Introdução
Última atualização: 11 de maio de 2021.
Em todos os problemas de inferência estatística considerados, assumimos que a distribuição da variável
aleatória que está sendo amostrada seja conhecida a menos, talvez, para alguns parámetros. Na prática,
entretanto, a forma funcional da distribuição é raramente ou nunca conhecida. Por conseguinte, é desejável
conceber alguns procedimentos que estejam livres desta hipótese relativa à distribuição.
Para entender a ideia de estatística não-paramétrica, este termo foi usado pela primeira vez por Jacob Wolfowitz em 1942, primeiro
requeremos uma compreensão de conceitos da estatística básica paramétrica. Conceitos elementares introduzem o conceito de
teste de significância estatística com base na distribuição amostral de uma estatística particular. Em resumo, se
tivermos um conhecimento básico da distribuição subjacente de uma variável, poderemos fazer previsões sobre como, em
amostras repetidas de tamanho igual, essa estatística específica se comportará, isto é, como será distribuída.
Estudamos aqui alguns procedimentos que são comumente referidos como métodos sem distribuição ou
não paramétricos. O termo livre de distribuição refere-se ao fato de que nenhuma suposição
é feita sobre a distribuição subjacente, exceto que a função de distribuição sendo
amostrada seja absolutamente contínua ou puramente discreta. O termo não paramétrico refere-se ao fato de não
haver parâmetros envolvidos no sentido tradicional do termo parâmetro utilizado até o momento.
Nos dois exemplos seguintes mostramos distribuições conhecidas que são livres de parâmetros.
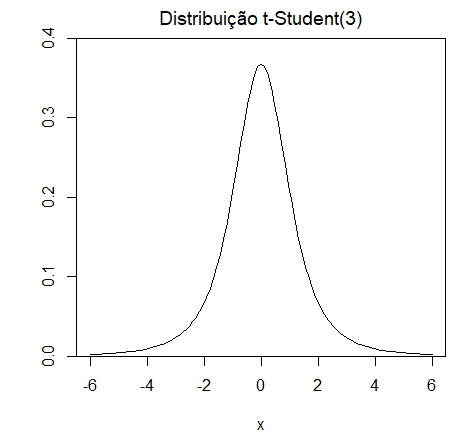
Exemplo. Seja \(X\sim t(n)\), ou seja, seja \(X\) uma variável aleatória com distribuição t-Student
com \(n\) graus de liberdade. Isto significa que \(X\) tem por função de densidade
\begin{equation}
f(x)=\dfrac{\Gamma\big(\frac{n+1}{2}\big)}{\Gamma\big(\frac{n}{2}\big)\sqrt{n\pi}}\Big( 1+\frac{x^2}{n} \Big)^{-\frac{n+1}{2}},
\end{equation}
para \(x\in (-\infty,\infty)\). Mostramos a forma desta função de densidade, quando \(n=3\), na figura abaixo à esquerda.
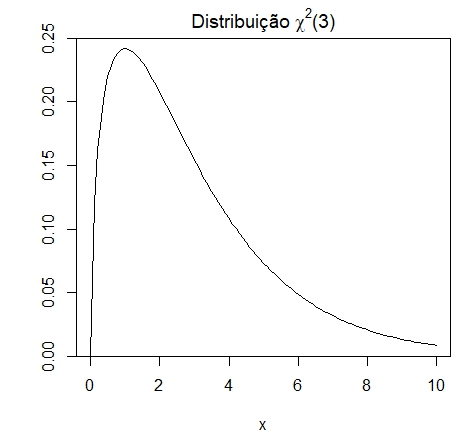
Exemplo. Seja \(X\sim \chi^2(n)\), ou seja, seja \(X\) uma variável aleatória com
distribuição qui-quadraado com \(n\) graus de liberdade. Isto significa que \(X\) tem por função de
densidade
\begin{equation}
f(x)=\dfrac{1}{\Gamma\big(\frac{n}{2}\big)2^{n/2}} e^{-x/2} x^{n/2-1},
\end{equation}
para \(x\in (0,\infty)\). Mostramos a forma desta função de densidade, quando \(n=3\), na figura acima à direita.
Grosseiramente falando, um procedimento não-paramétrico é um procedimento estatístico que possui certas
propriedades desejáveis que mantêm suposições relativamente leves em relação às
populações subjacentes das quais os dados são obtidos. O desenvolvimento repetido e contínuo de
procedimentos estatísticos não paramétricos nas últimas décadas deve-se às seguintes vantagens de
técnicas não paramétricas:
- 1- Métodos não-paramétricos exigem poucas suposições sobre as populações subjacentes
das quais os dados são obtidos. Em particular, os procedimentos não paramétricos abandonam a suposição tradicional de
que as populações subjacentes sejam normais.
