Figura 4: Gráfico de setores para variável civil.
Nesta sessão vamos ver alguns (mas não todos!) comandos do R para fazer uma análise descritiva de um conjunto de dados.
Uma boa forma de iniciar uma análise descritiva adequada é verificar os tipode de variáveis disponíveis. Variáveis podem ser classificadas da seguinte forma:
e podem ser resumidas por tabelas, gráficos e/ou medidas.
O livro Estatística Básica de W. Bussab e P. Morettin traz no primeiro capítulo um conjunto de dados hipotético de atributos de 36 funcionários da companhia “Milsa”. Os dados estão reproduzidos na tabela 8.2. Consulte o livro para mais detalhes sobre este dados.
Funcionário | Est. Civil | Instrução | No Filhos | Salário | Ano | Mês | Região
|
| 1 | solteiro | 1o Grau | - | 4.00 | 26 | 3 | interior |
| 2 | casado | 1o Grau | 1 | 4.56 | 32 | 10 | capital |
| 3 | casado | 1o Grau | 2 | 5.25 | 36 | 5 | capital |
| 4 | solteiro | 2o Grau | - | 5.73 | 20 | 10 | outro |
| 5 | solteiro | 1o Grau | - | 6.26 | 40 | 7 | outro |
| 6 | casado | 1o Grau | 0 | 6.66 | 28 | 0 | interior |
| 7 | solteiro | 1o Grau | - | 6.86 | 41 | 0 | interior |
| 8 | solteiro | 1o Grau | - | 7.39 | 43 | 4 | capital |
| 9 | casado | 2o Grau | 1 | 7.59 | 34 | 10 | capital |
| 10 | solteiro | 2o Grau | - | 7.44 | 23 | 6 | outro |
| 11 | casado | 2o Grau | 2 | 8.12 | 33 | 6 | interior |
| 12 | solteiro | 1o Grau | - | 8.46 | 27 | 11 | capital |
| 13 | solteiro | 2o Grau | - | 8.74 | 37 | 5 | outro |
| 14 | casado | 1o Grau | 3 | 8.95 | 44 | 2 | outro |
| 15 | casado | 2o Grau | 0 | 9.13 | 30 | 5 | interior |
| 16 | solteiro | 2o Grau | - | 9.35 | 38 | 8 | outro |
| 17 | casado | 2o Grau | 1 | 9.77 | 31 | 7 | capital |
| 18 | casado | 1o Grau | 2 | 9.80 | 39 | 7 | outro |
| 19 | solteiro | Superior | - | 10.53 | 25 | 8 | interior |
| 20 | solteiro | 2o Grau | - | 10.76 | 37 | 4 | interior |
| 21 | casado | 2o Grau | 1 | 11.06 | 30 | 9 | outro |
| 22 | solteiro | 2o Grau | - | 11.59 | 34 | 2 | capital |
| 23 | solteiro | 1o Grau | - | 12.00 | 41 | 0 | outro |
| 24 | casado | Superior | 0 | 12.79 | 26 | 1 | outro |
| 25 | casado | 2o Grau | 2 | 13.23 | 32 | 5 | interior |
| 26 | casado | 2o Grau | 2 | 13.60 | 35 | 0 | outro |
| 27 | solteiro | 1o Grau | - | 13.85 | 46 | 7 | outro |
| 28 | casado | 2o Grau | 0 | 14.69 | 29 | 8 | interior |
| 29 | casado | 2o Grau | 5 | 14.71 | 40 | 6 | interior |
| 30 | casado | 2o Grau | 2 | 15.99 | 35 | 10 | capital |
| 31 | solteiro | Superior | - | 16.22 | 31 | 5 | outro |
| 32 | casado | 2o Grau | 1 | 16.61 | 36 | 4 | interior |
| 33 | casado | Superior | 3 | 17.26 | 43 | 7 | capital |
| 34 | solteiro | Superior | - | 18.75 | 33 | 7 | capital |
| 35 | casado | 2o Grau | 2 | 19.40 | 48 | 11 | capital |
| 36 | casado | Superior | 3 | 23.30 | 42 | 2 | interior |
O que queremos aqui é ver como, no programa R:
Estes são dados no "estilo planilha", com variáveis de diferentes tipos: categóricas e numéricas (qualitativas e quantitativas). Portanto o formato ideal de armazenamento destes dados no R é o data.frame. Para entrar com estes dados no diretamente no R podemos usar o editor que vem com o programa. Para digitar rapidamente estes dados é mais fácil usar códigos para as variáveis categóricas. Desta forma, na coluna de estado civil vamos digitar o código 1 para solteiro e 2 para casado. Fazemos de maneira similar com as colunas Grau de Instrução e Região de Procedência. No comando a seguir invocamos o editor, entramos com os dados na janela que vai aparecer na sua tela e quanto saímos do editor (pressionando o botão QUIT) os dados ficam armazenados no objeto milsa. Após isto digitamos o nome do objeto (milsa) e podemos ver o conteúdo digitado, como mostra a tabela 8.2. Lembre-se que se voce precisar corrigir algo na digitação voce pode fazê-lo abrindo a planilha novamente com o comando fix(milsa).
