2(\omega)\) valores próprios da matriz espectral
estimada \(\widehat{f}_{_{XX}}(\omega)\). As linhas tracejadas verticais nos picos são \(\omega=0.25\) e \(\omega=0.125\), respectivamente.
Realize análises de componentes principais nas condições de estímulo (i) acordado-calor e (ii) acordado-choque, e compare seus resultados
com os resultados do Exemplo VII.13. Use os dados em fmri, pacote astsa e faça a média entre os sujeitos.
Para este problema, considere as três primeiras séries de terremotos (EQ1, EQ2, EQ3) listadas em eqexp, pacote astsa.
(a) Estime e compare a densidade espectral do componente P e, em seguida, do componente S para cada terremoto individual.
(b) Estime e compare a coerência quadrada entre os componentes P e S de cada terremoto individual. Comente sobre a força da coerência.
(c) Seja \(X_{ti}\) o componente P do terremoto \(i = 1,2,3\) e seja \(X_t = (X_{t1},X_{t2},X_{t3})^\top\) o vetor \(3\times 1\) de componentes P.
Estime a densidade espectral, \(\lambda_1(\omega)\), da primeira série de componentes principais de \(X_t\). Compare isso com os espectros correspondentes
calculados em (a).
(d) Analogamente à parte (c), seja \(Y_t\) a série de vetores \(3\times 1\) dos componentes S dos três primeiros terremotos.
Repita a análise da parte (c) em \(Y_t\).
No modelo de anáise fatorial \(\Sigma_{_{XX}}=\mathcal{B}\mathcal{B}^\top+D\), seja \(p=3\), \(q=1\) e
\begin{equation}
\Sigma_{_{XX}} \, = \, \begin{pmatrix} 1 & 0.4 & 0.9 \\ 0.4 & 1 & 0.7 \\ 0.9 & 0.7 & 1 \end{pmatrix}\cdot
\end{equation}
Mostre que há uma escolha única para \(\mathcal{B}\) e \(D\), mas \(\delta_3^2 <0\), então a escolha não é válida.