- 2- Os procedimentos não paramétricos permitem que o usuário obtenha p-valores exatos para testes, probabilidades
de cobertura exatas para intervalos de confiança, taxas exatas de erros experimentais para procedimentos de comparação múltipla
e probabilidades exatas de cobertura para faixas de confiança sem confiar nas suposições de que as populações
subjacentes sejam normais.
- 3- As técnicas não paramétricas são frequentemente, embora nem sempre, mais fáceis de aplicar do que as
suas contrapartes teóricas normais.
- 4- Os procedimentos não paramétricos são geralmente muito fáceis de entender.
- 5- Embora, à primeira vista, a maioria dos procedimentos não-paramétricos pareça sacrificar muito as
informações básicas nas amostras, as investigações de eficiência teórica mostraram que esse não
é o caso. Normalmente, os procedimentos não-paramétricos são apenas ligeiramente menos eficientes do que os seus concorrentes
de teoria normal quando as populações subjacentes são normais e podem ser moderadamente ou muito mais eficientes que os concorrentes
quando as populações subjacentes não são normais.
- 6- Métodos não paramétricos são relativamente insensíveis a observações distantes.
- 7- Os procedimentos não paramétricos são aplicáveis em muitas situações em que os procedimentos teóricos
normais não podem ser utilizados. Muitos procedimentos não-paramétricos exigem apenas as classificações das
observações em vez da magnitude real das observações, enquanto os procedimentos paramétricos exigem as magnitudes.
A Parte I é dedicada ao problema da estimação não-paramétrica e estimação
da função de densidade. A Parte II trata de alguns problemas comuns de teste de hipóteses para uma
única amostra, dentre eles a verificação da normalidade dos resíduos. Na Parte III consideramos
testes de hipóteses para o caso de duas ou mais amostras.
Como suporte computacional utilizamos a linguagem de programação e ambiente de desenvolvimento integrado para cálculos estatísticos
e gráficos R, última versão 3.5.2, Eggshell Igloo de 20 de dezembro de 2018.
Parte I. Estimação não paramétrica
- Estimação de densidades
- Exercícios
Parte II. Problemas de amostra única
- Testes de bondade de ajuste
- Teste qui-quadrado
- Teste Kolmogorov-Smirnov
- Teste Lilliefors
- Teste Cramér-von Mises
- Teste Anderson-Darling
- Teste Jarque-Bera
- Análise visual
- O problema de posição
- O teste do sinal
- Teste de Wilcoxon
- Testes de aleatoriedade
- Teste baseados no número total de corridas
- Momentos de \(R\) na distribuição nula
- Distribuição nula de \(R\) assintótica
- Teste baseado nos postos
- Métodos de reamostragem
- Jackknife
- O estimador jackknife do vício
- O estimador jackknife da variância
- Bootstrap
- Descriçãção do método bootstrap
- Intervalos confidenciais bootstrap
- Exercícios
Parte III: Procedimentos em \(k\) amostras
- Procedimentos de amostra única e com amostras pareadas
- Intervalo de confiança para o quantil populacional
- Teste de hipótese para um quantil populacional
- Procedimento com amostras pareadas
- O problema geral de duas amostras
- Teste de Wald-Wolfowitz
- Teste Kolmogorov-Smirnov para duas amostras
- O teste da mediana
- Teste \(U\) de Mann-Whitney
- Medidas de Associação em Classificações Múltiplas
- Extensão do teste da mediana
- Análise de Variância por postos de Friedman
- Comparações Múltiplas Não Paramétricas e Intervalos de Confiança Simultâneos
- Coeficientes de correlação
- Coeficiente de correlação de Kendall
- Coeficiente de correlação de Spearman
- Exercícios
Parte IV: Regressão Não Paramétirca
- Revisão do modelo de regressão linear
- Regressão associada ao coeficiente de correlação \(\tau_K\) de Kendall
- Suavizamento linear
- Avaliando a qualidade do ajuste
- Escolhendo o parâmetro de suavização
- Regressão local
- Polinômios locais
- Splines
- Estimação da variância
- Bandas de confiança
- Cobertura média
- Regressão múltipla
- Regressão local
- Modelos aditivos
- Splines bidimensionais
- Prospeção de Projeção
- Árvores de regressão
- Exercícios
Parte V: Redes neurais
- Regressão por prospeção de projeção
- Redes neurais
- Ajuste de redes neurais
- Alguns problemas no treinamento de redes neurais
- Valores iniciais
- Sobreajuste
- Dimensionamento das entradas
- Número de unidades e camadas ocultas
- Múltiplos mínimos
- Exemplos
Referências
- Kloke, J. and McKean, J.W. (2015). Nonparametric Statistical Methods Using R. Taylor & Francis Group, LLC.
