Capítulo 3 Regressão local
Agora nos voltamos para a regressão não paramétrica local. Suponha que \(x_i\in\mathbb{R}\) seja escalar e considere o modelo de regressão, no qual, a variável resposta \(Y_i\) está relacionada com a covariável pela equação \[\begin{equation} Y_i \, = \, r(x_i) \, + \, \epsilon_i, \end{equation}\] onde \(\mbox{E}(\epsilon_i)=0\), \(i=1,2,\cdots,n\).
Nesta seçã, consideramos os estimadores de \(r(x)\) obtidos pela média ponderada dos \(Y_i\), dando maior peso àqueles pontos próximos de \(x\). Começamos com o estimador de regressão Kernel.
Definição 5. Seja \(h>0\) um número positivo chamado a largura de banda. O estimador kernel Nadaraya–Watson é definido por \[\begin{equation} \widehat{r}_n(x) \, = \, \sum_{i=1}^n \mathcal{l}_i(x)Y_i, \end{equation}\] onde \(K\) é a função kernel e os pesos \(\mathcal{l}_i(x)\) são dados por \[\begin{equation} \mathcal{l}_i(x) \, = \, \frac{\displaystyle K\Big( \frac{x-x_i}{h}\Big)}{\displaystyle \sum_{j=1}^n K\Big( \frac{x-x_j}{h}\Big)}\cdot \end{equation}\]
O estimador de média local no Exemplo 3 é um particular estimador Kernel Nadaraya–Watson. Segundo esta definição, para encontrarmos estes estimadores somente faltaria encontrar qual deve ser o valor da largura de banda \(h\), mas fixando-a temos completamente definidos os pesos \(\mathcal{l}_i(x)\) e, portanto, o estimador \(\widehat{r}_n\).
Exemplo 5. (Continuação do Exemplo 1)
Queremos mostrar, comparativamente, a curva de regressão obtida pelo estimador kernel Nadaraya–Watson com o resultado do modelo de regressão linear paramétrico. A largura de banda é \(h = 1.892157\), valor obtido por validação cruzada.
## Multistart 1 of 1 |Multistart 1 of 1 |Multistart 1 of 1 |Multistart 1 of 1 /Multistart 1 of 1 |Multistart 1 of 1 | par(mfrow = c(1,1), mar = c(4, 4, 1, 1))
plot(logwage ~ age, data = cps71, col = "blue", pch=19); grid()
