|
|
Modelos de Regressão Não LinearFundamentos e Aplicações em R |
Alternativas para facilitar o ajuste de modelos não lineares
1 Informação de gradiente
library(lattice)
library(latticeExtra)
library(rootSolve)
llayer <- latticeExtra::layer#-----------------------------------------------------------------------
# Usar a informação de gradientes, em geral, acelera o procedimento de
# estimação. Para usar informação de gradiente função precisa ter um
# atributo gradiente.
data(wtloss, package = "MASS")
str(wtloss)## 'data.frame': 52 obs. of 2 variables:
## $ Days : int 0 4 7 7 11 18 24 30 32 43 ...
## $ Weight: num 184 183 180 180 178 ...p0 <- xyplot(Weight ~ Days, data = wtloss, col = 1,
xlab = "Dias em dieta",
ylab = "Peso (kg)")
p0 +
llayer(with(list(f0 = 81, f1 = 102, K = 141),
panel.curve(f0 + f1 * 2^(-x/K), add = TRUE, col = 2)))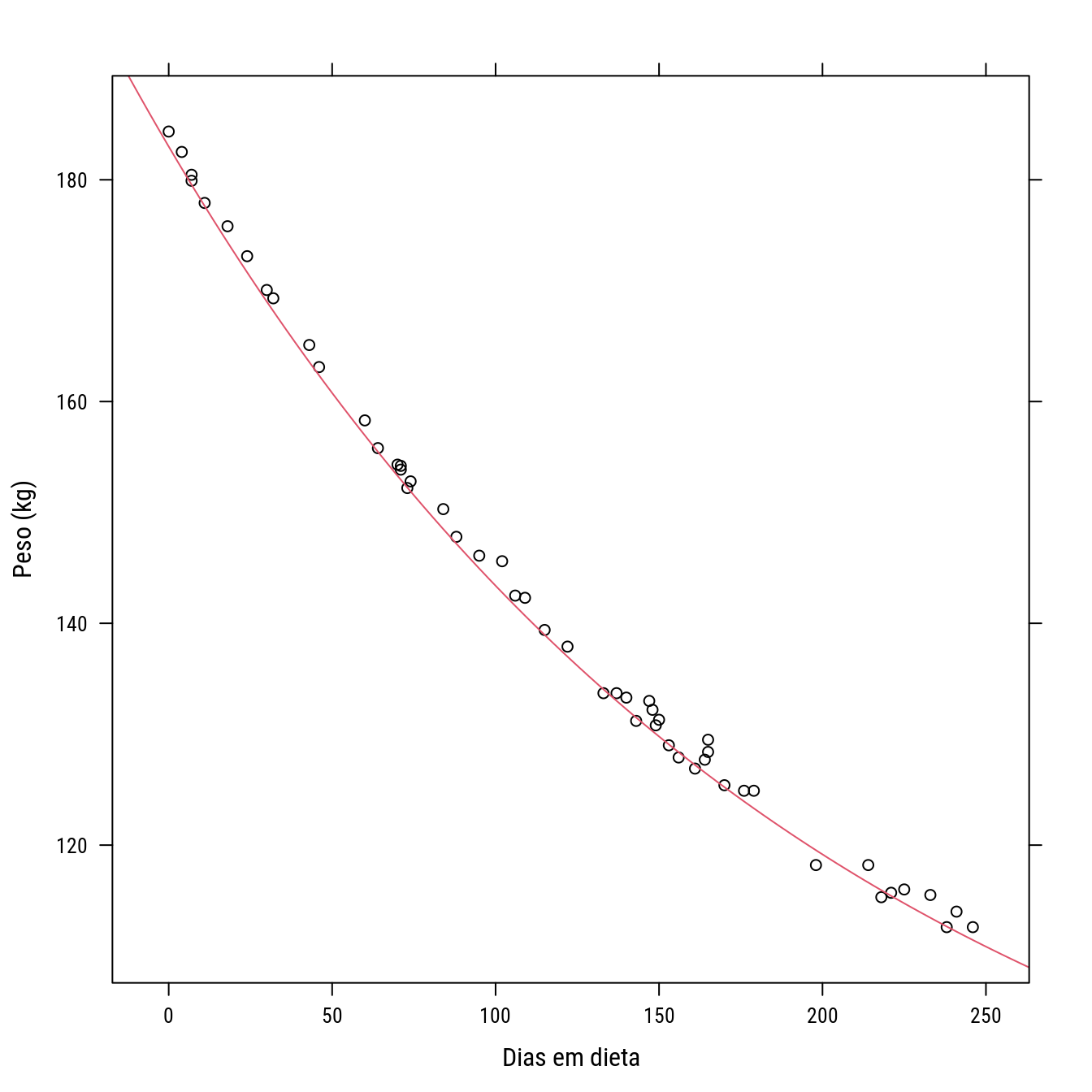
#-----------------------------------------------------------------------
# Modelo (é uma parametrização do monomolecular para tempo de meia vida)
# f0 + f1 * 2^(-x/K)
# * f0: assíntota, peso final após estabilização
# * f1: total de peso à perder, f0+f1 é intercepto ou peso inicial
# * K: tempo necessário para se perder metade do passível de perder,
# 0.5*(f1-f0)
# Para passar o gradiente tem-se que conhecer as derivadas do modelo com
# relação à cada parâmetro.
model <- expression(f0 + f1 * 2^(-x/K))
pars <- c("f0","f1","K")
sapply(pars, D, expr = model)## $f0
## [1] 1
##
## $f1
## 2^(-x/K)
##
## $K
## f1 * (2^(-x/K) * (log(2) * (x/K^2)))#-----------------------------------------------------------------------
# Agora precisa-se fazer uma função que avalie essas expressões em x e
# pars e passe isso como atributo "gradient".
modelfun <- function(x, f0, f1, K){
value <- f0 + f1 * 2^(-x/K)
attr(value, "gradient") <-
cbind(f0 = 1,
f1 = 2^(-x/K),
K = f1 * (2^(-x/K) * (log(2) * (x/K^2))))
return(value)
}
# Avalia a função.
modelfun(x = head(wtloss$Days), f0 = 81, f1 = 102, K = 141)## [1] 183.0000 181.0139 179.5497 179.5497 177.6308 174.3621
## attr(,"gradient")
## f0 f1 K
## [1,] 1 1.0000000 0.00000000
## [2,] 1 0.9805283 0.01394786
## [3,] 1 0.9661738 0.02405142
## [4,] 1 0.9661738 0.02405142
## [5,] 1 0.9473608 0.03705915
## [6,] 1 0.9153151 0.05859095#-----------------------------------------------------------------------
# Agora é só usar.
# Com informação de gradiente analítico.
n0 <- nls(Weight ~ modelfun(Days, f0, f1, K),
data = wtloss,
start = list(f0 = 60, f1 = 200, K = 41),
trace = TRUE)## 120543.9 : 60 200 41
## 5548.131 : 110.93529 70.05107 53.85617
## 383.9489 : 103.75522 78.74353 94.21701
## 57.24169 : 87.86922 96.00670 129.93709
## 39.34297 : 81.76984 102.28013 141.25126
## 39.2447 : 81.37412 102.68369 141.91071
## 39.2447 : 81.37382 102.68412 141.91036summary(n0)##
## Formula: Weight ~ modelfun(Days, f0, f1, K)
##
## Parameters:
## Estimate Std. Error t value Pr(>|t|)
## f0 81.374 2.269 35.86 <2e-16 ***
## f1 102.684 2.083 49.30 <2e-16 ***
## K 141.910 5.295 26.80 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.8949 on 49 degrees of freedom
##
## Number of iterations to convergence: 6
## Achieved convergence tolerance: 3.134e-08# Sem informação de gradiente analítico.
n1 <- nls(Weight ~ f0 + f1 * 2^(-Days/K),
data = wtloss,
start = list(f0 = 60, f1 = 200, K = 41),
trace = TRUE)## 120543.9 : 60 200 41
## 5548.131 : 110.93529 70.05107 53.85617
## 383.9489 : 103.75522 78.74353 94.21701
## 57.24169 : 87.86922 96.00670 129.93709
## 39.34297 : 81.76983 102.28013 141.25126
## 39.2447 : 81.37412 102.68369 141.91071
## 39.2447 : 81.37382 102.68412 141.91037summary(n1)##
## Formula: Weight ~ f0 + f1 * 2^(-Days/K)
##
## Parameters:
## Estimate Std. Error t value Pr(>|t|)
## f0 81.374 2.269 35.86 <2e-16 ***
## f1 102.684 2.083 49.30 <2e-16 ***
## K 141.910 5.295 26.80 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.8949 on 49 degrees of freedom
##
## Number of iterations to convergence: 6
## Achieved convergence tolerance: 3.19e-08# NOTA: para o presente exemplo não houve diferença em número de passos
# porque a função é muito simples.
#-----------------------------------------------------------------------
# A forma mais rápida de passar informação de gradiente é usar a função
# `deriv3()`. Tem esse nome porque faz as derivadas do modelo com
# relação aos parâmetros e retorna a avaliação de 3 funções avaliadas em
# x e theta: 1) modelo (f(x)), 2) o gradiente (df(x)/dtheta) e 3) o
# hessiano (d²f(x)/dtheta²). As derivadas são analíticas. Sendo assim, a
# `deriv3()` não sabe derivar modelos com segmentados pois não sabe
# interpretar as inequações do tipo x <= x0, por exemplo.
modelfun <- deriv3(expr = ~f0 + f1 * 2^(-x/K),
namevec = c("f0", "f1", "K"),
function.arg = function(x, f0, f1, K) NULL)
# Veja que retorna 2 atributos: gradient e hessian.
modelfun## function (x, f0, f1, K)
## {
## .expr3 <- 2^(-x/K)
## .expr6 <- log(2)
## .expr7 <- K^2
## .expr9 <- .expr6 * (x/.expr7)
## .expr10 <- .expr3 * .expr9
## .value <- f0 + f1 * .expr3
## .grad <- array(0, c(length(.value), 3L), list(NULL, c("f0",
## "f1", "K")))
## .hessian <- array(0, c(length(.value), 3L, 3L), list(NULL,
## c("f0", "f1", "K"), c("f0", "f1", "K")))
## .grad[, "f0"] <- 1
## .grad[, "f1"] <- .expr3
## .hessian[, "f1", "f1"] <- 0
## .hessian[, "f1", "K"] <- .hessian[, "K", "f1"] <- .expr10
## .grad[, "K"] <- f1 * .expr10
## .hessian[, "K", "K"] <- f1 * (.expr10 * .expr9 - .expr3 *
## (.expr6 * (x * (2 * K)/.expr7^2)))
## attr(.value, "gradient") <- .grad
## attr(.value, "hessian") <- .hessian
## .value
## }modelfun(x = head(wtloss$Days), f0 = 81, f1 = 102, K = 141)## [1] 183.0000 181.0139 179.5497 179.5497 177.6308 174.3621
## attr(,"gradient")
## f0 f1 K
## [1,] 1 1.0000000 0.00000000
## [2,] 1 0.9805283 0.01394786
## [3,] 1 0.9661738 0.02405142
## [4,] 1 0.9661738 0.02405142
## [5,] 1 0.9473608 0.03705915
## [6,] 1 0.9153151 0.05859095
## attr(,"hessian")
## , , f0
##
## f0 f1 K
## [1,] 0 0 0
## [2,] 0 0 0
## [3,] 0 0 0
## [4,] 0 0 0
## [5,] 0 0 0
## [6,] 0 0 0
##
## , , f1
##
## f0 f1 K
## [1,] 0 0 0.0000000000
## [2,] 0 0 0.0001367437
## [3,] 0 0 0.0002357982
## [4,] 0 0 0.0002357982
## [5,] 0 0 0.0003633250
## [6,] 0 0 0.0005744211
##
## , , K
##
## f0 f1 K
## [1,] 0 0.0000000000 0.0000000000
## [2,] 0 0.0001367437 -0.0001958968
## [3,] 0 0.0002357982 -0.0003352850
## [4,] 0 0.0002357982 -0.0003352850
## [5,] 0 0.0003633250 -0.0005114491
## [6,] 0 0.0005744211 -0.0007943076#-----------------------------------------------------------------------
# Alguns modelos não lineares possuem operadores/funções que não estão
# na tabela de derivadas considerada pela `deriv3()`. Um exemplo é o
# modelo linear-platô que possui os operadores < e >= na função. Dessa
# forma não tem como usar informação de derivada analítica por meio da
# `deriv3()`. Pode-se fazer à mão ou pode-se empregar derivadas
# numéricas. A função `rootSolve::gradiente()` pode ser usada.
# Dá mensagem de erro!
# mlp <- deriv3(~f0 + tx * x * (x < xde) + tx * xde * (x >= xde) ,
# c("f0", "tx", "xde") ,
# function(x, f0, tx, xde) NULL)
f <- function(theta, xi) {
with(as.list(theta),
f0 + tx * xi * (xi < xde) + tx * xde * (xi >= xde))
}
f(c(f0 = 10, tx = 1, xde = 3), xi = 1:4)## [1] 11 12 13 13# É um gradiente numérico (rootSolve).
