Figura 52: Exemplos de gráficos definidos através de fórmulas.
Objetos do R podem ser separados entre objetos de dados (vetores, matrizes, arrays, data-frames e listas) e outros tipos de objetos. As fórmulas constituem um tipo especial de objeto no Rque representam simbolicamente relação entre variáveis e/ou objetos de dados. Fórmulas podem são em geral usadas em funções gráficas e funções que analisam dados a partir de algum modelo definido pela fórmula.
Nesta seção vamos fazer uma breve introdução ao uso de fórmulas através de alguns exemplos de análises de dados. Para isto iremos utilizar o conjunto de dados mtcars disponível com o R. Este conjunto contém características técnicas de diversos modelos da automóvel. Para carregar os dados e e listar os nomes das variáveis utilize os comandos a seguir. Lembre-se ainda que help(mtcars) irá fornecer mais detalhes sobre estes dados.
Algumas (mas não todas!) funções gráficas do R aceitam uma fórmula como argumento. Em geral tais funções exibem gráficos para explorar a relação entre variáveis. O R possui dois tipos de sistemas gráficos: (i) gráficos base (base graphics) e (ii) gráficos lattice. Os exemplos mostrados aqui se referem apenas ao primeiro sistema. Gráficos láttice são disponibilizados pelo pacote lattice. no qual as fórmulas são ainda mais importante e largamente utilizadas.
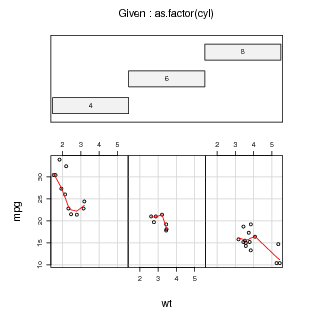
A Figura 52 mostra dois tipos de gráficos que são definidos a partir de fórmulas. No primeiro a variável de rendimento (mpg: milhas por galão) é relacionada com uma variável categórica (cyl: número de cilindros). No segundo caso o rendimento é relacionado com o peso do veículo. A fórmula do tipo y ~ x pode ser lida como: a variável y é explicada por x.
A Figura 23.1 mostra agora um exemplo onde o gráfico de rendimento explicado pelo peso é feito para cada número de cilindros separadamente. Neste caso a formula usa o símbolo | para indicar condicionamento e é do tipo y ~ x|A podendo ser lida como a relação entre y e x para cada nível da variável A.
Assim como no caso de gráficos, algums funções de análise de dados também aceitam fórmulas em seus argumentos. Considere o exemplo do texte-t para comparação de duas amostras na comparação do rendimento de veículos com cambio automático e manual. No exemplo a seguir mostramos o uso da função de duas formas que produzem resultados idênticos, uma sem usar fórmula e outra usando fórmula.
Portanto em mpg ~ am pode-se ler: rendimento (mpg) explicado por tipo de câmbio (am). De forma similar a função para comparação de variâncias também pode utilizar fórmulas.
A fórmula é um objeto do R e possui a classe formula. Desta forma, funções que tenham métodos para esta classe tratam o objeto adequadamente. Por exemplo, no caso de t.test recebendo uma formula como argumento o método formula para t.test é disponível, como indica a documentação da função.
A seguir reforçamos estas idéias e vemos alguns comandos aplicados à manipulação de fórmulas. As funções all.vars() e terms() são particularmente úteis para manipulação de fórmulas o objetos dentro de funções.
Entre os diversos usos de fórmulas, o mais importante deles é sem dúvida o fato que fórmulas são utimizadas na declaração de modelos estatísticos. Um aspecto particularmente importante da linguagem S, o portanto no programa R, é que adota-se uma abordagem unificada para modelagem, o que inclui a sintaxe para especificação de modelos. Variáveis respostas e covariáveis (variáveis explanatórias) são sempre especificadas de mesma forma básica, ou seja, na forma resposta ~ covariavel, onde:
No restante deste texto vamos, por simplicidade, considerar que há apenas uma variável resposta que poderá ser explicada por uma ou mais covariáveis.
Considere, para o conjunto de dados mtcars, ajustar um modelo que explique o rendimento (Y:mpg) pelo peso do veículo (X:wt). O modelo linear é dado por:
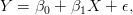
Note que a fórmula apenas especifica a relação entre as variáveis resposta e explanatórias e não implica que o modelo seja necessariamente linear. A linearidade é dada pela função lm(). Portanto a mesma fórmula pode ser usada para outros tipos de ajuste como o mostrado na linha tracejada do gráfico resultantes de regressão local polinomial obtida por loess()).
Nem todas as funções que relacionam variáveis aceitam formulas, como por exemplo o caso da regressão por núcleo (kernel) dada por ksmooth() cujo o ajuste é mostrado na linha pontilhada. Outras funções extendem a notação de funções como é o caso do ajuste por modelos aditivos generalizados gam() mostrado na linha sólida grossa, onde o termo s() indica que a variável resposta deve ser descrita por uma função suave da covariável incluída neste termo.
