Capítulo 5 Splines
Considere mais uma vez o modelo de regressão \[\begin{equation} Y_i \, = \, r(x_i) \, + \epsilon_i \end{equation}\] e suponha que estimamos \(r\) escolhendo \(\widehat{r}_n(x)\) que minimiza as somas de quadrados \[\begin{equation} \sum_{i=1}^n \big( Y_i - \widehat{r}_n(x_i)\big)^2\cdot \end{equation}\]
A minimização de todas as funções lineares, isto é, das funções da forma \(\beta_0 + \beta_1 x\) produz o estimador de mínimos quadrados. Minimizar todas as funções produz uma função que interpola os dados. Anteriormente evitamos essas duas soluções extremas, substituindo as somas de quadrados por somas de quadrados ponderadas localmente.
Uma maneira alternativa de obter soluções entre esses extremos é minimizar as somas de quadrados penalizadas \[\begin{equation} M(\lambda) \, = \, \sum_{i=1}^n \big( Y_i - \widehat{r}_n(x_i)\big)^2 \, + \, \lambda J(r), \end{equation}\] onde \(J(r)\) é uma penalidade de aspereza. Adicionar um termo de penalidade ao critério que estamos otimizando é às vezes chamado de regularização.
Vamos nos concentrar no caso especial \[\begin{equation} J(r) \, = \, \int \big(r''(x) \big)^2\mbox{d}x\cdot \end{equation}\] O parámetro \(\lambda\) controla a troca entre o ajuste e a penalidade. Vamos denotar por \(\widehat{r}_n\) a função que minimiza \(M(\lambda)\). Quando \(\lambda = 0\), a solução é a função de interpolação. Quando \(\lambda \to \infty\), \(\widehat{r}_n\) converge para a linha de mínimos quadrados. O parámetro \(\lambda\) controla a quantidade de suavização. Como é a aparência do \(\widehat{r}_n\) para \(0 <\lambda <\infty\)? Para responder a essa pergunta, precisamos definir splines.
Spline é um polinómio especial por partes, mais detalhes sobre splines podem ser encontrados em Wahba (1990). Os splines mais utilizadas são os splines cúbicos por partes.
- \(r\) é um polinómio cúbico sobre \((\xi_1,\xi_2),(\xi_2,\xi_3),\cdots\) e
- \(r\) tem primeira e segunda derivadas contínuas nos nós.
Generalizando mais, um spline de ordem \(m\) é um polinómio de grau \(m-1\) por partes com \(m-2\) derivadas contínuas nos nós. Um spline que é linear além dos nós limítrofes é chamado de spline natural.
Splines cúbicos, ou seja, com \(m = 4\) são os splines mais comuns usados na prática. Eles surgem naturalmente na estrutura de regressão penalizada, como mostra o seguinte teorema.
Demonstração. Wahba (1990).
O teorema acima não fornece uma forma explícita para \(\widehat{r}_n\). Para fazer isso, vamos construir uma base para o conjunto de splines.
Teorema 7. Sejam \(\xi_1 <\xi_2 < \cdots <\xi_k\) nós contidos em um intervalo \((a,b)\). Definimos \(h_1(x)=1\), \(h_2(x)=x\), \(h_3(x)=x^2\), \(h_4(x)=x^3\) e \(h_j(x)=(x-\xi_{j-4})^3_+\) para \(j=5,\cdots,k+4\). As funções \(\{h_1,\cdots,h_{k+4}\}\) formam uma base para o conjunto de splines cúbicos nesses nós, chamada de base do poder truncado. Assim, qualquer spline cúbico \(r(x)\) com esses nós pode ser escrito como \[\begin{equation} r(x) \, = \, \sum_{j=1}^{k+4} \beta_j h_j(x)\cdot \end{equation}\]
Demonstração. Wahba (1990).
Agora, introduzimos uma base diferente para o conjunto de splines naturais, chamada de base B-spline, que é particularmente adequada para cálculos. Estes são definidos da seguinte maneira.
Seja \(\xi_0=a\) e \(\xi_{k+1}=b\). Definimos novos nós \(\tau_1,\cdots,\tau_m\) tais que \[\begin{equation} \tau_1 \leq \tau_2 \leq \tau_3 \leq \cdots \leq \tau_m \leq \xi_0, \end{equation}\] \(\tau_{j+m}=\xi_j\) para \(j=1,\cdots,k\) e \[\begin{equation} \xi_{k+1} \leq \tau_{k+m+1} \leq \cdots \leq \tau_{k+2m}\cdot \end{equation}\]
A escolha dos nós extras é arbitrá, geralmente escolhemos \[\begin{equation} \tau_1=\cdots=\tau_m=\xi_0 \end{equation}\] e \[\begin{equation} \xi_{k+1}=\tau_{k+m+1}=\cdots=\tau_{k+2m}\cdot \end{equation}\] Definimos as funções na base recursivamente do seguinte modo. Primeiro definimos \[\begin{equation} B_{i,1}(x)=\left\{ \begin{array}{cc} 1, & \mbox{ caso } \tau_i\leq x < \tau_{i+1} \\ 0, & \mbox{ caso contrário}\end{array}\right., \end{equation}\] para \(i=1,2,\cdots,k+2m-1\). Em seguida, para \(r \leq m\) definimos \[\begin{equation} B_{i,r}(x) \, = \, \displaystyle \frac{x-\tau_i}{\tau_{i+r-1}-\tau_i}B_{i,r-1}(x) \, + \, \frac{\tau_{i+r}-x}{\tau_{i+r}-\tau_{i+1}}B_{i+1,r-1}(x), \end{equation}\] para \(i = 1,\cdots,k + 2m−r\). Entende-se que, se o denominador é 0, a função é definida como 0.
library(splines)
x = seq(0,1, by = 0.01)
curvas = bs(x, knots = seq(0,1,length.out = 9), degree = 3)
par(mfrow = c(1,1), mar = c(2, 2, 1, 1))
plot(seq(0,1,length.out = 101), curvas[,1], type = "l", ylim = c(0,1)); grid()
for(i in 2:10) lines(seq(0,1,length.out = 101), curvas[,i], lty = 2)
lines(seq(0,1,length.out = 101), curvas[,11], lty = 1)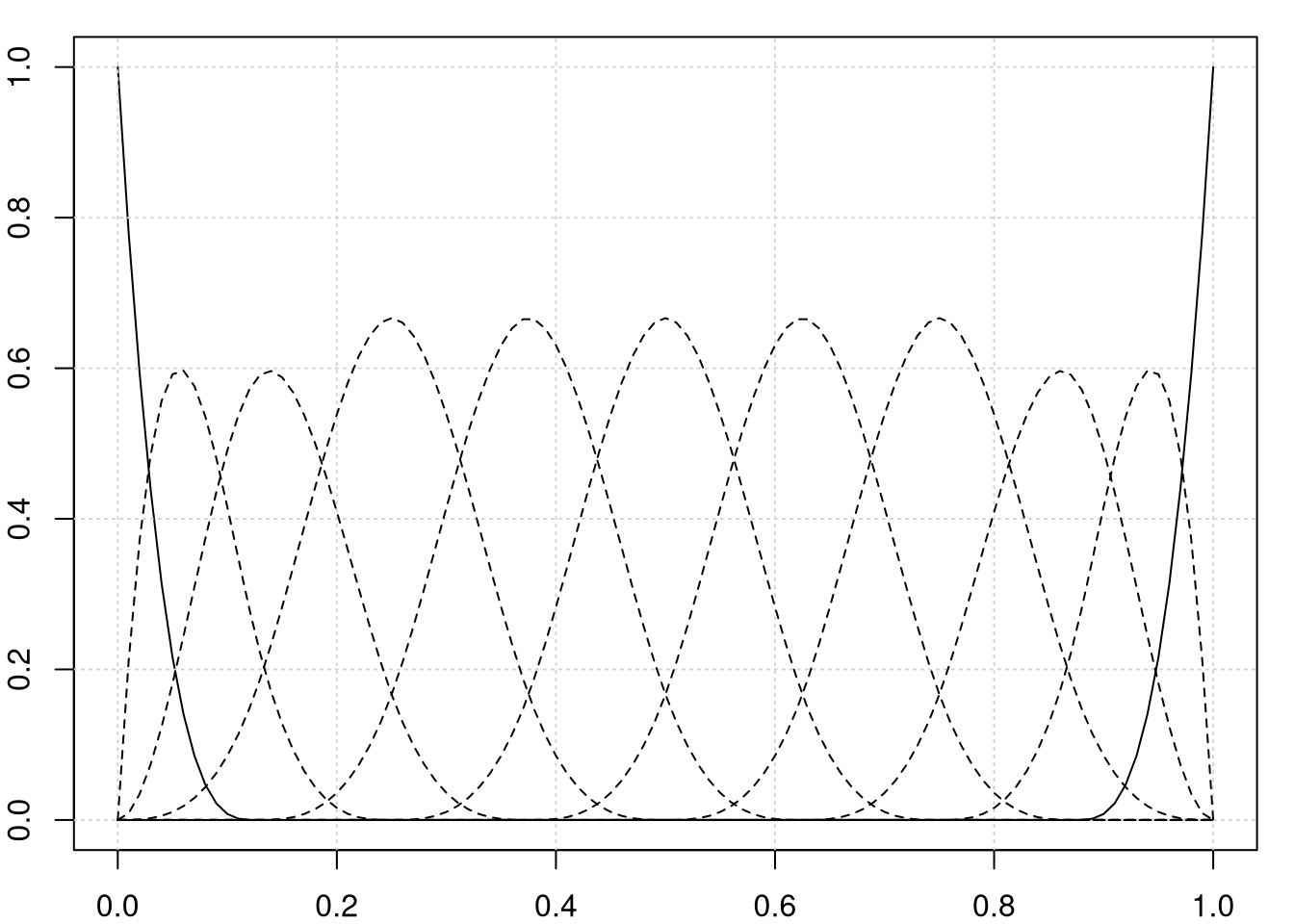 Base cúbica B-spline usando nove nós igualmente espaçados em (0,1).