gradient(f,
x = c(f0 = 3, tx = 0.9, xde = 3.5),
xi = seq(0, 5, by = 0.5))## f0 tx xde
## [1,] 1 0.0 0.0
## [2,] 1 0.5 0.0
## [3,] 1 1.0 0.0
## [4,] 1 1.5 0.0
## [5,] 1 2.0 0.0
## [6,] 1 2.5 0.0
## [7,] 1 3.0 0.0
## [8,] 1 3.5 0.0
## [9,] 1 3.5 0.9
## [10,] 1 3.5 0.9
## [11,] 1 3.5 0.9#-----------------------------------------------------------------------
# Criando uma função cujo gradiente é obtido numericamente. Existe
# custo em obter gradiente numérico, melhor seria analítico.
modelfun.n <- function(x, f0, tx, xde) {
f <- function(theta, xi) {
with(as.list(theta),
f0 + tx * xi * (xi < xde) + tx * xde * (xi >= xde))
}
value <- f(theta = c(f0 = f0, tx = tx, xde = xde), xi = x)
attr(value, "gradient") <-
gradient(f,
x = c(f0 = f0, tx = tx, xde = xde),
xi = x)
return(value)
}
modelfun.n(x = seq(0, 5, by = 0.5), f0 = 3, tx = 0.9, xde = 3.5)## [1] 3.00 3.45 3.90 4.35 4.80 5.25 5.70 6.15 6.15 6.15 6.15
## attr(,"gradient")
## f0 tx xde
## [1,] 1 0.0 0.0
## [2,] 1 0.5 0.0
## [3,] 1 1.0 0.0
## [4,] 1 1.5 0.0
## [5,] 1 2.0 0.0
## [6,] 1 2.5 0.0
## [7,] 1 3.0 0.0
## [8,] 1 3.5 0.0
## [9,] 1 3.5 0.9
## [10,] 1 3.5 0.9
## [11,] 1 3.5 0.9#-----------------------------------------------------------------------
# Criando uma função cujo gradiente é obtido analiticamente.
modelfun.a <- function(x, f0, tx, xde){
f <- function(theta, xi) {
with(as.list(theta),
f0 + tx * xi * (xi < xde) + tx * xde * (xi >= xde))
}
xo <- x < xde
value <- f(theta = c(f0 = f0, tx = tx, xde = xde), xi = x)
attr(value, "gradient") <-
cbind(1,
x * (xo) + xde * (!xo),
0 * (xo) + tx * (!xo))
return(value)
}
modelfun.n(x = seq(0, 5, by = 0.5), f0 = 3, tx = 0.9, xde = 3.5)## [1] 3.00 3.45 3.90 4.35 4.80 5.25 5.70 6.15 6.15 6.15 6.15
## attr(,"gradient")
## f0 tx xde
## [1,] 1 0.0 0.0
## [2,] 1 0.5 0.0
## [3,] 1 1.0 0.0
## [4,] 1 1.5 0.0
## [5,] 1 2.0 0.0
## [6,] 1 2.5 0.0
## [7,] 1 3.0 0.0
## [8,] 1 3.5 0.0
## [9,] 1 3.5 0.9
## [10,] 1 3.5 0.9
## [11,] 1 3.5 0.9modelfun.a(x = seq(0, 5, by = 0.5), f0 = 3, tx = 0.9, xde = 3.5)## [1] 3.00 3.45 3.90 4.35 4.80 5.25 5.70 6.15 6.15 6.15 6.15
## attr(,"gradient")
## [,1] [,2] [,3]
## [1,] 1 0.0 0.0
## [2,] 1 0.5 0.0
## [3,] 1 1.0 0.0
## [4,] 1 1.5 0.0
## [5,] 1 2.0 0.0
## [6,] 1 2.5 0.0
## [7,] 1 3.0 0.0
## [8,] 1 3.5 0.9
## [9,] 1 3.5 0.9
## [10,] 1 3.5 0.9
## [11,] 1 3.5 0.9#-----------------------------------------------------------------------
# Avaliando os custos computacionais.
microbenchmark::microbenchmark(
a = modelfun.a(x = seq(0, 5, by = 0.5),
f0 = 3, tx = 0.9, xde = 3.5),
n = modelfun.n(x = seq(0, 5, by = 0.5),
f0 = 3, tx = 0.9, xde = 3.5),
times = 500)## Unit: microseconds
## expr min lq mean median uq max neval cld
## a 63.735 70.5305 94.79558 73.770 93.1915 554.345 500 a
## n 216.808 238.5580 319.48861 259.743 311.1210 1404.394 500 b#-----------------------------------------------------------------------
# Com isso podemos usar modelos não lineares que possuem funções
# densidade ou acumuladas de distribuições de probabilidade (orgiva na
# normal, beta, gama, etc), funções que possuem integral dentro, funções
# compostas (como linear-platô), etc. O gradiente numérico pode ser
# usado não só para `nls()` mas para `optim()` ou outras funções de
# otmização.2 Modelos parcialmente lineares
#-----------------------------------------------------------------------
# Um modelo é parcilamente linear quando fixando o valor de alguns
# parâmetros o modelo se torna um modelo linear. Os modelos dessa sessão
# são parcialmente lineares. O modelo para perda de peso, se conhecido
# K, ele se torna a equação da reta. O modelo quadrático centrado, se
# conhecido xc, se torna o modelo quadrático sem termo linear. Pode-se
# tirar vantagem do modelo parcilamente linear para estimação que passa
# ter 2 passos: 1) analítico para porção linear e 2) númerico para
# porção não linear. O custo computacional de um modelo não linear está
# na parte não linear que requer otimização numérica. Deixando parte dos
# parâmetros para serem estimados analíticamente reduz-se o número de
# dimensões da otimização numérica. Quando mais facilitarmos isso
# melhor.
#-----------------------------------------------------------------------
# Ajustando com `algorthm = "plinear"`
# f0 + f1 * 2^(-x/K)
# se K é conhecido então temos
# f0 + f1 * g(x)
# que é a equação da reta. O trabalho de otimização se reduz à estimar K
# pois f0 e f1 é calculado por (X'X)^{-1} X'y quando g(x) for conhecido.
# De 3 dimensões passa-se para 1.
data(wtloss, package = "MASS")
p0 <- xyplot(Weight ~ Days, data = wtloss,
xlab = "Dias em dieta",
ylab = "Peso (kg)")
p0 +
llayer(with(list(f0 = 81, f1 = 102, K = 141),
panel.curve(f0 + f1 * 2^(-x/K),
add = TRUE, col = 2)))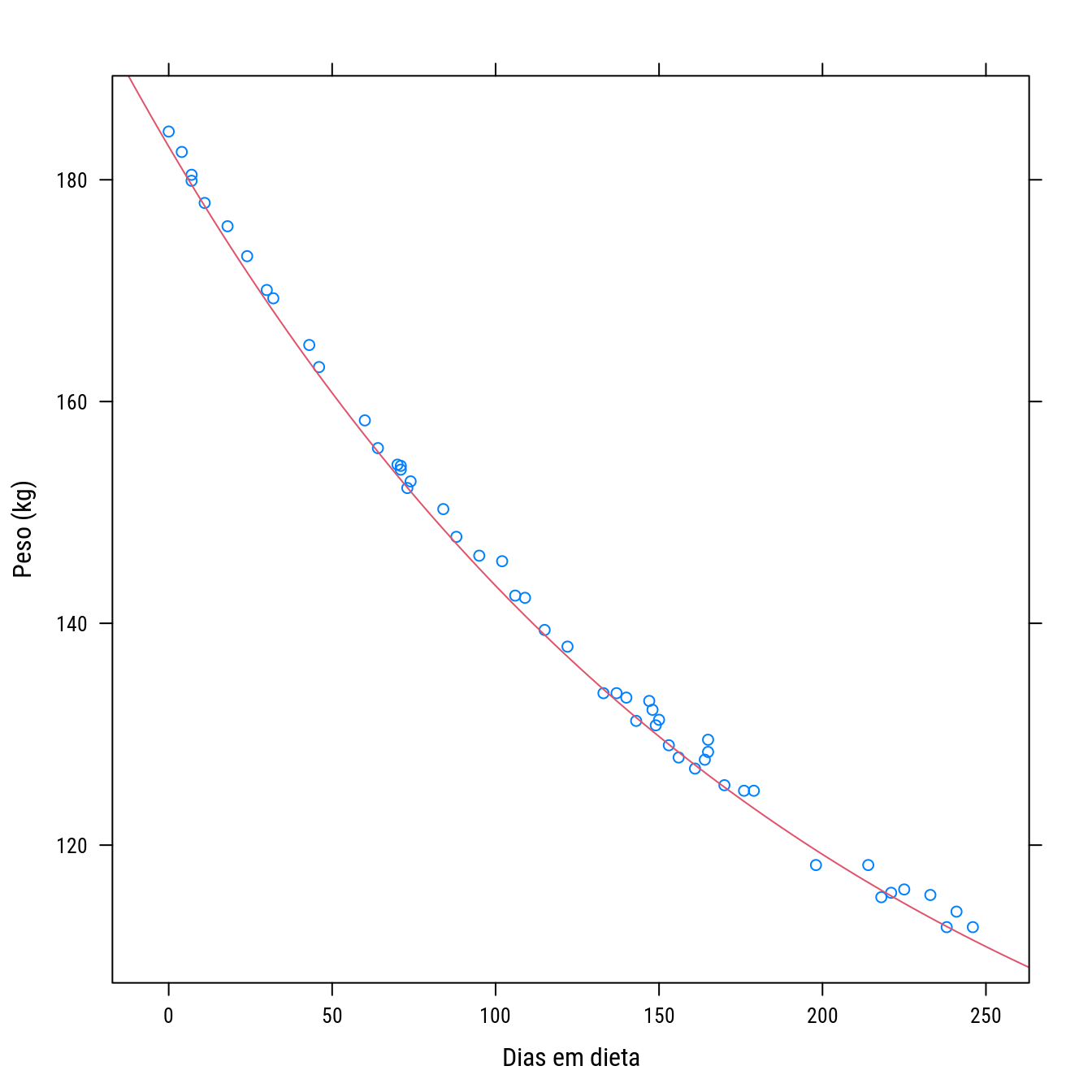
n0 <- nls(Weight ~ f0 + f1 * 2^(-Days/K),
data = wtloss,
start = list(f0 = 81, f1 = 102, K = 141),
trace = TRUE)## 87.49479 : 81 102 141
## 39.24471 : 81.3749 102.6829 141.9110
## 39.2447 : 81.37382 102.68411 141.91036summary(n0)##
## Formula: Weight ~ f0 + f1 * 2^(-Days/K)
##
## Parameters:
## Estimate Std. Error t value Pr(>|t|)
## f0 81.374 2.269 35.86 <2e-16 ***
## f1 102.684 2.083 49.30 <2e-16 ***
## K 141.910 5.295 26.80 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.8949 on 49 degrees of freedom
##
## Number of iterations to convergence: 2
## Achieved convergence tolerance: 1.47e-07# f0: df(x)/df0 = 1
# f1: df(x)/df1 = 2^(-Days/K)
# 2 parâmetros na parte analítica, 1 parâmetro na parte numérica.
n1 <- nls(Weight ~ cbind(f0 = 1, f1 = 2^(-Days/K)),
data = wtloss,
start = list(K = 141),
trace = TRUE,
algorithm = "plinear")## 39.26875 : 141.00000 81.75839 102.34194
## 39.2447 : 141.90792 81.37485 102.68320
## 39.2447 : 141.91037 81.37381 102.68412summary(n1)##
## Formula: Weight ~ cbind(f0 = 1, f1 = 2^(-Days/K))
##
## Parameters:
## Estimate Std. Error t value Pr(>|t|)
## K 141.910 5.295 26.80 <2e-16 ***
## .lin.f0 81.374 2.269 35.86 <2e-16 ***
## .lin.f1 102.684 2.083 49.30 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.8949 on 49 degrees of freedom
##
## Number of iterations to convergence: 2
## Achieved convergence tolerance: 8.722e-07# Perfil não disponível para plinear.
confint.default(n1)## 2.5 % 97.5 %
## K 131.53331 152.28744
## .lin.f0 76.92664 85.82098
## .lin.f1 98.60198 106.76626p0 +
llayer(with(as.list(coef(n0)),
panel.curve(f0 + f1 * 2^(-x/K),
add = TRUE, col = 2)))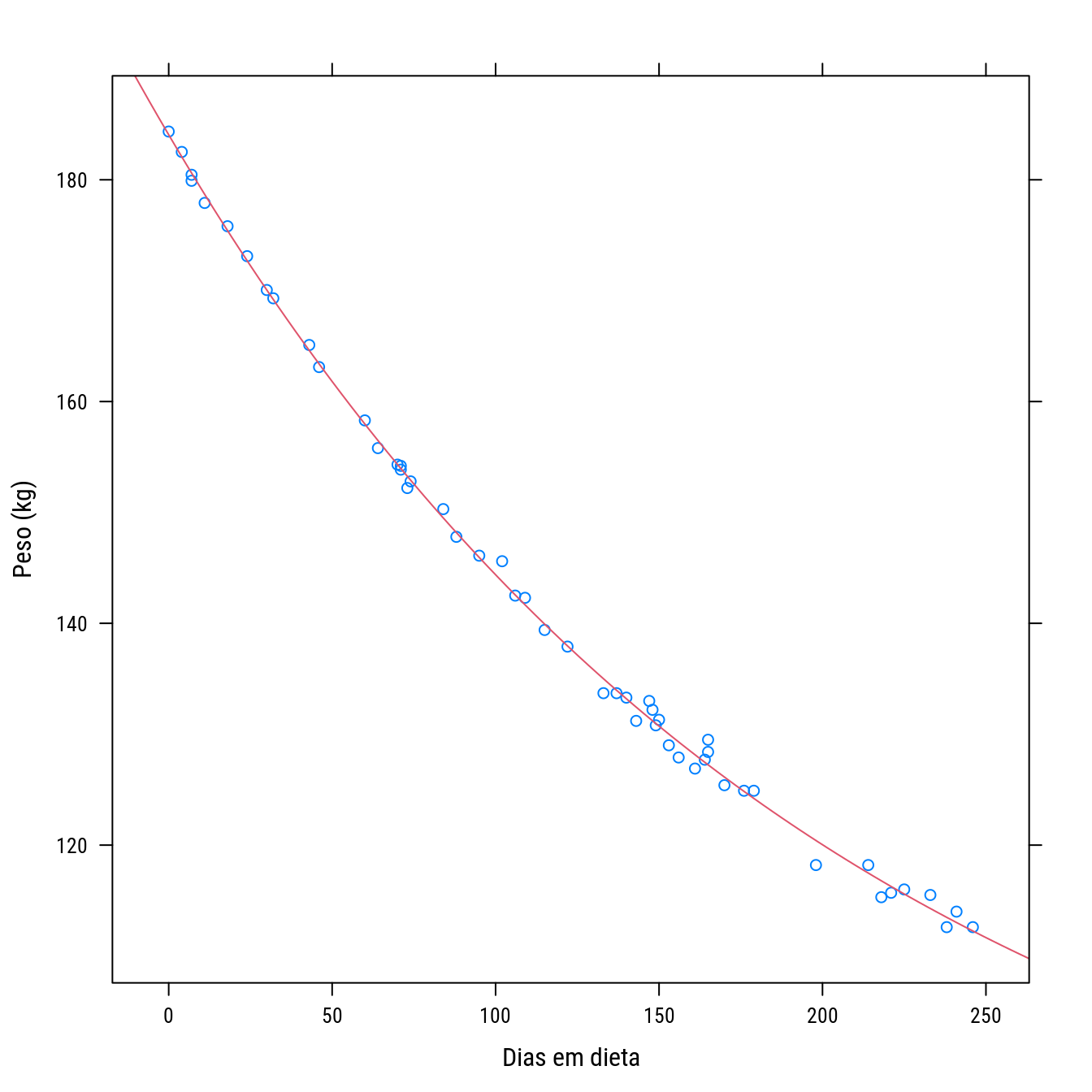
#-----------------------------------------------------------------------
# Usando para os dados de ganho de peso de peru.
data(turk0, package = "alr4")
str(turk0)## 'data.frame': 35 obs. of 2 variables:
## $ A : num 0 0 0 0 0 0 0 0 0 0 ...
## $ Gain: int 644 631 661 624 633 610 615 605 608 599 ...p1 <- xyplot(Gain ~ A, data = turk0, col = 1,
xlab = "Metionina",
ylab = "Ganho de peso")
p1 +
llayer(with(list(f0 = 620, f1 = 160, k = 9),
panel.curve(f0 + f1 * (1 - exp(-k * x)),
add = TRUE, col = 2)))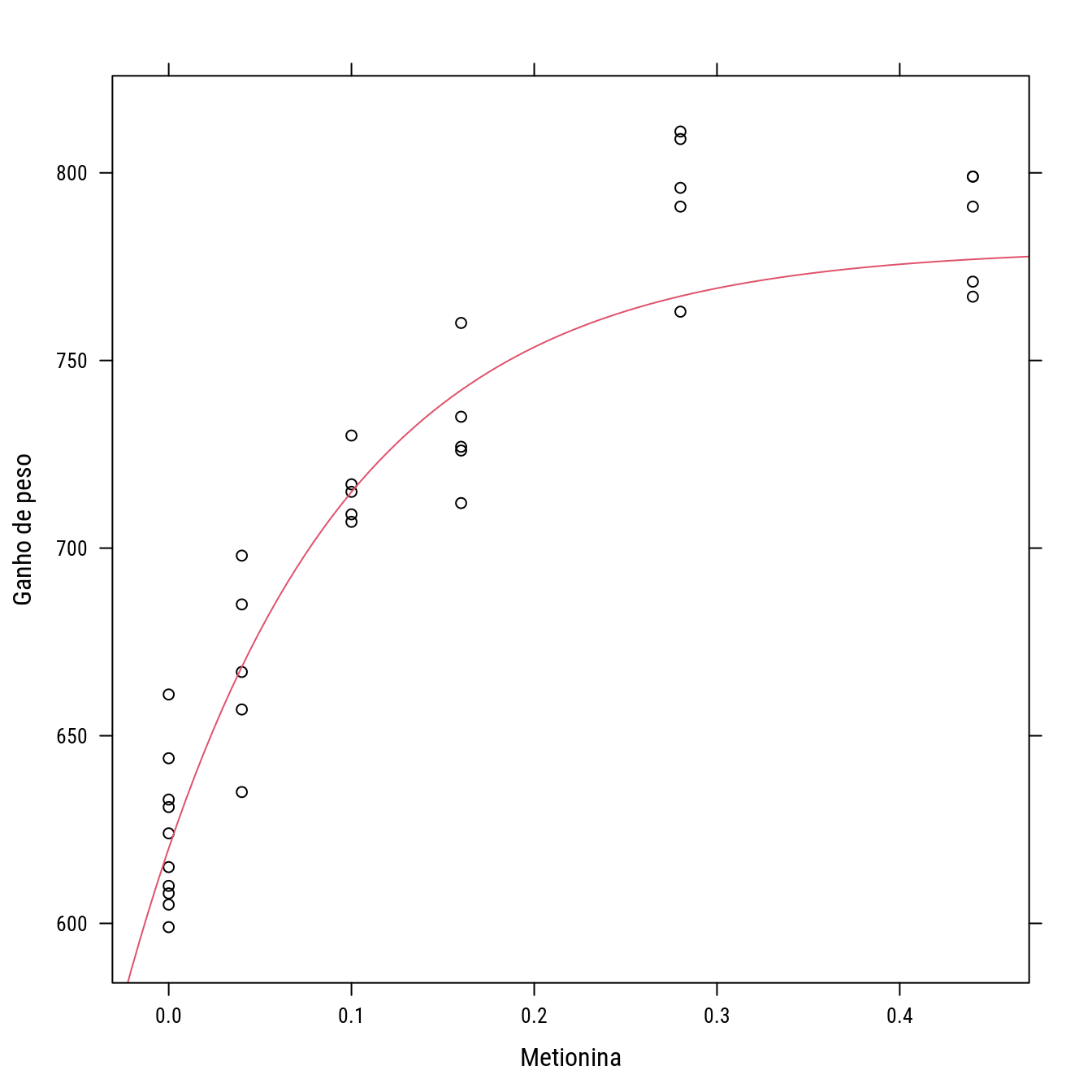
# Modelo monomolecular, na verdade é uma parametrização do anterior.
n0 <- nls(Gain ~ f0 + f1 * (1 - exp(-k * A)),
data = turk0,
start = list(f0 = 620, f1 = 160, k = 9))
summary(n0)##
## Formula: Gain ~ f0 + f1 * (1 - exp(-k * A))
##
## Parameters:
## Estimate Std. Error t value Pr(>|t|)
## f0 622.958 5.901 105.57 < 2e-16 ***
## f1 178.252 11.636 15.32 2.74e-16 ***
## k 7.122 1.205 5.91 1.41e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 19.66 on 32 degrees of freedom
##
## Number of iterations to convergence: 5
## Achieved convergence tolerance: 3.853e-06# f0: df(x)/df0 = 1
# f1: df(x)/df1 = 1 - exp(-k * A)
# 2 parâmetros na parte analítica, 1 parâmetro na parte numérica.
D(expression(f0 + f1 * (1 - exp(-k * A))), "k")## f1 * (exp(-k * A) * A)n1 <- nls(Gain ~ cbind(1, 1 - exp(-k * A)),
data = turk0,
start = list(k = 9),
trace = TRUE,
algorithm = "plinear")## 13227.65 : 9.0000 619.8563 169.2483
## 12393.93 : 6.822887 623.571298 180.124056
## 12367.55 : 7.143394 622.916003 178.125359
## 12367.42 : 7.120436 622.961583 178.262539
## 12367.42 : 7.12237 622.95774 178.25095
## 12367.42 : 7.122209 622.958057 178.251915summary(n1)##
## Formula: Gain ~ cbind(1, 1 - exp(-k * A))
##
## Parameters:
## Estimate Std. Error t value Pr(>|t|)
## k 7.122 1.205 5.91 1.41e-06 ***
## .lin1 622.958 5.901 105.57 < 2e-16 ***
## .lin2 178.252 11.636 15.32 2.74e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 19.66 on 32 degrees of freedom
##
## Number of iterations to convergence: 5
## Achieved convergence tolerance: 6.438e-06p1 +
llayer(with(as.list(coef(n0)),
panel.curve(f0 + f1 * (1 - exp(-k * x)),
add = TRUE, col = 2)))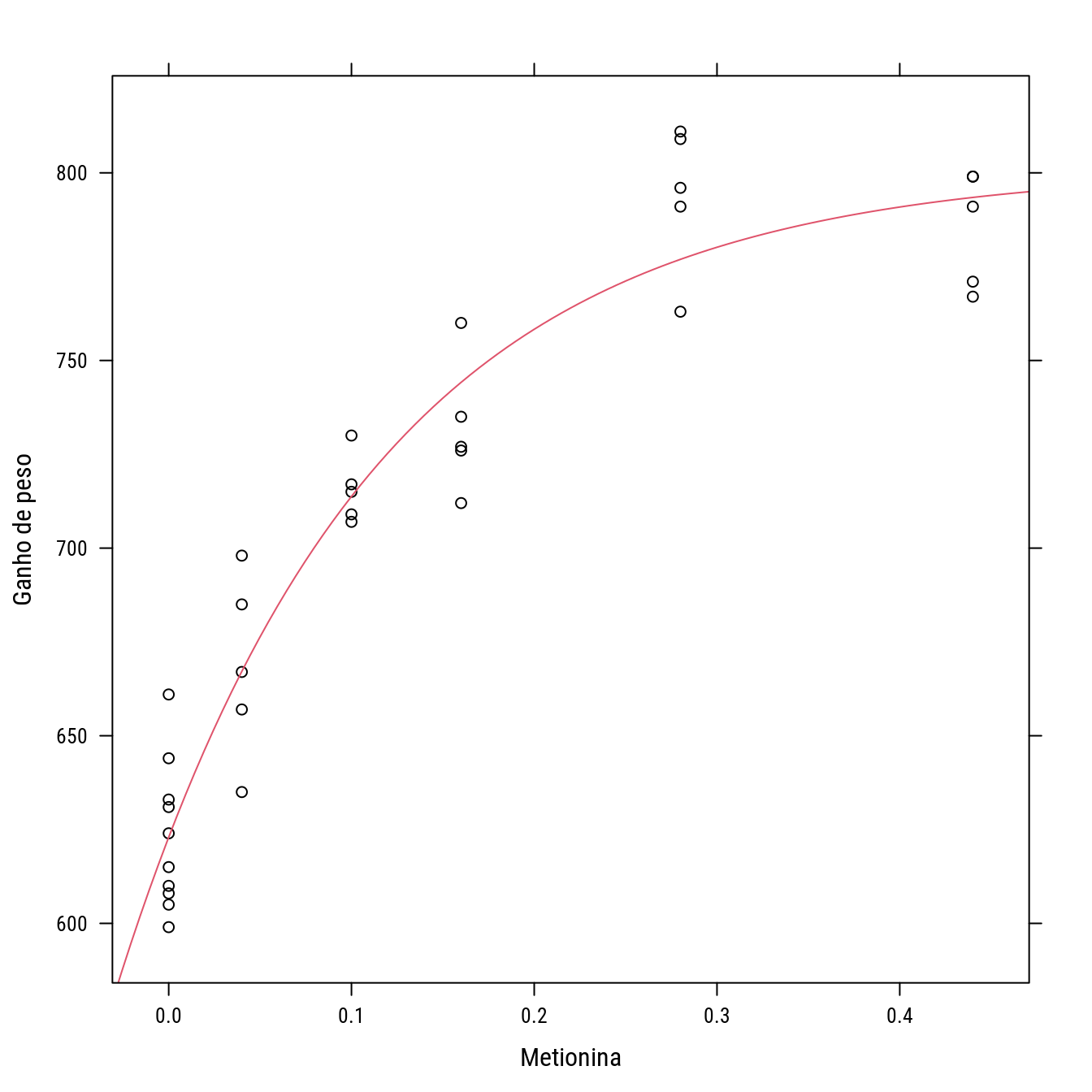
#-----------------------------------------------------------------------
# Modelo linear platô.
# b0: df(x)/db0 = 1
# b1: df(x)/db1 = x * (x < xb) + xb * (x >= xb)
# 2 parâmetros na parte analítica, 1 parâmetro na parte numérica.
n0 <- nls(Gain ~ b0 + b1 * A * (A < xb) + b1 * xb * (A >= xb),
data = turk0,
start = list(b0 = 600, b1 = 700, xb = 0.2),
trace = TRUE)## 60557 : 600.0 700.0 0.2
## 12736.14 : 629.6000000 713.3333333 0.2249048
## 12735.03 : 629.6000002 713.3333292 0.2244393n1 <- nls(Gain ~ cbind(b0 = 1, b1 = A * (A < xb) + xb * (A >= xb)),
data = turk0,
start = list(xb = 0.2),
trace = TRUE,
algorithm = "plinear")## 13618.1 : 0.2000 627.1939 787.2034
## 12742.28 : 0.222013 629.343549 720.398441
## 12735.03 : 0.2244153 629.5974606 713.4026302
## 12735.03 : 0.2244393 629.5999998 713.3333401summary(n1)##
## Formula: Gain ~ cbind(b0 = 1, b1 = A * (A < xb) + xb * (A >= xb))
##
## Parameters:
## Estimate Std. Error t value Pr(>|t|)
## xb 0.22444 0.01816 12.36 1.00e-13 ***
## .lin.b0 629.60000 5.55362 113.37 < 2e-16 ***
## .lin.b1 713.33334 64.38570 11.08 1.74e-12 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 19.95 on 32 degrees of freedom
##
## Number of iterations to convergence: 3
## Achieved convergence tolerance: 7.385e-08p1 +
llayer(with(as.list(coef(n0)),
panel.curve(b0 + b1 * x * (x < xb) +
b1 * xb * (x >= xb),
add = TRUE, col = 2)))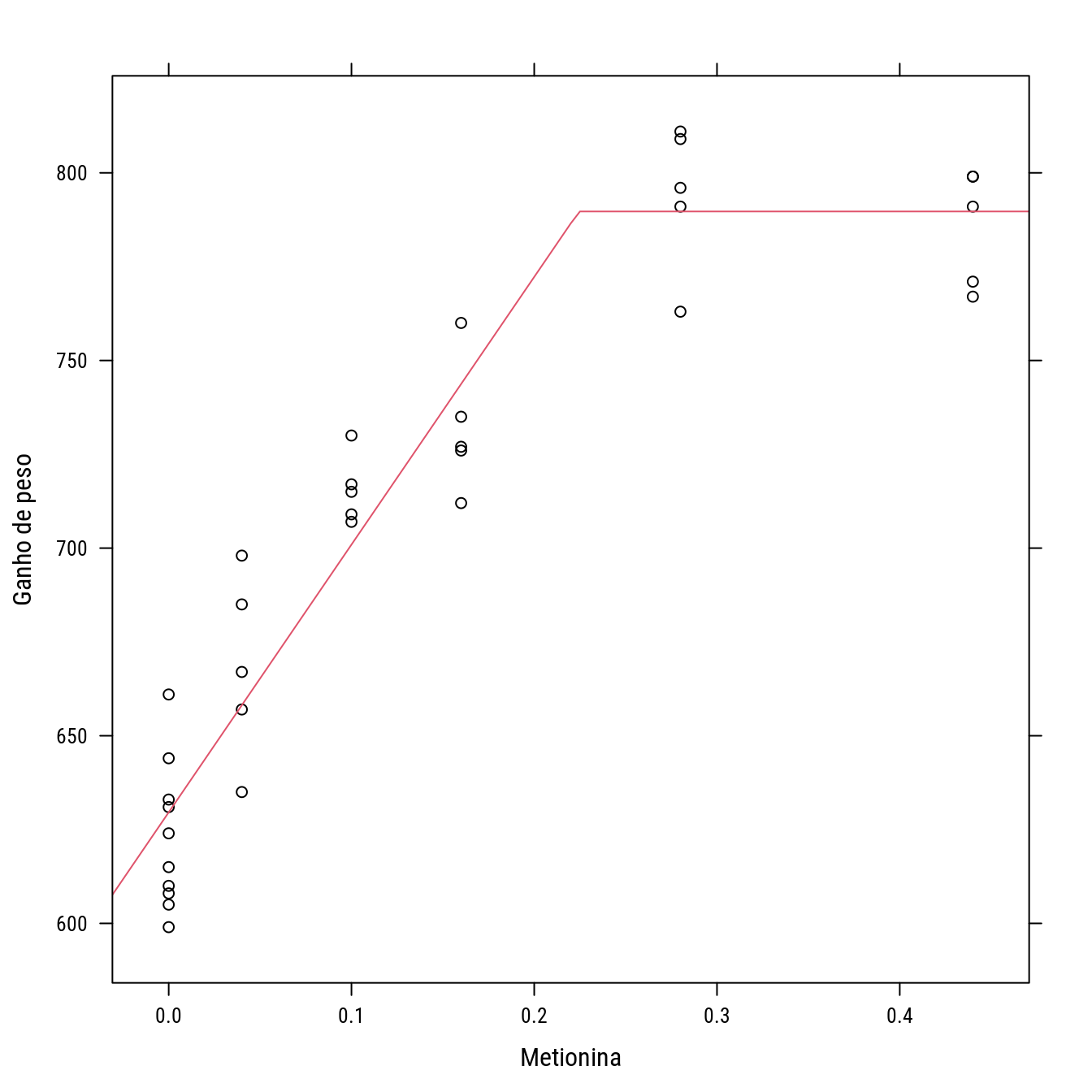
#-----------------------------------------------------------------------
# Modelo van Genuchten para retenção de água no solo.
cra <- read.table("http://www.leg.ufpr.br/~walmes/data/cra_manejo.txt",
header = TRUE, sep = "\t")
# Troca tensão 0 por 0.1.
cra$tens[cra$tens == 0] <- 0.1
str(cra)## 'data.frame': 1464 obs. of 6 variables:
## $ condi: chr "LVA3,5" "LVA3,5" "LVA3,5" "LVA3,5" ...
## $ prof : int 20 20 20 20 20 20 20 20 20 20 ...
## $ posi : chr "EL" "EL" "EL" "EL" ...
## $ rep : int 1 2 3 1 2 3 1 2 3 1 ...
## $ tens : num 0.1 0.1 0.1 1 1 1 2 2 2 4 ...
## $ umid : num 0.61 0.54 0.57 0.56 0.52 0.56 0.54 0.51 0.52 0.48 ...#-----------------------------------------------------------------------
# Selecionando um subconjunto para a presente demonstração.
cras <- droplevels(subset(cra, condi == "B"))
p2 <- xyplot(umid ~ tens, data = cras, col = 1,
ylab = expression("Conteúdo de água do solo" ~ (g ~ g^{-1})),
xlab = expression("Tensão matricial (kPa)"),
scales = list(x = list(log = 10)))
p2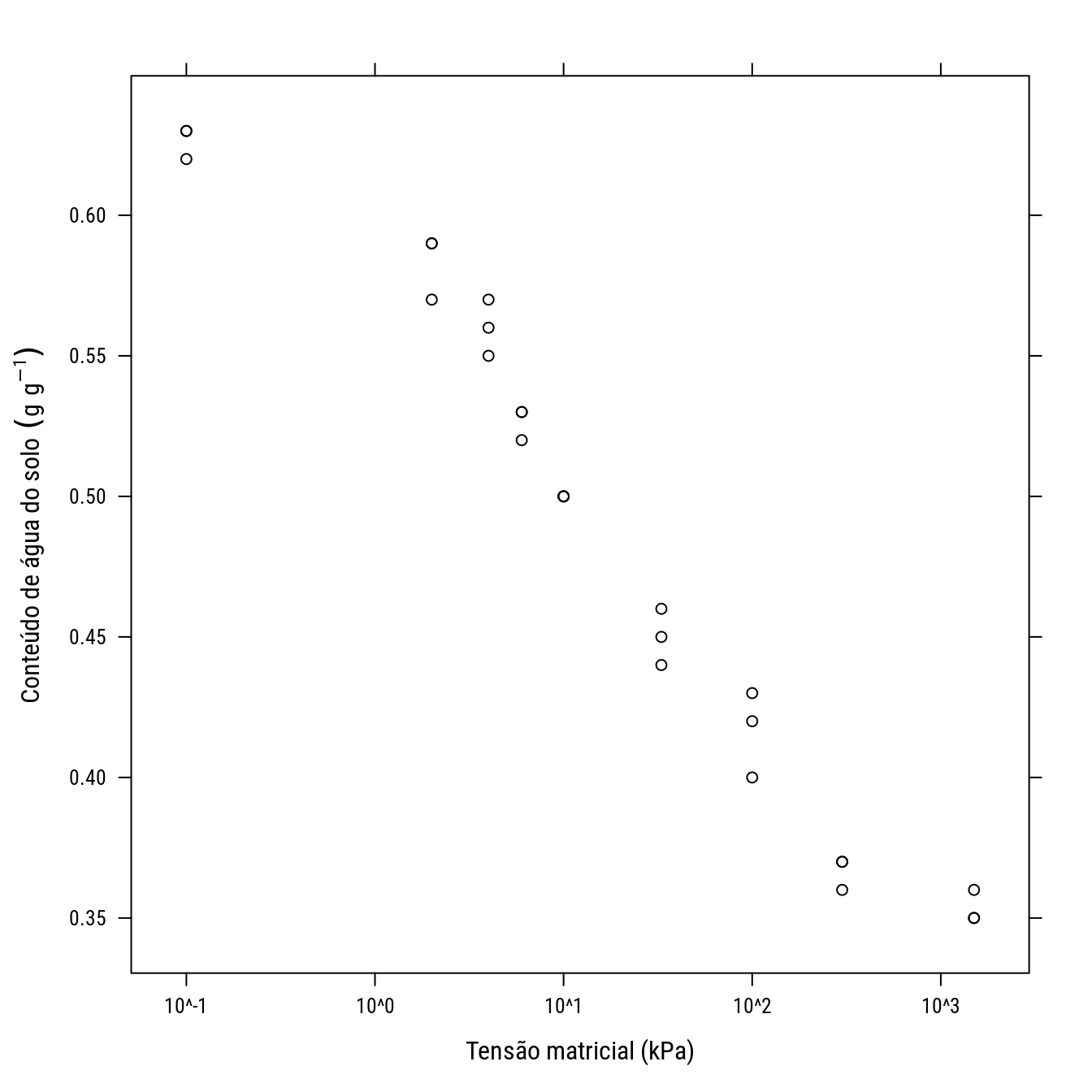
start <- list(tr = 0.3, ts = 0.6, al = 0.5, n = 1.3)
p2 +
llayer(panel.curve(tr + (ts - tr)/(1 + (al * 10^x)^n)^(1 - 1/n),
add = TRUE, col = 2),
data = start)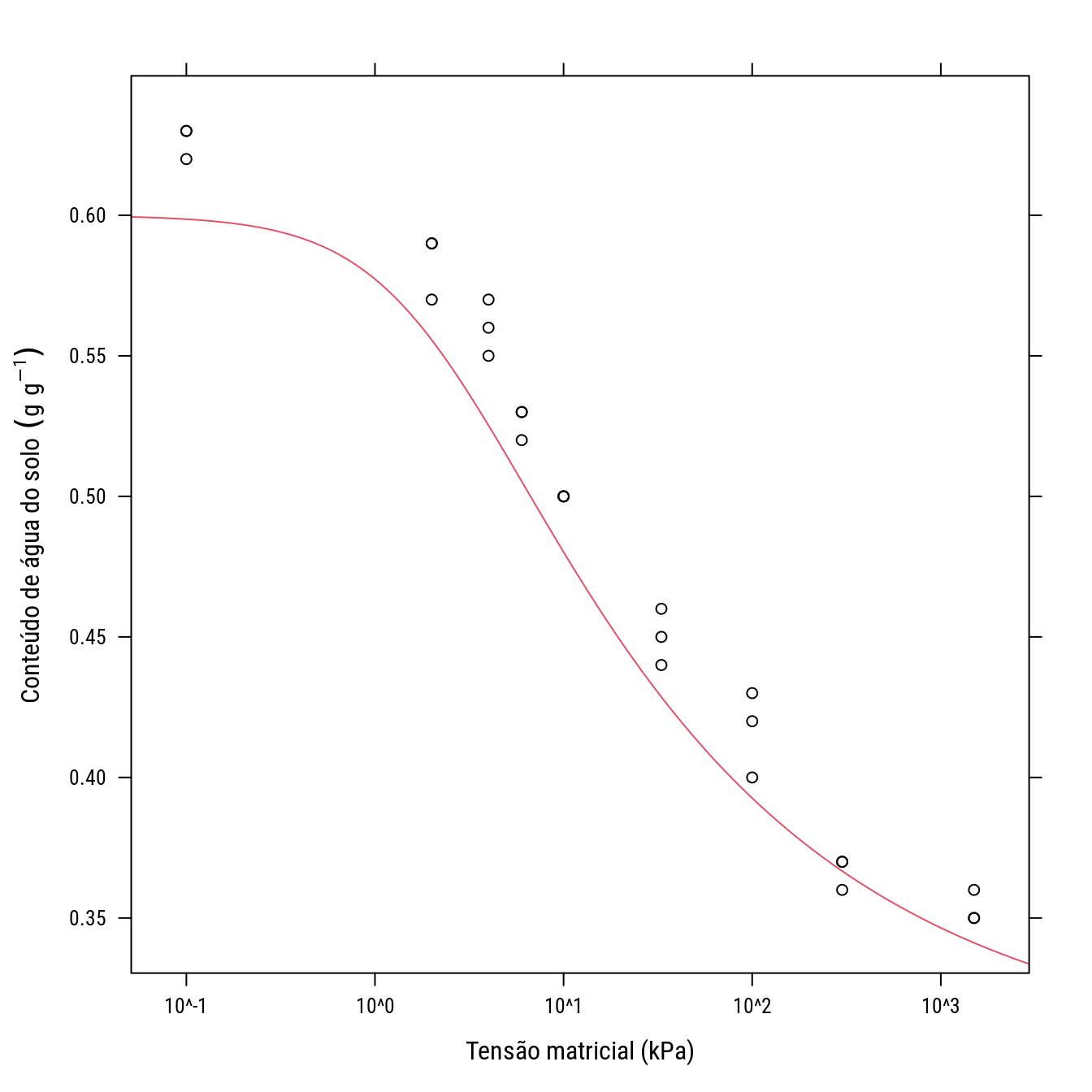
#-----------------------------------------------------------------------
# Modelo van Genuchten original
# f(x) = tr + (ts - tr)/(1 + (al * tens)^n)^(1 - 1/n)
# tr: assintota inferior;
# ts: assintota superior;
# al e n: parâmetros de forma e escala;
D(expression(tr + (ts - tr)/(1 + (al * tens)^n)^(1 - 1/n)), "tr")## 1 - 1/(1 + (al * tens)^n)^(1 - 1/n)D(expression(tr + (ts - tr)/(1 + (al * tens)^n)^(1 - 1/n)), "ts")## 1/(1 + (al * tens)^n)^(1 - 1/n)#-----------------------------------------------------------------------
n0 <- nls(umid ~ tr + (ts - tr)/(1 + (al * tens)^n)^(1 - 1/n),
data = subset(cras),
start = start,
trace = TRUE)## 0.01577304 : 0.3 0.6 0.5 1.3
## 0.002424601 : 0.3021933 0.6282174 0.4502268 1.2946416
## 0.00241469 : 0.3021613 0.6282819 0.4555884 1.2952971
## 0.00241469 : 0.3021867 0.6282759 0.4554458 1.2953747
## 0.00241469 : 0.3021857 0.6282761 0.4554512 1.2953720summary(n0)##
## Formula: umid ~ tr + (ts - tr)/(1 + (al * tens)^n)^(1 - 1/n)
##
## Parameters:
## Estimate Std. Error t value Pr(>|t|)
## tr 0.302186 0.020365 14.839 2.87e-13 ***
## ts 0.628276 0.006019 104.384 < 2e-16 ***
## al 0.455451 0.089933 5.064 3.98e-05 ***
## n 1.295372 0.049501 26.169 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.01025 on 23 degrees of freedom
##
## Number of iterations to convergence: 4
## Achieved convergence tolerance: 4.704e-07n1 <- nls(umid ~ cbind(tr = 1 - 1/(1 + (al * tens)^n)^(1 - 1/n),
ts = 1/(1 + (al * tens)^n)^(1 - 1/n)),
data = cras,
start = list(al = 0.5, n = 1.3),
trace = TRUE,
algorithm = "plinear")## 0.002509097 : 0.5000000 1.3000000 0.3070695 0.6322750
## 0.002414817 : 0.4541042 1.2950590 0.3019482 0.6281356
## 0.00241469 : 0.4554840 1.2953564 0.3021801 0.6282775
## 0.00241469 : 0.4554498 1.2953727 0.3021859 0.6282760summary(n1)##
## Formula: umid ~ cbind(tr = 1 - 1/(1 + (al * tens)^n)^(1 - 1/n), ts = 1/(1 +
## (al * tens)^n)^(1 - 1/n))
##
## Parameters:
## Estimate Std. Error t value Pr(>|t|)
## al 0.455450 0.089933 5.064 3.98e-05 ***
## n 1.295373 0.049501 26.169 < 2e-16 ***
## .lin.tr 0.302186 0.020365 14.839 2.87e-13 ***
## .lin.ts 0.628276 0.006019 104.384 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.01025 on 23 degrees of freedom
