O conceito de envelope espectral para a análise espectral e escalonamento de séries temporais categóricas foi introduzido pela primeira vez
em Stoffer et al. (1993). Desde então, a ideia foi estendida em várias direções, não apenas restrita a séries temporais
categóricas, e iremos explorar esses problemas também. Primeiro, damos uma breve introdução ao conceito de escalonamento de séries
temporais.
O envelope espectral foi motivado por colaborações com pesquisadores que coletaram séries temporais de valores categóricos com interesse
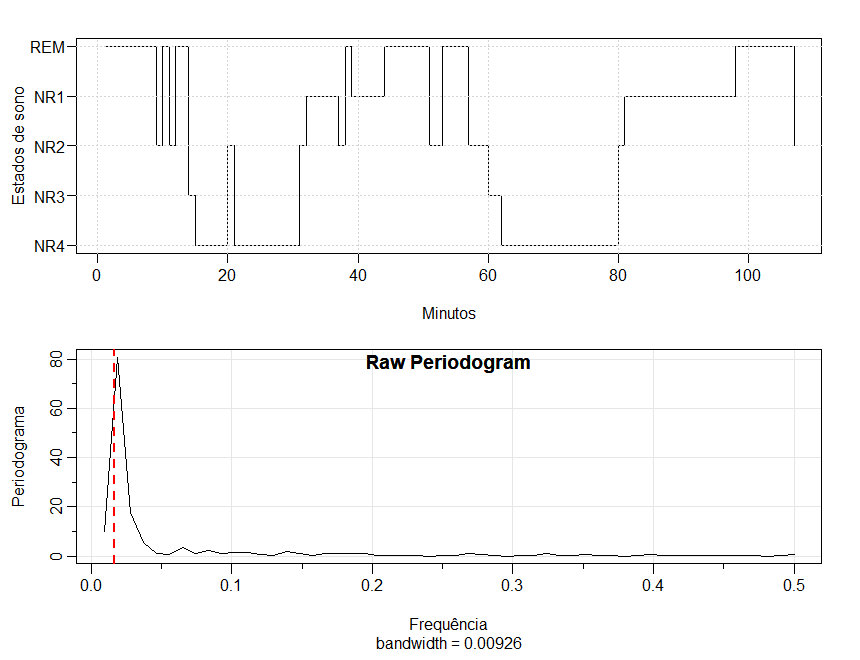
no comportamento cíclico dos dados. Por exemplo, no vetor EEG mostramos o estado de sono por minuto de uma criança obtido em um estudo sobre os efeitos
da exposição pré-natal ao álcool. Detalhes podem ser encontrados em Stoffer et al. (1988), mas brevemente, um registro eletroencefalográfico (EEG)
do sono de aproximadamente duas horas é obtido em um bebé 24 a 36 horas após o nascimento e o registro é avaliado por um neurologista
pediátrico para o estado de sono. Existem dois tipos principais de sono: movimento ocular não rápido (NON-REM), também conhecido como
sono tranquilo e movimento ocular rápido (REM), também conhecido como sono ativo. Além disso, existem quatro estágios de NON-REM (NR1-NR4),
com NR1 sendo o mais ativo dos quatro estados e, finalmente, acordado (AW), que ocorre naturalmente durante a noite. Este bebê em particular nunca estava
acordado durante o estudo.
Não é muito difícil notar um padrão nos dados se nos concentrarmos nos estados de sono REM versus NON-REM. Porém, seria difícil
tentar avaliar padrões em uma sequência mais longa ou se houvesse mais categorias, sem algum auxílio gráfico. Um método simples seria
dimensionar os dados, ou seja, atribuir valores numéricos às categorias e, em seguida, desenhar um gráfico de tempo das escalas. Como os estados
têm uma ordem, uma escala óbvia seria
\begin{equation}
NR4 \, = \, 1, \quad NR3 \, = \, 2, \quad NR2 \, = \, 3, \quad NR1 \, = \, 4, \quad REM \, = \, 5, \quad AW \, = \, 6
\end{equation}
e a Figura VII.22 mostra o gráfico de tempo usando essa escala. Outra escala interessante pode ser combinar os estados silenciosos e os estados ativos:
\begin{equation}
NR4 \, = \, NR3 \, = \, NR2 \, = \, NR1 \, = \, 0, \quad REM \, = \, 1, \quad AW \, = \, 2\cdot
\end{equation}
Figura VII.22: [Topo] Gráfico de tempo dos dados do estado de sono EEG usando a primeira escala.
[Inferior] Periodograma dos dados do estado de sono EEG com base na prmiera escala. O pico corresponde a uma frequência de aproximadamente
um ciclo a cada 60 minutos.
O gráfico de tempo usando a segunda codificação seria semelhante à Figura VII.22 no que diz respeito ao comportamento cíclico,
dentro e fora do sono tranquilo, do padrão de sono deste bebê. A Figura VII.22 mostra o periodograma dos dados do sono usando a primeira escala.
Existe um grande pico na frequência correspondente a um ciclo a cada 60 minutos. Como podemos imaginar, a aparência geral do periodograma usando a
segunda escala (não mostrado) é semelhante à Figura VII.22. A maioria de nós se sentiria confortável com essa análise,
embora tenhamos feito uma escolha arbitrária sobre a escala específica. É evidente a partir dos dados, sem qualquer escala, que se
o interesse for no ciclo do sono infantil, este estudo do sono em particular indica que o bebê faz um ciclo entre o sono ativo e o tranquilo a uma taxa
de cerca de um ciclo por hora.