civil | instrucao | filhos | salario | ano | mes | regiao
| |
| 1 | 1 | 1 | NA | 4.00 | 26 | 3 | 1 |
| 2 | 2 | 1 | 1 | 4.56 | 32 | 10 | 2 |
| 3 | 2 | 1 | 2 | 5.25 | 36 | 5 | 2 |
| 4 | 1 | 2 | NA | 5.73 | 20 | 10 | 3 |
| 5 | 1 | 1 | NA | 6.26 | 40 | 7 | 3 |
| 6 | 2 | 1 | 0 | 6.66 | 28 | 0 | 1 |
| 7 | 1 | 1 | NA | 6.86 | 41 | 0 | 1 |
| 8 | 1 | 1 | NA | 7.39 | 43 | 4 | 2 |
| 9 | 2 | 2 | 1 | 7.59 | 34 | 10 | 2 |
| 10 | 1 | 2 | NA | 7.44 | 23 | 6 | 3 |
| 11 | 2 | 2 | 2 | 8.12 | 33 | 6 | 1 |
| 12 | 1 | 1 | NA | 8.46 | 27 | 11 | 2 |
| 13 | 1 | 2 | NA | 8.74 | 37 | 5 | 3 |
| 14 | 2 | 1 | 3 | 8.95 | 44 | 2 | 3 |
| 15 | 2 | 2 | 0 | 9.13 | 30 | 5 | 1 |
| 16 | 1 | 2 | NA | 9.35 | 38 | 8 | 3 |
| 17 | 2 | 2 | 1 | 9.77 | 31 | 7 | 2 |
| 18 | 2 | 1 | 2 | 9.80 | 39 | 7 | 3 |
| 19 | 1 | 3 | NA | 10.53 | 25 | 8 | 1 |
| 20 | 1 | 2 | NA | 10.76 | 37 | 4 | 1 |
| 21 | 2 | 2 | 1 | 11.06 | 30 | 9 | 3 |
| 22 | 1 | 2 | NA | 11.59 | 34 | 2 | 2 |
| 23 | 1 | 1 | NA | 12.00 | 41 | 0 | 3 |
| 24 | 2 | 3 | 0 | 12.79 | 26 | 1 | 3 |
| 25 | 2 | 2 | 2 | 13.23 | 32 | 5 | 1 |
| 26 | 2 | 2 | 2 | 13.60 | 35 | 0 | 3 |
| 27 | 1 | 1 | NA | 13.85 | 46 | 7 | 3 |
| 28 | 2 | 2 | 0 | 14.69 | 29 | 8 | 1 |
| 29 | 2 | 2 | 5 | 14.71 | 40 | 6 | 1 |
| 30 | 2 | 2 | 2 | 15.99 | 35 | 10 | 2 |
| 31 | 1 | 3 | NA | 16.22 | 31 | 5 | 3 |
| 32 | 2 | 2 | 1 | 16.61 | 36 | 4 | 1 |
| 33 | 2 | 3 | 3 | 17.26 | 43 | 7 | 2 |
| 34 | 1 | 3 | NA | 18.75 | 33 | 7 | 2 |
| 35 | 2 | 2 | 2 | 19.40 | 48 | 11 | 2 |
| 36 | 2 | 3 | 3 | 23.30 | 42 | 2 | 1 |
Atenção: Note que além de digitar os dados na planilha digitamos também o nome que escolhemos para cada variável. Para isto basta, na planilha, clicar no nome da variável e escolher a opção CHANGE NAME e informar o novo nome da variável.