- Hollander, M., Wolfe, D.A. and Chicken, E. (2014). Nonparametric Statistical Methods. John Wiley & Sons, Inc.
- Fraser, D.A.S. (1965). Nonparametric Methods is Statistics. John Wiley, Inc.
- Conover, W.J. (1971). Practical Nonparametric Statistics. John Wiley & Sons.
- Gibbons, J.D. and Chakraborti, S. (2010). Nonparametric Statistical Inference. Chapman and Hall/CRC.
- Miller, L.H. (1956). Table of percentage points of Kolmogorov statistic. Journal of the American Statistical Association, 51, pp. 111-121.
- Owen, D.B. (1962). Handbook of Statistical Tables. Addison-Wesley, Reading.
- Birnbaum, Z.W. (1952). Numerical tabulation of the distribution of Kolmogorov's statistic for finite sample size. Journal of the American Statistical Association, 17, pp. 425-441.
- Birnbaum, Z.W. & Tingey, F.H. (1951). One-sided confidence contours for probability distribution functions. Annals of Mathematical Statistics, 22, pp. 592-596.
- Smirnov, N.V. (1944). Approximate laws of distribution of random variables from empirical data. Uspekhi Matematicheskikh Nauk, 10, pp. 179-206.
- Hope, A.C.A. (1968). A simplified Monte Carlo significance test procedure. Journal of the Royal Statistical Society, Series B, 30, pp. 582-598.
- Chernoff, H. and Lehmann, E. L. (1954). The use of the maximum likelihood estimate in \(\chi^2\) tests for goodness of fit. Annals of Mathematical Statistics, 25, pp. 579-589.
- Thode, H.C. (2002). Testing for Normality. Marcel Dekker, New York.
- Lilliefors, H.W. (1967). On the Kolmogorov-Smirnov test for normality with mean and variance unknown. Journal of the American Statistical Association, 62, pp. 399-402.
- Dallal, G.E. and Wilkinson, L. (1986). An analytical approximation to the distribution of Lilliefors's test statistic for normality. The American Statistician, 40, 4, pp. 294-296.
- Stephens, M.A. (1974). EDF statistics for goodness of fit and some comparisons. Journal of the American Statistical Association, 69, pp. 730-737.
- Anderson, T.W. and Darling, D.A. (1954). A test of goodness of fit. Journal of the American Statistical Association 49, 765-769.
- Marsaglia, G. and Marsaglia, J. (2004). Evaluating the Anderson-Darling Distribution. Journal of Statistical Software, 9 (2), 1-5.
- Lewis, P.A.W. (1961). Distribution of the Anderson-Darling statistic. Annals of Mathematical Statistics, 32, pp. 1118-1124.
- Bowman, K. and Shenton, L.R. (1975). Omnibus contours for departures from normality based on \(\sqrt{b_1}\) and \(b_2\). Biometrika, 62, pp. 243-250.
- Jarque, C. and Bera, A. (1987). A test for normality of observations and regression residuals. International Statistical Review, 55, pp. 163-172
- Sturges, H.A. (1929). The Choice of a Class Interval. Journal of the American Statistical Association, 21, pp. 65-66.
- Scott, D.W. (1979). On Optimal and Data-Based Histograms. Biometrika, 66, pp. 605-610.
- Mann, H.B. and Whitney, D.R. (1947). On a test whether one or two random variables is stochastically larger than the other. The Annals of Mathematical Statistics, 18, pp. 50-60.
- Berry, A.C. (1941). The accuracy of the Gaussian approximation to the sum of independent variates. Transactions of the American Mathematical Society, 49, pp. 122-136.
- Essen, C.G. (1942). ON the Liapounoff limit of error in the theory of probability. Arkiv för matematik, astronomi och fysik, 28A, pp. 1-19.
- Friedman, M. (1937). The use of ranks to avoid the assumption of normality implicit in the analysis of variance. Journal of the American Statistical Association, 32, pp. 675-701.
- Friedman, M. (1940). A comparison of alternative tests of significance for the problem of m rankings. Annals of Mathematical Statistics, 11, pp. 86-92.