Como identificamos que o pico do periodograma corresponde a uma frequência de aproximadamente um ciclo a cada 60 minutos? com o seguinte código
respondemos a pergunta e vemos que o pico acontece exatamente a cada 54 minutos:
A intuição usada no exemplo anterior se perde quando consideramos uma longa sequência de DNA. Resumidamente, uma fita de DNA pode ser vista
como uma longa sequência de nucleotídeos ligados. Cada nucleotídeo é composto de uma base nitrogenada, um açúcar de
cinco carbonos e um grupo fosfato. Existem quatro bases diferentes e podem ser agrupadas por tamanho: as pirimidinas, timina (T) e citosina (C), e as purinas,
adenina (A) e guanina (G).
Os nucleotídeos são ligados entre si por uma espinha dorsal de grupos alternados de a&ccedul;úcar e fosfato com o carbono 5to. de um
açúcar ligado ao carbono 3ro. do próximo, dando a direção da cadeia. As moléculas de DNA ocorrem naturalmente como
uma dupla hélice composta de fitas polinucleotídicas com as bases voltadas para dentro. As duas fitas são complementares, por isso é
suficiente representar uma molécula de DNA por uma sequência de bases em uma única fita. Assim, uma fita de DNA pode ser representada como
uma sequência de letras, denominadas pares de bases (bp), do alfabeto finito {A, C, G, T}. A ordem dos nucleotídeos contém a
informação genética específica do organismo. A expressão das informações armazenadas nessas moléculas
é um processo complexo de vários estágios.
Uma tarefa importante é traduzir as informações armazenadas nas sequências codificadoras de proteínas (CDS) do DNA. Um
problema comum na análise de dados de longa sequência de DNA é a identificação CDS dispersos por toda a sequência e
separados por regiões de não codificação, que constituem a maior parte do DNA. Abaixo mostramos parte da sequência de DNA
do vírus Epstein-Barr (EBV). Toda a sequência de DNA do EBV consiste em aproximadamente 172.000 pb.
Poderíamos tentar escalar de acordo com o alfabeto purina-pirimidina, que é A = G = 0 e C = T = 1, mas isso não é
necessariamente de interesse para todos os CDS do EBV. Existem numerosos alfabetos de interesse possíveis. Por exemplo, podemos nos concentrar
no alfabeto de ligações de hidrogénio forte-fraco C = G = 0 e A = T = 1. Embora os cálculos do modelo, bem como os
dados experimentais concordem fortemente que algum tipo de sinal periódico existe em certas sequências de DNA, um grande desacordo sobre
o tipo exato de periodicidade existe. Além disso, existe um desacordo sobre quais alfabetos de nucleotídeos estão envolvidos nos sinais.
Se considerarmos a abordagem ingênua de atribuir arbitrariamente valores numéricos (escalas) às categorias e, em seguida, prosseguir
com uma análise espectral, o resultado dependerá da atribuição particular de valores numéricos. Por exemplo, considere a
sequência artificial ACGTACGTACGT .... Então, definir A = G = 0 e C = T = 1 resulta na sequência numérica 010101010101..., ou um
ciclo a cada dois pares de bases. Outra escala interessante seria A = 1, C = 2, G = 3 e T = 4, que resulta na sequência 123412341234... ou um
ciclo a cada quatro bp. Neste exemplo, ambas as escalas, ou seja, {A, C, G, T} = {0, 1, 0, 1} e {A, C, G, T} =
{1, 2, 3, 4}, dos nucleotídeos são interessantes e revelam diferentes propriedades da sequência. Portanto, não
queremos nos concentrar em apenas um dimensionamento. Em vez disso, o foco deve ser localizar todas as escalas possíveis que revelem todos os
recursos interessantes nos dados. Em vez de escolher valores arbitrariamente, a abordagem do envelope espectral seleciona escalas que ajudam a enfatizar
qualquer recurso periódico que existe em uma série de tempo categórica de virtualmente qualquer comprimento de maneira rápida
e automatizada. Além disso, a técnica pode ajudar a determinar se uma sequência é meramente uma atribuição
aleatória de categorias.
O envelope espectral para séries temporais categóricas
Como uma descrição geral, o envelope espectral é uma técnica de componentes principais baseada em frequência aplicada a
uma série temporal multivariada. Primeiro, vamos nos concentrar no conceito básico e seu uso na análise de séries temporais
categóricas. Detalhes técnicos podem ser encontrados em Stoffer et al. (1993).
Resumidamente, ao estabelecer o envelope espectral para séries temporais categóricas, a questão básica de como descobrir
componentes periódicos em séries temporais categóricas foi abordada. Isso foi realizado por meio de análise espectral
não paramétrica como segue.
Seja \(X_t\), \(t=0,\pm 1,\pm 2,\cdots\) uma série temporal de valor categórico com espaço de estados finito \(\mathcal{C}=\{c_1,c_2,\cdots,c_k\}\).
Suponha que \(X_t\) seja estacionária e que \(p_j = P(X_t=c_j)>0\) para \(j = 1,2,\cdots,k\). Para o vetor de parâmetros \(\beta=(\beta_1,\beta_2,\cdots,\beta_k)^\top\in \mathbb{R}^k\),
denotemos por \(X_t(\beta)\) a série temporal estacionária de valor real correspondente à escala que atribui à categoria
\(c_j\) o valor numérico \(\beta_j\), \(j = 1,2,\cdots,k\). A densidade espectral de \(X_t(\beta)\) será denotada por \(f_{_{XX}}(\omega;\beta)\).