A planilha digitada como está ainda não está pronta. Precisamos informar para o programa que as variáveis civil, instrucao e regiao, NÃO são numéricas e sim categóricas. No R variáveis categóricas são definidas usando o comando factor(), que vamos usar para redefinir nossas variáveis conforme os comandos a seguir. Inicialmente inspecionamos as primeiras linhas do conjunto de dados. A seguir redefinimos a variável civil com os rótulos (labels) solteiro e casado associados aos níveis (levels) 1 e 2. Para variável instruçao usamos o argumento adicional ordered = TRUE para indicar que é uma variável ordinal. Na variável regiao codificamos assim: 2=capital, 1=interior, 3=outro. Ao final inspecionamos as primeiras linhas do conjunto de dados digitando usando head().
Em versões mais recentes do R foi introduzida a função transform() que pode ser usada alternativamente aos comandos mostrados acima para modificar ou gerar novas variáveis. Por exemplo, os comandos acima poderiam ser substituídos por:
Vamos ainda definir uma nova variável única idade a partir das variáveis ano e mes que foram digitadas. Para gerar a variável idade em anos fazemos:
Uma outra forma de se obter o mesmo resultado seria:
Agora que os dados estão prontos podemos começar a análise descritiva. A seguir mostramos como fazer análises descritivas uni e bi-variadas. Inspecione os comandos mostrados a seguir e os resultados por eleas produzidos. Sugerimos ainda que o leitor use o R para reproduzir os resultados mostrados no texto dos capítulos 1 a 3 do livro de Bussab & Morettin relacionados com este exemplo.
Inicialmente verificamos que o objeto milsa é um data-frame, usamos names() para ver os nomes das variáveis, e dim() para ver o número de linhas (36 indivíduos) e colunas (9 variáveis).
Como na sequência vamos fazer diversas análises com estes dados usaremos o command attach() para anexar o objeto ao caminho de procura para simplificar a digitação.
NOTA: este comando deve ser digitado para que os comandos mostrados a seguir tenham efeito.
A análise univariada consiste basicamente em, para cada uma das variáveis individualmente:
A partir destes resultados pode-se montar um resumo geral dos dados.
A seguir vamos mostrar como obter tabelas, gráficos e medidas com o R. Para isto vamos selecionar uma variável de cada tipo para que o leitor possa, por analogia, obter resultados para as demais.
Variável Qualitativa Nominal A variável civil é uma qualitativa nominal. Desta forma podemos obter: (i) uma tabela de frequências (absolutas e/ou relativas), (ii) um gráfico de setores, (iii) a "moda", i.e. o valor que ocorre com maior frequência.
Vamos primeiro listar os dados e checar se estao na forma de um fator, que é adequada para variáveis deste tipo.
A seguir obtemos frequências absolutas e relativas (note duas formas fiferentes de obter as frequências relativas. Note ainda que optamos por armazenar as frequências absolutas em um objeto que chamamos de civil.tb.
O gráfico de setores é adequado para representar esta variável conforme mostrado na Figura 8.2.1.
NOTA: Em computadores antigos e de baixa resolução gráfica (como por exemplo em alguns computadores da Sala A do LABEST/UFPR) o gráfico pode não aparecer de forma adequada devido limitação de memória da placa de vídeo. Se este for o caso use o comando mostrado a seguir ANTES de fazer o gráfico.
Finalmente encontramos a moda para esta variável cujo valor optamos por armazenar no objeto civil.mo.
Variável Qualitativa Ordinal Para exemplificar como obter análises para uma variável qualitativa ordinal vamos selecionar a variável instrucao.
As tabelas de frequências são obtidas de forma semelhante à mostrada anteriormente.
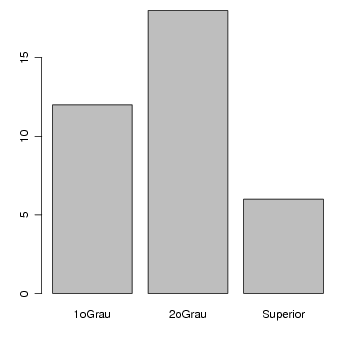
O gráfico de setores não é adequado para este tipo de variável por não expressar a ordem dos possíveis valores. Usamos então um gráfico de barras conforma mostrado na Figura 8.2.1.