Base cúbica B-spline usando nove nós igualmente espaçados em (0,1).
Por padrão, os splines são cúbicos, ou seja, com \(m=4\) ou \(degree = 3\) não sendo necessário especificar.
Teorema 8. As funções \(\{B_{i,4}, \, i = 1,\cdots, k + 4\}\) são uma base para o conjunto de splines cúbicos. Eles são chamados de funções de base B-spline.
Demonstração. Hastie et al. (2001).
A vantagem das funções de base B-spline é que elas possuem suporte compacto que torna possível acelerar os cálculos. Veja Hastie et al. (2001) para detalhes. A figura acima mostra a base cúbica B-spline usando nove nós igualmente espaçados em (0,1).
Estamos agora em condições de descrever o estimador spline em mais detalhes. De acordo com o Teorema 6, \(\widehat{r}\) é um spline cúbico natural. Portanto, podemos escrever \[\begin{equation} \widehat{r}_n(x) \, = \, \sum_{i=1}^N \widehat{\beta}_j B_j(x), \end{equation}\] onde \(B_1,\cdots,B_N\) são uma base para os splines naturais, como os B-splines com \(N = n + 4\). Assim, precisamos apenas encontrar os coeficientes \(\widehat{\beta}=(\widehat{\beta}_1,\cdots,\widehat{\beta}_N)^\top\).
Ao expandir \(r\) na base, podemos agora reescrever a minimização da seguinte forma: \[\begin{equation} \mbox{minimizar: } \quad (Y-B\beta)^\top (Y-B\beta) \, + \, \lambda \beta^\top \Omega \beta, \end{equation}\] onde \(B_{i,j}=B_j(X_i)\) e \(\Omega_{jk}=\int B_j''(x)B_k''(x)\mbox{d}x\).
Teorema 9. O valor de \(\beta\) que minimiza \((Y-B\beta)^\top (Y-B\beta) \, + \, \lambda \beta^\top \Omega \beta\) é \[\begin{equation} \widehat{\beta} \, = \, (B^\top B \, + \, \lambda \Omega)^{-1}B^\top Y\cdot \end{equation}\]
Demonstração. Hastie et al. (2001).
Deste teorema concluimos que os splines são outro exemplo de suavizadores lineares.
Teorema 10. O spline de suavização \(\widehat{r}_n(x)\) é um suavizador linear, ou seja, existem pesos \(\mathcal{l}(x)\) tais que \(\widehat{r}_n(x) \, = \, \sum_{i=1}^n Y_i \mathcal{l}_i(x)\). Em particular, a matriz de alisamento \(L\) é \[\begin{equation} L \, = \, B(B^\top B \, + \, \lambda\Omega)^{-1}B^\top, \end{equation}\] e o vetor \(r\) de valores ajustados é dado por \[\begin{equation} r \, = \, LY\cdot \end{equation}\]
Demonstração. Hastie et al. (2001).
Se tivessemos feito uma regressão linear ordinária de \(Y\) em \(B\), a matriz chapêu seria \[\begin{equation} L = B(B^\top B)^{-1}B^\top \end{equation}\] e os valores ajustados interpolariam os dados observados. O efeito do termo \(\lambda\Omega\) é reduzir os coeficientes de regressão para um subespaço, o que resulta em um ajuste mais suave. Como antes, nós definimos os graus de liberdade efetivos por \(\nu = \mbox{tr}(L)\) e escolhemos o parámetro de suavização \(\lambda\) por validação cruzada.
Exemplo 8.
Novamente utilizamos os dados do Exemplo assim como o resultado do modelo de regressão linear paramétrico para mostrar a curva de regressão não paramétrica obtida por splines.
As funções smooth.spline e bs, esta última utilizada anteriormente, estão disponíveis no pacote splines.
## Call:
## smooth.spline(x = age, y = logwage)
##
## Smoothing Parameter spar= 0.6265389 lambda= 0.001355428 (11 iterations)
## Equivalent Degrees of Freedom (Df): 7.803765
## Penalized Criterion (RSS): 8.241849
## GCV: 0.2925978A figura mostra o spline de suavização obtido por validação cruzada para os dados em cps71. O número efetivo de graus de liberdade é 7.8. O ajuste é tão suave quanto o obtido com o estimador de regressão local. A diferença entre os dois ajustes é pequena comparada com a largura das bandas de confiança que iremos calcular mais tarde.
par(mfrow = c(1,1), mar = c(4, 4, 1, 1))
plot(logwage ~ age, data = cps71, col = "blue", pch=19); grid()
lines(cps71$age, fitted.values(model.par), col="darkblue", lwd = 3)
lines(model.npar06, col = "red", lwd = 3)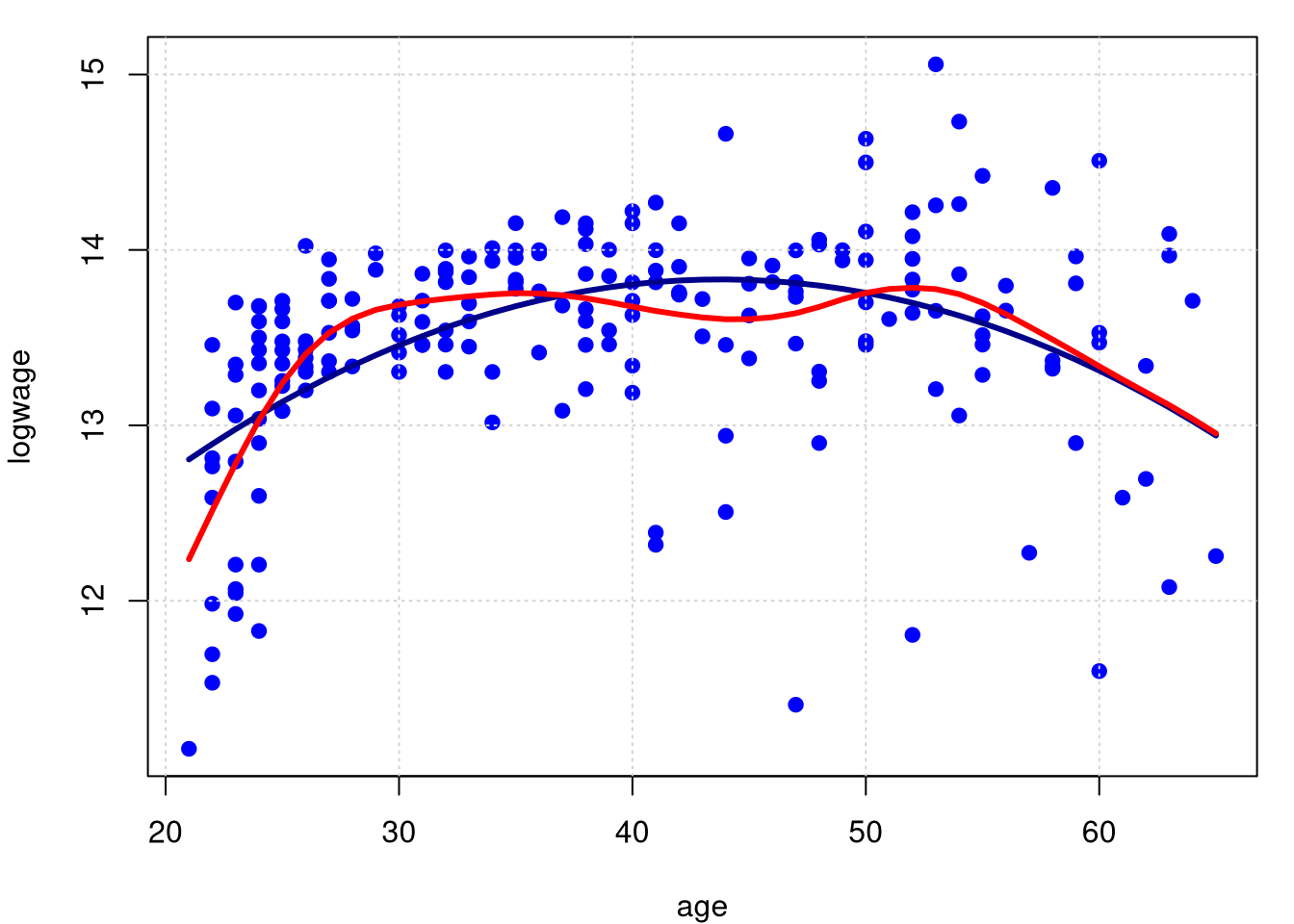
Para podermos clacular o valor do \(R^2\) nesta situação procedemos como mostrado a seguir.