O objetivo é encontrar \(\beta\) de forma que a densidade espectral seja interessante em certo sentido e resumir a informação espectral
pelo que é chamado de envelope espectral.
Em particular, \(\beta\) é escolhido para maximizar a potência em cada frequência \(\omega\) de interesse, em relação
à potência total \(\sigma^2(\beta) = \mbox{Var}\big(X_t(\beta)\big)\). Ou seja, escolhemos \(\beta(\omega)\) em cada \(\omega\) de interesse,
de maneira que
\begin{equation}
\lambda(\omega) \, = \, \max_{\beta} \left( \dfrac{f_{_{XX}}(\omega;\beta)}{\sigma^2(\beta)}\right),
\end{equation}
sobre todo \(\beta\) não proporcional a \(\pmb{1}_k\), o vetor \(k\times 1\) de uns.
Nota que \(\lambda(\omega)\) não está definido se \(\beta=a\pmb{1}_k\) para \(2\in\mathbb{R}\) porque tal escala corresponde a atribuir
a cada categoria o mesmo valor \(a\); neste caso, \(f_{_{XX}}(\omega;\beta)=0\) e \(\sigma^2(\beta)=0\). O critério de otimalidade \(\lambda(\omega)\)
possui a propriedade desejável de ser invariante sob mudanças de localização e escala de \(\beta\).
Como na maioria dos problemas de escala para dados categóricos, é útil representar as categorias em termos dos vetores unitários
\(u_1, u_2,\cdots,u_k\), onde \(u_j\) representa o vetor \(k\times 1\) com um na \(j\)-ésima linha e zeros em qualquer outro lugar. Definimos então
uma série temporal estacionária \(k\)-dimensional \(Y_t\) por \(Y_t = u_j\) quando \(X_t = c_j\).
A série temporal \(X_t(\beta)\) pode ser obtida a partir da série temporal \(Y_t\) pela relação \(X_t(\beta)= \beta^\top Y_t\).
Suponha que o processo vetorial \(Y_t\) tenha uma densidade espectral contínua denotada por \(f_{_{YY}}(\omega)\). Para cada \(\omega\), \(f_{_{YY}}(\omega)\)
é uma matriz Hermitiana \(k\times k\) de valor complexo.
A relação \(X_t(\beta)= \beta^\top Y_t\) implica
\begin{equation}
f_{_{XX}}(\omega;\beta) \, = \, \beta^\top f_{_{YY}}(\omega;\beta)\beta \, = \, \beta^\top f_{_{YY}}^{^{re}}(\omega;\beta)\beta,
\end{equation}
onde \(f_{_{YY}}^{^{re}}(\omega;\beta)\) denota a parte real de \(f_{_{YY}}(\omega;\beta)\). Nesta seção, é mais conveniente escrever valores complexos na forma \(z = z^{re} + iz^{im}\);
que representa uma mudança da notação usada anteriormente. A parte imaginária desaparece da expressão porque é assimétrica,
ou seja, \(f_{_{YY}}^{^{im}}(\omega;\beta)^\top=-f_{_{YY}}^{^{im}}(\omega;\beta)\).
O critério de otimalidade pode, portanto, ser expresso como
\begin{equation}
\lambda(\omega) \, = \, \max_{\beta} \left( \dfrac{\beta^\top f^{^{re}}_{_{YY}}(\omega;\beta)\beta}{\beta^\top V \beta}\right),
\end{equation}
onde \(V\) é a matriz de variância-covariância de \(Y_t\). A escala resultante \(\beta(\omega)\) é chamada de escala ótima.
O processo \(Y_t\) é um processo multivariado de ponto e qualquer componente particular de \(Y_t\) é o processo de ponto individual para o estado
correspondente, por exemplo, o primeiro componente de \(Y_t\) indica se o processo está no estado \(c_1\) no tempo \(t\). Para qualquer \(t\) fixo, \(Y_t\)
representa uma única observação de um esquema de amostragem multinomial simples. Segue-se prontamente que \(V = D-p\times p^\top\), onde
\(p = (p_1,\cdots,p_k)^\top\) e \(D\) é a matriz \(k\times k\) diagonal \(D = \mbox{diag}\{p_1,\cdots,p_k\}\). Porque, por suposição,
\(p_j> 0\) para \(j = 1,2,\cdots,k\), segue-se que \(\mbox{posto}(V) = k - 1\) com o espaço nulo de \(V\) sendo medido por \(\pmb{1}_k\). Para qualquer
matriz \(k\times (k-1)\) de classificação de posto completo \(Q\) cujas colunas sejam linearmente independentes de \(\pmb{1}_k\), \(Q^\top VQ\) será uma
matriz \((k-1)\times (k-1)\) simétrica definida positiva.