Para uma variável ordinal, além da moda podemos também calcular outras medidas, tais como a mediana conforme exemplificado a seguir. Note que o comando median() não funciona com variáveis não numéricas e por isto usamos o comando seguinte.
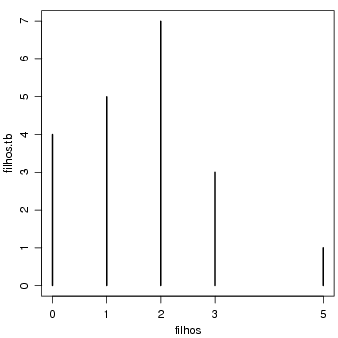
Variável quantitativa discreta Vamos agora usar a variável filhos (número de filhos) para ilustrar algumas análises que podem ser feitas com uma quantitativa discreta. Note que esta deve ser uma variável numérica, e não um fator.
Frequências absolutas e relativas são obtidas como anteriormente.
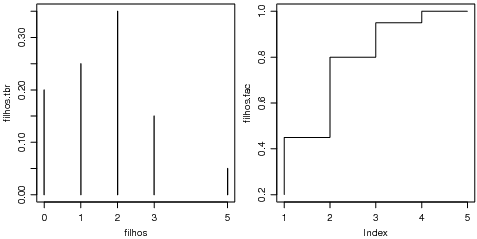
O gráfico adequado para frequências absolutas de uma variável discreta é mostrado na Figura 8.2.1 o obtido com os comandos a seguir.
Outra possibilidade seria fazer gráficos de frequências relativas e de prequências acumuladas conforme mostrado na Figura 8.2.1.
Sendo a variável numérica há uma maior diversidade de medidas estatísticas que podem ser calculadas.
A seguir mostramos como obter algumas medidas de posição: moda, mediana, média e média aparada. Note que o argumento na.rm=T é necessário porque não há informação sobre número de filhos para alguns indivíduos. O argumento trim=0.1 indica uma média aparada onde foram retirados 10% dos menores e 10% dos maiores dados. Ao final mostramos como obter os quartis, mínimo e máximo.
Passando agora para medidas de dispersão vejamos como obter máximo e mínimo daí a amplitude, variância e desvio padrão, coeficiente de variação. Depois obtemos os quartis e daí a amplitude interquartílica.
Finalmente, notamos que há comandos para se obter várias medidas de uma sá vez. Inspecione os resultados dos comandos abaixo.
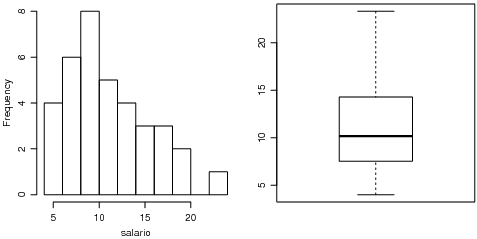
Variável quantitativa Contínua Para concluir os exemplos para análise univariada vamos considerar a variável quantitativa contínua salario. Começamos mostrando os valores da variável e verificando o seu tipo no R.
Para se fazer uma tabela de frequências de uma contínua é preciso primeiro agrupar os dados em classes. Nos comandos mostrados a seguir verificamos inicialmente os valores máximo e mínimo dos dados, depois usamos o critério de Sturges para definir o número de classes, usamos cut() para agrupar os dados em classes e finalmente obtemos as frequências absolotas e relativas.
Na sequência vamos mostrar dois possíveis gráficos para variáveis contínuas: histograma e box-plot conforme Figura 8.2.1. Neste comando fazemos main= para evitar que a função coloque automaticamente o título no gráfico, o que é o comportamento padrão de hist(). É sempre bom lembrar que há várias outras opções fornecidas pelos argumentos das funções. Por exemplo, em hist() acrescentando labels=TRUE as frequências são mostradas em coma de cada barra, prob=TRUE faz com que o gráfico exiba as frequências relaticas. Por default a função calcula automaticamente o número de classes e os valores limites de cada classe e isto pode ser alterado com o argumento breaks que pode receber um vetor definindo os limites das classes definidos pelo usuário, um nome de critério (default="Sturges"), número de classes ou mesmo uma função para definir as classes; ou ainda nclass pode receber um escalar definindo o número de classes. Além destas há ainda várias outras opções implementadas pelos argumentos da função conforme descrito em help(hist). Da mesma forma argumentos permitem variações em boxplot tais como caixas com tamanho proporcional aos tamanhos dos grupos, caixas "acinturadas"(notched boxplot) entre outras.