lines(cps71$age, fitted.values(model.par), col="darkblue", lwd = 3)
lines(cps71$age, predict(model.npar)$mean, col = "red", lwd = 3)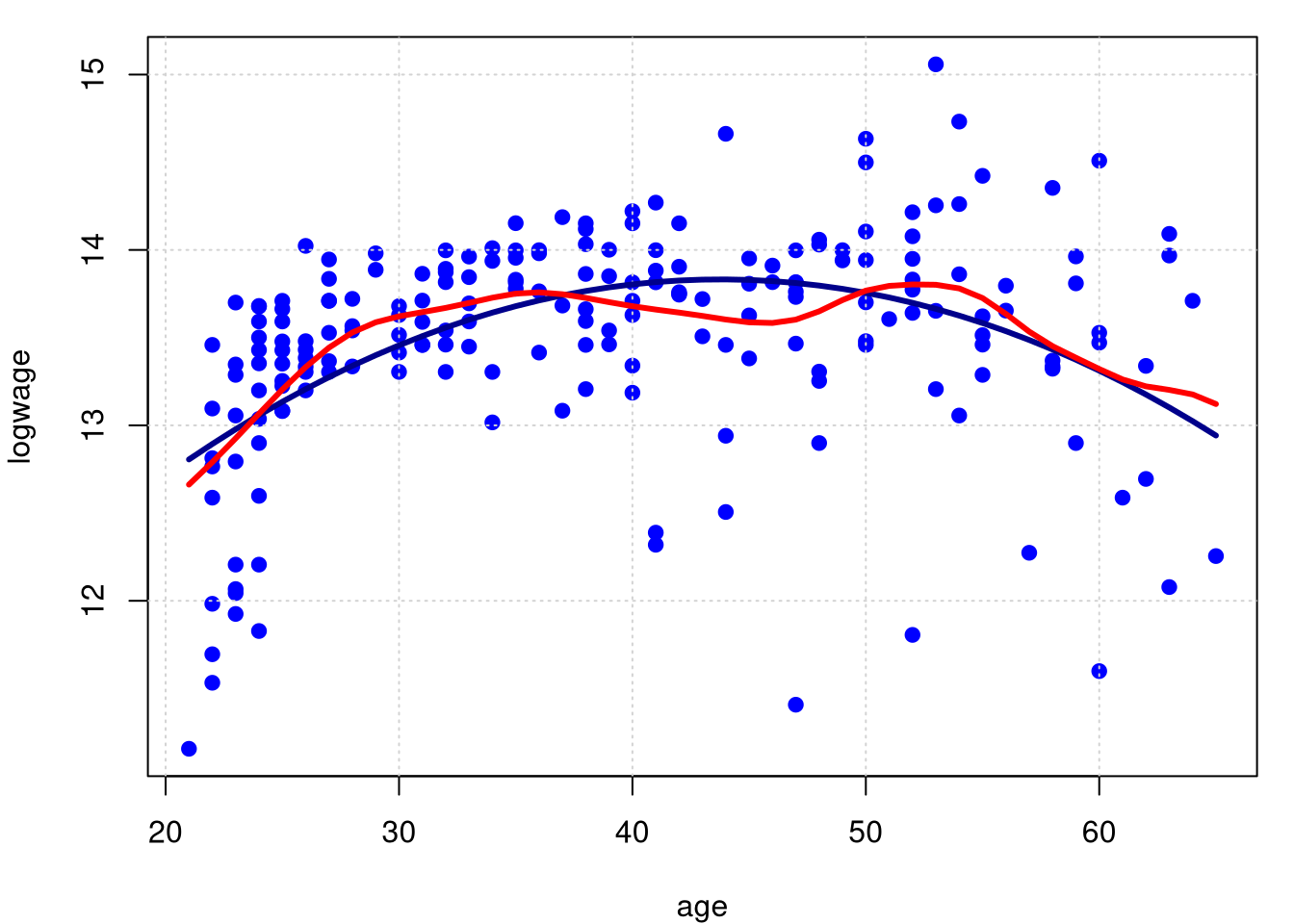
##
## Regression Data (205 observations, 1 variable(s)):
##
## Regression Type: Local-Constant
## Bandwidth Selection Method: Least Squares Cross-Validation
## Formula: logwage ~ age
## Bandwidth Type: Fixed
## Objective Function Value: 0.316055 (achieved on multistart 1)
##
## Exp. Var. Name: age Bandwidth: 1.892157 Scale Factor: 0.4487742
##
## Continuous Kernel Type: Second-Order Gaussian
## No. Continuous Explanatory Vars.: 1
## Estimation Time: 0.032 seconds## [1] 0.3108675## [1] 0.2231529Observe que o \(R^2\) no caso paramétrico foi 0.2231529, aumentando um pouco no caso não paramétrico para \(0.3108675\). Para calcularmos os graus de liberdade obsevamos que, \(\mbox{tr}(L)\) corresponde à soma dos valores diagonais da matriz \(L\). Então \[\begin{equation} \mathcal{l}_i(x_i) \, = \, \frac{\displaystyle K\Big(\frac{x_i-x_i}{h}\Big)}{\displaystyle \sum_{j=1}^n K\Big( \frac{x_i-x_j}{h}\Big)} \, = \, \frac{\displaystyle K(0)}{\displaystyle \sum_{j=1}^n K\Big( \frac{x_i-x_j}{h}\Big)}, \end{equation}\] logo \[\begin{equation} \mbox{tr}(L) \, = \, \displaystyle \sum_{i=1}^n \mathcal{l}_i(x_i) \, = \, K(0)\sum_{i=1}^n \frac{\displaystyle 1}{\displaystyle \sum_{j=1}^n K\Big( \frac{x_i-x_j}{h}\Big)}\cdot \end{equation}\]
L.matrix = function(modelo){
L.dim = modelo$nobs
x = predict(modelo)$eval[,1]
h = modelo$bw
L = matrix(0,nrow=L.dim,ncol=L.dim)
for(i in 1:L.dim){
for(j in 1:L.dim){
L[i,j] = dnorm((x[i]-x[j])/h)
}
}
L.sum = rep(0,L.dim)
for(i in 1:L.dim){
L.sum[i] = sum(L[i,1:L.dim])
}
graus.de.liberdade = dnorm(0)*sum(1/L.sum)
return(graus.de.liberdade)
}
L.matrix(model.npar)## [1] 9.516161Observe que os graus de liberdade nesta situação são \(9.516161\).