Com a matriz \(Q\) conforme definida anteriormente, defina \(\lambda(\omega)\) como o maior autovalor da equação determinante
\begin{equation}
\left|Q^\top f^{^{re}}_{_{YY}}(\omega;\beta)Q \, - \, \lambda(\omega)Q^\top V Q\right| \, = \, 0
\end{equation}
e seja \(b(\omega)\in \mathbb{R}^{k-1}\) ser qualquer autovetor correspondente, isto é,
\begin{equation}
Q^\top f^{^{re}}_{_{YY}}(\omega;\beta)Q b(\omega) \, = \, \lambda(\omega)Q^\top V Q b(\omega)\cdot
\end{equation}
O autovalor \(\lambda(\omega)>0\) não depende da escolha de \(Q\). Embora o autovetor \(b(\omega)\) dependa da escolha particular de \(Q\), a classe de
equivalência das escalas associadas com \(\beta(\omega)= Qb(\omega)\) não depende de \(Q\). Uma escolha conveniente de \(Q\) é
\(Q = \big( \mbox{I}_{k-1} \, | \, 0 \big)^\top\), onde \(\mbox{I}_{k-1}\) é a matriz \((k-1)\times (k-1)\) identidade e 0 é o vetor \((k-1)\times 1\)
de zeros. Para esta escolha, \(Q^\top f^{^{re}}_{_{YY}}(\omega;\beta)Q \) e \(Q^\top VQ\) são os blocos superiores de dimensões \((k-1)\times (k-1)\)
de \(f^{^{re}}_{_{YY}}(\omega;\beta) \) e \(V\), respectivamente. Esta escolha corresponde a definir o último componente de \(\beta(\omega)\) como zero.
O próprio valor \(\lambda(\omega)\) tem uma interpretação útil; especificamente, \(\lambda(\omega)\mbox{d}(\omega)\) representa a
maior proporção da potência total que pode ser atribuída às frequências \((\omega,\omega+\mbox{d}\omega)\) para qualquer
processo em escala particular \(X_t(\beta)\), com o máximo sendo alcançado pela escala \(\beta(\omega)\). Devido ao seu papel central, \(\lambda(\omega)\)
é definido como o envelope espectral de uma série temporal categórica estacionária.
O nome envelope espectral é apropriado, pois \(\lambda(\omega)\) envolve o espectro padronizado de qualquer processo escalado. Ou seja, dado qualquer \(\beta\)
normalizado de forma que \(X_t(\beta)\) tenha potência total um, \(f_{_{XX}}(\omega;\beta)\leq \lambda(\beta)\) com igualdade se, e somente se, \(\beta\)
for proporcional a \(\beta(\omega)\).
Dadas as observações \(X_t\), para \(t = 1,\cdots,n\), em uma série temporal categórica, formamos o processo pontual multinomial \(Y_t\),
para \(t = 1,\cdots,n\). Então, a teoria para estimar a densidade espectral de uma série temporal multivariada com valor real pode ser aplicada
para estimar \(f_{_{YY}}(\omega)\), a densidade espectral \(k\times k\) de \(Y_t\).
Dada uma estimativa \(\widehat{f}_{_{YY}}(\omega)\) de \(f_{_{YY}}(\omega)\), as estimativas \(\widehat{\lambda}(\omega)\) e \(\widehat{\beta}(\omega)\) do envelope
espectral, \(\lambda(\omega)\) e as escalas correspondentes \(\beta(\omega)\), podem então ser obtidas. Detalhes sobre estimação e inferência
para o envelope espectral amostral e as escalas ideais podem ser encontrados em Stoffer et al. (1993), mas o principal resultado desse artigo é o seguinte:
Se \(\widehat{f}_{_{YY}}(\omega)\) é um estimador espectral consistente e se para cada \(j = 1,\cdots,J\), a maior raiz de \(f^{^{re}}_{_{YY}}(\omega_j)\) é
distinta, então
\begin{equation}
\{\eta_n\big(\widehat{\lambda}(\omega_j)-\lambda(\omega_j)\big)/\lambda(\omega_j) , \, \eta_n\big(\widehat{\beta}(\omega_j)-\beta(\omega_j)\big) \, : \, j=1,\cdots,J\}
\end{equation}
converge, quando \(n\to\infty\), conjuntamente em distribuição para distribuições normais independentes de média zero, a primeira
das quais é normal padrão; a estrutura de covariância assintótica de \(\widehat{\beta}(\omega)\) é discutida em Stoffer et al. (1993).
O valor do termo \(\eta_n\) depende do tipo de estimador que está sendo usado. Com base nesses resultados, intervalos de confiança normais assintóticos
e testes para \(\lambda(\omega)\) podem ser construídos. Da mesma forma, para \(\beta(\omega)\), elipsóides de confiança assintóticos e
testes qui-quadrado podem ser construídos; detalhes podem ser encontrados em Stoffer et al. (1993).
A pesquisa do pico para a estimativa de envelope espectral suavizada pode ser auxiliada usando a seguinte aproximação. Usando uma expansão de Taylor
de primeira ordem, temos
\begin{equation}
\log\big(\widehat{\lambda}(\omega)\big) \, \approx \, \log\big(\lambda(\omega) \big)+\dfrac{\widehat{\lambda}(\omega)-\lambda(\omega)}{\lambda(\omega)},
\end{equation}
então \(\eta_n\big(\widehat{\lambda}(\omega_j)-\lambda(\omega_j)\big)\) é aproximadamente normal padrão. Segue-se que
\begin{equation}
\mbox{E}\Big( \log\big(\widehat{\lambda}(\omega)\big)\Big) \, \approx \, \log\big(\lambda(\omega)\big)
\end{equation}
e
\begin{equation}
\mbox{Var}\Big( \log\big(\widehat{\lambda}(\omega)\big)\Big) \, \approx \, \eta_n^{-2}\cdot
\end{equation}
Se nenhum sinal estiver presente em uma sequência de comprimento \(n\), esperamos \(\lambda(j/n)\approx 2/n\) para \(1 < j < n/2\) e, portanto, aproximadamente
\((1-\alpha)\times 100\)% do tempo, \(\log\big(\widehat{\lambda}(\omega)\big)\) será menor que \(\log(2/n)+(z_{\alpha}/\eta_n)\), onde \(z_\alpha\) é
o percentil \((1-\alpha)\) da cauda superior da distribuição normal padrão. Exponenciando, o valor crítico \(\alpha\) para
\(\widehat{\lambda}(\omega)\) torna-se \((2/n)\exp(z_{\alpha}/\eta_n)\). Os valores úteis de \(z_\alpha\) são \(z_{0.001} = 3.09\), \(z_{0.0001} = 3.71\) e
\(z_{0.00001} = 4.26\) e, de acordo com nossa experiência, o limiar nesses níveis funciona bem.