## [1] 0.3290406Observa-se que o valor do \(R^2=0.33\) é muito maior do que o obtido por outros modelos apresentados.
5.1 Estimação da variância
Consideramos vários métodos para estimar \(\sigma^2\). Para suavizadores lineares, existe uma estimativa simples e quase isenta de \(\sigma^2\).
Teorema 11 Seja \(\widehat{r}_n\) um suavizador linear. Então \[\begin{equation} \widehat{\sigma}^2 \, = \, \frac{\displaystyle\sum_{i=1}^n \Big( Y_i-\widehat{r}_n(x_i)\Big)^2}{n-2\nu+\widetilde{\nu}}, \end{equation}\] onde \[\begin{equation} \nu \, = \, \mbox{tr}(L) \qquad \mbox{e} \qquad \widetilde{\nu} \, = \, \mbox{tr}(L^\top L) \, = \, \sum_{i=1}^n ||\mathcal{l}(x_i)||^2\cdot \end{equation}\] Se \(r\) for suficientemente suave, \(\nu = o(n)\) e \(\widetilde{\nu} = o(n)\), então \(\widehat{\sigma}^2\) é um estimador consistente de \(\sigma^2\).
Demonstração. Lembremos que se \(Y\) é um vetor aleatório e \(Q\) uma matriz simétrica, então \(T^\top QY\) é uma forma quadrática e, como consequência, \[\begin{equation} \mbox{E}(T^\top QY) \, = \, \mbox{tr}(QV) \, + \, \mu^\top Q\mu, \end{equation}\] onde \(V=\mbox{Var}(Y)\) é a matriz de covariâncias de \(Y\) e \(\mu=\mbox{E}(Y)\) a esperança do vetor. Agora \[\begin{equation} Y-r \, = \, Y \, - \, LY \, = \, (I-L)Y \end{equation}\] e também \[\begin{equation} \widehat{\sigma}^2 \, = \, \frac{Y^\top \Lambda Y}{\mbox{tr}(\Lambda)}, \end{equation}\] onde \(\Lambda=(I-L)^\top (I-L)\). Consequentemente \[\begin{equation} \mbox{E}(\widehat{\sigma}^2) \, =\, \frac{\mbox{E}(T^\top \Lambda Y)}{\mbox{tr}(\Lambda)} \, =\, \sigma^2 \, + \, \frac{r^\top \Lambda r}{n-2\nu+\widetilde{\nu}}\cdot \end{equation}\] Assumindo que \(\nu\) e \(\widehat{\nu}\) não cresçam muito rapidamente e que \(r\) seja suave, o último termo é pequeno para \(n\) grande e, portanto, \(\mbox{E}(\widehat{\sigma}^2)\approx \sigma^2\). Da mesma forma, pode-se mostrar que \(\lim_{n\to\infty} \mbox{Var}(\widehat{\sigma}^2)=0\).
Aqui mostramos um outro estimador, devido a Rice (1984). Suponha que os \(x_i\) estejam ordenados. Definimos \[\begin{equation} \widehat{\sigma}^2 \, = \, \frac{1}{2(n-1)}\sum_{i=1}^{n-1} \big( Y_{i+1}-Y_i\big)^2\cdot \end{equation}\] Qual é a motivação para este estimador? Assumindo que \(r(x)\) seja suave, temos que \[\begin{equation} r(x_{i+1})-r(x_i)\approx 0 \end{equation}\] e portanto \[\begin{equation} Y_{i+1}-Y_i \, = \, \big( r(x_{i+1})+\epsilon_{i+1}\big) \, - \, \Big(r(x_i)+\epsilon_i\Big) \, \approx \, \epsilon_{i+1}-\epsilon_i \end{equation}\] e, portanto \(\big( Y_{i+1}-Y_i\big)^2\approx \epsilon_{i+1}^2+\epsilon_i^2-2\epsilon_{i+1}\epsilon_i\). Assim sendo, \[\begin{equation} \begin{array}{rcl} \mbox{E}\big( Y_{i+1}-Y_i\big)^2 & \approx & \mbox{E}(\epsilon_{i+1}^2) \, + \, \mbox{E}(\epsilon_i^2) \, - \, 2\mbox{E}(\epsilon_{i+1})\mbox{E}(\epsilon_i) \\ & = & \mbox{E}(\epsilon_{i+1}^2) \, + \, \mbox{E}(\epsilon_i^2) \, = \, 2\sigma^2\cdot \end{array} \end{equation}\] Assim, \(\mbox{E}(\widehat{\sigma}^2)\approx \sigma^2\). Uma variação deste estimador, devido a Gasser et al. (1986) é \[\begin{equation} \widehat{\sigma}^2 = \frac{1}{n-2}\sum_{i=2}^{n-1} c_i^2\delta_i^2, \end{equation}\] onde \[\begin{equation} \begin{array}{ll} \delta_i \, = \, a_iY_{i-1} \, + \, b_iY_{i+1} \, - \, Y_i, & a_i \, = \, (x_{i+1}-x_i)/(x_{i+1}-x_{i-1}), \\ b_i \, = \, (x_{i}-x_{i-1})/(x_{i+1}-x_{i-1}), & c_i^2 \, = \, (a_i^2 \, + \, b_i^2 \, + \, 1)^{-1}\cdot \end{array} \end{equation}\] A intuição deste estimador é que a média dos resíduos que resultam da montagem de uma linha ao primeiro e terceiro ponto de cada triplo consecutivo de pontos.
Exemplo 9.
Vamos utilizar novamente os dados do Exemplo 1. Nessa situação avaliamos os diferentes estimadores da variância apresentados até o momentos. O valor do estimador da variâcia no Teorema 11 é a saída padrão do comando locpol. Assim, podemos observar a estimativa da seguinte forma:
##
## Kernel =
## dnorm(x, 0, 1)
##
## n deg bw ase
## 205 1 1.49995 0.2612706Para avaliarmos o estimador de Rice (1984) podemos executar os seguintes comandos:
## [1] 0.3233995O estimador proposto por Gasser et al. (1986) é um pouco mais complexo e nesta situação não pode ser calculado. Isto acontece porque temos muitos valores iguais na variável explicativa cps71$age.
Até agora assumimos a homocedasticidade, significando que \(\sigma^2= \mbox{Var}(\epsilon_i)\) não varia com \(x\). No Exemplo 1 isso é flagrantemente falso. Claramente, \(\sigma^2\) aumenta com \(x\), então os dados são heterocedásticos. A estimativa da função \(\widehat{r}_n(x)\) é relativamente insensível à heterocedasticidade. No entanto, quando se trata de fazer bandas de confiança para \(r(x)\), devemos levar em conta a variância não constante.
Vamos assumir a seguinte abordagem. Veja Yu and Jones (2004) e referências para outras abordagens. Suponha que \[\begin{equation} Y_i \, = \, r(x_i) \, + \, \sigma(x_i)\epsilon_i\cdot \end{equation}\] Seja \(Z_i \, = \, \mbox{log}\big(Y_i-r(x_i)\big)^2\) e \(\delta_i \, = \, \mbox{log}(\epsilon_i^2)\). Então, \[\begin{equation} Z_i \, = \, \mbox{log}\big(\sigma^2(x_i)\big) \, + \, \delta_i\cdot \end{equation}\] Isto sugere obter a estimativa de \(\mbox{log}\big(\sigma^2(x)\big)\) pela regressão do logaritmo dos resíduos ao quadrado em \(x\).
Prosseguimos como segue:- Estimar \(r(x)\) com qualquer método não paramétrico para obter a estimativa \(\widehat{r}_n(x)\).
- Definir \(Z_i \, = \, \mbox{log}\big(Y_i-\widehat{r}_n(x_i)\big)^2\).
- Obter uma curva de regressão de \(Z\) nos \(x\), novamente usando qualquer método não paramétrico, para obter uma estimativa \(\widehat{q}(x)\) do \(\mbox{log}\big(\sigma^2(x)\big)\) e calcular \[\begin{equation} \widehat{\sigma}^2(x) \, = \, e^{\widehat{q}(x)}\cdot \end{equation}\]
Uma desvantagem dessa abordagem é que o logaritmo de um resíduo muito pequeno será um grande outlier. Uma alternativa é suavizar diretamente os resíduos ao quadrado.
Exemplo 10.
Utilizaremos os dados do Exemplo 1. O objetivo agora é mostrar a curva \(\mbox{log}\big(\sigma^2(x)\big)\) para cada um dos modelos estudados e utilizados nos dados deste exemplo, ou seja, mostrarmos a curva heterocedástica do logaritmo da variância para os modelos de regressão não paramétricos de polinômios locais e splines. Procedemos como descrito anteriormente e as curvas obtidas apresentam-se nos gráficos a seguir.
