Capítulo 2 Álgebra Matricial
A técnica escolhida para ilustrar os conceitos de funções e derivadas em ciência de dados foi o modelo de regressão linear simples. Nós vimos na Seção 1.2.9 que neste modelo o treinamento, ou estimação dos parâmetros, se resumiu a encontrar a solução de um sistema de duas equações lineares. Agora imagine uma situação prática com milhares de potenciais variáveis explicativas: como seria o treinamento deste modelo? Assim, fica claro que precisamos de ferramentas que nos permitam lidar com muitas equações simultâneas e de preferência de uma forma compacta e eficiente. É neste contexto que as ferramentas de Álgebra Matricial são valiosas em ciência de dados.
O objetivo deste Capítulo é apresentar as principais ferramentas de Álgebra Matricial úteis em ciência de dados. Como exemplo ilustrativo será apresentado o modelo de regressão linear múltipla que estende o modelo de regressão linear simples permitindo um número arbitrário de variáveis explicativas. Para a sua representação utilizaremos uma notação matricial em que o modelo é escrito matematicamente de uma forma compacta e de fácil entendimento. Além disso, as ferramentas de Álgebra Matricial vão permitir obter equações compactas para os estimadores dos coeficientes de regressão, o que facilita o processo de treinamento do modelo.
Por fim, nós vamos discutir algumas decomposições matriciais que consistem em escrever a matriz gerada pelos dados em formas convenientes para o processo de treinamento e discutir como utilizar tais decomposições em ciência de dados. Especial ênfase será dada ao caso de problemas em que o número de variáveis explicativas é maior que o número de observações (High Dimensional data). Nestas situações a decomposição em valores singulares leva ao modelo de regressão ridge, também bastante popular em ciência de dados e uma extensão natural do modelo de regressão linear múltipla.
2.1 Vetores e escalares
Em termos de notação nós vamos usar letras minúsculas em negrito, por exemplo,
\[ \mathbf{a} = \begin{pmatrix} a_1 & \ldots & a_n \end{pmatrix} \quad \text{ou} \quad \mathbf{a} = \begin{pmatrix} a_1 \\ \vdots \\ a_n \end{pmatrix}. \] Quando os elementos estão organizados em linha dizemos que temos um vetor linha. Por outro lado, quando os elementos estão organizados em coluna dizemos que temos um vetor coluna. Um elemento do vetor é chamado de \(a_i\), sendo \(i\) a posição do elemento no vetor. O tamanho de um vetor é o seu número de elementos.
O módulo de um vetor é o seu comprimento
\[ |\mathbf{a}| = \sqrt{a_1^2 + \ldots + a_n^2}.\] O vetor unitário é o vetor com comprimento \(1\). Podemos padronizar um vetor qualquer para ter tamanho \(1\) dividindo cada elemento do vetor pelo seu comprimento,
\[\hat{\mathbf{a}} = \frac{\mathbf{a}}{|\mathbf{a}|}.\]
Dizemos que dois vetores são iguais se têm o mesmo tamanho e se todos os seus elementos em posições equivalentes são iguais.
2.1.1 Operações com vetores
Da mesma forma que podemos fazer operações soma, subtração, multiplicação e divisão com números (no contexto de Álgebra Linear são chamados de escalares) também podemos fazer operações com vetores. No entanto, nem todas as operações usuais de escalares são válidas para vetores. De forma geral, vetores podem ser somados, subtraídos e multiplicados de forma especial. Porém, vetores não podem ser divididos e existem algumas operações especiais com vetores como o produto interno.
Dois vetores podem ser somados ou subtraídos apenas se forem do mesmo tipo (linha ou coluna) e do mesmo tamanho. Para definirmos as operações com vetores, considere dois vetores \(\mathbf{a}\) e \(\mathbf{b}\) adequados, ou seja, mesmo tipo e tamanho, e \(\alpha\) um escalar, as seguintes operações são bem definidas:
Soma: \(\mathbf{a} + \mathbf{b} = (a_i + b_i) = (a_1 + b_1, \ldots, a_n + b_n).\)
Subtração: \(\mathbf{a} - \mathbf{b} = (a_i - b_i) = (a_1 - b_1, \ldots, a_n - b_n).\)
Multiplicação por escalar: \(\alpha \mathbf{a} = (\alpha a_1, \ldots, \alpha a_n)\).
Transposta de um vetor: a operação transposta transforma um vetor coluna em um vetor linha e vice-versa. Por exemplo,
\[ \mathbf{a} = \begin{pmatrix} a_1 & \ldots & a_n \end{pmatrix} \quad \quad \mathbf{a}^{\top} = \begin{pmatrix} a_1 \\ \vdots \\ a_n \end{pmatrix}. \]
- Produto interno ou escalar entre dois vetores resulta em um escalar:
\[\mathbf{a} \cdot \mathbf{b} = (a_1 b_1 + a_2 b_2 + \ldots + a_n b_n).\]
O co-seno do ângulo \(\theta\) entre os vetores \(\mathbf{a}\) e \(\mathbf{b}\) é dado por:
\[\begin{equation} \cos(\theta)=\frac{\mathbf{a}^{\top}\mathbf{b}}{\sqrt{\mathbf{a}^{\top}\mathbf{a}}\sqrt{\mathbf{b}^{\top}\mathbf{b}}}. \end{equation}\]
Dizemos que dois vetores são ortogonais entre si se o ângulo \(\theta\) entre eles é 90º o que implica que \(\cos(\theta)=0\) e que \(\mathbf{a}^{\top} \mathbf{b}=0\).
Todas as operações descritas para vetores são trivialmente definidas em R. Vamos ver alguns exemplos. Para declarar um vetor em R usamos a função c().
a <- c(4,5,6)
b <- c(1,2,3)Sendo os vetores compatíveis podemos facilmente somá-los, subtraí-los, multiplicar por um escalar ou obter o produto interno, conforme ilustrado no Código 2.1. Porém, cabe enfatizar que a divisão entre vetores não é definida.
Código 2.1 Operações com vetores.
## Soma
a + b## [1] 5 7 9## Subtração
a - b## [1] 3 3 3## Multiplicação por escalar
alpha = 10
alpha*a## [1] 40 50 60## Produto interno
a%*%b## [,1]
## [1,] 32Neste ponto é importante falar sobre a lei da reciclagem em R e dos cuidados que devemos ter ao fazer operações com vetores.
Vamos definir dois vetores, \(a\) e \(b\), porém de tamanhos diferentes.
a <- c(4,5,6,5,6,7)
b <- c(1,2,3)
a + b## [1] 5 7 9 6 8 10Note que apesar dos vetores não serem compatíveis para a soma, o R realizou alguma operação. É neste ponto que aparece a lei da reciclagem. Veja que os três primeiros elementos do vetor resultante da soma de a + b são \(4 + 1 = 5; 5 + 2 = 7\) e \(6 + 3 = 9\). Porém, o R ainda reporta mais três números que são o resultado de \(5 + 1 = 6; 6 + 2 = 8\) e \(7 + 3 = 10\), ou seja, o R reciclou os elementos do vetor b para completar a tarefa de somar a + b. Portanto, é muito importante tomar cuidado ao fazer operações com vetores em R.
Um outro ponto importante é a forma de fazer a multiplicação entre vetores. Veja o uso do operador especial %*% para a multiplicação entre vetores. O símbolo usual de multiplicação * não realiza a multiplicação vetorial, mas sim uma multiplicação elemento por elemento, também chamada de produto de Hadamard.
a <- c(4,5,6)
b <- c(1,2,3)
## Multiplicação elemento a elemento (Hadamard)
a*b## [1] 4 10 18## Multiplicação entre vetores
a%*%b## [,1]
## [1,] 32Usando as operações com vetores podemos facilmente calcular o co-seno do ângulo \(\theta\) entre dois vetores compatíveis.
cos_theta <- t(a)%*%b/(sqrt(t(a)%*%a)*sqrt(t(b)%*%b))
cos_theta## [,1]
## [1,] 0.9752.2 Matrizes
Definição 2.2 Uma matriz é um arranjo retangular ou quadrado de números ou variáveis. Uma matriz \((n \times m)\) tem \(n\) linhas e \(m\) colunas: \[ \mathbf{A} = \begin{pmatrix} a_{11} & a_{12} & \ldots & a_{1m} \\ a_{21} & a_{22} & \ddots & a_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} & \ldots & \ldots & a_{nm} \end{pmatrix}. \]
Em termos de notação, nós vamos usar letras maiúsculas em negrito para representar uma matriz, por exemplo: \(\mathbf{A}\). Neste livro os elementos de uma matriz serão números reais ou variáveis representando números reais. Por exemplo, a matriz \(\mathbf{A}\) representa as notas e o número de faltas de três alunos do curso de estatística básica. Cada linha representa um aluno, a primeira coluna a nota e a segunda o número de faltas.
\[ \mathbf{A} = \begin{pmatrix} 80 & 0 \\ 95 & 1 \\ 70 & 5 \end{pmatrix}. \]
Para representar os elementos da matriz como variáveis ou incógnitas, usamos letras minúsculas, por exemplo,
\[ \mathbf{A} = \begin{pmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \\ a_{31} & a_{32} \end{pmatrix}. \]
Vamos adotar que o primeiro subscrito representa linha e o segundo a coluna do elemento, ou seja, \(a_{\text{linha}\;\text{coluna}}\). Assim, podemos representar a matriz também por meio dos seus elementos, \(\mathbf{A} = a_{ij}\) para \(i=1, \ldots, n\) e \(j=1, \ldots, m\) onde \(n\) e \(m\) são o número de linhas e colunas da matriz, respectivamente. Para o exemplo dos alunos, temos \(n = 3\) e \(m = 2\). É comum referenciar uma matriz pela sua dimensão ou tamanho, ou seja, o número de linhas e colunas. Dizemos, então que \(\mathbf{A}\) tem dimensão \(n \times m\), leia-se “A matriz \(\mathbf{A}\) tem dimensão \(n\) por \(m\).” Particularizando para o nosso exemplo \(\mathbf{A}\) é \(3 \times 2\).
Note que um vetor é simplesmente uma matriz com apenas uma linha ou uma coluna. De forma similar, podemos pensar que um escalar é apenas uma matriz de dimensão \(1 \times 1\). No entanto, um escalar é tecnicamente diferente de uma matriz \(1 \times 1\) em termos de aplicações e propriedades em Álgebra Linear. Tais diferenças ficarão claras no decorrer do Capítulo.
Dizemos que duas matrizes são iguais se tem a mesma dimensão e se os elementos das correspondentes posições são iguais. A operação de transpor também é definida para matrizes de forma similar ao realizado para vetores. Assim, a operação de transposição rearranja uma matriz de forma que suas linhas são transformadas em colunas e vice-versa. Considere o exemplo,
\[ \begin{pmatrix} 1 & 2\\ 3 & 4\\ 5 & 6 \end{pmatrix}^{\top} = \begin{pmatrix} 1 & 3 & 5\\ 2 & 4 & 6 \end{pmatrix}. \]
Além disso, é claro que \((\mathbf{A}^{\top})^{\top} = \mathbf{A}\), ou seja, a transposta da transposta de uma matriz é a matriz original.
Para definir uma matriz em R usamos o comando matrix() que permite rearranjar um vetor em uma matriz. O Código 2.2 define uma matriz \(3 \times 2\) em R.
Código 2.2 Inicialização de uma matriz.
a <- c(1,2,3,4,5,6)
A <- matrix(a, nrow = 3, ncol = 2)
A## [,1] [,2]
## [1,] 1 4
## [2,] 2 5
## [3,] 3 6Por default o R vai preencher a matriz por coluna. Assim, os primeiros três valores do vetor formam a primeira coluna, enquanto que os três últimos formam a segunda coluna. Os argumentos nrow e ncol definem o número de linhas e colunas da matriz resultante. É possível também preencher a matriz por linhas, caso seja de interesse. Neste caso usamos o argumento byrow = TRUE.
A <- matrix(a, nrow = 3, ncol = 2, byrow = TRUE)
A## [,1] [,2]
## [1,] 1 2
## [2,] 3 4
## [3,] 5 6A transposição de uma matriz ou vetor é realizada pela função t(), conforme ilustrado no Código 2.3.
Código 2.3 Transposta de uma matriz.
## Transposta de uma matriz
t(A)## [,1] [,2] [,3]
## [1,] 1 3 5
## [2,] 2 4 62.2.1 Operações com matrizes
Algumas operações entre matrizes e vetores também são definidas. Qualquer escalar pode ser multiplicado por qualquer matriz da seguinte forma:
\[ \alpha \mathbf{A} = \begin{pmatrix} \alpha a_{11} & \alpha a_{12} & \ldots & \alpha a_{1m} \\ \alpha a_{21} & \alpha a_{22} & \ddots & \alpha a_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ \alpha a_{n1} & \ldots & \ldots & \alpha a_{nm} \end{pmatrix}. \]
Em palavras, multiplicar um escalar por uma matriz é simplesmente multiplicar cada entrada da matriz pelo escalar de interesse. O resultado é uma matriz de mesma dimensão da matriz original. Note ainda que \(\alpha \mathbf{A} = \mathbf{A} \alpha\).
O código 2.4 ilustra tal operação em R.
Código 2.4 Multiplicação de escalar por matriz.
A <- matrix(c(1,2,3,4,5,6), nrow = 3, ncol = 2)
alpha <- 10
alpha*A## [,1] [,2]
## [1,] 10 40
## [2,] 20 50
## [3,] 30 60Duas matrizes podem ser somadas ou subtraídas somente se tiverem o mesmo tamanho. O resultado da soma ou subtração de duas matrizes \(\mathbf{A}\) e \(\mathbf{B}\) ambas \((n \times m)\) é uma matriz \(\mathbf{C}\) de mesmo tamanho cujos elementos são dados por:
- Soma \(c_{ij} = a_{ij} + b_{ij}.\)
- Subtração \(c_{ij} = a_{ij} - b_{ij}.\)
Por exemplo,
\[ \begin{pmatrix} 1 & 2\\ 3 & 4\\ 5 & 6 \end{pmatrix} + \begin{pmatrix} 10 & 20\\ 30 & 40 \\ 50 & 60 \end{pmatrix} = \begin{pmatrix} 11 & 22\\ 33 & 44\\ 55 & 66 \end{pmatrix}. \]
O Código 2.5 ilustra a soma de matrizes em R.
Código 2.5 Soma de matrizes.
