Nesta aula vamos nos aprofundar um pouco mais na teoria de intervalos de confiança. São ilustrados os conceitos de:
Voce vai precisar conhecer de conceitos do método da quantidade pivotal, a propriedade de normalidade assintótica dos estimadores de máxima verossimilhança e a distribuição limite da função deviance.
Os dados abaixo são uma amostra aleatória da distribuição ![]() .
.
Primeiramente vamos entrar com os dados na forma de um vetor.
> y <- c(0,0,0,1,1,0,1,1,1,1,0,1,1,0,1,1,1,1,0,1,1,1,1,1,1)
(a)
Vamos escrever uma função para obter a função de verossimilhança.
> vero.binom <- function(p, dados){
+ n <- length(dados)
+ x <- sum(dados)
+ return(dbinom(x, size = n, prob = p, log = TRUE))
+ }
Esta função exige dados do tipo ![]() ou
ou ![]() da distribuição Bernoulli.
Entretanto às vezes temos dados Binomiais do tipo
da distribuição Bernoulli.
Entretanto às vezes temos dados Binomiais do tipo ![]() e
e ![]() (número
(número ![]() de sucessos em
de sucessos em ![]() observações).
Por exemplo, para os dados acima teríamos
observações).
Por exemplo, para os dados acima teríamos ![]() e
e ![]() .
Vamos então escrever a função acima de forma mais geral de forma que possamos utilizar dados
disponíveis tanto em um quanto em ou outro formato.
.
Vamos então escrever a função acima de forma mais geral de forma que possamos utilizar dados
disponíveis tanto em um quanto em ou outro formato.
> vero.binom <- function(p, dados, n = length(dados), x = sum(dados)){
+ return(dbinom(x, size = n, prob = p, log = TRUE))
+ }
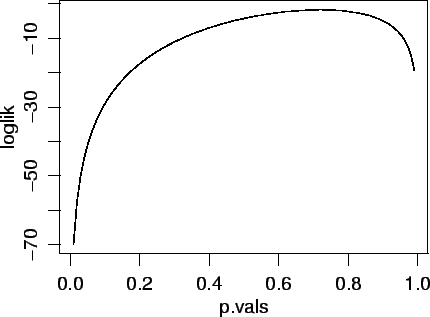
Agora vamos obter o gráfico da função de verossimilhança para estes dados.
Uma forma de fazer isto é criar uma sequência de valores para o parâmetro ![]() e calcular o valor da verossimilhança para cada um deles. Depois fazemos o gráfico dos valores obtidos contra os valores do parâmetro.
No R isto pode ser feito com os comandos abaixo que produzem o gráfico mostrado na
Figura 14.
e calcular o valor da verossimilhança para cada um deles. Depois fazemos o gráfico dos valores obtidos contra os valores do parâmetro.
No R isto pode ser feito com os comandos abaixo que produzem o gráfico mostrado na
Figura 14.
> p.vals <- seq(0.01,0.99,l=99) > logvero <- sapply(p.vals, vero.binom, dados=y) > plot(p.vals, logvero, type="l")
Note que os três comandos acima podem ser substituídos por um único que produz o mesmo resultado:
> curve(vero.binom(x, dados=y), from = 0, to = 1)
(b)
Dos resultados para distribuição Bernoulli sabemos que
o estimador de máxima verossimilhança é dado por
> p.est <- mean(y) > arrows(p.est, vero.binom(p.est,dados=y), p.est, min(logvero)) > io <- ie <- length(y)/(p.est * (1 - p.est)) > io [1] 124.0079 > ie [1] 124.0079
(c)
O intervalo de confiança baseado na normalidade assintótica do estimador de máxima verossimilhança é dado por:
> ic1.p <- p.est + qnorm(c(0.025, 0.975)) * sqrt(1/ie) > ic1.p [1] 0.5439957 0.8960043
(d)
Vamos agora obter o intervalo baseado na função deviance graficamente.
Primeiro vamos escrever uma função para calcular a deviance que vamos chamar de dev.binom, lembrando que a deviance é definida pela expressão:
> dev.binom <- function(p, dados, n = length(dados), x =sum(dados)){
+ p.est <- x/n
+ vero.p.est <- vero.binom(p.est, n = n, x = x)
+ dev <- 2 * (vero.p.est - vero.binom(p, n = n, x = x))
+ dev
+ }
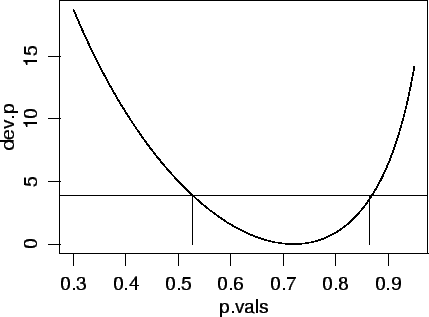
E agora vamos fazer o gráfico de forma similar ao que fizemos para função de verossimilhança, definindo uma sequência de valores, calculando as valores da deviance e traçando a curva.
