Subsections
5 Ilustrando propriedades de estimadores
Um estimador é consistente quando seu valor se aproxima do verdadeiro valor do parâmetro à medida que aumenta-se o tamanho da amostra.
Vejamos como podemos ilustrar este resultado usando simulação.
A idéia básica é a seguite:
- escolher uma distribuição e seus parâmetros,
- definir o estimador,
- definir uma sequência crescente de valores de tamanho de amostras,
- obter uma amostra de cada tamanho,
- calcular a estatística para cada amostra,
- fazer um gráfico dos valores das estimativas contra o tamanho de amostra,
indicando neste gráfico o valor verdadeiro do parâmetro.
Seguindo os passos acima vamos:
- tomar a distribuição Normal de média 10 e variância 4,
- definir o estimador
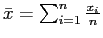 ,
,
- escolhemos os tamanhos de amostra
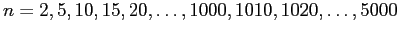 ,
,
- fazemos os cálculos e produzimos um gráfico com os comandos abaixo.
> ns <- c(2, seq(5, 1000, by=5), seq(1010, 5000, by=10))
> estim <- numeric(length(ns))
> for (i in 1:length(ns)){
> amostra <- rnorm(ns[i], 10, 4)
> estim[i] <- mean(amostra)
> }
> plot(ns, estim)
> abline(h=10)
Figura 9:
Médias de amostras de diferentes tamanhos.
|
|
5.2 Momentos das distribuições amostrais de estimadores
Para inferência estatística é necessário conhecer a distribuição amostral dos estimadores.
Em alguns casos estas distribuições são derivadas analiticamente.
Isto se aplica a diversos resultados vistos no curso de Inferência I.
Por exemplo o resultado visto na Sessãosimulacao 3:
se
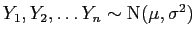 então
então
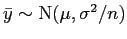 .
Resultados como estes podem ser ilustrados computacionalmente como visto na
Sessãosimulacao 3.
.
Resultados como estes podem ser ilustrados computacionalmente como visto na
Sessãosimulacao 3.
Além disto este procedimento permite investigar distribuições amostrais
que não podem ser obtidas analiticamente.
Vamos ver um exemplo: considere 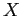 uma v.a. com distribuição normal
uma v.a. com distribuição normal
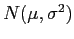 e seja um parâmetro de interesse
e seja um parâmetro de interesse
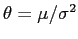 .
Obter a esperança e variância de um estimador de
.
Obter a esperança e variância de um estimador de
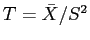 onde
onde 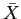 é a média e
é a média e 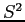 a variância de uma amostra.
a variância de uma amostra.
- escolher uma distribuição e seus parâmetros, no caso vamos escolher uma
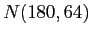 ,
,
- definir um tamanho de amostra, no caso escolhemos
 ,
,
- obter por simulação um número
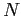 de amostras, vamos usar
de amostras, vamos usar 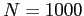 ,
,
- calcular a estatística de interesse para cada amostra,
- obter as estimativas
![$ \hat{E}[T]$](img89.png) e
e
![$ \hat{{\rm Var}}[T]$](img90.png) usando as amostras.
usando as amostras.
Vamos ver agora comandos do .
> amostras <- matrix(rnorm(20*1000, mean=180, sd=8), nc=1000)
> Tvals <- apply(amostras, 2, function(x) {mean(x)/var(x)})
> ET <- mean(Tvals)
> ET
[1] 3.134504
> VarT <- var(Tvals)
> VarT
[1] 1.179528
Nestes comandos primeiro obtemos 1000 amostras de tamanho 20 que armazenamos em uma matrix de dimensão
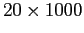 , onde cada coluna é uma amostra. A seguir usamos a função
, onde cada coluna é uma amostra. A seguir usamos a função apply para calcular a quantidade desejada que definimos com
function(x) {mean(x)/var(x)}.
No meu caso acima obtive
![$ \hat{E}[T] \approx 3.13$](img92.png) e
e
![$ \hat{{\rm Var}}[T] \approx 1.18$](img93.png) .
Se voce rodar os comandos acima deverá obter resultados um pouco diferentes (mas não muito!) pois nossas amostras da distribuição normal não são as mesmas.
.
Se voce rodar os comandos acima deverá obter resultados um pouco diferentes (mas não muito!) pois nossas amostras da distribuição normal não são as mesmas.
Fica como exercício, ver abaixo.
Fica como exercício, ver abaixo.
- Ilustre a consistência do estimador
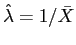 de uma distribuição exponencial
de uma distribuição exponencial
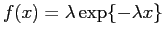 .
.
- No exemplo dos momentos das distribuições de estimadores visto em (5.2) ilustramos a obtenção dos momentos para um tamanho fixo de amostra . Repita o procedimento para vários tamanho de amostra e faça um gráfico mostrando o comportamento de
e
em função de
 .
.
- Estime por simulação a esperança e variância do estimador
 de uma distribuição de Poisson de parâmetro
de uma distribuição de Poisson de parâmetro 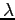 para um tamanho de amostra
para um tamanho de amostra  . Compara com os valores obtidos analiticamente. Mostre em um gráfico como os valores de
. Compara com os valores obtidos analiticamente. Mostre em um gráfico como os valores de
![$ \hat{E}[\lambda]$](img98.png) e
e
![$ \hat{{\rm Var}}[\lambda]$](img99.png) variam em função de .
variam em função de .
- Crie um exemplo para ilustrar a não tendenciosidade de estimadores. Sugestão: compare os estimadores
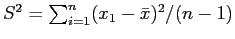 e
e
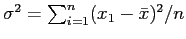 do parâmetro de variância
do parâmetro de variância  de uma distribuição normal.
de uma distribuição normal.
- Crie um exemplo para comparar a variância de dois estimadores.
Por exemplo compare por simulação as variâncias dos estimadores
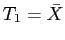 e
e
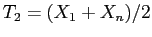 do parâmetro
do parâmetro  de uma distribuição
de uma distribuição
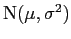 , onde
, onde 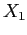 e
e 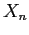 são os valores mínimo e máximo da amostra, respectivamente.
são os valores mínimo e máximo da amostra, respectivamente.
Paulo Justiniano & Paulo Ricardo
![\includegraphics[width=0.6\textwidth]{figuras/prop01.ps}](img81.png)