A <- matrix(c(1,2,3,4,5,6), nrow = 3, ncol = 2)
B <- matrix(c(10,20,30,40,50,60), nrow = 3, ncol = 2)
C = A + B
C## [,1] [,2]
## [1,] 11 44
## [2,] 22 55
## [3,] 33 66A multiplicação \(\mathbf{C} = \mathbf{A} \mathbf{B}\) é definida apenas quando o número de colunas de \(\mathbf{A}\) é igual ao número de linhas de \(\mathbf{B}\). \(\underset{m \times n}{\mathbf{C}} = \underset{m \times q}{\mathbf{A}} \underset{q \times n}{\mathbf{B}}\). Cada elemento \(c_{ij} = \sum_{k = 1}^q a_{ik} b_{kj}.\)
Por exemplo,
\[ \begin{pmatrix} 2 & -1\\ 8 & 3\\ 6 & 7 \end{pmatrix} \begin{pmatrix} 4 & 9 & 1 & -3\\ -5 & 2 & 4 & 6 \end{pmatrix} = \]
\[ \begin{pmatrix} (2 \cdot 4 + -1 \cdot-5) & (2\cdot 9 + -1 \cdot 2) & (2\cdot1 + -1 \cdot 4) & (2 \cdot -3 + -1 \cdot 6) \\ (8\cdot 4 + 3 \cdot -5) & (8\cdot 9 + 3 \cdot 2) & (8 \cdot 1 + 3 \cdot 4) & (8 \cdot -3 + 3 \cdot 6) \\ (6\cdot4 + 7\cdot -5) & (6 \cdot 9 + 7 \cdot 2) & (6 \cdot 1 + 7 \cdot 4) & (6 \cdot - 3 + 7 \cdot 6) \end{pmatrix} = \]
\[ \begin{pmatrix} 13 & 16 & -2 & -12\\ 17 & 78 & 20 & -6\\ -11 & 68 & 34 & 24 \end{pmatrix}. \]
O Código 2.6 ilustra a multiplicação de matrizes em R. Novamente note o uso do operador especial %*% ao invés do símbolo usual de multiplicação *.
Código 2.6 Multiplicação de matrizes.
A <- matrix(c(2,8,6,-1,3,7), nrow = 3, ncol = 2)
B <- matrix(c(4,-5,9,2,1,4,-3,6), nrow = 2, ncol = 4)
C = A%*%B
C## [,1] [,2] [,3] [,4]
## [1,] 13 16 -2 -12
## [2,] 17 78 20 -6
## [3,] -11 68 34 24Em geral \(\mathbf{A} \mathbf{B} \neq \mathbf{B} \mathbf{A}\). Veja que no caso das matrizes do exemplo anterior \(\mathbf{B}\) tem dimensão \(2\times 4\), enquanto \(\mathbf{A}\) tem dimensão \(3 \times 2\), e portanto o produto não pode ser feito. Apenas como ilustração o Código 2.7 tenta realizar a multiplicação entre duas matrizes não compatíveis.
Código 2.7 Multiplicação de matrizes não compatíveis.
B %*% A## Error in B %*% A: non-conformable argumentsNeste caso o R retorna uma mensagem de erro indicando que as matrizes não são compatíveis para multiplicação.
Algumas propriedades da multiplicação de matrizes são apresentadas a seguir. Sendo \(\mathbf{A}, \mathbf{B}, \mathbf{C}\) e \(\mathbf{D}\) compatíveis temos,
- \(\mathbf{A} + \mathbf{B} = \mathbf{B} + \mathbf{A}\).
- \((\mathbf{A} + \mathbf{B}) + \mathbf{C} = \mathbf{A} + (\mathbf{B} + \mathbf{C}).\)
- \(\alpha (\mathbf{A} + \mathbf{B}) = \alpha \mathbf{A} + \alpha \mathbf{B}.\)
- \((\alpha + \beta) \mathbf{A} = \alpha \mathbf{A} + \beta \mathbf{A}.\)
- \(\alpha(\mathbf{A}\mathbf{B}) = (\alpha \mathbf{A})\mathbf{B} = \mathbf{A}(\alpha \mathbf{B}).\)
- \(\mathbf{A}(\mathbf{B} \pm \mathbf{C}) = \mathbf{A}\mathbf{B} \pm \mathbf{A}\mathbf{C}.\)
- \((\mathbf{A} \pm \mathbf{B})\mathbf{C} = \mathbf{A}\mathbf{C} \pm \mathbf{B}\mathbf{C}.\)
- \((\mathbf{A} - \mathbf{B})(\mathbf{C} - \mathbf{D}) = \mathbf{A}\mathbf{C} - \mathbf{B}\mathbf{C} - \mathbf{A}\mathbf{D} + \mathbf{B}\mathbf{D}.\)
Duas propriedades interessantes envolvendo transposta e multiplicação de matrizes são:
- Se \(\mathbf{A}\) é \(n \times m\) e \(\mathbf{B}\) é \(m \times n\), então \[(\mathbf{A} \mathbf{B})^{\top} = \mathbf{B}^{\top} \mathbf{A}^{\top}.\]
- De maneira similar, se \(\mathbf{A}, \mathbf{B}\) e \(\mathbf{C}\) são compatíveis \[(\mathbf{A} \mathbf{B} \mathbf{C} )^{\top} = \mathbf{C}^{\top} \mathbf{B}^{\top} \mathbf{A}^{\top}.\]
Neste momento estamos aptos a fazer a distinção entre escalar e uma matriz \(1 \times 1\). Considere que \(\mathbf{a}\) é uma matriz \(1 \times 1\). O produto de um escalar (\(\alpha\)) por uma matriz está definido para qualquer matriz. Entretanto, uma matriz \(1 \times 1\) só pode ser multiplicada por um vetor \(\mathbf{b}\) (\(1 \times n\), vetor linha) pela direita, ou seja, \(\mathbf{a} \mathbf{b}\) ou pela esquerda por um vetor \(\mathbf{b}\) (\(n \times 1\), vetor coluna) pela esquerda \(\mathbf{b} \mathbf{a}\). O Código 2.8 ilustra esta situação.
Código 2.8 Ilustração da diferença entre escalar e matriz \(1 \times 1\).
alpha <- 10
a <- matrix(10, nrow = 1, ncol = 1)
b <- matrix(c(1,2,3,4), nrow = 1, ncol = 4)
dim(a) # Dimensão de a## [1] 1 1dim(b) ## Dimensão de b## [1] 1 4a%*%b # Compatível## [,1] [,2] [,3] [,4]
## [1,] 10 20 30 40b%*%a ## Não compatível## Error in b %*% a: non-conformable argumentst(b)%*%a ## Compatível## [,1]
## [1,] 10
## [2,] 20
## [3,] 30
## [4,] 40alpha*b # Escalar com matriz## [,1] [,2] [,3] [,4]
## [1,] 10 20 30 40b*alpha # Escalar com matriz## [,1] [,2] [,3] [,4]
## [1,] 10 20 30 40Um outro tipo de produto entre vetores ou matrizes é o chamado produto de Hadamard. Sendo duas matrizes ou dois vetores de mesmo tamanho o produto de Hadamard é simplesmente o resultado da multiplicação direta dos elementos correspondentes:
\[
\mathbf{A} \odot \mathbf{B} = \begin{pmatrix}
a_{11} b_{11} & a_{12} b_{12} & \cdots & a_{1m}b_{1m} \\
a_{21} b_{21} & a_{22} b_{22} & \cdots & a_{2m} b_{2m} \\
\vdots & \vdots & \vdots & \vdots\\
a_{n1} b_{n1} & a_{n2} b_{n2} & \cdots & a_{nm} b_{nm}
\end{pmatrix}.
\]
Estamos usando a notação \(\odot\) para diferenciar o produto de Hadamard do produto matricial usual. Em R este produto é obtido usando o operador * usual, conforme ilustrado no Código 2.9.
Código 2.9 Produto de Hadamard.
A <- matrix(c(1,2,3,4), nrow = 2, ncol = 2)
B <- matrix(c(10,20,30,40), nrow = 2, ncol = 2)
A*B## [,1] [,2]
## [1,] 10 90
## [2,] 40 1602.2.2 Matrizes de formas especiais
Nesta subseção veremos algumas matrizes com formas especiais.
Dizemos que uma matriz é quadrada quando tem o mesmo número de linhas e colunas. Por exemplo,
\[ \mathbf{A} = \begin{pmatrix} a_{11} & a_{12} & a_{13} & a_{14} \\ a_{21} & a_{22} & a_{23} & a_{24} \\ a_{31} & a_{32} & a_{33} & a_{34} \\ a_{41} & a_{42} & a_{43} & a_{44} \end{pmatrix}. \]
Chamamos os elementos \(a_{ii}\) de elementos diagonais ou da diagonal. Já os elementos \(a_{ij}\) para \(i \neq j\) são chamados de elementos fora da diagonal. Os elementos \(a_{ij}\) para \(j > i\) são os elementos acima da diagonal e os elementos \(a_{ij}\) para \(i > j\) são os elementos abaixo da diagonal.
Uma matriz é diagonal se apenas os elementos diagonais são diferentes de zero. Por exemplo,
\[ \mathbf{D} = \begin{pmatrix} a_{11} & 0 & 0 & 0 \\ 0 & a_{22} & 0 & 0 \\ 0 & 0 & a_{33} & 0 \\ 0 & 0 & 0 & a_{44} \end{pmatrix}. \]
Uma matriz é triangular superior se os elementos abaixo da diagonal são todos iguais a zero. É comum denotar uma matriz triangular superior por \(\mathbf{U}\) do Inglês upper.
\[ \mathbf{U} = \begin{pmatrix} a_{11} & a_{12} & a_{13} & a_{14} \\ 0 & a_{22} & a_{23} & a_{24} \\ 0 & 0 & a_{33} & a_{34} \\ 0 & 0 & 0 & a_{44} \end{pmatrix}. \]
Por outro lado, uma matriz é triangular inferior se os elementos acima da diagonal são todos iguais a zero. Neste caso a notação usual é \(\mathbf{L}\) do Inglês lower.
\[ \mathbf{L} = \begin{pmatrix} a_{11} & 0 & 0 & 0 \\ a_{21} & a_{22} & 0 & 0 \\ a_{31} & a_{32} & a_{33} & 0 \\ a_{41} & a_{42} & a_{43} & a_{44} \end{pmatrix}. \]
A matriz identidade é uma matriz diagonal onde os elementos diagonais são todos iguais a \(1\). A notação usual é \(\mathbf{I}\) do Inglês identity.
\[ \mathbf{I} = \begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{pmatrix}. \]
A matriz zero ou nula é aquela cuja todas as entradas são iguais a zero, ou seja,
\[ \mathbf{0} = \begin{pmatrix} 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{pmatrix}. \]
Uma matriz quadrado é dita ser simétrica se \(a_{ij} = a_{ji}\). De forma equivalente, se \(\mathbf{A}^{\top} = \mathbf{A}\), então \(\mathbf{A}\) é simétrica. Por exemplo,
\[ \mathbf{A} = \begin{pmatrix} 1 & 0.8 & 0.6 & 0.4 \\ 0.8 & 1 & 0.2 & 0.4 \\ 0.6 & 0.2 & 1 & 0.1 \\ 0.4 & 0.4 & 0.1 & 1 \end{pmatrix}. \]
2.2.3 Rank e inversa de uma matriz
Na seção 2.2.1 vimos diversas operações com matrizes. Muitas destas operações são extensões das operações de soma, subtração e multiplicação de escalares. No entanto, a divisão entre matrizes não foi definida. De forma geral duas matrizes não podem ser divididas, porém existe um tipo especial de matriz que tenta de certa forma estender a operação de divisão entre escalares para matrizes. Essa matriz especial é chamada de matriz inversa. Porém, a sua obtenção está limitada a um certo conjunto de matrizes que são chamadas não singulares. Nesta seção nós vamos entender o que é uma matriz não singular e como avaliar se uma matriz qualquer é ou não singular por meio da avaliação do seu rank, também chamado de posto.
Para definir o que é o rank de uma matriz precisamos da noção de dependência e independência linear. Um conjunto de vetores \(\mathbf{a}_1, \mathbf{a}_2, \ldots, \mathbf{a}_n\) é dito ser linearmente dependente se escalares \(c_1, c_2, \ldots, c_n\) não todos iguais a zero puderem ser encontrados de tal forma que
\[\begin{equation} c_1 \mathbf{a}_1 + c_2 \mathbf{a}_2 + \ldots + c_n \mathbf{a}_n = 0. \tag{2.1} \end{equation}\]
No caso em que os coeficientes \(c_1, c_2, \ldots, c_n\) não puderem ser encontrados satisfazendo (2.1) o conjunto de vetores \(\mathbf{a}_1, \mathbf{a}_2, \ldots, \mathbf{a}_n\) é dito ser linearmente independente. Note que a Equação (2.1) pode ser reescrita em formato matricial, onde os vetores \(\mathbf{a}_1, \mathbf{a}_2, \ldots, \mathbf{a}_n\) formam as colunas de uma matriz \(\mathbf{A}\) e os escalares são empilhados em um vetor \(\mathbf{c}\). Assim,
\[\mathbf{A} \mathbf{c} = \mathbf{0}.\] Neste caso as colunas de \(\mathbf{A}\) são linearmente independentes se \(\mathbf{A} \mathbf{c} = \mathbf{0}\) implicar que \(\mathbf{c} = 0\). Intuitivamente um conjunto de vetores linearmente dependentes é de alguma forma redundante, no sentido de que um dos vetores pode ser escrito como uma combinação linear dos outros.
Considere um exemplo trivial com os vetores \(\mathbf{a}_1 = (1,0)\) e \(\mathbf{a}_2 = (0,1)\). Veja que qualquer outro vetor de tamanho dois pode ser escrito como uma combinação linear dos vetores \(\mathbf{a}_1\) e \(\mathbf{a}_2\). Assim, qualquer outro vetor de tamanho dois concatenado com \(\mathbf{a}_1\) e \(\mathbf{a}_2\) em uma matriz \(\mathbf{A}\) tornará as colunas de \(\mathbf{A}\) linearmente dependentes. Porém, uma matriz \(\mathbf{A}\) formada apenas por \(\mathbf{a}_1\) e \(\mathbf{a}_2\) tem colunas linearmente independentes.
Definição 2.3 O rank ou posto de qualquer matriz quadrada ou retangular \(\mathbf{A}\) é definido como
\[\mathrm{rank}(\mathbf{A}) = \text{número de colunas ou linhas linearmente independentes em } \mathbf{A}.\]
Pode ser provado que o número de linhas e colunas linearmente independentes em uma matriz qualquer é sempre o mesmo. Se uma matriz \(\mathbf{A}\) tem apenas um elemento diferente de zero, então \(\mathrm{rank}(\mathbf{A}) = 1\). O \(\mathrm{rank}\) da matriz nula é \(0\).
Sendo \(\mathbf{A}\) uma matriz retangular \(n \times m\) o maior rank possível para \(\mathbf{A}\) é o \(\min(n,m)\). Quando o rank da matriz é o \(\min(n,m)\) dizemos que a matriz tem rank completo ou é de posto completo. Importante salientar que qualquer matriz retangular terá colunas linearmente dependentes. Com os conceitos apresentados até aqui podemos finalmente definir o que entendemos por uma matriz não singular e matriz inversa.
Definição 2.5 Dada uma matriz quadrada \(\mathbf{A}\) de posto completo a matriz inversa de \(\mathbf{A}\) denotada por \(\mathbf{A}^{-1}\) é única tal que
\[\mathbf{A}\mathbf{A}^{-1} = \mathbf{I}.\]
Se a matriz \(\mathbf{A}\) não for quadrada e de posto completo, então \(\mathbf{A}\) não terá inversa e é dita ser singular. Baseado na Definição 2.5 é fácil ver que \((\mathbf{A}^{-1})^{-1} = \mathbf{A}.\)
Em aplicações reais obter a inversa de uma matriz é uma tarefa complexa e requer o uso de algoritmos numéricos. Nós vamos ver algumas opções na Seção 2.3 quando discutiremos algoritmos para a solução de sistemas de equações lineares.