Uma outra representação gráfica para variáveis numéricas é o diagrama ramo-e-folhas que pode ser obtido conforme mostrado a seguir.
Finalmente medidas s obtidas da mesma forma que para variáveis discretas. Veja alguns exemplos a seguir.
Na análise bivariada procuramos identificar relaccões entre duas variáveis. Assim como na univariada estas relações podem ser resumidas por gráficos, tabelas e/ou medidas estatística. O tipo de resumo vai depender dos tipos das variáveis envolvidas. Vamos considerar três possibilidades:
Salienta-se ainda que:
Qualitativa vs Qualitativa Vamos considerar as variáveis civil (estado civil) e instrucao (grau de instrução). A tabela envolvendo duas variáveis é chamada tabela de cruzamento ou tabela de contingência e pode ser apresentada de várias formas, conforme discutido a seguir. A forma mais adequada de apresentação vai depender dos objetivos da análise e da interpretação desejada para os dados. Iniciamente obtemos com table() a tabela de frequências absolutas. A tabela extendida incluindo os totais marginais pode ser obtida com addmargins().
Tabelas de frequências relativas são obtidas com prop.table() e tais frequências podem ser globais, por linha (margin=1) ou por coluna (margin=2).
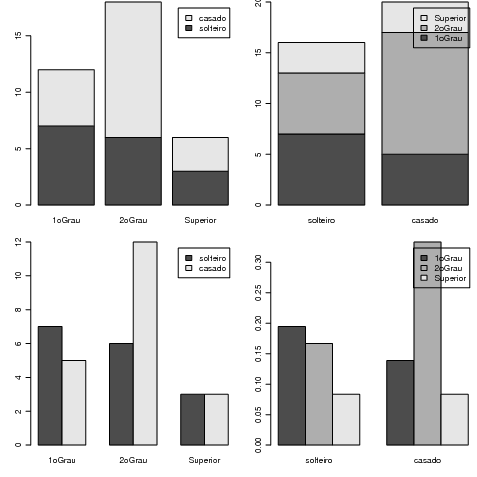
Na Figura 8.2.2 mostramos quatro diferentes gráficos de barras que podem ser usados para representar o cruzamento das variáveis. A transposição da tabela com t() permite alterar a variável que define os grupos no eixo horizontal. O uso de prop.table() permite o obtenção de gráficos com frequências relativas.
Medidas de associação entre duas variáveis qualitativas incluem o Chi-quadrado dado por:
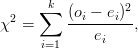
![∘ -------
χ2 C
C = -2-----, C1 = ----------2,
χ + n [(t - 1)∕t]](Rembrapa37x.png)
Muitas vezes é necessário reagrupar categorias porque algumas frequências são muito baixas. Por exemplo vamos criar uma nova variável para agrupar 2o Grau e Superior usando ifelse() e depois podemos refazer as análises do cruzamento com esta nova variável
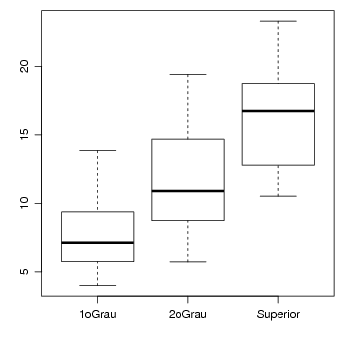
Qualitativa vs Quantitativa Para exemplificar este caso vamos considerar as variáveis instrucao e salario.
Para se obter uma tabela de frequências é necessário agrupar a variável quantitativa em classes. No exemplo a seguir vamos agrupar a variável salário em 4 classes definidas pelos quartis usando cut(). Note que as classes são definidas por intervalos abertos à esquerda e então usamos o argumento include.lowest=TRUE para garantir que todos os dados, incluve o menor (mínimo) seja incluído na primeira classe. Após agrupar esta variável obtemos a(s) tabela(s) de cruzamento como mostrado no caso anterior.
No gráfico vamos considerar que neste exemplo a instrução deve ser a variável explicativa e portanto colocada no eixo-X e o salário é a variável resposta e portanto no eixo-Y. Isto é, consideramos que a instrução deve explicar, ainda que parcialmente, o salário (e não o contrário!). Vamos então obter um boxplot dos salários para cada nível de instrução. Note que o função abaixo usamos a notação de formula do R, com salario instrucao indicando que a variável salario é explicada (~) pela variável instrucao.