> p.vals <- seq(0.3, 0.95, l=101) > dev.p <- dev.binom(p.vals, dados=y) > plot(p.vals, dev.p, typ="l")
Agora usando esta função vamos obter o intervalo gráficamente.
Para isto definimos o ponto de corte da função usando o fato que
a função deviance ![]() tem distribuição assintótica
tem distribuição assintótica ![]() .
Nos comandos a seguir primeiro encontramos o ponto de corte para o nível de confiança de 95%.
Depois traçamos a linha de corte com o comando
.
Nos comandos a seguir primeiro encontramos o ponto de corte para o nível de confiança de 95%.
Depois traçamos a linha de corte com o comando abline.
Os comandos seguintes consistem em uma forma simples e aproximada para encontrar os pontos onde a linha conta a função, que definem o intervalo de confiança.
> corte <- qchisq(0.95, df=1) > abline(h=corte) > dif <- abs(dev.p - corte) > inf <- ifelse(p.est==0, 0, p.vals[p.vals<p.est][which.min(dif[p.vals<p.est])]) > sup <- ifelse(p.est==1, 1, p.vals[p.vals>p.est][which.min(dif[p.vals>p.est])]) > ic2.p <- c(inf, sup) > ic2.p [1] 0.5275 0.8655 > segments(ic2.p, 0, ic2.p, corte)
Agora que já vimos as duas formas de obter o IC passo a passo vamos usar os comandos acima para criar uma função geral para encontrar IC para qualquer conjunto de dados e com opções para os dois métodos.
> ic.binom <- function(dados, n=length(dados), x=sum(dados),
+ nivel = 0.95,
+ tipo=c("assintotico", "deviance")){
+ tipo <- match.arg(tipo)
+ alfa <- 1 - nivel
+ p.est <- x/n
+ if(tipo == "assintotico"){
+ se.p.est <- sqrt((p.est * (1 - p.est))/n)
+ ic <- p.est + qnorm(c(alfa/2, 1-(alfa/2))) * se.p.est
+ }
+ if(tipo == "deviance"){
+ p.vals <- seq(0,1,l=1001)
+ dev.p <- dev.binom(p.vals, n = n, x = x)
+ corte <- qchisq(nivel, df=1)
+ dif <- abs(dev.p - corte)
+ inf <- ifelse(p.est==0, 0, p.vals[p.vals<p.est][which.min(dif[p.vals<p.est])])
+ sup <- ifelse(p.est==1, 1, p.vals[p.vals>p.est][which.min(dif[p.vals>p.est])])
+ ic <- c(inf, sup)
+ }
+ names(ic) <- c("lim.inf", "lim.sup")
+ ic
+ }
E agora vamos utilizar a função, primeiro com a aproximação assintótica e depois pela deviance. Note que os intervalos são diferentes!
> ic.binom(dados=y) lim.inf lim.sup 0.5439957 0.8960043 > ic.binom(dados=y, tipo = "dev") lim.inf lim.sup 0.528 0.869
(e)
O cálculo do intervalo de cobertura consiste em:
Para isto vamos escrever uma função implementando estes passos e que utiliza internamente ic.binom definida acima.
> cobertura.binom <- function(n, p, nsim, ...){
+ conta <- 0
+ for(i in 1:nsim){
+ ysim <- rbinom(1, size = n, prob = p)
+ ic <- ic.binom(n = n, x = ysim, ...)
+ if(p > ic[1] & p < ic[2]) conta <- conta+1
+ }
+ return(conta/nsim)
+ }
E agora vamos utilizar esta função para cada um dos métodos de obtenção dos intervalos.
> set.seed(123) > cobertura.binom(n=length(y), p=0.8, nsim=1000) [1] 0.885 > set.seed(123) > cobertura.binom(n=length(y), p=0.8, nsim=1000, tipo = "dev") [1] 0.954
Note que a cobertura do método baseado na deviance é muito mais próxima do nível de 95% o que pode ser explicado pelo tamanho da amostra. O IC assintótico tende a se aproximar do nível nominal de confiança na medida que a amostra cresce.