A intuição da matriz inversa é poder fazer operações similares a que realizamos com escalares quando estamos resolvendo sistemas de equações lineares. Lembre-se do sistema de equações lineares representado nas Equações (1.14) e (1.15) no modelo de regressão linear simples.
No decorrer deste livro seremos frequentemente confrontados com sistemas lineares do tipo \(\mathbf{A} \mathbf{x} = \mathbf{c}\) em que precisamos encontrar o vetor de incógnitas \(\mathbf{x}\). No caso em que \(\mathbf{A}\) é não singular, o sistema de equações \(\mathbf{A} \mathbf{x} = \mathbf{c}\) terá uma única solução dada por \(\mathbf{x} = \mathbf{A}^{-1} \mathbf{c}\). Veja como a inversa imita o que costumamos fazer com escalares quando resolvendo uma simples equação linear. É o equivalente ao que falamos grosseiramente de “passa pro outro lado.” O que realmente está sendo feito é que multiplicamos o sistema em ambos os lados por \(\mathbf{A}^{-1}\) para obter a solução, ou seja,
\[\begin{eqnarray} \mathbf{A}^{-1} \mathbf{A} \mathbf{x} &=& \mathbf{A}^{-1} \mathbf{c} \\ \mathbf{I}\mathbf{x} &=& \mathbf{A}^{-1} \mathbf{c}. \end{eqnarray}\]
Em R podemos facilmente obter a inversa de uma matriz usando a função solve(). No entanto, como ficará claro quando discutirmos métodos para a solução de sistemas lineares, tal solução é cara computacionalmente e raramente necessária explicitamente. O Código 2.10 ilustra a obtenção da inversa.
Código 2.10 Inversa de uma matriz.
A <- matrix(c(4, 2, 7, 6), 2, 2)
A_inv <- solve(A)
## Conferindo: deve resultar na matriz identidade
A%*%A_inv## [,1] [,2]
## [1,] 1 0
## [2,] 0 1Duas propriedades importantes envolvendo multiplicação e inversão de matrizes são:
- Se \(\mathbf{A}\) é não singular, então \(\mathbf{A}^{\top}\) é não singular e sua inversa é dada por \[(\mathbf{A}^{\top})^{-1} = (\mathbf{A}^{-1})^{\top}.\]
- Se \(\mathbf{A}\) e \(\mathbf{B}\) são matrizes não singulares de mesmo tamanho, então o produto \(\mathbf{A} \mathbf{B}\) é não singular e \[(\mathbf{A} \mathbf{B})^{-1} = \mathbf{B}^{-1} \mathbf{A}^{-1}.\]
No caso em que uma matriz é retangular não podemos obter a inversa. Nestes casos podemos recorrer a matriz inversa generalizada.
Definição 2.6 A inversa generalizada de uma matriz \(\mathbf{A}\) \(n \times p\) é qualquer matriz \(\mathbf{A}^{-}\) que satisfaça
\[\mathbf{A}\mathbf{A}^{-}\mathbf{A} = \mathbf{A}.\]
A inversa generalizada não é única exceto quando \(\mathbf{A}\) é não-singular, e neste caso coincide com a inversa. Toda matriz, seja quadrada ou retangular tem uma inversa generalizada, isto inclui vetores. Como um exemplo ilustrativo, considere o vetor
\[ \mathbf{a} = \begin{pmatrix} 1\\ 2\\ 3\\ 4 \end{pmatrix}. \]
Neste caso o vetor \(\mathbf{a}^{-} = (1, 0, 0, 0)\) é a inversa generalizada de \(\mathbf{a}\). Para verificar basta fazer a multiplicação matricial.
a <- matrix(c(1, 2, 3, 4), 4, 1)
a_invg <- matrix(c(1,0,0,0), 1, 4)
a%*%a_invg%*%a## [,1]
## [1,] 1
## [2,] 2
## [3,] 3
## [4,] 4Importante notar que se \(\mathbf{A}\) é \(n \times p\), então qualquer inversa generalizada de \(\mathbf{A}\) terá dimensão \(p \times n\).
Como dito, a inversa generalizada não é única. Em particular a inversa generalizada chamada de Moore-Penrose (Moore-Penrose Genereralized Inverse) está implementada em R por meio do pacote MASS. O Código 2.11 ilustra a obtenção da inversa generalizada de Moore-Penrose para uma matriz quadrada, porém singular.
Código 2.11 Inversa generalizada de Moore-Penrose.
## Matriz singular (a terceira coluna é a soma da primeira com a segunda)
A <- matrix(c(2, 1, 3, 2, 0, 2, 3, 1, 4), 3, 3)
## Carregando o pacote MASS
library(MASS)
A_ginv <- ginv(A)
## Conferindo
A%*%A_ginv%*%A## [,1] [,2] [,3]
## [1,] 2 2.00e+00 3
## [2,] 1 2.22e-16 1
## [3,] 3 2.00e+00 42.2.4 Matrizes positivas definidas
No decorrer deste livro vamos encontrar frequentemente as chamadas somas de quadrados. Nós já discutimos sobre soma de quadrados nas seções 1.2.5 e 1.2.9 quando encontramos a média e os coeficientes de regressão do modelo de regressão linear simples. De forma matricial, a soma de quadrados pode ser reescritas usando formas quadráticas.
Considere uma matriz \(\mathbf{A}\) simétrica e \(\mathbf{y}\) um vetor, o produto
\[\mathbf{y}^{\top} \mathbf{A} \mathbf{y} = \sum_{i} a_{ij} y_i^2 + \sum_{i \neq j} a_{ij} y_i y_j,\] é chamado de forma quadrática.
Para uma matriz \(\mathbf{y}\) de dimensão \(n \times 1\), ou seja, um vetor coluna o produto matricial \(\mathbf{y}^{\top}\mathbf{I} \mathbf{y} = y_1^2 + y_2^2 + \ldots, y_n^2\). Assim, \(\mathbf{y}^{\top} \mathbf{y}\) é a soma de quadrados dos elementos do vetor \(\mathbf{y}\). A raiz quadrado da soma de quadrados é a distância do ponto \(\mathbf{y}\) até a origem, também chamada de comprimento de \(\mathbf{y}\). As somas de quadrados permanecem positivas, ou ao menos não negativas para todos os valores de \(\mathbf{y}\) exceto no caso em que \(\mathbf{y} = 0\).
Definição 2.7 Sendo \(\mathbf{A}\) uma matriz simétrica com a propriedade \(\mathbf{y}^{\top} \mathbf{A} \mathbf{y} > 0\) para todos os possíveis \(\mathbf{y}\) exceto para quando \(\mathbf{y} = 0\), então a forma quadrática \(\mathbf{y}^{\top} \mathbf{A} \mathbf{y}\) é chamada positiva definida, e \(\mathbf{A}\) é dita ser uma matriz positiva definida. No caso de \(\mathbf{y}^{\top} \mathbf{A} \mathbf{y} \geq 0\) e existir ao menos um \(\mathbf{y} \neq 0\) tal que \(\mathbf{y}^{\top} \mathbf{A} \mathbf{y} = 0\), então \(\mathbf{y}^{\top} \mathbf{A} \mathbf{y}\) é dita ser positiva semi-definida e \(\mathbf{A}\) é uma matriz positiva semi-definida.
Para ilustração considere a seguinte matriz
\[ \mathbf{A} = \begin{pmatrix} 2 & -1\\ -1 & 3 \end{pmatrix}. \] A forma quadrática associada é dada por
\[ \mathbf{y}^{\top} \mathbf{A} \mathbf{y} = \begin{pmatrix} y_1 & y_2 \end{pmatrix} \begin{pmatrix} 2 & -1\\ -1 & 3 \end{pmatrix} \begin{pmatrix} y_1 \\ y_2 \end{pmatrix} = 2 y_1^2 - 2 y_1 y_2 + 3 y_2^2, \] que é claramente positiva, desde que \(y_1\) e \(y_2\) sejam diferentes de zero. Algumas propriedades interessantes sobre matrizes positivas definidas ou semi-definidas são:
- Se \(\mathbf{A}\) é positiva definida, então todos os valores da diagonal de \(\mathbf{A}\) são positivos.
- Se \(\mathbf{A}\) é positiva semi-definida, então os elementos da diagonal de \(\mathbf{A}\) são maiores ou iguais a zero.
- Sendo \(\mathbf{P}\) uma matriz não-singular e \(\mathbf{A}\) uma matriz positiva definida, o produto \(\mathbf{P}^{\top} \mathbf{A} \mathbf{P}\) é uma matriz positiva definida.
- Sendo \(\mathbf{P}\) uma matriz não-singular e \(\mathbf{A}\) uma matriz positiva semi-definida, o produto \(\mathbf{P}^{\top} \mathbf{A} \mathbf{P}\) é uma matriz positiva semi-definida.
- Uma matriz positiva definida é não-singular.
Matrizes positivas definidas são fundamentais em estatística pois representam a matriz de variância e covariância de vetores aleatórios.
2.2.5 Determinante e traço de uma matriz
Definição 2.8 O determinante de uma matriz \(\mathbf{A}\) é o escalar \[|\mathbf{A}| = \sum_j (-1)^k a_{1 j_1} a_{2 j_2}, \ldots, a_{n j_n},\] onde a soma é realizada para todas as \(n!\) permutações de grau \(n\), e \(k\) é o número de mudanças necessárias para que os segundos subscritos sejam colocados na ordem \(1,2, \ldots, n.\)
Em termos de notação vamos usar \(|\mathbf{A}|\) ou \(\det{(A)}\). A Definição 2.8 é difícil de entender e pouco útil para avaliar determinantes de matrizes de grande dimensão. Entretanto, nestes casos temos sempre que recorrer a métodos computacionais. Para matrizes pequenas é fácil obter o determinante. Vamos fazer um exemplo simples com uma matriz \(2 \times 2\) apenas como ilustração.
Considere a matriz
\[ \mathbf{A} = \begin{pmatrix} 3 & -2\\ -2 & 4 \end{pmatrix}. \]
Usando a definição precisamos encontrar todas as \(n!\) combinações de produtos contendo um elemento de cada linha e coluna. Neste caso \(n = 2\) e \(n! = 2 \cdot 1 = 2\). Teremos apenas duas combinações. Na primeira combinação vamos pegar o elemento \(a_{11} = 3\) e multiplicar pelo elemento \(a_{22} = 4\). Neste caso os índices de coluna já estão na ordem crescente, então o número de trocas foi \(0\). O segundo termo será o elemento \(a_{12} = -2\) multiplicado pelo elemento \(a_{21} = -2\). Neste caso, para que os índices de coluna fiquem em ordem crescente, precisamos fazer uma mudança, então \(k = 1\).
\[ |\mathbf{A}| = (-1)^0 a_{11} a_{22} + (-1)^1 a_{12} a_{21} = 1 \cdot (3 \cdot 4) - (-2 \cdot -2) = 12 - 4 = 8. \]
Em R o determinante de uma matriz pode ser obtido por meio da função determinant(), conforme ilustrado no Código 2.12.
Código 2.12 Determinante de uma matriz.
A <- matrix(c(3,-2,-2,4),2,2)
determinant(A, logarithm = FALSE)## $modulus
## [1] 8
## attr(,"logarithm")
## [1] FALSE
##
## $sign
## [1] 1
##
## attr(,"class")
## [1] "det"É muito comum precisarmos do logaritmo do determinante, assim a função determinant() traz essa opção como default. Por isso, para obter o determinante de \(\mathbf{A}\) precisamos incluir o argumento logarithm = FALSE. Caso contrário o determinante seria obtido em escala logarítmica.
determinant(A, logarithm = TRUE)## $modulus
## [1] 2.08
## attr(,"logarithm")
## [1] TRUE
##
## $sign
## [1] 1
##
## attr(,"class")
## [1] "det"Alguns aspectos interessantes sobre determinantes são:
- Se \(\mathbf{A}\) é singular, \(|\mathbf{A}| = 0\).
- Se \(\mathbf{A}\) é não singular, \(|\mathbf{A}| \neq 0\).
- Se \(\mathbf{A}\) é positiva definida, \(|\mathbf{A}| > 0\).
- \(|\mathbf{A}^{\top}| = |\mathbf{A}|\).
- Se \(\mathbf{A}\) é não singular, \(|\mathbf{A}^{-1}| = \frac{1}{|\mathbf{A}|}\).
Definição 2.9 O traço de uma matriz \(\mathbf{A}\) \(n \times n\) é um escalar definido como a soma dos elementos da diagonal, \(\mathrm{tr}(\mathbf{A}) = \sum_{i=1}^n a_{ii}\).
Algumas propriedades do traço:
- Se \(\mathbf{A}\) e \(\mathbf{B}\) são \(n \times n\), então \[\mathrm{tr}(\mathbf{A} + \mathbf{B}) = \mathrm{tr}(\mathbf{A}) + \mathrm{tr}(\mathbf{B}).\]
- Se \(\mathbf{A}\) é \(n \times p\) e \(\mathbf{B}\) e \(p \times n\), então \[\mathrm{tr}(\mathbf{AB}) = \mathrm{tr}(\mathbf{BA}).\]
Em R não temos uma função explícita para a obtenção do traço devido a sua simplicidade. Assim, podemos obter o traço simplesmente acessando os elementos da diagonal da matriz com a função diag() e somar com a função sum(), conforme ilustrado no Código 2.13.
A <- matrix(c(3,-2,-2,4),2,2)
sum(diag(A))## [1] 72.2.6 Cálculo vetorial e matricial
No Capítulo \(1\) vimos como obter a derivada de funções com até duas variáveis independentes. Usando as ferramentas de Cálculo vetorial e matricial podemos obter derivadas de funções com um número arbitrário de variáveis independentes. Seja \(y = f(\mathbf{x})\) uma função das variáveis \(x_1, x_2, \ldots, x_p\) e \(\frac{\partial y}{\partial x_1}, \frac{\partial y}{\partial x_2}, \ldots, \frac{\partial y}{\partial x_p}\) as respectivas derivadas parciais. Assim,
\[ \frac{\partial y}{\partial \mathbf{x}} = \begin{pmatrix} \frac{\partial y}{\partial x_1}\\ \frac{\partial y}{\partial x_2}\\ \vdots\\ \frac{\partial y}{\partial x_p} \end{pmatrix}. \]
Basicamente, a ideia é derivar em cada uma das variáveis independentes e arranjar as derivadas parciais em um vetor de tamanho adequado. Usando esta ideia simples é possível calcular a derivada de funções mais complicadas. Vejamos algumas derivadas vetoriais e matriciais úteis em ciência de dados.
Sendo \(\mathbf{a}^{\top} = (a_1, a_2, \ldots, a_p)\) um vetor de constantes e \(\mathbf{A}\) uma matriz simétrica de constantes.