Exemplo VII.16. Análise espectral de sequências de DNA.
Para ajudar a entender a metodologia, mostramos instruções explícitas para os cálculos envolvidos na estimação do envelope espectral
de uma sequência de DNA \(X_t\), para \(t = 1,\cdots,n\), usando o alfabeto de nucleotídeos.
(i) Neste exemplo, mantemos a escala para T fixada em zero. Neste caso, formamos os vetores \(3\times 1\) de dados \(Y_t\):
\begin{array}{cc}
Y_t \, = \, (1,0,0)^\top \, \mbox{ se } X_t=\mbox{A}; & Y_t \, = \, (0,1,0)^\top \, \mbox{ se } X_t=\mbox{C}; \\
Y_t \, = \, (0,0,1)^\top \, \mbox{ se } X_t=\mbox{G}; & Y_t \, = \, (0,0,0)^\top \, \mbox{ se } X_t=\mbox{T}\cdot
\end{array}
O vetor de escala é \(\beta=(\beta_1,\beta_2,\beta_3)^\top\) e o processo em escala é \(X_t(\beta) = \beta^\top Y_t\).
(ii) Calcular a transformada discreta de Fourier (DFT) dos dados
\begin{equation}
Y(j/n) \, = \, \dfrac{1}{n}\sum_{t=1}^n Y_t \exp\big( -2\pi \, i \, tj/n\big)\cdot
\end{equation}
Observe que \(Y(j/n)\) é um vetor \(3\times 1\) de valor complexo. Calcule o periodograma, \(I(j/n) = Y(j/n)Y^*(j/n)\) para
\(j=1,\cdots,[n/2]\) e guarde apenas a parte real, \(I^{^{re}}(j/n)\).
(iii) Suavize o \(I^{^{re}}(j/n)\) para obter uma estimativa de \(f^{^{re}}(j/n)\). Sejam \(\{h_k \, : \, k=0,\pm 1,\cdots, \pm m\}\)
os pesos descritos na Seção IV.4. Calcular
\begin{equation}
\widehat{f}^{^{re}}(j/n) \, = \, \sum_{k=-m}^m h_k I^{^{re}}(j/n+k/n)\cdot
\end{equation}
(iv) Calcule a matriz \(3\times 3\) de variâncias-covariâncias amostral,
\begin{equation}
S_{_{YY}} \, = \, \dfrac{1}{n}\big(Y_t-\overline{Y}_t\big)\big(Y_t-\overline{Y}_t\big)^\top,
\end{equation}
onde \(\overline{Y}=\frac{1}{n}\sum_{t=1}^n Y_t\) é a médias amostral dos dados.
(v) Para cada \(\omega_j = j/n\), \(j = 0,1,\cdots,[n/2]\), determinar o maior autovalor e o autovetor correspondente da matriz
\begin{equation}
\dfrac{2}{n}S_{_{YY}}^{-1/2}\widehat{f}^{^{re}}(\omega_j)S_{_{YY}}^{-1/2}\cdot
\end{equation}
Observe que \(S_{_{YY}}^{1/2}\) é a raiz quadrada única da matriz \(S_{_{YY}}\).
(vi) O envelope espectral amostral \(\widehat{\lambda}(\omega_j)\) é o autovalor obtido na etapa anterior. Se \(b(\omega_j)\) denota o
autovetor obtido na etapa anterior, a escala amostral ótima é
\begin{equation}
\widehat{\beta}(\omega_j) \, = \, S_{_{YY}}^{-1/2}b(\omega_j),
\end{equation}
isso resultará em três valores, o valor correspondente à quarta categoria, \(\mbox{T}\), sendo mantido fixo em zero.
Exemplo VII.17. Análise de um gene do vírus Epstein-Barr.
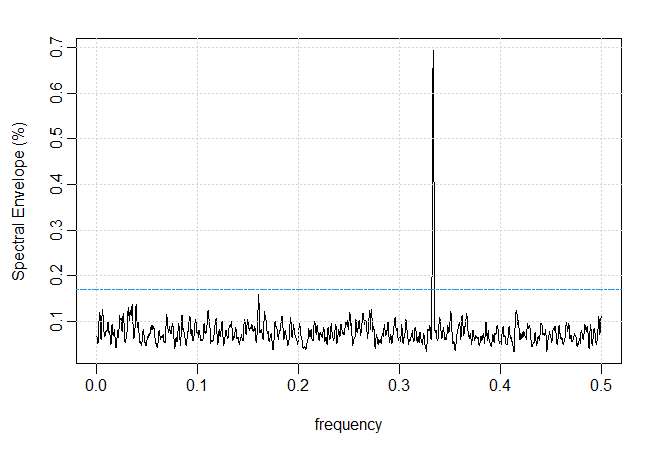
Neste exemplo, nos concentramos em uma análise dinâmica ou janela deslizante do gene BNRF1 (bp 1736-5689) do Epstein-Barr. A Figura VII.23 mostra
a estimativa do envelope espectral de toda a sequência de codificação (comprimento 3954 bp). A figura também mostra um sinal forte na frequência
1/3; a escala ideal correspondente foi A = 0.10, C = 0.61, G = 0.78, T = 0, que indica que o sinal está no alfabeto de ligação forte-fraca,
S = {C, G} e W = {A, T}.