##
## Number of iterations to convergence: 3
## Achieved convergence tolerance: 6.964e-06p2 +
llayer(panel.curve(tr + (ts - tr)/(1 + (al * 10^x)^n)^(1 - 1/n),
add = TRUE, col = 2),
data = as.list(coef(n0)))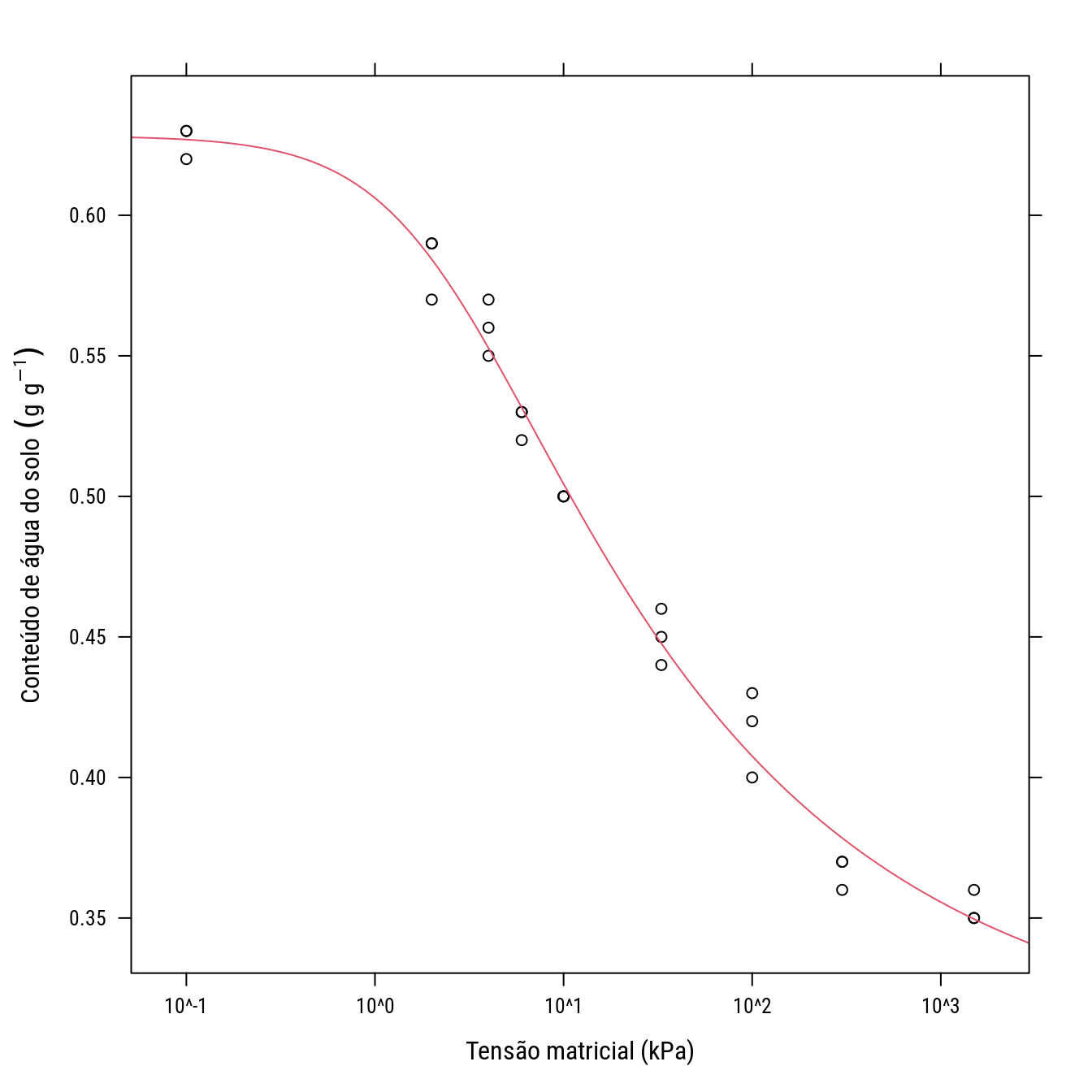
#-----------------------------------------------------------------------
# Em todos os exemplos pode-se até pensar que não existe vantagem em
# usar o algortimo plinear porque o número de passos para convergência
# foi igual. Vale ressaltar que os modelos considerados são bem
# regulares/comportados e os valores iniciais foram bem próximos das
# estimativas. O gargalo da estimação são os valores iniciais. Se os
# valores forncecidos são bons espera-se pouca contribuição do método de
# estimação.3 Funções self-start
#-----------------------------------------------------------------------
# Em algumas situações, é possível obter valores iniciais para os
# parâmetros baseados em estatísticas da amostra. O primeiro passo é
# definir quais os melhores "pré-estimadores" para cada parâmetro. O
# segundo é escrever uma função que passe esses valores para a `nls()`
# ou outra função de estimação. Modelos que auto providênciam valores
# iniciais são chamadas de self-start.
#-----------------------------------------------------------------------
# Self-start para o modelo de perda de peso (wtloss).
data(wtloss, package = "MASS")
p0 <- xyplot(Weight ~ Days, data = wtloss, col = 1,
xlab = "Dias em dieta",
ylab = "Peso (kg)")
p0 +
llayer(with(list(f0 = 81, f1 = 102, K = 141),
panel.curve(f0 + f1 * 2^(-x/K),
add = TRUE, col = 2)))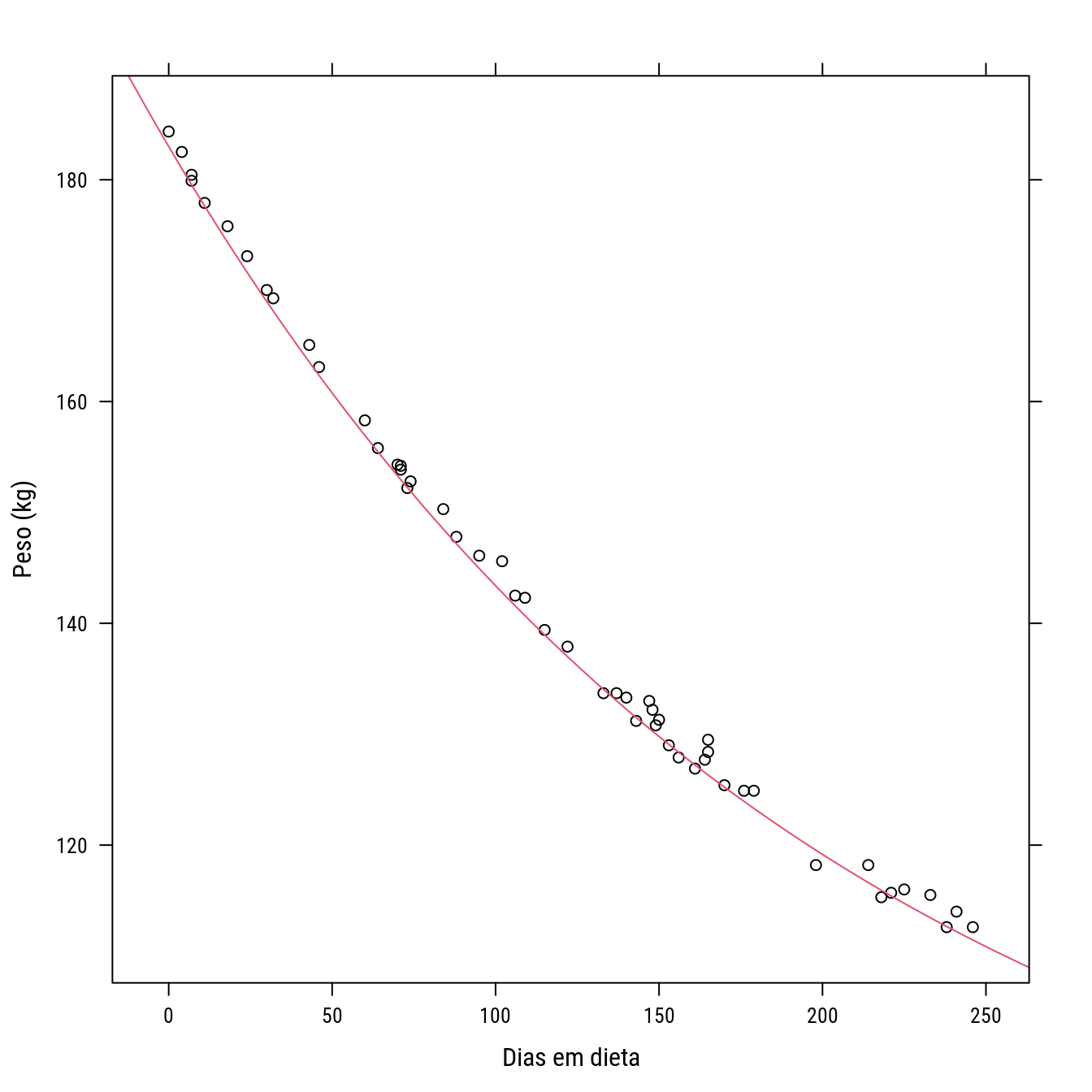
#-----------------------------------------------------------------------
# Pré-estimativas (uma idéia realmente simples!).
pe <- with(wtloss, {
f1 <- diff(range(Weight)) # Amplitude.
f0 <- min(Weight) # Mínimo.
m <- f0 + 0.5 * f1 # Semiamplitude.
mm <- which.min(abs(Weight - m))[1] # y mais perto da semiamplitude.
K <- Days[mm] # x correspondente.
list(f0 = f0, f1 = f1, K = K)
})
p0 +
llayer(with(pe,
panel.abline(v = K,
h = c(f0 + c(0, 0.5, 1) * f1),
lty = 2)))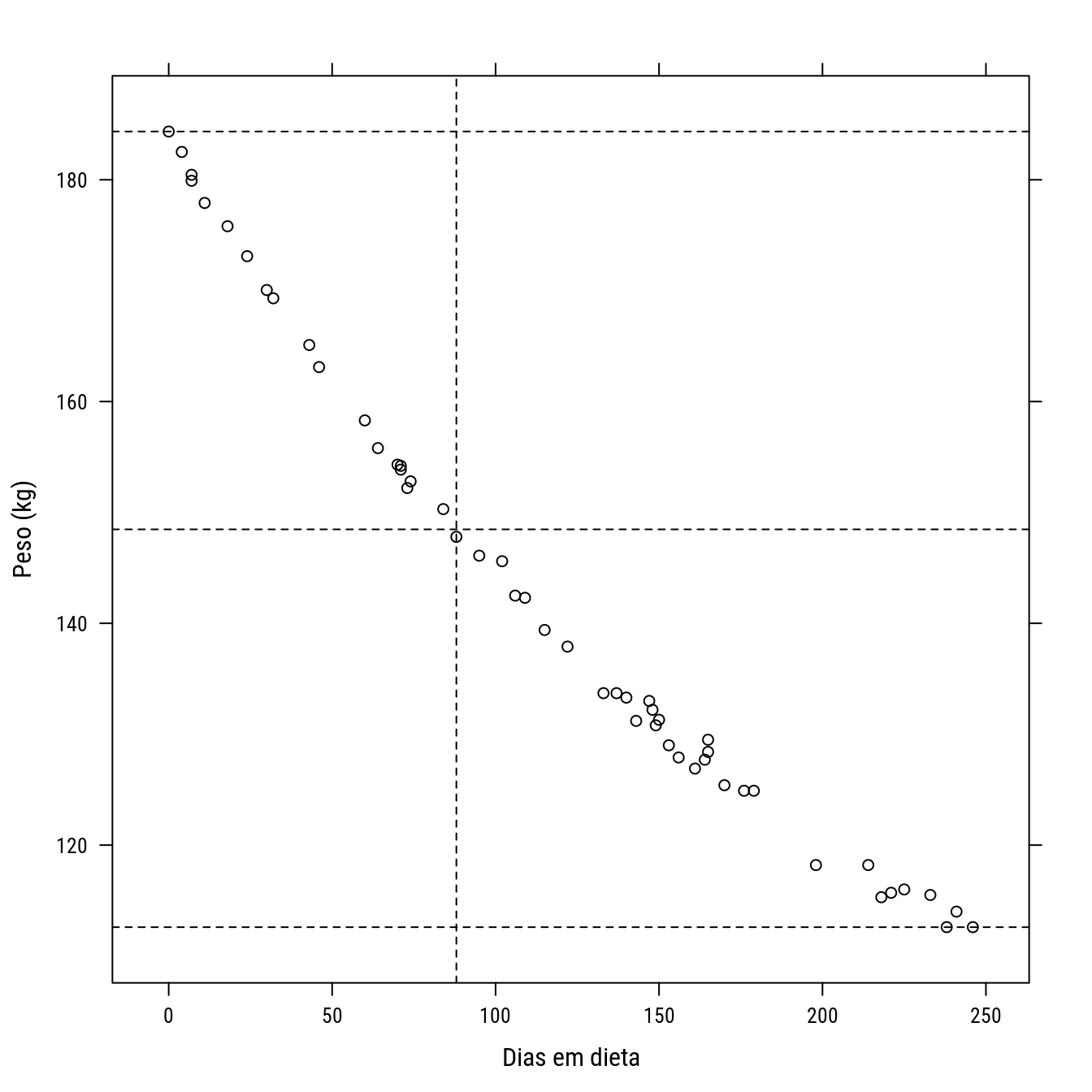
#-----------------------------------------------------------------------
# Criando função que retorna as estimativas.
model.init <- function(x, y){
f1 <- diff(range(y)) # Amplitude.
f0 <- min(y) # Mínimo.
m <- f0 + 0.5 * f1 # Semiamplitude.
mm <- which.min(abs(y - m))[1] # y mais perto da semiamplitude.
K <- x[mm] # x correspondente.
list(f0 = f0, f1 = f1, K = K)
}
model.init(x = wtloss$Days, y = wtloss$Weight)## $f0
## [1] 112.6
##
## $f1
## [1] 71.75
##
## $K
## [1] 88#-----------------------------------------------------------------------
# Colocando isso dentro de uma função self-start.
model.init <- function(mCall, data, LHS){
xy <- data.frame(sortedXyData(mCall[["input"]], LHS, data))
xx <- xy[["x"]]
yy <- xy[["y"]]
f0 <- min(yy) # Mínimo da amostra.
f1 <- diff(range(yy)) # Amplitude.
m <- f0 + 0.5 * f1 # Semiamplitude.
mm <- which.min(abs(yy - m))[1] # y mais perto da semiamplitude.
K <- xx[mm] # x correspondente.
value <- c(f0, f1, K)
names(value) <- mCall[c("f0","f1","K")]
value
}
# Saí o gradiente atributo gradiente junto.
SSmodel <- selfStart(model = ~f0 + f1 * 2^(-input/K),
parameters = c("f0", "f1", "K"),
initial = model.init,
template = function(input, f0, f1, K) NULL)
SSmodel## function (input, f0, f1, K)