- Seja \(y = \mathbf{a}^{\top} \mathbf{x} = \mathbf{x}^{\top} \mathbf{a}\). Então,
\[\frac{\partial y}{\partial \mathbf{x}} = \frac{\partial (\mathbf{x}^{\top} \mathbf{a})}{\partial \mathbf{x}} = \mathbf{a}.\]
- Seja \(y = \mathbf{x}^{\top} \mathbf{A} \mathbf{x}\). Então,
\[\frac{\partial y}{\partial \mathbf{x}} = \frac{\partial (\mathbf{x}^{\top} \mathbf{A} \mathbf{x}) }{\partial \mathbf{x}} = 2 \mathbf{A} \mathbf{x}.\]
De forma similar, se \(y = f(\mathbf{X})\) onde \(\mathbf{X}\) é uma matriz \(p \times p\). As derivadas parciais de \(y\) em relação a cada \(x_{ij}\) são organizadas em uma matriz.
\[ \frac{\partial y}{\partial \mathbf{X}} = \begin{pmatrix} \frac{\partial y}{\partial x_{11}} & \ldots & \frac{\partial y}{\partial x_{1p}}\\ \vdots & \ddots & \vdots\\ \frac{\partial y}{\partial x_{p1}} & \ldots & \frac{\partial y}{\partial x_{pp}} \end{pmatrix}. \]
Algumas derivadas importantes envolvendo matrizes são apresentadas abaixo.
- Seja \(y = \mathrm{tr}(\mathbf{X}\mathbf{A})\) sendo \(\mathbf{X}\) \(p \times p\) e definida positiva e \(\mathbf{A}\) \(p \times p\) constantes. Então,
\[ \frac{\partial y}{\partial \mathbf{X}} = \frac{\partial \mathrm{tr}(\mathbf{X}\mathbf{A})}{\partial \mathbf{X}} = \mathbf{A} + \mathbf{A}^{\top} - \mathrm{diag}(\mathbf{A}). \]
- Sendo \(\mathbf{A}\) não singular com derivadas \(\frac{\partial \mathbf{A}}{\partial x}\). Então,
\[ \frac{\partial \mathbf{A}^{-1}}{\partial x} = - \mathbf{A}^{-1} \frac{\partial \mathbf{A}}{\partial x} \mathbf{A}^{-1}. \]
- Sendo \(\mathbf{A}\) \(n \times n\) positiva definida. Então,
\[ \frac{\partial \log |\mathbf{A}|}{\partial x} = \mathrm{tr} \left( \mathbf{A}^{-1} \frac{\partial \mathbf{A}}{\partial x} \right). \]
2.2.7 Regressão linear múltipla
Na seção 1.2.9 construímos o modelo de regressão linear simples, onde apenas uma covariável \(x\) descreve o comportamento da variável dependente \(y\), por meio de uma reta, ou seja,
\[ y_i = \beta_0 + \beta_1 x_i + \epsilon_i.\]
No modelo de regressão linear múltipla estendemos este modelo para levar em consideração um número arbitrário \(p\) de covariáveis \(x_{ip}\). Nesta notação \(x_{ip}\) é o valor da \(p-\)ésima covariável associada a observação \(i\) para \(i = 1, \ldots, n\), sendo \(n\) o número de observações. Note que a primeira covariável é assumida como \(1\) para representar o intercepto.
O modelo de regressão linear múltipla é então escrito como
\[ y_i = \beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \ldots + \beta_p x_{ip} + \epsilon_i. \] Podemos escrever o modelo para cada uma das \(n\) observações, como segue
\[ \begin{matrix} y_1 = \beta_0 + \beta_1 x_{11} + \beta_2 x_{12} + \ldots \beta_{p} x_{1p} + \epsilon_1 \\ y_2 = \beta_0 + \beta_1 x_{21} + \beta_2 x_{22} + \ldots \beta_{p} x_{2p} + \epsilon_2\\ \vdots \\ y_n = \beta_0 + \beta_1 x_{n1} + \beta_2 x_{n2} + \ldots \beta_{p} x_{np} + \epsilon_p.\\ \end{matrix} \] Agora organizamos os termos em formato matricial
\[ \underset{n\times 1}{\begin{bmatrix} y_1\\ y_2\\ \vdots \\ y_n \end{bmatrix}} = \underset{n\times p}{\begin{bmatrix} 1 & x_{11} & \ldots & x_{p1} \\ 1 & x_{12} & \ldots & x_{p1} \\ \vdots & \vdots & \ddots & \vdots \\ 1& x_{1n} & \ldots & x_{pn} \end{bmatrix} } \underset{p \times 1}{ \begin{bmatrix} \beta_0 \\ \vdots \\ \beta_p \end{bmatrix} } + \underset{n\times 1}{\begin{bmatrix} \epsilon_1\\ \epsilon_2\\ \vdots \\ \epsilon_n \end{bmatrix}} \]
Por fim, usamos uma notação mais compacta para representar o modelo
\[ \underset{n \times 1}{\mathbf{y}} = \underset{n \times p }{\mathbf{X}} \underset{p\times 1}{\boldsymbol{\beta}} + \underset{n \times 1}{\mathbf{\epsilon}}. \]
Note como todas as multiplicações envolvidas no modelo são compatíveis respeitando as regras dos produtos de matrizes.
Nosso objetivo é encontrar o vetor \(\boldsymbol{\hat{\beta}}\), tal que
\[ SQ(\boldsymbol{\beta}) = (\mathbf{y} - \mathbf{X}\boldsymbol{\beta})^{\top} (\mathbf{y} - \mathbf{X}\boldsymbol{\beta}), \] seja a menor possível.
Esse processo é o que chamamos de estimação dos parâmetros de regressão ou de treinamento do modelo, a segunda nomenclatura é comum na literatura de aprendizado de máquina. Note que novamente temos um processo de minimização, porém agora de uma função com muitas variáveis independentes. Usando as ferramentas de Álgebra Linear podemos facilmente proceder com esse problema de minimização.
O primeiro passo é derivar a soma de quadrados em \(\boldsymbol{\beta}\), usando Cálculo vetorial (ver Seção 2.2.6).
Derivando em \(\boldsymbol{\beta}\), temos \[\begin{eqnarray*} \frac{\partial SQ(\boldsymbol{\beta})}{\partial \boldsymbol{\beta}} &=& \frac{\partial}{\partial \boldsymbol{\beta}} (\mathbf{y} - \mathbf{X}\boldsymbol{\beta})^{\top} (\mathbf{y} - \mathbf{X}\boldsymbol{\beta}) \\ &=& \frac{\partial}{\partial \boldsymbol{\beta}} \left ( (\mathbf{y} - \mathbf{X}\boldsymbol{\beta})^{\top} \right ) (\mathbf{y} - \mathbf{X}\boldsymbol{\beta}) + (\mathbf{y} - \mathbf{X}\boldsymbol{\beta})^{\top} \frac{\partial}{\partial \boldsymbol{\beta}} (\mathbf{y} - \mathbf{X}\boldsymbol{\beta}) \\ &=& -\mathbf{X}^{\top}(\mathbf{y} - \mathbf{X}\boldsymbol{\beta}) + (\mathbf{y} - \mathbf{X}\boldsymbol{\beta})^{\top} (-\mathbf{X}) \\ &=& -2\mathbf{X}^{\top}(\mathbf{y} - \mathbf{X}\boldsymbol{\beta}). \end{eqnarray*}\]
O segundo passo é resolver o sistema de equações lineares resultantes
\[\begin{eqnarray} \mathbf{X}^{\top}(\mathbf{y} - \mathbf{X}\boldsymbol{\hat{\beta}}) &=& \boldsymbol{0} \\ \mathbf{X}^{\top}\mathbf{y} - \mathbf{X}^{\top}\mathbf{X}\boldsymbol{\hat{\beta}} &=& 0 \\ \mathbf{X}^{\top}\mathbf{X}\boldsymbol{\hat{\beta}} &=& \mathbf{X}^{\top}\mathbf{y} \tag{2.2} \\ \boldsymbol{\hat{\beta}} &=& (\mathbf{X}^{\top}\mathbf{X})^{-1}\mathbf{X}^{\top}\mathbf{y}. \tag{2.3} \end{eqnarray}\]
Note que a Equação (2.2) foi multiplicada em ambos os lados por \((\mathbf{X}^{\top}\mathbf{X})^{-1}\) para encontrar (2.3).
Essa operação corresponde a resolver o sistema de equações lineares.
Nós vimos na Seção 2.2.3 como obter a inversa de uma matriz usando o R.
Assim, estamos aptos a implementar tais operações em R.
Para exemplificar a implementação do modelo de regressão linear múltipla, vamos usar um conjunto de dados muito famoso sobre o preço de imóveis na cidade de Boston. O conjunto de dados está disponível no pacote MASS e contém além da variável resposta \(13\) covariáveis e \(506\) observações. As primeiras seis observações do conjunto de dados são apresentadas abaixo.
require(MASS)
data(Boston)
head(Boston)## crim zn indus chas nox rm age dis rad tax ptratio black
## 1 0.00632 18 2.31 0 0.538 6.58 65.2 4.09 1 296 15.3 397
## 2 0.02731 0 7.07 0 0.469 6.42 78.9 4.97 2 242 17.8 397
## 3 0.02729 0 7.07 0 0.469 7.18 61.1 4.97 2 242 17.8 393
## 4 0.03237 0 2.18 0 0.458 7.00 45.8 6.06 3 222 18.7 395
## 5 0.06905 0 2.18 0 0.458 7.15 54.2 6.06 3 222 18.7 397
## 6 0.02985 0 2.18 0 0.458 6.43 58.7 6.06 3 222 18.7 394
## lstat medv
## 1 4.98 24.0
## 2 9.14 21.6
## 3 4.03 34.7
## 4 2.94 33.4
## 5 5.33 36.2
## 6 5.21 28.7As covariáveis disponíveis são
- crim: taxa de crimes per capita.
- zn: proporção de terrenos residenciais zoneados para lotes com mais de 25.000 pés quadrados.
- indus: proporção de acres de negócios não varejistas por cidade.
- chas: variável dummy de Charles River (1 se a área limita o rio; 0 caso contrário).
- nox: concentração de óxido de nitrogênio (parte por 10 milhões).
- rm: número médio de quartos por habitação.
- age: proporção de unidades ocupadas pelo proprietário construídas antes de 1940.
- dis: média ponderada das distâncias a cinco centros de empregos de Boston.
- rad: índice de acessibilidade às rodovias radiais.
- tax: taxa de imposto sobre a propriedade de valor total por $10.000.
- ptratio: proporção aluno-professor por cidade.
- black: \(1000 (Bk - 0,63)^2\) onde \(Bk\) é a proporção de negros por cidade.
- lstat: Porcentagem da população em pobreza.
A variável resposta é o valor mediano das casas ocupadas pelos proprietários em \(\$1000\), codificada como medv. O primeiro passo para implementar o modelo de regressão linear múltipla para este problema é montar a matriz \(\mathbf{X}\), também chamada de matriz de delineamento. Ela vai conter os valores de todas as covariáveis de interesse. Em R podemos usar a função model.matrix() para construir tal matriz. Para este exemplo, vamos usar apenas as primeiras cinco covariáveis.
X <- model.matrix(~ crim + zn + indus + chas + nox, data = Boston)
head(X)## (Intercept) crim zn indus chas nox
## 1 1 0.00632 18 2.31 0 0.538
## 2 1 0.02731 0 7.07 0 0.469
## 3 1 0.02729 0 7.07 0 0.469
## 4 1 0.03237 0 2.18 0 0.458
## 5 1 0.06905 0 2.18 0 0.458
## 6 1 0.02985 0 2.18 0 0.458Note que a função model.matrix() automaticamente inclui uma coluna de \(1\)’s para representar o intercepto. O vetor \(y\) neste caso é a coluna medv.
y <- Boston$medvPor fim, implementamos a Equação (2.3) de duas formas distintas. Convido o leitor a tentar entender qual a diferença computacional entre elas. Tal diferença ficará clara quando discutirmos algoritmos para a solução de sistemas de equações lineares e obtenção da matriz inversa.
# Forma ingênua
solve(t(X)%*%X)%*%t(X)%*%y## [,1]
## (Intercept) 29.4899
## crim -0.2185
## zn 0.0551
## indus -0.3835
## chas 7.0262
## nox -5.4247# Forma eficiente
solve(t(X)%*%X, t(X)%*%y)## [,1]
## (Intercept) 29.4899
## crim -0.2185
## zn 0.0551
## indus -0.3835
## chas 7.0262
## nox -5.4247Podemos usar a função lm() para conferir a nossa implementação.
coef(lm(medv ~ crim + zn + indus + chas + nox, data = Boston))## (Intercept) crim zn indus chas
## 29.4899 -0.2185 0.0551 -0.3835 7.0262
## nox
## -5.4247Os resultados são idênticos. Podemos usar o modelo para predizer o valor de um imóvel dado os valores de suas covariáveis. Basicamente, tudo o que foi discutido no caso do modelo de regressão linear simples se adapta naturalmente para o modelo de regressão linear múltipla.
2.3 Sistemas de equações lineares
Um sistema de equações de duas incógnitas pode ser escrito da seguinte forma
\[\begin{eqnarray*} f_1(x_1,x_2) &=& c_1 \\ f_2(x_1,x_2) &=& c_2. \end{eqnarray*}\]
De forma geral, desejamos encontrar a solução numérica do sistema que consiste em encontrar valores \(\hat{x}_1\) e \(\hat{x}_2\) que satisfaçam o sistema de equações, ou seja, que ao aplicar as funções \(f_1\) e \(f_2\) simultâneamente em \(\hat{x}_1\) e \(\hat{x}_2\), resultem em \(c_1\) e \(c_2\). Em termos de notação, desejamos que \(f_1(x_1 = \hat{x}_1, x_2 = \hat{x}_2) = c_1\) e \(f_2(x_1 = \hat{x}_1, x_2 = \hat{x}_2) = c_2\), simultâneamente.
A ideia é facilmente estendida para um sistema com \(n\) equações com \(p\) incógnitas
\[\begin{eqnarray*} f_1(x_1,\ldots, x_p) &=& c_1 \\ &\vdots& \\ f_n(x_1,\ldots, x_p) &=& c_p. \end{eqnarray*}\]
Um sistema de equações é dito ser linear se as funções \(f_1, f_2, \ldots, f_n\) são lineares e não-linear caso contrário. Nesta seção, nós vamos lidar apenas com sistemas lineares. Na Seção 3.1, nós vamos apresentar alguns métodos numéricos para sistemas de equações não-lineares.
Quando as \(n\) funções são lineares o sistema pode escrito da seguinte forma
\[\begin{eqnarray*} a_{11} x_1 + a_{12} x_2 + \ldots a_{1p} x_p &=& c_1 \\ a_{21} x_1 + a_{22} x_2 + \ldots a_{2p} x_p &=& c_2 \\ &\vdots& \\ a_{n1} x_1 + a_{n2} x_2 + \ldots a_{np} x_p &=& c_p. \\ \end{eqnarray*}\]
É mais fácil e compacto usar a notação matricial, neste caso o sistema toma a seguinte forma
\[\mathbf{A} \mathbf{x} = \mathbf{c},\] onde \(\mathbf{A}\) é uma matriz \(n \times p\), \(\mathbf{x}\) é um vetor \(p \times 1\), e \(\mathbf{c}\) é um vetor \(n \times 1\). Quando \(n = p\) e \(\mathbf{A}\) é não-singular é possível mostrar que o sistema tem uma solução única dada por \(\mathbf{\hat{x}} = \mathbf{A}^{-1} \mathbf{c}\). No caso em que \(n > p\), \(\mathbf{A}\) terá mais linhas do que colunas e o sistema tipicamente não terá solução. Por fim, se \(n < p\), \(\mathbf{A}\) terá menos linhas do que colunas e o sistema tipicamente terá um número infinito de soluções. Neste livro vamos considerar apenas o caso em que o sistema tem uma única solução, ou seja, \(n = p\) e \(\mathbf{A}\) é não-singular (admite inversa).