Figura VII.23: Envelope espectral amostral suavizado do gene BNRF1 do vírus Epstein-Barr.
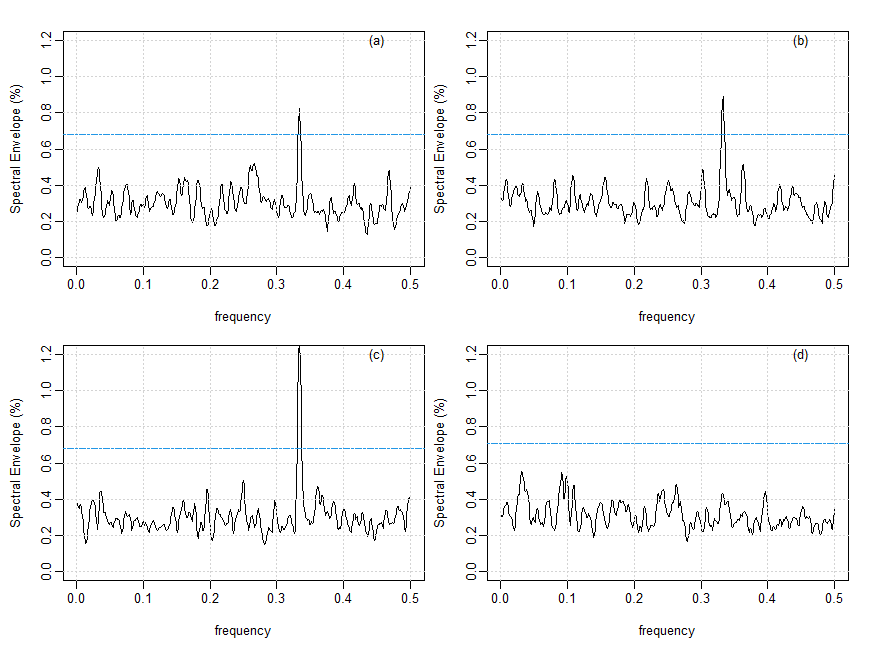
A Figura VII.24 mostra o resultado do cálculo do envelope espectral sobre três janelas não sobrepostas de 1000 bp e uma janela de 954 bp,
através do CDS, a saber: o primeiro, segundo, terceiro e quarto trimestres do BNRF1.
Figura VII.24: Envelope espectral amostral suavizado do gene BNRF1 do vírus Epstein-Barr: (a) primeiros
1000 bp, (b) segundos 1000 bp, (c) terceiro 1000 bp e (d) últimos 954 bp.
Um limite de significância aproximado de 0.0001 é 0.69%. Os primeiros três quartos contêm o sinal na frequência 1/3
(Figura VII.24 a-c); as escalas ideais amostrais correspondentes para as três primeiras janelas foram (a) A = 0.01, C = 0.71, G = 0.71, T = 0;
(b) A = 0.08, C = 0.71, G = 0.70, T = 0; (c) A = 0.20, C = 0.58, G = 0.79, T = 0. As primeiras duas janelas são consistentes com a análise
geral. A terceira seção, no entanto, mostra alguns pequenos desvios do alfabeto da ligação forte-fraca. O resultado mais
interessante é que a quarta janela mostra que nenhum sinal est&aacte; presente. Isso leva à conjectura de que o quarto trimestre de
BNRF1 do Epstein-Barr é, na verdade, não codificador.
O código R para este exemplo é o seguinte:
> library(astsa)
> u = factor(bnrf1ebv) # first, input the data as factors and then
> x = model.matrix(~u-1)[,1:3] # make an indicator matrix
> # x = x[1:1000,] # select subsequence if desired
> Var = var(x) # var-cov matrix
> xspec = mvspec(x, spans=c(7,7), plot=FALSE)
> fxxr = Re(xspec$fxx) # fxxr is real(fxx)
> # compute Q = Var^-1/2
> ev = eigen(Var)
> Q = ev$vectors%*%diag(1/sqrt(ev$values))%*%t(ev$vectors)
> # compute spec envelope and scale vectors
> num = xspec$n.used # sample size used for FFT
> nfreq = length(xspec$freq) # number of freqs used
> specenv = matrix(0,nfreq,1) # initialize the spec envelope
> beta = matrix(0,nfreq,3) # initialize the scale vectors
> for (k in 1:nfreq){
ev = eigen(2*Q%*%fxxr[,,k]%*%Q/num, symmetric=TRUE)
specenv[k] = ev$values[1] # spec env at freq k/n is max evalue
b = Q%*%ev$vectors[,1] # beta at freq k/n
beta[k,] = b/sqrt(sum(b^2)) } # helps to normalize beta
> # output and graphics
> frequency = xspec$freq
> par(mfrow=c(1,1), mar=c(5,4,0,0), oma=c(0,0,2,2), mgp = c(2.6,0.6,0))
> plot(frequency, 100*specenv, type="l", ylab="Spectral Envelope (%)")
> grid()
> # add significance threshold to plot
> m = xspec$kernel$m
> # add significance threshold to plot
> m = xspec$kernel$m
> etainv = sqrt(sum(xspec$kernel[-m:m]^2))
> thresh=100*(2/num)*exp(qnorm(.9999)*etainv)
> abline(h=thresh, lty=6, col=4)
> which.max(specenv)
[1] 1333
> frequency[1333]
[1] 0.33325
> 1/frequency[1333]
[1] 3.00075
> # details
> output = cbind(frequency, specenv, beta)
> colnames(output) = c("freq","specenv", "A", "C", "G")
> round(output,3)[1:10,]
freq specenv A C G
[1,] 0.000 0.001 0.368 0.143 0.919
[2,] 0.000 0.001 0.367 0.135 0.920
[3,] 0.001 0.001 0.422 0.122 0.898
[4,] 0.001 0.001 0.575 0.136 0.807
[5,] 0.001 0.001 0.745 0.141 0.652
[6,] 0.002 0.001 0.864 0.031 0.503
[7,] 0.002 0.001 0.918 -0.199 0.343
[8,] 0.002 0.001 0.884 -0.428 0.187
[9,] 0.002 0.001 0.804 -0.592 0.056
[10,] 0.003 0.001 0.727 -0.687 -0.028
O envelope espectral para séries temporais contínuas
O conceito de envelope espectral para séries temporais categóricas foi estendido para séries temporais contínuas,
\(\{X_t \, : \, t = 0,\pm 1,\pm 2,\cdots\}\) em McDougall et al. (1997). O processo \(X_t\) pode ter valor vetorial, mas aqui nos concentraremos no caso
univariado. Mais detalhes podem ser encontrados em McDougall et al. (1997). O conceito é semelhante à busca por projeção
(Friedman and Stuetzle, 1981).
