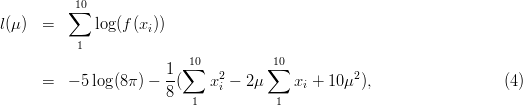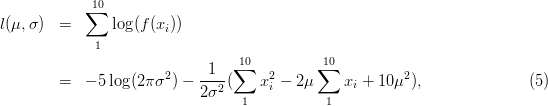16 Funções de verossimilhança
A função de verossimilhança é central na inferência estatística. Nesta sessão vamos
ver como traçar gráficos de funções de verossimilhança de um parâmetro utilizando o
programa R. Também veremos como traçar a função deviance, obtida a partir da função de
verossimilhança e conveniente em certos casos para representações gráficas, cálculos e
inferências.
16.1 Definições e notações
Seja L(θ; y) a função de verossimilhança. A notação indica que o argumento da função é θ que pode
ser um escalar ou um vetor de parâmetros. Nesta sessão consideraremos que é um escalar. O termo y
denota valores realizados de uma variável aleatória Y , isto é os valores obtidos em uma
amostra.
O valor que maximiza L(θ; y) é chamado do estimador de máxima verossimilhança e denotado por
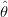 . A função de verossimilhança relativa ou normatizada R(θ; y) é dada pela razão entre a função de
verossimilhança e o valor maximizado desta função, portanto R(θ; y) = L(θ; y)∕L(
. A função de verossimilhança relativa ou normatizada R(θ; y) é dada pela razão entre a função de
verossimilhança e o valor maximizado desta função, portanto R(θ; y) = L(θ; y)∕L(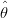 ; y),
assumindo valores no intervalo [0, 1]. Esta função é útil para comparar todos dos modelos dados
pelos diferentes valores de θ com o modelo mais plausível (verossível) para a amostra
obtida.
; y),
assumindo valores no intervalo [0, 1]. Esta função é útil para comparar todos dos modelos dados
pelos diferentes valores de θ com o modelo mais plausível (verossível) para a amostra
obtida.
O valor que maximiza a função de verossimilhança é também o que maximiza a a função obtida
pelo logarítimo da função de verossimilhança, chamada função de log-verossimilhança, uma vez que
a função logarítimo é uma função monotônica. Denotamos a função de log-verossimilhança por
l(θ; y) sendo l(θ; y) = log(L(θ; y)). A função de log-verossimilhança é mais adequada para cálculos
computacionais e permite que modelos possam ser comparados aditivamente, ao invés de
multiplicativamente.
Aplicando-se o logarítimo à função padronizada obtemos log{R(θ; y)} = l(θ; y) -l(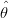 ; y), que tem
portanto um valor sempre não-positivo. Desta forma esta função pode ser multiplicada
por um número negativo arbitrário, e sendo este número -2 obtemos a chamada função
deviance, D(θ; y) = -2
; y), que tem
portanto um valor sempre não-positivo. Desta forma esta função pode ser multiplicada
por um número negativo arbitrário, e sendo este número -2 obtemos a chamada função
deviance, D(θ; y) = -2![[ ]
ˆ
l(θ;y) - l(θ; y)](Rembrapa77x.png) , onde lembramos que
, onde lembramos que 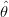 é o estimador de máxima
verossimilhança de θ. Esta função tem portanto o seu mínimo em zero e quanto maior o seu valor,
maior a diferença de plausibilidade entre o modelo considerado e o modelo mais plausível
para os dados obtidos na amostra. Esta função combina as vantagens da verossimilhança
relativa e da log-verossimilhança sendo portanto conveniente para cálculos computacionais e
inferência.
é o estimador de máxima
verossimilhança de θ. Esta função tem portanto o seu mínimo em zero e quanto maior o seu valor,
maior a diferença de plausibilidade entre o modelo considerado e o modelo mais plausível
para os dados obtidos na amostra. Esta função combina as vantagens da verossimilhança
relativa e da log-verossimilhança sendo portanto conveniente para cálculos computacionais e
inferência.