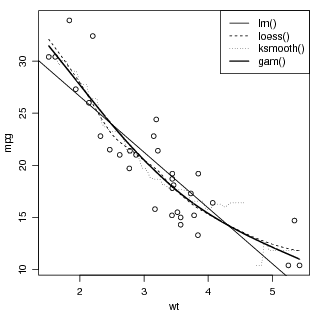
Nos exemplos acima é interessante notar o uso de predict() que é utilizada para predizer o valor da resposta para um conjunto arbitrário de valores da covariável, baseando-se no modelo ajustado. No exemplo utilizamos este recurso para produzir o gráfico com a "curva"do modelo ajustado para uma sequência de valores da covariável. Para a função lm() utilizamos apenas abline() devido ao fato que esta função retorna a equação de uma reta que é interpretada a traçada por um método abline. Entretanto predict() também poderia ser usada e a reta traçada com o comando a seguir. Esta forma é mais flexível para traçar funções (modelos) ajustados que sejam mais complexos que uma equação de uma reta.
As formulas admitem operadores aritméticos em seus termos. Por exemplo considere a relação entre o rendimento (mgp) e a potência (hp). A linha sólida no gráfico da esquerda da Figura 23.5 sugere que o modelo linear não descreve bem a relação entre estas variáveis, enquanto no gráfico da direita sugere a relação é melhor descrita por um modelo linear entre o rendimento e o logarítmo de potência. Na chamada das funções utilizamos a operação aritmética log() diretamente na fórmula, sem a necessidade de transformar os dados originais.
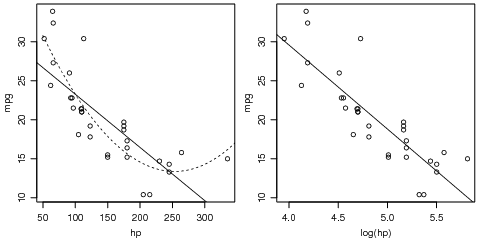
Uma outra possibilidade para os dados originais é o ajuste de um modelo dado por uma função polinomial, conforme mostrado na linha tracejada no gráfico da esquerda da Figura 23.5 e que é ajustado com os comandos a seguir. Neste ajuste é importante notar que a variável quadrática deve ser especificada com I(hp^2) e o uso de I() é obrigatório para garantir que os valores de hp sejam de fato elevados ao quadrado. O uso de hp^2 possui um significado diferente que veremos na próxima sessão.
Uma outra forma de especificar regressões polinomiais é com o uso de poly(), onde o grau do desejado do polinômio é um argumento desta função conforme ilustrado nos comandos a seguir. No exemplo é importante notar que a interpretação dos parâmetros é diferente devido ao fato de que polinômios ortogonais são utilizados. Entretanto os valores preditos e as estatísticas de ajuste são iguais. O ajuste por polinômios ortogonais é numericamente mais estável e portanto deve ser preferido quando possível. Quando se usa as opções default a função poly() vai sempre contruir polinômios ortogonais. Caso queira-se usar potências usuais deve-se adicionar à chamada desta funções o argumento raw=T.
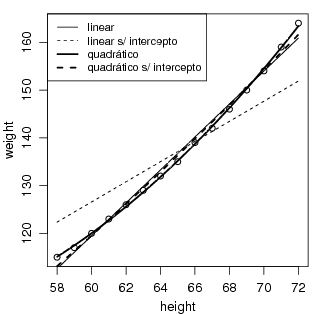
Vamos considerar agora um outro exemplo de ajuste de modelo linear, agora para o conjunto de dados women que fornece peso (weight) em libras (lbs) e altura (height) em polegadas (in) de 15 mulheres americanas de 30-39 anos. Os comandos a seguir mostram os quatro ajustes indicados na Figura 56. O primeiro (linha fina sólida) é uma regressão linear, o segundo (linha fina tracejada) é uma regressão linear com intercepto igual a zero, isto é, a reta passa pela origem. O terceiro (linha sólida grossa) é uma regressão quadrática e o quarto (linha sólida grossa) é uma regressão quadrática passando pela origem. Neste exemplo fica então ilustrado que a adição do termo + 0 na fórmula faz com que o intercepto do modelo seja nulo e apenas o parâmetro referente ao coeficiente angular da reta seja estimado.
Nos exemplos anteriores a variável resposta era explicada por apenas uma variável explanatória. Isto pode ser expandido considerando-se a presença de duas ou mais variáveis explicativas. A Tabela 23.6 resume as principais operações possíveis para definir modelos com uma ou duas variáveis e que podem ser extendidas para o caso de mais variáveis.
| Termos | Especificação |
| A + B | Efeitos principais A e B |
| A : B | Termo de interação entre A e B |
| A * B | Efeitos principais e interação, corresponde a A + B + A : B |
| B %in% A | B dentro (aninhado) de A |
| A/B | Efeito principal e aninhado, corresponde a A + B%in%A |
| A-B | tudo de A exceto o que está em B |
| A^k | Todos os termos de A e interação de ordem k |
| A + 0 | exclui o intercepto de modelo |
| I() | operador de identidade aritmética, ver explicação no texto |
Esta notação é uma implementação das idéias propostas por Wilkinson e Rogers para especificação de modelos estatísticos. (G. N. Wilkinson. C. E. Rogers. Symbolic Description of Factorial Models for Analysis of Variance. Applied Statistics, Vol. 22, No. 3, 392-399. 1973).