A escolha do kernel não é muito importante. As estimativas obtidas usando kernels diferentes são, geralmente, numericamente muito semelhantes. Esta observação é confirmada por cálculos teóricos que mostram que, o risco é muito insensível à escolha do kernel; veja Seção 6.2.3 de Scott (1992). Então mostramos o resultado utilizando o kernel gaussiano, que é padrão do comando. Com esta observação vemos que, especificar ou não o kernel, não é muito importante.
O que importa muito mais é a escolha da largura de banda \(h\), que controla a quantidade de suavização. Larguras de banda pequenas fornecem estimativas muito aproximadas, enquanto larguras de banda maiores fornecem estimativas mais suaves. Em geral, vamos deixar a largura de banda depender do tamanho da amostra então, às vezes, escrevemos \(h_n\).
O teorema a seguir mostra como a largura de banda afeta o estimador. Para declarar estes resultados, precisamos fazer alguma suposição sobre o comportamento de \(x_1,\cdots,x_n\) quando \(n\) aumenta. Para os propósitos do teorema, assumiremos que estes são escolhidos aleatoriamente de alguma densidade \(f\).
Teorema 3. O risco, usando perda de erro quadrada integrada, do estimador kernel Nadaraya-Watson é \[\begin{equation} \begin{array}{rcl} R(\widehat{r}_n,r) & = & \displaystyle\frac{h_n^4}{4}\left(\int x^2K(x)\mbox{d}x \right)^2 \int \left(r''(x)+2r'(x)\frac{f'(x)}{f(x)} \right)^2 \mbox{d}x\\ & & \qquad \qquad \qquad \displaystyle + \frac{\displaystyle \sigma^2\int K^2(x)\mbox{d}x}{nh_n}\int \frac{1}{f(x)}\mbox{d}x + o(nh_n^{-1}) + o(h_n^4), \end{array} \end{equation}\] quando \(h_n\to 0\) e \(nh_n\to \infty\).
Demonstração. Ver Scott (1992).
O primeiro termo no Teorema 3 é o viés ao quadrado e o segundo termo é a variância. O que é especialmente notável é a presença do termo \[\begin{equation} 2r'(x)\frac{f'(x)}{f(x)} \end{equation}\] no viés.
Chamamos esta expressão de viés de design, pois depende do design, ou seja, da distribuição dos \(x_i\). Isso significa que o viés é sensível à posição dos \(x_i\). Além disso, pode-se mostrar que os estimadores de kernel também possuem alta tendência perto dos limites. Isso é conhecido como viés de limite. Veremos que podemos reduzir esses vieses usando um refinamento chamado regressão polinomial local.
Se diferenciarmos a expresão no Teorema 3 e definirmos o resultado igual a 0, veremos que a largura de banda ideal \(h_*\) é \[\begin{equation} h_* \, = \, \Big(\frac{1}{n}\Big)^{1/5}\left( \dfrac{\displaystyle \sigma^2\int K^2(x)\mbox{d}x \int \frac{1}{f(x)}\mbox{d}x} {\displaystyle \left(\int x^2K(x)\mbox{d}x \right)^2 \int \left(r''(x)+2r'(x)\frac{f'(x)}{f(x)} \right)^2 \mbox{d}x}\right)^{1/5}\cdot \end{equation}\] Assim, \(h_*= O(n^{-1/5})\). Colocando \(h_*\) de volta na expressão do Teorema 3, vemos que o risco diminui na taxa \(O(n^{−4/5})\).
Na maioria dos modelos paramétricos, o risco do estimador de máxima verossimilhança diminui para 0 na taxa \(1/n\). A taxa mais lenta \(n^{−4/5}\) é o preço de usar métodos não paramétricos. Na prática, não podemos usar a largura de banda dada acima, isso devido a que \(h_*\) depende da função desconhecida \(r\). Em vez disso, usamos a validação cruzada, conforme descrita no Teorema 2.