16.2 Exemplo 1: Distribuição normal com variância conhecida
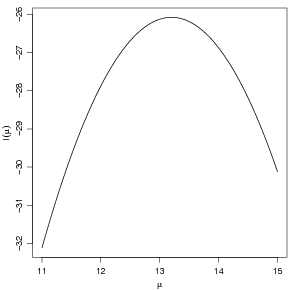
Seja o vetor (12, 15, 9, 10, 17, 12, 11, 18, 15, 13) uma amostra aleatória de uma distribuição normal
de média μ e variância conhecida e igual a 4. O objetivo é fazer um gráfico da função de
log-verossimilhança.
Solução:
Vejamos primeiro os passos da solução analítica:
-
1.
- Temos que X1,…,Xn onde, neste exemplo n = 10, é uma a.a. de X ~ N(μ, 4),
-
2.
- a densidade para cada observação é dada por f(xi) =
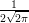 exp{-
exp{-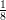 (xi - μ)2},
(xi - μ)2},
-
3.
- a verossimilhança é dada por L(μ) = ∏
110f(μ; x
i),
-
4.
- e a log-verossimilhança é dada por
-
5.
- que é uma função de μ e portanto devemos fazer um gráfico de l(μ) versus μ tomando vários
valores de μ e calculando os valores de l(μ).
Vamos ver agora uma primeira possível forma de fazer a função de verossimilhança no
R.
-
1.
- Primeiro entramos com os dados que armazenamos no vetor x
> x <- c(12, 15, 9, 10, 17, 12, 11, 18, 15, 13)
-
2.
- e calculamos as quantidades ∑
110x
i2 e ∑
110x
i
> sx2 <- sum(x^2)
> sx <- sum(x)
-
3.
- agora tomamos uma sequência de valores para μ. Sabemos que o estimador de máxima
verossimilhança neste caso é
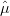 = 13.2 (este valor pode ser obtido com o comando mean(x)) e
portanto vamos definir tomar valores ao redor deste ponto.
= 13.2 (este valor pode ser obtido com o comando mean(x)) e
portanto vamos definir tomar valores ao redor deste ponto.
> mu.vals <- seq(11, 15, l = 100)
-
4.
- e a seguir calculamos os valores de l(μ) de acordo com a equação acima
> lmu <- -5 * log(8 * pi) - (sx2 - 2 * mu.vals * sx + 10 * (mu.vals^2))/8
-
5.
- e finalmente fazemos o gráfico visto na Figura 34
> plot(mu.vals, lmu, type = "l", xlab = expression(mu), ylab = expression(l(mu)))
Entretanto podemos obter a função de verossimilhança no R de outras forma mais geral e menos
trabalhosa. Sabemos que a função dnorm() calcula a densidade f(x) da distribuição normal e
podemos usar este fato para evitar a digitação da expressão acima.
Para encerrar este exemplo vamos apresentar uma solução ainda mais genérica que consiste em
criar uma função que vamos chamar de vero.norm.v4 para cálculo da verossimilhança de
distribuições normais com σ2=4. Esta função engloba os comandos acima e pode ser utilizada para
obter o gráfico da log-verossimilhança para o parâmetro μ para qualquer amostra obtida desta
distribuição.