Para ilustrar algumas destas opções vamos considerar novamente o conjunto de dados mtcars ajustando modelos para o rendimento (mpg) explicado pelo peso (wt) e potência (hp) do veículo. Nos comandos a seguir mostramos os coeficientes estimados a partir de cinco formas de especificação de modelos.
Os resultados sugerem que as fórmulas definem modelos diferentes, exceto pelos termos wt * hp e (wt * hp)^2 onde o mesmo modelo é especificado de duas formas alternativas. Os modelos ajustados para explicar o rendimento mpg denotado por Y são:
Chama-se atenção ao fato que a notação de "potência" em (wt+hp)^2 não indica uma operação aritmética mas sim a inclusão de todos os efeitos principais e interações até as de ordem indicada pela potência. Para incluir a operação aritmética de potência é necessário utilizar I() no termo a ser exponenciado.
De forma geral, a mensagem é de que os operadores soma (+), produto (*), divisão (/) e potência
( ) têm nas fórmulas o papel de definir numa notação simbólica quais e como os termos devem
ser incluídos no modelo. Em fórmulas, tais operadores só indicam operações aritméticas
com os termos envolvidos quando utilizados dentro de I(). A função I() garante que a
expressão nela contida seja avaliada como uma função aritmética, tal e qual está escrita ("as
is").
) têm nas fórmulas o papel de definir numa notação simbólica quais e como os termos devem
ser incluídos no modelo. Em fórmulas, tais operadores só indicam operações aritméticas
com os termos envolvidos quando utilizados dentro de I(). A função I() garante que a
expressão nela contida seja avaliada como uma função aritmética, tal e qual está escrita ("as
is").
Na tabela 23.6 são ilustradas mais algumas especificações de modelos. No caso marcado com (*) os modelos são equivalentes porém os coeficientes resultantes são diferentes como comentado sobre polinômios ortogonais na Sessão 23.5.
| Declaração | Modelo equivalente | Descrição |
| A+B*C | A+B+C+B:C | todos efeitos principais e interação dupla apenas |
| entre B e C | ||
| A+B*(C+D) | A+B+C+D+B:C+B:D | todos efeitos principais e interações duplas |
| de B com C e B com D | ||
| A*B*C | A+B+C+A:B+A:C+B:C+A:B:C | todos efeitos principais e interações possíveis |
| (A+B+C)^3 | A+B+C+A:B+A:C+B:C+A:B:C | três covariáveis e interações de ordem 2 e 3 |
| (igual ao anterior) | ||
| (A+B+C)^2 | A+B+C+A:B+A:C+B:C | três covariáveis e interações de ordem 2 |
| (A+B+C)^3 - A:B:C | (A+B+C)^2 | três covariáveis e interações de ordem 2 |
| (A+B+C)^2 - A:C | A+B+C+A:B+B:C | três covariáveis e interações de ordem 2, |
| exceto por A : C | ||
| A+I(A^2)+I(A^3) | poly(A,3) | regressão polinomial cúbica em A (*) |
| A+I(A^2)+I(A^3) | poly(A,3,raw=TRUE) | regressão polinomial cúbica em A |
| A+I(A^2)+B | poly(A,2)+B | termos lineares em A e B e quadrático em A (*) |
| A+I(A^2)+B | poly(A,2,raw=TRUE)+B | termos lineares em A e B e quadrático em A |
| y ~ . | A+B+... | inclui como covariáveis todas as variáveis no |
| objeto de dados, exceto a resposta | ||
| y ~ . - A | B+... | inclui como covariáveis todas as variáveis no |
| objeto de dados, exceto a resposta e a variável A | ||
Uma vez que um objeto contenha uma fórmula, é possível obter uma nova fórmula que seja uma modificação da original utilizando update.formula().
A lógica da sintaxe é que o primeiro argumento recebe uma fórmula inicial e o segundo indica a modificação. O caracter ponto (⋅) indica tudo. Ou seja, em . ~ . - x2 entende-se: a nova fórmula deverá possuir tudo que estava do lado esquerdo, e tudo do lado direito, excluindo a variável x2.
Este mecanismos é útil para evitar que fórmulas precisem ser totalmente redigitadas a cada redefinição do modelo, o que é útil ao se investigar vários modelos que são obtidos uns a partir de outros. O mecanismo também reduz a chance de erros nas especificações uma vez que garante a igualdade daquilo que é indicado pela notação de ponto (⋅).