Como um exemplo ilustrativo, considere o seguinte sistema de duas equações
\[\begin{eqnarray} 7 x_1 + 3x_2 &=& 45 \tag{2.4}\\ 4 x_1 + 5x_2 &=& 29. \tag{2.5} \end{eqnarray}\]
A solução deste sistema consiste em encontrar valores \(\hat{x}_1\) e \(\hat{x}_2\), que satisfaçam as Equações (2.4) e (2.5). Para começar vamos isolar o \(x_1\) na Equação (2.4).
\[\begin{eqnarray} 7x_1 + 3 x_2 &=& 45 \\ 7x_1 &=& 45 - 3x_2 \\ x_1 &=& \frac{45 - 3x_2}{7}. \tag{2.6} \end{eqnarray}\]
Agora substituímos a Equação (2.6) na Equação (2.5)
\[\begin{eqnarray} 4x_1 + 5x_2 &=& 29 \\ 4 \left( \frac{45 - 3x_2}{7} \right ) + 5x_2 &=& 29 \\ \frac{180 - 12 x_2}{7} + 5x_2 &=& 29 \\ \frac{180}{7} - \frac{12}{7} x_2 + 5 x_2 &=& 29 \\ 5 x_2 - \frac{12}{7} x_2 &=& 29 - \frac{180}{7} \\ \frac{35x_2 - 12 x_2}{7} &=& 29 - \frac{180}{7} \\ 35x_2 - 12 x_2 &=& 7 \left(29 - \frac{180}{7} \right ) \\ 23 x_2 &=& 203 - 180 \\ 23 x_2 &=& 23 \\ \hat{x}_2 &=& \frac{23}{23} = 1. \tag{2.7} \end{eqnarray}\]
Por fim, substituindo (2.7) em (2.6) obtemos \(\hat{x}_1\)
\[\begin{eqnarray} \hat{x}_1 &=& \frac{45 - 3 \cdot 1}{7} \\ \hat{x}_1 &=& 6. \end{eqnarray}\]
Portanto, a solução é \(\hat{x}_1 = 6\) e \(\hat{x}_2 = 1\).
Importante ressaltar que apesar de matematicamente simples o procedimento utilizado é bastante trabalhoso e impraticável em sistemas maiores, tais como os que vamos encontrar na prática em ciência de dados. Assim, fica claro que precisamos de algoritmos genéricos que possam ser adaptáveis para sistemas de qualquer tamanho.
Para resolver o sistema nós realizamos uma série de manipulações com as linhas do sistema até encontrar a solução. Estas operações são chamadas de operações com linhas. Sem qualquer alteração na relação linear é possível
- Trocar a posição de linhas, por exemplo
\[\begin{eqnarray*} 4 x_1 + 5 x_2 &=& 29 \\ 7 x_1 + 3 x_2 &=& 45. \end{eqnarray*}\]
- Multiplicar qualquer linha por uma constante, aqui \(4 x_1 + 5 x_2\) por \(\frac{1}{4}\), obtendo
\[\begin{eqnarray} x_1 + \frac{5}{4} x_2 &=& \frac{29}{4} \tag{2.8}\\ 7 x_1 + 3 x_2 &=& 45. \tag{2.9} \end{eqnarray}\]
\[\begin{eqnarray*} x_1 + \frac{5}{4} x_2 &=& \frac{29}{4} \\ 0 x_1 + \left(\frac{35}{4} - 3\right) x_2 &=& \frac{203}{4} - 45. \end{eqnarray*}\]
Fazendo as contas, tem-se \[\begin{eqnarray*} 0 x_1 + \frac{23}{4} x_2 &=& \frac{23}{4} \\ x_2 &=& 1. \end{eqnarray*}\]
Baseado em operações com linhas podemos estabelecer diferentes estratégias para transformar um sistema linear qualquer em um sistema equivalente, porém de fácil solução. Esta é a ideia subjacente a uma classe de métodos chamados de métodos diretos para a solução de sistemas lineares. Por outro lado, existem os chamados métodos iterativos cuja ideia principal é a partir de uma solução inicial ir melhorando esta solução até que um certo critério de parada seja satisfeito. Na subseção 2.3.1 nós vamos apresentar alguns dos métodos diretos mais famosos, enquanto que na subseção 2.3.2 serão apresentados alguns métodos iterativos.
2.3.1 Métodos diretos
Nos métodos diretos o sistema linear é manipulado usando operações com linhas até se transformar em um sistema equivalente de fácil solução. Por exemplo, o sistema pode ser manipulado até se tornar um sistema triangular superior
\[ \begin{bmatrix} a_{11} & a_{12} & a_{13} & a_{14}\\ 0 & a_{22} & a_{23} & a_{24}\\ 0 & 0 & a_{33} & a_{34} \\ 0 & 0 & 0 & a_{44} \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \\ x_3 \\ x_4 \end{bmatrix} = \begin{bmatrix} b_1 \\ b_2 \\ b_3 \\ b_4 \end{bmatrix}. \] Que é facilmente resolvido utilizando substituição regressiva
\[ x_n = \frac{b_n}{a_{nn}} \quad x_i = \frac{b_i - \sum_{j = i+1 }^{j=n} a_{ij} x_j}{a_{ii}}, \quad i = n-1, n-2,\ldots, 1. \]
Outra opção é manipular o sistema até obter um sistema triangular inferior, ou seja,
\[ \begin{bmatrix} a_{11} & 0 & 0 & 0 \\ a_{21} & a_{22} & 0 & 0 \\ a_{31} & a_{32} & a_{33} & 0 \\ a_{41} & a_{42} & a_{43} & a_{44} \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \\ x_3 \\ x_4 \end{bmatrix} = \begin{bmatrix} b_1 \\ b_2 \\ b_3 \\ b_4 \end{bmatrix}. \]
Neste caso usamos a substituição progressiva para obter a solução
\[ x_1 = \frac{b_1}{a_{11}} \quad x_i = \frac{b_i - \sum_{j = i}^{j=i-1} a_{ij} x_j}{a_{ii}}, \quad i = 2, 3,\ldots, n. \]
Por fim, o mais óbvio porém mais caro computacionalmente é tornar o sistema diagonal
\[ \begin{bmatrix} a_{11} & 0 & 0 & 0 \\ 0 & a_{22} & 0 & 0 \\ 0 & 0 & a_{33} & 0 \\ 0 & 0 & 0 & a_{44} \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \\ x_3 \\ x_4 \end{bmatrix} = \begin{bmatrix} b_1 \\ b_2 \\ b_3 \\ b_4 \end{bmatrix}. \]
Um dos métodos diretos mais utilizados é o método de Eliminação de Gauss. Este método consiste em usar operações com linhas para obter um sistema triangular superior e depois usar substituição regressiva para obter a solução. Vamos fazer um exemplo para ilustrar como este método funciona.
Example 2.1 Resolva o seguinte sistema usando o método de eliminação de Gauss.
\[ \begin{bmatrix} 3 & 2 & 6 \\ 2 & 4 & 3 \\ 5 & 3 & 4 \\ \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \\ x_3 \end{bmatrix} = \begin{bmatrix} 24 \\ 23 \\ 33 \end{bmatrix} \]
O algoritmo pode ser descrito passo-a-passo
- Passo 1: Encontrar o primeiro pivô e eliminar os elementos abaixo dele usando operações com linhas.
\[ \begin{bmatrix} [3] & 2 & 6 \\ 2 - \frac{2}{3}3 & 4 - \frac{2}{3}2 & 3 - \frac{2}{3}6 \\ 5 - \frac{5}{3}3 & 3 - \frac{5}{3}2 & 4 - \frac{5}{3}6 \\ \end{bmatrix} \begin{bmatrix} 24 \\ 23 - \frac{2}{3}24\\ 33 - \frac{5}{3}24 \end{bmatrix} \to \begin{bmatrix} [3] & 2 & 6 \\ 0 & \frac{8}{3} & -1 \\ 0 & -\frac{1}{3} & -6 \\ \end{bmatrix} \begin{bmatrix} 24 \\ 7 \\ -7 \end{bmatrix}. \]
Neste caso o primeiro pivô é o número \(3\) (note entre colchetes) e precisamos tornar os elementos abaixo dele zero. Para isto multiplicamos a primeira linha por \(\frac{2}{3}\), ou seja, o valor da posição a ser zerada dividida pelo valor do pivô. E depois subtraímos da segunda linha. Importante é que a operação deve ser feita em todos os elementos da linha para não modificar o sistema. A mesma ideia é usada para zerar o primeiro elemento da terceira linha.
- Passo 2: Encontrar o segundo pivô e eliminar os elementos abaixo dele usando operações com linhas.
\[ \begin{bmatrix} 3 & 2 & 6 \\ 0 & [\frac{8}{3}] & -1 \\ 0 & -\frac{1}{3} - \left (-\frac{3}{24} \right ) \left (\frac{8}{3}\right ) & -6 - (-\frac{3}{24})(-1) \\ \end{bmatrix} \begin{bmatrix} 24 \\ 7 \\ -7 - (- \frac{3}{24})(7) \end{bmatrix} \to \\ \begin{bmatrix} 3 & 2 & 6 \\ 0 & [\frac{8}{3}] & -1 \\ 0 & 0 & -\frac{147}{24} \\ \end{bmatrix} \begin{bmatrix} 24 \\ 7 \\ -\frac{147}{24} \end{bmatrix} \]
Neste caso o segundo pivô é \(\frac{8}{3}\) e multiplicamos a segunda linha pelo pivô e subtraímos da terceira para zerar o elemento da segunda linha da terceira coluna. Com isso chegamos a um sistema triangular superior.
- Passo 3: Substituição regressiva.
\[\begin{eqnarray*} \hat{x}_3 &=& \frac{b_3}{a_{33}} \\ \hat{x}_3 &=& \frac{-147/24}{-147/24} = 1. \\ \hat{x}_2 &=& \frac{b_2 - a_{23}x_3}{a_{22}} \\ \hat{x}_2 &=& \frac{7 - (-1) \cdot 1}{8/3} = 3. \\ \hat{x}_1 &=& \frac{(b_1 - (a_{12}x_2 + a_{13}x_3) }{a_{11}} \\ \hat{x}_1 &=& \frac{24 - (2 \cdot 3 + 6 \cdot 1)}{3} = 4. \end{eqnarray*}\]
Portanto, a solução do sistema é \(\hat{x}_1 = 4\), \(\hat{x}_2 = 3\) e \(\hat{x}_3 = 1\).
Estender o procedimento para um sistema com \(n\) equações é trivial. Basta transformar o sistema em triangular superior usando operações com linhas e resolver o novo sistema usando substituição regressiva.
Para ilustrar o procedimento de eliminação de Gauss o Código 2.14 implementa a estratégia para tornar um sistema triangular superior.
gauss <- function(A, b) {
# Sistema aumentado
Ae <- cbind(A, b)
rownames(Ae) <- paste0("x", 1:length(b))
n_row <- nrow(Ae)
n_col <- ncol(Ae)
# Matriz para receber os resultados
SOL <- matrix(NA, n_row, n_col)
SOL[1,] <- Ae[1,]
pivo <- matrix(0, n_col, n_row)
for(j in 1:c(n_row-1)) {
for(i in c(j+1):c(n_row)) {
pivo[i,j] <- Ae[i,j]/SOL[j,j]
SOL[i,] <- Ae[i,] - pivo[i,j]*SOL[j,]
Ae[i,] <- SOL[i,]
}
}
return(SOL)
}Precisamos também de uma função genérica para o passo de substituição regressiva, conforme apresentado no Código 2.15.
sub_reg <- function(SOL) {
n_row <- nrow(SOL)
n_col <- ncol(SOL)
A <- SOL[1:n_row,1:n_row]
b <- SOL[,n_col]
n <- length(b)
x <- c()
x[n] <- b[n]/A[n,n]
for(i in (n-1):1) {
x[i] <- (b[i] - sum(A[i,c(i+1):n]*x[c(i+1):n] ))/A[i,i]
}
return(x)
}Por fim, vamos resolver o sistema apresentado no Exemplo 2.1 utilizando as funções criadas.
# Entrando com o sistema na forma matricial
A <- matrix(c(3,2,5,2,4,3,6,3,4),3,3)
b <- c(24,23,33)
# Passo 1: Triangularização
S <- gauss(A, b)
S## [,1] [,2] [,3] [,4]
## [1,] 3 2.00e+00 6.00 24.00
## [2,] 0 2.67e+00 -1.00 7.00
## [3,] 0 -5.55e-17 -6.12 -6.12# Passo 2: Substituição regressiva
sol = sub_reg(SOL = S)
sol## [1] 4 3 1# Verificando a solução
A%*%sol## [,1]
## [1,] 24
## [2,] 23
## [3,] 33O método de eliminação de Gauss pode apresentar dois problemas:
o elemento pivô é zero e neste caso não podemos dividir por zero e
o elemento pivô é pequeno em magnitude em relação aos demais. Isso pode levar a problemas numéricos por fazer uma divisão por um número muito próximo de zero.
Para resolver estes problemas é usual combinar o método de eliminação de Gauss com o procedimento de pivotação. O procedimento de pivotação nada mais é do que trocar a ordem das linhas para evitar pivôs iguais a zero ou muito pequenos. Além disso, a pivotação também pode ajudar a diminuir o número de operações para resolver o sistema.
Se durante o procedimento uma equação pivô tiver um elemento nulo e o sistema tiver solução, uma equação com um elemento pivô diferente de zero sempre existirá. Uma recomendação é ordenar as linhas para que o maior valor seja o primeiro pivô.
\[\begin{eqnarray*} 0x_1 + 2x_2 + 3x_2 &=& 46\\ 4 x_1 -3x_2 + 2x_3 &=& 16 \\ 2x_1 + 4x_2 -3x_3 &=& 12 \end{eqnarray*}\]
Note que neste caso o primeiro pivô é zero o procedimento não pode ser iniciado da maneira usual. A estratégia de pivotação é simplesmente trocar a ordem das linhas de forma que valores maiores apareçam primeiro como pivôs. Por exemplo,
\[\begin{eqnarray*} 4 x_1 -3x_2 + 2x_3 &=& 16 \\ 2x_1 + 4x_2 -3x_3 &=& 12 \\ 0x_1 + 2x_2 + 3x_2 &=& 46. \end{eqnarray*}\]
Importante notar que ao trocar a ordem das linhas a ordem da solução também será alterada. Vejamos como resolver este sistema usando as funções que criamos nesta seção.