## {
## .expr3 <- 2^(-input/K)
## .value <- f0 + f1 * .expr3
## .grad <- array(0, c(length(.value), 3L), list(NULL, c("f0",
## "f1", "K")))
## .grad[, "f0"] <- 1
## .grad[, "f1"] <- .expr3
## .grad[, "K"] <- f1 * (.expr3 * (log(2) * (input/K^2)))
## attr(.value, "gradient") <- .grad
## .value
## }
## attr(,"initial")
## function(mCall, data, LHS){
## xy <- data.frame(sortedXyData(mCall[["input"]], LHS, data))
## xx <- xy[["x"]]
## yy <- xy[["y"]]
## f0 <- min(yy) # Mínimo da amostra.
## f1 <- diff(range(yy)) # Amplitude.
## m <- f0 + 0.5 * f1 # Semiamplitude.
## mm <- which.min(abs(yy - m))[1] # y mais perto da semiamplitude.
## K <- xx[mm] # x correspondente.
## value <- c(f0, f1, K)
## names(value) <- mCall[c("f0","f1","K")]
## value
## }
## attr(,"pnames")
## [1] "f0" "f1" "K"
## attr(,"class")
## [1] "selfStart"# As pré-estimativas avaliadas.
getInitial(Weight ~ SSmodel(Days, f0, f1, K),
data = wtloss)## f0 f1 K
## 112.60 71.75 88.00#-----------------------------------------------------------------------
# Usando o modelo self-start.
n0 <- nls(Weight ~ SSmodel(Days, f0, f1, K),
data = wtloss,
trace = TRUE)## 1159.454 : 112.60 71.75 88.00
## 100.393 : 89.68663 94.11074 128.73510
## 39.59629 : 81.85524 102.19312 141.26936
## 39.2447 : 81.37408 102.68373 141.91136
## 39.2447 : 81.37382 102.68411 141.91036summary(n0)##
## Formula: Weight ~ SSmodel(Days, f0, f1, K)
##
## Parameters:
## Estimate Std. Error t value Pr(>|t|)
## f0 81.374 2.269 35.86 <2e-16 ***
## f1 102.684 2.083 49.30 <2e-16 ***
## K 141.910 5.295 26.80 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.8949 on 49 degrees of freedom
##
## Number of iterations to convergence: 4
## Achieved convergence tolerance: 9.199e-08#-----------------------------------------------------------------------
# Modelo quadrático com ponto crítico (QCC) desenvolvido na minha Tese.
# Taxa de crescimento do disco de micélio para de 16 isolados de fungo
# em função da temperatura.
# Dados de Paulo Lichtemberg (Doutorando em Produção Vegetal UFPR).
cm <- read.table("http://www.leg.ufpr.br/~walmes/data/cresmicelial.txt",
header = TRUE,
sep = "\t",
colClasses = c("factor", "numeric", "numeric"))
str(cm)## 'data.frame': 192 obs. of 3 variables:
## $ isolado: Factor w/ 16 levels "1","10","12",..: 1 1 1 8 8 8 11 11 11 12 ...
## $ temp : num 20 20 20 20 20 20 20 20 20 20 ...
## $ mmdia : num 14.25 13.25 13.25 9.75 12.75 ...#-----------------------------------------------------------------------
# Ver os dados.
p1 <- xyplot(mmdia ~ temp | isolado,
data = cm,
type = c("p", "a"),
col = 1,
ylab = "Taxa de crescimento em diâmetro do disco micelial",
xlab = "Temperatuda da câmara de crescimento")
print(p1)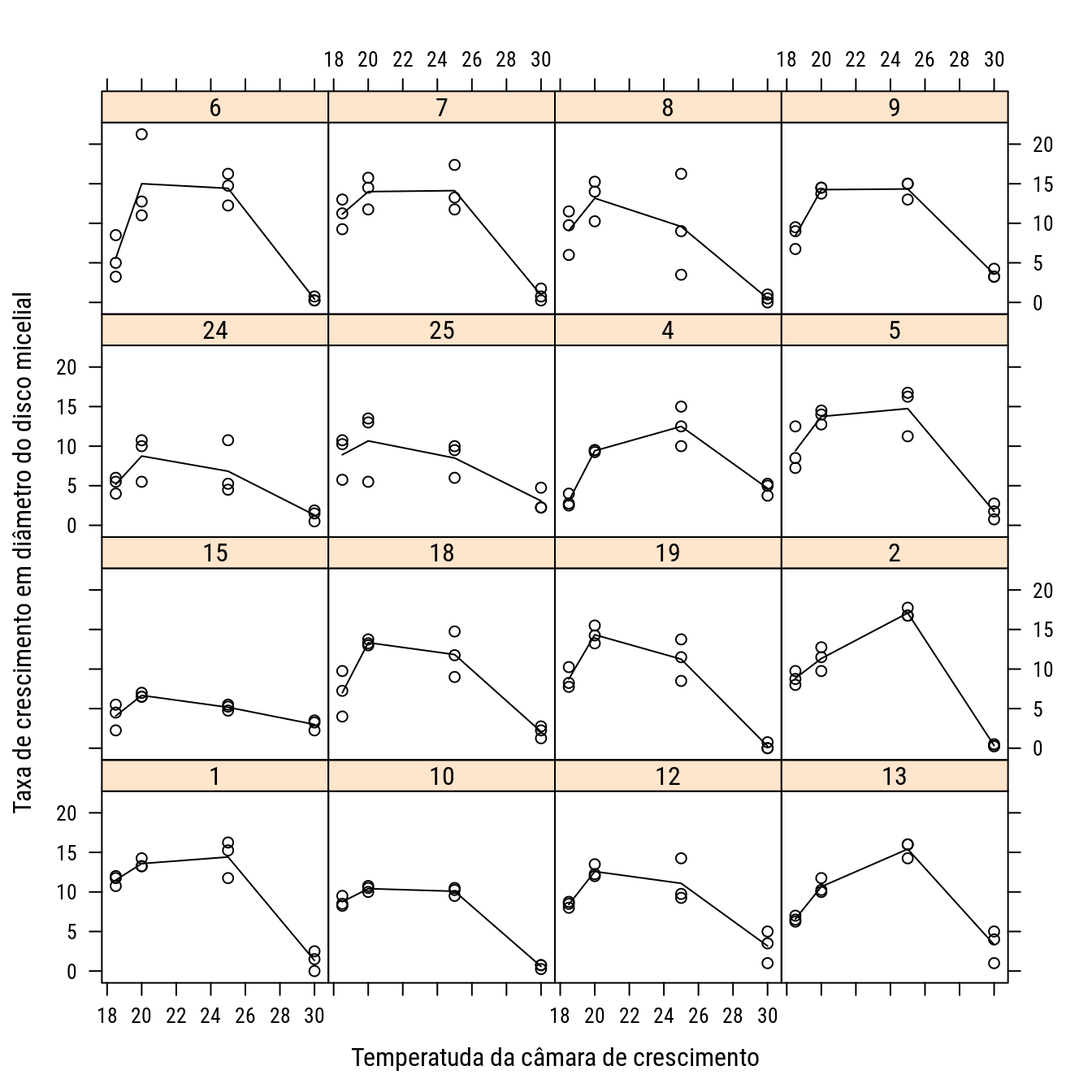
#-----------------------------------------------------------------------
# Ajustar para as 16 situações requer 16 conjutos de 3 valores iniciais
# (48 no total). Esse modelo tem interpretação cartesiana dos parâmetros,
# é fácil conseguí-los. Dada relação entre os parâmetros nas duas
# parametrizações do quadrático, podemos ajustar com a lm() e passar os
# valores para nls(). Vamos incorporar isso na self-start.
#-----------------------------------------------------------------------
# Modelo quadrático original (MQO)
# f(x) = f0+tx0*x+cv*x^2
# f0: valor da função na origem
# tx0: taxa na origem
# cv: curvatura
#
# Modelo quadrático centrado no ponto crítico (MQC)
# f(x) = fc+cv*(x-xc)^2
# fc: valor da função no ponto crítico (mínimo ou máximo)
# xc: ponto crítico
# cv: curvatura
#
# xc é calculado por xc=-tx0/(2*cv);
# fc é clauclado por fc=f0+tx0*xc+cv*xc^2;
#-----------------------------------------------------------------------
# Fazendo a self-start para o modelo quadrático.
mqc.init <- function(mCall, data, LHS) {
xy <- data.frame(sortedXyData(mCall[["input"]], LHS, data))
m0 <- lm(y ~ poly(x, 2, raw = TRUE), data = xy)
c0 <- coef(m0)
cv <- c0[3]
xc <- -0.5 * c0[2]/cv
fc <- c0[1] + c0[2] * xc + cv * xc
value <- c(fc, xc, cv)
names(value) <- mCall[c("fc", "xc", "cv")]
value
}
SSmqc <- selfStart(model = ~fc + cv * (input - xc)^2,
parameters = c("fc", "xc", "cv"),
initial = mqc.init,
template = function(input, fc, xc, cv) NULL)
# São mais que pré-estimativas, são as próprias estimativas!
getInitial(mmdia ~ SSmqc(temp, fc, xc, cv),
data = subset(cm, isolado == "1"))## fc xc cv
## 144.8294997 22.6213375 -0.2639147#-----------------------------------------------------------------------
# Ajustando o modelo para todos os isolados, usar lapply.
cms <- split(cm, f = cm$isolado)
# São as estimativas.
sapply(cms,
FUN = getInitial,
object = mmdia ~ SSmqc(temp, fc, xc, cv))## 1 10 12 13 15 18 19
## fc 144.8294997 98.4113423 103.4151912 193.5447032 36.29401324 141.2557967 128.8486643
## xc 22.6213375 22.3112078 22.7514927 23.8436386 22.81546454 23.1069169 22.4207221
## cv -0.2639147 -0.1829921 -0.1834489 -0.3264447 -0.06088136 -0.2497444 -0.2396385
## 2 24 25 4 5 6 7
## fc 222.8228983 71.0619101 50.68873740 167.7179993 169.7166482 217.37310 147.3360725
## xc 23.4325194 22.5735045 21.28915437 24.3359842 23.0839096 23.41014 22.5886086
## cv -0.3908379 -0.1290247 -0.09392596 -0.2720432 -0.3013447 -0.38257 -0.2698738
## 8 9
## fc 92.4982155 159.9247939
## xc 21.8205085 23.3071114
## cv -0.1769139 -0.2771935# Ajuste em lote.
n0 <- lapply(cms,
FUN = nls,
formula = mmdia ~ SSmqc(temp, fc, xc, cv))
c0 <- t(sapply(n0, coef))