- Hollander, M. & D. A.Wolfe (1999). Nonparametric Statistical Methods, 2nd ed., John Wiley & Sons, New York.
- Kendall, M.G. & Smith, B.B. (1939). The problem of m rankings. Annals of Mathematical Statistics, 10, pp. 275-287.
- Spearman, C. E. 1904. The proof and measurement of association between two things. American Journal of Psychology, 15, pp. 72-101
- Tukey, J.W. (1958). Bias and confidence in not quite large samples. Annals of Mathematical Statistics. 29, p. 614.
- Efron, B. (1982). The Jackknife, the Bootstrap and Other Resampling Plans. Philadelphia: SIAM.
- Efron, B. & Tibshirani, R.J. (1993). An Introduction to the Bootstrap. New York: Chapman and Hall.
- Quenouille, M. (1949). Approximate tests of correlation in time series. Journal of the Royal Statistical Society, Series B. 11, pp.18-44.
- Babu, G. J. & Singh, K. (1983). Inference on means using the bootstrap. Annals of Statistics, 11, pp. 999-1003.
- Wald, A. & Wolfowitz, J. (1940). On a test whether two samples are from the same population. Annals of Mathematical Statistics, 11, pp.147-162.
- Wolfowitz, J. (1949). Nonparametric statistical inference, pp.93-113, in J. Neyman, ed., Proceedings of the Berkeley Symposium on Mathematical Statistics and Probability, University of California Press, Berkeley.
- Gnedenko, B.V. (1954). Tests of homogeneity of probability distributions in two independent samples (in Russian). Doklody Akademii Nauk SSSR, 80, pp.525-528.
- Korolyuk, V.S. (1961)., On the discrepancy of empiric distributions for the case of two independent samples. Selected Translations in Mathematical Statistics and Probability, 1, pp.105-121.
- Massey, F.J. (1951). The distribution of the maximum deviation between two sample cumulative step functions. Annals of Mathematical Statistics, 22, pp.125-128.
- Massey, F.J. (1952). Distribution table for the deviation between two sample cumulatives. Annals of Mathematical Statistics, 23, pp.435-441.
- Drion, E.F. (1952). Some distribution free tests for the difference between two empirical cumulative distributions. Annals of Mathematical Statistics, 23, pp.563-574.
- Hodges, J.L., Jr. (1958). The significance probability of the Smirnov two sample test. Arkiv foer Matematik, Astronomi och Fysik, 3, pp.469-486.
- Konietschke, F. (2015). nparcomp: Perform Multiple Comparisons and Compute Simultaneous Confidence Intervals for the Nonparametric Relative Contrast Effects. R package version 2.6, URL http://CRAN.R-project.org/package=nparcomp.
- Dunnett, C.W. (1955). A Multiple Comparison Procedure for Comparing Several Treatments with a Control. Journal of the American Statistical Association, 50(272), pp.1096-1121.
- Tukey, J.W. (1953). The Problem of Multiple Comparisons. Unpublished manuscript reprinted in The Collected Works of John W. Tukey, Volume VIII, Chapman and Hall, London.
- Carvalho, L. (2015). An Improved Evaluation of Kolmogorov's Distribution. Journal of Statistical Software, 65(3), pp.1-7. URL http://www.jstatsoft.org/v65/c03/.
- Wang, J., Tsang W.W. & Marsaglia, G. (2003). Evaluating Kolmogorov's Distribution. Journal of Statistical Software, 8(18), pp.1-4. URL http://www.jstatsoft.org/v08/i18/.
- Durbin, J. (1973). Distribution Theory for Tests Based on the Sample Distribution Function, 9. Society for Industrial Mathematics.
- Bartels, R. (1982). The rank version of von Neumann’s ratio test for randomness. Journal of the American Statistical Association, 77, pp.40-46.
- Wald, A. & Wolfowitz, J. (1943). An exact test for randomness in the nonparametric case based on serial correlation. Annals of Mathematical Statistics, 14, pp.378-388.
- Mann, H.B. & Whitney, D.R. (1947). On a test whether one of two random variables is stochastically larger than the other. Annals of Mathematical Statistics, 18, pp.50-60.
- Brown, T.S. & Evans, J.K. (1986). Hemispheric dominance and recall follwing graphical and tabular presentation of information. Proceedings of the 1986 Annual Meeting of the Decision Sciences Institute, 1, pp.595-598.