Em ambos gráficos mantivemos a mesma escala nos eixos, isto com o objetivo de melhor visualizar as diferenças entre as curvas e entre os pontos, lembrando que são o logaritmo dos resíduos ao quadrado. Percebemos que tanto os resíduos quanto as curvas são bem diferentes entre estes modelos.
# Polinomio local
Z = log((cps71$logwage-model.npar05$lpFit[,2])^2)
hn = regCVBwSelC(cps71$age, Z, deg = 1, kernel = gaussK, interval = c(0,10))
model.npar05.Z = locpol(Z ~ age, data = cps71, kernel = gaussK, bw = hn,
xevalLen = length(cps71$age))
sigma05 = exp(model.npar05.Z$lpFit[,2])
## adicionando espaço extra às margens direita e esquerda do gráfico dentro do quadro
par(mar=c(1, 3, 2, 3) + 0.1)
## Plotando o primeiro conjunto de dados e desenhando seu eixo
plot(Z ~ age, data = cps71, col = "blue", pch=19, ylab = "", xlab = "", cex = 0.8,
ylim = c(-18,3), main = "Polinômios locias", axes = FALSE); grid()
axis(2, ylim=c(-18,3), col="blue", las=1, cex.axis = 0.8)
mtext(expression(paste("log(",sigma^2,"(x))")), side = 2, adj = 1,
las = 0, at = 3, line = 1.5)
lines(cps71$age, model.npar05.Z$lpFit[,2], col="darkblue", lwd = 3)
box()
par(new=TRUE)
## Plotando o segundo gráfico e colocando a escala do eixo à direita
plot(sigma05, pch=15, xlab="", ylab="", ylim=c(0,0.6), axes=F, type="b", col="red")
axis(4, ylim=c(0,0.6), lwd=2, line=0.1, col="red", col.axis = "red",
las = 1, cex.axis = 0.8)
mtext("Variância", side=4, line=1.9, col="red")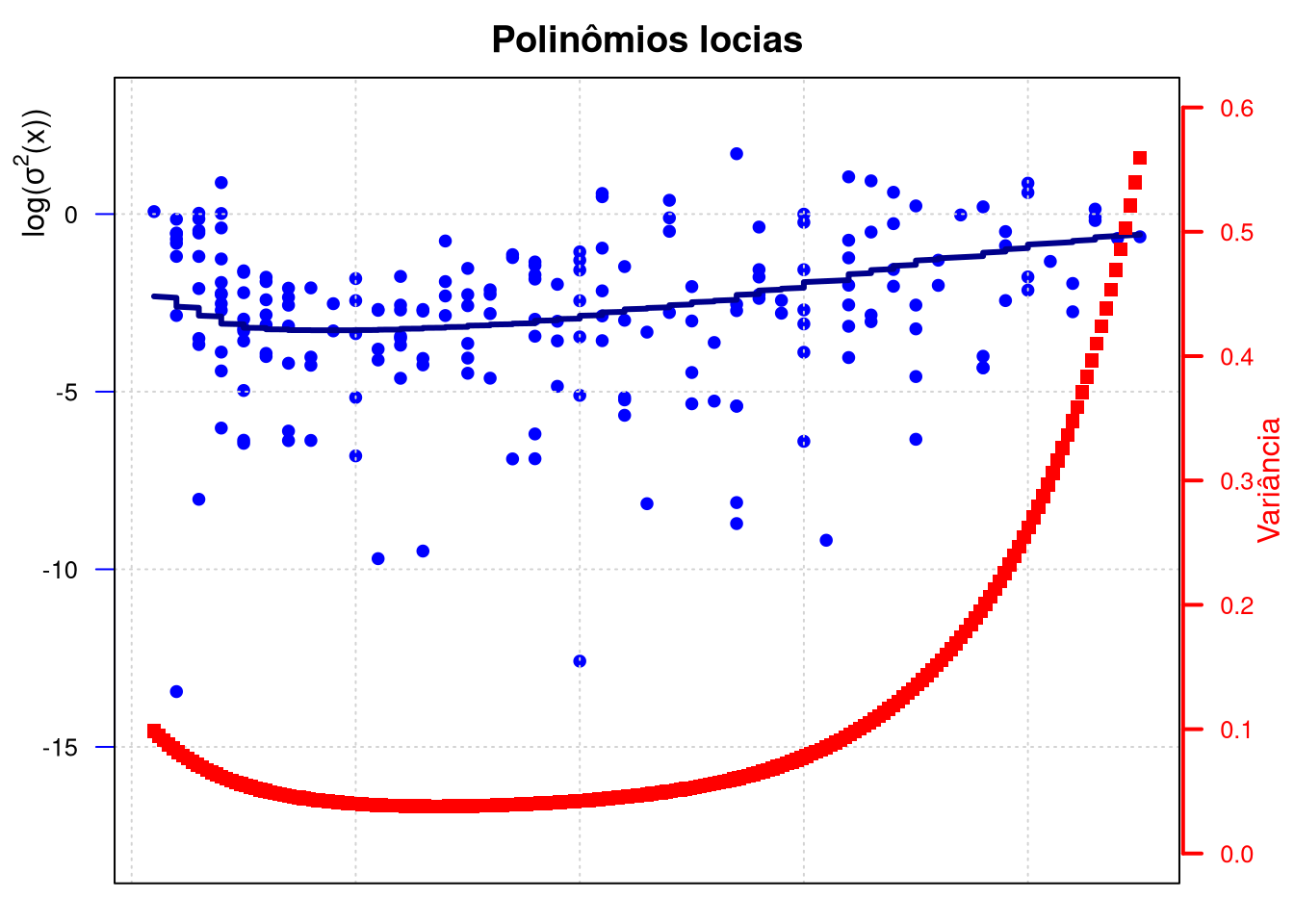
# Spline
Z1 = log((cps71$logwage-fitted(model.npar06))^2)
model.npar06.Z1 = with(cps71, smooth.spline(age, Z1))
sigma06 = exp(fitted(model.npar06.Z1))
par(mar = c(1, 3, 2, 3) + 0.1)
plot(Z1 ~ age, data = cps71, col = "blue", pch=19, ylab = "", ylim = c(-18,3),
cex = 0.8, main = "Splines", axes = FALSE); grid()
axis(2, ylim=c(-18,3), col="blue", las=1, cex.axis = 0.8)
mtext(expression(paste("log(",sigma^2,"(x))")), side = 2, adj = 1,
las = 0, at = 3, line = 1.5)
lines(cps71$age, fitted(model.npar06.Z1), col="darkblue", lwd = 3)
box()
par(new=TRUE)
## Plotando o segundo gráfico e colocando a escala do eixo à direita
plot(sigma06, pch=15, xlab="", ylab="", ylim=c(0,0.6), axes=F, type="b", col="red")
axis(4, ylim=c(0,0.6), lwd=2, line=0.1, col="red", col.axis = "red",
las =1, cex.axis = 0.8)
mtext("Variância", side=4, line=1.9, col="red")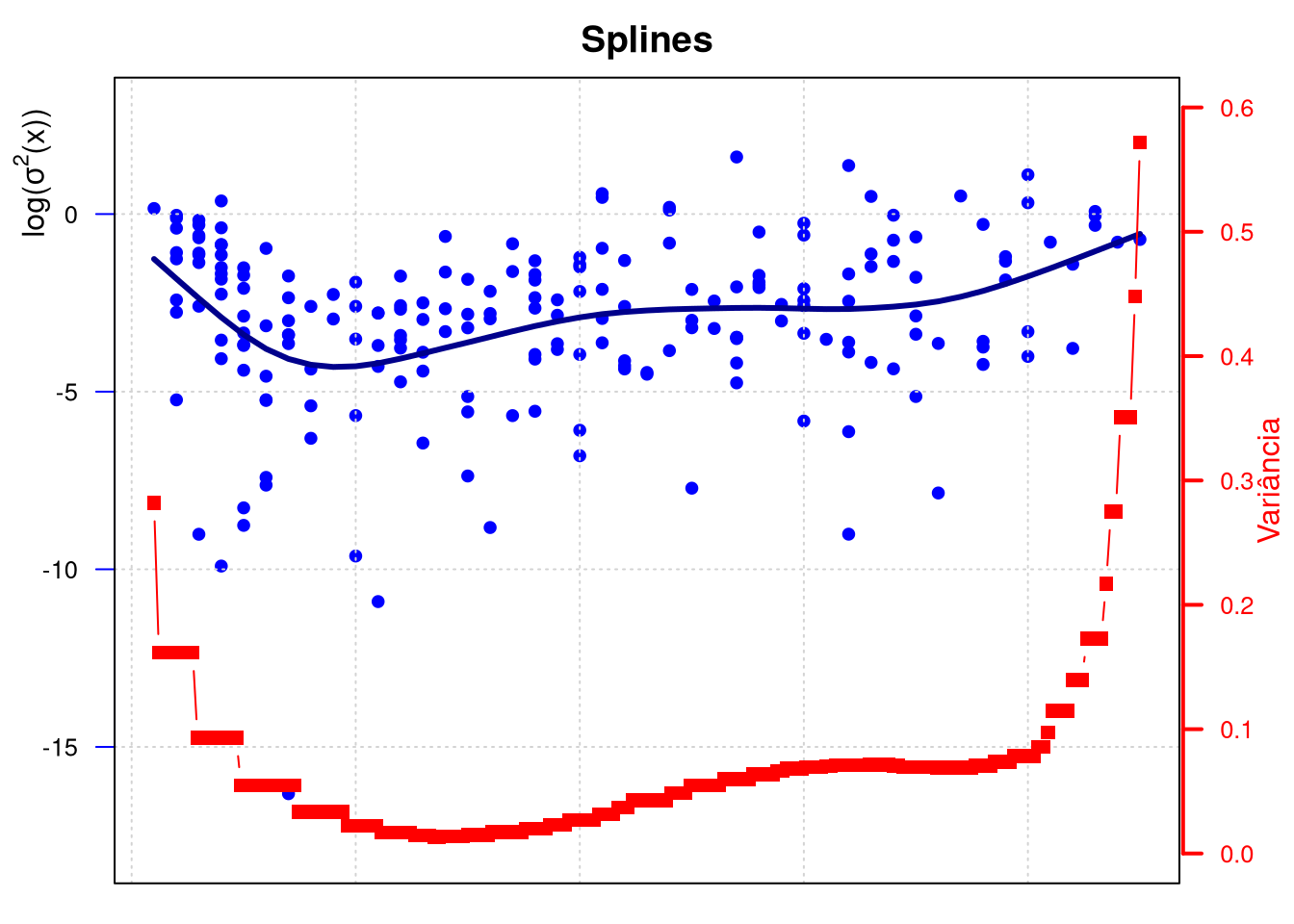
5.2 Bandas de confiança
Nesta seção, vamos construir faixas de confiança para \(r(x)\). Normalmente, essas bandas são da forma \[\begin{equation} \widehat{r}_n(x) \, \pm \, c \, \mbox{se}(x), \end{equation}\] onde \(\mbox{se}(x)\) é uma estimativa do desvio padrão de \(\widehat{r}_n(x)\) e \(c> 0\) é alguma constante. Antes de prosseguirmos, discutimos um problema pernicioso que surge sempre que fazemos o alisamento, ou seja, o problema do viés.