Poderíamos ainda fazer gráficos com a variável salario agrupada em classes, e neste caso os gráficos seriam como no caso anterior com duas variáveis qualitativas.
Para as medidas o usual é obter um resumo da quantitativa como mostrado na análise univariada, porém agora infromando este resumo para cada nível do fator qualitativo. A seguir mostramos alguns exemplos de como obter a média, desvio padrão e o resumo de cinco números do salário para cada nível de instrução.
Quantitativa vs Quantitativa Para ilustrar este caso vamos considerar as variáveis salario e idade. Para se obter uma tabela é necessário agrupar as variáveis em classes conforma fizemos no caso anterior. Nos comandos abaixo agrupamos as duas variáveis em classes definidas pelos respectivos quartis gerando portanto uma tabela de cruzamento 4 × 4.
Caso queiramos definir um número menor de classes podemos fazer como no exemplo a seguir onde cada variável é dividida em 3 classes e gerando um tabela de cruzamento 3 × 3.
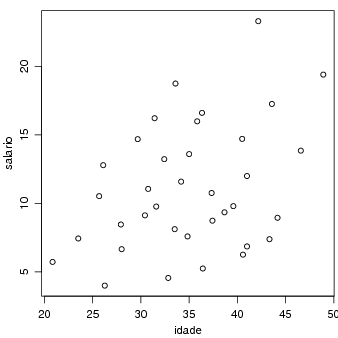
O gráfico adequado para representar duas variáveis quantitativas é um diagrama de dispersão. Note que se as variáveis envolvidas puderem ser classificadas como "explicativa"e "resposta"devemos colocar a primeira no eixo-X e a segunda no eixo-Y. Neste exemplo é razoável admitir que a idade deve explicar, ao menos parcialmente, o salário e portanto fazemos o gráfico com idade n eixo-X.
Para quantificar a associação entre variáveis deste tipo usamos um coeficiente de correlação. A função cor() do R possui opção para três coeficientes tendo como default o coeficiente de correlação linear de Pearson.
Em geral as técnicas descritivas uni e bivariadas mostradas até aqui podem ser extendidas a mais dimensões. Além disto há ferramentas específicas para exploração de dados multidimensionais. Neste momento vamos apenas ilustrar como o comando tapply() pode ser extendido. Anteriormente nesta sessão mostramos como calcular o salário médio para cada nível de instrução. Vamos extender este exemplo calculando o salário médio também para cada estado civil e para combinação dos níveis destes dois fatores. Esta úmtima é mostrada de duas maneiras, uma delas retornando um vetor e outra uma matrix.
Além de funções pré-definidas no R, como mean() utilizada nos comandos anteriores, podemos definir uma função particular que desejemos. Como exemplo, considere contar em cada grupo, o número de indivíduos que tem salário igual ou superior a 10 unidades, os comandos seriam como mostrado a seguir.
Lembre que ao iniciar as análises com este conjunto de dados anexamos os dados com o comando attach(milsa). Portanto ao terminar as análises com estes dados devemos desanexar este conjunto de dados com o detach()
O R vem com algumas demonstrações (demos) de seus recursos “embutidas” no programa. Para listar as demos disponíveis digite na linha de comando:
Para rodar uma delas basta colocar o nome da escolhida entre os parênteses. As demos são úties para termos uma idéia dos recursos disponíveis no programa e para ver os comandos que devem ser utilizados.
Por exemplo, vamos rodar a demo de recursos gráficos. Note que os comandos vão aparecer na janela de comandos e os gráficos serão automaticamente produzidos na janela gráfica. A cada passo voce vai ter que teclar ENTER para ver o próximo gráfico.
Há vários conjuntos de dados incluídos no programa R como, por exemplo, o conjunto mtcars. Estes conjuntos são todos documentados, isto é, voce pode usar a função help para obter uma descrição dos dados. Para ver a lista de conjuntos de dados disponíveis digite data(). Por exemplo tente os seguintes comandos:
As funções do R são documentadas e o uso é explicado e ilustrado usando a help(). Por exemplo, o comando help(mean) vai exibir e documentação da função mean(). Note que no final da documentação há exemplos de uso da função que voce pode reproduzir para entendê-la melhor.