> vero.normal.v4 <- function(mu, dados) {
+ logvero <- function(mu, dados) sum(dnorm(dados, mean = mu, sd = 2,
+ log = TRUE))
+ sapply(mu, logvero, dados = dados)
+ }
> curve(vero.normal.v4(x, dados = x), 11, 15, xlab = expression(mu),
+ ylab = expression(l(mu)))
16.3 Exemplo 2: Distribuição Poisson
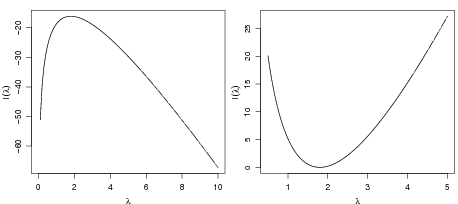
Considere agora a amostra armazenada no vetor y:
> y <- c(5, 0, 3, 2, 1, 2, 1, 1, 2, 1)
de uma distribuição de Poisson de parâmetro λ. A função de verossimilhança pode ser definida por:
> lik.pois <- function(lambda, dados) {
+ loglik <- function(l, dados) {
+ sum(dpois(dados, lambda = l, log = TRUE))
+ }
+ sapply(lambda, loglik, dados = dados)
+ }
E podemos usar esta função para fazer o gráfico da função de verossimilhança como visto à
esquerda da Figura 35
> lambda.vals <- seq(0, 10, l = 101)
> loglik <- sapply(lambda.vals, lik.pois, dados = y)
> plot(lambda.vals, loglik, ty = "l")
E o comando para gerar o gráfico poderia incluir o texto do eixos:
> plot(lambda.vals, loglik, type = "l", xlab = expression(lambda),
+ ylab = expression(l(lambda)))
ou simplesmente usar:
> curve(lik.pois(x, dados = y), 0, 10, xlab = expression(lambda),
+ ylab = expression(l(lambda)))
Alternativamente pode-se fazer um gráfico da função deviance, como nos comandos abaixo.
> dev.pois <- function(lambda, dados) {
+ lambda.est <- mean(dados)
+ lik.lambda.est <- lik.pois(lambda.est, dados = dados)
+ lik.lambda <- lik.pois(lambda, dados = dados)
+ return(-2 * (lik.lambda - lik.lambda.est))
+ }
> curve(dev.pois(x, dados = y), 0, 10, xlab = expression(lambda),
+ ylab = expression(D(lambda)))
Ou fazendo novamente em um intervalo menor
> curve(dev.pois(x, dados = y), 0.5, 5, xlab = expression(lambda),
+ ylab = expression(l(lambda)))
O estimador de máxima verossimilhança é o valor que maximiza a função de verossimilhança que
é o mesmo que minimiza a função deviance. Neste caso sabemos que o estimador tem expressão
analítica fechada λ = x e portanto pode ser obtido diretamente.
> lambda.est <- mean(y)
> lambda.est
Caso o estimador não tenha expressão fechada pode-se usar maximização (ou minimização)
numérica. Para ilustrar isto vamos encontrar a estimativa do parâmetro da Poisson e verificar que o
valor obtido coincide com o valor dado pela expressão fechada do estimador. Usamos o função
optimise() para encontrar o ponto de mínimo da função deviance.
> optimise(dev.pois, int = c(0, 10), dados = y)
$minimum
[1] 1.800004
$objective
[1] 1.075264e-10
A função optimise() é adequada para minimizações envolvendo um único parâmetro. Para dois
ou mais parâmetros deve-se usar a função optim() ou nlminb().
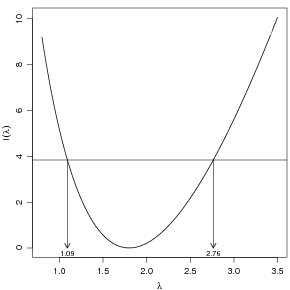
Finalmente os comandos abaixo são usados para obter graficamente o intervalo de confiança (a
95%) baseado na função deviance.
> curve(dev.pois(x, dados = y), 0.8, 3.5, xlab = expression(lambda),
+ ylab = expression(l(lambda)))
> L.95 <- qchisq(0.95, df = 1)
> abline(h = L.95)
Os limites do intervalo são dados pela interseção dessa função com o valor do quantil da
distribuição χ2 para o nível de significância desejado.