O problema do viés
Bandas de confiança não são realmente bandas de confiança para \(r(x)\), ao contrário, elas são bandas de confiança para \(\widehat{r}_n(x) = \mbox{E}\big(\widehat{r}_n(x)\big)\) que podemos imaginar como uma versão suavizada de \(r(x)\). Obter um conjunto de confiança para a verdadeira função \(r(x)\) é complicado por razões que agora explicamos.
Denote a média e o desvio padrão de \(\widehat{r}_n(x)\) por \(\overline{r}_n(x)\) e \(s_n(x)\). Então, \[\begin{equation} \begin{array}{rcl} \displaystyle\frac{\widehat{r}_n(x)-r(x)}{s_n(x)} & = & \displaystyle\frac{\widehat{r}_n(x)-\overline{r}_n(x)}{s_n(x)} \, + \, \frac{\overline{r}_n(x)-r(x)}{s_n(x)} \\ & = & Z_n(x) \, + \, \, + \, \displaystyle\frac{\mbox{bias}\big( \widehat{r}_n(x)\big)} {\sqrt{\mbox{variância}\big( \widehat{r}_n(x)\big)}}, \end{array} \end{equation}\] onde \(Z_n(x)=\big(\widehat{r}_n(x)-\overline{r}_n(x)\big)/s_n(x)\).
Tipicamente, o primeiro termo \(Z_n(x)\) converge para uma Normal padrão do qual derivam as faixas de confiança. O segundo termo é o viés dividido pelo desvio padrão. Na inferência paramétrica, o viés é geralmente menor que o desvio padrão do estimador, portanto, esse termo vai para zero à medida que o tamanho da amostra aumenta. Na inferência não paramétrica, vimos que o alisamento ótimo corresponde ao balanceamento do viés e do desvio padrão. O segundo termo não desaparece mesmo com amostras grandes.
A presença desse segundo termo não invasivo introduz um viés no limite Normal. O resultado é que o intervalo de confiança não será centrado em torno da verdadeira função \(r\) devido ao viés de suavização \(\overline{r}_n(x)-r(x)\).
Existem várias coisas que podemos fazer sobre esse problema. A primeira é: viva com isso. Em outras palavras, basta aceitar o fato de que a faixa de confiança é para \(\overline{r}_n(x)\) não para \(r\). Não há nada de errado com isso, contanto que tenhamos cuidado quando reportarmos os resultados para deixar claro que as inferênças são para \(\overline{r}_n\) não \(r\). Uma segunda abordagem é estimar a função de viés \[\begin{equation} \overline{r}_n(x) - r(x)\cdot \end{equation}\]
Isso é difícil de fazer. De fato, o termo principal do viés é \(r''(x)\) e a estimativa da segunda derivada de \(r\) é muito mais difícil do que a estimativa de \(r\). Isso requer a introdução de condições de suavidade extras que, em seguida, colocam em questão o estimador original que não usou essa suavidade extra. Isso tem uma certa circularidade desagradável para ele. Uma terceira abordagem é a falta de bom senso. Se suavizarmos menos do que a quantidade ideal, a tendência diminuirá assintoticamente em relação à variação. Infelizmente, não parece haver uma regra prática simples para escolher a quantidade certa de sub alisamento.Adotaremos a primeira abordagem e nos contentaremos em encontrar uma banda de confiança para \(\overline{r}_n(x)\).
Construindo bandas de confiança
Assuma que \(\widehat{r}_n(x)\) seja um suavizador linear, de modo que \(\widehat{r}_n(x) = \sum_{i=1}^n \mathcal{l}_i(x)Y_i\). Então, \[\begin{equation} \overline{r}_n(x) \, = \, \mbox{E}\big( \widehat{r}_n(x)\big) \, = \, \sum_{i=1}^n \mathcal{l}_i(x)r(x_i)\cdot \end{equation}\]
Por enquanto, vamos assumir que \(\sigma^2(x)=\sigma^2=\mbox{Var}(\epsilon_i)\) seja constante. Então, \[\begin{equation} \mbox{Var}\big(\widehat{r}_n(x)\big) \, = \, \sigma^2 ||\mathcal{l}(x) ||^2\cdot \end{equation}\]
Vamos considerar uma banda de confiança para \(\overline{r}_n(x)\) da forma \[\begin{equation} \mbox{I}(x) \, = \, \Big( \widehat{r}_n(x) \, - \, c \widehat{\sigma}||\mathcal{l} ||, \, \widehat{r}_n(x) \, + \, c \widehat{\sigma}||\mathcal{l} ||\Big), \end{equation}\] para algum \(c>0\) e \(a\leq x\leq b\).
Seguiremos a abordagem em Sun and Loader (1994). Primeiro suponha que \(\sigma\) seja conhecido. Então, \[\begin{equation} P\Big( \overline{r}(x) \, \notin \, \mbox{I}(x) \; \mbox{para algum} \; x\in[a,b]\Big) \, = \, \displaystyle P\left( {\mbox{max}_{x\in [a,b]}} \, \frac{|\widehat{r}_n(x)-\overline{r}_n(x)|}{\sigma||\mathcal{l} ||} > c \right) \, = \\ \qquad \qquad \qquad \qquad \qquad = \, P\left( {\mbox{max}_{x\in [a,b]}} \, \frac{|\sum_{i=1}^n \epsilon_i\mathcal{l}_i(x)|}{\sigma||\mathcal{l} ||} > c \right) \, = \, P\left( {\mbox{max}_{x\in [a,b]}} \, |W(x)| > c \right), \end{equation}\] onde \(W(x)=\sum_{i=1}^n Z_i T_i(x)\), \(Z_i=\epsilon_i/\sigma\sim N(0,1)\) e \(T_i(x)=\mathcal{l}_i(x)/||\mathcal{l}(x)||\).
Agora, \(W(x)\) é um processo gaussiano. Para encontrar \(c\), precisamos ser capazes de calcular a distribuição do máximo de um processo gaussiano. Felizmente, esse é um problema bem estudado. Em particular, Sun and Loader (1994) mostraram que, a chamada de fórmula tubo, seja dada por \[\begin{equation} P\left( \max_x \Big| \sum_{i=1}^n Z_i T_i(x)\Big|> c \right) \, \approx \, 2\big( 1-\Phi(c)\big) \, + \, \frac{\kappa_0}{\pi}e^{-c^2/2}, \end{equation}\] para \(c\) grande, onde \[\begin{equation} \kappa_0 \, = \, \int_a^b || \, T'(x) \, ||\mbox{d}x, \end{equation}\] \(T'(x)=(T_1'(x),\cdots,T_n'(x))\) e \(T_i'(x)=\partial T_i(x)/\partial x\).