c0## fc xc cv
## 1 15.747872 22.62134 -0.26391471
## 10 11.402460 22.31121 -0.18299214
## 12 12.630189 22.75149 -0.18344892
## 13 15.738307 23.84364 -0.32644466
## 15 5.991539 22.81546 -0.06088136
## 18 13.680697 23.10692 -0.24974439
## 19 13.757928 22.42072 -0.23963854
## 2 17.378770 23.43252 -0.39083792
## 24 8.228228 22.57350 -0.12902469
## 25 10.118459 21.28915 -0.09392596
## 4 13.223529 24.33598 -0.27204322
## 5 16.096225 23.08391 -0.30134475
## 6 16.667437 23.41014 -0.38257005
## 7 15.730306 22.58861 -0.26987384
## 8 12.123749 21.82051 -0.17691388
## 9 15.807922 23.30711 -0.27719350ic0 <- lapply(n0, confint.default)
ic0## $`1`
## 2.5 % 97.5 %
## fc 14.4326624 17.063082
## xc 22.1462456 23.096429
## cv -0.3211214 -0.206708
##
## $`10`
## 2.5 % 97.5 %
## fc 10.9737562 11.8311634
## xc 22.0551298 22.5672857
## cv -0.2022811 -0.1637032
##
## $`12`
## 2.5 % 97.5 %
## fc 10.7184582 14.5419191
## xc 21.8126286 23.6903568
## cv -0.2655552 -0.1013426
##
## $`13`
## 2.5 % 97.5 %
## fc 14.4660573 17.0105557
## xc 23.6042484 24.0830288
## cv -0.3774317 -0.2754576
##
## $`15`
## 2.5 % 97.5 %
## fc 4.7740561 7.209021508
## xc 21.0626370 24.568292125
## cv -0.1128637 -0.008898969
##
## $`18`
## 2.5 % 97.5 %
## fc 11.1510401 16.2103547
## xc 22.3202574 23.8935763
## cv -0.3551974 -0.1442914
##
## $`19`
## 2.5 % 97.5 %
## fc 11.7527082 15.7631470
## xc 21.5493807 23.2920636
## cv -0.3287375 -0.1505396
##
## $`2`
## 2.5 % 97.5 %
## fc 15.9461134 18.8114258
## xc 23.1803316 23.6847072
## cv -0.4493119 -0.3323639
##
## $`24`
## 2.5 % 97.5 %
## fc 5.9016375 10.55481760
## xc 20.8180431 24.32896597
## cv -0.2307185 -0.02733085
##
## $`25`
## 2.5 % 97.5 %
## fc 7.8178177 12.41910097
## xc 17.1062047 25.47210407
## cv -0.2130253 0.02517337
##
## $`4`
## 2.5 % 97.5 %
## fc 11.49458 14.9524756
## xc 23.96148 24.7104893
## cv -0.34066 -0.2034265
##
## $`5`
## 2.5 % 97.5 %
## fc 14.0025901 18.189861
## xc 22.5393259 23.628493
## cv -0.3887714 -0.213918
##
## $`6`
## 2.5 % 97.5 %
## fc 12.8654097 20.4694640
## xc 22.7211688 24.0991153
## cv -0.5379462 -0.2271939
##
## $`7`
## 2.5 % 97.5 %
## fc 13.8599378 17.6006746
## xc 21.9183626 23.2588546
## cv -0.3514993 -0.1882483
##
## $`8`
## 2.5 % 97.5 %
## fc 8.8379606 15.40953712
## xc 19.2978930 24.34312409
## cv -0.3343823 -0.01944545
##
## $`9`
## 2.5 % 97.5 %
## fc 14.3175646 17.2982790
## xc 22.9204540 23.6937689
## cv -0.3384766 -0.2159104#-----------------------------------------------------------------------
# Análise dos resíduos em série.
res <- do.call(c, lapply(n0, residuals))
qqmath(~res | cm$isolado)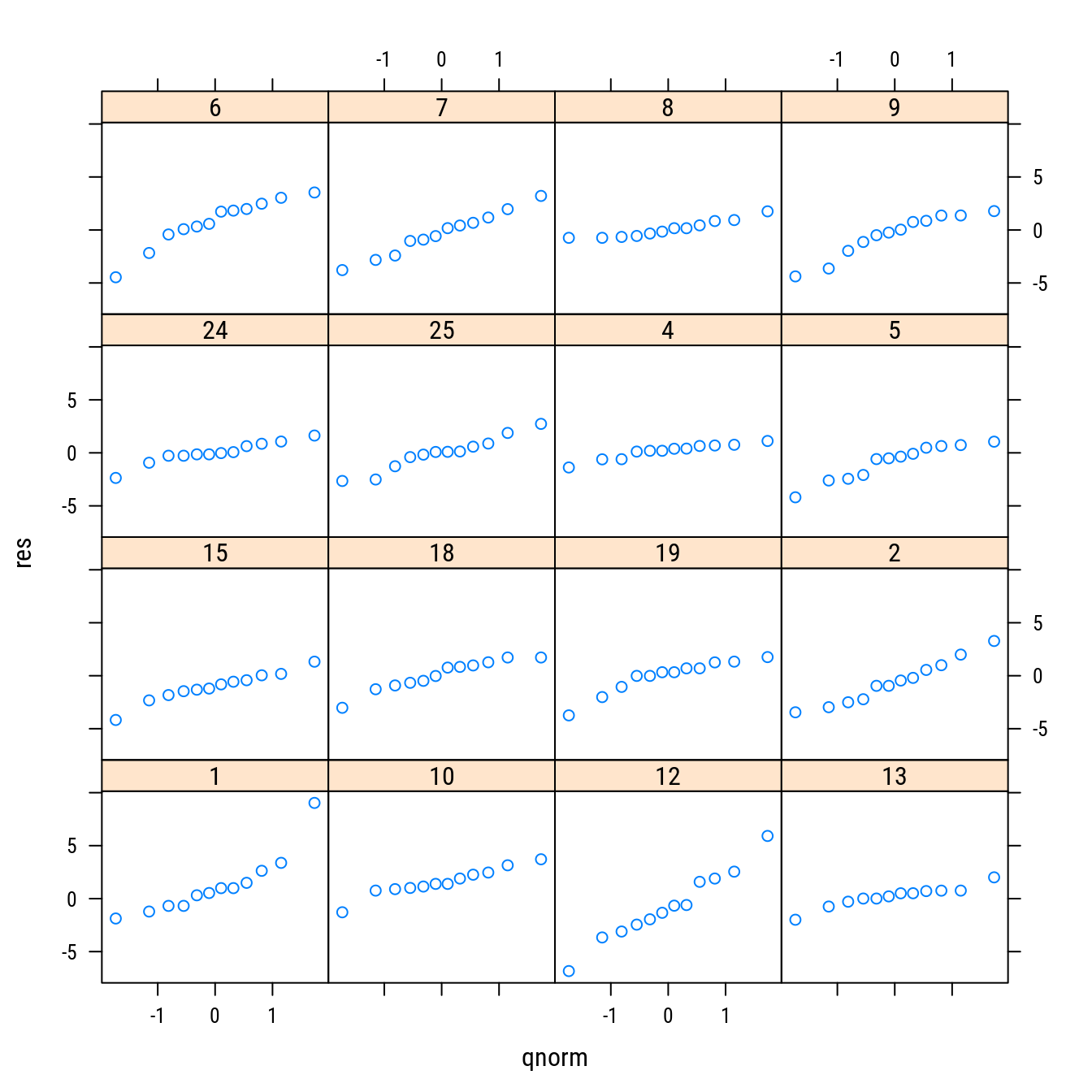
#-----------------------------------------------------------------------
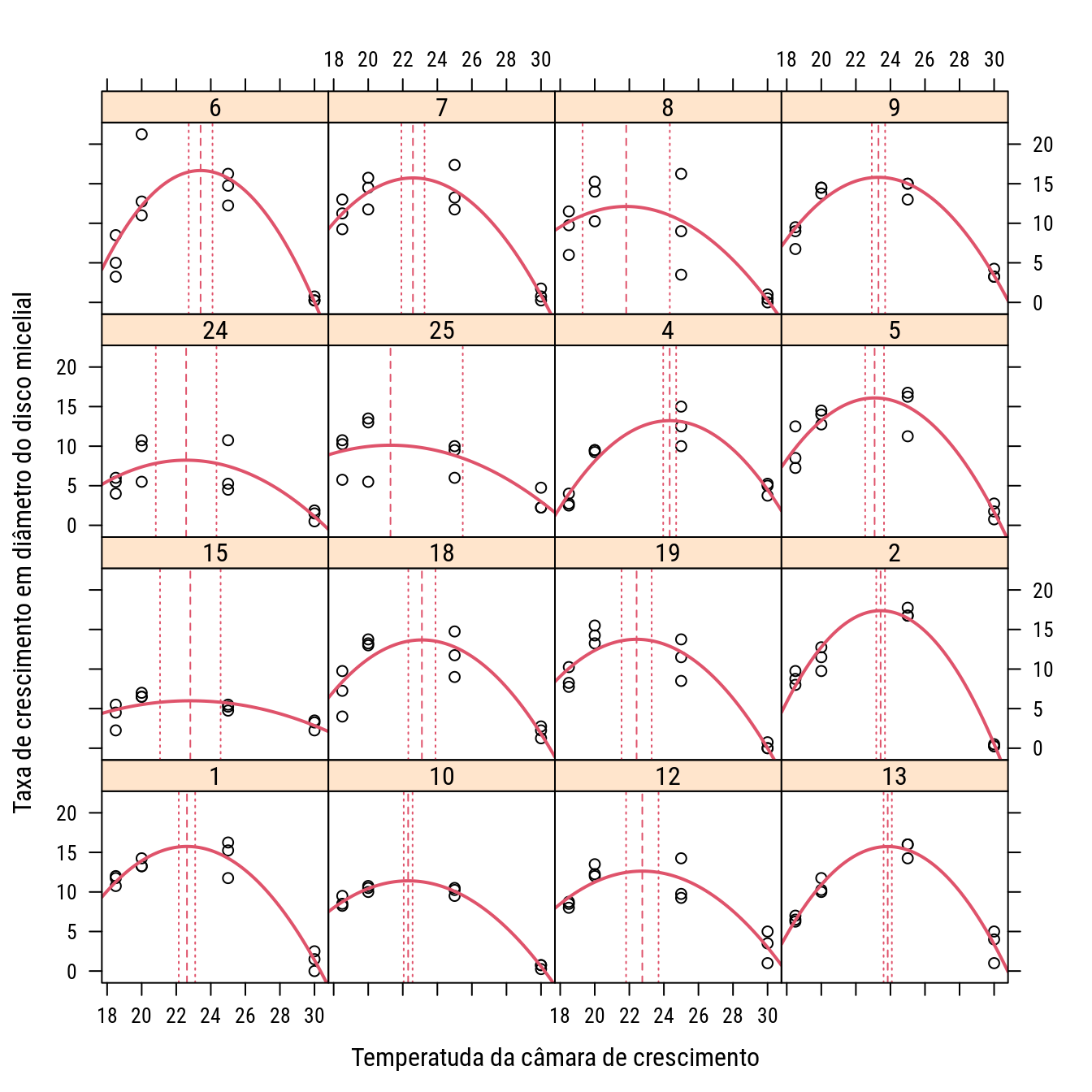
# Colocando os resultados no gráfico.
# Formato de lista com vetores nomeados é mais adequado agora.
c0 <- lapply(n0, coef)
xyplot(mmdia ~ temp | isolado,
data = cm,
col = 1,
ylab = "Taxa de crescimento em diâmetro do disco micelial",
xlab = "Temperatuda da câmara de crescimento",
panel = function(...) {
panel.xyplot(...)
wp <- which.packet()
with(as.list(c0[[wp]]),
panel.curve(fc + cv * (x - xc)^2,
col = 2, lwd = 2))
panel.abline(v = c0[[wp]]["xc"], lty = 2, col = 2)
panel.abline(v = ic0[[wp]]["xc", ], lty = 3, col = 2)
})
#-----------------------------------------------------------------------
# Para essas situações é mais indicado usar a `nls::nlsList()`, pois ela
# trata melhor as saídas colocando todos os ajustes no mesmo output.
# Outra opção de análise é tratar o efeito de isolado como aleatório
# (pois são uma amostra) e verificar os componentes de variância em
# relação à cada parâmetro. Para inferir sobre a temperatura de ótimo
# pode-se usar o modelo quadrático original e obter IC por meio do
# método delta. Eles serão exatamente iguais aos IC assintóticos feitos
# a partir do modelo quadrático centrado.
#-----------------------------------------------------------------------
# Inferência para xc via método delta.
m0 <- lm(mmdia ~ temp + I(temp^2), cms[[1]])
n0 <- nls(mmdia ~ SSmqc(temp, fc, xc, cv), cms[[1]])
# mesma estimativa e erro padrão, logo mesmo IC
car::deltaMethod(m0, "-0.5 * b1/b2",
parameterNames = c("b0", "b1", "b2"))## Estimate SE 2.5 % 97.5 %
## -0.5 * b1/b2 22.6213 0.2424 22.1462 23.096summary(n0)$coeff["xc", 1:2]## Estimate Std. Error
## 22.6213375 0.2423983#-----------------------------------------------------------------------
# Mais funções self-start você encontra procurando aquelas que começam
# com SS.
apropos("^SS", where = TRUE)## 33 33 33 33 33 33
## "SSasymp" "SSasympOff" "SSasympOrig" "SSbiexp" "SSD" "SSfol"
## 33 33 33 33 1 1
## "SSfpl" "SSgompertz" "SSlogis" "SSmicmen" "SSmodel" "SSmqc"
## 33
## "SSweibull"# Mais delas no pacote drc, HydroMe e outros.4 Busca em grid
#-----------------------------------------------------------------------
# Não raramente tem-se modelos que não apresentam interpretação
# cartesiana para os parâmetros dificultando assim o usuário obter
# valores iniciais pela inspeção de gráficos ou medidas descritivas. Em
# geral, gasta-se muito tempo testando valores iniciais e uma forma de
# evitar isso é criar um grid de valores e avaliar a função para
# comninações dos parâmetros. Aquela que apresentar menor soma de
# quadrados pode ser usada como valor inicial de onde espera-se sucesso
# na convergência. Para essa tarefa usa-se funções disponíveis no
# pacote `nls2`, em especial a função `nls()` que tem o algortimo
# "grid-search" ou "brute-force".
#-----------------------------------------------------------------------
# Curvas de lactação.
milk <- read.table("http://www.leg.ufpr.br/~walmes/data/saxton_lactacao1.txt",
header = TRUE, sep = "\t", colClasses = c("factor", NA, NA))
str(milk)## 'data.frame': 29 obs. of 3 variables:
## $ vaca : Factor w/ 3 levels "1","2","3": 1 1 1 1 1 1 1 1 1 2 ...
## $ leite: num 27.4 30.5 29.9 30.2 29.1 28.6 27.4 25.4 22.8 35.8 ...
## $ dia : int 23 54 83 114 146 175 205 266 297 17 ...xyplot(leite ~ dia, groups = vaca, data = milk, type = "o")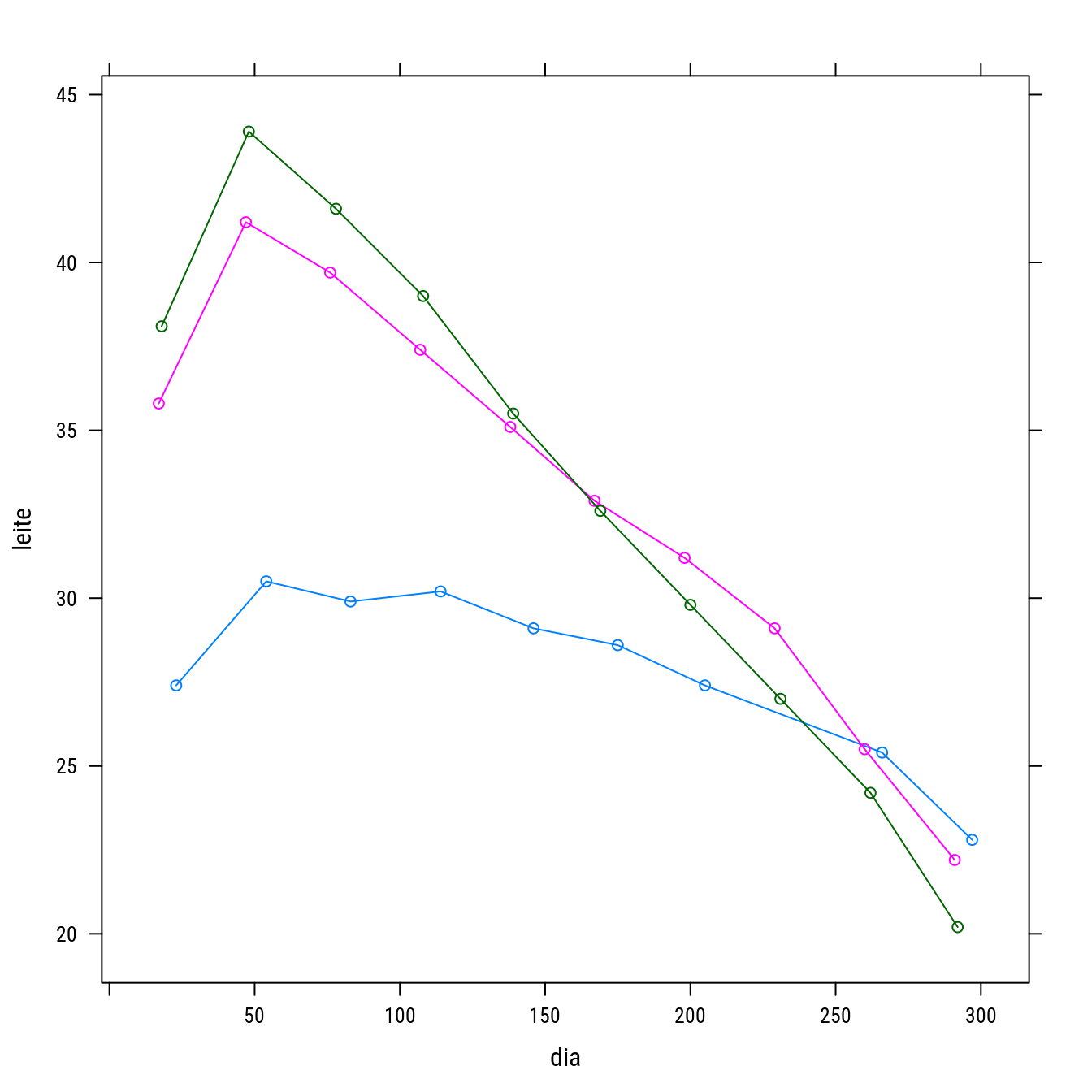
milks <- subset(milk, vaca == "3")
p4 <- xyplot(leite ~ dia,
groups = vaca,
data = milks,
col = 1,
type = "o")
p4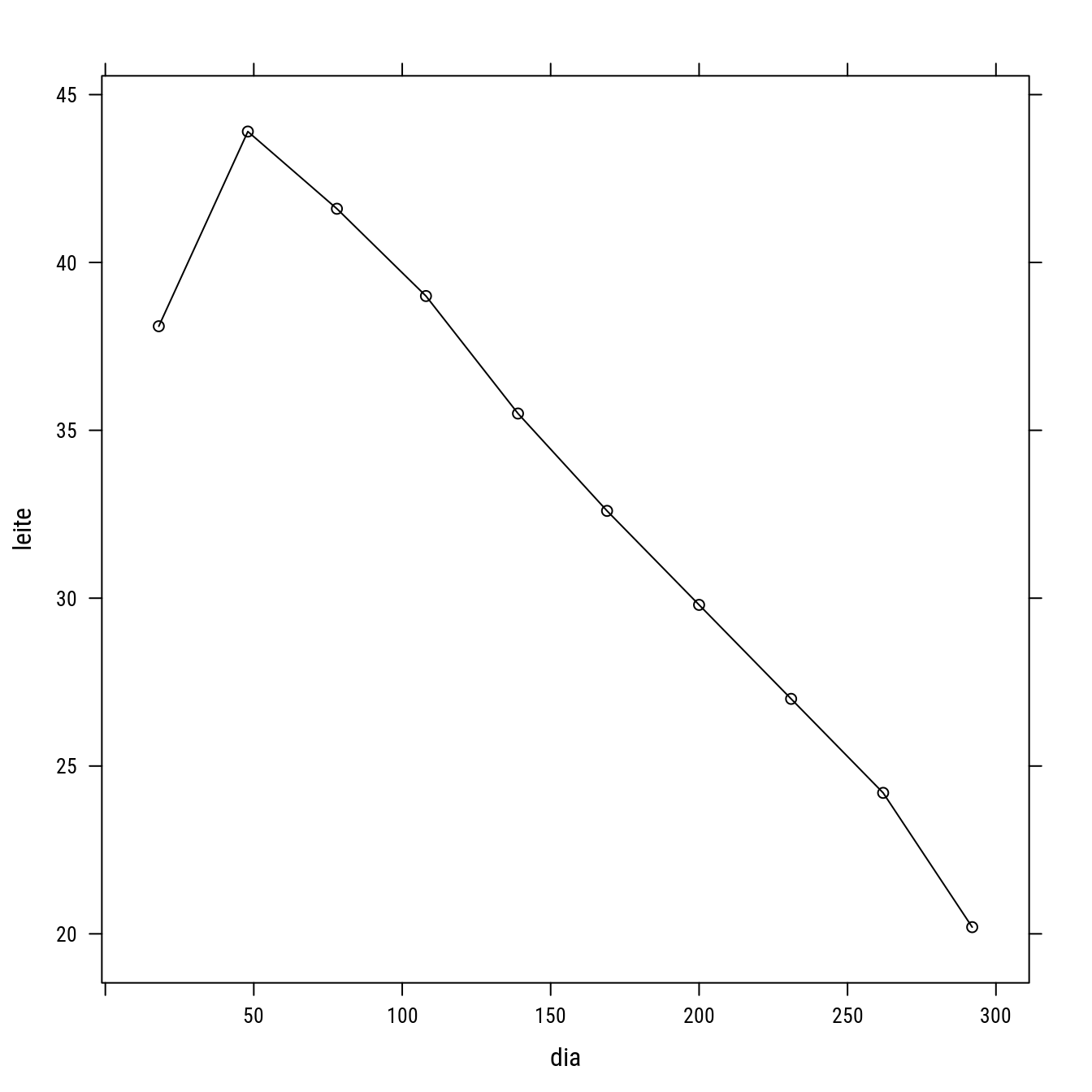
#-----------------------------------------------------------------------
# Ajustar o modelo de Wood f(x) = A * x^B * exp(-C * x), como obter
# valores inicais para esses parâmetros? O modelo de Wood usa o núcleo
# da distribuição Gama.
# Grid de valores iniciais (as amplitudes vem do conhecimento prévio)
vi.grid <- expand.grid(A = seq(5, 30, l = 10),
B = seq(0, 1, l = 10),
C = seq(0, 0.1, l = 50))
nrow(vi.grid)## [1] 5000# Testa toda tupla de parâmetros e fica com a melhor.