> lim.fc <- function(lambda) dev.pois(lambda, dados = y) - L.95
> ic2.lambda <- c(inf = uniroot(lim.fc, c(0, lambda.est))$root, sup = uniroot(lim.fc,
+ c(lambda.est, max(y)))$root)
> ic2.lambda
inf sup
1.091267 2.764221
E adicionados ao gráfico com
> arrows(ic2.lambda, L.95, ic2.lambda, 0, len = 0.1)
> text(ic2.lambda, 0, round(ic2.lambda, dig = 2), pos = 1, cex = 0.8,
+ offset = 0.3)
16.4 Exemplo 3: Distribuição normal com variância desconhecida
Vamos agora revisitar o Exemplo 1 desta seção, usando os mesmos dados porém agora sem
assumir que a variância é conhecida. Portanto temos agora dois parâmetros sobre os quais queremos
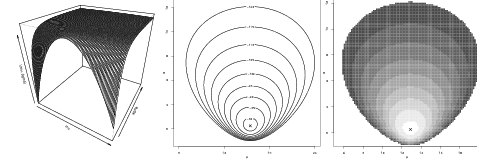
fazer inferência: μ e σ . O objetivo é fazer um gráfico 3-D da função de log-verossimilhança de dois
argumentos l(μ,σ).
Solução:
Vejamos primeiro os passos da solução analítica:
-
1.
- Temos que X1,…,Xn onde, neste exemplo n = 10, é uma a.a. de X ~ N(μ,σ2),
-
2.
- a densidade para cada observação é dada por f(xi) =
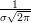 exp{-
exp{-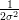 (xi - μ)2},
(xi - μ)2},
-
3.
- a verossimilhança é dada por L(μ,σ) = ∏
110f(μ,σ; x
i),
-
4.
- e a log-verossimilhança é dada por
-
5.
- que é uma função de μ e σ e portanto devemos fazer um gráfico tridimensional de l(μ,σ) versus
μ e σ tomando vários valores de pares (μ,σ) e calculando os valores correspondentes de
l(μ,σ).
Assim como no Exemplo 1 poderíamos calcular a verossimilhança fazendo as contas "passo a
passo"da função acima, ou então usando a função dnorm(). Neste exemplo vamos fazer apenas da
segunda forma, ficando a primeira como exercício para o leitor.
-
1.
- Primeiro entramos com os dados que armazenamos no vetor x. Vamos também calcular as
estimativas de máxima verossimilhança.
> x <- c(12.1, 15.4, 9.8, 10.1, 17.4, 12.3, 11, 18.2, 15.4, 13.3,
+ 13.8, 12.7, 15.2, 10.3, 9.9, 11.5, 14, 12.1, 11.2, 11.9, 11.1,
+ 12.5, 13.5, 14.8, 12.1, 12.5, 9.7, 11.3, 8.6, 15.9, 12.8, 13.6,
+ 13.8, 15.7, 15.5)
> pars.MV <- c(mu = mean(x), sd = sqrt(var(x) * (length(x) - 1)/length(x)))
> pars.MV
-
2.
- a seguir vamos criar uma função que calcula o valor da log-verossimilhança para um certo par
de valores dos parâmetros (média e desvio padrão, nesta ordem) e para um certo conjunto de
dados,
> logveroN <- function(pars, dados) sum(dnorm(dados, mean = pars[1],
+ sd = pars[2], log = TRUE))
-
3.
- a seguir criamos uma sequência adequada de pares de valores de (μ,σ) e calculamos l(μ,σ) para
cada um dos pares.