Se escolhermos \(c\) como o valor que resolve a equação \[\begin{equation} 2\big( 1-\Phi(c)\big) \, + \, \frac{\kappa_0}{\pi}e^{-c^2/2} \, = \, \alpha, \end{equation}\] então obtemos a banda de confiança simultânea desejada. Caso \(\sigma\) seja desconhecido, usamos uma estimativa \(\widehat{\sigma}\). Sun and Loader sugerem substituir o lado direito da fórmula tubo com \[\begin{equation} P(|T_m|>c) \, + \, \frac{\kappa_0}{\pi}\left( 1+\frac{c^2}{m}\right)^{-m/2} \end{equation}\] onde \(T_m\) têm distribuição \(t-Student\) com \(m=n-\mbox{tr}(L)\) graus de liberdade. Para \(n\) grande, continua a ser uma aproximação adequada.
Agora suponhamos que \(\sigma(x)\) seja uma função de \(x\). Então, \[\begin{equation} \mbox{Var}\big( \widehat{r}_n(x)\big) \, = \, \sum_{i=1}^n \sigma^2(x_i)l_i^2(x)\cdot \end{equation}\] Neste caso escolhemos que \[\begin{equation} I(x) \, = \, \widehat{r}_n(x)\pm c \, s(x), \end{equation}\] sendo que \[\begin{equation} s(x) \, = \, \sqrt{\sum_{i=1}^n \widehat{\sigma}^2(x_i)l_i^2(x)}, \end{equation}\] onde \(\widehat{\sigma}(x)\) é um estimador de \(\sigma(x)\) e \(c\) a constante definida acima. Caso \(\widehat{\sigma}(x)\) varie lentamente com \(x\), então \(\sigma_(x_i)\approx \sigma(x)\) para aqueles \(i\) tais que \(l_i(x)\) é grande e então \[\begin{equation} s(x) \, \approx \, \widehat{\sigma}(x)||l(x)||\cdot \end{equation}\]
Assim, uma banda de confiança aproximada é \[\begin{equation} I(x) \, = \, \widehat{r}_n(x) \, \pm \, c \, \widehat{\sigma}(x)||l(x)||\cdot \end{equation}\] Para mais detalhes sobre esses métodos, veja Faraway and Sun (1995). Esta será a banda de confiança que utilizaremos de preferência.
Exemplo 11.
Utilizaremos os dados do Exemplo 1. Para o modelo no objeto R model.npar05 vamos mostrar a variância estimada e a banda de confiança. Existe uma saáda padrão do comando locpol, mas não gostamos do resultado. Então, utilizamos nossa própria função. Mostramos o resultado para o modelo ajustado utilizando polinómios locais.
plot(model.npar05$lpFit[, model.npar05$X], model.npar05$lpFit$var, type = "l",
xlab = model.npar05$X, ylab = "Variância", col = "darkgreen"); grid()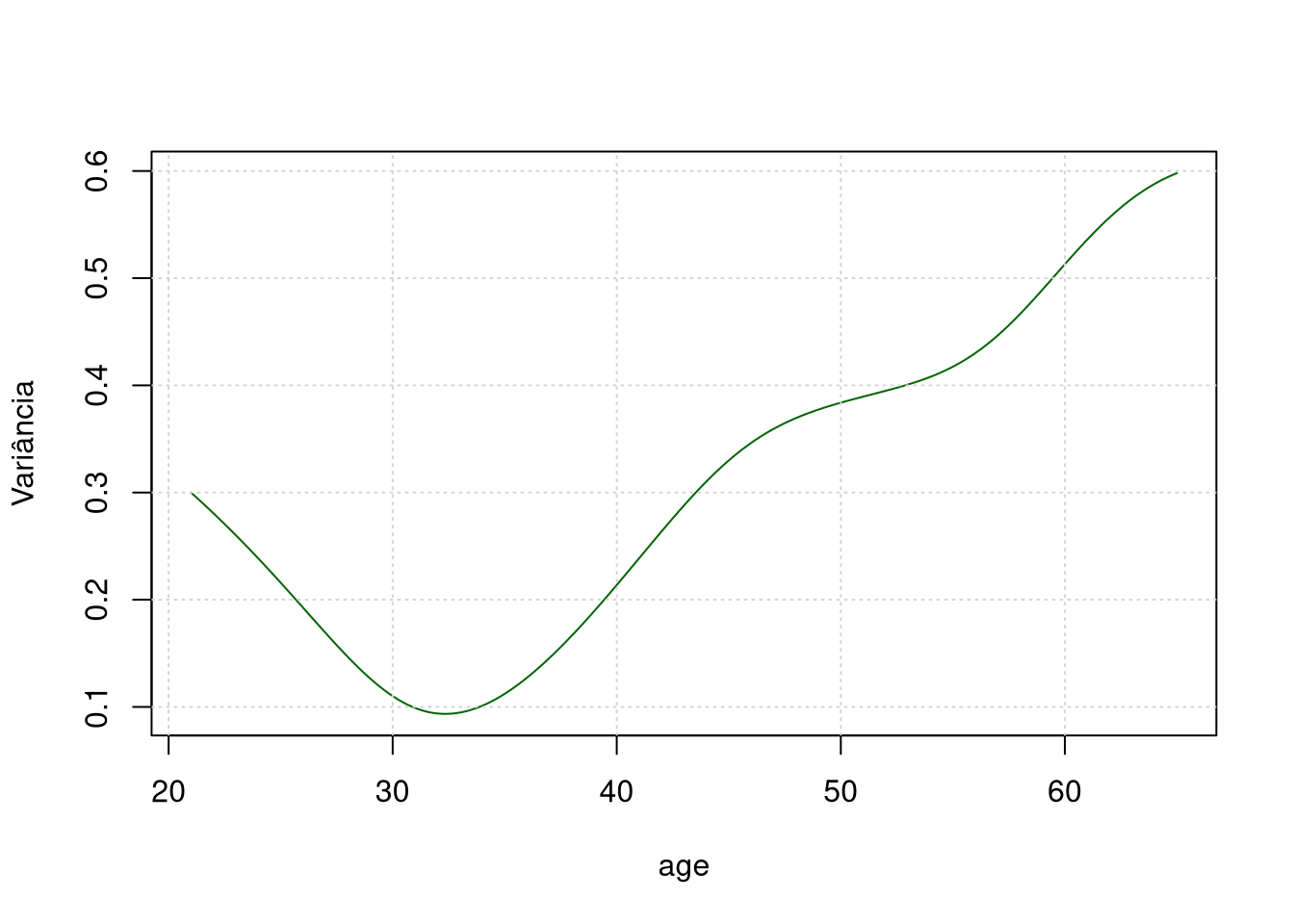
par(mfrow = c(1,1), mar = c(4, 4, 1, 1))
plot(logwage ~ age, data = cps71, col = "blue", pch=19, cex = 0.8);grid()
lines(model.npar05$lpFit[,1], model.npar05$lpFit[,2], col = "red", lwd = 3)
Intervalo.Conf = function (x)
{
dev <- sqrt(x$CIwidth * x$lpFit$var/x$lpFit$xDen)
points(x$lpFit[, x$X], x$lpFit[, x$Y] + 2 * dev, type = "l", lwd = 2,
col = "darkgreen")
points(x$lpFit[, x$X], x$lpFit[, x$Y] - 2 * dev, type = "l", lwd = 2,
col = "darkgreen")
}
Intervalo.Conf(model.npar05)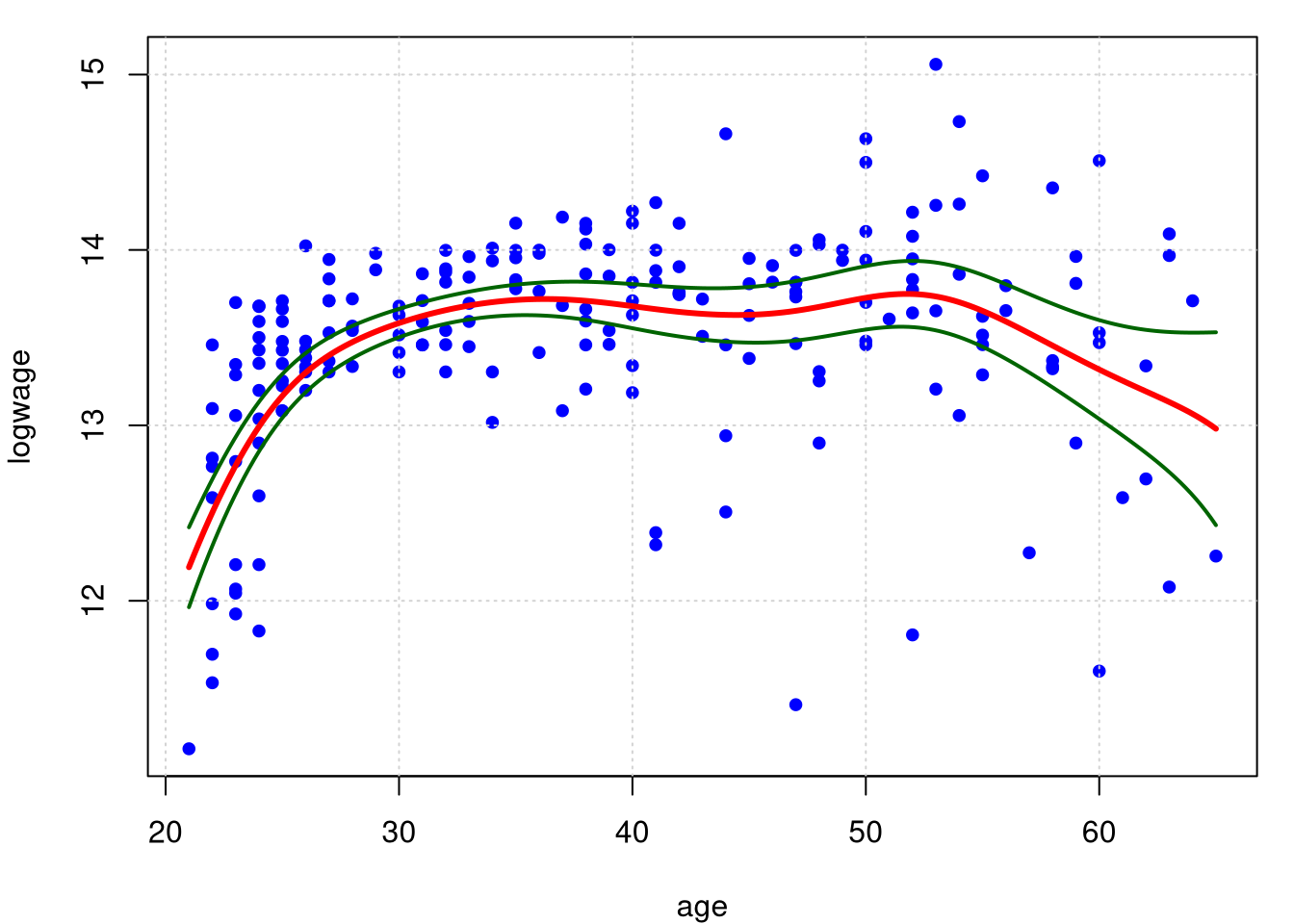
Agora o caso do modelo em model.npar06, nesta situação foram utilizado splines. Vamos investigar uma outra forma de encontrarmos faixas de confiança para o spline. Desta vez, precisamos fazer o bootstrap, e podemos fazê-lo reamostrando os resíduos ou reamostrando os todos os dados. Vamos escolher a última abordagem, que pressupõe menos sobre os dados. Precisamos de um simulador.