n0 <- nls2::nls2(leite ~ A * dia^B * exp(-C * dia),
data = milks,
start = vi.grid,
algorithm = "grid-search")
coef(n0)## A B C
## 21.666666667 0.222222222 0.004081633# Usa a melhor tupla como valores iniciais.
n1 <- nls(formula(n0), data = milks, start = coef(n0))
summary(n1)##
## Formula: leite ~ A * dia^B * exp(-C * dia)
##
## Parameters:
## Estimate Std. Error t value Pr(>|t|)
## A 2.023e+01 1.465e+00 13.81 2.46e-06 ***
## B 2.529e-01 2.135e-02 11.85 6.93e-06 ***
## C 4.803e-03 2.252e-04 21.33 1.26e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.7134 on 7 degrees of freedom
##
## Number of iterations to convergence: 3
## Achieved convergence tolerance: 1.984e-06p4 +
llayer(with(as.list(coef(n1)),
panel.curve(A * x^B * exp(-C * x),
add = TRUE, col = 2)))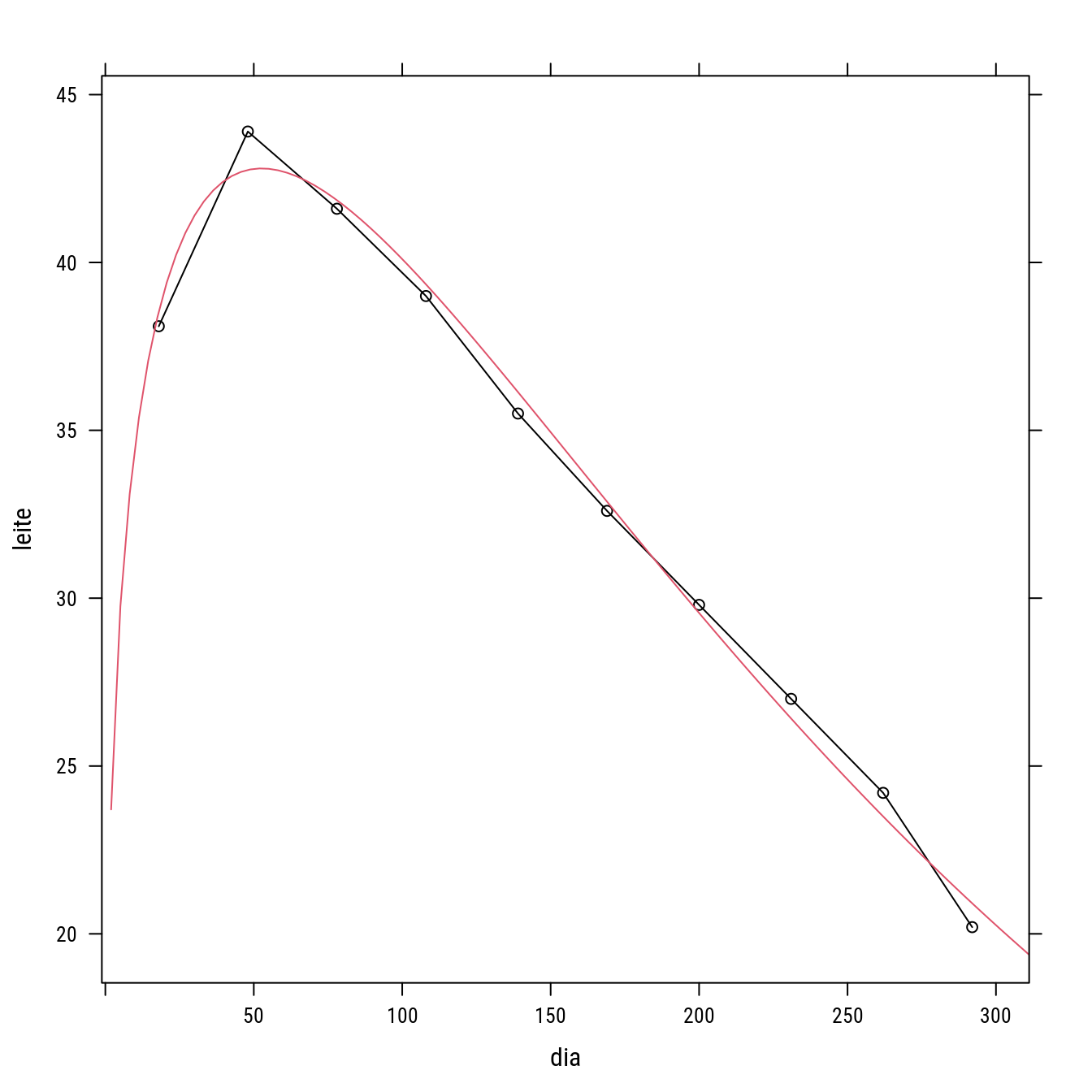
#-----------------------------------------------------------------------
# No caso de modelos onde é dificil montar uma função self-start pode-se
# usar a `nls2()` com o "grid-search" dentro e os valores inicais seriam
# aqueles selecionados.5 Ajuste com interface gráfica
library(rpanel)
#-----------------------------------------------------------------------
# Exemplos da documentação.
# library(wzRfun)
# help(rp.nls, h = "html")
# Se não possuir o pacote `wzRfun`, carregue a função da fonte.
source("https://raw.githubusercontent.com/walmes/wzRfun/master/R/rp.nls.R")
#-----------------------------------------------------------------------
# Ganho de peso de perus.
library(rpanel)
data(turk0, package = "alr4")
str(turk0)
plot(Gain ~ A, data = turk0,
xlab = "Metionine", ylab = "Weight gain")
turk_fit <- rp.nls(model = Gain ~ Int + (Asy - Int) * A/(Half + A),
data = turk0,
start = list(Int = c(600, 650),
Asy = c(750, 850),
Half = c(0, 0.2)),
extra = function(Int, Asy, Half) {
abline(h = c(Asy, Int), v = Half,
col = "green")
},
xlab = "Metionine", ylab = "Weight gain")
summary(turk_fit)
confint(turk_fit)
# Guarde isso para reusar.
dput(as.list(round(coef(turk_fit), 4)))
# list(Int = 622.2417, Asy = 857.4585, Half = 0.1548)
f <- formula(turk_fit)
plot(Gain ~ A, data = turk0,
xlab = "Metionine", ylab = "Weight gain")
with(as.list(coef(turk_fit)), {
eval(call("curve", f[[3]], add = TRUE,
xname = intersect(all.vars(f[-2]),
names(turk0))))
})
#-----------------------------------------------------------------------
# 1. Ajuste de curvas de retenção de água do solo.
cra <- read.table("http://www.leg.ufpr.br/~walmes/data/cra_manejo.txt",
header = TRUE, sep = "\t")
cra$tens[cra$tens == 0] <- 0.1
cras <- subset(cra, condi == "LVA3,5")
cras <- aggregate(umid ~ posi + prof + tens, data = cras, FUN = mean)
cras$caso <- with(cras, interaction(posi, prof))
cras$ltens <- log(cras$tens)
xyplot(umid ~ ltens | posi, groups = prof, data = cras,
type = c("p", "a"))
# modelo : van Genuchten com retrição de Mualem.
# ltens : representado por ltens (log da tensão matricial, psi).
# umid : representado por umid, conteúdo de água do solo ( % ).
# Us : assíntota inferior, mínimo da função, quando x -> +infinito.
# Ur : assíntota superior, máximo da função, quando x -> -infinito.
# al : locação, translada o ponto de inflexão.
# n : forma, altera a taxa ao redor da inflexão.
model <- umid ~ Ur + (Us - Ur)/(1 + exp(n * (al + ltens)))^(1 - 1/n)
start <- list(Ur = c(init = 0.2, from = 0, to = 0.5),
Us = c(init = 0.6, from = 0.4, to = 0.8),
al = c(1, -2, 4),
n = c(1.5, 1, 4))
cra_fit <- rp.nls(model = model,
data = cras,
start = start,
subset = "caso")
sapply(cra_fit, coef)
#-----------------------------------------------------------------------
# 2. Curva de produção em função da desfolha do algodão.
cap <- read.table("http://www.leg.ufpr.br/~walmes/data/algodão.txt",
header = TRUE, sep = "\t", encoding = "latin1")
cap$desf <- cap$desf/100
cap <- subset(cap, select = c(estag, desf, pcapu))
cap$estag <- factor(cap$estag, labels = c("vegetativo", "botão floral",
"florescimento", "maçã",
"capulho"))
str(cap)
xyplot(pcapu ~ desf | estag, data = cap, layout = c(5, 1),
xlab = "Nível de desfolha artificial", ylab = "Peso de capulhos")
# modelo: potência.
# desf : representado por desf (nível de desfolha artifical).
# pcapu : representado por pcapu (peso de capulhos), produto do algodão.
# f0 : intercepto, valor da função quando x=0 (situação ótima).
# delta : diferença no valor da função para x=0 e x=1 (situação
# extrema).
# curv : forma, indica como a função decresce, se th3=0 então função
# linear.
model <- pcapu ~ f0 - delta * desf^exp(curv)
start <- list(f0 = c(30, 25, 35),
delta = c(8, 0, 16),
curv = c(0, -2, 4))
cap_fit <- rp.nls(model = model,
data = cap,
start = start,
subset = "estag")
length(cap_fit)
sapply(cap_fit, coef)
lapply(cap_fit, summary)
#-----------------------------------------------------------------------
# 3. Curva de produção em função do nível de potássio no solo.
soja <- read.table("http://www.leg.ufpr.br/~walmes/data/soja.txt",
header = TRUE, sep = "\t", encoding = "latin1",
dec = ",")
soja$agua <- factor(soja$agua)
str(soja)
xyplot(rengrao ~ potassio|agua, data=soja)
# modelo: linear-plato.
# x: representado por potássio, conteúdo de potássio do solo.
# y: representado por rengrao, redimento de grãos por parcela.
# f0: intercepto, valor da função quando x=0.
# tx: taxa de incremento no rendimento por unidade de x.
# brk: valor acima do qual a função é constante.
model <- rengrao ~ f0 + tx * potassio * (potassio < brk) +
tx * brk * (potassio >= brk)
start <- list(f0 = c(15, 5, 25),
tx = c(0.2, 0, 1),
brk = c(50, 0, 180))
pot_fit <- rp.nls(model = model, data = soja, start = start,
subset = "agua")
sapply(pot_fit, coef)
#-----------------------------------------------------------------------
# 4. Curva de lactação.
lac <- read.table("http://www.leg.ufpr.br/~walmes/data/saxton_lactacao1.txt",
header = TRUE, sep = "\t", encoding = "latin1")
lac$vaca <- factor(lac$vaca)
str(lac)
xyplot(leite ~ dia | vaca, data = lac)
# modelo: de Wood (nucleo da densidade gama).
# x: representado por dia, dia após parto.
# y: representado por leite, quantidade produzida.
# th1: escala, desprovido de interpretação direta.
# th2: forma, desprovido de interpretação direta.
# th3: forma, desprovido de interpretação direta.
model <- leite ~ th1 * dia^th2 * exp(-th3 * dia)
start <- list(th1 = c(15, 10, 20),
th2 = c(0.2, 0.05, 0.5),
th3 = c(0.0025, 0.001, 0.008))
lac_fit <- rp.nls(model = model,
data = lac,
start = start,
subset = "vaca",
xlim = c(0, 310))
# dput(sapply(lac_fit, coef))
# structure(c(15.753532986063, 0.194320322994364, 0.00237895534802468,
# 20.6944991160729, 0.220198842519765, 0.00391704656088934, 20.2268920495124,
# 0.252907554946877, 0.00480308843437403), .Dim = c(3L, 3L), .Dimnames = list(
# c("th1", "th2", "th3"), c("1", "2", "3")))
# save(lac_fit, "ajustes.RData")
# load("ajustes.RData")
#-----------------------------------------------------------------------
# 5. Curva de secagem do solo em microondas.
sec <- read.table("http://www.leg.ufpr.br/~walmes/data/emr11.txt",
header = TRUE, sep = "\t", encoding = "latin1")
sec$nome <- factor(sec$nome)
str(sec)
xyplot(umrel ~ tempo | nome, data = sec)
# modelo: logístico.
# x: representado por tempo, período da amostra dentro do microondas.
# y: representado por umrel, umidade relativa o conteúdo total de água.
# th1: assíntota superior.
# th2: tempo para evaporar metade do conteúdo total de água.
# th3: proporcional à taxa máxima do processo.
model <- umrel ~ th1/(1 + exp(-(tempo - th2)/th3))
start <- list(th1 = c(1, 0.8, 1.2),
th2 = c(15, 0, 40),
th3 = c(8, 2, 14))
sec_fit <- rp.nls(model = model,
data = sec,
start = start,
subset = "nome")
sapply(sec_fit, coef)
lapply(sec_fit, summary)|
Modelos de Regressão Não Linear: Fundamentos e Aplicações em R leg.ufpr.br/~walmes/cursoR/mrnl |
Prof. Walmes M. Zeviani Departamento de Estatística · UFPR |