# Entrando com o sistema original
A <- matrix(c(0,4,2,2,-3,4,3,2,-3), 3,3)
b <- c(46,16,12)
# Pivoteamento
A_order <- A[order(A[,1], decreasing = TRUE),]
b_order <- b[order(A[,1], decreasing = TRUE)]
## Triangulação
S <- gauss(A_order, b_order)
S## [,1] [,2] [,3] [,4]
## [1,] 4 -3.0 2.00 16.0
## [2,] 0 5.5 -4.00 4.0
## [3,] 0 0.0 4.45 44.5## Substituição regressiva
sol <- sub_reg(SOL = S)
sol## [1] 5 8 10## Solução
A_order%*%sol## [,1]
## [1,] 16
## [2,] 12
## [3,] 46Um segundo método direto muito popular é o método de Gauss-Jordan. Este método é similar ao método de eliminação de Gauss, porém busca transformar o sistema original em um sistema diagonal usando operações com linhas. O algoritmo pode ser resumido em dois passos:
- Normalize a equação pivô com a divisão de todos os seus termos pelo coeficiente pivô.
- Elimine os elementos fora da diagonal principal em TODAS as demais equações usando operações com linhas.
Além disso, o método de Gauss-Jordan pode ser combinado com pivotação igual ao método de eliminação de Gauss. Uma sugestão ao leitor é adaptar a implementação computacional do método de Gauss para o caso do método de Gauss-Jordan.
2.3.2 Métodos iterativos
Os métodos iterativos trabalham de forma ligeiramente diferente. Neste caso, as equações são colocadas em uma forma explícita onde cada incógnita é escrita em termos das demais, ou seja,
\[ \begin{matrix} a_{11} x_1 + a_{12} x_2 + a_{13} x_3 = b_1 \\ a_{21} x_1 + a_{22} x_2 + a_{23} x_3 = b_2 \\ a_{31} x_1 + a_{32} x_2 + a_{33} x_3 = b_3 \end{matrix} \to \begin{matrix} x_1 = [b_1 - (a_{12} x_2 + a_{13}x_3)]/a_{11} \\ x_2 = [b_2 - (a_{21} x_1 + a_{23}x_3)]/a_{22} \\ x_3 = [b_3 - (a_{31} x_1 + a_{32}x_2)]/a_{33} \end{matrix}. \]
Dado um valor inicial para as incógnitas estas são atualizadas até a convergência. Em um sistema com \(n\) equações, as equações explícitas para as incógnitas \(x_i\) são
\[x_i = \frac{1}{a_{ii}} \left [ b_i - \left ( \sum_{j=1;j \neq i}^{j=n} a_{ij} x_j \right ) \right ] \quad i = 1, \ldots, n.\]
Dentro da classe dos métodos iterativos os métodos de Jacobi e Gauss-Seidel são muito populares. A diferença básica entre os dois é que no método de Jacobi os valores das incógnitas são atualizados todos de uma vez no final de cada iteração. Por outro lado, no método de Gauss-Seidel, o valor de cada incógnita é atualizado e usado no cálculo da nova estimativa das demais incógnitas dentro da mesma iteração.
Dado um valor inicial para cada uma das incógnitas, \(x_1^{(1)}, x_2^{(1)}, \ldots, x_n^{(1)}\) o método de Jacobi atualiza a solução usando a seguinte equação de atualização:
\[\begin{equation} x_i^{k+1} = \frac{1}{a_{ii}} \left[b_i - \left(\sum_{j=1, j \neq i}^{j=n} a_{ij} x_j^{(k)} \right) \right] \quad i = 1, 2, \ldots, n. \end{equation}\]
No método de Gauss-Seidel as equações de atualização são as seguintes:
\[\begin{equation} x_1^{k+1} = \frac{1}{a_{11}} \left[b_1 - \sum_{j=2}^{j=n} a_{1j} x_j^{(k)} \right], \end{equation}\]
\[\begin{equation} x_i^{(k+1)} = \frac{1}{a_{ii}} \left[ b_i - \left( \sum_{j=1}^{j = i-1} a_{ij} x_j^{(k+1)} + \sum_{j = i+1}^{j = n} a_{ij} x_j^{(k)} \right) \right] \quad i = 2, 3, \ldots, n-1 \quad \text{e} \end{equation}\]
\[\begin{equation} x_n^{(k+1)} = \frac{1}{a_{nn}} \left[b_n - \sum_{j = 1}^{j=n-1} a_{nj} x_j^{(k+1)} \right]. \end{equation}\]
Em ambos os métodos as iterações continuam até que algum critério de parada seja atingido. Por exemplo, as iterações podem ser interrompidas quando o valor absoluto do erro relativo estimado de todas as incógnitas for menor que algum valor especificado:
\[\begin{equation} \left| \frac{x_i^{k+1} - x_i^{(k)} }{x_i^{(k)}} \right| < \epsilon. \end{equation}\]
A escolha de valores iniciais é sempre um problema a ser considerado caso a caso. Uma estratégia simples é inicializar com zeros, porém obviamente esses valores nem sempre serão razoáveis e a convergência do método pode ficar muito lenta devido a valores iniciais ruins.
Para exemplificar o uso e implementação computacional dos métodos iterativos o Código 2.16 implementa o método de Jacobi.
jacobi <- function(A, b, inicial, max_iter = 10, tol = 1e-04) {
n <- length(b)
x_temp <- matrix(NA, ncol = n, nrow = max_iter)
x_temp[1,] <- inicial
x <- x_temp[1,]
## Equação de atualização
for(j in 2:max_iter) {
for(i in 1:n) {
x_temp[j,i] <- (b[i] - sum(A[i,1:n][-i]*x[-i]))/A[i,i]
}
x <- x_temp[j,]
## Critério de parada
if(sum(abs(x_temp[j,] - x_temp[c(j-1),])) < tol) break
}
return(list("Solucao" = x, "Iteracoes" = x_temp))
}Example 2.3 Resolva o seguinte sistema de equações lineares usando o método de Jacobi.
\[\begin{eqnarray*} 9x_1 - 2x_2 + 3x_3 + 2x_4 &=& 54.5\\ 2x_1 + 8x_2 - 2x_3 + 3x_4 &=& -14 \\ -3x_1 + 2x_2 + 11x_3 - 4x_4 &=& 12.5 \\ -2x_1 + 3x_2 + 2x_3 - 10x_4 &=& -21 \\ \end{eqnarray*}\]Vamos começar entrando com a matriz do sistema.
# Matriz do sistema
A <- matrix(c(9,2,-3,-2,-2,8,2,3,3,-2,11,2,2,3,-4,10), 4, 4)
# Vetor de solução
b <- c(54.5, -14, 12.5, -21)Agora usamos a função implementada no Código 2.16.
sol <- jacobi(A = A, b = b, inicial = c(0,0,0,0))
sol$Solucao## [1] 4.99 -2.00 2.50 -1.00Note que a solução fornecida é uma aproximação para a solução exata. A solução exata pode ser obtida, por exemplo usando o método de eliminação de Gauss.
S <- gauss(A = A, b = b)
sol_ex <- sub_reg(SOL = S)
sol_ex## [1] 5.0 -2.0 2.5 -1.0Uma questão importante sobre a implementação dos métodos iterativos é o uso do duplo for(). Isso torna a implementação computacional destes métodos diretamente em R conforme feito no Código 2.16 lento. Uma implementação eficiente dos métodos de Jacobi e Gauss-Seidel está disponível em R através do pacote Rlinsolve. Este pacote implementa os métodos utilizando a linguagem C++ o que torna a implementação bastante rápida computacionalmente. O uso do pacote Rlinsolve é ilustrado no Código 2.17.
Rlinsolve para resolver sistemas lineares via métodos iterativos.
# Carregando o pacote
require(Rlinsolve)
# Método de Jacobi
lsolve.jacobi(A, b)$x## [,1]
## [1,] 5.0
## [2,] -2.0
## [3,] 2.5
## [4,] -1.0# Método de Gauss-Seidel
lsolve.gs(A, b)$x## [,1]
## [1,] 5.0
## [2,] -2.0
## [3,] 2.5
## [4,] -1.02.3.3 Decomposição LU
Para motivar o uso de decomposições matriciais considere que precisamos resolver vários sistemas lineares do tipo \[\mathbf{A} \boldsymbol{x} = \boldsymbol{b}\] para diferentes \(\boldsymbol{b}\)’s.
A ideia é manipular apenas a matriz \(\mathbf{A}\) de modo que as operações feitas em \(\mathbf{A}\) possam ser aproveitadas para resolver os diversos sistemas lineares.
A decomposição LU é uma das decomposições mais populares e comumente implementada em diversos softwares. Em R a função solve() que nós já usamos resolve um sistema linear usando a decomposição LU. O procedimento consiste em decompor ou fatorar a matriz \(\mathbf{A}\) em um produto de duas matrizes
\[\mathbf{A} = \mathbf{L} \mathbf{U},\] onde \(\mathbf{L}\) é triangular inferior e \(\mathbf{U}\) é triangular superior.
Baseado na decomposição o sistema terá a forma:
\[\begin{equation} \mathbf{L} \mathbf{U} \boldsymbol{x} = \boldsymbol{b}. \tag{2.10} \end{equation}\]
Defina \(\mathbf{U} \boldsymbol{x} = \boldsymbol{y}.\) Substituindo em (2.10) tem-se
\[\begin{equation} \mathbf{L} \boldsymbol{y} = \boldsymbol{b}. \tag{2.11} \end{equation}\]
Assim, a solução é obtida em dois passos
- Resolva Equação (2.11) para obter \(\boldsymbol{y}\) usando substituição progressiva.
- Resolva Equação (2.10) para obter \(\boldsymbol{x}\) usando substituição regressiva.
Um método para obter a decomposição \(\mathbf{LU}\) é o próprio método de eliminação de Gauss. Dentro do processo de eliminação de Gauss as matrizes \(\mathbf{L}\) e \(\mathbf{U}\) são obtidas como um subproduto. Considere uma matriz \(4 \times 4\), a decomposição \(\mathbf{LU}\) toma a seguinte forma
\[ \begin{bmatrix} a_{11} & a_{12} & a_{13} & a_{14} \\ a_{21} & a_{22} & a_{23} & a_{24} \\ a_{31} & a_{32} & a_{33} & a_{34} \\ a_{41} & a_{41} & a_{43} & a_{44} \end{bmatrix} = \begin{bmatrix} 1 & & & \\ m_{21} & 1 & & \\ m_{31} & m_{32} & 1 & \\ m_{41} & m_{42} & m_{43} & 1 \end{bmatrix} \begin{bmatrix} a_{11} & a_{12} & a_{13} & a_{14} \\ 0 & a'_{22} & a'_{23} & a'_{24} \\ 0 & 0 & a'_{33} & a'_{34} \\ 0 & 0 & 0 & a'_{44} \end{bmatrix}. \] Os elementos \(m_{ij}'s\) são os multiplicadores que multiplicam a equação pivô. Os elementos \(a'_{ij}\) são os elementos usuais da triangular superior obtida pelo método de eliminação de Gauss.
Relembre o Exemplo 2.1
\[ \begin{bmatrix} [3] & 2 & 6 \\ 2 - \boldsymbol{\frac{2}{3}}3 & 4 - \frac{2}{3}2 & 3 - \frac{2}{3}6 \\ 5 - \boldsymbol{\frac{5}{3}}3 & 3 - \frac{5}{3}2 & 4 - \frac{5}{3}6 \\ \end{bmatrix} \begin{bmatrix} 24 \\ 23 - \frac{2}{3}24\\ 33 - \frac{5}{3}24 \end{bmatrix} \to \begin{bmatrix} [3] & 2 & 6 \\ 0 & \frac{8}{3} & -1 \\ 0 & -\frac{1}{3} & -6 \\ \end{bmatrix} \begin{bmatrix} 24 \\ 7 \\ -7 \end{bmatrix} \]
\[ \begin{bmatrix} 3 & 2 & 6 \\ 0 & [\frac{8}{3}] & -1 \\ 0 & -\frac{1}{3} - \left (-\frac{3}{24} \right ) \left (\frac{8}{3}\right ) & -6 - (\boldsymbol{-\frac{3}{24}})(-1) \\ \end{bmatrix} \begin{bmatrix} 24 \\ 7 \\ -7 - (- \frac{3}{24})(7) \end{bmatrix} \to \begin{bmatrix} 3 & 2 & 6 \\ 0 & [\frac{8}{3}] & -1 \\ 0 & 0 & [-\frac{147}{24}] \\ \end{bmatrix} \begin{bmatrix} 24 \\ 7 \\ -\frac{147}{24} \end{bmatrix} \]
Assim, tem-se
\[ \mathbf{L} = \begin{bmatrix} 1 & & \\ \frac{2}{3} & 1 & \\ \frac{5}{3} & -\frac{3}{24} & 1 \end{bmatrix} \quad \text{e} \quad \mathbf{U} = \begin{bmatrix} 3 & 2 & 6 \\ 0 & \frac{8}{3} & -1 \\ 0 & 0 & -\frac{147}{24} \\ \end{bmatrix}. \]
Neste caso, o método de eliminação de Gauss foi realizado sem pivotação. Porém, conforme já discutido a pivotação pode ser necessária. Quando realizada a pivotação, as mudanças feitas devem ser armazenadas, tal que
\[\mathbf{P} \mathbf{A} = \mathbf{L}\mathbf{U},\] onde \(\mathbf{P}\) é chamada de matriz de permutação. Se as matrizes \(\mathbf{L}\mathbf{U}\) forem usadas para resolver o sistema \[\mathbf{A} \boldsymbol{x} = \boldsymbol{b},\] a ordem das linhas de \(\boldsymbol{b}\) deve ser alterada de forma consistente com a pivotação, ou seja, \(\mathbf{P} \boldsymbol{b}\).
Para ilustrar a implementação computacional da decomposição \(\mathbf{LU}\) vamos implementá-la baseada no método de eliminação de Gauss sem pivotação e depois usar as funções nativas do R para exemplificar o uso da matriz de permutação. O Código 2.18 apresenta uma implementação ilustrativa da decomposição \(\mathbf{LU}\).
Código 2.18 Decomposição \(\mathbf{LU}\).
my_lu <- function(A) {
n_row <- nrow(A)
n_col <- ncol(A)
# Matriz para receber os resultados
SOL <- matrix(NA, n_row, n_col)
SOL[1,] <- A[1,]
pivo <- matrix(0, n_col, n_row)
for(j in 1:c(n_row-1)) {
for(i in c(j+1):c(n_row)) {
pivo[i,j] <- A[i,j]/SOL[j,j]
SOL[i,] <- A[i,] - pivo[i,j]*SOL[j,]
A[i,] <- SOL[i,]
}
}
diag(pivo) <- 1
return(list("L" = pivo, "U" = SOL))
}Para ilustrar o uso da decomposição \(\mathbf{LU}\) considere a matriz \(\mathbf{A}\) do Exemplo 2.3.
LU <- my_lu(A) # Decomposição
LU## $L
## [,1] [,2] [,3] [,4]
## [1,] 1.000 0.000 0.00 0
## [2,] 0.222 1.000 0.00 0
## [3,] -0.333 0.158 1.00 0
## [4,] -0.222 0.303 0.28 1
##
## $U
## [,1] [,2] [,3] [,4]
## [1,] 9 -2.00e+00 3.00 2.00
## [2,] 0 8.44e+00 -2.67 2.56
## [3,] 0 0.00e+00 12.42 -3.74
## [4,] 0 -4.44e-16 0.00 10.72LU$L %*% LU$U # Verificando a solução## [,1] [,2] [,3] [,4]
## [1,] 9 -2 3 2
## [2,] 2 8 -2 3
## [3,] -3 2 11 -4
## [4,] -2 3 2 10Para resolver o sistema usamos a matriz decomposta combinada com os procedimentos de substituição progressiva e regressiva, respectivamente. Em R as funções forwardsolve() e backsolve() implementam os procedimentos de substituição progressiva e regressiva, respectivamente. O Código 2.19 ilustra como resolver o sistema baseado na decomposição \(\mathbf{LU}\).