- Oden, D.L., Thompson, R.K.R. & Premack, D. (1988). Spontaneous matching by infant chimpanzees. Journal of Experimental Psychology, 14, pp.140-145.
- Andrews, J.C. (1989). The dimensionality of beliefs toward advertising in general. Journal of Advertising, 18, pp.26-35.
- Mood, A.M. (1950). Introduction to the Theory of Statistics. McGraw-Hill Book Company, New York, pp.394-406.
- Brown, G.W. & Mood, A.M. (1948). Homogeneity of several samples. The American Statistician, 2, p.22.
- Brown, G.W. & Mood, A.M. (1951). On median tests for linear hypotheses, pp.159–166, in J. Neyman, ed., Proceedings of the Second Berkeley Symposium on Mathematical Statistics and Probability, University of California Press, Berkeley.
- Pagan, A. & Ullah, A. (1999). Nonparametric Econometrics. Cambridge University Press, New York.
- Scheffé, H. (1959). The Analysis of Variance. Wiley. New York.
- Fan, J. and Gijbels, I. (1996). Local polynomial modelling and its applications. Chapman & Hall, London.
- Härdle, W., Hall, P. and Marron, J. S. (1988). How far are automatically chosen regression smoothing parameters from their optimum? Journal of the American Statistical Association, 83, pp.86–95.
- Scott, D.W. (1992). Multivariate Density Estimation: Theory, Practice and Visualization. Wiley. New York, NY.
- Rice, J. (1984). Bandwidth choice for nonparametric regression. The Annals of Statistics, 12, pp.1215-1230.
- Sun, J. and Loader, C.R. (1994). Simultaneous confidence bands for linear regression and smoothing. The Annals of Statistics, 22, pp. 1328-1345.
- Gasser, T., Sroka, L. and Jennen-Steinmetz, C. (1986). Residual variance and residual pattern in nonlinear regression. Biometrika, 73, pp.625-633.
- Yu, K. and Jones, M. (2004). Likelihood-based local linear estimation of the conditional variance function. Journal of the American Statistical Association, 99, pp.139–144.
- Fan, J. (1992). Design-adaptive nonparametric regression. Journal of the American Statistical Association, 87, pp.998-1004.
- Hastie, T. and Loader, C. (1993). Local regression: Automatic kernel carpentry. Statistical Science, 8, pp.120-129.
- Wahba, G. (1990). Spline models for observational data. SIAM. New York, NY.
- Hastie, T., Tibshirani, R. and Friedman, J.H. (2001). The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer-Verlag. New York, NY.
- Marron, J.S. and Chung, S.S. (1997). Presentation of smoothers: the family approach, unpublished manuscript.
- Ruppert, D. and Wand, M.P. (1994). Multivariate locally weighted least squares regression. The Annals of Statistics, 22, pp.1346–1370.
- Hayfield T. and Racine, J.S. (2008). Nonparametric Econometrics: The np Package. Journal of Statistical Software, 27(5). URL http://www.jstatsoft.org/v27/i05/.
- Green, P.J. and Silverman, B.W. (1994). Nonparametric regression and generalized linear models: a roughness penalty approach. Chapman and Hall. New York, NY.
- Friedman, J.H. and Stuetzle, W. (1981). Projection pursuit regression. Journal of the American Statistical Association 76, pp.817-823.
- Morgan, J.N. and Sonquist, J.A. (1963). Problems in the analysis of survey data, and a proposal. Journal of the American Statistical Association, 58, pp.415-434.
- Breiman, L., Friedman, J. H., Olshen, R.A. and Stone, C.J. (1984). Classification and regression trees. Wadsworth. New York, NY.
- Hastie, T., Tibshirani, R. and Friedman, J.H. (2001). The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer-Verlag. New York, NY.
- Venables, W.N. and Ripley, B.D. (2002). Modern Applied Statistics with S. Springer-Verlag. New York, NY.
- Faraway, J.J. and Sun, J. (1995). Simultaneous confidence bands for linear regression with heteroscedastic errors. Journal of the American Statistical Association, 90, pp.1094-1098.
- Theil, H. (1950). A rank invariant method of linear and polynomial regression analysis, I, II, III. Proc. Kon. Nederl. Akad. Wetensch. A, 53, pp.386-392, pp.521–525, pp.1397–1412.
- Sen, P.K. (1968). Estimates of the regression coefficient based on Kendall’s tau. J. Amer. Statist. Assoc., 63, pp.1379–1389.
- Maritz, J.S. (1995). Distribution-free Statistical Methods. 2nd edn. London: Chapman & Hall.