Seja \(\mathcal{G}\) um espaço vetorial \(k\)-dimensional de transformações reais contínuas com \(\{g_1,\cdots,g_k\}\) sendo
um conjunto de funções básicas que satisfazem \(\mbox{E}\big( g_i^2(X_t)\big)<\infty\), \(i = 1,\cdots,k\). Análogo ao caso
da série temporais categóricas, defina a série temporal escalonada em relação ao conjunto \(\mathcal{G}\) para ser
o processo com valor real
\begin{equation}
X_t(\beta) \, = \, \beta^\top Y_t \, = \, \beta_1g_1(X_t)+\cdots \beta_k g_k(X_t)
\end{equation}
obtida do processo vetorial
\begin{equation}
Y_t \, = \, \big(g_1(X_t),\cdots,g_k(X_t) \big)^\top,
\end{equation}
onde \(\beta=(\beta_1,\cdots,\beta_k)^\top\in\mathbb{R}^k\).
Se o processo vetorial \(Y_t\), for assumido como tendo uma densidade espectral contínua \(f_{_{YY}}(\omega)\), então \(X_t(\beta)\) terá
uma densidade espectral contínua \(f_{_{XX}}(\omega;\beta)\) para todo \(\beta\neq 0\). Observando que
\begin{equation}
f_{_{XX}}(\omega;\beta) \, = \, \beta^\top f_{_{YY}}(\omega)\beta \, = \, \beta^\top f^{^{re}}(\omega)\beta
\end{equation}
e
\begin{equation}
\sigma^2(\beta) \, = \, \mbox{Var}\big( X_t(\beta)\big) \, = \, \beta^\top V \beta,
\end{equation}
onde \(V=\mbox{Var}(Y_t)\) é assumida como definida positivo; o critério de otimalidade
\begin{equation}
\lambda(\omega) \, = \, \sup_{\beta\neq 0} \left( \dfrac{\beta^\top f^{^{re}}(\omega)\beta}{\beta^\top V \beta}\right),
\end{equation}
está bem definido e representa a maior proporção da potência total que pode ser atribuída à frequência \(\omega\)
para qualquer processo em escala particular \(X_t(\beta)\). Esta interpretação de \(\lambda(\omega)\) é consistente com a noção
do envelope espectral introduzido na seção anterior e fornece a seguinte definição de trabalho: O envelope espectral de uma
série temporal com relação ao espaço \(\mathcal{G}\) é definido como \(\lambda(\omega)\).
A solução para este problema, como no caso categórico, é alcançada encontrando-se o maior escalar \(\lambda(\omega)\) tal que
\begin{equation}
f^{^{re}}(\omega)\beta(\omega) \, = \, \lambda(\omega) V \beta(\omega),
\end{equation}
para \(\beta(\omega)\neq 0\). Ou seja, \(\lambda(\omega)\) é o maior autovalor de \(f^{^{re}}(\omega)\) na métrica de \(V\) e a escala ótima
\(\beta(\omega)\), é o autovetor correspondente.
Se \(X_t\) é uma série temporal categórica assumindo valores no espaço de estados finito \(\mathcal{S} = \{c_1,c_2,\cdots,c_k\}\),
onde \(c_j\) representa uma categoria particular, uma escolha apropriada para \(\mathcal{G}\) é o conjunto de funções indicadoras
\(g_j(X_t) = I(X_t = c_j)\). Portanto, esta é uma generalização natural do caso categórico.
No caso categórico, \(\mathcal{G}\) não consiste em funções \(g\) linearmente independentes, mas foi fácil superar esse
problema reduzindo a dimensão em um. No caso de valor vetorial, \(X_t = (X_{1t},\cdots,X_{pt})^\top\), consideramos \(\mathcal{G}\) como a classe de
transformações de \(\mathbb{R}^p\) em \(\mathbb{R}\) tal que existe a densidade espectral de \(g(X_t)\).