# Passo 1: Substituição progressiva
y = forwardsolve(LU$L, b)
# Passo 2: Substituição regressiva
x = backsolve(LU$U, y)
x## [1] 5.0 -2.0 2.5 -1.0A%*%x # Verificando a solução## [,1]
## [1,] 54.5
## [2,] -14.0
## [3,] 12.5
## [4,] -21.0O Código 2.18 é apenas para ilustrar a obtenção da decomposição \(\mathbf{LU}\). Em problemas reais devemos usar as implementações disponíveis no pacote Matrix. O Código 2.20 ilustra o uso da função lu() do pacote Matrix para obtenção da decomposição \(\mathbf{LU}\) neste exemplo com pivotação.
Matrix.
require(Matrix)
LU_M <- Matrix::lu(A) # Calcula mas não retorna
LU_M <- Matrix::expand(LU_M) # Captura as matrizes L U e P
# Substituição progressiva. NOTE MATRIZ DE PERMUTAÇÃO
y <- forwardsolve(LU_M$L, LU_M$P%*%b)
x = backsolve(LU_M$U, y) # Substituição regressiva
x## [1] 5.0 -2.0 2.5 -1.02.3.4 Cálculo da inversa
A decomposição \(\mathbf{LU}\) é especialmente adequada para o cálculo da inversa. Lembre-se que a inversa de \(\mathbf{A}\) é tal que \[\mathbf{A} \mathbf{A}^{-1} = \mathbf{I}.\] O procedimento de cálculo da inversa é essencialmente o mesmo da solução de um sistema de equações lineares, porém com mais incógnitas.
\[ \begin{bmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \end{bmatrix} \begin{bmatrix} x_{11} & x_{12} & x_{13} \\ x_{21} & x_{22} & x_{23} \\ x_{31} & x_{32} & x_{33} \end{bmatrix} = \begin{bmatrix} 1 & 0 & 0\\ 0 & 1 & 0\\ 0 & 0 & 1 \end{bmatrix} \]
Neste exemplo simples, precisamos resolver três sistemas de equações diferentes. Em cada sistema, uma coluna da matriz \(\mathbf{X}\) é a incógnita. A implementação computacional pode ser facilmente feita combinando a função 2.18 com as funções forwardsolve() e backsolve(). O Código 2.21 implementa o cálculo da inversa usando a decomposição \(\mathbf{LU}\).
Código 2.21 Cálculo da matriz inversa usando decomposição \(\mathbf{LU}\).
## Resolve um sistema de equações
solve_lu <- function(LU, b) {
y <- forwardsolve(LU$L, b)
x = backsolve(LU$U, y)
return(x)
}
# Cálculo da inversa
my_solve <- function(LU, B) {
n_col <- ncol(B)
n_row <- nrow(B)
inv <- matrix(NA, n_col, n_row)
for(i in 1:n_col) {
inv[,i] <- solve_lu(LU, B[,i])
}
return(inv)
}A implementação foi feita em dois passos. Na primeira função solve_lu() resolve um sistema de equação usual. A função my_solve() usa uma instrução for para varrer todas as colunas da matriz de incógnitas e assim obter a inversa. É importante notar que ambas recebem a decomposição \(\mathbf{LU}\) da matriz original.
\[ \mathbf{A} = \begin{bmatrix} 3 & 2 & 6\\ 2 & 4 & 3\\ 5 & 3 & 4 \end{bmatrix} \]
Para resolver este exemplo, vamos usar as funções que criamos.
## Entrando com a matriz
A <- matrix(c(3,2,5,2,4,3,6,3,4),3,3)
# Criando a matriz de incógnitas
I <- Diagonal(3, 1)
# Decomposição LU
LU <- my_lu(A)
# Obtendo a inversa
inv_A <- my_solve(LU = LU, B = I)
inv_A## [,1] [,2] [,3]
## [1,] -0.143 -0.2041 0.3673
## [2,] -0.143 0.3673 -0.0612
## [3,] 0.286 -0.0204 -0.1633# Verificando o resultado
A%*%inv_A## [,1] [,2] [,3]
## [1,] 1.00e+00 0.00e+00 -1.11e-16
## [2,] 1.11e-16 1.00e+00 0.00e+00
## [3,] 0.00e+00 6.94e-17 1.00e+00A função nativa do R recomendada para a solução tanto de sistemas lineares quanto para a obtenção da inversa é a função solve(). A função solve() implementa a decomposição \(\mathbf{LU}\) com pivotação. O R usa uma implementação eficiente disponível na biblioteca lapack para mais detalhes veja lapack library.
Existem diversas outras estratégias para o cálculo da inversa de uma matriz. Talvez o método mais simples seja usar o método de Gauss-Jordan. Neste método uma matriz aumentada é construída e a inversa é obtida usando operações com linhas. A matriz aumentada toma a seguinte forma:
\[ \begin{bmatrix} a_{11} & a_{21} & a_{31} & 1 & 0 & 0\\ a_{21} & a_{22} & a_{32} & 0 & 1 & 0\\ a_{31} & a_{32} & a_{33} & 0 & 0 & 1 \end{bmatrix} \to \begin{bmatrix} 1 & 0 & 0 & a'_{11} & a'_{21} & a'_{31} \\ 0 & 1 & 0 & a'_{21} & a'_{22} & a'_{32} \\ 0 & 0 & 1 & a'_{31} & a'_{32} & a'_{33} \end{bmatrix}. \]
O método é bastante simples, porém computacionalmente caro. Para implementações de alto desempenho computacional de tópicos em álgebra linear eu recomendo ao leitor interessado consultar as bibliotecas eigen e armadillo. Ambas podem ser utilizadas diretamente do R usando os pacotes RcppEigen e RcppArmadillo.
2.4 Autovalores e autovetores
Em ciência de dados é comum lidar com grandes matrizes de dados que apresentam um intrincado sistema de relações ou, em termos estatísticos, correlações. De forma intuitiva pode-se pensar em correlação como sendo uma forma de relacionamento entre duas variáveis de interesse. Por exemplo, o número de quartos em um apartamento pode estar associado com o seu preço. Porém, o número de quartos também pode estar associado com o tamanho total do imóvel, que por sua vez também está associado com o preço do imóvel. Neste exemplo simples com apenas três variáveis podemos notar como é complexo entender a estrutura de correlações em uma base de dados com muitas variáveis de interesse.
Neste tipo de situação é comum fazer uma redução de dimensionalidade. Este tipo de técnica busca reduzir o número de variáveis a serem analisadas facilitando a interpretação. Essa redução baseia-se em criar novas variáveis que são combinações (em particular combinações lineares) das variáveis originais. Talvez a técnica de redução de dimensionalidade mais popular em ciência de dados seja Análise de Componentes principais que por sua vez é baseada na decomposição em autovalores e autovetores da matriz de dados. Neste livro, nós vamos discutir apenas os aspectos práticos da obtenção da decomposição em autovalores e autovetores.
Autovalores e autovetores são definidos por uma simples igualdade
\[\begin{equation} \mathbf{A} \boldsymbol{v} = \boldsymbol{\lambda} \boldsymbol{v}. \tag{2.12} \end{equation}\]
Qualquer vetor unitário \(\boldsymbol{v}\) que satisfaz a Equação (2.12) tem apenas o efeito de alongar ou encolher \(\boldsymbol{v}\), ou seja, o vetor não é rotacionado e a direção é preservada. Os vetores \(\boldsymbol{v}\)’s que satisfazem Equação (2.12) são os autovetores. Enquanto que os valores \(\boldsymbol{\lambda}\)’s que satisfazem Equação (2.12) são os autovalores. Neste livro, vamos considerar apenas o caso em que \(\mathbf{A}\) é simétrica.
Sendo \(\mathbf{A}\) uma matriz simétrica \(n \times n\), então existem exatamente \(n\) pares \((\lambda_j, \boldsymbol{v}_j)\) que satisfazem a equação
\[\begin{equation*} \mathbf{A} \boldsymbol{v} = \boldsymbol{\lambda} \boldsymbol{v}. \end{equation*}\]
Se \(\mathbf{A}\) tem autovalores \(\lambda_1, \ldots, \lambda_n\), então:
- \(\mathrm{tr}(\mathbf{A}) = \sum_{i=1}^n \lambda_i\).
- \(\mathrm{det}(\mathbf{A}) = \prod_{i=1}^n \lambda_i\).
- \(\mathbf{A}\) é positiva definida, se e somente se todos \(\lambda_j > 0\).
- \(\mathbf{A}\) é semi-positiva definida, se e somente se todos \(\lambda_j \geq 0\).
Qualquer matriz simétrica \(\mathbf{A}\) pode ser fatorada em
\[\mathbf{A} = \mathbf{Q} \boldsymbol{\Lambda} \mathbf{Q}^{\top},\] onde \(\boldsymbol{\Lambda}\) é diagonal contendo os autovalores de \(\mathbf{A}\) e as colunas de \(\mathbf{Q}\) contêm os autovetores ortonormais (ortogonais de comprimento unitário).
A obtenção da decomposição em autovalores e autovetores de uma matriz não é simples, e em geral é baseada em uma outra decomposição chamada de decomposição \(\mathbf{QR}\). Está fora do escopo deste livro descrever tal algoritmo, porém usando o R podemos facilmente obter a decomposição em autovalores e autovetores usando a função eigen(), conforme ilustrado no Código 2.22
A <- matrix(c(1,0.8, 0.3, 0.8, 1, 0.2, 0.3, 0.2, 1),3,3)
isSymmetric.matrix(A)## [1] TRUEout <- eigen(A)
Q <- out$vectors
D <- diag(out$values)
# Autovetores
Q## [,1] [,2] [,3]
## [1,] -0.671 -0.182 0.7187
## [2,] -0.651 -0.320 -0.6886
## [3,] -0.355 0.930 -0.0965# Autovalores
D## [,1] [,2] [,3]
## [1,] 1.93 0.000 0.000
## [2,] 0.00 0.873 0.000
## [3,] 0.00 0.000 0.193# Verificando
Q%*%D%*%t(Q)## [,1] [,2] [,3]
## [1,] 1.0 0.8 0.3
## [2,] 0.8 1.0 0.2
## [3,] 0.3 0.2 1.0Uma aspecto interessante dos autovalores é que eles permitem lidar com matrizes da mesma forma que lidamos com números. A ideia é que se você deseja aplicar uma função em uma matriz, como por exemplo o inverso, você pode simplesmente aplicar a função na matriz diagonal \(\boldsymbol{\Lambda}\) e fazer a multiplicação por \(\mathbf{Q}\) para obter a matriz resultante da aplicação da função.
Assim, a decomposição em autovalores e autovetores pode ser usada para obter a inversa de uma matriz. Se \(\mathbf{A}\) tem autovetores \(\mathbf{Q}\) e autovalores \(\lambda_j\). Então \(\mathbf{A}^{-1}\) tem autovetores \(\mathbf{Q}\) e autovalores \(\lambda_j^{-1}\). Isso implica que \(\mathbf{A}^{-1} = \mathbf{Q} \boldsymbol{\Lambda}^{-1} \mathbf{Q}^{\top}\). O Código 2.23 ilustra a obtenção da inversa usando a decomposição em autovalores e autovetores.
out <- eigen(A)
Q <- out$vectors
inv_D <- diag(1/out$values)
inv_A <- Q%*%inv_D%*%t(Q)
## Verificando
A%*%inv_A## [,1] [,2] [,3]
## [1,] 1.00e+00 2.57e-16 -3.33e-16
## [2,] 4.86e-16 1.00e+00 3.33e-16
## [3,] -1.78e-15 1.67e-15 1.00e+002.5 Decomposição em valores singulares
Uma outra decomposição associada a decomposição em autovalores e autovetores é a decomposição em valores singulares. A principal diferença é que a decomposição em valores singulares é definida para qualquer matriz, enquanto que a decomposição em autovalores e autovetores é definida apenas para matrizes simétricas.
Note que matrizes não quadradas não tem autovalores, porém \(\mathbf{D}\) no Teorema 2.1 é obtida para qualquer matriz. Assim, os elementos de \(\mathbf{D}\) são chamados de valores singulares e correspondem aos autovalores de \(\mathbf{A}^{\top} \mathbf{A}\).
No caso da decomposição em valores singulares é importante estar atento à dimensão das matrizes envolvidas. Assim,
- Se \(\mathbf{A}\) é \(n \times n\), então \(\mathbf{U}, \mathbf{D}\) e \(\mathbf{V}\) são \(n \times n\).
- Se \(\mathbf{A}\) é \(n \times p\), sendo \(n > p\), então \(\mathbf{U}\) é \(n \times p\), \(\mathbf{D}\) e \(\mathbf{V}\) são \(p \times p\).
- Se \(\mathbf{A}\) é \(n \times p\), sendo \(n < p\), então \(\mathbf{V}^{\top}\) é \(n \times p\), \(\mathbf{D}\) e \(\mathbf{U}\) são \(n \times n\).
- \(\mathbf{D}\) será sempre quadrada com dimensão igual ao mínimo entre \(p\) e \(n\).
Em R a obtenção da decomposição em valores singulares está implementada na função svd(), conforme ilustrado no Código 2.24.
svd(A)## $d
## [1] 1.934 0.873 0.193
##
## $u
## [,1] [,2] [,3]
## [1,] -0.671 0.182 0.7187
## [2,] -0.651 0.320 -0.6886
## [3,] -0.355 -0.930 -0.0965
##
## $v
## [,1] [,2] [,3]
## [1,] -0.671 0.182 0.7187
## [2,] -0.651 0.320 -0.6886
## [3,] -0.355 -0.930 -0.09652.6 Regressão ridge
Para ilustrar a aplicação da decomposição em valores singulares em ciência de dados vamos considerar o modelo de regressão ridge. Relembre que na seção 2.2.7 nós escrevemos o modelo de regressão linear múltipla usando matrizes da seguinte forma:
\[ \underset{n\times 1}{\begin{bmatrix} y_1\\ y_2\\ \vdots \\ y_n \end{bmatrix}} = \underset{n\times p}{\begin{bmatrix} 1 & x_{11} & \ldots & x_{p1} \\ 1 & x_{12} & \ldots & x_{p1} \\ \vdots & \vdots & \ddots & \vdots \\ 1& x_{1n} & \ldots & x_{pn} \end{bmatrix} } \underset{p \times 1}{ \begin{bmatrix} \beta_0 \\ \vdots \\ \beta_p \end{bmatrix} }. \]
Também, usamos a seguinte notação mais compacta, \[\underset{n \times 1}{\mathbf{y}} = \underset{n \times p }{\mathbf{X}} \underset{p\times 1}{\boldsymbol{\beta}}.\]
Vimos que o vetor \(\boldsymbol{\hat{\beta}}\) que minimiza a perda quadrática é dado por
\[\boldsymbol{\hat{\beta}} = (\mathbf{X}^{\top}\mathbf{X})^{-1}\mathbf{X}^{\top}\mathbf{y}.\]
Note a importância do termo \((\mathbf{X}^{\top}\mathbf{X})^{-1}\) para a obtenção da solução. Vimos também que para calcular a inversa de uma matriz ela precisa ser não-singular. Neste caso sempre que \(n > p\) a matriz \(\mathbf{X}^{\top}\mathbf{X}\) será não-singular. Porém, existem situações práticas em ciência de dados em que \(n < p\), ou seja, temos mais covariáveis do que observações na base de dados. Este é o tipo de problema comumente chamado de high dimensional data. Neste caso, o sistema gerado será singular, ou seja, tem múltiplas soluções. Porém, ainda gostaríamos de ajustar um modelo similar ao modelo de regressão linear múltipla.