simulador = function(dados){
n = nrow(dados)
resample.rows = sample(1:n, size = n, replace = TRUE)
return(dados[resample.rows,])
}Tratamos assim os pontos no gráfico de dispersão como uma população completa e, em seguida, extraímos uma amostra deles, com substituição, tão grande quanto o original. Também precisamos de um estimador. O que queremos fazer é obter um monte de curvas de spline, uma em cada conjunto de dados simulado. Mas, como os valores da variável de entrada mudam de uma simulação para outra, para tornar tudo comparável, avaliamos cada função spline em uma grade fixa de pontos, que percorre o intervalo dos dados.
spline.estimator = function(dados, m=300){
# Ajuste por spline aos dados, com validação cruzada para selecionar lambda
ajuste = smooth.spline(x=dados[,1], y=dados[,2], cv=TRUE)
# Configurando uma grade de pontos com espaçamento uniforme para avaliar o spline
eval.grid = seq(from=min(dados[,1]), to=max(dados[,1]), length.out=m)
# Um pouco ineficiente para redefinir a mesma grade toda vez que chamamos isso,
# mas não uma grande sobrecarga
# Fazemos a previsão e retornamos os valores previstos
return(predict(ajuste, x=eval.grid)$y) # Somente queremos os valores previstos
}Isso define o número de pontos de avaliação como 300, que é grande o suficiente para fornecer curvas visualmente suaves, mas não tão grandes a ponto de serem computacionalmente incômodas. Agora juntemo-os para obter bandas de confiança.
spline.cis = function(dados, B, alpha, m=300) {
spline.main = spline.estimator(dados, m=m)
# Desenhe B amostras de bootstrap, ajustemos o spline para cada
spline.boots = replicate(B, spline.estimator(simulador(dados),m=m))
# O resultado tem m linhas e B colunas
cis.lower = 2*spline.main - apply(spline.boots,1,quantile,probs=1-alpha/2)
cis.upper = 2*spline.main - apply(spline.boots,1,quantile,probs=alpha/2)
return(list(main.curve = spline.main,lower.ci=cis.lower,upper.ci=cis.upper,
x=seq(from=min(dados[,1]),to=max(dados[,1]),length.out=m)))
}O valor de retorno aqui é uma lista que inclui a curva ajustada original, os limites de confiança inferior e superior e os pontos nos quais todas as funções foram avaliadas.
Exemplo 12. Continuando o Exemplo 11, mostramos agora o rssultado do ajuste utilizando spline.
## logwage age
## 1 11.1563 21
## 2 12.8131 22
## 3 13.0960 22
## 4 11.6952 22
## 5 11.5327 22
## 6 12.7657 22## age logwaget
## 1 21 11.1563
## 2 22 12.8131
## 3 22 13.0960
## 4 22 11.6952
## 5 22 11.5327
## 6 22 12.7657Construímos a nova base de dados dados porque nas funções spline.estimaotr e spline.cis assumimos a primeira coluna como x e a segunda coluna da base dados como y. Observe que na base de dados original estas variáveis estavam trocadas de posição.
dados.cis = spline.cis(dados, B=1000, alpha=0.05)
par(mfrow = c(1,1), mar = c(4, 5, 2, 1))
plot(logwage ~ age, data = cps71, col = "blue", pch=19, cex = 0.8); grid()
lines(model.npar06, col = "red", lwd = 3)
lines(x=dados.cis$x, y=dados.cis$lower.ci, lwd = 2, col = "darkgreen")
lines(x=dados.cis$x, y=dados.cis$upper.ci, lwd = 2, col = "darkgreen")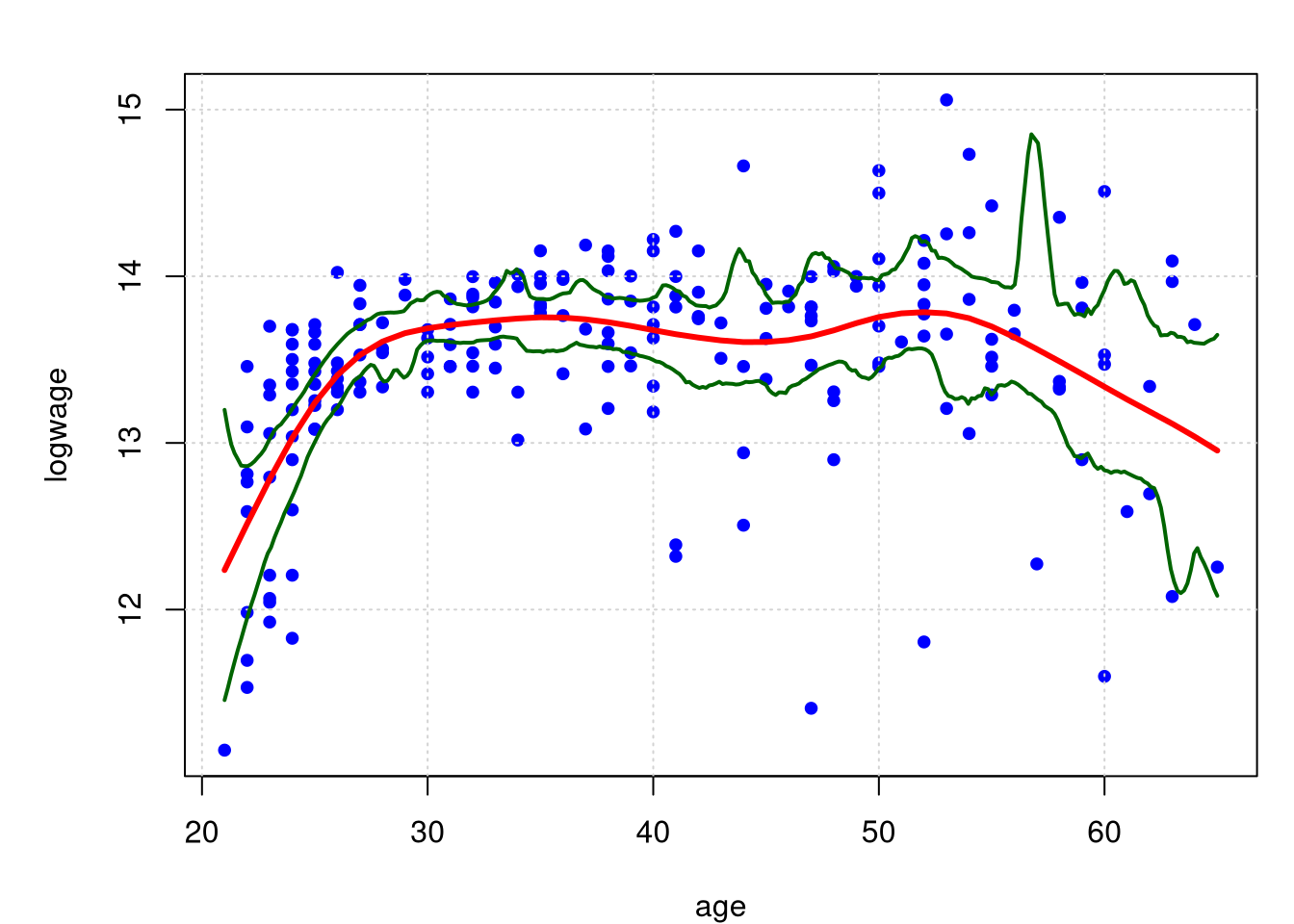
No gráficos acima mostramos os limites de confiança de 95% resultantes, com base nas B = 1000 replicações bootstrap. Estas bandas são claramente assimétricas da mesma forma que a curva se ajusta a todos os dados, mas perceba como elas são largas e como elas se ampliam à medida que vamos do centro dos dados em qualquer direção.