> par.vals <- expand.grid(mu = seq(5, 20, l = 100), sd = seq(1, 12.2,
+ l = 100))
> dim(par.vals)
mu sd
1 5.000000 1
2 5.151515 1
3 5.303030 1
4 5.454545 1
5 5.606061 1
6 5.757576 1
mu sd
9995 19.24242 12.2
9996 19.39394 12.2
9997 19.54545 12.2
9998 19.69697 12.2
9999 19.84848 12.2
10000 20.00000 12.2
> par.vals$logL <- apply(par.vals, 1, logveroN, dados = x)
> head(par.vals)
mu sd logL
1 5.000000 1 -1208.903
2 5.151515 1 -1167.486
3 5.303030 1 -1126.873
4 5.454545 1 -1087.064
5 5.606061 1 -1048.058
6 5.757576 1 -1009.856
Note na sintaxe acima que a função apply aplica a função logveroN a cada par de valores em
cada linha de par.vals. Ao final o objeto |par.vals| contém na terceira coluna os valores da
log-verossimilhança correspondentes as valores dos parâmetros dados na primeira e segunda
colunas.
-
4.
- O gráfico 3-D da função pode ser visualizado de três formas alternativas como mostrado na
Figura 37: como uma superfície 3D gerada pela função persp(), como um mapa de curvas de
isovalores obtido com image(), ou ainda como um mapa de cores correspondentes aos valores
gerado por image().
> with(par.vals, persp(unique(mu), unique(sd), matrix(logL, ncol = length(unique(sd))),
+ xlab = expression(mu), ylab = expression(sigma), zlab = expression(l(mu,
+ sigma)), theta = 30, phi = 30))
> with(par.vals, contour(unique(mu), unique(sd), matrix(logL, ncol = length(unique(sd))),
+ xlab = expression(mu), ylab = expression(sigma), levels = seq(-120,
+ -75, by = 5)), ylim = c(0, 12))
> points(pars.MV[1], pars.MV[2], pch = 4, cex = 1.5)
> with(par.vals, image(unique(mu), unique(sd), matrix(logL, ncol = length(unique(sd))),
+ xlab = expression(mu), ylab = expression(sigma), breaks = seq(-120,
+ -75, by = 5), col = gray(seq(0.3, 1, length = 9))))
> points(pars.MV[1], pars.MV[2], pch = 4, cex = 1.5)
Notas:
- a obtenção da função foi necessário especificar faixas de valores para μ e σ. A definição
desta faixa foi feita após várias tentativas pois depende do problema, em especial do
número e variabilidade dos dados.
- as funções gráficas utilizadas requirem: dois vetores de tamanhos n1 e n2 com os valores
dos argumentos da função e os valores da função em uma matrix de dimensão n1×n2. Por
isto usamos unique() para extrair os valores dos argumentos, sem repeti-los e matrix()
para os valores da função.
- na função perp() as argumentos theta e phi são utilizados para rotacionar o gráfico a
fim de se obter uma melhor visualização.
- o valor das estimativas de máxima verossimilhança são indicados por x nos dois últimos gráficos.
Neste caso eles foram encontrados facilmente como mostrado acima no objeto pars.MV pois
podem ser obtidos analiticamente. De forma mais geral, a função fitdistr() do
pacote MASS poide ser usada para encontrar estimativas de máxima verossimilhança.
> require(MASS)
> MV <- fitdistr(x, "normal")
> MV
mean sd
12.8857143 2.2489544
( 0.3801427) ( 0.2688015)
16.5 Exercícios
-
1.
- Seja a amostra abaixo obtida de uma distribuição Poisson de parâmetro λ.
5 4 6 2 2 4 5 3 3 0 1 7 6 5 3 6 5 3 7 2
Obtenha o gráfico da função de log-verossimilhança.
-
2.
- Seja a amostra abaixo obtida de uma distribuição Binomial de parâmetro p e com n = 10.
7 5 8 6 9 6 9 7 7 7 8 8 9 9 9
Obtenha o gráfico da função de log-verossimilhança.
-
3.
- Seja a amostra abaixo obtida de uma distribuição χ2 de parâmetro ν.
8.9 10.1 12.1 6.4 12.4 16.9 10.5 9.9 10.8 11.4
Obtenha o gráfico da função de log-verossimilhança.