Uma classe de transformações de interesse são combinações lineares de \(X_t\). Em Tiao et al. (1993), por exemplo,
transformações lineares desse tipo são usadas em uma abordagem no domínio do tempo para investigar relações
contemporâneas entre os componentes de séries temporais multivariadas. A estimação e a inferência para o caso real
são análogas aos métodos descritos na seção anterior para o caso categórico. Consideramos um exemplo aqui;
numerosos outros exemplos podem ser encontrados em McDougall et al. (1997).
Exemplo VII.18. Transformações ótimas para dados financeiros: retornos da NYSE.
Em muitas aplicações financeiras, normalmente se trata da análise dos retornos quadrados, como foi feito na Seção V.3 e na Seção VI.11.
No entanto, pode haver outras transformações que fornecem mais informações do que simplesmente quadrar os dados. Por exemplo, Ding et al. (1993) que
aplicou transformações da forma \(|X_t|^d\), para \(d\in (0,3]\), à série do mercado de ações S&P 500. Eles descobriram que a
transformação de poder do retorno absoluto tem uma autocorrelação bastante alta para longas defasagens e essa propriedade é mais forte quando \(d\)
está em torno de 1. Eles concluíram que o "resultado parece argumentar contra as especificações do tipo ARCH com base em retornos quadrados."
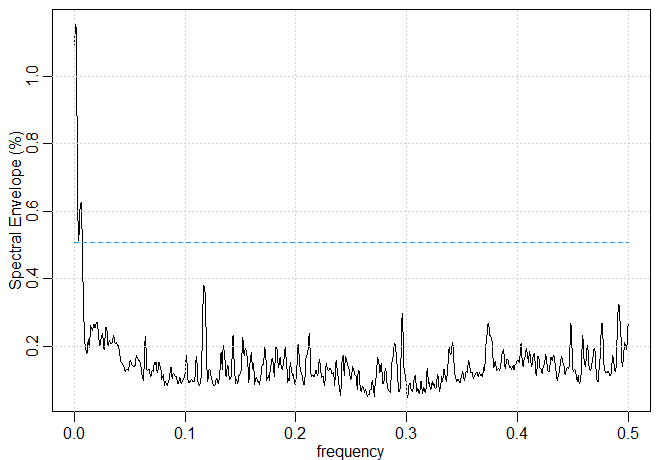
Figura VII.25: Envelope espectral em relação a \(\mathcal{G}=\{x, |x|,x^2\}\) para os restornos da NYSE.
Neste exemplo, examinamos os retornos da NYSE (nyse). Usamos com o conjunto gerador \(\mathcal{G}=\{x, |x|,x^2\}\), que parece natural para esta análise
para estimar o envelope espectral e o resultado é mostrado na Figura VII.25. Embora os dados sejam um ruído branco, eles claramente não são independentes
identicamente distribuídos e uma potência considerável está presente nas frequências baixas. A presença de potência espectral em
frequências muito baixas em séries econômicas destendidas tem sido freqüentemente relatada e está tipicamente associada à dependência
de longo alcance.
A transformação ótima estimada perto da frequência zero \(\omega = 0.001\); foi \(\widehat{\beta}(0.001) = (-1,921,-2596)^\top\), o que leva à
transformação
\begin{equation}
g(x) \, = \, -x +921 |x|-2596 x^2\cdot
\end{equation}
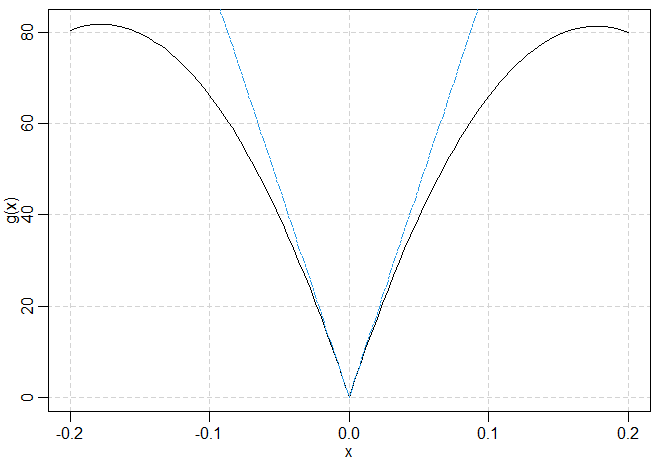
Essa transformação é mostrada na Figura VII.26. A transformação dada acima é basicamente o valor absoluto, com alguma ligeira
curvatura e assimetria, para a maioria dos valores, mas o efeito dos extremos é amortecido.
Figura VII.26: Envelope espectral em relação a \(\mathcal{G}=\{x, |x|,x^2\}\) para os restornos da NYSE.
Verifique que a parte imaginária de uma matriz \(k\times k\) espectral \(f^{^{im}}(\omega)\) é simétrica e, em seguida,
mostre que \(\beta^\top f^{^{im}}(\omega)\beta=0\) para um vetor \(k\times 1\) real \(\beta\).
Repita a análise do Exemplo VII.17 no BNRF1 do herpesvírus saimiri, os arquivo de dados é bnrf1hvs
e compare os resultados com aqueles obtidos para o vírus Epstein–Barr.
Para os retornos semanais S&P 500, digamos, \(r_t\), analisados no Exemplo VI.17:
(a) Estime o espectro do \(r_t\). A estimativa espectral parece apoiar a hipótese de que os retornos são um ruído branco?
(b) Examine a possibilidade de potência espectral perto da frequência zero para uma transformação dos retornos, digamos,
\(g(r_t)\), usando o envelope espectral com o Exemplo VII.18 como seu guia. Compare a transformação ideal próxima ou na
frequência zero com a transformação usual \(Y_t = r_t^2\).