No caso do gráfico abaixo utilizamos o resultado das bandas de confiança mostradas nesta seção e utilizamos o resultado guardado em sigma06.
norma = sum(model.npar06$lev^2)
par(mfrow = c(1,1), mar = c(4, 5, 2, 1))
plot(logwage ~ age, data = cps71, col = "blue", pch=19)
lines(model.npar06, col = "red", lwd = 3)
lines(model.npar06$x, model.npar06$y +
2*sqrt(sigma06[model.npar06$x])*norma, lwd = 2, col = "darkgreen")
lines(model.npar06$x, model.npar06$y -
2*sqrt(sigma06[model.npar06$x])*norma, lwd = 2, col = "darkgreen")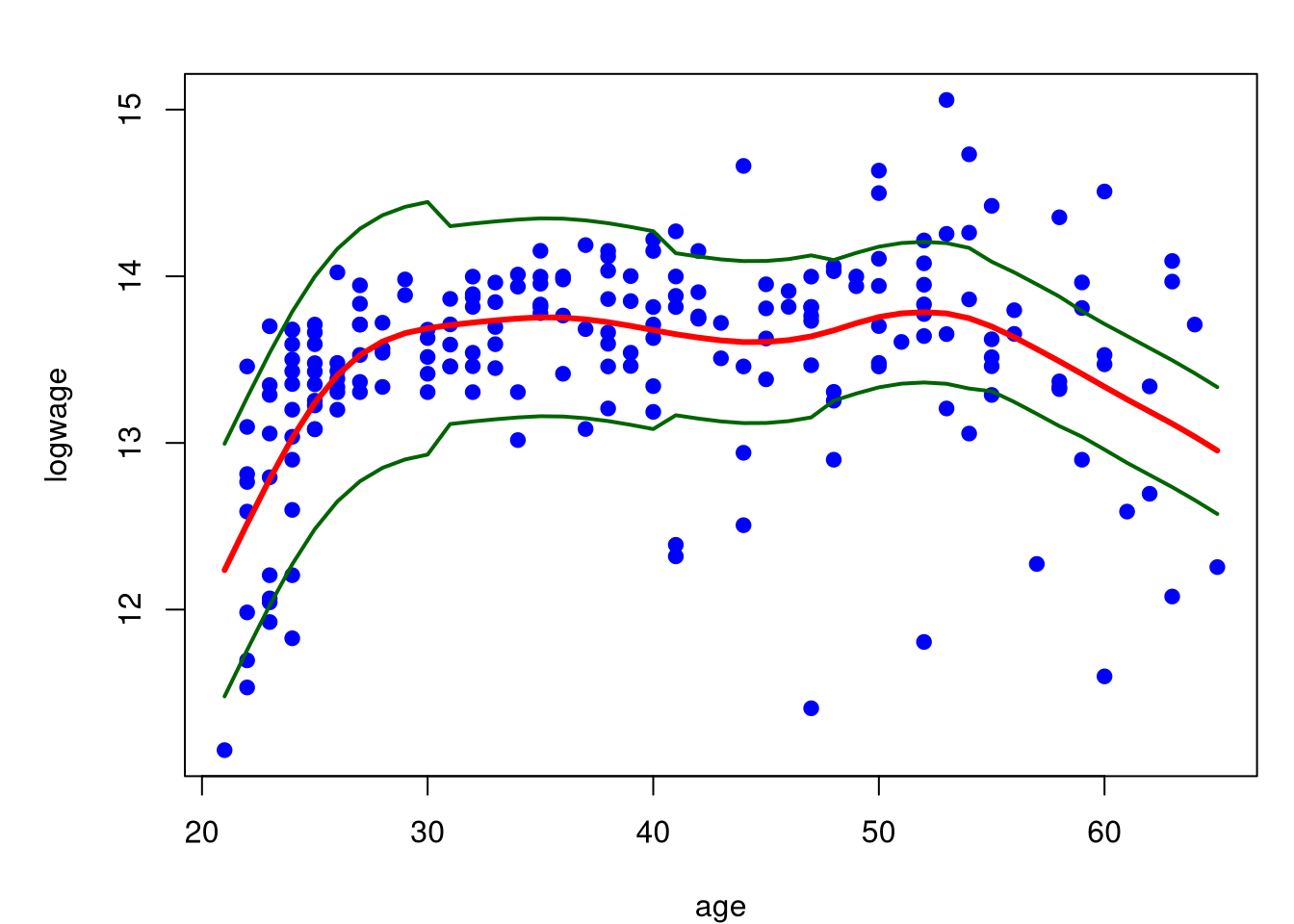
5.3 Cobertura média
Pode-se argumentar que exigir que as bandas de confiança cubram a função em todos os \(x\) é muito rigoroso. Wahba (1983), Nychka (1988) e Cummins et al. (2001) introduziram um tipo diferente de cobertura a que nos referimos como cobertura média. Aqui vamos discutir um método para construir bandas de cobertura média com base na ideia em Juditsky and Lambert-Lacroix (2003).
Suponha que estamos estimando \(r(x)\) no intervalo \([0,1]\). Defina a cobertura média de uma banda \((\mathcal{l}, u)\) por \[\begin{equation} \mathcal{C} \, = \, \int_0^1 P\big( r(x) \in [\mathcal{l}(x),u(x)]\big)\mbox{d}x\cdot \end{equation}\] Vamos construir bolas de confiança para \(r\), os quais são conjuntos \(\mathcal{B}_n(\alpha)\), da forma \[\begin{equation} \mathcal{B}_n(\alpha) \, = \, \big\{ r \, : \, ||\widehat{r}_n \, - \, r || \, \leq \, s_n(\alpha)\big\}, \end{equation}\] tais que \[\begin{equation} P\big( r \, \in \, \mathcal{B}_n(\alpha)\big) \, \geq \, 1-\alpha\cdot \end{equation}\]
Dada uma bola de confiança, sejam \[\begin{equation} \displaystyle \mathcal{l}(x) \, = \, \widehat{r}_n(x) \, - \, s_n(\alpha/2)\sqrt{\frac{2}{\alpha}}, \qquad \displaystyle u(x) \, = \, \widehat{r}_n(x) \, + \, s_n(\alpha/2)\sqrt{\frac{2}{\alpha}}\cdot \end{equation}\]
Nós agora vamos mostrar que essas bandas têm uma cobertura média de pelo menos \(1 - \alpha\). Primeiro, observe que \(\mathcal{C} = P\big(r(U)\in [\mathcal{l}(U), u(U)]\big)\) onde \(U\sim U(0,1)\) é independente dos dados. Seja \(A\) o evento que \(r \in \mathcal{B}_n(\alpha/2)\). No evento \(A\), \(||\widehat{r}_n \, - \, r || \, \leq \, s_n(\alpha)\). Escrevendo \(s_n\) para \(s_n(\alpha/2)\) temos, \[\begin{equation} \begin{array}{rcl} 1 - \mathcal{C} & = & P\Big( r(U) \, \notin [\mathcal{l}(U), u(U))]\Big) \, = \, P\Big( |\widehat{r}_n(U) - r(U)| \, > \, s_n\sqrt{\frac{2}{\alpha}}\Big) \\ & = & P\Big( |\widehat{r}_n(U) - r(U)| \, > \, s_n\sqrt{\frac{2}{\alpha}}, \, A \Big) \, + \, P\Big( |\widehat{r}_n(U) - r(U)| \, > \, s_n\sqrt{\frac{2}{\alpha}}, \, A^c \Big) \\ & \leq & P\Big( |\widehat{r}_n(U) - r(U)| \, > \, s_n\sqrt{\frac{2}{\alpha}}, \, A \Big) \, + \, P(A^c) \\ & \leq & \displaystyle\frac{\mbox{E}\big( \mbox{I}_A||\widehat{r}_n \, - \, r ||^2 \big)}{\displaystyle s_n^2\frac{2}{\alpha}} \, + \, \frac{\alpha}{2} \, \leq \, \frac{s_n^2}{\displaystyle s_n^2\frac{2}{\alpha}} \, + \, \frac{\alpha}{2} \, \leq \, \alpha\cdot \end{array} \end{equation}\]