Para superar o problema de \(n < p\) é comum introduzir uma penalização pela complexidade na soma de quadrados. A soma de quadrados penalizada é dada por:
\[PSQ(\boldsymbol{\beta}) = \sum_{i=1}^n (y_i - \boldsymbol{x}_i^{\top} \boldsymbol{\beta})^2 + \lambda \sum_{j = 1}^p \beta_j^2.\]
Matricialmente, tem-se
\[PSQ(\boldsymbol{\beta}) = (\boldsymbol{y} - \mathbf{X} \boldsymbol{\beta})^{\top}(\boldsymbol{y} - \mathbf{X} \boldsymbol{\beta}) + \lambda \boldsymbol{\beta}^{\top} \boldsymbol{\beta}.\]
IMPORTANTE Na soma de quadrados penalizada \(\boldsymbol{y}\) deve estar centrado na média ou o intercepto do modelo não deve ser penalizado. E a matriz \(\mathbf{X}\) deve estar padronizada por coluna, o que implica que cada coluna deve ter média zero e variância um.
Nosso objetivo é minimizar a soma de quadrados penalizada e vamos proceder usando a mesma estratégia da Seção 2.2.7. Começamos obtendo a derivada da soma de quadrados penalizada em relação a \(\boldsymbol{\beta}\)
\[\begin{eqnarray*} \frac{\partial PQS(\boldsymbol{\beta})}{\partial \boldsymbol{\beta}} &=& \frac{\partial}{\partial \boldsymbol{\beta}} \left [ (\boldsymbol{y} - \mathbf{X} \boldsymbol{\beta} )^{\top} (\boldsymbol{y} - \mathbf{X} \boldsymbol{\beta} ) + \lambda \boldsymbol{\beta}^{\top}\boldsymbol{\beta} \right ] \\ &=& \left [ \frac{\partial}{\partial \boldsymbol{\beta}} (\boldsymbol{y} - \mathbf{X} \boldsymbol{\beta} )^{\top} \right ] (\boldsymbol{y} - \mathbf{X} \boldsymbol{\beta} ) + (\boldsymbol{y} - \mathbf{X} \boldsymbol{\beta} )^{\top} \left [ \frac{\partial}{\partial \boldsymbol{\beta}} (\boldsymbol{y} - \mathbf{X} \boldsymbol{\beta} ) \right ] \\ &+& \lambda \left\{ \left [ \frac{\partial \boldsymbol{\beta}^{\top}}{\partial \boldsymbol{\beta}}\right ]\boldsymbol{\beta} + \boldsymbol{\beta}^{\top} \left [ \frac{\partial \boldsymbol{\beta}}{\partial \boldsymbol{\beta}}\right ] \right\}\\ &=& -2 \mathbf{X}^{\top} (\boldsymbol{y} - \mathbf{X}\boldsymbol{\beta}) + 2 \lambda \boldsymbol{\beta} \\ &=& -\mathbf{X}^{\top} (\boldsymbol{y} - \mathbf{X}\boldsymbol{\beta}) + \lambda \boldsymbol{\beta}. \end{eqnarray*}\]
Resolvendo o sistema linear, tem-se
\[\begin{eqnarray*} -\mathbf{X}^{\top}(\boldsymbol{y} - \mathbf{X}\boldsymbol{\hat{\beta} }) + \lambda \mathbf{I} \boldsymbol{\hat{\beta}} &=& \boldsymbol{0} \\ -\mathbf{X}^{\top}\boldsymbol{y} + \mathbf{X}^{\top}\mathbf{X}\boldsymbol{\hat{\beta} } + \lambda \mathbf{I} \boldsymbol{\hat{\beta}} &=& \boldsymbol{0} \\ \mathbf{X}^{\top}\mathbf{X}\boldsymbol{\hat{\beta} } + \lambda \mathbf{I} \boldsymbol{\hat{\beta}} &=& \mathbf{X}^{\top}\boldsymbol{y} \\ \left( \mathbf{X}^{\top}\mathbf{X} + \lambda \mathbf{I} \right )\boldsymbol{\hat{\beta} } &=& \mathbf{X}^{\top}\boldsymbol{y} \\ \boldsymbol{\hat{\beta} } &=& \left( \mathbf{X}^{\top}\mathbf{X} + \lambda \mathbf{I} \right )^{-1}\mathbf{X}^{\top}\boldsymbol{y}. \end{eqnarray*}\]
Note que a solução depende de \(\lambda\) e que foi a inclusão de \(\lambda\) que tornou o sistema não-singular. Pode-se interpretar que quando fixamos o \(\lambda\) selecionamos uma solução particular.
Um aspecto que está subjacente é que matrizes que são diagonais dominantes permitem inversa. Note que \(\mathbf{X}^{\top} \mathbf{X}\) não é diagonal dominante no caso em que \(n < p\). Porém, se simplesmente somarmos uma certa quantidade positiva na diagonal de \(\mathbf{X}^{\top}\mathbf{X}\) ela será diagonal dominante e portanto permitirá inversa. Apesar de parecer uma solução ad hoc, como mostrado, essa solução tem uma forte fundamentação matemática baseada em uma soma de quadrados penalizada.
Calcular \(\boldsymbol{\hat{\beta}}\) envolve a inversão de uma matrix \(p \times p\) potencialmente grande
\[\boldsymbol{\hat{\beta}} = \left( \mathbf{X}^{\top}\mathbf{X} + \lambda \mathbf{I} \right )^{-1}\mathbf{X}^{\top}\boldsymbol{y}.\]
Para obter esta inversa podemos usar a decomposição em valores singulares. Lembre-se que a decomposição em valores singulares, fatora a matriz \(\mathbf{X}\) da seguinte forma:
\[\mathbf{X} = \mathbf{U} \mathbf{D} \mathbf{V}^{\top}.\]
Substituindo na Equação para \(\boldsymbol{\hat{\beta}}\) é fácil mostrar que
\[\begin{equation} \boldsymbol{\hat{\beta}} = \mathbf{V} \mathrm{diag}\left ( \frac{d_j}{d_j^2 + \lambda} \right ) \mathbf{U}^{\top} \boldsymbol{y}. \tag{2.13} \end{equation}\]
Importante notar que o valor de \(\lambda\) é desconhecido e que a escolha de um valor ótimo para \(\lambda\) não é uma tarefa fácil. É comum em termos práticos usar validação cruzada. A ideia básica é separar o conjunto de dados em dois: um chamado de treino e outro de teste. Ajusta-se o modelo no conjunto de treino com o valor de \(\lambda\) fixado em algum valor e avalia-se alguma função perda no conjunto de teste. Este processo é repetido para diversos valores de \(\lambda\) e escolhe-se aquele \(\lambda\) que minimiza a função perda no conjunto de teste. Existem diversas versões do procedimento de validação cruzada. Porém, está fora do escopo deste livro discutir tais aspectos práticos. O que importa é notar que o sistema terá que ser resolvido para muitos valores de \(\lambda\).
A princípio poderíamos usar a decomposição \(\mathbf{LU}\) para resolver o sistema \((\mathbf{X}^{\top} \mathbf{X} + \lambda \mathbf{I}) \boldsymbol{\beta} = \mathbf{X}^{\top}\boldsymbol{y}\). Porém, teríamos que para cada valor de \(\lambda\) resolver um novo sistema o que tornaria o problema computacionalmente caro e lento. Por outro lado, note que na Equação (2.13) o valor de \(\lambda\) aparece apenas no termo \(\mathrm{diag}\left ( \frac{d_j}{d_j^2 + \lambda} \right )\) e portanto não afeta as matrizes \(\mathbf{V}\) e \(\mathbf{U}\) que são obtidas apenas uma vez independente do número de valores para \(\lambda\), o que torna o uso da decomposição em valores singulares bastante interessante neste contexto.
Para ilustrar a implementação computacional do modelo de regressão ridge vamos simular um conjunto de dados com \(100\) linhas (observações) e \(200\) covariáveis. Para simular as covariáveis vamos usar a distribuição Normal com média zero e
variância um. Se você não é familiar com a distribuição Normal, pense que é apenas uma forma de gerar dados artificiais. Para tornar o procedimento de simulação reproduzível vamos usar a função set.seed(). Outro aspecto importante é que a primeira coluna da matriz \(\mathbf{X}\) deve ser uma coluna de \(1\)s e portanto não deve ser centrada.
# Fixa a semente para a simulação ser reproduzível
set.seed(123)
X <- matrix(NA, ncol = 200, nrow = 100)
X[,1] <- 1 # Intercepto
for(i in 2:200) {
X[,i] <- rnorm(100, mean = 0, sd = 1)
X[,i] <- (X[,i] - mean(X[,i]))/var(X[,i])
}O próximo passo para simular o conjunto de dados é fixar o vetor de parâmetros \(\boldsymbol{\beta}\). Como estamos em um exemplo de high dimensional data é comum a suposição que a solução seja esparsa. Isso significa que apenas alguns elementos do vetor \(\boldsymbol{\beta}\) são diferentes de zero. Neste exemplo vamos fixar que os primeiros dez elementos de \(\boldsymbol{\beta}\) sejam diferentes de zero assumindo valores entre 5 e 10 de forma uniforme.
set.seed(123)
## Gerando o vetor de beta's
beta <- c(0, runif(9, min = 5, max = 10), rep(0, 190))
## Média da distribuição Normal
mu <- X%*%beta
## Gerando as observações
y <- rnorm(100, mean = mu, sd = 10)Podemos agora usar o nosso procedimento para estimar os coeficientes de regressão.
X_svd <- svd(X) # Decomposição svd
lambda = 0.1 # Penalização
DD <- Diagonal(100, X_svd$d/(X_svd$d^2 + lambda))
DD[1] <- 0
beta_hat = as.numeric(X_svd$v%*%DD%*%t(X_svd$u)%*%y)
beta_hat[1:10]## [1] -0.141 2.878 4.458 3.639 2.051 3.333 5.026 3.341 5.785
## [10] 1.860Para verificar a qualidade do nosso procedimento comparamos os valores simulados com os estimados via regressão ridge.
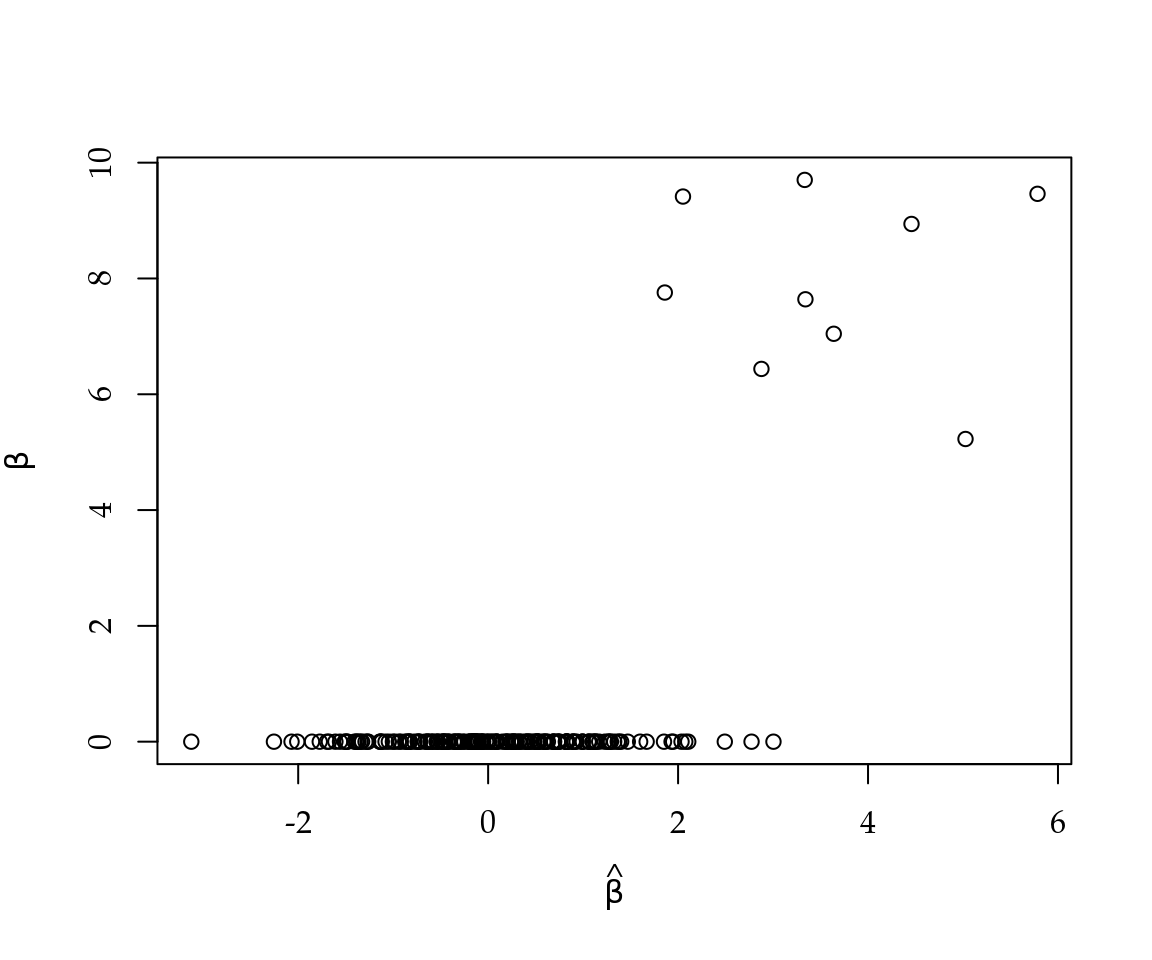
Figura 2.1: Parâmetros de regressão versus suas estimativas obtidas via regressão ridge.
Os resultados da Figura 2.1 mostram que a regressão ridge teve sucesso em identificar boa parte dos coeficientes diferentes de zero. No entanto, parece que a penalização precisa ser melhor especificada. O leitor pode verificar o efeito de diferentes valores de \(\lambda\) e tamanhos de amostra nas estimativas. Desta forma, terminamos a nossa pequena incursão no mundo da Álgebra Matricial.
2.7 Referências bibliográficas
Novamente, como inspiração para estruturar o capítulo foram usados livros básicos de matemática aplicada à economia e administração tais como Dowling (1984) e Leithold (1988). Para as seções de solução de sistemas lineares e decomposições matriciais as principais referências consultadas foram Gilat and Subramaniam (2009) e Rencher and Schaalje (2008).
2.8 Exercícios
Os exercícios deste livro são na forma de tutoriais interativos. Acesse Exercícios Álgebra Matricial.